OpenAI Codex驾驭工程:在以代理为先的世界中利用Codex Harness engineering: leveraging Codex in an agent-first world
Harness engineering: leveraging Codex in an agent-first world
驾驭工程:在以代理为先的世界中利用
https://openai.com/index/harness-engineering/
Over the past five months, our team has been running an experiment: building and shipping an internal beta of a software product with 0 lines of manually-written code.
The product has internal daily users and external alpha testers. It ships, deploys, breaks, and gets fixed. What’s different is that every line of code—application logic, tests, CI configuration, documentation, observability, and internal tooling—has been written by Codex. We estimate that we built this in about 1/10th the time it would have taken to write the code by hand.
在过去的五个月里,我们团队一直在进行一项实验:开发并发布了一个内部测试版的软件产品,且全程未手动编写一行代码。
该产品拥有内部日常用户和外部测试人员。它会正常发布、部署,也会崩溃并得到修复。不同之处在于每一行代码——包括应用逻辑、测试用例、持续集成配置、文档说明、可观测性工具和内部工具——都是由Codex自动生成的。我们估算这次开发耗时仅为人工编写代码所需时间的十分之一。
Humans steer. Agents execute.
We intentionally chose this constraint so we would build what was necessary to increase engineering velocity by orders of magnitude. We had weeks to ship what ended up being a million lines of code. To do that, we needed to understand what changes when a software engineering team’s primary job is no longer to write code, but to design environments, specify intent, and build feedback loops that allow Codex agents to do reliable work.
This post is about what we learned by building a brand new product with a team of agents—what broke, what compounded, and how to maximize our one truly scarce resource: human time and attention.
人类掌舵,代理执行。
我们特意选择这一限制条件,是为了构建能大幅提升工程效率的必要系统。在短短数周内,我们完成了最终达百万行代码的项目交付。要实现这一点,我们必须重新思考:当软件工程团队的核心任务从编写代码转变为设计环境、明确意图、构建反馈机制以使Codex代理能可靠工作时,整个工作范式将发生怎样的变革。
本文记录了我们与代理团队共同开发全新产品的经验教训——哪些环节遭遇瓶颈,哪些优势产生复利效应,以及如何最大化利用我们真正稀缺的资源:人类的时间与注意力。
We started with an empty git repository
我们从一个空的 git 仓库开始
The first commit to an empty repository landed in late August 2025.
The initial scaffold—repository structure, CI configuration, formatting rules, package manager setup, and application framework—was generated by Codex CLI using GPT‑5, guided by a small set of existing templates. Even the initial AGENTS.md file that directs agents how to work in the repository was itself written by Codex.
2025年8月下旬,空仓库迎来了首次提交。
最初的脚手架——包括仓库结构、持续集成配置、格式化规则、包管理器设置和应用程序框架——是由Codex CLI在少量现有模板的指导下,基于GPT-5生成的。就连指导智能体如何在仓库中工作的初始AGENTS.md文件,也是由Codex自行撰写的。
There was no pre-existing human-written code to anchor the system. From the beginning, the repository was shaped by the agent.
Five months later, the repository contains on the order of a million lines of code across application logic, infrastructure, tooling, documentation, and internal developer utilities. Over that period, roughly 1,500 pull requests have been opened and merged with a small team of just three engineers driving Codex. This translates to an average throughput of 3.5 PRs per engineer per day, and surprisingly the throughput has increased as the team has grown to now seven engineers. Importantly, this wasn’t output for output’s sake: the product has been used by hundreds of users internally, including daily internal power users.
Throughout the development process, humans never directly contributed any code. This became a core philosophy for the team: no manually-written code.
一开始并没有预先由人类编写的代码作为系统基础。从一开始,这个代码库就是由智能体塑造的。
五个月后,该代码库已经包含了约百万行代码,涵盖应用逻辑、基础设施、工具链、文档和内部开发者实用程序。在此期间,仅由三名工程师组成的小团队驱动Codex,他们开启并合并了约1500个拉取请求。这意味着每位工程师平均每天处理3.5个PR,而令人惊讶的是,随着团队扩大到七名工程师,吞吐量反而有所提升。重要的是,这些产出并非为了数量而数量:该产品已被数百名内部用户使用,其中包括日常高频使用的内部资深用户。
在整个开发过程中,人类从未直接贡献过任何代码。这成为了团队的核心理念:不手动编写代码。
Redefining the role of the engineer
重新定义工程师的角色
The lack of hands-on human coding introduced a different kind of engineering work, focused on systems, scaffolding, and leverage.
Early progress was slower than we expected, not because Codex was incapable, but because the environment was underspecified. The agent lacked the tools, abstractions, and internal structure required to make progress toward high-level goals. The primary job of our engineering team became enabling the agents to do useful work.
In practice, this meant working depth-first: breaking down larger goals into smaller building blocks (design, code, review, test, etc), prompting the agent to construct those blocks, and using them to unlock more complex tasks. When something failed, the fix was almost never “try harder.” Because the only way to make progress was to get Codex to do the work, human engineers always stepped into the task and asked: “what capability is missing, and how do we make it both legible and enforceable for the agent?”
缺乏实际的人工编码引入了一种不同的工程工作,其重点在于系统、脚手架和杠杆作用。
早期的进展比我们预期的要慢,不是因为Codex能力不足,而是因为环境未被充分定义。智能体缺乏实现高层次目标所需的工具、抽象概念和内部结构。我们工程团队的主要工作变成了让智能体能够完成有用的任务。
在实践中,这意味着采用深度优先的工作方式:将大目标分解为更小的构建模块(设计、编码、审查、测试等),提示智能体构建这些模块,并利用它们来解锁更复杂的任务。当某个环节失败时,解决方法几乎从来不是"再努力一点"。因为取得进展的唯一途径就是让Codex完成工作,人类工程师总是会介入任务并提出:"缺少什么能力?我们如何让智能体既能理解又能执行这项能力?"
Humans interact with the system almost entirely through prompts: an engineer describes a task, runs the agent, and allows it to open a pull request. To drive a PR to completion, we instruct Codex to review its own changes locally, request additional specific agent reviews both locally and in the cloud, respond to any human or agent given feedback, and iterate in a loop until all agent reviewers are satisfied (effectively this is a Ralph Wiggum Loop(opens in a new window)). Codex uses our standard development tools directly (gh, local scripts, and repository-embedded skills) to gather context without humans copying and pasting into the CLI.
Humans may review pull requests, but aren’t required to. Over time, we’ve pushed almost all review effort towards being handled agent-to-agent.
人类几乎完全通过提示与系统交互:工程师描述任务、运行代理程序,并允许其提交拉取请求。为了推动PR完成流程,我们会指示Codex在本地审查自身修改,请求本地和云端其他特定代理的审查,回应任何人类或代理给出的反馈,并循环迭代直至所有代理审核者满意(这本质上是一个拉尔夫·威格姆循环(在新窗口中打开))。Codex直接使用我们的标准开发工具(gh命令、本地脚本和仓库嵌入式技能)来收集上下文,无需人类通过CLI进行复制粘贴操作。
人类可以审查拉取请求,但并非必须参与。随着时间的推移,我们已将几乎所有审查工作转向由代理间自主处理。
Increasing application legibility
提高应用程序可读性
As code throughput increased, our bottleneck became human QA capacity. Because the fixed constraint has been human time and attention, we’ve worked to add more capabilities to the agent by making things like the application UI, logs, and app metrics themselves directly legible to Codex.
For example, we made the app bootable per git worktree, so Codex could launch and drive one instance per change. We also wired the Chrome DevTools Protocol into the agent runtime and created skills for working with DOM snapshots, screenshots, and navigation. This enabled Codex to reproduce bugs, validate fixes, and reason about UI behavior directly.
随着代码吞吐量的增加,我们的瓶颈变成了人工质量检测的能力。由于固定约束一直是人类的时间和注意力,我们努力通过让应用程序用户界面、日志和应用指标本身对Codex直接可读,来为代理添加更多功能。
例如,我们使应用程序可以在每个git工作树中启动,因此Codex可以为每个变更启动并驱动一个实例。我们还将Chrome开发者工具协议集成到代理运行时中,并创建了处理DOM快照、屏幕截图和导航的技能。这使得Codex能够直接复现错误、验证修复并推理用户界面行为。
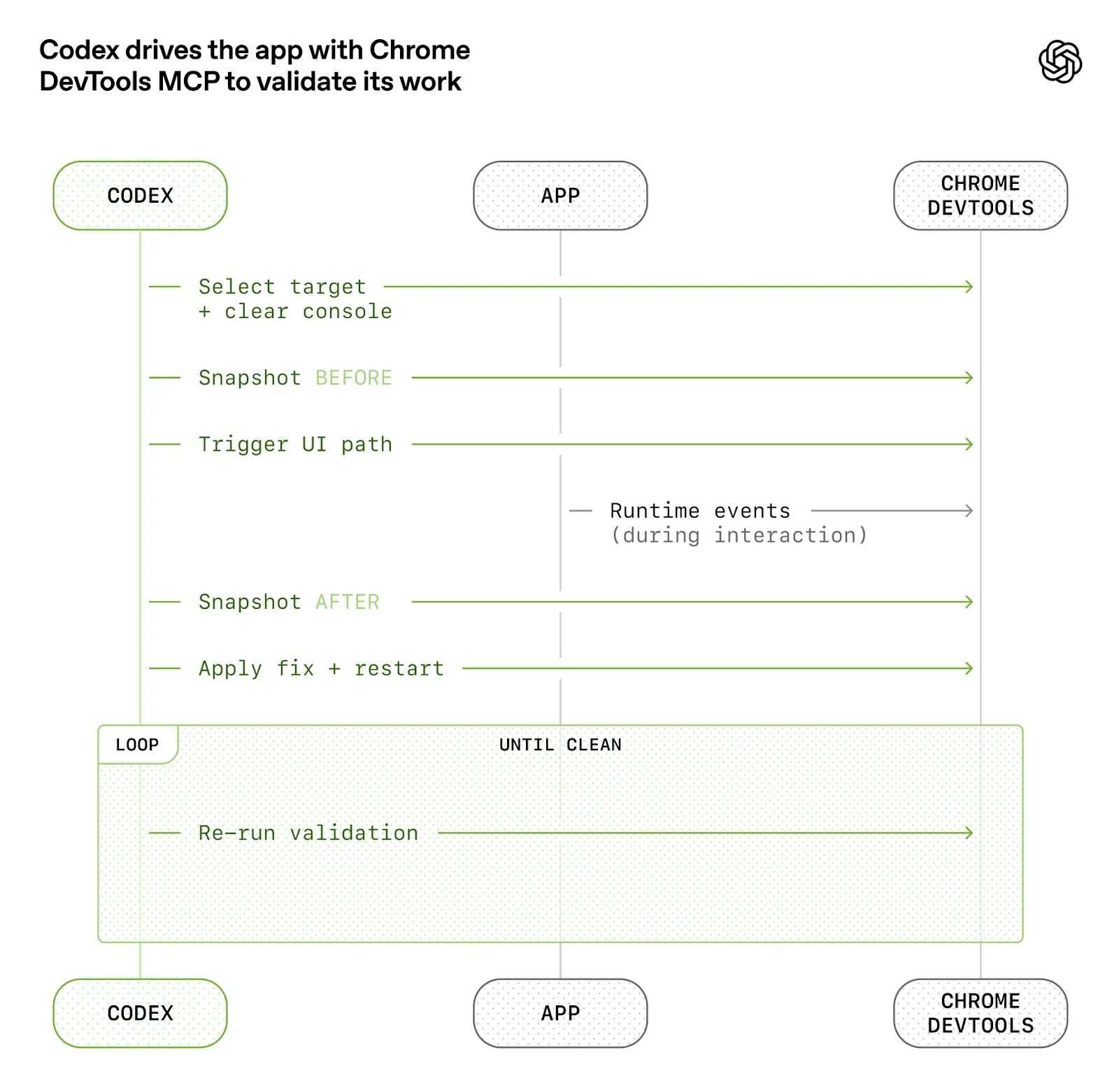
We did the same for observability tooling. Logs, metrics, and traces are exposed to Codex via a local observability stack that’s ephemeral for any given worktree. Codex works on a fully isolated version of that app—including its logs and metrics, which get torn down once that task is complete. Agents can query logs with LogQL and metrics with PromQL. With this context available, prompts like “ensure service startup completes in under 800ms” or “no span in these four critical user journeys exceeds two seconds” become tractable.
我们对可观测性工具也做了同样的处理。日志、指标和追踪信息通过一个临时性的本地可观测性栈暴露给Codex,该栈针对每个工作树都是临时的。Codex在一个完全隔离的应用版本上工作——包括其日志和指标,这些都会在任务完成后被销毁。代理可以使用LogQL查询日志,使用PromQL查询指标。有了这些上下文,诸如"确保服务启动在800毫秒内完成"或"这四个关键用户旅程中的任何跨度不超过两秒"这样的提示就变得可行了。
We regularly see single Codex runs work on a single task for upwards of six hours (often while the humans are sleeping).
我们经常看到单个Codex运行在单个任务上工作长达六个小时(通常是在人类睡觉的时候)。
We made repository knowledge the system of record
我们将知识库打造为记录系统
Context management is one of the biggest challenges in making agents effective at large and complex tasks. One of the earliest lessons we learned was simple: give Codex a map, not a 1,000-page instruction manual.
We tried the “one big AGENTS.md(opens in a new window)” approach. It failed in predictable ways:
- Context is a scarce resource. A giant instruction file crowds out the task, the code, and the relevant docs—so the agent either misses key constraints or starts optimizing for the wrong ones.
- Too much guidance becomes non-guidance. When everything is “important,” nothing is. Agents end up pattern-matching locally instead of navigating intentionally.
- It rots instantly. A monolithic manual turns into a graveyard of stale rules. Agents can’t tell what’s still true, humans stop maintaining it, and the file quietly becomes an attractive nuisance.
- It’s hard to verify. A single blob doesn’t lend itself to mechanical checks (coverage, freshness, ownership, cross-links), so drift is inevitable.
So instead of treating AGENTS.md as the encyclopedia, we treat it as the table of contents.
上下文管理是让智能体有效处理大型复杂任务时面临的最大挑战之一。我们最早获得的经验很简单:给Codex一张地图,而不是一本千页说明书。
我们尝试过"超大AGENTS.md(在新窗口打开)"方案,它以可预见的方式失败了:
上下文是稀缺资源。庞大的说明文件会挤占任务、代码和相关文档的空间——导致智能体要么遗漏关键约束,要么开始针对错误约束进行优化。
过度指导等于没有指导。当所有内容都标注"重要"时,真正重要的反而被淹没。智能体最终只会进行局部模式匹配,而非有意识地全局导航。
即时腐化。庞大的手册会迅速变成过时规则的坟场。智能体无法辨别哪些规则仍然有效,人类维护者停止更新,文件悄然成为具有诱惑性的无用信息。
难以验证。单一文档不利于机械化检查(覆盖率、时效性、归属权、交叉引用),因此规则漂移不可避免。
因此我们不再将AGENTS.md视为百科全书,而是作为目录使用。
The repository’s knowledge base lives in a structured docs/ directory treated as the system of record. A short AGENTS.md (roughly 100 lines) is injected into context and serves primarily as a map, with pointers to deeper sources of truth elsewhere.
存储库的知识库位于结构化的 docs/ 目录中,被视为记录系统。一个简短的 AGENTS.md(大约 100 行)被注入到上下文中,主要用作地图,指向其他更深层次的真相来源。
1AGENTS.md
2
ARCHITECTURE.md
3
docs/
4
├── design-docs/
5
│ ├── index.md
6
│ ├── core-beliefs.md
7
│ └── ...
8
├── exec-plans/
9
│ ├── active/
10
│ ├── completed/
11
│ └── tech-debt-tracker.md
12
├── generated/
13
│ └── db-schema.md
14
├── product-specs/
15
│ ├── index.md
16
│ ├── new-user-onboarding.md
17
│ └── ...
18
├── references/
19
│ ├── design-system-reference-llms.txt
20
│ ├── nixpacks-llms.txt
21
│ ├── uv-llms.txt
22
│ └── ...
23
├── DESIGN.md
24
├── FRONTEND.md
25
├── PLANS.md
26
├── PRODUCT_SENSE.md
27
├── QUALITY_SCORE.md
28
├── RELIABILITY.md
29
└── SECURITY.mdDesign documentation is catalogued and indexed, including verification status and a set of core beliefs that define agent-first operating principles. Architecture documentation(opens in a new window) provides a top-level map of domains and package layering. A quality document grades each product domain and architectural layer, tracking gaps over time.
Plans are treated as first-class artifacts. Ephemeral lightweight plans are used for small changes, while complex work is captured in execution plans(opens in a new window) with progress and decision logs that are checked into the repository. Active plans, completed plans, and known technical debt are all versioned and co-located, allowing agents to operate without relying on external context.
This enables progressive disclosure: agents start with a small, stable entry point and are taught where to look next, rather than being overwhelmed up front.
We enforce this mechanically. Dedicated linters and CI jobs validate that the knowledge base is up to date, cross-linked, and structured correctly. A recurring “doc-gardening” agent scans for stale or obsolete documentation that does not reflect the real code behavior and opens fix-up pull requests.
设计文档已编目并建立索引,包含验证状态和定义"智能体优先"操作原则的核心信念集。架构文档(在新窗口中打开)提供了领域和包分层的高级图谱。质量文档会对各产品领域和架构层进行评级,并跟踪随时间推移产生的差距。
计划被视为一等产物。短暂性轻量计划用于小型变更,而复杂工作则通过执行计划(在新窗口中打开)来记录,其中包含进度和决策日志,并会签入代码库。活跃计划、已完成计划以及已知技术债务均进行版本控制并集中存放,使智能体无需依赖外部上下文即可运作。
这实现了渐进式披露:智能体从一个小而稳定的入口点开始,并被引导下一步该查看何处,而非一开始就面临信息过载。
我们通过机制化手段强制执行这一原则。专用检测工具和持续集成任务会验证知识库是否处于最新状态、正确交叉链接且结构无误。周期性运行的"文档园艺"智能体会扫描与真实代码行为不符的过时文档,并提交修复拉取请求。
Agent legibility is the goal
代理可读性是目标
As the codebase evolved, Codex’s framework for design decisions needed to evolve, too.
Because the repository is entirely agent-generated, it’s optimized first for Codex’s legibility. In the same way teams aim to improve navigability of their code for new engineering hires, our human engineers’ goal was making it possible for an agent to reason about the full business domain directly from the repository itself.
From the agent’s point of view, anything it can’t access in-context while running effectively doesn’t exist. Knowledge that lives in Google Docs, chat threads, or people’s heads are not accessible to the system. Repository-local, versioned artifacts (e.g., code, markdown, schemas, executable plans) are all it can see.
随着代码库的演进,Codex的设计决策框架也需要同步进化。
由于该代码库完全由智能体生成,其首要优化目标是确保Codex的可解读性。就像开发团队致力于提高代码对新入职工程师的可导航性那样,我们人类工程师的目标是让智能体能够直接从代码库本身理解完整的业务领域。
从智能体的视角来看,任何它在运行过程中无法在上下文中获取的信息实际上等同于不存在。存储在Google文档、聊天记录或人类头脑中的知识对系统而言都是不可访问的。只有代码库内版本化的产物(如代码、markdown文件、架构图、可执行方案)才是其可见范围。
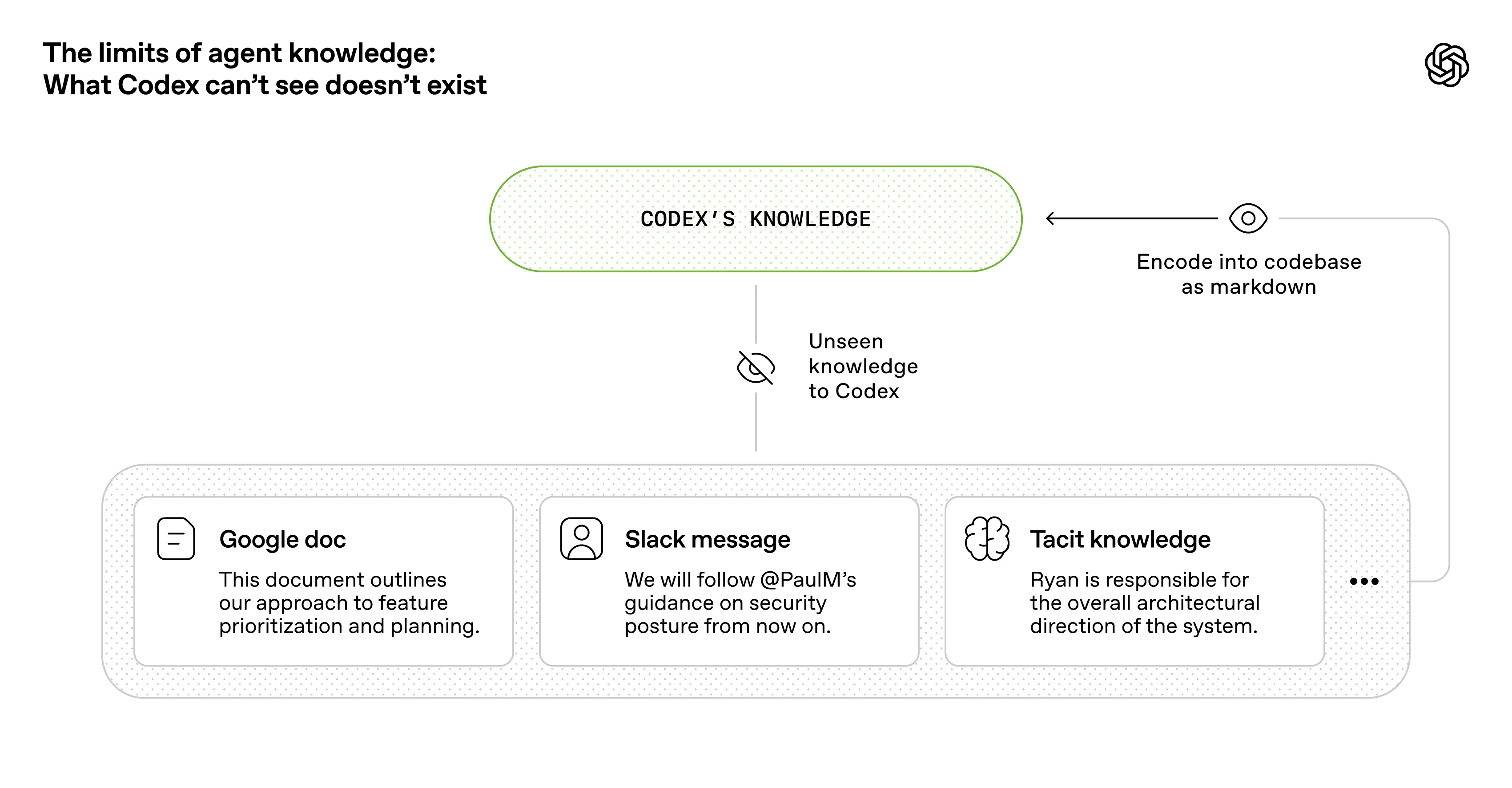
We learned that we needed to push more and more context into the repo over time. That Slack discussion that aligned the team on an architectural pattern? If it isn’t discoverable to the agent, it’s illegible in the same way it would be unknown to a new hire joining three months later.
Giving Codex more context means organizing and exposing the right information so the agent can reason over it, rather than overwhelming it with ad-hoc instructions. In the same way you would onboard a new teammate on product principles, engineering norms, and team culture (emoji preferences included), giving the agent this information leads to better-aligned output.
This framing clarified many tradeoffs. We favored dependencies and abstractions that could be fully internalized and reasoned about in-repo. Technologies often described as “boring” tend to be easier for agents to model due to composability, api stability, and representation in the training set. In some cases, it was cheaper to have the agent reimplement subsets of functionality than to work around opaque upstream behavior from public libraries. For example, rather than pulling in a generic p-limit-style package, we implemented our own map-with-concurrency helper: it’s tightly integrated with our OpenTelemetry instrumentation, has 100% test coverage, and behaves exactly the way our runtime expects.
Pulling more of the system into a form the agent can inspect, validate, and modify directly increases leverage—not just for Codex, but for other agents (e.g. Aardvark) that are working on the codebase as well.
我们逐渐认识到,需要将越来越多的上下文信息纳入代码库。那次让团队就架构模式达成一致的Slack讨论?如果智能体无法发现这些内容,其理解难度就如同三个月后新入职员工对此一无所知。
为Codex提供更多上下文意味着要有条理地组织和呈现恰当信息,使其能够进行推理,而非用临时指令使其不堪重负。就像你会向新成员介绍产品原则、工程规范和团队文化(包括表情符号使用偏好)一样,为智能体提供这些信息能使其输出更符合预期。
这一思路澄清了许多权衡取舍。我们倾向于选择那些能在代码库中被完全内化和推理的依赖项与抽象。那些常被称为"无聊"的技术,由于可组合性、API稳定性和训练集中的代表性,往往更易被智能体建模。某些情况下,让智能体重现部分功能比绕开公共库不透明的上游行为更经济。例如,我们没有引入通用的p-limit类包,而是自行实现了并发控制映射工具:它与我们的OpenTelemetry检测深度集成,拥有100%测试覆盖率,且完全符合运行时预期。
将更多系统内容转化为智能体可检查、验证和直接修改的形式,不仅能提升Codex的杠杆效应,也惠及代码库中的其他智能体(如Aardvark)。
Enforcing architecture and taste
强制执行架构和品味
Documentation alone doesn’t keep a fully agent-generated codebase coherent. By enforcing invariants, not micromanaging implementations, we let agents ship fast without undermining the foundation. For example, we require Codex to parse data shapes at the boundary(opens in a new window), but are not prescriptive on how that happens (the model seems to like Zod, but we didn’t specify that specific library).
Agents are most effective in environments with strict boundaries and predictable structure(opens in a new window), so we built the application around a rigid architectural model. Each business domain is divided into a fixed set of layers, with strictly validated dependency directions and a limited set of permissible edges. These constraints are enforced mechanically via custom linters (Codex-generated, of course!) and structural tests.
The diagram below shows the rule: within each business domain (e.g. App Settings), code can only depend “forward” through a fixed set of layers (Types → Config → Repo → Service → Runtime → UI). Cross-cutting concerns (auth, connectors, telemetry, feature flags) enter through a single explicit interface: Providers. Anything else is disallowed and enforced mechanically.
仅靠文档无法保持完全由智能体生成的代码库的连贯性。通过强化约束条件而非微观管理实现方式,我们让智能体能够快速交付代码而不破坏基础架构。例如,我们要求Codex在边界解析数据结构(在新窗口打开),但不对具体实现方式作硬性规定(模型似乎偏好Zod库,但我们并未指定必须使用该库)。
智能体在具有严格边界和可预测结构的环境中(在新窗口打开)能发挥最大效能,因此我们围绕刚性架构模型构建应用程序。每个业务领域被划分为固定层级,依赖方向经过严格验证,仅允许有限的连接路径。这些约束通过定制化linter(当然由Codex生成!)和结构测试来自动执行。
下图展示了规则:在每个业务领域内(如应用设置),代码只能通过固定层级"向前"依赖(类型→配置→仓库→服务→运行时→用户界面)。横切关注点(认证、连接器、遥测、功能开关)通过单一明确接口进入:Providers。其他任何方式都被禁止并由系统自动拦截。
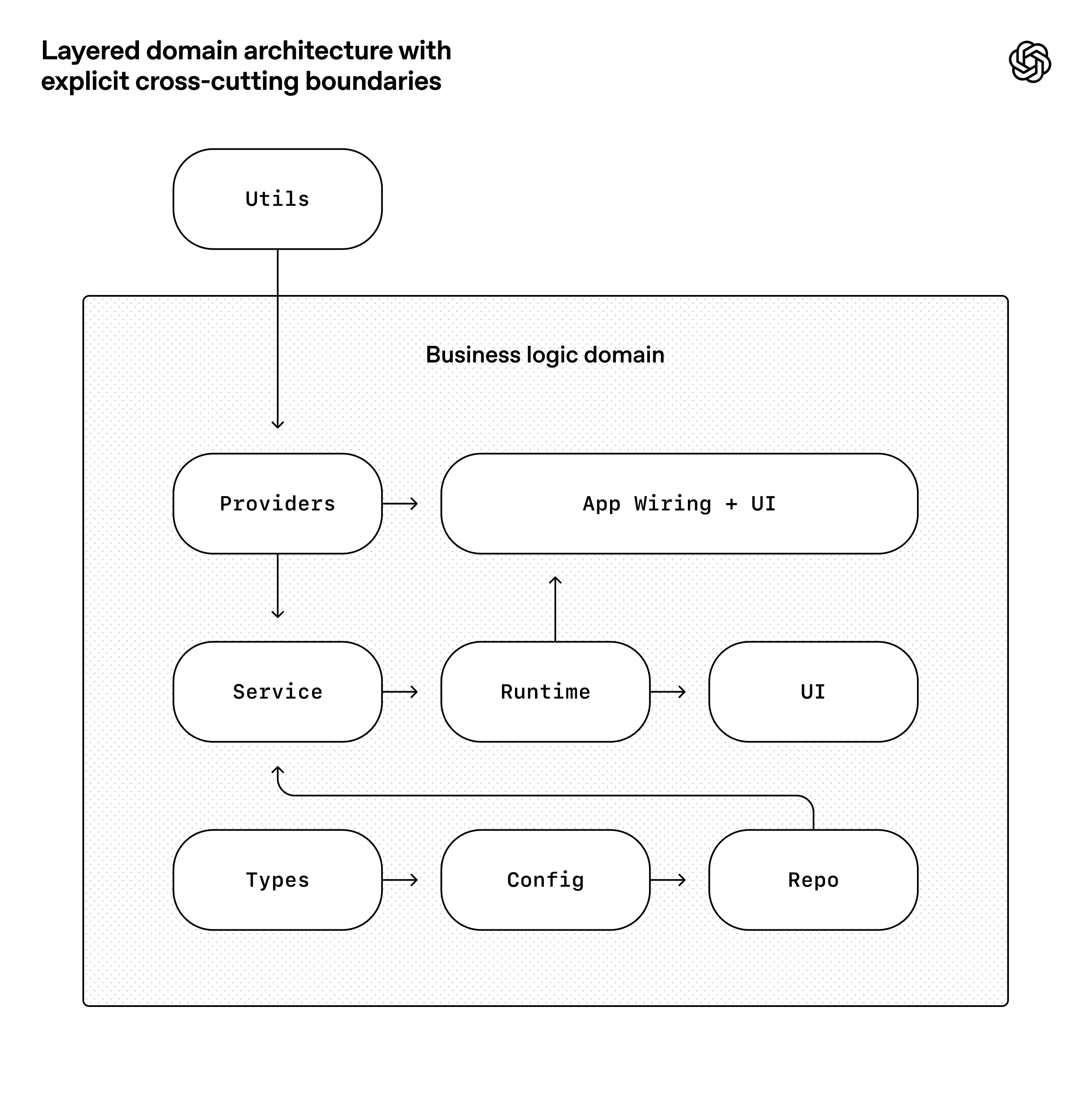
This is the kind of architecture you usually postpone until you have hundreds of engineers. With coding agents, it’s an early prerequisite: the constraints are what allows speed without decay or architectural drift.
In practice, we enforce these rules with custom linters and structural tests, plus a small set of “taste invariants.” For example, we statically enforce structured logging, naming conventions for schemas and types, file size limits, and platform-specific reliability requirements with custom lints. Because the lints are custom, we write the error messages to inject remediation instructions into agent context.
In a human-first workflow, these rules might feel pedantic or constraining. With agents, they become multipliers: once encoded, they apply everywhere at once.
At the same time, we’re explicit about where constraints matter and where they do not. This resembles leading a large engineering platform organization: enforce boundaries centrally, allow autonomy locally. You care deeply about boundaries, correctness, and reproducibility. Within those boundaries, you allow teams—or agents—significant freedom in how solutions are expressed.
这类架构通常要等到拥有数百名工程师时才会着手构建。但对于编码智能体而言,这却是早期必备条件:正是这些约束条件保证了高速推进时不会出现质量滑坡或架构偏移。
实践中,我们通过定制化的代码检查工具、结构性测试以及少量"审美不变准则"来落实这些规则。例如采用静态检查确保结构化日志记录,强制规范数据模型和类型的命名约定,设置文件大小限制,并通过定制检查项落实各平台特定的可靠性要求。由于检查规则是定制的,我们会精心编写错误提示信息,将修复指引直接注入智能体的上下文环境。
在以人为本的工作流程中,这些规则可能显得迂腐或束缚手脚。但对智能体而言,它们却成为效率倍增器:一旦编码实现,就能立即全域生效。
与此同时,我们明确界定哪些领域需要约束、哪些无需干预。这类似于领导大型工程平台组织的理念:中央管控边界,地方保持自治。你需要严格把控系统边界、正确性和可复现性。在这些边界之内,则应给予团队(或智能体)充分的解决方案表达自由。
The resulting code does not always match human stylistic preferences, and that’s okay. As long as the output is correct, maintainable, and legible to future agent runs, it meets the bar.
Human taste is fed back into the system continuously. Review comments, refactoring pull requests, and user-facing bugs are captured as documentation updates or encoded directly into tooling. When documentation falls short, we promote the rule into code
生成的代码并不总是符合人类的风格偏好,这没关系。只要输出结果正确、可维护,并且能让未来的智能体运行顺利理解,就达到了标准。
人类的审美偏好会持续反馈到系统中。审查意见、重构拉取请求以及用户遇到的错误会被记录为文档更新,或直接编码到工具中。当文档不足时,我们会将规则提升为代码。
Throughput changes the merge philosophy
吞吐量改变了合并理念
As Codex’s throughput increased, many conventional engineering norms became counterproductive.
The repository operates with minimal blocking merge gates. Pull requests are short-lived. Test flakes are often addressed with follow-up runs rather than blocking progress indefinitely. In a system where agent throughput far exceeds human attention, corrections are cheap, and waiting is expensive.
This would be irresponsible in a low-throughput environment. Here, it’s often the right tradeoff.
随着Codex吞吐量的提升,许多传统工程规范反而适得其反。
该代码库采用最低限度的合并拦截机制。拉取请求的生命周期极短。测试偶现问题通常通过后续运行来解决,而非无限期阻碍进度。在这个智能体吞吐量远超人类注意力的系统中,纠错成本低廉,而等待代价高昂。
这种模式在低吞吐环境中会显得不负责任。但在此处,往往是最合理的权衡取舍。
What “agent-generated” actually means
“agent-generated” 实际含义
When we say the codebase is generated by Codex agents, we mean everything in the codebase.
Agents produce:
- Product code and tests
- CI configuration and release tooling
- Internal developer tools
- Documentation and design history
- Evaluation harnesses
- Review comments and responses
- Scripts that manage the repository itself
- Production dashboard definition files
Humans always remain in the loop, but work at a different layer of abstraction than we used to. We prioritize work, translate user feedback into acceptance criteria, and validate outcomes. When the agent struggles, we treat it as a signal: identify what is missing—tools, guardrails, documentation—and feed it back into the repository, always by having Codex itself write the fix.
Agents use our standard development tools directly. They pull review feedback, respond inline, push updates, and often squash and merge their own pull requests.
当我们说代码库是由Codex智能体生成时,指的是代码库中的全部内容。
智能体负责产出:
- 产品代码与测试用例
- 持续集成配置与发布工具
- 内部开发者工具
- 文档及设计沿革
- 评估框架
- 评审意见与回复
- 仓库管理脚本
- 生产看板定义文件
人类始终参与其中,但工作抽象层级与以往不同。我们负责确定优先级、将用户反馈转化为验收标准、验证产出结果。当智能体遇到困难时,我们将其视为信号:识别缺失要素(工具、防护机制、文档等),并通过让Codex自行编写修复方案的方式反馈到代码库中。
智能体直接使用我们的标准开发工具。它们提取评审意见、进行行内回复、推送更新,并经常自行压缩合并拉取请求。
Increasing levels of autonomy
自主性不断提高
As more of the development loop was encoded directly into the system—testing, validation, review, feedback handling, and recovery—the repository recently crossed a meaningful threshold where Codex can end-to-end drive a new feature.
Given a single prompt, the agent can now:
- Validate the current state of the codebase
- Reproduce a reported bug
- Record a video demonstrating the failure
- Implement a fix
- Validate the fix by driving the application
- Record a second video demonstrating the resolution
- Open a pull request
- Respond to agent and human feedback
- Detect and remediate build failures
- Escalate to a human only when judgment is required
- Merge the change
This behavior depends heavily on the specific structure and tooling of this repository and should not be assumed to generalize without similar investment—at least, not yet.
随着开发环节的更多部分被直接编码进系统——测试、验证、评审、反馈处理和恢复——该代码库最近跨越了一个重要门槛,使得Codex能够端到端驱动新功能开发。
现在只需一个指令,智能体就能:
- 验证代码库当前状态
- 复现报告的缺陷
- 录制故障演示视频
- 实施修复方案
- 通过驱动应用程序验证修复
- 录制解决方案演示视频
- 发起拉取请求
- 响应智能体与人工反馈
- 检测并修复构建失败
- 仅在需要判断时转交人工处理
- 合并变更
这种行为高度依赖于该代码库的特定结构和工具链,在缺乏类似投入的情况下不应假定其具有普适性——至少目前如此。
Entropy and garbage collection
熵与垃圾回收
Full agent autonomy also introduces novel problems. Codex replicates patterns that already exist in the repository—even uneven or suboptimal ones. Over time, this inevitably leads to drift.
Initially, humans addressed this manually. Our team used to spend every Friday (20% of the week) cleaning up “AI slop.” Unsurprisingly, that didn’t scale.
Instead, we started encoding what we call “golden principles” directly into the repository and built a recurring cleanup process. These principles are opinionated, mechanical rules that keep the codebase legible and consistent for future agent runs. For example: (1) we prefer shared utility packages over hand-rolled helpers to keep invariants centralized, and (2) we don’t probe data “YOLO-style”—we validate boundaries or rely on typed SDKs so the agent can’t accidentally build on guessed shapes. On a regular cadence, we have a set of background Codex tasks that scan for deviations, update quality grades, and open targeted refactoring pull requests. Most of these can be reviewed in under a minute and automerged.
This functions like garbage collection. Technical debt is like a high-interest loan: it’s almost always better to pay it down continuously in small increments than to let it compound and tackle it in painful bursts. Human taste is captured once, then enforced continuously on every line of code. This also lets us catch and resolve bad patterns on a daily basis, rather than letting them spread in the code base for days or weeks.
完全自主的AI代理也带来了新问题。Codex会复制代码库中已存在的模式——包括那些不均衡或欠优化的模式。长此以往,这不可避免地导致代码质量滑坡。
最初人类通过人工方式解决这个问题。我们团队过去每周五(占20%工作时间)都在清理"AI生成的代码垃圾"。不出所料,这种方式难以持续。
于是我们开始在代码库中直接植入所谓的"黄金原则",并建立了定期清理机制。这些原则是带有倾向性的机械规则,能确保代码库对后续AI生成代码保持可读性和一致性。
例如:
(1) 我们优先使用共享工具包而非手工编写的辅助函数,以集中控制不变量;
(2) 禁止"YOLO式"数据探查——必须验证边界或依赖类型化SDK,防止AI基于猜测的数据结构生成代码。我们设置了一系列后台Codex任务,定期扫描偏差、更新质量评级,并创建精准的重构拉取请求。大多数请求可在1分钟内完成审核并自动合并。
这套机制如同垃圾回收系统。技术债务就像高息贷款:持续小额偿还总比任其利滚利后痛苦清偿更划算。人类制定的标准只需定义一次,就能持续贯彻到每行代码。这让我们能够每天发现并修正不良模式,而不是任由它们在代码库中扩散数日甚至数周。
What we’re still learning
This strategy has so far worked well up through internal launch and adoption at OpenAI. Building a real product for real users helped anchor our investments in reality and guide us towards long-term maintainability.
What we don’t yet know is how architectural coherence evolves over years in a fully agent-generated system. We’re still learning where human judgment adds the most leverage and how to encode that judgment so it compounds. We also don’t know how this system will evolve as models continue to become more capable over time.
What’s become clear: building software still demands discipline, but the discipline shows up more in the scaffolding rather than the code. The tooling, abstractions, and feedback loops that keep the codebase coherent are increasingly important.
Our most difficult challenges now center on designing environments, feedback loops, and control systems that help agents accomplish our goal: build and maintain complex, reliable software at scale.
As agents like Codex take on larger portions of the software lifecycle, these questions will matter even more. We hope that sharing some early lessons helps you reason about where to invest your effort so you can just build things.
这一策略迄今为止在OpenAI内部发布和采用过程中表现良好。为真实用户打造真实产品,帮助我们将投资锚定于现实,并指引我们走向长期可维护性。
我们尚未完全了解的是:在一个完全由智能体生成的系统中,架构一致性会如何随时间演变。我们仍在探索人类判断力在何处能发挥最大杠杆效应,以及如何编码这种判断力使其产生复合效应。我们也不清楚随着模型能力持续提升,这个系统将如何演化。
现在已明确的是:软件开发仍需纪律性,但这种纪律性更多体现在脚手架而非代码本身。保持代码库一致性的工具、抽象层和反馈循环正变得日益重要。
当前我们最严峻的挑战集中在设计环境、反馈循环和控制系统上,这些系统要能帮助智能体实现目标:规模化构建和维护复杂可靠的软件。
随着Codex等智能体承担软件生命周期中更大比重的工作,这些问题将愈发关键。我们希望通过分享早期经验,能帮助您思考该将精力投向何处,从而专注于真正重要的构建工作。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献83条内容
已为社区贡献83条内容

所有评论(0)