知识图谱(关系抽取方法)【第十一章】
一、注意力机制实现过程
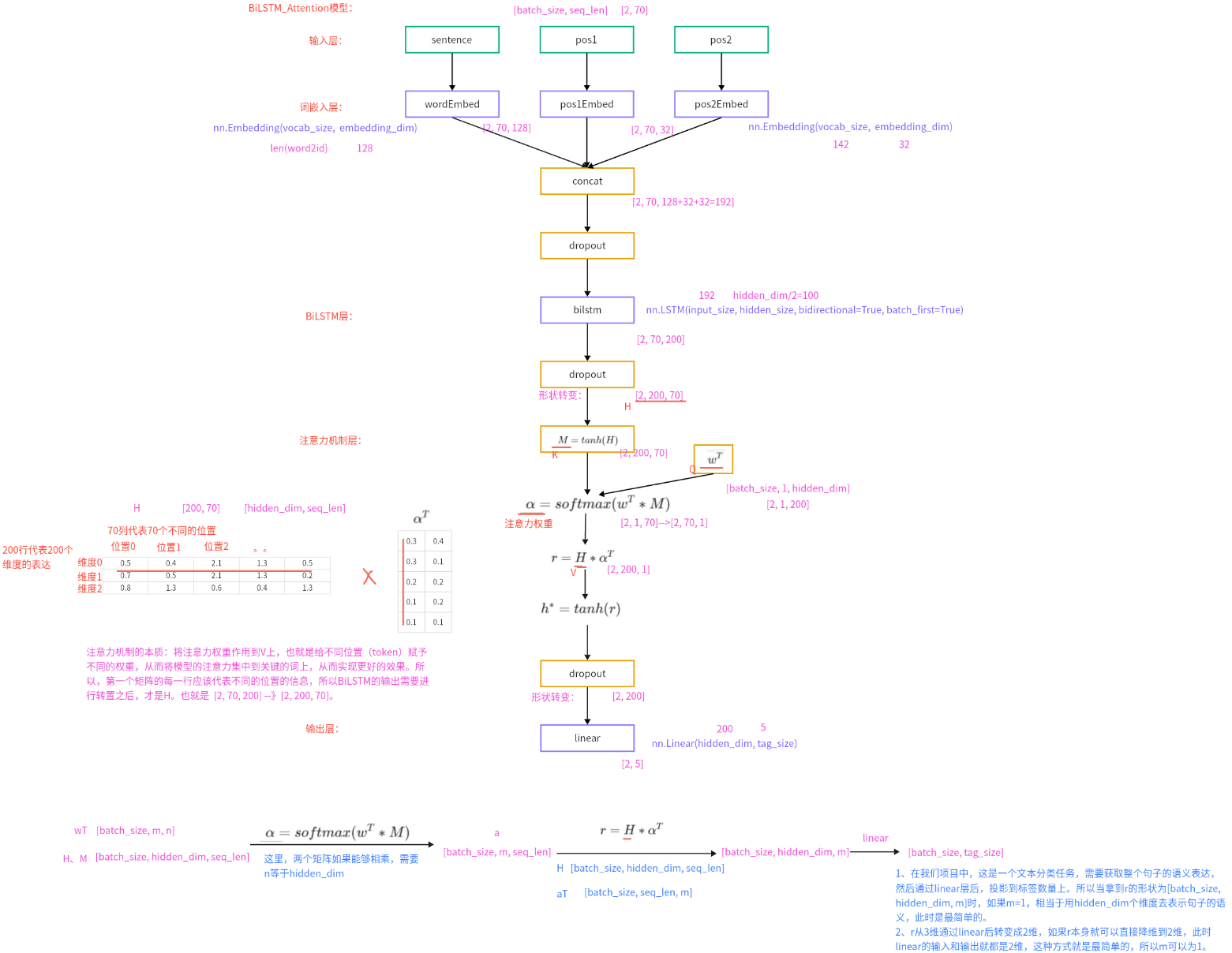
1.1 bilstm_atten.py
import torch
import torch.nn as nn
from P04_RE.Bilstm_Attention_RE.config import Config
from P04_RE.Bilstm_Attention_RE.utils.data_loader import word2id, get_data_loader
from P04_RE.Bilstm_Attention_RE.utils.process import relation2id
class BiLSTM_Attention(nn.Module):
def __init__(self, config, vocab_size, pos_size, tag_size):
'''
初始化
:param config: 配置文件对象
:param vocab_size: 字符词表大小
:param pos_size: 相对位置编码的数量
:param tag_size: 标签数量
'''
super(BiLSTM_Attention, self).__init__()
self.conf = config
self.vocab_size = vocab_size
self.pos_size = pos_size
self.tag_size = tag_size
# 定义词嵌入层
self.wordEmbed = nn.Embedding(self.vocab_size, self.conf.embedding_dim)
self.pos1Embed = nn.Embedding(self.pos_size, self.conf.pos_dim)
self.pos2Embed = nn.Embedding(self.pos_size, self.conf.pos_dim)
# 定义bilstm层
self.bilstm = nn.LSTM(input_size=self.conf.embedding_dim + self.conf.pos_dim * 2,
hidden_size=self.conf.hidden_dim // 2,
bidirectional=True,
batch_first=True)
# 定义全连接层
self.fc = nn.Linear(self.conf.hidden_dim, self.tag_size)
# 定义3个dropout层
self.dropout_embed = nn.Dropout(p=0.2)
self.dropout_lstm = nn.Dropout(p=0.2)
self.dropout_attention = nn.Dropout(p=0.2)
# 定义注意力参数,即wT,需要注意的是:不能将batch_size写死,因为一旦写死之后,后续在进行使用时,只能使用固定的batch_size
# 所以,这里将batch_size设置成1,然后在具体使用时,根据具体的batch_size进行动态广播
self.wT = nn.Parameter(torch.randn(1, 1, self.conf.hidden_dim)).to(self.conf.device)
def forward(self, sentence, pos1, pos2):
# 1)将sentence,pos1,pos2进行embedding处理,获取词嵌入向量后再将结果拼接到一起
embeds = torch.concat([self.wordEmbed(sentence), self.pos1Embed(pos1), self.pos2Embed(pos2)], dim=-1)
# print(f'embeds-->{embeds.shape}')
embeds = self.dropout_embed(embeds)
# 2)将拼接结果送入bilstm层进行训练
lstm_out, (h_n, c_n) = self.bilstm(embeds)
lstm_out = self.dropout_lstm(lstm_out)
# 3)将bilstm层输出结果进行转置,然后送到注意力机制层中
H = lstm_out.transpose(1, 2)
attention_out = self.attention(H)
attention_out = self.dropout_attention(attention_out)
# 4)将注意力机制的结果进行降维,然后送入全连接层
result = self.fc(attention_out.squeeze(-1))
return result
def attention(self, H):
'''
实现注意力机制
:param H: bilstm层输出结果,维度为[batch_size, hidden_dim, seq_len]
:return:
'''
# 1)经过tanh激活函数,得到M
M = torch.tanh(H)
# print(f'M-->{M.shape}')
# 2)将wT和M进行相乘,然后送入softmax中,得到注意力权重
alpha = torch.softmax(torch.matmul(self.wT, M), dim=-1) # 使用matmul进行矩阵乘法,此时wT会自动进行广播
# print(f'alpha-->{alpha.shape}')
# print(f'alpha-->{alpha}')
# 3)将 alpha 进行转置,然后再和H进行相乘
attention_out = torch.matmul(H, alpha.transpose(1, 2))
# print(f'attention_out-->{attention_out.shape}')
# 4)返回经过tanh激活函数后的结果
return torch.tanh(attention_out)
if __name__ == '__main__':
config = Config()
vocab_size = len(word2id)
pos_size = 142
tag_size = len(relation2id)
model = BiLSTM_Attention(config, vocab_size, pos_size, tag_size).to(config.device)
print(model)
train_dataloader, test_dataloader = get_data_loader()
for datas_tensor, labels_tensor, positionE1_tensor, positionE2_tensor, entities in train_dataloader:
result = model(datas_tensor, positionE1_tensor, positionE2_tensor)
print(f'result-->{result.shape}')
break1.2训练模型 train.py
训练函数基本步骤
1.构建数据迭代器Dataloader(包括数据处理与构建数据源Dataset)
2.实例化模型
3.实例化损失函数对象
4.实例化优化器对象
5.定义打印日志参数
6.开始训练
6.1 实现外层大循环epoch
6.2 将模型设置为训练模式
6.3 内部遍历数据迭代器dataloader
1)将数据送入模型得到输出结果
2)计算损失
3)梯度清零: optimizer.zero_grad()
4)反向传播(计算梯度): loss.backward()
5)梯度更新(参数更新): optimizer.step()
6)打印内部训练日志
6.4 使用验证集进行模型评估【将模型设置为评估模式】
6.5 保存模型: torch.save(model.state_dict(), "model_path")
6.6 打印外部训练日志验证函数基本步骤——
1.定义打印日志参数
2.将模型设置为评估模式
3.内部遍历数据迭代器dataloader
3.1 将数据送入模型得到输出结果
3.2 计算损失
3.3 处理结果
3.4 统计批次内指标
4.统计整体指标1.4
import time
import torch
import torch.nn as nn
from tqdm import tqdm
from P04_RE.Bilstm_Attention_RE.config import Config
from P04_RE.Bilstm_Attention_RE.model.bilstm_atten import BiLSTM_Attention
from P04_RE.Bilstm_Attention_RE.utils.data_loader import get_data_loader, word2id
from P04_RE.Bilstm_Attention_RE.utils.process import relation2id
def model2dev(test_dataloader, model, criterion):
# 1.定义打印日志参数
train_loss = 0 # 每个批次的损失之和
total_iter_num = 0 # 总的批次数
train_acc = 0 # 预测正确的样本数
total_sample = 0 # 总的样本数
# 2.将模型设置为评估模式
model.eval()
# 3.内部遍历数据迭代器dataloader
for index, (datas, labels, positionE1, positionE2, entities) in enumerate(tqdm(test_dataloader, desc='模型评估')):
# 3.1 将数据送入模型得到输出结果
output = model(datas, positionE1, positionE2)
# 3.2 计算损失
loss = criterion(output, labels)
# 3.3 处理结果
predict_labels = output.argmax(dim=-1)
# predict_labels = torch.argmax(output, dim=-1) # 另一种写法
# 3.4 统计批次内指标
train_loss += loss.item()
train_acc += sum(predict_labels == labels)
total_iter_num += 1
total_sample += labels.shape[0]
# 4.统计整体指标
dev_loss = train_loss / total_iter_num
dev_acc = train_acc / total_sample
return dev_loss, dev_acc
def model2train(conf, vocab_size, pos_size, tag_size):
# 1.构建数据迭代器Dataloader(包括数据处理与构建数据源Dataset)
train_dataloader, test_dataloader = get_data_loader()
# 2.实例化模型
model = BiLSTM_Attention(conf, vocab_size, pos_size, tag_size).to(conf.device)
print(f'model-->{model}')
# 3.实例化损失函数对象
criterion = nn.CrossEntropyLoss()
# 4.实例化优化器对象
optimizer = torch.optim.Adam(model.parameters(), lr=conf.learning_rate)
# 5.定义打印日志参数
start_time = time.time()
train_loss = 0 # 每个批次的损失之和
total_iter_num = 0 # 总的批次数
train_acc = 0 # 预测正确的样本数
total_sample = 0 # 总的样本数
best_acc = 0 # 最佳准确率
# 6.开始训练
# 6.1 实现外层大循环epoch
for epoch in range(conf.epochs):
# 6.2 将模型设置为训练模式
model.train()
# 6.3 内部遍历数据迭代器dataloader
for index, (datas, labels, positionE1, positionE2, entities) in enumerate(tqdm(train_dataloader, desc='模型训练')):
# 1)将数据送入模型得到输出结果
output = model(datas, positionE1, positionE2)
# print(f'output-->{output.shape}')
# 2)计算损失
loss = criterion(output, labels)
# print(f'loss-->{loss.item()}')
# 3)梯度清零: optimizer.zero_grad()
optimizer.zero_grad()
# 4)反向传播(计算梯度): loss.backward()
loss.backward()
# 梯度裁剪
torch.nn.utils.clip_grad_norm_(parameters=model.parameters(), max_norm=10)
# 5)梯度更新(参数更新): optimizer.step()
optimizer.step()
# 6)打印内部训练日志
train_loss += loss.item()
# 计算预测正确的样本数
predict_labels = output.argmax(dim=-1)
# print(f'predict_labels-->{predict_labels}')
# print(f'labels-->{labels}')
# print(f'predict_labels==labels-->{predict_labels == labels}')
# print(f'sum(predict_labels==labels)-->{sum(predict_labels == labels)}')
train_acc += sum(predict_labels == labels)
total_iter_num += 1
total_sample += labels.shape[0]
# 每隔50次,打印日志
if (index + 1) % 50 == 0:
loss_avg = train_loss / total_iter_num
acc_avg = train_acc / total_sample
end_time = time.time()
print(f'轮次:{epoch + 1},,训练损失:{loss_avg:.4f},训练准确率:{acc_avg:.4f},用时:{end_time - start_time:.2f}秒')
# break
# break
# 6.4 使用验证集进行模型评估【将模型设置为评估模式】
dev_loss, dev_acc = model2dev(test_dataloader, model, criterion)
# print(f'dev_loss-->{dev_loss:.4f}')
# print(f'dev_acc-->{dev_acc:.4f}')
# 6.5 保存模型: torch.save(model.state_dict(), "model_path")
if dev_acc > best_acc:
best_acc = dev_acc
torch.save(model.state_dict(), "save_model/bilstm_atten_best.pth")
print(f'保存模型,准确率:{best_acc:.4f}, 平均损失:{dev_loss:.4f}')
# break
# 6.6 打印外部训练日志
end_time = time.time()
print(f'训练时间:{end_time - start_time:.2f}')
if __name__ == '__main__':
conf = Config()
vocab_size = len(word2id)
pos_size = 142
tag_size = len(relation2id)
model2train(conf, vocab_size, pos_size, tag_size)1.3模型预测 predict.py
import torch
from P04_RE.Bilstm_Attention_RE.config import Config
from P04_RE.Bilstm_Attention_RE.model.bilstm_atten import BiLSTM_Attention
from P04_RE.Bilstm_Attention_RE.utils.data_loader import word2id
from P04_RE.Bilstm_Attention_RE.utils.process import relation2id, sentence_padding, position_padding
id2relation = {v: k for k, v in relation2id.items()}
# 1.实例化模型
config = Config()
vocab_size = len(word2id)
pos_size = 142
tag_size = len(relation2id)
model = BiLSTM_Attention(config, vocab_size, pos_size, tag_size).to(config.device)
print(f'model-->{model}')
# 2.加载模型参数
model.load_state_dict(torch.load('save_model/bilstm_atten_best.pth', weights_only=True))
def model2predict(sample, entity1, entity2):
'''
:param sample: 样本(要预测的句子)
:param entity1: 主实体
:param entity2: 客实体
:return:
'''
# 3.处理数据
# 3.1 通过遍历,获取中间数据
# 获取主实体的索引
e1_index = sample.index(entity1)
# 获取客实体的索引
e2_index = sample.index(entity2)
# 定义3个空列表,分别存储每个文本中的字符、主实体的相对位置编码和客实体的相对位置编码。
sentence, position1, position2 = [], [], []
for index, word in enumerate(sample):
# ①遍历原始文本,将每个字符存储到一个子列表中,遍历完成后再存到datas列表中。
sentence.append(word)
# ②先获取主实体的索引,在遍历过程中使用原始索引-主实体的索引,获取相对于主实体的位置编码,存储到一个子列表中,遍历完成后再存到positionE1列表中。
position1.append(index - e1_index)
# ③使用相同的方式,获取客实体的相对位置编码。
position2.append(index - e2_index)
# print(f'sentence-->{sentence}')
# print(f'position1-->{position1}')
# print(f'position2-->{position2}')
# 3.2 将字符转成id,且将负数转成正数,同时对齐长度
sentence_id = sentence_padding(sentence, word2id)
position1_ids = position_padding(position1)
position2_ids = position_padding(position2)
# print(f'sentence_id-->{sentence_id}')
# print(f'position1_ids-->{position1_ids}')
# print(f'position2_ids-->{position2_ids}')
# 3.3 将数据转成张量,并且将数据移动到GPU上
datas_tensor = torch.tensor([sentence_id], dtype=torch.long).to(config.device) # 需要给数据添加一个batch_size维度
positionE1_tensor = torch.tensor([position1_ids], dtype=torch.long).to(config.device)
positionE2_tensor = torch.tensor([position2_ids], dtype=torch.long).to(config.device)
# print(f'datas_tensor-->{datas_tensor.shape}')
# print(f'positionE1_tensor-->{positionE1_tensor.shape}')
# print(f'positionE2_tensor-->{positionE2_tensor.shape}')
# 4.模型预测
model.eval()
with torch.no_grad():
output = model(datas_tensor, positionE1_tensor, positionE2_tensor)
# print(f'output-->{output}')
# 5.结果解析
predict_label = torch.argmax(output, dim=-1)[0].item()
# print(f'predict_label-->{predict_label}')
# 将标签类型id转成标签类型
final_label = id2relation[predict_label]
print(f'输入的句子为:{sample}')
print(f'主实体为:{entity1}')
print(f'客实体为:{entity2}')
print(f'预测结果为:{final_label}')
if __name__ == '__main__':
sample = '《爱人们的故事》是全基尚导演,裴勇俊、李英爱、李慧英等主演的18集爱情类型的电视剧'
entity1 = '爱人们的故事'
entity2 = '全基尚'
model2predict(sample, entity1, entity2)
print('----------------------------------------------------------------------------------------')
entity2 = '裴勇俊'
model2predict(sample, entity1, entity2)二、BiLSTM+Attention模型优化项
1)模型优化
-
句子嵌入方式:可以使用jieba分词得到词语,然后再使用词语的方式进行嵌入。
-
替换BiLSTM:将BiLSTM替换成BERT/RoBERTa等这种预训练模型 或 BiGRU去 做语义编码,看是否可以提供模型的语义表达能力。
-
多头注意力机制:借鉴Transformer中多头注意力机制,将单一注意力拆分到多个子空间,去捕捉不同维度的语义信息。
-
修改注意力机制的方式:使用transformer中注意力机制的计算方式 或者先进行从concat再经过linear层的方式等,来计算注意力机制,看模型的性能效果。
-
调整随机失活层:调整随机失活层的位置、有无或随机失活比例,来观察模型的性能变化。
2)训练过程的优化
-
shuffle设置:注意在真正训练时,需要将dataloader中的shuffle设置为True
-
梯度裁剪:在反向传播时对梯度进行裁剪,防止梯度消失或爆炸。
-
早停机制:监控验证集上F1值或其他关键指标,如果连续多个epoch未提升或者开始下降,则提前终止训练。
3)训练数据优化
-
通过过采样或欠采样来解决样本不均衡问题
-
通过同义词替换、回译、实体替换等方法来扩充数据集。或者直接使用大模型进行训练样本的生成。
三、Pipeline方法的优缺点
Pipline方法的主要特点是实体抽取和关系抽取是分开的
-
优点:
-
易于实现,实体模型和关系模型使用独立的数据集,不需要同时标注实体和关系的数据集.
-
两者相互独立,若关系抽取模型没训练好不会影响到实体抽取.(这也会导致实体抽取会影响到关系抽取)
-
可以解决sep问题(一句话里面只有一对实体,只有一个关系。可以提取实体关系)
-

-
缺点:
-
关系和实体两者是紧密相连的,互相之间的联系没有捕捉到.
-
上游 NER 的错误会直接影响下游关系抽取,容易造成误差积累(实体抽取和关系抽取本来是有关联的,分开实现会导致误差累积).
-
BiLSTM+Attention难以处理EPO问题(多对实体共享一个实体,关系交叉。无法提取实体关系)
鲁迅 出生于 绍兴, 鲁迅 代表作是 《朝花夕拾》
实体对 1:(鲁迅,绍兴)
实体对 2:(鲁迅,朝花夕拾)👉 共享头实体「鲁迅」,这就是 EPO 重叠问题
-
四、Joint方法实现关系抽取
4.1 概念
通过修改标注方法和模型结构直接输出文本中包含的(ei,rk,ej)三元组
4.2 类型
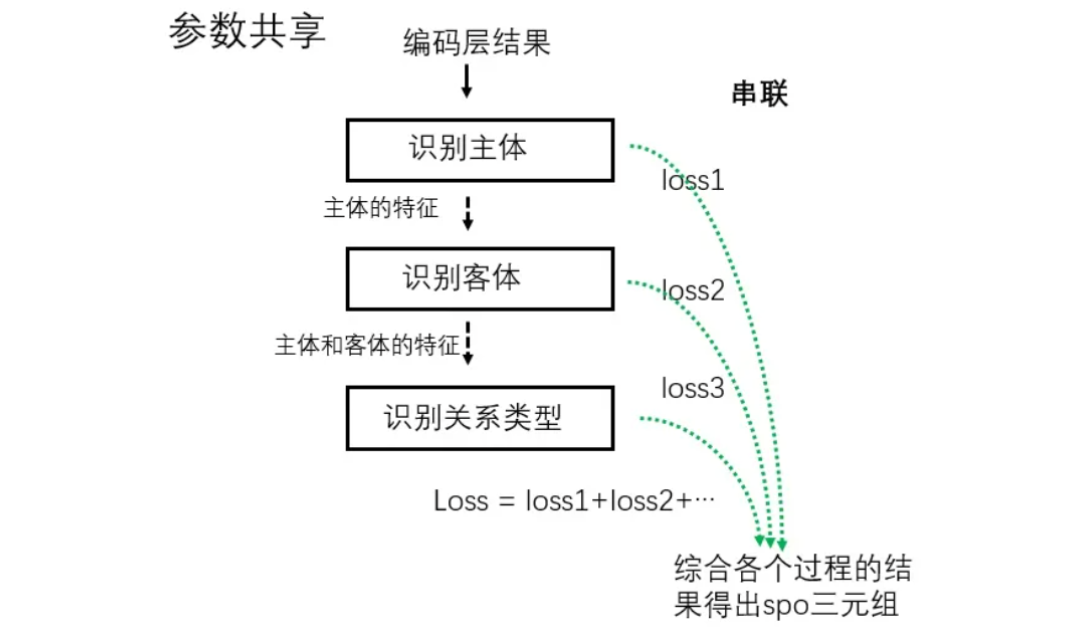
4.2.1 参数共享的联合模型【修改模型结构】
主体、客体和关系的抽取不是严格同步进行的 (通常是依次执行,但是某些情况下也可以其中两个任务一起进行) ,各个过程都可以得到一个loss值,==整个模型的loss是各过程loss值之和.
4.2.2 联合解码的联合模型【修改标注方法】
主体、客体和关系的抽取是同时进行的,通过一个模型直接得到SPO三元组.
BIOS里面的S指的是signle,表示如果实体是一个字,那么标记为s;
标签类型总数:2*3*N+1:
2指的是主实体+客实体
3指的是B、I、S
N指的是有N种关系1指的是非实体
例如 我是中国人
有一种标签类型是:
主实体会被标注为1
客实体会被标注为2
我-1s
中-2B
国-2I
人-2I
两个实体直接如果有a关系那么会被标注为:
a-1-S O a-2-B a-2-I a-2-I

五、Casrel模型架构
- Casrel是2020 ACL 上的实体关系抽取的一篇论文,该论文的主要解决的问题为关系三元组重叠(EPO)问题;
- CasRel 本质上是基于参数共享的联合实体关系抽取方法(顺序识别实体和关系)。
casrel实现流程:
BERT编码 → 线性+Sigmoid预测边界(预测每个token是不是实体的开始、结束位置) → 最近匹配生成候选实体
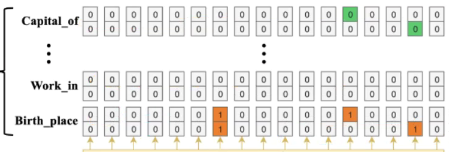
输入隐藏层输出+subject的特征向量→ 使用预定义的关系匹配是否有合适的客实体→解决epo问题
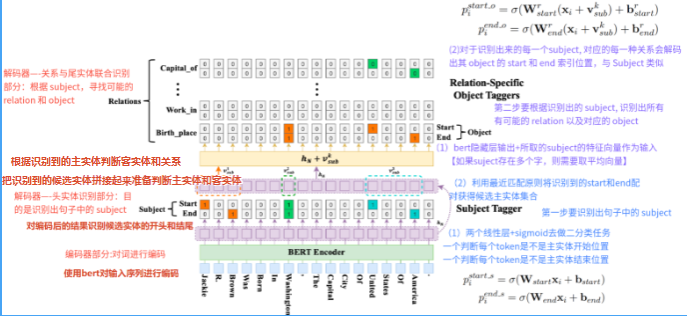
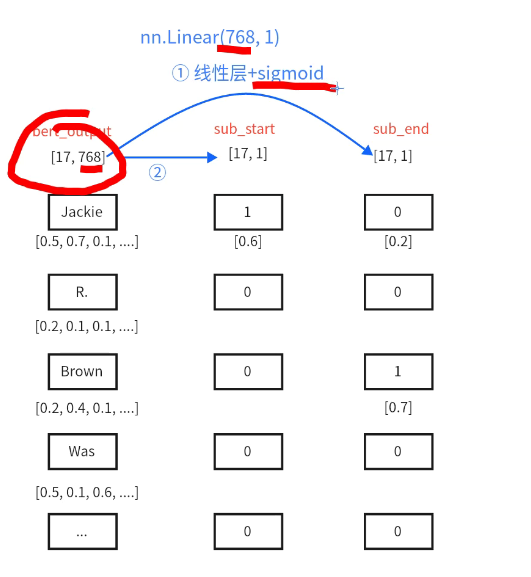
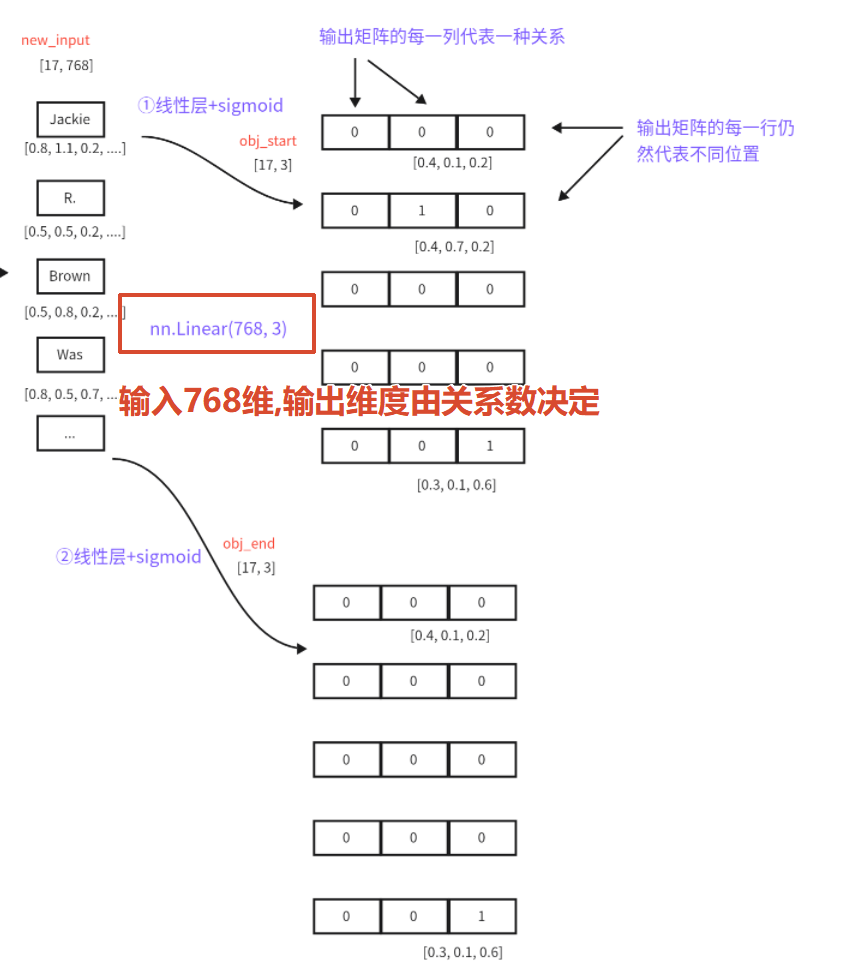
两个线性层+两个sigmoid判断候选实体的开始结束索引:

线性层只作用在向量化的最后一个维度上面,得到一个数值以后在使用sigmoid函数判断是否是开头和结尾;
主实体的开始索引放在一起,结束索引放在一起,然后使用就近匹配原则进行匹配:

bert编码的结果+实体的平均向量作为模型的输入:

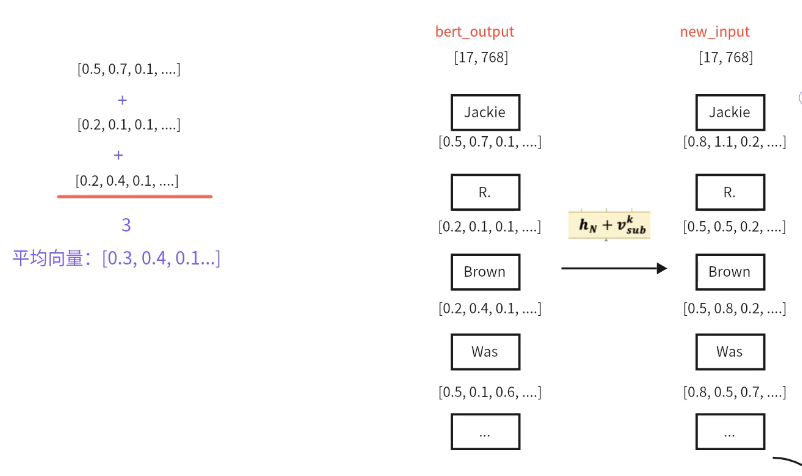
然后使用线性层+sigmoid函数预测关系和客实体:和预测主实体不同,这里输出的结果是每种关系的客实体开始位置和结束位置;

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)