苹果新论文炸场!大模型回答“有”或“没有”时,你的隐私早已被它悄悄出卖
设想一下,你给AI看了一张杂乱办公桌的照片,并问它:“图里有一个红色的杯子吗?”AI干脆地回答:“有。” 听起来非常完美和高效,对吧?
但这篇推文将为你揭示一个令人细思极恐的现象:在AI吐出“有”这个词的概率分布(Logits)里,竟然偷偷藏着旁边笔记本的颜色、笔的大小,甚至照片的噪点信息!今天,我们将为你深度解读来自苹果(Apple)研究团队的最新力作。这篇文章证明了,即使是我们以为最“干净”的最终输出概率,也可能成为隐私泄露的后门。准备好颠覆你对大模型的认知了吗?
为了给方便大家更好的复现,我给大家准备了完整版的技术资料、代码和复现路径,如有需要点击链接!
📄 论文信息

- 论文标题: What do your logits know? (The answer may surprise you!)
- 论文链接: https://arxiv.org/abs/2604.09885
一、 大模型的“信息漏斗”失效了吗?
在理想状态下,当我们做决定或回答问题时,大脑会过滤掉无关信息。在深度学习中,这被称为信息瓶颈理论(Information Bottleneck, IB):优秀的模型在训练时会像漏斗一样,逐层压缩信息。
但是,Transformer模型中的“残差连接”就像是在漏斗旁边开了一条条直达通道。为了搞清楚大模型到底保留了多少“废话”,研究团队给模型看一张图片,然后问一个极简的选择题:“图片里有<某物体>吗?请用一个词回答。”
二、 探秘大模型的三层“记忆”
为了顺藤摸瓜,研究人员检查了模型推理过程中的三个不同“表征层级”:
- 残差流(Residual Stream): 大模型的“全知视角”。
- Logit轨迹(Tuned Lens Trajectories): 模型得出结论前的“思考演练”。
- 最终Logits(Final Top-k Logits): 模型输出时附带的概率分数(如 OpenAI API 提供的 logprobs)。

三、 不可思议的七大发现(全补全版)
通过训练专门的探测器(Probes),研究团队揭开了 Logits 的七个秘密:
-
发现 1:残差流是“全知全能”的。 隐藏状态保留了图片里近乎所有的细节(如背景方块数量、噪声强度),无论这些细节对回答问题是否有用。
-
发现 2 & 3:Logits 编码了决策关键的“非任务”信息。

即便你只问图片里有没有物体,模型在最终 Logits 里依然记住了这些噪声的强度和类型。
- 发现 4:泄露了“未被提及”的目标特征。
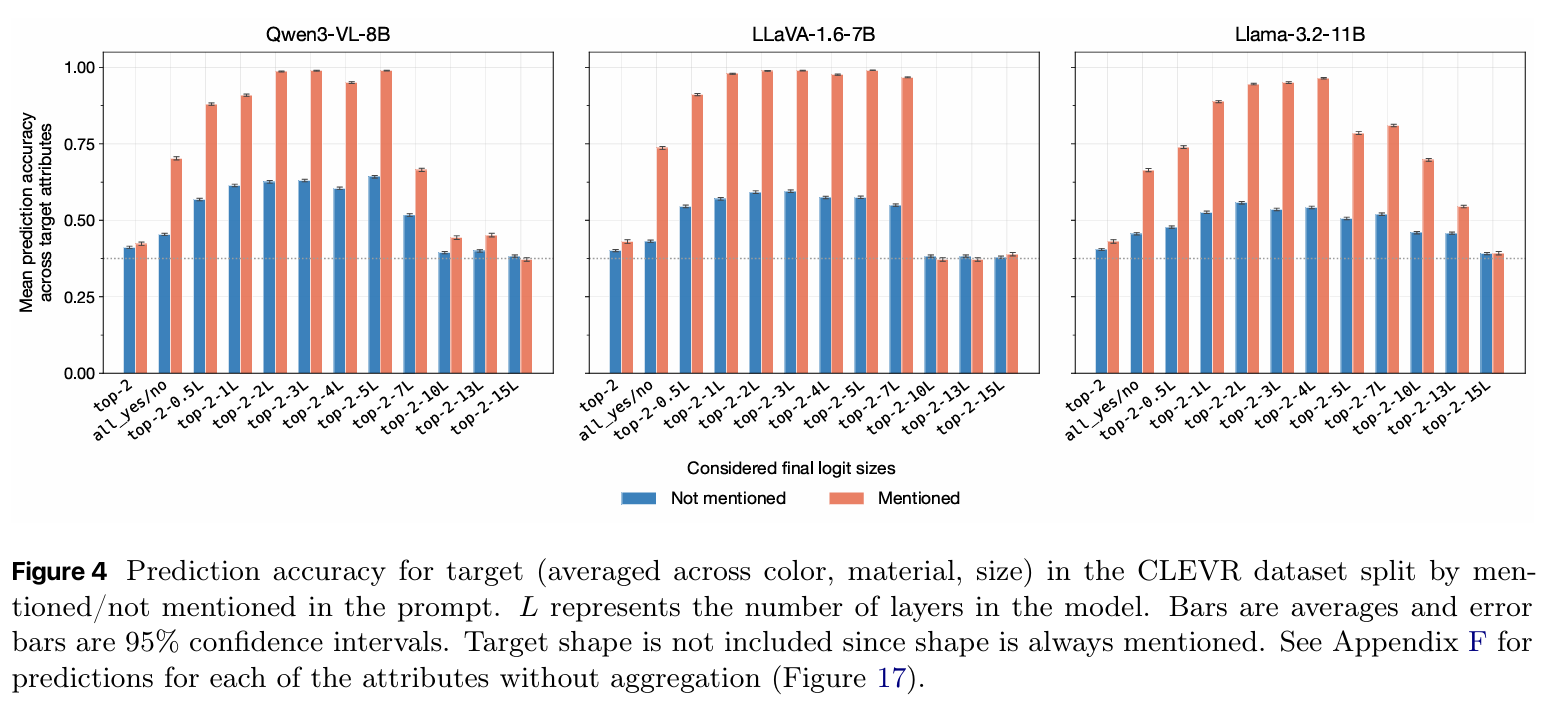
如果你问:“图里有圆柱体吗?”模型不仅在 Logits 里回答“有”,还顺带泄露了该物体的颜色、材质和大小
-
发现 5:背景属性也会跟着“偷渡”。 即使是背景中完全不相关的物体(如背景里的方块颜色),只要你观察的 Logits 数量(k值)足够大,攻击者就能从概率分布中还原出这些背景细节。
-
发现 6:“Top-60”是个甜蜜点(U型曲线)。
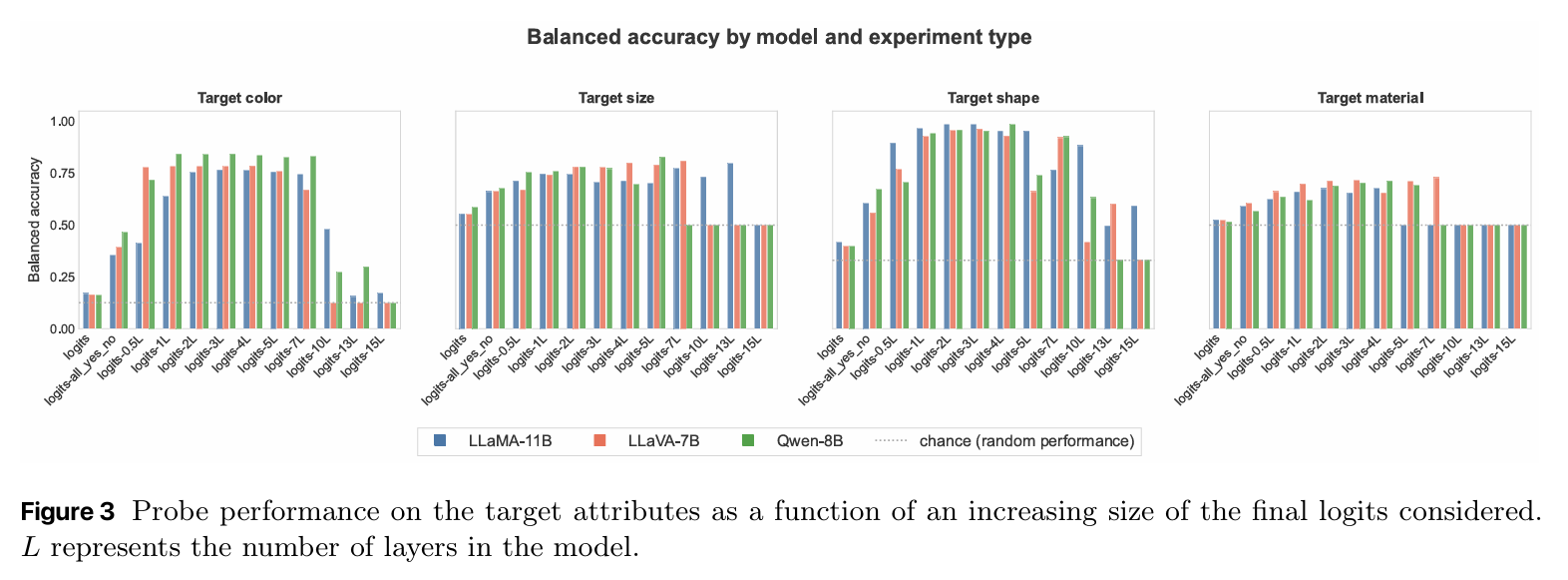
获取排名靠前的 30 到 80 个 Logits(大约等同于模型层数)时,泄露的信息最精准。看太多(如 Top-1000)反而会因为随机噪声干扰而让准确率下降。
- 发现 7:表层 Logits 的泄露程度媲美深层 internals。 这是一个最让人吃惊的结论:在控制维度相同的情况下,Top-2L 的最终层 Logits 所包含的秘密信息量,竟然和直接窥视模型内部深层的“Logit 轨迹”几乎一样多!
四、 细思极恐的安全隐患
你可能会问:这跟我有什么关系?
获取模型内部状态需要**“白盒”权限**。然而,获取 Top-k Logits 只需要**“灰盒”权限**——通过各大 AI 厂商开放的商业 API(支付几分钱调用费)就能拿到。
真实漏洞: 恶意攻击者可以上传一张包含你隐私的照片,表面问一个安全问题(“图里有杯子吗?”),然后收集返回的 Logits 分数,利用解码工具还原出你背景里的一张账单、机密文件甚至是人脸特征。
结语
我们常常以为,只要 AI 的回答是简单明了的“是”或“否”,它就没有过度思考。但苹果的这篇论文无情地打破了这种错觉:你的 Logits 知道得太多了。
在追求更聪明、更多模态的 AI 之路上,如何真正让模型学会“该忘掉的就忘掉”,或许是下一个亟待解决的超级难题。
为了给方便大家更好的复现,我给大家准备了完整版的技术资料、代码和复现路径,如有需要点击链接!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)