arxiv-paper-writer skill:用 Claude Code 写出 arXiv 风格论文
- GitHub:https://github.com/16Miku/arxiv-paper-writer-skill
- ClawHub:https://clawhub.ai/16miku/arxiv-paper-writer
如果你曾经尝试过让 AI 直接“一次性写完一篇论文”,大概率会遇到这些问题:结构看起来像论文,但细节经不起推敲;引用容易编造;LaTeX 能不能编译全靠运气;图表和表格往往只是摆设,缺乏真正支撑论点的作用。
arxiv-paper-writer 这个 skill 的价值,恰恰就在于它不把论文写作当成一次性生成任务,而是把它当成一个可验证、可迭代、可调试的工程流程。
它面向的不是“随便生成一段学术风格文字”,而是更完整的 arXiv 风格论文工作流:从选题规划、LaTeX 项目初始化、BibTeX 文献库构建,到章节增量写作、TikZ 图表和 LaTeX 表格生成,再到编译调试和最终质量审查,整个过程都是分阶段推进的。
一、这个 skill 解决的是什么问题?
很多人写论文时,真正困难的不是“写一段话”,而是下面这些更具体的问题:
- 怎么把一个研究主题快速初始化成可编译的 LaTeX 项目?
- 怎样先搭一个能跑通的论文骨架,而不是一上来就堆满正文?
- BibTeX 文献库怎么组织,才能避免键名混乱和引用失真?
- 如何让 AI 在写作时坚持“只使用真实可核验文献”,而不是编造 citation?
- 图、表、正文、引用、编译、调试,如何形成闭环,而不是各写各的?
- 当
undefined citation、缺少宏包、Bbbk冲突之类问题出现时,怎么快速定位并修复?
arxiv-paper-writer 的设计目标,就是把这些问题整合成一个标准化工作流,让 Claude Code 在写论文时像做工程一样,按阶段推进、按日志修复、按产物验收。
二、核心理念:论文写作不是一锤子买卖,而是工程闭环
这个 skill 最核心的一句话是:
Treat paper writing as an engineering loop, not a one-shot generation task.
也就是说,它强调的不是“一口气写完”,而是下面这个闭环:
plan → scaffold → bibliography → section writing → figures/tables → compile → debug → review
这个流程特别适合以下几类任务:
- 写 arXiv 风格英文综述论文
- 初始化一个新的 LaTeX 论文项目
- 给已有论文补 BibTeX、补图表、补章节结构
- 修复编译错误、引用错误、宏包冲突
- 审查一篇论文距离“可投稿 / 可公开展示”的差距
对于实际使用者来说,这种思路比“直接让 AI 给我写完一篇 paper”可靠得多,因为每一步都有明确产物,也更容易发现问题、及时回滚。
三、这个 skill 的完整工作流
架构图
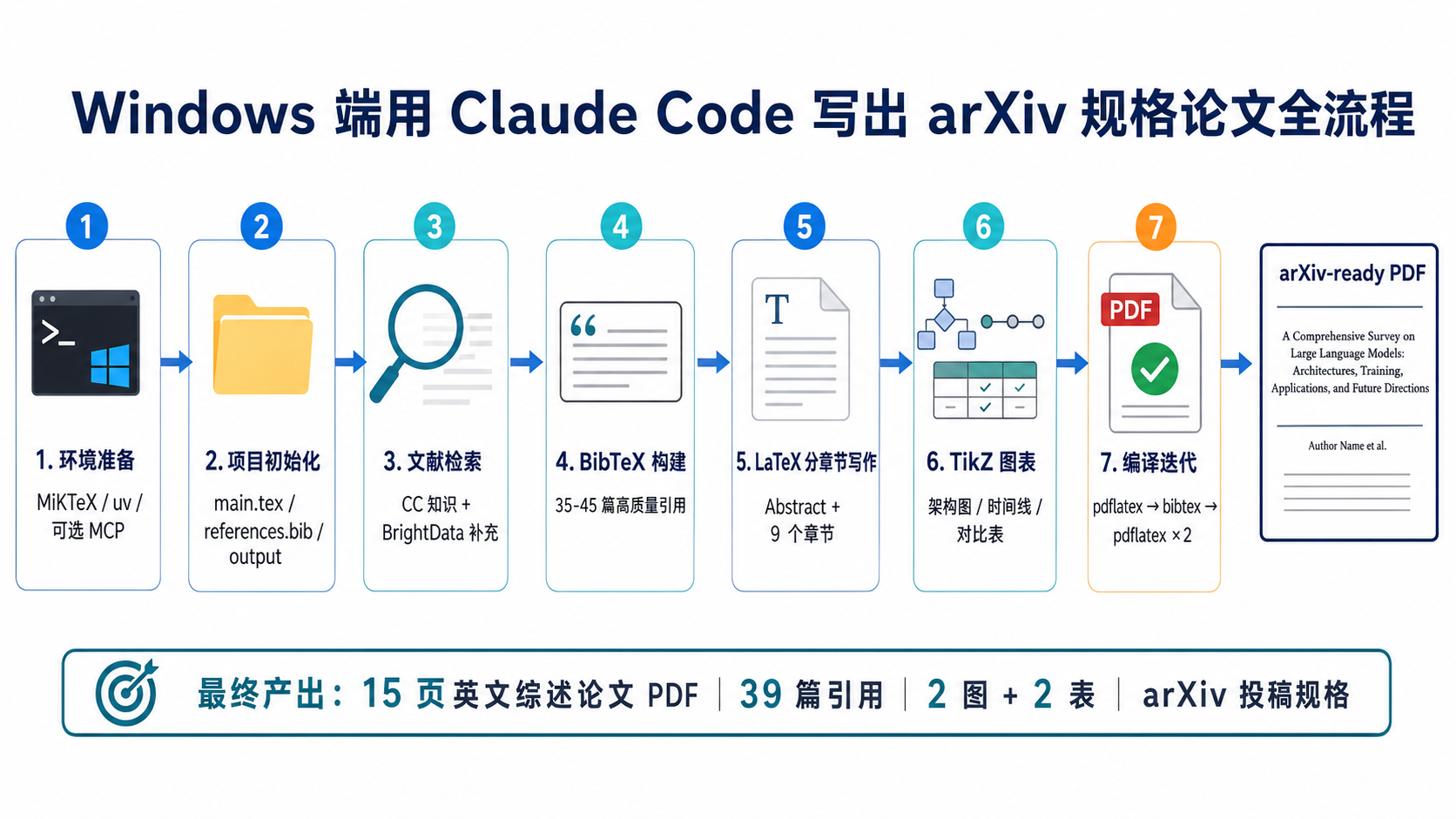
1)Plan:先明确论文方案,而不是先写正文
在真正动手写之前,这个 skill 要求先明确:
- 论文主题和范围
- 论文类型:survey、methods paper、benchmark、position paper、tutorial 等
- 目标长度
- 受众是谁
- 预期贡献点是什么
- 计划做哪些图和表
- 准备用哪些验证命令检查编译与引用
这一点非常重要。很多 AI 写作失败,不是因为模型不会写,而是因为没有先把论文边界定义清楚。这个 skill 把“写前规划”变成了显式步骤。
2)Scaffold:先搭可编译骨架
它建议先创建一个标准论文目录,例如:
paper-project/
├── main.tex
├── references.bib
├── figures/
├── sections/
└── output/然后先保证 LaTeX 骨架能编译出 PDF,再逐步填充正文。这个思路很像软件工程里的“先把项目跑起来,再迭代功能”。
对 survey 场景,它还区分了两种模板思路:
- 一个是紧凑型 starter survey 模板
- 一个是更完整的 9 章节 survey scaffold
如果用户想复现已经验证过的 AI 论文写作路径,它还会引导去参考 Agent Survey 的实践材料。
3)Build bibliography:先建文献库,再重写正文
这是我觉得它最有价值的部分之一。
很多人用 AI 写论文时最怕的就是“引用看起来很多,实际上是假的”。而这个 skill 把 BibTeX 当成前置资产来建设,明确提出:
- 优先使用真实、可核验文献
- 使用稳定的 BibTeX key,例如
authorYYYYshorttitle - 不确定的 DOI、venue、页码不要编造
- 先建立 15–25 篇核心文献(短文)或 35–60 篇文献(综述)
换句话说,它不鼓励“边写边瞎 cite”,而是鼓励先把参考文献池建好,再驱动正文写作。这一点对论文可信度提升非常大。
4)Write sections incrementally:按章节增量写作
这个 skill 不建议一次生成整篇,而是建议:
- 一次只写 1–2 节
- 每写完一个较大部分,就检查引用和 LaTeX 语法
- 抽象、引言、背景、主体、挑战与未来方向、结论按阶段推进
- 摘要放到最后写
这实际上很符合高质量论文的生产方式:摘要必须等正文稳定以后再写,否则很容易“摘要写得像另一篇论文”。
5)Create figures and tables:图表不是装饰,而是论证工具
这个 skill 明确偏好:
- TikZ 图
- LaTeX 原生表格
- booktabs 风格表格
也就是说,它强调图表的可复现性。如果是概念图、架构图、时间线、taxonomy 表、框架对比表,最好直接用 LaTeX/TikZ 写出来,而不是贴一张外部截图了事。
在它的经验总结里,一篇高质量 survey 通常可以包含这些高价值图表:
- 时间线图
- 架构图
- taxonomy / framework comparison table
- benchmark 或 limitation matrix
这些图表不是为了让版面更好看,而是为了提升论文的“综合性表达能力”。
6)Compile and debug:不要猜,先读 log
如果你写过 LaTeX,就会知道真正折磨人的往往不是写,而是编译报错。
这个 skill 对这一点很务实,明确要求:
- Linux 上优先用
latexmk - Windows MiKTeX 环境下使用
pdflatex -> bibtex -> pdflatex -> pdflatex - 遇到报错,先读
.log文件,不要靠猜
它甚至把一些常见问题直接纳入了经验库,比如:
- 缺少
.sty宏包怎么办 newtxmath和amssymb导致的\Bbbk冲突怎么修undefined citation应该先查 BibTeX key 还是编译轮次
这种设计特别像一个“论文工程调试手册”,而不是普通写作提示词。
7)Final review:把论文当成可交付成果审查
最后一阶段不是“看起来差不多就算了”,而是做系统审查,包括:
- PDF 是否成功生成
- 参考文献是否正常显示
- 是否还有 undefined citation / reference
- 图表是否渲染成功
- 结构叙事是否连贯
- 贡献是否明确
- 局限和 future work 是否写清楚
- 是否符合 arXiv 源码提交习惯
对于真正想把 AI 用进论文生产流程的人来说,这一步非常关键。因为“能生成一篇文档”和“能交付一篇可复现论文”完全是两回事。
四、为什么它特别适合写综述论文?
从 skill 的内容来看,它明显对 survey paper 做了额外优化。
原因很简单:综述类论文的难点从来都不只是“写学术语气”,而是:
- 范围怎么划
- 文献怎么分簇
- 结构怎么搭
- 图表怎么做综合表达
- 不同方法的对比维度怎么抽象
arxiv-paper-writer 在这些地方都有明确指导。它建议把文献按主题分成多个 cluster,例如基础工作、代表性系统、benchmark、限制与安全问题等;它还给出了一个已经验证过的 9 章节 survey 结构,可以直接迁移到新项目里。
这意味着它不是一个“泛泛而谈的写论文 prompt 包”,而是真正沉淀过 survey 实战经验的写作 skill。
五、它已经复用了一个成功案例的经验
这个 skill 的来源并不是凭空设计,而是从一个成功完成的 Agent Survey 项目里抽取出来的。
那个实践案例大致包括:
- 15 页英文 PDF
- 39 条真实 BibTeX 参考文献
- 2 张 TikZ 图
- 2 张 LaTeX 表格
- 完整的 survey 章节结构
- Claude Code + LaTeX + BibTeX + TikZ 的完整闭环
也就是说,这个 skill 不是“理论上可行”,而是已经有过从零到成稿的落地经验。这一点会让它比很多临时拼出来的 prompt 更靠谱。
六、适合哪些用户?
如果你属于下面这些人,这个 skill 会非常有用:
1. 想用 Claude Code 写论文初稿的人
尤其是希望生成一个真正可编译、可继续维护的 LaTeX 工程,而不是只要一份纯文本草稿。
2. 正在写 survey / tutorial / benchmark paper 的研究者
这类论文最需要结构化写作、文献管理和图表综合表达,正好是这个 skill 的强项。
3. 经常被 LaTeX / BibTeX 编译问题卡住的人
如果你每次都在 undefined citation、缺宏包、冲突修复上浪费大量时间,这个 skill 的 compile-debug 思路会很实用。
4. 想把 AI 纳入正式论文工作流的人
如果你的目标不是“试试玩 AI 写论文”,而是想把 AI 变成生产工具,那么这种工程化闭环比单次生成强太多了。
七、它和普通“AI 写论文”方案最大的区别
一句话总结:
普通方案是在生成文本,arxiv-paper-writer 在生成一个可维护的论文工程。
两者的区别体现在很多细节上:
- 普通方案关心“写得像不像论文”
- 它关心“是不是能编译、能引用、能复现、能审查”
- 普通方案容易一口气生成很多不可靠内容
- 它强调逐阶段验证和小步迭代
- 普通方案把图表当附属品
- 它把图表当作论证结构的一部分
- 普通方案在编译报错时容易瞎修
- 它要求先读 log,再做定点修复
这也是为什么我觉得它更像一个“研究写作流水线 skill”,而不只是一个论文 prompt 模板。
八、使用Linux端的OpenClaw进行使用演示
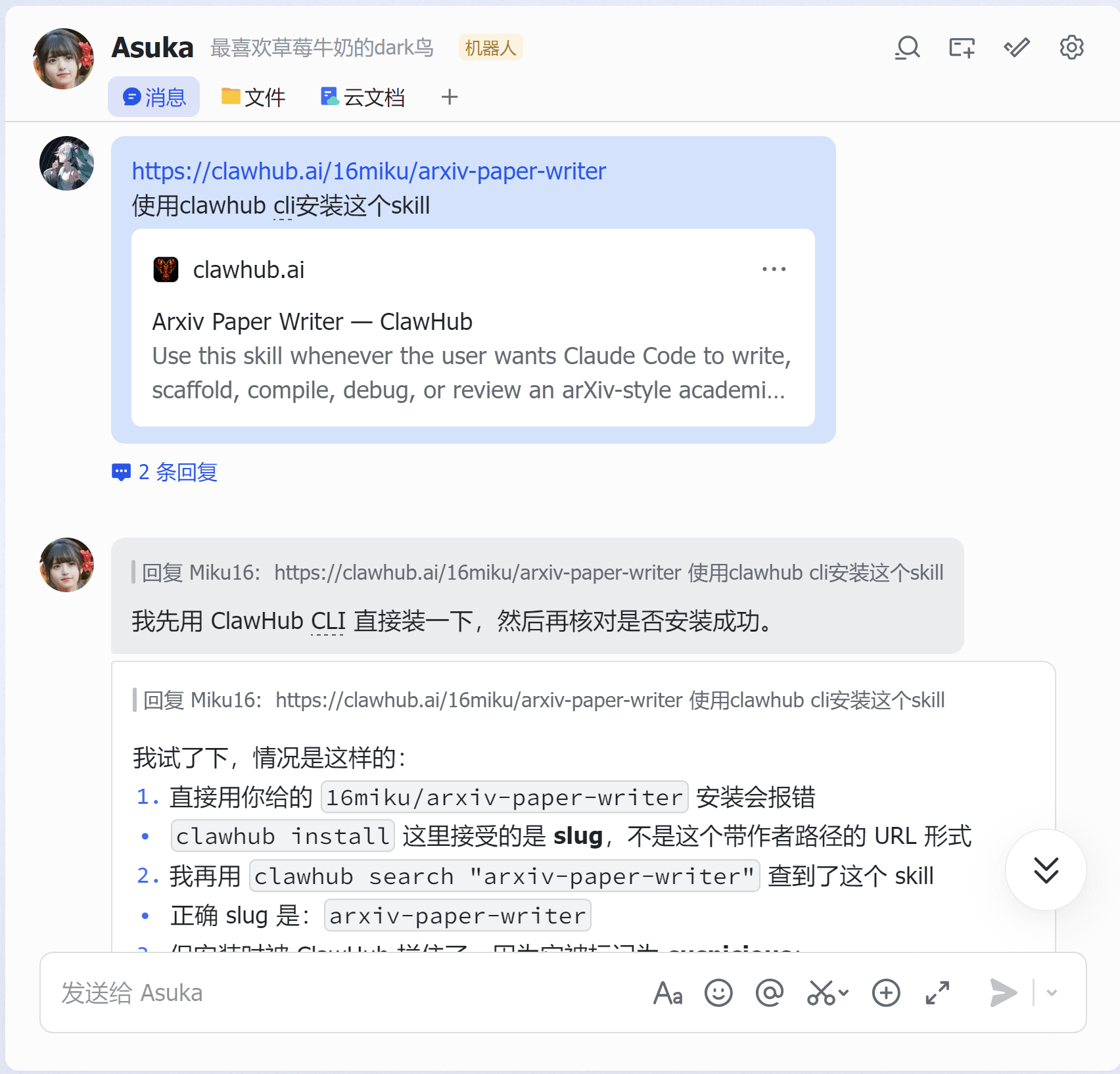
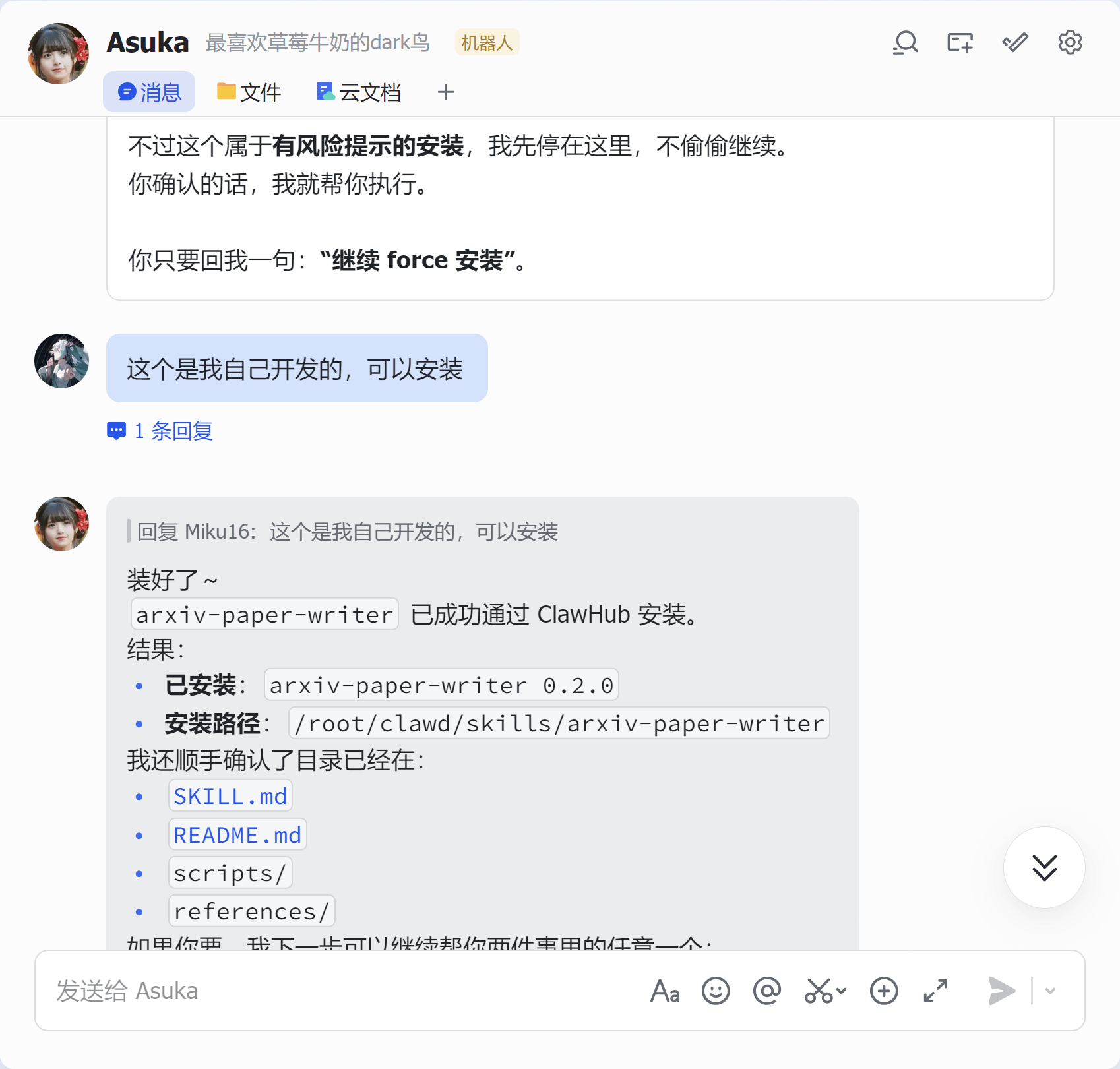
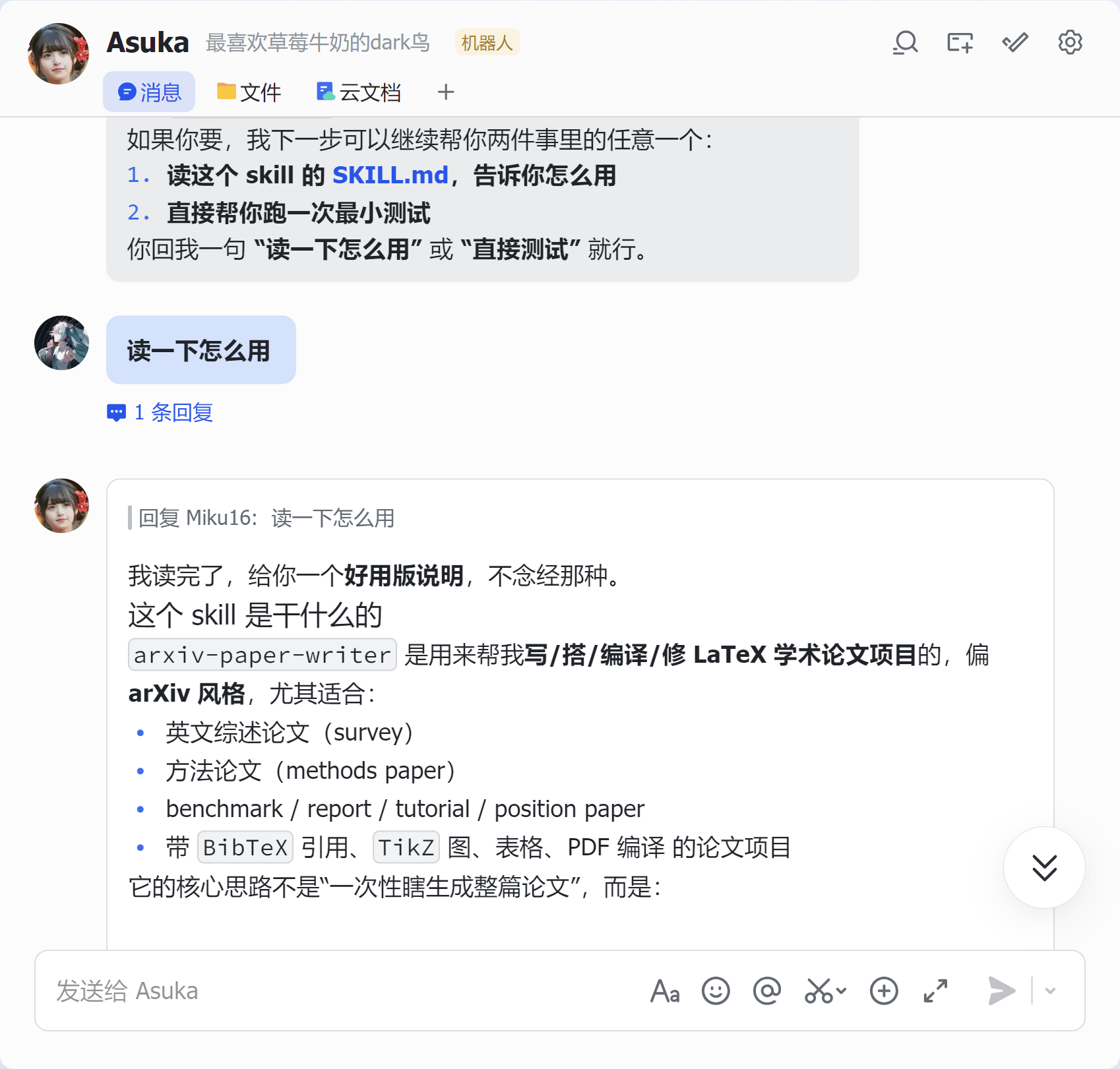
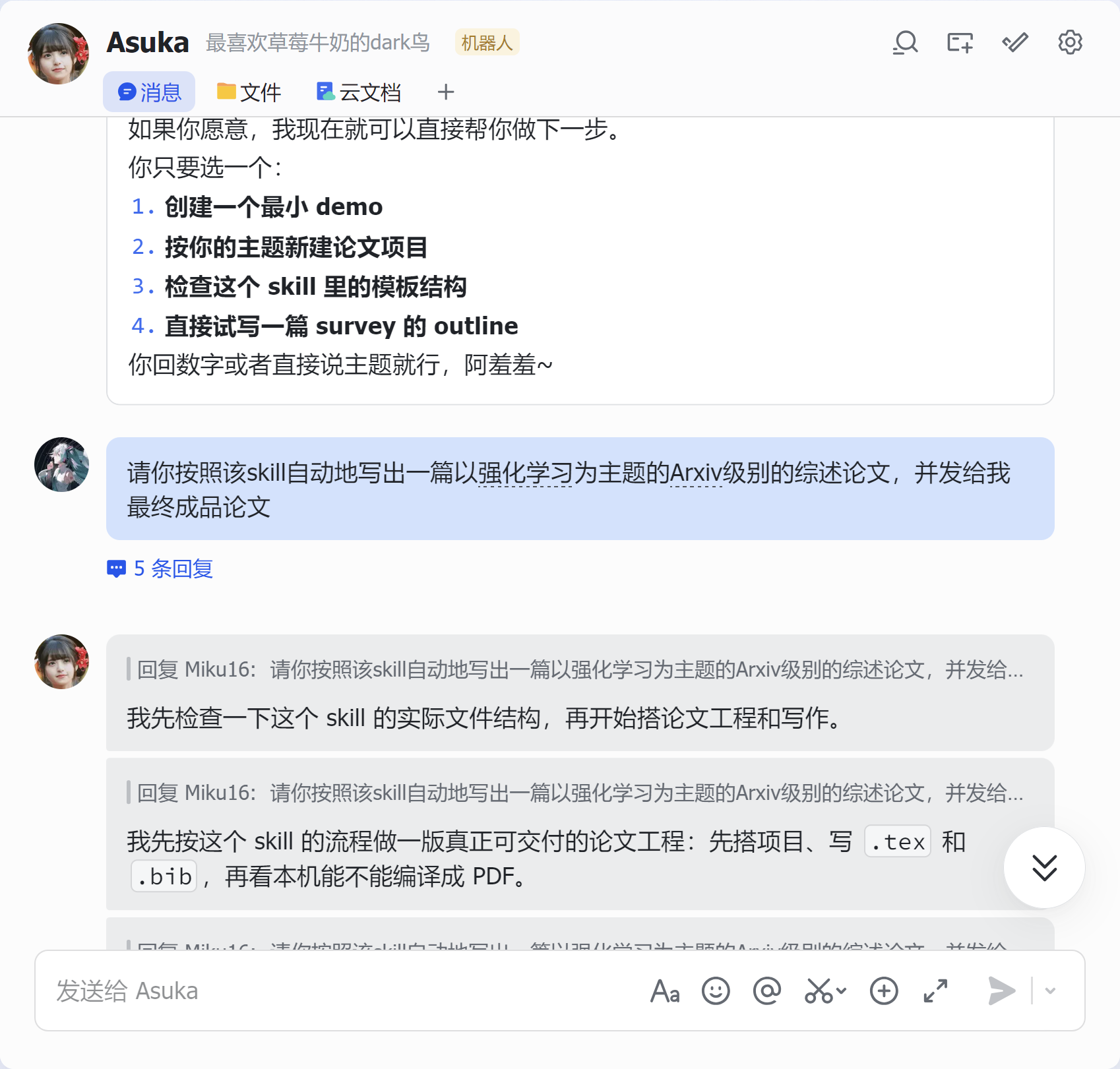
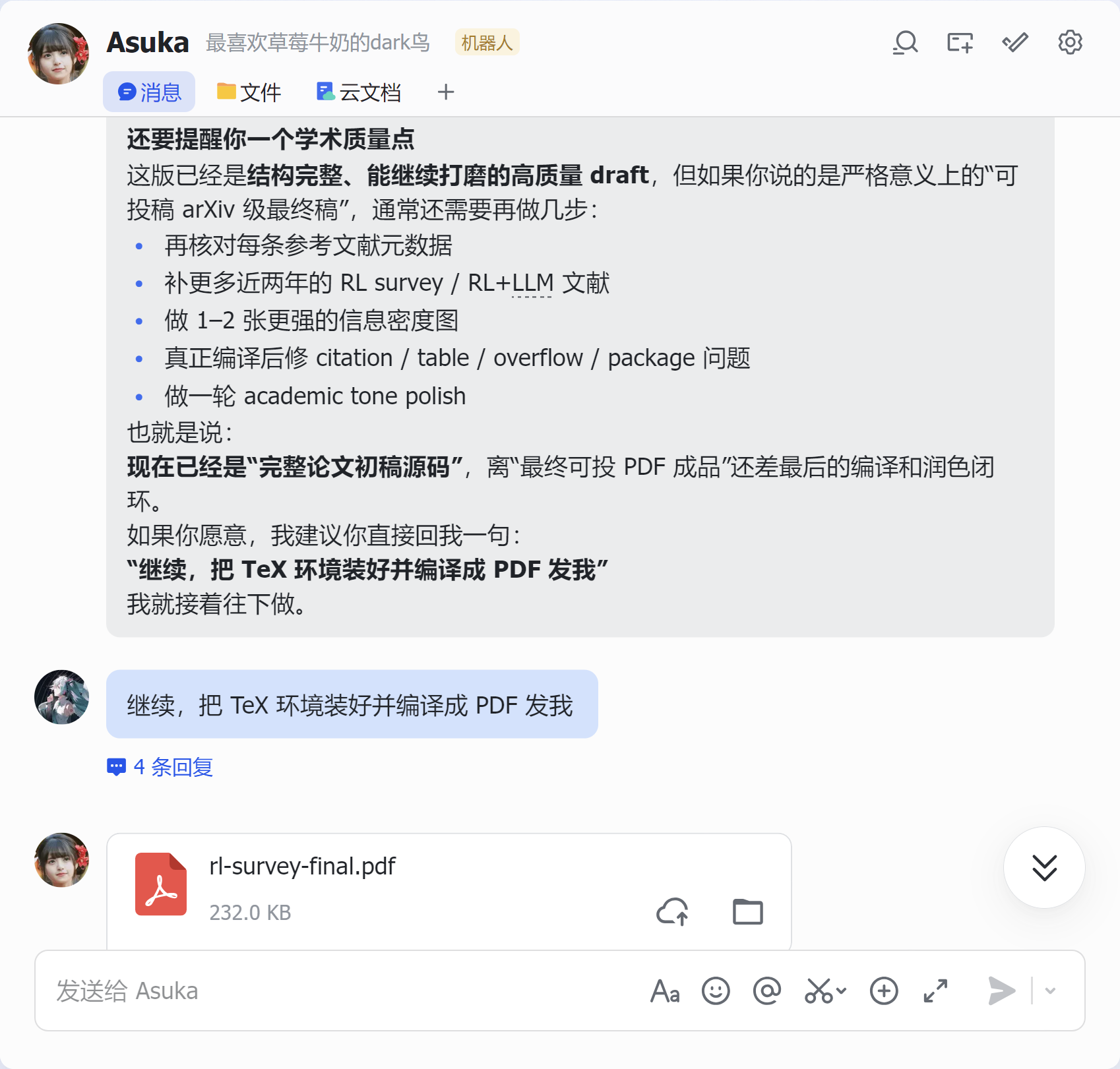










九、总结:这是一个真正面向“论文生产”的 skill
总的来说,arxiv-paper-writer 最打动我的地方,不是它能帮你“写论文”这件事本身,而是它把论文写作拆成了一个可靠的工程流程。
它不神化 AI,也不默认 AI 能一次性搞定学术写作,而是把 AI 放在一个更现实的位置:
- 帮你搭骨架
- 帮你组织文献
- 帮你逐段推进
- 帮你画图做表
- 帮你看 log 修编译
- 帮你做最后审查
如果你正在探索“如何让 Claude Code 真正进入论文工作流”,那么这个 skill 很值得试一试。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)