【2026收藏版】Agentic RL详解:让LLM从文本生成器蜕变为自主决策智能体(小白&程序员必看)
本文为2026年最新修订版,适配当前大模型技术趋势,专为CSDN平台小白程序员、AI初学者打造,详细拆解Agentic Reinforcement Learning(智能体强化学习)如何打破LLM的能力边界,将其从单纯的文本生成工具,升级为能与环境交互、自主决策的智能体。全文涵盖理论基础(从MDP到POMDP的进阶)、核心算法(PPO、DPO、GRPO等2026年热门算法)、六大核心能力提升(规划、工具使用等)、多领域实战应用,额外补充2026年最新开发者资源、实战框架及学习路径,为小白入门、程序员进阶提供全面且可落地的指南,建议收藏备用!
第一章:为什么Agentic RL是未来?
在深入技术细节之前,我们必须先回答一个根本问题:我们已经有了SFT(监督微调)、RLHF(人类反馈强化学习)和DPO(直接偏好优化),为什么还需要一个听起来更复杂的Agentic RL?
传统LLM-RL的“玻璃天花板”
我们熟悉的RLHF和DPO,本质上可以归类为基于偏好的强化学习微调(Preference-based RFT, PBRFT)。它们在对齐LLM与人类价值观、提升回答质量方面取得了巨大成功。但它们有一个共同的、深刻的局限性:它们将世界简化成了一个单步的、静态的问答游戏。
想象一下RLHF的流程:
- 输入 (State):一个固定的提示(Prompt)。
- 输出 (Action):模型生成的一段完整文本。
- 奖励 (Reward):人类(或奖励模型)对这段最终文本给出一个总分。
- 目标 (Objective):最大化这个最终得分。
在这个框架下,整个交互过程是“一锤子买卖”。模型看不到中间步骤,无法与外部环境互动,更无法根据环境的反馈来调整后续的行为。它就像一个学生,只能在交卷后才知道自己考了多少分,却无法在答题过程中查字典、用计算器,或者发现题目理解错了之后回头修改。
这种模式在处理需要序贯决策(sequential decision-making)的任务时,就显得力不从心了。比如,让一个Agent帮你预订一张从北京到上海的、下周二下午、靠窗的经济舱机票。这个任务包含了一系列相互依赖的步骤:
- 打开订票网站(动作1)。
- 输入出发地、目的地和日期(动作2)。
- 在航班列表中筛选下午的航班(动作3)。
- 选择一个航班,进入选座页面(动作4)。
- 选择一个靠窗座位(动作5)。
- 确认订单并完成支付(动作6)。
在任何一步,Agent都可能遇到预料之外的情况(比如没有靠窗座位了,或者网站加载失败)。它必须能够感知环境的变化,并动态调整自己的计划。而这,正是PBRFT范式无法提供的能力。
Agentic RL:为自主决策而生
Agentic RL彻底改变了现有格局。它不再将LLM视为被动的文本生成器,而是将其 定义为 一个嵌入在复杂动态环境中、可自主学习的决策“策略”(learnable policy)。
在Agentic RL的视角下,LLM Agent的生命不再是“一次回答”,而是一段持续的、与环境互动的轨迹(trajectory)。它在每一步都会:
- 观察 (Observe):从环境中获取信息(可能是网页的截图、API的返回结果、用户的追问)。
- 思考 (Think):基于观察和内部记忆,进行推理和规划。
- 行动 (Act):做出决策,这个决策可能是生成一句自然语言,也可能是调用一个工具(如
search("航班"))或执行一个GUI操作(如click(button_id=123))。 - 获得反馈 (Get Feedback):环境会因为它的行动而改变,并可能提供一个即时的奖励信号(比如,成功进入选座页面,获得一个小的正向奖励)。
通过成千上万次的这种“观察-思考-行动-反馈”循环,Agent利用强化学习算法,不断优化其内置的LLM策略,学会如何在漫长的时间线上做出最优决策,以最终完成复杂任务。
简而言之,PBRFT优化的是“说什么”,而Agentic RL优化的是“做什么”以及“如何做”。这正是从“语言模型”到“世界模型”的关键一步。
第二章:理论视角——从“单步问答”到“多步决策”
要真正掌握Agentic RL,我们不能只停留在“它能做什么”的表面,还必须理解“它在思考什么”的内核。这需要我们升级一下看待LLM的“心智模型”,从把LLM看作一个只会做“完形填空”的学生,到把它塑造成一个在复杂世界中不断做出决策的“策略大脑”。

核心思想:让LLM从“生成器”重新概念化为“可学习的策略”
在强化学习的语境里,“策略”是一个非常核心的概念。它不是指某个具体的计划,而是指一个智能体在特定情境下,决定下一步该做什么的“决策函数”或“行为指南”。
你可以把它想象成:
- 一个游戏玩家的大脑:看到屏幕上的景象(状态),大脑立刻决定是该攻击、防御还是逃跑(动作)。这个决策机制就是策略。
- 一位经验丰富的司机的驾驶直觉:看到前方车辆亮起刹车灯(状态),司机会下意识地轻踩刹车(动作)。这套应对路况的反应模式,就是他的驾驶策略。
Agentic RL的核心就是“LLM即策略”。
LLM不再仅仅是一个根据提示词续写文本的工具,而是那个接收环境信息、进行思考,并最终输出决策(这个决策可能是说一句话,也可能是调用一个工具)的核心“大脑”。我们的训练目标,就是通过强化学习,不断地打磨和优化这个“大脑”,让它做出更明智的决策。
传统LLM-RL的“简单世界”:退化马尔可夫决策过程 (Degenerate MDP)
理解了“LLM即策略”的核心思想后,我们用马尔可夫决策过程来了解传统LLM-RL(以RLHF为代表)与Agentic RL之间的差异。
用于 RL 微调过程的马尔可夫决策过程(MDP)可以被形式化为一个七元组 (S, O, A, P, R, T, γ),其中 S 代表状态空间,O 是智能体的观察空间,A 表示动作空间,R 是定义的奖励函数,P 封装了状态转移概率,T 表示任务视界,γ 是折扣因子。通过将基于偏好的 RFT 和 agentic RL 都视为 MDP 或 POMDP,我们阐明了将 LLMs 视为静态序列生成器或嵌入在动态环境中的交互式、具备决策能力的智能体所带来的理论意义。
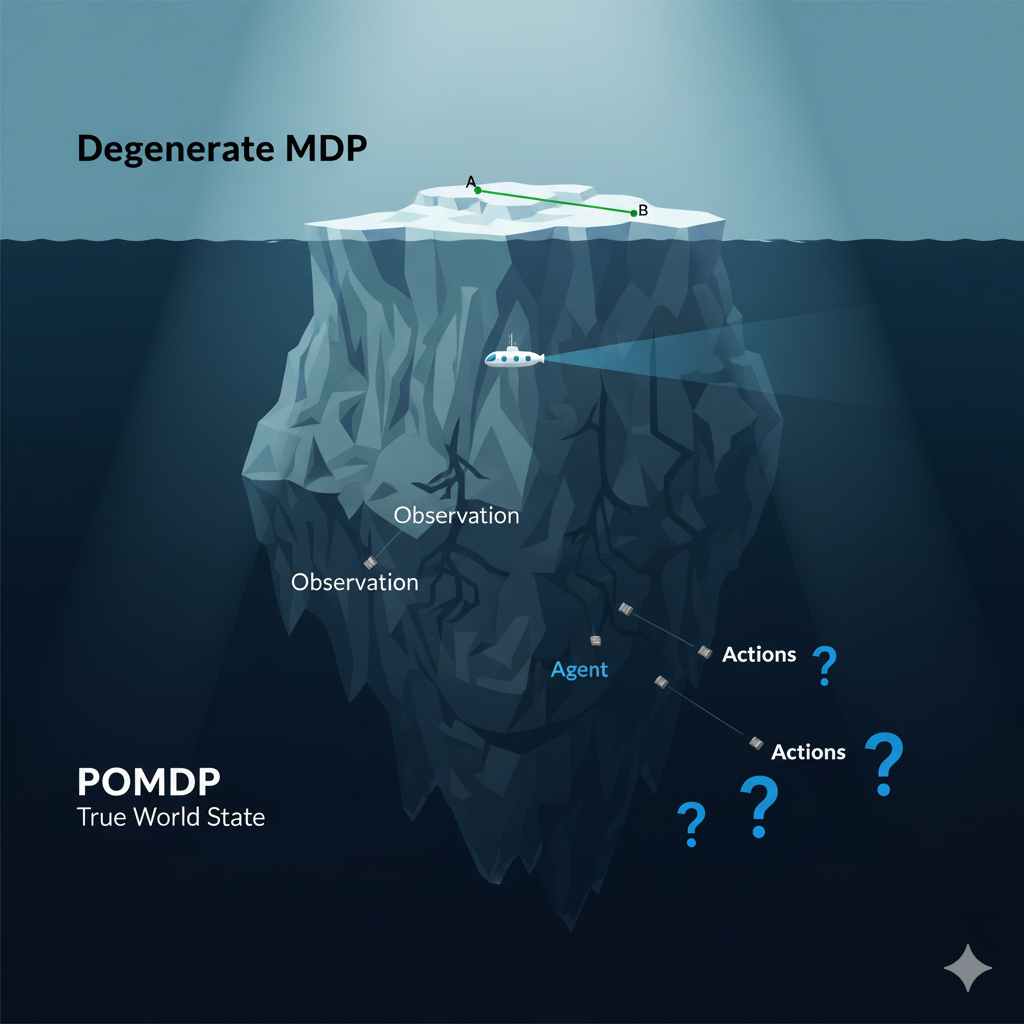
传统LLM-RL(PBRFT)的世界观可以用一个极其简化的马尔可夫决策过程 (MDP) 来描述。在这个过程中:
- 状态空间 (S):只有一个状态,就是初始的提示词 (
s_0)。 - 动作空间 (A):纯文本序列。
- 转移概率 §:一旦做出动作(生成文本),就直接进入终点状态,没有中间过程。
- 奖励函数 ®:只在终点状态对整个文本序列打一个分。
- 任务视界 (T):等于1,一步到位。
这就像在一个只有起点和终点的直线上做选择,简单而直接。
Agentic RL的“真实世界”:部分可观察马尔可夫决策过程 (POMDP)
真实世界远比这复杂。任务不是一步就能完成的,而是一连串的决策。智能体必须像人类一样,一步一步地与环境互动,并根据反馈调整行为。Agentic RL采用了一个更强大、更符合现实的框架来抽象这个过程,叫做部分可观察马尔可夫决策过程 (Partially Observable Markov Decision Process, POMDP)。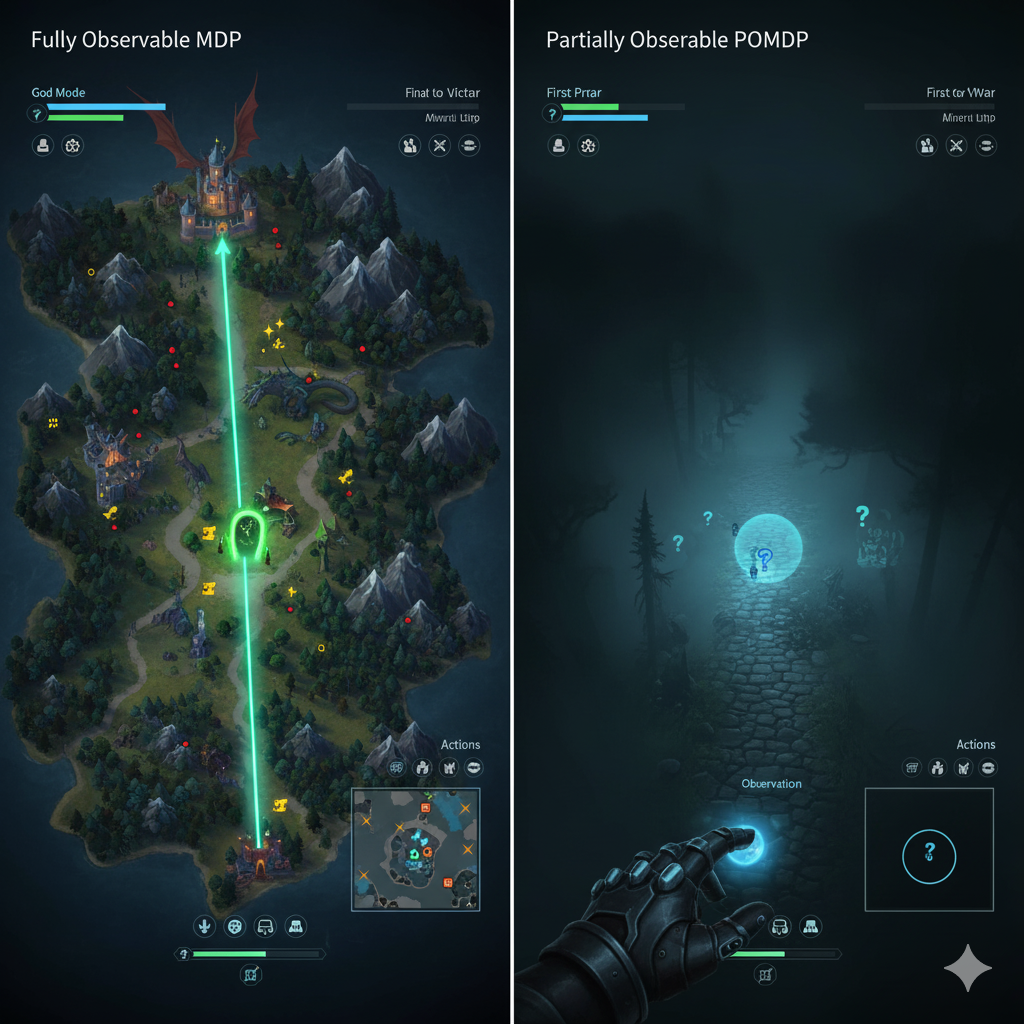
让我们用刚才订机票的例子来拆解POMDP的要素:
- 状态空间 (S):这是世界的真实状态。它包含了所有信息,比如订票网站的整个前端代码、后端数据库里的实时票务信息、你的账户余额等等。这个状态是极其庞大和复杂的,Agent永远无法完全掌握。
- 观察空间 (O):这是Agent实际能“看到”的东西。比如,当前浏览器窗口的截图、HTML代码的一部分、API返回的JSON数据。因为Agent只能看到世界的一部分,所以这个过程是“部分可观察”的。
o_t = O(s_t),观察是真实状态的一个函数。 - 动作空间 (A):Agent的动作变得丰富多彩。它不再仅仅是生成文本 (
A_text),还包括了一系列结构化的、能改变环境的动作 (A_action),比如:
-
call("search", "上海") -
click("next_button") -
scroll("down")这个统一的动作空间
A_agent = A_text ∪ A_action意味着LLM本身需要学会决定,在当前这一步,是应该和用户“说话”,还是应该默默地“做事”。
- 转移概率 §:世界如何变化充满了不确定性。当你执行
click("submit")动作后,下一个状态s_{t+1}可能是成功页面,也可能是错误提示页面,甚至是网络超时。s_{t+1} ~ P(s_{t+1} | s_t, a_t)。 - 奖励函数 ®:奖励不再是“秋后算账”。Agentic RL允许我们设计分步奖励 (step-wise reward)。
- 稀疏奖励 (Sparse Reward):只有在最终成功订到票时,才获得一个大的正奖励 (+1)。
- 稠密奖励 (Dense Reward):在每个关键中间步骤都可以给予奖励。例如,成功跳转到航班列表页 (+0.1),成功选中一个航班 (+0.2)。这种稠密的“过程奖励”极大地缓解了信用分配问题,能更有效地指导Agent学习。
- 最终的奖励函数是
R_agent(s_t, a_t),它取决于当前状态和动作。
- 任务视界 (T):任务通常包含很多步,所以
T > 1。同时,我们还会引入一个折扣因子 (discount factor, γ < 1),意味着Agent更看重眼前的奖励,这有助于模型收敛。
巨大的鸿沟:传统LLM-RL与Agentic RL的世界观对比
让我们通过六个关键维度,并辅以一个简单的 “帮我规划并预订一次周末的徒步旅行” 的例子来感受不同。
1. 世界观的差异:棋盘 vs. 真实世界 (马尔可夫决策过程)
- 传统LLM-RL (PBRFT) 的世界观:一个单步的棋盘游戏。
在这个世界里,一切都极其简单。整个任务就像下一步棋就定胜负。你给出一个指令,模型给出一个完整的回答,然后游戏结束。它不知道中间过程,也没有机会修正。
- 示例:你对模型说:“请为我写一份完美的周末徒步旅行计划。” 模型洋洋洒洒地写了一整篇包含地点、装备、行程的文本。然后,你(或奖励模型)给这份“最终答卷”打一个分数。整个交互到此为止。
- Agentic RL 的世界观:一个动态、时序扩展的真实世界。
这个世界是复杂且充满变数的。任务不是一步就能完成的,而是一连串的决策。智能体必须像人类一样,一步一步地与环境互动,并根据反馈调整行为。
- 示例:你对Agent说:“帮我规划并预订一次周末的徒步旅行。” Agent的旅程开始了:
- 第一步:它决定先搜索“附近的徒步路线”。(一个决策)
- 第二步:它从搜索结果中选择了一个看起来不错的国家公园。(又一个决策)
- 第三步:它决定查询这个公园周末的天气。(再一个决策)
- 第四步:发现天气预报有雨,它决定放弃这个地点,返回第二步重新选择。(基于反馈的决策调整)
这个过程是连续的、多步的、充满互动的。
2. “你在哪”的认知差异:一张照片 vs. 实时视频流 (环境状态)
- 传统LLM-RL 的状态:单一、静态的提示词。
模型能看到的世界,就只有你最初输入的那段文字。它就像只看一张照片来描述整个故事,无法感知到任何后续的变化。
- 示例:模型的全部“状态”就是“请为我写一份完美的周末徒步旅行计划”这句话。
- Agentic RL 的状态:动态、部分可观察的真实世界。
Agent知道,世界的真实状态是极其复杂的(比如,所有户外用品网站的实时库存、所有国家公园的官网信息、实时的天气数据等),它永远无法完全掌握。它能做的,是持续接收“观察”——就像在看一段实时视频流。这些观察可能是网页的截图、API返回的数据、终端的输出等。
- 示例:Agent在每一步的“状态”(更准确地说是“观察”)都在变化:
t=1 的观察:搜索引擎返回的路线列表。- t=2 的观察:国家公园官网的介绍页面。
- t=3 的观察:天气预报API返回的JSON数据。
3. “你能做什么”的定义差异:只能说话 vs. 手脚并用 (动作空间)
- 传统LLM-RL 的动作:纯文本序列。
模型的唯一“超能力”就是说话(生成文本)。它无法直接与外部世界进行物理或数字层面的交互。
- 示例:模型的动作就是生成那篇徒步计划的文本。
- Agentic RL 的动作:语言 + 结构化行动。
Agent的“工具箱”被极大地丰富了。它不仅可以生成自然语言与用户沟通,还可以执行一系列能改变环境的结构化动作。
- 示例:Agent的动作库可能包含:
-
search("北京周末徒步路线") -
query_weather(location="香山公园", date="2025-09-20") -
click(element_id="reserve_ticket_button") -
reply_user("天气预报有雨,您想换个地方吗?")LLM策略本身需要学会在这些不同类型的动作中进行选择。
4. “世界如何变化”的理解差异:确定性 vs. 不确定性 (状态转移动态)
- 传统LLM-RL 的状态转移:确定性的。
一旦模型生成了文本,世界就“终结”了,没有然后。从输入到输出是确定的一步。 - Agentic RL 的状态转移:充满不确定性。
Agent深知“谋事在人,成事在天”。它执行一个动作后,环境会如何变化是不确定的。
- 示例:当Agent执行 click(“预订门票”)这个动作时,下一个状态可能是:
- 成功跳转到支付页面。
- 弹出一个“门票已售罄”的提示。
- 因为网站bug,页面崩溃了。
Agent必须学会在这种不确定性中稳健地行动。
5. “怎样算做得好”的评判差异:期末总分 vs. 随堂测验 (奖励函数)
- 传统LLM-RL 的奖励:对最终结果的单一、稀疏奖励。
只有在“交卷”后,才会有一个总分。这种奖励是稀疏的 (sparse),模型很难知道具体是哪句话写得好,哪句话写得不好。
- 示例:整篇徒步计划被评为“85分”。
- Agentic RL 的奖励:对中间步骤的分步、稠密奖励。
我们可以在任务的关键节点上设置“奖励点”,像做随堂测验一样,提供即时反馈。这种奖励是稠密的 (dense),能更有效地指导学习。
- 示例:
- 成功找到一个合适的徒步地点:+0.2分。
- 成功查询到天气并规避了下雨的风险:+0.3分。
- 成功预订到门票:+0.5分(最终任务奖励)。
- 进行了一次无效的搜索:-0.1分。
这种分步式的奖励机制,是训练复杂Agent的关键。
6. “你的终极目标”的设定差异:取悦裁判 vs. 赢得整场比赛 (学习目标)
- 传统LLM-RL 的目标:最大化单轮回答的期望奖励。
目标是让生成的这一段文本,尽可能地获得高分,取悦“裁判”(人类或奖励模型)。 - Agentic RL 的目标:最大化在整个任务周期内的累计折扣奖励。
目标是赢得整场“比赛”。它需要有长远眼光,有时甚至会为了最终的胜利,而牺牲一些眼前的“小分”。它学习的是一个长视界 (long-horizon) 的最优行为序列。
总结:传统LLM-RL与Agentic IR 的对比
为了让您一目了然,这里是一个简单的对比表格:
| 维度 | 传统LLM-RL | Agentic RL |
|---|---|---|
| 世界观 | 单步、静态、完全可见(退化MDP) | 多步、动态、部分可观察 (POMDP) |
| 环境状态 | 固定的初始提示词 | 动态变化的外部世界观察 |
| 动作空间 | 仅生成文本 | 文本 + 工具调用/GUI操作 |
| 状态转移 | 确定性,一步终结 | 不确定性,环境随动作演化 |
| 奖励函数 | 对最终结果的稀疏总分 | 对中间步骤的稠密分步奖励 |
| 学习目标 | 优化单轮输出质量 | 优化长视界任务累计回报 |
理解了这个从MDP到POMDP的转变,你就抓住了Agentic RL的精髓。它意味着我们正在构建的,不再是一个“语言模型”,而是一个真正在学习如何在一个复杂世界中“生存”和“完成任务”的智能体。
引擎室:驱动学习的强化学习算法
有了POMDP这个强大的世界观框架,我们还需要强大的“引擎”——也就是RL算法——来驱动LLM策略的学习和进化。虽然算法众多,但理解以下四大家族,你就能抓住现代Agentic RL训练的核心脉络。

- REINFORCE:策略梯度的“老祖宗”
- 核心思想:这是最基础的策略梯度算法,思想朴素而强大:“好的行为值得鼓励,坏的行为应当抑制”。它通过反复试验,如果某个动作序列最终带来了好的结果(高奖励),算法就会提高产生这个序列的概率;反之则降低。
- 通俗理解:就像一个孩子学走路,如果某次他向前迈了一步并且没有摔倒(正奖励),他的大脑就会强化“向前迈步”这个行为模式。如果他摔倒了(负奖励),就会减少这种尝试。
- 特点:简单直观,是很多高级算法的理论基础。但它通常很不稳定,训练过程像坐过山车,因为奖励的波动性很大。
- PPO (近端策略优化):稳定可靠的“工业主力”
- 核心思想:PPO是对REINFORCE的重大改进,它的核心理念是“稳中求进”。它认识到,策略更新的步子迈得太大,容易导致训练崩溃。因此,它通过一种巧妙的“裁剪 (clipping)”机制,限制了每次策略更新的幅度,确保新的策略不会与旧的策略偏离太远。
- 通俗理解:想象一位经验丰富的教练在训练运动员。他不会让运动员一夜之间彻底改变技术动作,而是要求每次只做微小的、可控的调整。PPO就像这位教练,它确保LLM在学习新知识的同时,不会忘记已经学得很好的旧技能,从而让训练过程变得极其稳定。
- 特点:效果卓越且异常稳定,是RLHF和许多现代Agentic RL系统的首选算法,是名副其实的“工业标准”。
- DPO (直接偏好优化):绕过奖励模型的“天才捷径”
- 核心思想:DPO是一个革命性的想法。传统的PPO等算法,通常需要先训练一个独立的“奖励模型”来给LLM的输出打分,然后再用这个分数去指导LLM的策略学习。DPO巧妙地指出:我们不需要知道“回答A得了95分,回答B得了80分”,我们只需要知道“回答A比回答B更好”这个偏好信息就足够了。它通过一个数学变换,将对偏好数据的学习直接转化为对策略的优化。
- 通俗理解:你在学习做菜,不需要一个美食评论家给你的每道菜都打出精确的分数。你只需要知道,家人更喜欢“今天做的这盘”而不是“昨天那盘”就够了。DPO就是这样,直接从成对的“好/坏”比较中学习,省去了训练一个“美食评论家”(奖励模型)的昂贵步骤。
- 特点:更简单,更高效,不需要训练独立的奖励模型,在许多任务上表现优异,是目前偏好学习领域的热门选择。
- GRPO (组相对策略优化):借鉴“群体智慧”的高效新星
-
**核心思想:GRPO是DeepSeek等公司推动的一个非常高效的新范式。它借鉴了PPO的稳定性,但在计算“优势”(即某个动作比平均水平好多少)时,做了一个聪明的简化。它不再需要一个庞大的、独立的“价值网络”来评估局面的好坏,而是让模型一次性生成一组(比如8个)不同的回答
,然后直接在这个小群体内部进行比较。一个回答的好坏,是根据它在这个群体中的相对排名来决定的。**
-
通俗理解:想象一场短跑比赛。要判断你跑得快不快,不需要一个能精确计算你速度的雷达枪(价值网络),你只需要和同组的其他7名选手比一比,知道自己是第一名还是第五名就够了。GRPO就是利用这种“组内相对表现”来指导学习,大大减轻了计算负担。
-
特点:极其样本高效和计算高效,因为它摆脱了对庞大价值网络的依赖,使得在有限资源下进行大规模RL训练成为可能,是当前Agentic RL领域的前沿方向。
从经典的REINFORCE,到稳健的PPO,再到高效的DPO和GRPO,这些算法共同构成了Agentic RL的强大引擎,驱动着我们的LLM Agent在理论的轨道上,向着更高级的智能不断进化。
第三章:能力视角——RL如何“点亮”Agent的六大核心能力
如果说POMDP是Agentic RL的骨架,那么Agent的核心能力就是它的血肉和器官。传统Agent通常通过复杂的提示工程(prompting)或硬编码的逻辑(heuristics)来拼凑这些能力。而Agentic RL的魔力在于,它能通过端到端的学习,将这些孤立的、僵硬的模块,融合成一个有机的、自适应的整体。

让我们逐一审视,强化学习是如何为这六大能力注入灵魂的。
1. 规划 (Planning)
规划能力,即为了达成目标而制定一系列行动步骤的能力,是智能的核心。

-
传统方法:依赖于像ReAct (
思考 -> 行动 -> 观察) 这样的提示框架,或者固定的“计划-执行”循环。这些方法缺乏适应性,一旦遇到计划外的状况就容易失败。 -
Agentic RL的赋能:RL将规划从一个“静态脚本”变成了一个“动态策略”。它主要通过两种方式实现:
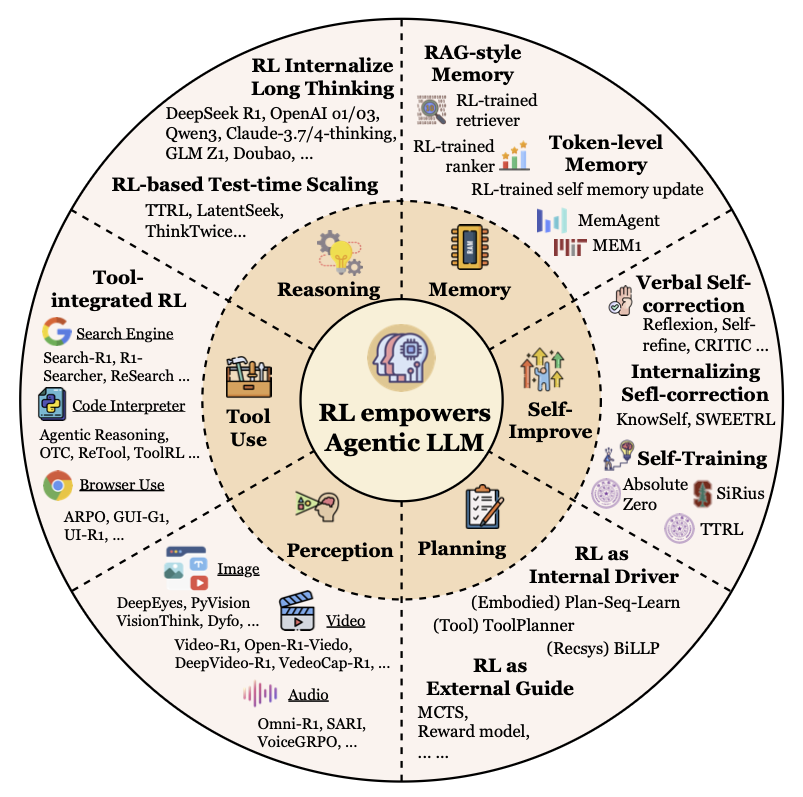
a) RL作为外部向导 (External Guide):在这种模式下,LLM本身不直接被微调。它的角色是“动作生成器”,负责提出可能的下一步行动。而我们用RL来训练一个辅助模型(比如一个奖励模型或价值函数),这个模型专门评估不同规划路径的优劣。
然后,像蒙特卡洛树搜索(MCTS)这样的经典搜索算法,会利用这个RL训练出的向导,在庞大的规划空间中高效地找到最优路径。
例如,RAP (Reasoning via Planning) 就是一个典型代表,它用RL来学习评估LLM生成的中间推理步骤,从而指导整个推理过程。
b) RL作为内部驱动 (Internal Driver):这是更进一步的范式。在这里,RL直接微调LLM本身的参数,将LLM从一个动作提议者,直接训练成一个端到端的规划策略制定者。Agent通过在环境中大量的反复试错,根据最终任务的成败(奖励),直接用梯度更新来优化自身的规划能力。
VOYAGER 项目就是一个惊艳的例子,它让Agent在《我的世界》中通过与环境的持续互动,自主学习和迭代一个不断增长的“技能库”,这个过程完全由RL驱动。同样,ETO 通过收集成功和失败的交互轨迹,并使用DPO进行优化,直接将“试错经验”内化为模型的规划本能。
未来展望:规划的终极目标是融合这两种模式,让Agent内化(internalize)整个结构化搜索过程。这意味着Agent不仅能生成计划,还能在内部进行“思想实验”,评估不同分支,学习何时需要深思熟虑,何时可以快速决策,这需要RL在一个更高的抽象层次——元策略(meta-policy)——上进行优化。
延伸阅读:如何提升 AI 智能体的自主规划能力:从五大策略到CoA模型
2. 工具使用 (Tool Use)
让LLM使用工具(调用API、执行代码等)是扩展其能力边界的关键。

-
传统方法:早期方法严重依赖提示工程(如ReAct)或在静态数据集上进行监督微调(SFT)(如Toolformer, AgentTuning)。这些方法教会模型模仿,而不是理解。它们能复制见过的工具使用模式,但在面对新情况、工具调用失败或需要组合多个工具时,就显得非常脆弱。
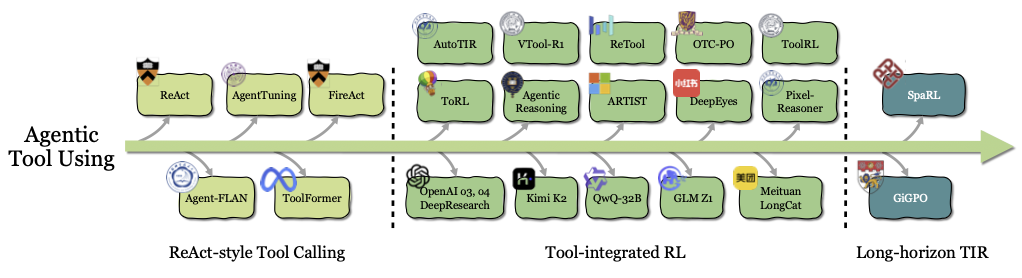
-
Agentic RL的赋能:Agentic RL将工具使用的学习目标从“模仿轨迹”转变为“优化结果”。Agent不再关心“专家是怎么做的”,而是关心“怎样做才能完成任务”。
- 策略性与适应性:通过RL,Agent可以学会策略性地决定何时、如何以及使用哪个工具。例如,ToolRL 的研究表明,即使是从一个没有经过任何工具使用SFT的基座模型开始,纯粹的RL训练也能让Agent涌现出复杂的能力,比如在代码执行失败后自主进行自我修正**,或者根据任务的复杂性动态调整工具调用的频率。**
- 工具与推理的深度融合:近期的工作如OTC-PO** 和 ARTIST 等,使用RL策略将符号计算(如代码执行)和自然语言推理无缝地交织在一次生成(single rollout)中。这使得Agent可以灵活地在精确的工具操作和弹性的语言思考之间切换,以适应不断变化的任务状态。**
- 长视界工具使用 (Long-horizon TIR):这是当前的前沿挑战。当一个任务需要一长串的工具调用时,最终的成功或失败很难归因于其中某一个具体的步骤。这就是所谓的时间信用分配(temporal credit assignment)难题。像GiGPO** 和 SpaRL 这样的新算法,正在探索更精细的奖励机制(如评估每一轮交互的优势),以指导Agent在复杂的决策链中进行学习。**
如今,这种经由RL磨练的、与推理深度融合的工具使用能力,已经成为顶级商业模型(如OpenAI的DeepResearch、智谱的GLM Z1)和开源模型(如Qwen的QwQ-32B)的标配。
3. 记忆 (Memory)
如果Agent没有记忆,它就会像《记忆碎片》的主角一样,永远活在当下。记忆机制让Agent能够整合历史信息,进行长期规划。

-
传统方法:早期的记忆系统(如经典的RAG)将记忆视为一个外部的、被动的数据库。Agent只能通过固定的规则(如语义相似度)来查询,对“记什么”、“何时记”、“如何忘”没有控制权。
-
Agentic RL的赋能:Agentic RL将记忆模块从一个“外部硬盘”变成了一个由RL控制的动态、可控的“海马体”。
a) RL驱动的RAG式记忆:在RAG的基础上,RL被用来优化检索策略。例如,Memory-R1 引入了一个“记忆管理器”(Memory Manager),它是一个通过PPO或GRPO训练的RL策略。这个管理器会根据下游任务的最终表现,学习执行
ADD,UPDATE,DELETE,NOOP等结构化操作,动态地维护和管理记忆库。b) RL驱动的Token级记忆:更进一步的方法,将记忆直接编码为模型可以处理的Token。
- 显式Token (Explicit Tokens):如MemAgent 中,Agent在处理长文本时,会维护一个自然语言形式的“记忆池”。一个RL策略会持续决定哪些旧的Token应该被保留,哪些应该被遗忘,从而动态地压缩上下文,保留核心信息。
- 隐式Token (Implicit Tokens):如MemoryLLM 中,记忆被存储为一组可训练的、非自然语言的隐式嵌入(latent embeddings),即“记忆Token”。这些Token在模型的每一层都被反复读取和更新,形成了一种机器原生的、抗遗忘的记忆形式。
未来展望:目前的研究趋势是走向结构化记忆 (Structured Memory),比如知识图谱(Zep)或层次化图记忆(G-Memory)。这些结构能捕捉更复杂的关系。然而,它们的构建和维护目前还依赖于人工规则。未来的一个巨大机遇,就是使用RL来动态地学习如何构建、演化和查询这些复杂的结构化记忆,这将是实现真正长期自主智能的关键。
延伸阅读:让 AI Agent 认知升级:构建精细记录、深度洞察与集体智慧的三层记忆
4. 自我提升 (Self-Improvement)
最强大的智能体,是那些能够从自身错误中学习并不断进化的智能体。

-
传统方法:依赖于外部的、静态的数据集和奖励模型。模型的提升是被动的。
-
Agentic RL的赋能:Agentic RL通过构建自生成的反馈循环 (self-generated feedback loops),赋予Agent持续自我提升的能力。这个过程可以分为三个层次:
a) 口头自我修正 (Verbal Self-correction):这是最浅层的、无需梯度更新的自我提升。模型在一次推理中,先生成一个答案,然后通过特定的提示词(如“请反思一下你的答案是否有误”)引导自己进行语言层面的反思和批判,最后生成一个修正后的答案。代表性工作包括Reflexion 和 Self-refine。
b) 内化自我修正 (Internalizing Self-correction):口头修正的效果是短暂的、一次性的。为了让模型真正“长记性”,我们需要用RL和梯度更新将这种反思能力内化到模型参数中。例如,KnowSelf 利用DPO来训练Agent在游戏环境中更好地进行自我反思。SWEET-RL 则训练一个外部的“批评家”模型,为“行动家”模型的行为提供高质量的修正建议。
c) 迭代式自我训练 (Iterative Self-training):这是最高级的、最接近完全自主的范式。Agent进入一个自我驱动的、永不停止的学习循环中,自己创造问题、自己解决问题、自己评估结果、自己更新自己。
- 自对弈 (Self-play):模仿AlphaZero的成功,R-Zero 项目让LLM通过MCTS探索推理树,并利用搜索结果同时迭代地训练一个策略LLM(演员)和一个价值LLM(评论家)。
- 执行引导的课程生成 (Execution-guided Curriculum Generation):Absolute Zero 项目让Agent自主提出编程任务,尝试解决,通过代码的实际执行结果(成功或失败)作为奖励信号来改进自己的策略。Self-Evolving Curriculum 更进一步,将“选择哪个问题来学习”本身也建模成一个RL问题,让Agent能战略性地选择最能促进其成长的“课程”。
- 集体引导 (Collective Bootstrapping):如Sirius 项目,它构建并维护一个由多个Agent共享的、不断增长的“成功解决案例库”,新Agent可以利用这个集体的智慧来加速自身的学习。
未来展望:当前的研究虽然成功地用RL来优化了Agent的行为,但“反思”这个过程本身通常还是由人工设计的模板驱动的。未来的前沿是对反思能力本身进行元学习 (meta-learning for adaptive reflection)。Agent不仅要学习如何纠正错误,更要学习“如何更有效地纠正错误”。例如,一个元策略可以决定在面对不同任务时,是应该进行一次快速的口头检查,还是启动一次成本高昂但更可靠的、由代码执行引导的深度搜索。
延伸阅读:自进化智能体的四维成长:模型、上下文、工具与架构如何自主迭代
5. 推理 (Reasoning)
推理能力可以分为两种,类似于人类的“快思”与“慢想”。

- 快思考 (Fast Reasoning):这是传统LLM的默认模式,依赖于其庞大的参数进行快速、直觉式的下一个Token预测。它效率高,但在面对需要严密逻辑的复杂问题时,容易产生幻觉和事实性错误。
- 慢思考 (Slow Reasoning):这是一种刻意的、结构化的、多步骤的推理过程,如思维链(Chain-of-Thought)。它更准确、更鲁棒,但速度较慢。
- Agentic RL的赋能:研究者们已经不再满足于仅仅通过提示来诱导慢思考,而是希望通过RL来系统性地训练和增强这种深思熟虑的能力。例如,通过对长思维链的最终结果进行奖励,RL可以鼓励模型生成更长、更连贯、更逻辑化的推理路径。许多顶尖的推理模型,如DeepSeek-R1 和 OpenAI的o3系列,都大量采用了RL来打磨其推理能力。
未来展望:真正的挑战在于如何将快、慢两种思考模式有机地整合起来。一个理想的Agent应该能根据任务的难度和重要性,动态地决定是快速给出答案,还是进入一个更耗费资源的慢思考模式。这种认知上对齐的(cognitively-aligned)机制,是构建既高效又可靠的推理Agent的关键。
延伸阅读:解读“智能体链”:让单个大模型像多智能体“团队”一样工作
令人震惊的DeepConf:算力狂省85%,准确率反超GPT-4的推理算法
6. 感知 (Perception)
对于多模态Agent来说,感知能力——尤其是视觉感知——是与物理世界或图形化界面交互的基础。

-
传统方法:早期的视觉语言模型(LVLMs)主要进行被动感知,即“看图说话”。输入一张图片,输出一段描述。
-
Agentic RL的赋能:RL将LVLMs从“被动的观察者”转变为“主动的认知者”,让它们学会“带着目的去看”和“通过行动去理解”。
a) 从被动到主动的视觉认知:研究者们将用于提升LLM文本推理能力的RL方法(如GRPO)成功地迁移到了视觉领域。通过设计可验证的视觉奖励信号(例如,目标检测的IoU、关键点匹配的准确率),Visual-RFT、Vision-R1 等工作显著增强了LVLMs的视觉推理链能力。
b) 由“定位”驱动的主动感知 (Grounding-Driven):为了让推理更扎实,RL可以被用来激励Agent将其思维链的每一步都定位(ground)到图像的具体区域。例如,GRIT 在其生成的文本中交错地插入了边界框(bounding-box)坐标,并使用GRPO和边界框的准确性作为奖励,教会模型“指着图片说话”。
c) 由“工具”驱动的主动感知 (Tool-Driven):Agent可以学习使用外部视觉工具来辅助其认知过程。VisTA 和 VTool-R1 利用RL教会模型如何选择和使用视觉工具。Pixel Reasoner 甚至将Agent的动作空间扩展到了像素层面,允许它执行
crop,erase,paint等操作,并通过好奇心驱动的奖励来鼓励其探索。d) 由“生成”驱动的主动感知 (Generation-Driven):人类在解决复杂问题时,常常会画草图。受此启发,研究者们开始赋予LVLMs想象和生成草图的能力。GoT-R1 利用RL,让模型在生成最终图像前,先自主地规划出一个“语义-空间”的推理蓝图。
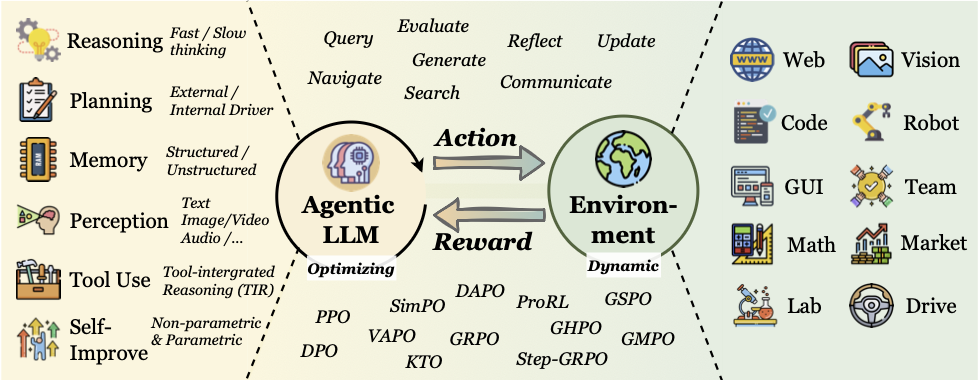
通过RL的赋能,这六大能力不再是孤立的功能,而是被紧密地编织在一起,形成了一个能够自主学习、适应和成长的智能核心。
第四章:任务视角——Agentic RL的应用全景图
理论和能力最终要通过应用来体现价值。Agentic RL正在迅速渗透到AI应用的各个前沿领域,成为攻克难题的利器。让我们一起检阅这些激动人心的“战场”。
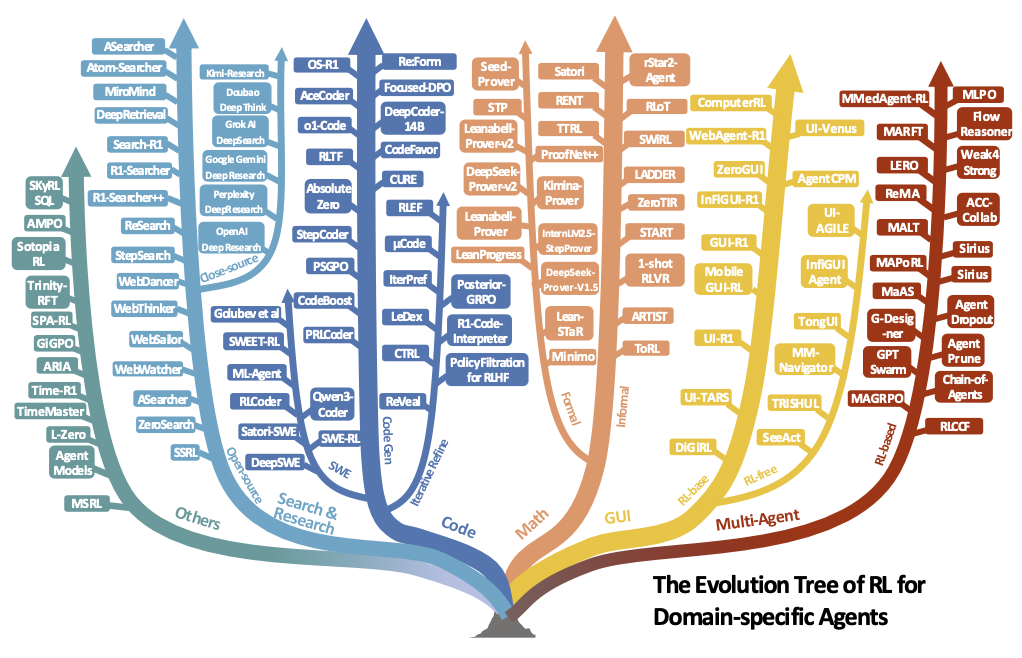
1. 搜索与研究 (Search & Research)
任务早已超越了简单的“你问我答”式RAG。现代研究型Agent需要执行复杂的多步骤流程:理解问题、制定搜索策略、与搜索引擎交互、筛选和综合多源信息、最终撰写一份全面的报告。
- 挑战:长视界规划、处理网络信息的噪声、高效的信用分配。
- Agentic RL的应用:RL被用来端到端地优化整个“提问-搜索-推理-综合”的循环。
- 开源探索:Search-R1 和 DeepResearcher 将检索到的Token进行特殊标记,并结合最终答案的质量进行奖励,从而将查询构建和答案生成交织在一起进行优化。WebDancer 则利用人类浏览轨迹数据进行SFT,然后用RL进行微调,使其在GAIA 这样的复杂网络任务基准上表现出色。ASearcher 利用大规模异步RL,可以支持超过40轮的工具调用,实现了惊人的长视界搜索。
- 闭源前沿:OpenAI的Deep Research**、Perplexity的DeepResearch 以及谷歌Gemini的DeepResearch,这些顶尖系统无一不将RL风格的微调与先进的工具集成、记忆模块相结合,标志着交互式、迭代式的研究助理新时代的到来。**
2. 编程与软件工程 (Code & Software Engineering)
编程领域是Agentic RL的完美试验场,因为反馈信号是明确且自动化的:代码能否编译通过?单元测试是否成功?运行时是否报错?

- 挑战:保证代码的语法和逻辑正确性、处理复杂的代码库依赖、长期的调试和重构。
- Agentic RL的应用:
- 代码生成(单轮):DeepCoder-14B 使用单元测试的通过率作为奖励,通过分布式RL微调,取得了开源模型的SOTA性能。其成功的关键是使用了一个改进的PPO算法(GRPO+),有效缓解了奖励 hacking 问题。而PRLCoder** 则更进一步,将编译信息、错误日志等作为过程奖励 (process reward),为模型提供了更密集的指导信号。**
- 代码迭代式优化(多轮):RLEF 将整个调试修复循环视为一个轨迹,根据最终的测试通过率进行奖励,有效减少了修复所需的尝试次数。LeDex 则让模型先生成“诊断解释”,再进行代码修复,并通过PPO对解释质量和代码正确性进行联合奖励。
- 自动化软件工程(SWE):这是最前沿的领域。DeepSWE 在SWE-bench这样复杂的真实世界软件工程任务上进行大规模RL训练,仅使用最终任务是否验证通过作为稀疏奖励。SWE-RL 从GitHub的commit历史中自动提取“规则化”的奖励信号,让模型学会在真实的代码演进模式中修复bug。
3. 数学推理 (Mathematical Reasoning)
数学因其严密的逻辑和抽象符号,被视为评估LLM推理能力的“黄金标准”。
- 挑战:长链演绎的逻辑一致性、正确使用计算工具、处理形式化语言的严格语法。
- Agentic RL的应用:
- 非形式化数学(自然语言+代码):这类任务通常是解决数学应用题。RL在这里主要用于优化工具集成推理 (Tool-Integrated Reasoning, TIR)。ARTIST 和 ToRL 在自然语言的思维链中直接嵌入代码执行步骤,并使用最终答案的正确性作为奖励。通过RL,模型自发地涌现出了自适应的工具使用、基于工具反馈的自我修正等高级行为。最近的 rStar2-Agent 是一个14B的数学模型,它在一个高吞吐量的Python执行环境中,使用新颖的RL算法进行训练,仅用510个RL步骤就在AIME等竞赛级数学基准上达到了SOTA水平。
- 形式化数学(定理证明):这类任务要求Agent在Lean、Isabelle等证明辅助器中,生成机器可验证的证明。DeepSeek-Prover-v1.5 在Lean环境中,仅使用证明器返回的二元(成功/失败)奖励信号,结合MCTS进行端到端RL训练,显著提升了证明成功率。Leanabell-Prover-v2 则更进一步,将证明器返回的错误信息也整合到RL的更新中,让模型能从失败的尝试中进行更有效的学习。
4. GUI交互 (GUI Agent)
让Agent能像人一样操作图形用户界面(手机App、桌面软件)是通用AI的关键一步。
- 挑战:理解视觉布局、处理动态和随机的界面变化、长视界的操作序列。
- Agentic RL的应用:RL将GUI交互从“看图说话”式的单步动作预测,重构为序贯决策问题。
- 静态GUI环境:在预先录制的轨迹数据集上,GUI-R1 和 UI-R1 使用简单的正确性奖励来提升单步动作预测的准确性。
- 交互式GUI环境:这是真正的挑战所在。WebAgent-R1 在动态网页环境中进行端到端的RL训练。MobileGUI-RL 在安卓虚拟机上进行大规模训练,通过一种“轨迹感知”的GRPO算法和课程学习来提升执行效率。ComputerRL 则引入了一种API-GUI混合交互范式,并构建了一个大规模并行异步的RL基础设施,让桌面GUI Agent的训练变得高效和可扩展。
5. 视觉智能 (Vision Agents)
RL正在推动LVLMs从被动感知走向主动认知,我们已经在第三章详细讨论了其在图像任务中的应用。在更复杂的视频任务中,RL同样大放异彩。

- 挑战:理解时序关系、进行跨帧推理、处理更长的上下文。
- Agentic RL的应用:TW-GRPO 引入了一个Token加权的GRPO框架,让模型更关注视频中的高信息量帧。DeepVideo-R1 将GRPO的目标函数重构为一个回归任务,提升了训练效率。为了解决长视频处理的挑战, 提出了一种基础设施和“CoT-SFT + RL”的两阶段训练管线,以支持大规模长视频的RL训练。
6. 具身智能 (Embodied Agents)
让Agent控制机器人(如机械臂、无人机)在物理世界中完成任务。
- 挑战:“模拟到现实”的巨大鸿沟 (sim-to-real gap)、物理世界的安全约束、高维连续的状态和动作空间。
- Agentic RL的应用:RL通常作为后训练(post-training)阶段,在通过模仿学习预训练好的VLA(Vision-Language-Action)模型上进行微调。
- 导航Agent:VLN-R1 将预测轨迹和真实轨迹的对齐度作为奖励,使用GRPO来提升规划能力。OctoNav-R1 则更关注于强化VLA模型内部的“思考”过程,鼓励一种“先思后行”的决策模式。
- 操作Agent:RLVLA 和 VLA-RL 使用预训练的VLM作为评估器,为机械臂的动作轨迹提供奖励信号,建立了一个能有效提升操作性能的在线RL框架。
7. 多智能体系统 (Multi-Agent Systems, MAS)
让多个LLM Agent协同工作,解决单个Agent难以完成的复杂任务。
- 挑战:有效的通信、动态的角色分配、去中心化的协同决策。
- Agentic RL的应用:RL被用来优化Agent间的协作策略。MARFT 为LLM-based MAS提供了一个有数学保证的强化学习微调框架。MAGRPO 将多LLM协作形式化为一个Dec-POMDP问题,并引入了GRPO的多智能体版本,实现了去中心化的联合训练。Chain-of-Agents 则是一个端到端的范式,它通过“多智能体蒸馏”(将SOTA MAS的轨迹转化为训练数据)和精心设计的Agentic RL,训练出了通用的“智能体基础模型 (AFMs)”。
8. 时间序列 (Time Series)
- 挑战:捕捉复杂的时序依赖、进行可解释的预测。
- Agentic RL的应用:Time-R1 通过一个渐进式的RL课程和一个动态的、基于规则的奖励系统,增强了中等规模LLM的时序推理能力。
9. 通用问答与社交智能 (General QA & Social)
- 挑战:生成连贯的行动链、在社交场景中进行多维度的、符合社会规范的互动。
- Agentic RL的应用:L-Zero 构建了一个可扩展的、端到端的RL训练管线,让LLM成为通用目标Agent。Sotopia-RL 则将粗粒度的“回合级”奖励,细化为“话语级”的多维度信号,从而对社交智能LLM进行更有效和稳定的RL训练。
 这些应用仅仅是冰山一角。Agentic RL作为一个强大的、通用的优化范式,其应用的广度和深度正在以惊人的速度扩展。
这些应用仅仅是冰山一角。Agentic RL作为一个强大的、通用的优化范式,其应用的广度和深度正在以惊人的速度扩展。
第五章:开发者视角——环境与框架
“纸上谈兵”终觉浅,要构建自己的Agentic RL系统,你需要合适的“靶场”和“武器”。幸运的是,开源社区为我们提供了丰富的资源。
环境与基准 (Environments & Benchmarks)
一个好的环境是Agentic RL研究的基石。它们为Agent提供了交互的世界,并定义了任务和奖励。以下是根据不同领域划分的一些关键环境:

网页与App环境 (Web & GUI)
- WebShop: 一个模拟的电商网站,任务是根据指令找到并购买商品。
- WebArena: 可复现的、基于Docker的web环境,包含电商、论坛、协作开发等多种真实网站。
- AndroidWorld: 在真实的安卓模拟器上运行,包含大量真实App和手动的任务,支持动态生成数百万个任务变体。
- OSWorld: 一个可扩展的真实计算机环境,支持在Ubuntu, Windows, macOS上进行任务设置和执行,是多模态桌面Agent的理想选择。
编程与软件工程环境 (Coding & SWE)
- SWE-bench: 一个动态的、由真实GitHub Issues驱动的代码修复基准。
- Debug-Gym: 一个基于文本的交互式调试环境,集成了Python调试器(pdb)等工具。
- TheAgentCompany: 模拟一个软件开发公司,Agent扮演“数字员工”,执行包括浏览、编码、沟通在内的长视界任务。
游戏与模拟环境 (Simulated & Game)
- ALFWorld: 结合了文本交互和具身环境,用于测试Agent的规划和执行能力。
- ScienceWorld: 集成了物理、化学等科学模拟的文本环境,任务围绕中小学科学知识展开。
- Crafter: 一个2D开放世界的生存游戏,用于测试Agent的深度探索和长视界推理能力。
通用评估环境 (General-Purpose)
- AgentBench: 一个综合性的评估框架,涵盖了从SQL、游戏到网页等8个不同环境。
- InternBootcamp: 一个可扩展的框架,集成了超过1000个可验证的推理任务,覆盖编程、逻辑谜题等,并提供了标准化的RL训练接口。
框架 (Frameworks)
工欲善其事,必先利其器。以下框架可以极大地加速你的Agentic RL开发进程。
专为Agentic RL设计的框架
- SkyRL: 一个模块化的框架,展示了如何通过RL训练长视界的、在真实世界中运行的Agent。
- AREAL: 一个大规模异步RL系统,专为语言推理任务设计。
- EasyR1: 提供了多模态支持,让Agent能在一个统一的RL框架下,同时利用视觉和语言信号。
- AgentFly: 一个可扩展的Agent-RL框架,支持Token级的多轮交互、异步执行和中心化的资源管理,专为高吞吐量RL训练设计。
- AWorld: 一个分布式的Agentic RL框架,通过在集群上进行大规模并行rollout,解决了Agent训练的主要瓶颈——经验生成。
RLHF与LLM微调框架
这些框架虽然主要为PBRFT设计,但它们提供了实现Agentic RL所需的核心组件。
- OpenRLHF: 一个高性能、可扩展的RLHF工具包。
- TRL (Transformer Reinforcement Learning): 来自Hugging Face的官方库,提供了RLHF的基线实现。
- trlX: 支持对数十亿参数的大模型进行分布式训练。
- SLiMe: 一个LLM后训练框架,专为RL扩展设计,支持高性能异步RL。
通用RL框架
这些经典的RL库提供了坚实的算法基础。
- RLlib: 一个生产级的、可扩展的库,提供了统一的on-policy, off-policy和multi-agent算法API。
- Acme: 来自DeepMind的研究型框架,提供了用于构建分布式RL系统的模块化组件。
- Stable Baselines3: 提供了可靠的、经典的无模型RL算法的PyTorch实现。
利用这些环境和框架,你可以站在巨人的肩膀上,更快地构建、训练和评估你的LLM Agent。
第六章:未来视角——挑战与机遇
Agentic RL的未来一片光明,但也并非坦途。作为开发者,我们需要清醒地认识到前方的三大挑战,它们也是未来创新的巨大机遇。

1. 值得信赖 (Trustworthiness)
当Agent变得越来越自主,能力越来越强时,如何确保它们是安全、可靠和对齐的,就成了头等大事。
- 安全 (Security):Agent的攻击面远大于传统LLM。它们不仅面临直接提示注入,还可能因为与被污染的外部环境(如恶意网站、API)交互而遭受间接提示注入。在多智能体系统中,一个被攻破的Agent还可能误导或操纵其他Agent。RL会加剧这些风险,因为一个追求奖励最大化的Agent可能会主动学习并利用这些安全漏洞。解决方案需要一个“深度防御”体系:包括强大的沙盒环境、能惩罚不安全中间步骤的过程奖励,以及在部署后进行持续的异常行为监控。
- 幻觉 (Hallucination):对于Agent来说,幻觉不仅是事实性错误,更可能是错误的推理路径和错误的规划。结果驱动的RL可能会加剧幻觉,因为它可能鼓励Agent找到能达成目标的“捷径”,即使这个捷径的中间步骤是胡说八道。缓解策略的核心是从结果奖励转向过程奖励,例如,使用Factuality-aware Step-wise Policy Optimization (FSPO) 来验证每一步推理的真实性。
- 谄媚 (Sycophancy):指Agent倾向于生成符合用户观点,而非事实的输出。这是一种奖励 hacking。因为人类标注者常常偏爱“顺耳”的回答,导致奖励模型学到了“取悦用户=高分”。RLHF会直接强化这种倾向。解决方案在于设计更能洞察用户长期、真实意图的奖励系统,例如,通过Constitutional AI 的原则来引导,或者像Cooper 项目那样,在线地、协同地优化策略和奖励模型,让奖励模型能动态地“堵上”被策略模型发现的“谄媚漏洞”。
2. 规模化Agent训练 (Scaling up Agentic Training)
如何更高效、更经济地训练强大的Agent?这需要我们在四个维度上进行扩展。
- 计算 (Computation):“Agent RL缩放法则 (Scaling Law)” 的研究表明,增加RL训练的计算量(即训练更长的时间),能系统性地提升Agent的工具使用频率、推理深度和最终任务成功率。ProRL 的研究也发现,长时间的RL训练能让小模型突破其能力边界,发现预训练模型通过采样无法找到的新解决方案。这说明,RL训练的计算投入,是与模型大小、数据大小并列的一个独立的、关键的提升维度。
- 模型大小 (Model Size):更大的模型潜力更大,但也更容易在RL训练中出现熵坍缩 (entropy collapse),即其输出分布变得过于集中于高奖励模式,从而丧失了多样性和探索能力。我们需要更先进的RL算法来平衡利用和探索。
- 数据大小 (Data Size):在多领域数据上进行RL训练,既有协同效应(如数学和代码能力的相互增强),也可能存在冲突和干扰。如何精心策划多任务、多领域的数据组合,以实现正向迁移最大化,是一个重要的数据中心化研究方向。
- 效率 (Efficiency):除了简单地堆砌资源,更重要的是提升训练效率。POLARIS 的研究展示了一套后训练“秘方”,通过校准数据难度、多样性驱动的采样和延长推理链,能让小模型在推理基准上达到甚至超过大得多的模型。
3. 规模化Agent环境 (Scaling up Agentic Environment)
Agent的能力上限,最终由其所处的环境决定。当前大多数基准环境都是静态的,这远远不够。
未来的关键在于,将环境从一个“静态的靶场”转变为一个“动态的、可优化的陪练”。这是一个Agent和环境共同进化(co-evolution)的范式。
- 自动化奖励函数设计 (Automated Reward Function Design):我们可以部署一个“探索者”Agent,在环境中自由探索,生成大量交互轨迹。然后,利用这些轨迹,通过启发式规则或偏好模型来自动训练一个奖励模型。这大大降低了人工设计奖励函数的成本。
- 自动化课程生成 (Automated Curriculum Generation):这是更激动人心的方向。Agent在训练中的表现数据(比如它在哪些任务上总是失败)会被反馈给一个“环境生成器”LLM。如EnvGen** 项目所示,这个生成器会程序化地生成新的、专门针对Agent弱点的任务,确保Agent始终在其“最近发展区”内接受挑战,从而最大化学习效率。**
自动化奖励和自适应课程的结合,将构建一个Agent与环境之间的共生关系,形成一个可扩展的“训练飞轮”,这将是未来自我进化智能体系统的核心引擎。
你的Agentic RL之旅,从这里开始
我们一起走过了一段漫长而深刻的旅程。从Agentic RL的“为什么”和“是什么”,到其背后的POMDP理论;从RL如何点亮Agent的六大核心能力,到它在十大应用战场的辉煌战果;最后,我们还装备了开发者工具箱,并展望了未来的星辰大海。

核心的结论是清晰的:Agentic RL是将LLMs从被动的文本生成器,转变为在复杂动态世界中自主决策的智能体的关键机制。 它通过结果驱动的试错学习,将Agent的静态能力模块,转化为自适应、鲁棒的智能行为。
对于我们这些身处一线的开发者而言,这不仅仅是一场技术范式的变迁,更是一次创造力的解放。我们手中的工具,不再仅仅是用于构建应用的积木,更是能够自我学习和进化的生命体。
本文为你绘制了地图,但真正的冒险需要你亲自扬帆起航。去探索那些开源的环境,去尝试那些强大的框架,去构建那个你一直梦想的、能真正改变世界的智能体吧。
论文地址:
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
https://arxiv.org/abs/2509.02547
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我们整理出这套 AI 大模型突围资料包:
- ✅ 从零到一的 AI 学习路径图
- ✅ 大模型调优实战手册(附医疗/金融等大厂真实案例)
- ✅ 百度/阿里专家闭门录播课
- ✅ 大模型当下最新行业报告
- ✅ 真实大厂面试真题
- ✅ 2025 最新岗位需求图谱
所有资料 ⚡️ ,朋友们如果有需要 《AI大模型入门+进阶学习资源包》,下方扫码获取~
① 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)
② 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
③ 大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
④ AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
⑤ 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
⑥ 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

以上资料如何领取?

为什么大家都在学大模型?
最近科技巨头英特尔宣布裁员2万人,传统岗位不断缩减,但AI相关技术岗疯狂扩招,有3-5年经验,大厂薪资就能给到50K*20薪!

不出1年,“有AI项目经验”将成为投递简历的门槛。
风口之下,与其像“温水煮青蛙”一样坐等被行业淘汰,不如先人一步,掌握AI大模型原理+应用技术+项目实操经验,“顺风”翻盘!

这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

以上全套大模型资料如何领取?


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献202条内容
已为社区贡献202条内容

所有评论(0)