深度探索:概念框架与语言层要素
概念框架与语言层要素
Vibe Coding 的知识层由两套互补的底层框架支撑:一套是用于理解和描述系统变化的哲学概念框架(对象、状态、快照、序列、过程、变换、同一、差异、关系),另一套是用于逐层穿透代码含义的语言层要素模型(从 L1 控制语法到 L12 设计意图)。本文档将二者合并为统一的认知工具,帮助你从“能看懂语法”跃迁到“能透视架构”。
为什么需要统一的概念框架?
一个反直觉但真实的前提:看不懂代码 ≠ 不懂语法,而 = 不懂其中某一层模型。本仓库的源文件明确指出,语法只占“看懂代码”所需能力的不到 30%——剩下的 70% 以上是内存模型、执行模型、类型系统、隐含契约和设计意图这些“非语法要素”。与此同时,本仓库的哲学基础文件定义了一组跨学科的原生概念:对象、状态、快照、序列、过程、变换、同一、差异、关系。这组概念并非松散的术语表,而是一套“动态本体论框架”,在哲学、数学、物理、计算机科学、系统科学、语言学和认知科学中均属于基础语法。
两套框架的关系可以这样理解:哲学概念框架回答“世界由什么构成、如何变化”,语言层要素模型回答“代码在说什么、为什么这样写”。前者是认知元工具,后者是工程应用层。将二者对齐后,你面对任何陌生代码库时,都能同时回答两个维度的问题——它描述了什么系统状态,以及它在哪个语言层级上传达了什么信息。
下面这张架构图展示了两个框架的统一关系与它们在本仓库知识体系中的位置:
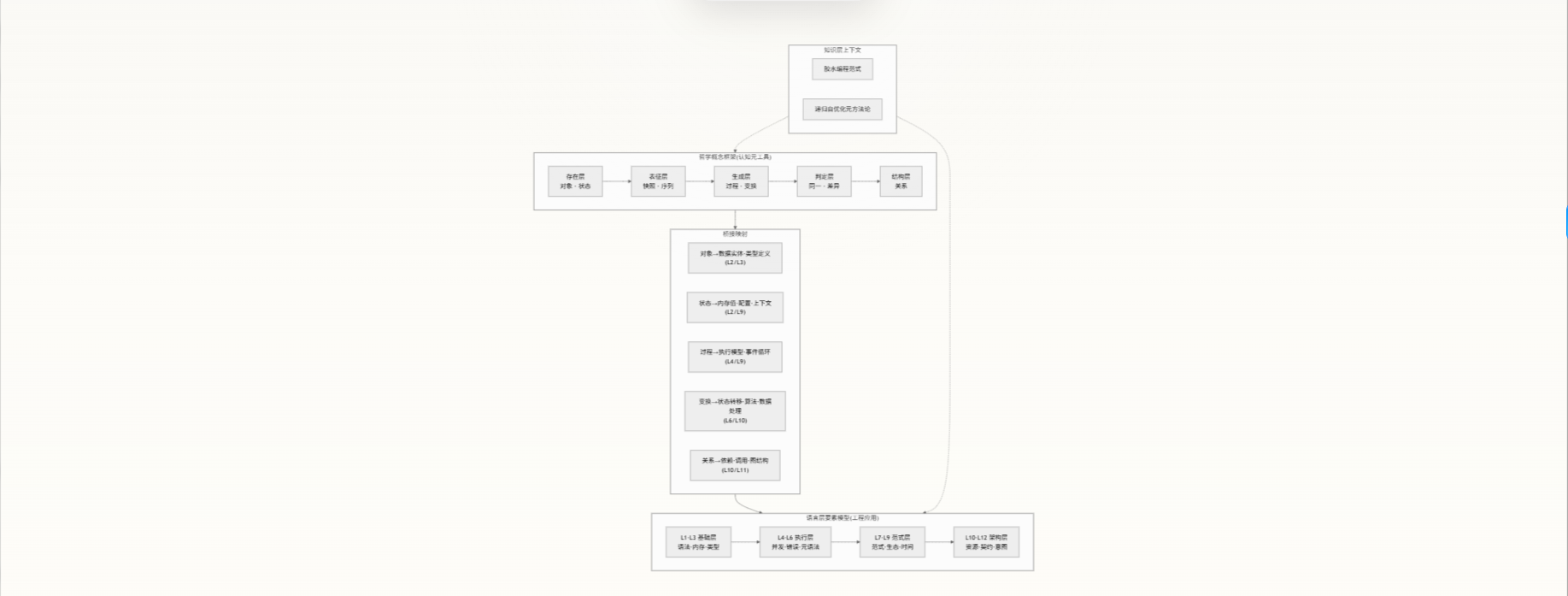
哲学概念框架:九个原生概念
本仓库哲学基础文件提出了一组跨学科的九个核心概念,它们组成了一条从静态存在走向动态生成的认知路径。
对象是我们用来指认、区分和讨论的基本单位——可以是一棵树、一个算法、一个数据结构。对象的关键不在于它是否“独立存在”,而在于它能否被识别为一个相对稳定的单位,总是与边界、识别、持续性绑定在一起。在计算机科学中,对象可以是数据实体、类实例、进程、节点。状态是对象在某个时刻的规定性总和,是对象“此时此地如何存在”的方式——没有状态,对象只是一个空名字。
快照是对状态进行一次静态截取,强调“截面”而非“流动”。数据库备份是系统快照,Git commit 是代码快照。快照天然带有选择性——它既是认知工具,也是一种简化。序列是多个快照按时间或逻辑规则排列的结果,当从“这一刻是什么”走向“前后发生了什么”时,快照就进入了序列。序列让分散的快照之间建立起可追踪的连续性。
过程是序列的动态整体——并非许多状态的简单排列,而是状态之间具有生成关系、演化方向和内在联系。种子发芽是过程,化学反应是过程,程序运行也是过程。变换是从一个状态到另一个状态的规则或机制,它回答“为什么会变、怎么变的”。在代码中,变换就是算法、状态转移函数、数据处理规则。
这三组概念形成一条主线的同时,被三个更深层概念所支撑:同一保证我们追踪的依然是“同一个对象”,差异保证变化和比较能够被识别,关系保证这些单位不是孤立的,而是在结构中获得意义。
五层统一模型
九个概念可以压缩为五层统一模型,适用于跨学科分析:
| 层次 | 包含概念 | 核心问题 | 代码中的映射 |
|---|---|---|---|
| 存在层 | 对象、状态 | 有什么?它此刻怎么存在? | 数据实体、类型定义、内存值 |
| 表征层 | 快照、序列 | 怎么记录?怎么组织记录? | Git commit、日志、事件溯源 |
| 生成层 | 过程、变换 | 怎么变化?机制是什么? | 执行流、状态机、算法 |
| 判定层 | 同一、差异 | 什么保持不变?什么变了? | 对象 ID、版本比较、diff |
| 结构层 | 关系 | 一切怎么被连成系统? | 依赖图、调用链、网络拓扑 |
💡:这五层统一模型直接对应 胶水编程范式 中的“实体—连接—功能”三元组:实体映射存在层,连接映射结构层(关系),功能映射生成层(过程与变换)。理解这个对应关系,就能在哲学思维和工程实践之间自由切换。
语言层要素模型:从看懂语法到透视意图
语言层要素模型将“看懂代码”的能力分解为 12 个层级,每个层级对应不同的认知能力和工程角色。下表是完整概览:
| 层级 | 名称 | 核心内容 | 决定你能不能… |
|---|---|---|---|
| L1 | 控制语法 | 变量、if/else、for/while、函数/return | 写出能跑的代码 |
| L2 | 内存模型 | 值 vs 引用、栈 vs 堆、可变/不可变 | 不写出隐式 bug |
| L3 | 类型系统 | 静态/动态类型、泛型、Option/Null | 不靠注释理解代码 |
| L4 | 执行模型 | 同步/异步、线程/协程、事件循环 | 不被 async/并发坑 |
| L5 | 错误模型 | 异常 vs 返回值、RAII、defer/finally | 不漏资源/不崩 |
| L6 | 元语法 | 宏、装饰器、注解、反射、代码生成 | 看懂“不像代码的代码” |
| L7 | 语言范式 | OOP、FP、过程式、声明式 | 理解不同风格 |
| L8 | 领域与生态 | SQL、正则、Shell、DSL、框架约定 | 看懂真实项目 |
| L9 | 时间维度模型 | 何时执行、多久、是否重复/延迟 | 控制性能与时序 |
| L10 | 资源模型 | CPU/IO/内存/网络调度 | 写出高性能系统 |
| L11 | 隐含契约 | 线程安全、可重入、允许阻塞/panic | 写出可上线代码 |
| L12 | 代码意图层 | 防误用、性能换可读性、扩展钩子 | 成为架构者 |
关键层级详解
L2 内存模型是语言间差异的根源。int *p = &a; 在 C 中操控地址,a = b 在 Python 中创建引用而非拷贝。不理解值与引用、栈与堆的区别,就会在不知不觉中写出隐式 bug。L4 执行模型是 99% 新手卡壳的地方:await fetch() 到底什么时候执行、谁在等谁、事件循环如何调度——这些不是语法问题,而是执行模型问题。
L6 元语法解释了大量“看起来不像代码的代码”。Python 的 @cache 装饰器在编译时改写了被装饰函数的代码,Rust 的宏在编译期生成代码——你需要知道它在改写什么,而不是把宏调用当作普通函数调用。L9 时间维度模型进一步要求你判断代码“在什么时候跑”——setTimeout(fn, 0) 并非立刻执行,而是当前调用栈清空之后;@lru_cache 则是一次计算多次复用。
💡L11 隐含契约是 99% 教程都不会写,但你在真实项目里天天踩雷的东西。比如 Go 的
http.HandleFunc("/", handler)隐藏了三条契约:handler 不能阻塞太久、可能被并发调用、不能 panic。识别隐含契约决定了你写出的代码是“能跑”还是“能上线”。
诊断卡点:你会在哪一层卡住?
当你面对陌生代码时,卡住的症状直接指向缺失的层级:
| 卡住表现 | 实际缺失的层级 | 典型场景 |
|---|---|---|
| “这行代码看不懂” | L2/L3(内存/类型) | C 指针、Rust 生命周期 |
| “为啥结果是这样” | L4(执行模型) | async/await 执行顺序 |
| “函数去哪了” | L6(元语法) | 装饰器/宏改写 |
| “风格完全不一样” | L7(范式) | FP 风格 vs OOP 风格 |
| “这不是编程吧” | L8(领域语法) | SQL、正则、DSL |
两套框架的桥接映射
哲学概念框架和语言层要素模型并非两套独立体系——它们可以在多个维度上建立精确的桥接关系。理解这些映射关系,是本仓库 -递归自优化元方法论---中“元认知”能力的核心体现。
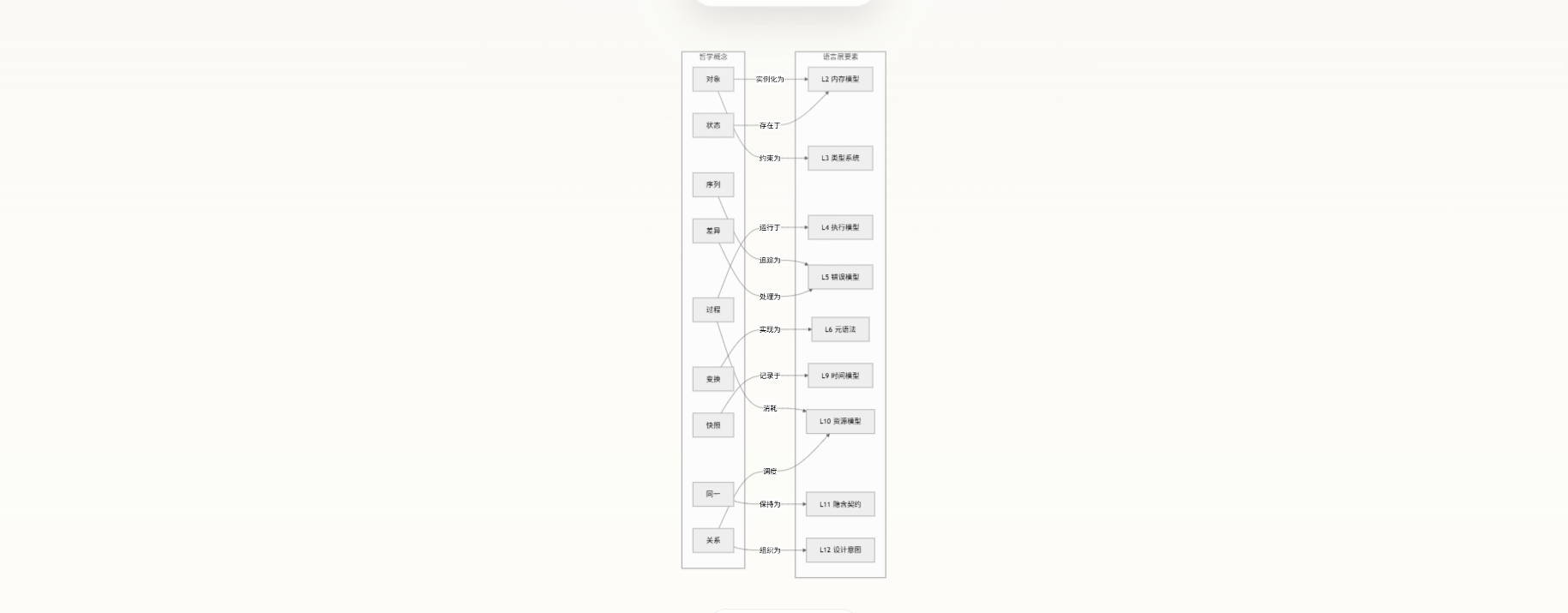
对象↔L2/L3:对象在代码中首先表现为数据实体(L2 内存模型:存在栈上还是堆上?是值还是引用?),然后被类型系统约束(L3:它的形状、能力边界是什么?)。过程↔L4/L10:过程是状态在时间中的展开,对应 L4 执行模型(同步还是异步?线程还是协程?)和 L10 资源模型(CPU 密集还是 IO 密集?数据在哪?)。变换↔L6:代码中的变换机制经常通过元语法实现——宏、装饰器、代码生成器都是在编译时或运行时执行“从 A 到 B”的变换规则。
同一↔L11:隐含契约本质上就是关于“同一性”的工程承诺——函数是否可重入?是否线程安全?是否允许重复调用?这些都是在问“在什么条件下,多次调用仍然是‘同一个操作’”。关系↔L12:设计意图层的核心能力是识别对象之间的关系网络——模块依赖、数据流向、抽象层次——这直接映射到哲学概念中的“关系”。
实战演练:用统一框架“剥洋葱”
以一段典型的 FastAPI 路由代码为例,演示如何同时运用两套框架逐层分析:
@app.get("/users/{user_id}")
async def get_user(user_id: int, db: Session = Depends(get_db)):
user = await db.execute(select(User).where(User.id == user_id))
if not user:
raise HTTPException(status_code=404)
return user| 分析维度 | 哲学概念 | 语言层级 | 你要看到什么 |
|---|---|---|---|
| 存在识别 | 对象、状态 | L1, L2, L3 | 函数定义、if/return;user 是引用,db 是共享连接;user_id: int 类型约束 |
| 执行路径 | 过程、变换 | L4, L6, L9 | async/await 非阻塞不占线程;@app.get 装饰器注册路由,Depends 依赖注入;每请求独立协程 |
| 防御设计 | 同一、差异 | L5, L11 | HTTPException 中断请求由框架捕获;db 必须线程安全,不能跨请求共享状态 |
| 架构意图 | 关系 | L7, L8, L12 | 声明式路由、SQLAlchemy ORM;作者用类型+DI 强制规范,防止裸 SQL 和硬编码 |
这段 6 行代码涵盖了 L1 到 L12 中的至少 9 个层级。真正的“语言高手”并非某语言语法背得多,而是同一段代码,他比别人多看 6 层含义。
从框架到能力的进阶路径
四阶段训练体系
语言层要素模型将能力提升组织为四个阶段,与哲学框架的五层模型存在自然对应:
| 阶段 | 语言层级 | 对应哲学层次 | 核心方法 | 典型练习 |
|---|---|---|---|---|
| 基础层 | L1-L3 | 存在层 | 刷题 + 类型体操 | LeetCode 100 题、TS 类型体操、Rust 生命周期 |
| 执行层 | L4-L6 | 生成层 | 读异步框架源码 | 手写 Promise、读 asyncio 源码、写装饰器库 |
| 范式层 | L7-L9 | 表征层 | 跨语言重写同一项目 | Python/Go/Rust 实现同一 CLI,对比性能与代码量 |
| 架构层 | L10-L12 | 判定层 + 结构层 | 参与开源 Code Review | 给知名项目提 PR、读 RFC/设计文档 |
自检清单:你到了哪一层?
当你看到一段陌生代码时,问自己四个问题:
- 我知道它的数据在哪吗?(L2 内存模型 / L10 资源模型)——在内存、磁盘还是网络上?是拷贝还是共享?
- 我知道它什么时候执行吗?(L4 执行模型 / L9 时间模型)——同步还是异步?是否延迟?会跑多久?
- 我知道失败会发生什么吗?(L5 错误模型 / L11 隐含契约)——资源是否泄漏?是否线程安全?允许 panic 吗?
- 我知道作者在防什么吗?(L12 设计意图)——是在防 bug?防误用?性能换可读性?为扩展留钩子?
四个全 YES = 真·100% 看懂。 目标并非“学完 12 层”,而是“遇到问题知道卡在哪一层”。
常见语言层级对照
不同编程语言在各层级上的差异,直接决定了它们适合的问题域。以下对照表可作为快速参考:
| 层级 | Python | Rust | Go | JavaScript |
|---|---|---|---|---|
| L2 内存 | 引用为主,GC | 所有权+借用 | 值/指针,GC | 引用为主,GC |
| L3 类型 | 动态,type hints | 静态,强类型 | 静态,简洁 | 动态,TS 可选 |
| L4 执行 | asyncio / GIL | tokio / async | goroutine / channel | event loop |
| L5 错误 | try/except | Result/Option | error 返回值 | try/catch/Promise |
| L6 元语法 | 装饰器/metaclass | 宏 | go generate | Proxy/Reflect |
| L9 时间 | GIL 限制并行 | 零成本异步 | 抢占式调度 | 单线程事件循环 |
| L10 资源 | CPU 受限于 GIL | 零开销抽象 | 轻量 goroutine | IO 密集友好 |
概念框架与 Vibe Coding 的关系
套统一框架并非纯学术抽象,它直接服务于本仓库的工程方法论。
与胶水编程的关系:胶水编程的“实体—连接—功能”三元组,分别映射哲学框架的对象(实体)、关系(连接)和过程/变换(功能)。当你用胶水编程范式连接成熟模块时,实际上是在用关系层(L12)组织存在层(L2/L3)的实体,通过元语法层(L6)实现生成层的过程与变换。
与递归自优化的关系:本仓库的形式化论文定义了一个递归算子 Φ: G → G,其中生成器 G 不断通过生成→优化→更新循环逼近不动点 G*。这个不动点 G* 的本质就是同一性在变换中的保持——生成器在变化中仍然是“同一个生成器”,其输出已经编码了自我改进所需的标准。这正是哲学框架中“同一”概念在计算理论中的精确实现。
与现象学还原的关系:本仓库的 哲学方法论工具箱 提供了“现象学还原”方法——悬置假设、回到可观察事实。这与概念框架中的“快照”概念直接对应:把连续变化暂时冻结,先记录“这一刻就是这样”,再分析“它怎么变成这样”。当你面对模糊需求时,先用现象学还原产出 MRE(最小可复现体),本质上就是在做“快照截取”和“状态记录”。
推荐阅读与延伸
概念框架和语言层要素模型作为知识层的方法论基础,与知识层其他文档构成递进关系:
- 胶水编程范式:将概念框架的“对象—关系—变换”映射为工程实践中的“实体—连接—功能”三元组
- 递归自优化元方法论:形式化定义了生成器的递归自修改过程,用数学语言精确表达了哲学框架中的“变换”与“同一”
- 提示词库与云端表格:用概念框架的九个概念组织提示词,让 AI 指令具备跨层级穿透力
如果你想深入哲学基础本身,建议直接阅读源文件 理解世界、描述变化、整理知识的一套较小框架.md 和 控制论与科学方法论.md,它们分别从本体论和控制论角度为本文的统一框架提供了更深层的理论支撑。
下一章:提示词库与云端表格

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)