Dockers容器化环境构建在大模型推理测试下的应用
摘要以及相关背景
当前人工智能浪潮下,增加了大量的大模型推理性能测试需求,相比于物理环境直接搭建,多人复用相同环境的情况下,在容器内部署大模型(LLM)推理测试,相比传统部署方式,其核心优势在于能够构建一个高度一致、隔离、可复现且易于扩展的标准化环境。这对于解决大模型部署中常见的依赖冲突、资源管理复杂和环境不一致等问题至关重要。其具有的五大优势:一:环境一致性与可复现性。二:依赖封装与快速部署。三:资源隔离与高效利用。四:弹性伸缩与高可用性。五:安全与隔离。本文主要以小模型为例,讲解从头搭建容器化模型推理测试环境。
相关架构工具及部署讲解
一:Dockers原理讲解:
技术本质:轻量级的“虚拟化”
从技术层面讲,Docker 是一种操作系统层级的虚拟化技术。
很多人会把它和“虚拟机”混淆,但它们的本质区别很大:
|
特性 |
传统虚拟机 |
Docker 容器 |
|
比喻 |
盖一栋新房子 |
在现有房子里打个隔断 |
|
原理 |
模拟硬件,每个虚拟机都要装一个完整的操作系统(Guest OS)。 |
共享宿主机的内核,只虚拟化应用层,不需要额外的操作系统。 |
|
体积 |
很大(GB 级),笨重。 |
很小(MB 级),轻量。 |
|
启动 |
慢(分钟级)。 |
快(秒级)。 |
Docker 的生命周期围绕着三个核心概念:镜像、容器、仓库。
1. 打包环境(镜像 Image)
Docker 允许你将应用打包成一个镜像。镜像是只读的模板,就像是一个安装包的“光盘”。它里面包含了应用运行所需的一切(比如 Python 环境 + 代码 + 配置文件)。
2. 运行应用(容器 Container)
容器是镜像运行时的实体。你可以把镜像理解为一个“类”,而容器就是这个类“实例化”出来的对象。Docker 负责启动这个容器,让应用跑起来,并确保它和外面的环境是隔离的。
3. 分发与共享(仓库 Registry)
做好了镜像,你可以把它上传到仓库(比如 Docker Hub)。其他的服务器或同事只需要从仓库下载这个镜像,就能立刻运行起和你一模一样的环境。(这里涉及的是镜像仓构建)
补充说明:在实际使用中,遇到相关同事提出会产生性能损耗产生输出结果不准确问题,这其实是不需要担心的,在实际应用过程中,2u服务器(768GB)服务器为例,docker所占性能损耗量化后实际只占用3%,这在大多数情况下是不被testcase的baseline感知的。
|
性能维度 |
典型损耗范围 |
损耗来源与说明 |
|
CPU |
< 1% ~ 3% |
容器直接共享宿主机内核,CPU 调度由宿主机管理,性能接近原生。损耗主要来自极少量的调度开销。 |
|
内存 |
接近 0% |
容器内存即为宿主机内存,没有额外的转换层,访问性能与原生一致。 |
|
磁盘 I/O |
5% ~ 15% |
损耗主要来自容器的分层文件系统(如 overlay2)。在大量小文件读写或随机写入时,会因“写时复制”(Copy-on-Write)机制产生额外开销,存储越大开销越小。 |
|
网络 |
1% ~ 5% |
默认的桥接(Bridge)网络模式需要经过虚拟网卡、网桥和 NAT 转换,会引入少量延迟和吞吐量下降。 |
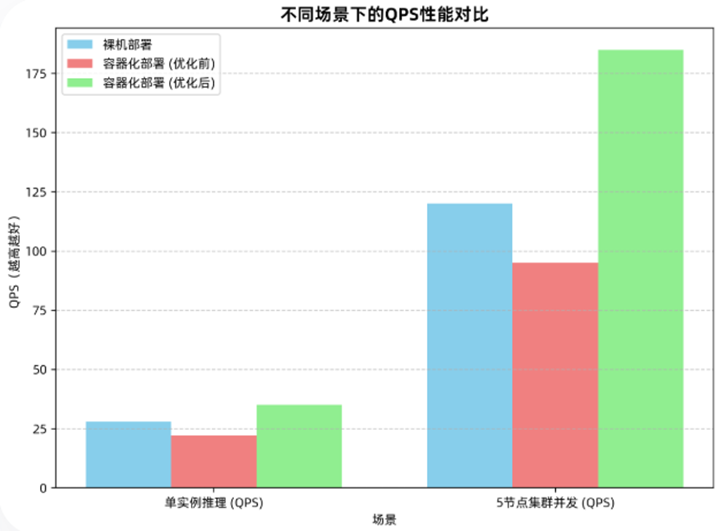
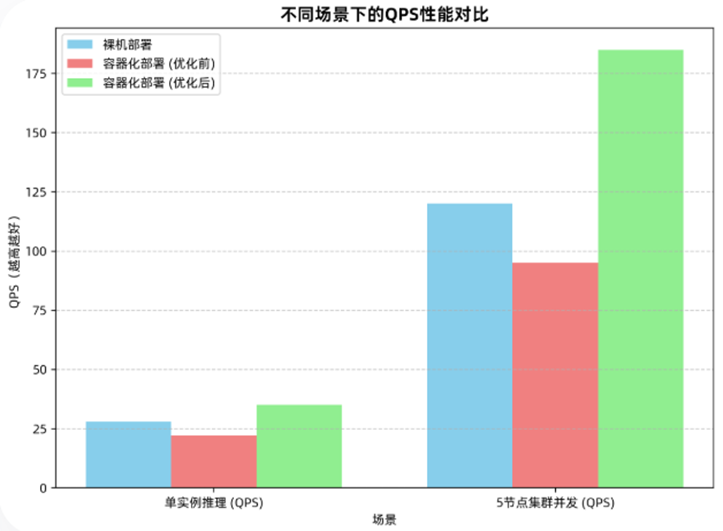
二:docker内模型部署全流程讲解
一:代码与模型准备拉取
大家有时候拉不到huggingface 我们就以清华源为例,公司内应该是可以直连的。
安装docker (如环境上有 先卸载)
sudo yum remove -y docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
安装 yum
sudo yum install -y yum-utils
如有则显示:

添加阿里云镜像源
sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo

安装docker核心组件
sudo yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
设置为开机自启
# 启动 Docker
sudo systemctl start docker
输入docker 验证是否成功
# 设置开机自动启动
sudo systemctl enable docker
配置优化(可选)
Vim /etc/docker/daemon.json(如果没有则创建)
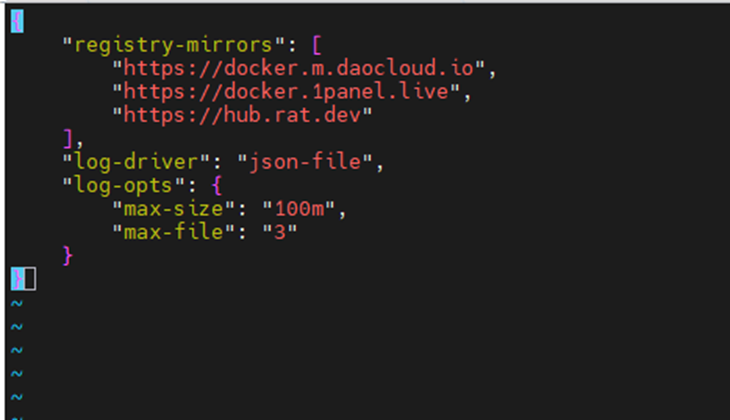
配置如上
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://docker.1panel.live",
"https://hub.rat.dev"
],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m",
"max-file": "3"
}
}
EOF
重启服务

sudo systemctl daemon-reload
sudo systemctl restart docker
验证与鉴权

免 Sudo 权限设置(推荐)
# 将当前用户加入 docker 组
sudo usermod -aG docker $USER
# 激活组权限(或者你可以直接退出重连 SSH)
newgrp docker
二:Dockerfile编写
Dockerfilr原理讲解
本质是给你的隔离空间写一套环境定义,和你物理环境上的版本做了隔离
假设你的服务器上正在运行一个老项目,它依赖 Python 3.6 和 Pandas 1.0。
现在你想用 Docker 部署一个新项目,它需要 Python 3.9 和 Pandas 2.0。
如果 Docker 调用你的环境:
你必须升级服务器的 Python 到 3.9。
结果:老项目崩了,因为它不兼容新版本。
或者你必须小心翼翼地配置虚拟环境(venv/conda),一旦配置出错,两个项目互相打架。
Docker 的做法:
Dockerfile 里写 FROM python:3.6,老项目镜像里就是 3.6。
Dockerfile 里写 FROM python:3.9,新项目镜像里就是 3.9。
结果:两者互不干扰,并行运行,井水不犯河水。
场景:你在 CentOS 7 上开发,服务器是 Ubuntu 20.04。
如果 Docker 调用环境:
你在 CentOS 上装好了 gcc 和 openssl,代码能跑。
你把代码发到 Ubuntu 服务器上,Docker 尝试调用服务器的 Python,结果报错:找不到头文件 或 动态库版本不匹配。
你需要花一下午时间去排查两个系统的环境差异。
Docker 的做法:
Dockerfile 里明确写了 RUN apt-get install libssl-dev。
无论你在 Windows、Mac 还是 CentOS 上构建,生成的镜像里永远包含那个特定的 libssl 库。
结果:镜像在哪台服务器上跑,表现都完全一样。
在根目录下构建dockerfile文件(通用docker版本)
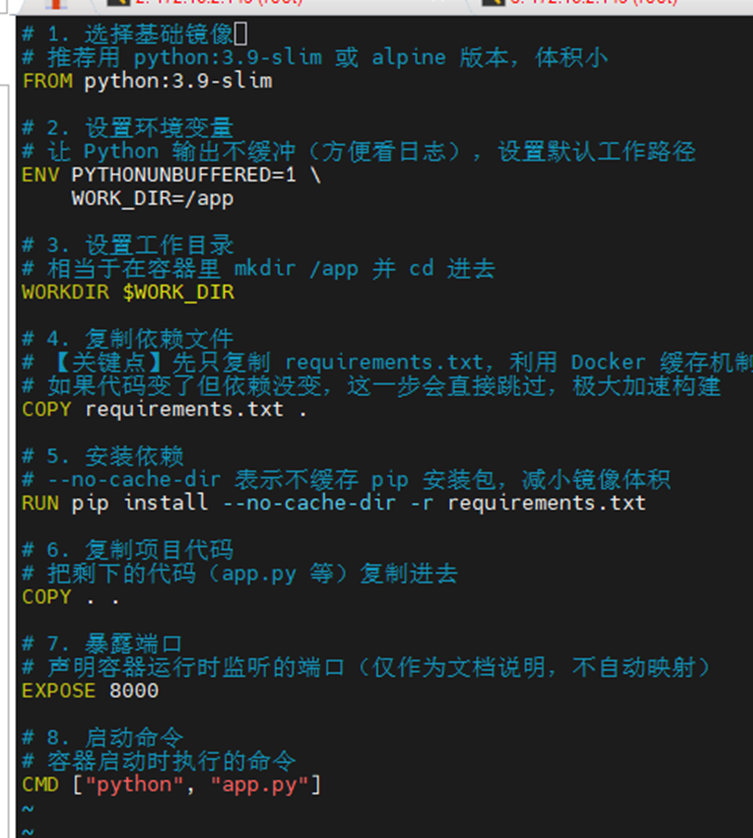
# 1. 选择基础镜像
# 推荐用 python:3.9-slim 或 alpine 版本,体积小
FROM python:3.9-slim
# 2. 设置环境变量
# 让 Python 输出不缓冲(方便看日志),设置默认工作路径
ENV PYTHONUNBUFFERED=1 \
WORK_DIR=/app
# 3. 设置工作目录
# 相当于在容器里 mkdir /app 并 cd 进去
WORKDIR $WORK_DIR
# 4. 复制依赖文件
# 【关键点】先只复制 requirements.txt,利用 Docker 缓存机制
# 如果代码变了但依赖没变,这一步会直接跳过,极大加速构建
COPY requirements.txt .
# 5. 安装依赖
# --no-cache-dir 表示不缓存 pip 安装包,减小镜像体积
RUN pip install --no-cache-dir -r requirements.txt
# 6. 复制项目代码
# 把剩下的代码(app.py 等)复制进去
COPY . .
# 7. 暴露端口
# 声明容器运行时监听的端口(仅作为文档说明,不自动映射)
EXPOSE 8000
# 8. 启动命令
# 容器启动时执行的命令
CMD ["python", "app.py"]
如存在多个版本迭代替换
对应的文件格式应该为
/my-projects/
├── project-a/ # 项目 A (Python 3.8)
│ ├── Dockerfile # 里面写 FROM python:3.8
│ ├── app.py
│ └── requirements.txt
│
└── project-b/ # 项目 B (Python 3.11)
├── Dockerfile # 里面写 FROM python:3.11
├── app.py
└── requirements.txt
三:构建镜像与拉取模型
构建镜像 (Build)有两种(拉取现有镜像/构建环境生成镜像)
构建环境生成镜像
目录下执行 构建版本
docker build -t my-model-app:v1 .

# -p 8000:8000 把容器的 8000 端口映射到宿主机的 8000
# --name my-app 给容器起个名字
docker run -d -p 8000:8000 --name my-app my-model-app:v1


这里经常会遇到超时失败的问题,具体解决方式可以改用清华源


此处根据选择自主构建requiremets.txt
二:从云端或者环境上拉取以qwen为例
https://www.modelscope.cn/models/LLM-Research/
容器内模型选择拉取
创建容器:
docker run -d \
--name qwen3-0.6b \
--gpus all \
-p 8000:8000 \
-v $(pwd)/models:/models \
--ipc=host \
registry.cn-hangzhou.aliyuncs.com/qwen/qwen3-0.6b:latest(镜像仓可变动为私有仓)
进入容器:
四:运行容器以及相关测试
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen3-0.6B",
"messages": [
{"role": "user", "content": "请写一篇关于人工智能发展的500字短文。"}
],
"stream": true,
"stream_options": {
"include_usage": true
}
}'
们在请求中加入 stream_options 来获取详细的 Token 统计。
方法二:使用 Python 脚本进行专业压测
如果你需要量化数据(如计算具体的 tokens/s),可以使用 Python 脚本。这个脚本会记录从发送请求到接收完毕的全过程时间。
import time
import requests
import json
# 配置地址
url = "http://localhost:8000/v1/chat/completions"
headers = {"Content-Type": "application/json"}
payload = {
"model": "Qwen/Qwen3-0.6B",
"messages": [{"role": "user", "content": "计算 1+1 等于几,并解释原因。"}],
"max_tokens": 100,
"temperature": 0
}
print("🚀 开始发送请求...")
start_time = time.time()
response = requests.post(url, headers=headers, json=payload)
end_time = time.time()
total_latency = (end_time - start_time) * 1000 # 毫秒
if response.status_code == 200:
data = response.json()
usage = data.get("usage", {})
completion_tokens = usage.get("completion_tokens", 0)
# 计算生成速度
duration = end_time - start_time
tokens_per_second = completion_tokens / duration if duration > 0 else 0
print(f" 推理完成!")
print(f" 总耗时: {total_latency:.2f} ms")
print(f" 生成 Token 数: {completion_tokens}")
print(f" 生成速度: {tokens_per_second:.2f} tokens/s")
print(f" 回复内容: {data['choices'][0]['message']['content']}")
else:
print(f" 请求失败: {response.text}")
至此全流程完成

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)