【SpringBoot 3.x 第179节】GraphQL 安全——查询复杂度、深度限制与权限模型,一文带你搞定!

🏆本文收录于《滚雪球学SpringBoot 3.x》,专门攻坚指数提升,本年度国内最系统+最专业+最详细(永久更新)。
该专栏致力打造最硬核 SpringBoot3 从零基础到进阶系列学习内容,🚀均为全网独家首发,打造精品专栏,专栏持续更新中…欢迎大家订阅持续学习。 如果想快速定位学习,可以看这篇【SpringBoot3教程导航帖】,你想学习的都被收集在内,快速投入学习!!两不误。
若还想学习更多,可直接订阅 《Spring Boot实战合集》,一次订阅,持续学习,后续更新内容无需重复付费,适合长期收藏与系统进阶。
演示环境说明:
- 开发工具:IDEA 2021.3
- JDK版本: JDK 17(推荐使用 JDK 17 或更高版本,因为 Spring Boot 3.x 系列要求 Java 17,Spring Boot 3.5.4 基于 Spring Framework 6.x 和 Jakarta EE 9,它们都要求至少 JDK 17。)
- Spring Boot版本:3.5.4(于25年7月24日发布)
- Maven版本:3.8.2 (或更高)
- Gradle:(如果使用 Gradle 构建工具的话):推荐使用 Gradle 7.5 或更高版本,确保与 JDK 17 兼容。
- 操作系统:Windows 11
全文目录:
-
- 一、为什么 GraphQL 更容易被“合法打爆”?
- 二、先搭一个能跑的 Spring Boot 3.x GraphQL 示例
- 三、Query Depth:为什么“查询太深”会拖垮服务?
- 四、Query Cost:为什么“字段不深”也可能很贵
- 五、字段级权限控制:把安全下沉到字段而不是接口
- 六、防止滥用 introspection:让生产环境更克制
- 七、一套更完整的 GraphQL 安全组合拳
- 八、从请求到响应:完整链路的安全模型图
- 九、常见坑位与排障思路
- 十、建议你直接落地的生产实践清单
- 十一、如果把本文做成一个最小可运行项目,建议的文件结构如下
- 十二、启动与验证思路
- 十三、把今天的知识点再收一遍
- 十四、总结
- 附:本文案例查询示例
- 🧧 学习福利 · 限时开放 🧧
- 🫵 Who am I?
一、为什么 GraphQL 更容易被“合法打爆”?
GraphQL 的核心价值,是让客户端“按需取数”。你只拿想要的字段,不再为冗余数据支付网络和解析成本。这种灵活性非常适合移动端、多端统一、前后端协作频繁的场景。问题也恰恰出在这里:灵活性越强,越容易被滥用。
在传统 REST 接口里,接口边界比较清晰。比如 /users/1 就是一个用户详情,服务端通常只会返回一层对象。即使攻击者持续请求,它的单次成本也相对可控。
而 GraphQL 的成本不是“一个接口一次固定开销”,而是“一个查询可能触发很多层数据展开”。用户表面上只发起了一个合法的 /graphql 请求,实际上可能同时触发:
- 多次数据库查询;
- 多个 service 之间的链式调用;
- 大量对象装配与序列化;
- 深层嵌套字段的重复展开;
- introspection 带来的 schema 暴露与自动化探测。
这就带来一个很现实的问题:攻击者不一定需要发非法请求,只要把查询写得“足够聪明”,就能把系统合法压垮。
举个例子,下面这段查询看起来完全正常,语法也合法,没有任何“攻击”痕迹:
query DeepUsers {
users(page: 0, size: 10) {
id
username
posts(first: 10) {
id
title
comments(first: 10) {
id
content
author {
id
username
posts(first: 5) {
id
title
}
}
}
}
}
}
它的问题不是“非法”,而是“太贵”。
如果你的数据访问层没有做批量加载、没有做深度限制、没有做复杂度控制、没有做字段级鉴权,那么一条查询就可能把 CPU、数据库连接、缓存命中率、序列化时间一起拉爆。
可以把 GraphQL 想成一把刀。刀本身并不坏,但如果没有刀鞘、没有使用规范、没有权限边界,它就会变成危险工具。GraphQL 安全治理的重点,不是“禁止 GraphQL”,而是给 GraphQL 建立可量化、可验证、可审计的安全边界。
二、先搭一个能跑的 Spring Boot 3.x GraphQL 示例
为了把后面的安全机制讲清楚,我们先搭一个最小但完整的示例应用。这里故意不引入过重的基础设施,先用内存数据模拟用户、文章、评论,重点放在 GraphQL 请求、深度限制、复杂度控制和权限控制上。
2.1 项目依赖
下面是一个典型的 pom.xml 依赖片段。你可以直接把它作为新项目的起点。
<dependencies>
<!-- Web 与基础启动器 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- GraphQL 支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-graphql</artifactId>
</dependency>
<!-- 安全控制 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
<!-- 参数校验 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>
<!-- 用于演示数据层;实际项目可替换为数据库 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
如果你希望把示例扩展成真实项目,也可以继续加入 spring-boot-starter-data-jpa、H2、MySQL 或 PostgreSQL。本文先把重点放在 GraphQL 的安全治理逻辑上。
2.2 schema 设计
GraphQL 的安全,很大程度上从 schema 设计阶段就已经开始了。字段怎么命名、关系怎么展开、分页参数怎么定义,都会影响后续复杂度和权限控制。
下面是一个简化版 schema:
type Query {
user(id: ID!): User
users(page: Int = 0, size: Int = 20): [User!]!
post(id: ID!): Post
posts(page: Int = 0, size: Int = 20): [Post!]!
}
type User {
id: ID!
username: String!
email: String!
roles: [String!]!
posts(first: Int = 10): [Post!]!
}
type Post {
id: ID!
title: String!
content: String!
author: User!
comments(first: Int = 10): [Comment!]!
}
type Comment {
id: ID!
content: String!
author: User!
}
这个 schema 有两个优点:
第一,关系清晰。User -> Post -> Comment -> User 这样的链路非常适合演示深度问题。
第二,字段本身就暗含安全策略。比如 email 明显比 username 更敏感,roles 也可能是管理端字段。后面我们会把这些字段做成字段级权限控制的例子。
2.3 领域模型
我们先用 Java 记录类来表达数据模型,简单、清晰、适合教学。
package com.example.graphqlsecurity.domain;
import java.util.List;
public record User(
Long id,
String username,
String email,
List<String> roles
) {}
package com.example.graphqlsecurity.domain;
public record Post(
Long id,
String title,
String content,
Long authorId
) {}
package com.example.graphqlsecurity.domain;
public record Comment(
Long id,
String content,
Long authorId,
Long postId
) {}
2.4 内存数据服务
下面这个服务负责模拟数据读取。虽然它不是真实数据库,但结构和真实项目很接近,足够支撑后续的安全案例。
package com.example.graphqlsecurity.service;
import com.example.graphqlsecurity.domain.Comment;
import com.example.graphqlsecurity.domain.Post;
import com.example.graphqlsecurity.domain.User;
import jakarta.annotation.PostConstruct;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
@Service
public class DemoDataService {
private final Map<Long, User> users = new LinkedHashMap<>();
private final Map<Long, Post> posts = new LinkedHashMap<>();
private final Map<Long, Comment> comments = new LinkedHashMap<>();
@PostConstruct
public void init() {
users.put(1L, new User(1L, "alice", "alice@example.com", List.of("USER")));
users.put(2L, new User(2L, "bob", "bob@example.com", List.of("USER")));
users.put(3L, new User(3L, "admin", "admin@example.com", List.of("ADMIN", "USER")));
posts.put(1L, new Post(1L, "Spring Boot 3 入门", "内容 A", 1L));
posts.put(2L, new Post(2L, "GraphQL 安全实践", "内容 B", 1L));
posts.put(3L, new Post(3L, "Java 21 与 Spring", "内容 C", 2L));
posts.put(4L, new Post(4L, "管理后台设计", "内容 D", 3L));
comments.put(1L, new Comment(1L, "写得不错", 2L, 1L));
comments.put(2L, new Comment(2L, "受益匪浅", 3L, 1L));
comments.put(3L, new Comment(3L, "希望更新深度限制案例", 1L, 2L));
comments.put(4L, new Comment(4L, "这个版本我也在用", 1L, 3L));
}
public User findUserById(Long id) {
return users.get(id);
}
public List<User> findUsers(int page, int size) {
return users.values().stream()
.skip((long) page * size)
.limit(size)
.toList();
}
public Post findPostById(Long id) {
return posts.get(id);
}
public List<Post> findPosts(int page, int size) {
return posts.values().stream()
.skip((long) page * size)
.limit(size)
.toList();
}
public List<Post> findPostsByAuthorId(Long authorId, int first) {
return posts.values().stream()
.filter(post -> post.authorId().equals(authorId))
.limit(first)
.toList();
}
public List<Comment> findCommentsByPostId(Long postId, int first) {
return comments.values().stream()
.filter(comment -> comment.postId().equals(postId))
.limit(first)
.toList();
}
public User findUserByIdFromAuthor(Long authorId) {
return users.get(authorId);
}
public List<User> allUsers() {
return new ArrayList<>(users.values());
}
public Map<Long, User> userMap() {
return users;
}
public Map<Long, Post> postMap() {
return posts;
}
public Map<Long, Comment> commentMap() {
return comments;
}
}
2.5 GraphQL Controller
Spring for GraphQL 提供了注解式编程模型。你可以把 Query 和字段解析写成普通的 Spring Bean 方法。对于初学者而言,这比手写很多 DataFetcher 更容易上手。
package com.example.graphqlsecurity.controller;
import com.example.graphqlsecurity.domain.Comment;
import com.example.graphqlsecurity.domain.Post;
import com.example.graphqlsecurity.domain.User;
import com.example.graphqlsecurity.service.DemoDataService;
import org.springframework.graphql.data.method.annotation.Argument;
import org.springframework.graphql.data.method.annotation.QueryMapping;
import org.springframework.graphql.data.method.annotation.SchemaMapping;
import org.springframework.stereotype.Controller;
import org.springframework.security.access.prepost.PreAuthorize;
import java.util.List;
@Controller
public class GraphqlQueryController {
private final DemoDataService demoDataService;
public GraphqlQueryController(DemoDataService demoDataService) {
this.demoDataService = demoDataService;
}
@QueryMapping
public User user(@Argument Long id) {
return demoDataService.findUserById(id);
}
@QueryMapping
public List<User> users(@Argument(defaultValue = "0") int page,
@Argument(defaultValue = "20") int size) {
return demoDataService.findUsers(page, size);
}
@QueryMapping
public Post post(@Argument Long id) {
return demoDataService.findPostById(id);
}
@QueryMapping
public List<Post> posts(@Argument(defaultValue = "0") int page,
@Argument(defaultValue = "20") int size) {
return demoDataService.findPosts(page, size);
}
@SchemaMapping(typeName = "User", field = "posts")
@PreAuthorize("hasAuthority('post:read')")
public List<Post> posts(User user, @Argument(defaultValue = "10") int first) {
return demoDataService.findPostsByAuthorId(user.id(), first);
}
@SchemaMapping(typeName = "Post", field = "author")
@PreAuthorize("hasAuthority('user:read')")
public User author(Post post) {
return demoDataService.findUserByIdFromAuthor(post.authorId());
}
@SchemaMapping(typeName = "Post", field = "comments")
@PreAuthorize("hasAuthority('comment:read')")
public List<Comment> comments(Post post, @Argument(defaultValue = "10") int first) {
return demoDataService.findCommentsByPostId(post.id(), first);
}
@SchemaMapping(typeName = "Comment", field = "author")
@PreAuthorize("hasAuthority('user:read')")
public User commentAuthor(Comment comment) {
return demoDataService.findUserByIdFromAuthor(comment.authorId());
}
@SchemaMapping(typeName = "User", field = "email")
@PreAuthorize("hasAuthority('user:read:sensitive')")
public String email(User user) {
return user.email();
}
@SchemaMapping(typeName = "User", field = "roles")
@PreAuthorize("hasRole('ADMIN')")
public List<String> roles(User user) {
return user.roles();
}
}
这段代码有一个非常重要的设计思想:敏感字段不要直接靠默认属性映射裸奔。而是显式写出 @SchemaMapping,这样就能把权限检查放进字段解析环节。后面你会看到,GraphQL 的字段级权限控制,恰恰应该落在这个位置。
2.6 application.yml
spring:
graphql:
path: /graphql
graphiql:
enabled: true
main:
allow-bean-definition-overriding: false
logging:
level:
org.springframework.graphql: INFO
graphql: INFO
如果你在开发环境里开启了 GraphiQL,调试查询会非常方便。到了生产环境,建议关闭或至少加上强认证和访问控制。
三、Query Depth:为什么“查询太深”会拖垮服务?
3.1 深度限制到底在防什么
深度限制防的是“树太深”。GraphQL 查询本质上是一棵树,字段继续展开就会形成更深的层级。层级越深,往往意味着:
- 更多的对象装配;
- 更长的执行链路;
- 更多的下游调用;
- 更高的 N+1 风险;
- 更难预测的执行时间。
深度限制不是为了限制“业务功能”,而是为了给执行成本设一道上限。你可以把它理解成 GraphQL 的“安全栅栏”。
3.2 查询树长什么样
下面用 Mermaid 画一个典型查询的结构图。这个图很适合让读者直观看出“合法查询”是怎么一步一步展开成高开销请求的。
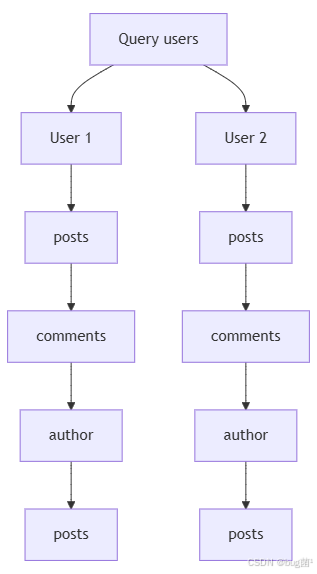
从表面看,这只是一条查询;从执行角度看,它可能触发多轮数据访问。尤其当每一层都在做数据库查询时,问题会被迅速放大。
3.3 Spring Boot 3.x 中如何限制深度?
GraphQL Java 已经提供了成熟的深度限制工具。我们可以通过 MaxQueryDepthInstrumentation 来控制查询最大深度。
下面是一个最简单且常用的配置方式:
package com.example.graphqlsecurity.config;
import graphql.analysis.MaxQueryDepthInstrumentation;
import graphql.execution.instrumentation.ChainedInstrumentation;
import graphql.execution.instrumentation.Instrumentation;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.graphql.execution.GraphQlSourceBuilderCustomizer;
import java.util.List;
@Configuration
public class GraphQlInstrumentationConfig {
@Bean
public Instrumentation maxQueryDepthInstrumentation() {
// 这里设置最大深度为 8 层,超过就直接拒绝执行
return new MaxQueryDepthInstrumentation(8);
}
@Bean
public GraphQlSourceBuilderCustomizer graphQlSourceBuilderCustomizer(List<Instrumentation> instrumentations) {
return builder -> builder.configureGraphQl(graphQlBuilder ->
graphQlBuilder.instrumentation(new ChainedInstrumentation(instrumentations)));
}
}
这段配置的含义非常直接:当查询深度超过 8 时,GraphQL 引擎不会继续执行,而是提前拦截。
3.4 为什么深度限制足够重要
很多初学者在做 GraphQL 时,会把注意力放在“字段查询写得很灵活”上,却忽略了深度带来的成本。实际上,深度限制是一个非常实用的第一道防线,因为它实现简单、收益明显、误伤率低。
尤其是以下场景,深度限制几乎是刚需:
- 用户、订单、评论、标签之间存在多级关联;
- 一个字段返回列表,列表元素又能展开子列表;
- 业务团队缺乏稳定的 schema 约束规范;
- 前端有时会临时拼接查询,容易不小心写出超深查询;
- 第三方集成方可能尝试“把所有字段一次拉完”。
3.5 真实项目里怎么定阈值
阈值不是拍脑袋定的,而是根据业务复杂度、下游承受能力和实际使用模式来决定。
通常建议的做法是:
- 开发环境可放宽;
- 测试环境贴近生产;
- 生产环境严格限制;
- 先通过日志观察,再逐步收紧。
如果你的系统主要是“单层查详情”,深度 8 甚至偏宽松;如果你的系统天然存在 4~5 层关联,深度 6~8 往往比较合理。
3.6 深度限制的边界
深度限制不是万能的。因为一个浅层查询也可能很贵。比如:
query HeavyUsers {
users(page: 0, size: 5000) {
id
username
email
}
}
这条查询深度很浅,但如果 size 允许非常大,仍然会对系统造成压力。所以深度限制必须和复杂度限制、分页上限、鉴权、限流一起使用。
四、Query Cost:为什么“字段不深”也可能很贵
4.1 深度和复杂度不是一回事
深度关注“层数”,复杂度关注“代价”。这两个概念必须区分开来。
一个查询可能只有 3 层,但每层都返回几千条数据,复杂度依然非常高。反过来,一个查询可能很深,但每层只拿几个字段,也许并不算太贵。
所以真正成熟的 GraphQL 安全治理,不能只看 depth,还要看 cost。
4.2 复杂度模型的基本思路
可以把复杂度看成一个简单的评分系统:
- 每个字段有基础成本;
- 列表字段根据返回数量放大成本;
- 某些特别贵的字段单独加权;
- 整个查询的总成本不能超过阈值。
例如:
user基础成本 1;posts因为是列表,成本 3;comments因为常常更大,成本 5;email这类敏感字段不一定成本高,但会受权限控制。
4.3 复杂度限制的配置
GraphQL Java 提供了 MaxQueryComplexityInstrumentation,我们可以直接使用它来限制查询复杂度。
package com.example.graphqlsecurity.config;
import graphql.analysis.MaxQueryComplexityInstrumentation;
import graphql.analysis.MaxQueryDepthInstrumentation;
import graphql.execution.instrumentation.ChainedInstrumentation;
import graphql.execution.instrumentation.Instrumentation;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.graphql.execution.GraphQlSourceBuilderCustomizer;
import java.util.List;
@Configuration
public class GraphQlCostConfig {
@Bean
public Instrumentation maxQueryDepthInstrumentation() {
return new MaxQueryDepthInstrumentation(8);
}
@Bean
public Instrumentation maxQueryComplexityInstrumentation() {
// 这里设置总复杂度上限为 120
return new MaxQueryComplexityInstrumentation(120);
}
@Bean
public GraphQlSourceBuilderCustomizer graphQlSourceBuilderCustomizer(List<Instrumentation> instrumentations) {
return builder -> builder.configureGraphQl(graphQlBuilder ->
graphQlBuilder.instrumentation(new ChainedInstrumentation(instrumentations)));
}
}
4.4 为什么复杂度阈值必须结合业务调整
复杂度阈值不是“越小越安全”。太小会导致正常用户也被拦,太大则失去意义。
设置阈值时,建议考虑下面几个维度:
- 典型查询路径:用户最常查询的接口是什么?
- 峰值访问场景:活动、定时任务、批量同步是否会让查询数暴涨?
- 列表上限:每个分页字段允许的最大
first/size是多少? - 下游资源:数据库、缓存、第三方接口哪个更脆弱?
- 业务分层:普通用户与管理员是否应有不同的复杂度阈值?
4.5 一个更贴近实战的思路:把“最大页大小”也当成成本控制
很多 GraphQL 事故并不是因为查询特别深,而是因为参数特别大。比如:
query BigPage {
posts(page: 0, size: 1000) {
id
title
content
}
}
这里的解决思路通常有两层:
- 业务层限制参数最大值,例如
size <= 50; - 复杂度层对列表字段加权,例如
size越大,成本越高。
这两个层面互不替代,而是相互补充。
4.6 为什么很多项目要再加一道“分页硬上限”
即便有 complexity 控制,也建议显式限制分页参数。因为复杂度模型是“整体评分”,而分页上限是“单点保护”。
下面给一个更实用的写法:
package com.example.graphqlsecurity.controller;
import org.springframework.graphql.data.method.annotation.Argument;
import org.springframework.graphql.data.method.annotation.QueryMapping;
import org.springframework.stereotype.Controller;
import java.util.List;
@Controller
public class SafePagingController {
@QueryMapping
public List<String> demoList(@Argument(defaultValue = "0") int page,
@Argument(defaultValue = "20") int size) {
int safeSize = Math.min(Math.max(size, 1), 50);
int safePage = Math.max(page, 0);
return List.of("page=" + safePage, "size=" + safeSize);
}
}
这里虽然只是示例,但思路很重要:不要把用户输入的分页参数原样交给查询层。
五、字段级权限控制:把安全下沉到字段而不是接口
5.1 为什么 GraphQL 的权限模型必须更细
REST 的权限控制,通常落在“接口”上。GraphQL 不一样。一个接口里既可能包含普通字段,也可能包含敏感字段,还可能同时返回不同权限层级的数据。
比如同一个 User:
- 普通用户可以看
id、username; - 登录用户可以看自己相关的
posts; - 管理员可以看
roles; - 高权限用户才可以看
email。
如果你只在 Query.user 上做一次权限检查,就会出现一个问题:查询主体合法,但其中某些字段不该被某些人看到。
所以 GraphQL 的正确姿势是:权限控制要尽量靠近字段解析点。
5.2 用 Spring Security 6 做方法级权限控制
Spring Boot 3.x 对应的是 Spring Security 6。你可以直接启用方法级权限,然后把 @PreAuthorize 放在 @QueryMapping 或 @SchemaMapping 上。
package com.example.graphqlsecurity.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.config.Customizer;
import org.springframework.security.config.annotation.method.configuration.EnableMethodSecurity;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.core.userdetails.User;
import org.springframework.security.core.userdetails.UserDetails;
import org.springframework.security.core.userdetails.UserDetailsService;
import org.springframework.security.provisioning.InMemoryUserDetailsManager;
import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;
import org.springframework.security.crypto.password.PasswordEncoder;
import org.springframework.security.web.SecurityFilterChain;
@Configuration
@EnableMethodSecurity
public class SecurityConfig {
@Bean
public SecurityFilterChain securityFilterChain(HttpSecurity http) throws Exception {
return http
.csrf(csrf -> csrf.disable())
.authorizeHttpRequests(auth -> auth
.requestMatchers("/graphiql").authenticated()
.requestMatchers("/graphql").authenticated()
.anyRequest().permitAll())
.httpBasic(Customizer.withDefaults())
.build();
}
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
@Bean
public UserDetailsService userDetailsService(PasswordEncoder passwordEncoder) {
UserDetails user = User.withUsername("user")
.password(passwordEncoder.encode("user123"))
.authorities("user:read", "post:read", "comment:read")
.build();
UserDetails admin = User.withUsername("admin")
.password(passwordEncoder.encode("admin123"))
.authorities("user:read", "user:read:sensitive", "post:read", "comment:read")
.roles("ADMIN")
.build();
return new InMemoryUserDetailsManager(user, admin);
}
}
5.3 字段级权限为什么比“接口级权限”更适合 GraphQL
接口级权限像大门,字段级权限像房间门。
大门可以决定“你能不能进入这栋楼”;房间门决定“你能不能进某个房间”。GraphQL 里同一个请求经常会穿过很多“房间”,所以只控制大门是不够的。
下面这张图可以很形象地表达这种关系。

5.4 把敏感字段显式写成 SchemaMapping
前面我们已经在 GraphqlQueryController 里给 email 和 roles 写了显式字段映射。这样做的意义不只是“代码好看”,而是为了让权限拦截点更清楚。
例如:
@SchemaMapping(typeName = "User", field = "email")
@PreAuthorize("hasAuthority('user:read:sensitive')")
public String email(User user) {
return user.email();
}
这种写法有几个优点:
- 语义明确:这个字段就是敏感字段;
- 审计清楚:谁能看邮箱一眼就能查到;
- 扩展容易:未来可以加入脱敏、分级授权、审计日志;
- 不依赖默认属性映射,避免“无意间暴露”。
5.5 不同角色看到不同字段的示例
假设普通用户执行:
query MyUser {
user(id: 1) {
id
username
email
roles
}
}
如果当前登录账号只有 user:read,那么:
id、username可能正常返回;email可能被AccessDeniedException拦截;roles可能因为缺少ADMIN角色而被拒绝。
这就是字段级权限的价值:同一个 schema,可以服务不同权限层级的人。
5.6 字段级鉴权的补充建议
字段级权限只是核心之一。为了更稳,建议同时做以下几件事:
- 对敏感字段做脱敏展示;
- 对高风险字段做访问审计;
- 对管理员字段做最小授权;
- 对跨租户数据做租户隔离;
- 对对象级权限做二次校验。
特别是“对象级权限”非常重要。比如用户能不能看某个订单,不只看他有没有 order:read,还要看这个订单是不是属于他的租户。
六、防止滥用 introspection:让生产环境更克制
6.1 introspection 为什么危险
GraphQL 的 introspection 本来是为了开发体验而设计的。它允许客户端查询 schema,自动发现类型、字段、参数和关系。对开发阶段来说,这几乎是神器;但对生产环境来说,它也意味着:
- 攻击者更容易摸清 schema;
- 自动化扫描更容易生成查询;
- 敏感字段、关系结构、分页参数暴露得更清楚;
- 攻击面更容易被系统化分析。
所以不少团队会在生产环境中关闭 introspection,或者至少限制只有内网、测试账号、运维账号才能使用。
6.2 禁用 introspection 的基本思路
常见做法有三种:
- 生产环境直接拒绝
__schema和__type; - 仅对高权限用户开放 introspection;
- 测试环境和生产环境使用不同配置。
本文建议你采用第 3 种,并把第 1 种作为生产兜底。
6.3 使用 WebGraphQlInterceptor 拦截 introspection
下面是一种可运行的实现方式:通过拦截请求文档,检查是否包含 introspection 字段,如果包含就直接拒绝。
package com.example.graphqlsecurity.security;
import graphql.language.Document;
import graphql.language.Field;
import graphql.language.FragmentDefinition;
import graphql.language.FragmentSpread;
import graphql.language.InlineFragment;
import graphql.language.OperationDefinition;
import graphql.language.Selection;
import graphql.language.SelectionSet;
import graphql.parser.Parser;
import org.springframework.context.annotation.Profile;
import org.springframework.graphql.server.WebGraphQlInterceptor;
import org.springframework.graphql.server.WebGraphQlRequest;
import org.springframework.graphql.server.WebGraphQlResponse;
import org.springframework.security.access.AccessDeniedException;
import org.springframework.stereotype.Component;
import reactor.core.publisher.Mono;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.function.Function;
import java.util.stream.Collectors;
@Component
@Profile("prod")
public class IntrospectionBlockerInterceptor implements WebGraphQlInterceptor {
@Override
public Mono<WebGraphQlResponse> intercept(WebGraphQlRequest request, Chain chain) {
String document = request.getDocument();
if (document != null && containsIntrospection(document)) {
return Mono.error(new AccessDeniedException("Production 环境禁止使用 introspection 查询"));
}
return chain.next(request);
}
private boolean containsIntrospection(String query) {
Document document = Parser.parseDocument(query);
Map<String, FragmentDefinition> fragments = document.getDefinitionsOfType(FragmentDefinition.class)
.stream()
.collect(Collectors.toMap(FragmentDefinition::getName, Function.identity()));
for (OperationDefinition operation : document.getDefinitionsOfType(OperationDefinition.class)) {
if (containsIntrospection(operation.getSelectionSet(), fragments, new HashSet<>())) {
return true;
}
}
return false;
}
private boolean containsIntrospection(SelectionSet selectionSet,
Map<String, FragmentDefinition> fragments,
Set<String> visitedFragments) {
if (selectionSet == null) {
return false;
}
for (Selection<?> selection : selectionSet.getSelections()) {
if (selection instanceof Field field) {
if ("__schema".equals(field.getName()) || "__type".equals(field.getName())) {
return true;
}
if (containsIntrospection(field.getSelectionSet(), fragments, visitedFragments)) {
return true;
}
} else if (selection instanceof InlineFragment inlineFragment) {
if (containsIntrospection(inlineFragment.getSelectionSet(), fragments, visitedFragments)) {
return true;
}
} else if (selection instanceof FragmentSpread spread) {
String name = spread.getName();
if (visitedFragments.add(name)) {
FragmentDefinition fragmentDefinition = fragments.get(name);
if (fragmentDefinition != null
&& containsIntrospection(fragmentDefinition.getSelectionSet(), fragments, visitedFragments)) {
return true;
}
}
}
}
return false;
}
}
6.4 为什么要用 Profile 而不是“一刀切”
@Profile("prod") 的意义很大。开发环境里你需要 introspection 来联调、看 schema、调试字段关系;生产环境则强调最小暴露面。
也就是说,安全不是把开发体验彻底砍掉,而是让不同环境遵循不同策略。
6.5 introspection 的替代方案
如果生产环境禁止 introspection,前端和第三方调用方怎么办?通常有几种替代方式:
- 提供一份受控的 schema 文档;
- 使用 schema registry 或文档站;
- 在 CI/CD 中导出 schema;
- 对内部团队保留只读的 schema 浏览权限;
- 使用 persisted queries 让客户端只调用已批准查询。
这些方式都比“开放所有 schema 探测能力”更安全。
七、一套更完整的 GraphQL 安全组合拳
单独一个深度限制、复杂度限制或者权限控制,都不足以覆盖 GraphQL 的全部风险。更成熟的实践,应该是多层防御叠加。
7.1 推荐的安全链路
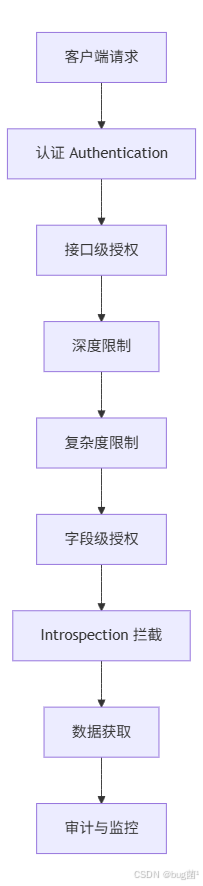
这条链路看起来长,但每一层承担的职责都不同:
- 认证:你是谁;
- 接口级授权:你能不能访问这个 GraphQL 服务;
- 深度限制:你能展开多深;
- 复杂度限制:你能消耗多少资源;
- 字段级授权:你能看哪些字段;
- introspection 拦截:你能不能探测 schema;
- 审计监控:发生了什么,谁在频繁触发高成本查询。
7.2 还应该加上的两个治理措施
1)Persisted Query(持久化查询)
把允许执行的查询提前登记,客户端只提交 query id,不直接提交自由文本查询。这样可以大幅减少未知查询带来的风险。
2)Rate Limiting(限流)
即便查询本身合法,也要限制单位时间内的请求频率。否则,攻击者可以通过“低复杂度高频率”把系统拖慢。
7.3 数据加载层也要做保护
GraphQL 最大的性能问题之一是 N+1。安全治理和性能治理在这里是重叠的。建议使用 DataLoader 或批量加载策略,避免一个列表字段触发成百上千次单独查询。
如果你在 JPA、MyBatis 或远程服务调用中没有做批量聚合,深度限制虽然能挡一部分请求,但服务仍然可能在正常流量下很慢。
7.4 审计日志该记录什么
建议至少记录以下内容:
- 请求用户;
- 查询时间;
- query 文本摘要;
- 深度值;
- 复杂度值;
- 被拒绝的字段或权限点;
- introspection 命中情况;
- 查询耗时。
这些日志能帮你在安全、排障、容量规划三个方向同时受益。
八、从请求到响应:完整链路的安全模型图
下面这张图把 GraphQL 请求在 Spring Boot 3.x 中的主要处理阶段串起来。
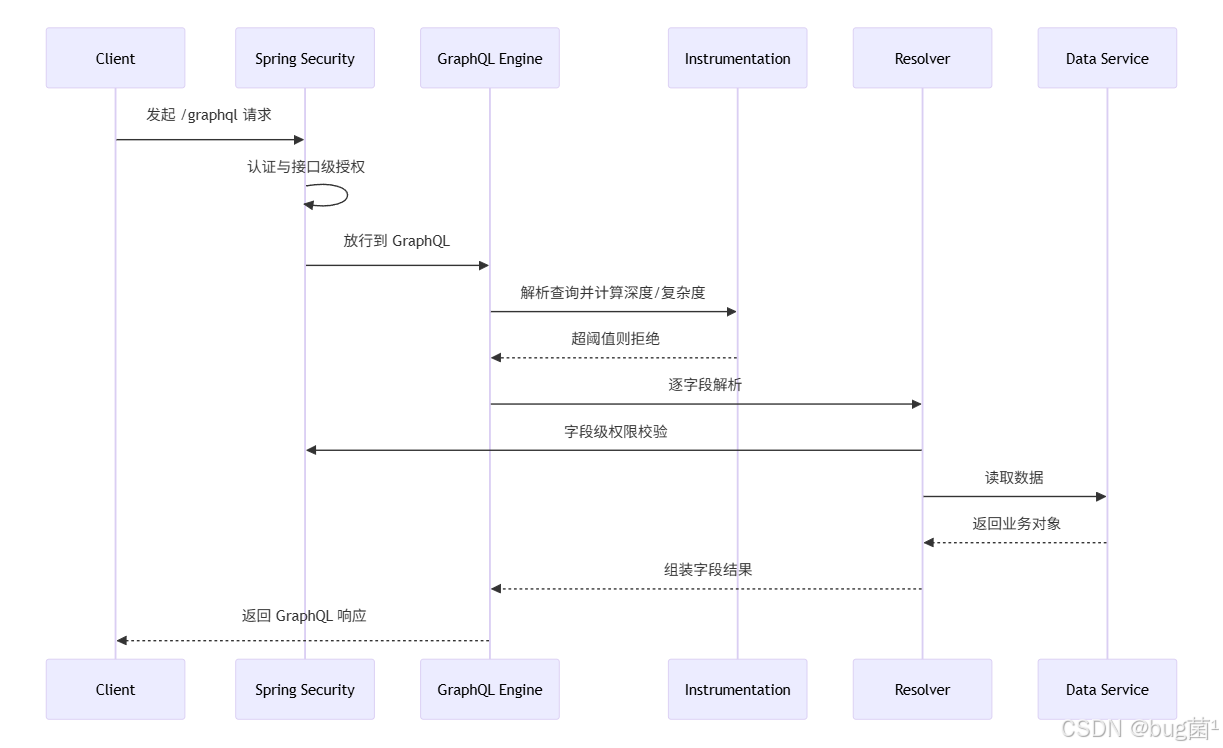
这条链路说明了一个关键点:GraphQL 的安全不是单点功能,而是贯穿请求生命周期的系统工程。
九、常见坑位与排障思路
9.1 只限制深度,不限制复杂度
这是最常见的初学者问题。深度浅不代表便宜,尤其是列表字段一旦放大,成本会非常高。
9.2 只做接口级鉴权,不做字段级鉴权
这样很容易让普通用户通过“同一个合法查询”碰到不该看的字段。
9.3 把敏感字段直接交给默认属性映射
默认属性映射很方便,但对高风险字段不够稳妥。建议对敏感字段显式写 @SchemaMapping。
9.4 生产环境还保留完整 introspection
这会让 schema 结构、字段命名、参数形式暴露得更充分。哪怕你没有明显漏洞,也会增加被枚举和自动化探测的风险。
9.5 没有配合限流和超时
深度限制和复杂度限制主要是“入口防守”,而限流和超时是“运行时保护”。缺一不可。
9.6 N+1 问题和安全问题混在一起处理
这两件事不是一回事,但它们往往共同出现。你应该同时优化数据加载和安全阈值,而不是只盯住其中一个。
十、建议你直接落地的生产实践清单
如果你准备把 GraphQL 用到生产环境,建议按下面的顺序落地:
- 给 schema 设计分页上限;
- 开启深度限制;
- 开启复杂度限制;
- 对敏感字段做字段级鉴权;
- 生产环境限制 introspection;
- 为高成本请求加限流;
- 对数据读取层做批量加载;
- 记录复杂度、深度与拒绝原因;
- 为内部客户端引入 persisted query;
- 定期回顾 schema 和权限策略。
这套顺序非常适合 Spring Boot 3.x 项目,原因很简单:它既能快速落地,也能逐步加固。
十一、如果把本文做成一个最小可运行项目,建议的文件结构如下
src/main/java/com/example/graphqlsecurity
├── GraphqlSecurityApplication.java
├── config
│ ├── GraphQlCostConfig.java
│ └── SecurityConfig.java
├── controller
│ └── GraphqlQueryController.java
├── domain
│ ├── Comment.java
│ ├── Post.java
│ └── User.java
├── security
│ └── IntrospectionBlockerInterceptor.java
└── service
└── DemoDataService.java
src/main/resources/graphql
└── schema.graphqls
src/main/resources
└── application.yml
如果你按照这个结构创建项目,基本上就能把本文所有示例串起来。
十二、启动与验证思路
12.1 启动项目
启动后访问 /graphql,使用 POST 请求发送查询即可。开发环境如果开启了 GraphiQL,也可以直接在页面里调试。
12.2 验证深度限制
尝试发送前面那条很深的查询。如果超出阈值,你应该看到执行被拒绝,而不是服务持续往下游打。
12.3 验证复杂度限制
把分页参数调大,或者让多层列表字段叠加展开。若总复杂度超出阈值,也应该被拦截。
12.4 验证字段级权限
用普通用户账号登录,尝试查询 email 或 roles。如果权限不够,系统应返回访问拒绝,而不是把敏感字段直接暴露出去。
12.5 验证 introspection 拦截
发送 __schema 或 __type 相关查询。生产 profile 下应被拦下,开发 profile 下则可以正常调试。
十三、把今天的知识点再收一遍
GraphQL 很强,但也很容易被“合法打爆”。原因不在于 GraphQL 本身有问题,而在于它的表达能力太强,强到必须配套安全治理。
你今天学到的三个核心点,可以浓缩成下面这句话:
深度限制控制“树长多高”,复杂度控制“树有多贵”,字段级权限控制“树上的每一片叶子谁能看”。
再加上 introspection 管控、限流、持久化查询和数据批量加载,GraphQL 才真正具备生产可用的安全边界。
十四、总结
对于 Spring Boot 3.x 项目来说,GraphQL 安全不是一个可选项,而是上线前必须做的基础建设。尤其在以下情况下更要谨慎:
- schema 关系比较深;
- 有很多列表字段;
- 有敏感字段、管理字段、租户字段;
- 客户端来源复杂;
- 团队里有人还在把 GraphQL 当“更灵活的 REST”。
正确的方式不是回避 GraphQL,而是用更严密的方式使用它:
- 用深度限制防止“无限展开”;
- 用复杂度限制防止“低深度高消耗”;
- 用字段级权限控制防止“同一查询不同权限越权”;
- 用 introspection 控制减少 schema 暴露;
- 再配合限流、审计、批量加载和持久化查询,把风险压到可控范围。
如果把这套思路真正落到工程里,你会发现 GraphQL 不仅没有那么可怕,反而会成为一个更优雅、更可控、更容易演进的 API 方案。
附:本文案例查询示例
普通查询
query GetUser {
user(id: 1) {
id
username
}
}
深层查询
query DeepUsers {
users(page: 0, size: 10) {
id
username
posts(first: 10) {
id
title
comments(first: 10) {
id
content
author {
id
username
posts(first: 5) {
id
title
}
}
}
}
}
}
可能触发权限拦截的查询
query SensitiveUser {
user(id: 1) {
id
username
email
roles
}
}
introspection 查询片段
query Introspection {
__schema {
types {
name
}
}
}
…
ok,同学们,本节课就上到这儿,下课~
🧧 学习福利 · 限时开放 🧧
当然,无论你是计算机专业在读学生,还是对编程充满兴趣的入门者,都强烈建议系统学习SpringBoot全体系专栏:👉 「滚雪球学 Spring Boot」;涵盖SpringBoot所有教学内容。
该专栏以“循序渐进 + 实战驱动”为核心理念,从基础到进阶到就业到架构师逐层展开,帮助你快速建立完整的 Spring Boot 技术体系,带你玩转SpringBoot框架。
📌 学习承诺:
通过该专栏,你将能够:
- 快速掌握 Spring Boot 核心开发能力
- 构建完整的后端项目认知体系
- 实现从“入门”到“独立开发”的跃迁
就像“滚雪球”一样,知识不断积累、能力持续放大,实现指数级成长 🚀
最后,如果这篇文章对你有所帮助,帮忙给作者来个一键三连,关注、点赞、收藏,您的支持就是我坚持写作最大的动力。
同时欢迎大家关注技术号:「猿圈奇妙屋」 ,以便学习更多同类型的技术文章,免费白嫖最新BAT互联网公司面试题、4000G PDF编程电子书、简历模板、技术文章Markdown文档等海量资料。
ps:本文涉及所有源代码,均已上传至Gitee开源,供同学们直接对照学习 Gitee传送门,同时,原创开源不易,欢迎给个star🌟,想体验下被🌟的感jio,非常感谢❗
🫵 Who am I?
我是 bug菌,一名深耕 Java 后端领域数十年的一线研发老兵,曾担任独角兽企业后端技术经理、研发架构师等职位,长期专注于 Java 后端、分布式架构、微服务治理、高并发系统、工程效能与研发管理等方向。
目前活跃于多个主流技术社区,包括:
CSDN|稀土掘金|InfoQ|51CTO|华为云开发者社区|阿里云开发者社区|腾讯云开发者社区|开源中国|博客园|墨天轮 等平台。
曾获得:
- CSDN 博客之星 Top30
- 华为云多年度十佳博主 & 卓越贡献奖
- 掘金多年度人气作者 Top40
- CSDN、掘金、InfoQ、51CTO 等平台签约作者 / 优质作者
截至目前,全网技术内容累计影响读者众多,全网粉丝已超过 30w+。
如果你也关注 Java 后端、架构设计、技术成长、职场进阶与研发管理,欢迎关注我的技术内容合集入口:👉 点击查看 👈️
硬核技术号 「猿圈奇妙屋」 期待你的加入。
这里不仅分享技术干货,也记录一线研发人的成长、踩坑、思考与进阶路径。
愿我们一起打怪升级,在技术路上持续进阶。

- End -

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 1
1 0
0- 0



 已为社区贡献110条内容
已为社区贡献110条内容

所有评论(0)