AI 时代最大的谎言:你以为在学习,其实在欠债—思维决定上限的反焦虑框架
文章目录
🍃作者介绍:AI 应用负责人/AI产品架构师,阿里云专家博主。专注 LLM 应用开发、Agent 系统设计、具身智能与工业 AI 落地。日常在大模型训练、Coding Agent 工具链、AI 产品商业化等方向持续输出实战内容。
🦅个人主页:@逐梦苍穹
🐼GitHub主页:https://github.com/XZL-CODE
✈ 您的一键三连,是我创作的最大动力🌹

1、写在前面:我为什么不再写"AI 焦虑"
2026 年 4 月中旬,AI 圈最不缺的就是焦虑文。我也不想再写一篇。
这篇文章只想说一句话:
AI 时代不是机会在变多,而是差异化空间在收缩——所有人最容易做到的事,都不再是壁垒。
过去半年我和大多数人,被各路 Agent、coding agent、prompt 工作流卷得像永动机。但当我把这半年实际产出倒出来盘点的时候,发现一个让我清醒的事实:
- 折腾过的 Agent 不下二十个;
- 学过的工具、跑过的 prompt、刷过的 token,都不少;
- 但真正能拿出来摆桌面上的硬通货——一个完整闭环的项目、一篇有方法论的论文、一个能被市场验证的产品——并不多。
这不是个人懒,是个结构性问题:当一个能力可以三个月学会,它就不可能成为你的壁垒。所以这篇文章我想把过去半年想清楚的事,用一个完全属于工程师视角的框架讲一下:护城河堆栈——宽度、深度、沉淀。
2、本文速览
| 章节 | 一句话主张 |
|---|---|
| § 3 | AI 焦虑的真实闭环不是"错过",是"被 AI 替你跑步" |
| § 4 | MIT 认知负债:AI 给的是"完成态",不是"思考态" |
| § 5 | 护城河堆栈:宽度被抹平、深度留下来、沉淀做杠杆 |
| § 6 | K 字型不是 AI 把人拉两极,是 AI 把"中等熟练度"挤掉了 |
| § 7 | 商业上同样的规律:从不确定性向确定性收敛 |
| § 8 | 行动指南:今晚就能做的三件事 |
如果你时间不够,直接跳到 § 5 和 § 8——这两章是文章的骨架。
3、AI 焦虑的真实闭环:你不是在错过 AI
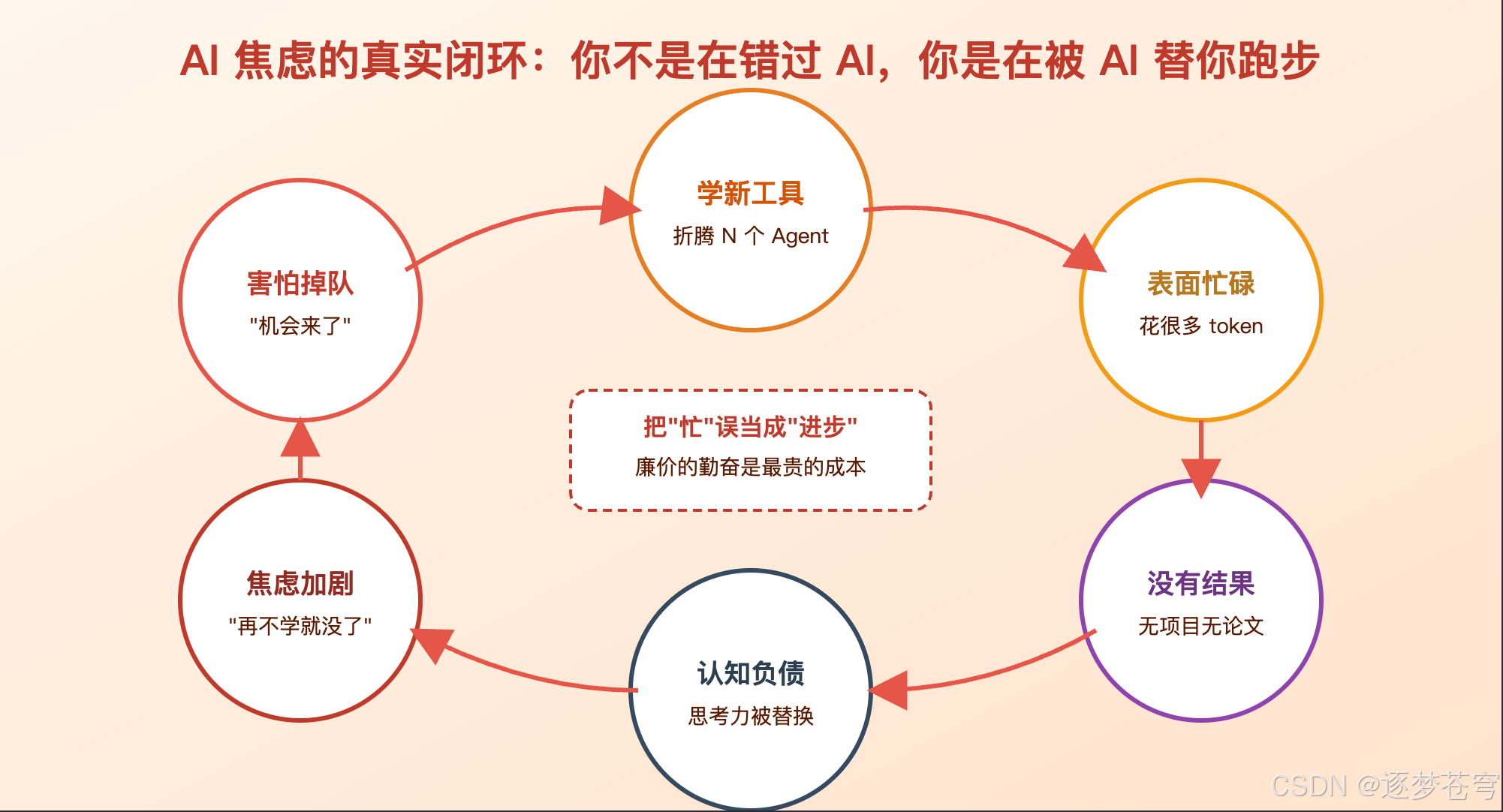
3.1、焦虑的来源不是机会,是怕
去年下半年到今年这小半年,我见到太多人陷入一个相似的状态:工具学了一堆,但生产力没本质提升;周围人都在学,所以不学就更焦虑——焦虑驱动学习,学习消化不了,再焦虑。
这是一个标准的负反馈闭环。它的表面驱动力是"机会感",底层驱动力是怕——怕错过、怕被抛下、怕到了 30 岁还没站住脚。
3.2、机会从来不属于"绝大多数人"
我先说一个不太友好但很必要的判断:机会的本质就是只属于少数人的事情。如果它真属于绝大多数人,它就不叫机会,叫常识。
回看中国过去 20 年——PC 互联网、移动互联网、O2O、共享经济、短视频、新能源——每一波"人人都能翻身"的话术,最后兑现的人都不是绝大多数。这不是 AI 的问题,是统计学问题。
所以现在更像的状态,不是"人人都能翻身的窗口期",而是:一次低门槛、大规模、低成本的实验场。
把实验场当成窗口期跑,是当下大部分焦虑的真正源头。窗口期的关键动作是"快速冲进去",实验场的关键动作是"想清楚自己在做什么实验"。
3.3、对你的实际意义
如果你过去半年做的事情,不能在三句话内说清楚"我学到了什么、我能交付什么、我下一步要做什么"——那不是不够努力,是你没在做实验,是实验在做你。
4、MIT 认知负债:所有 AI 重度使用者必须知道的预警
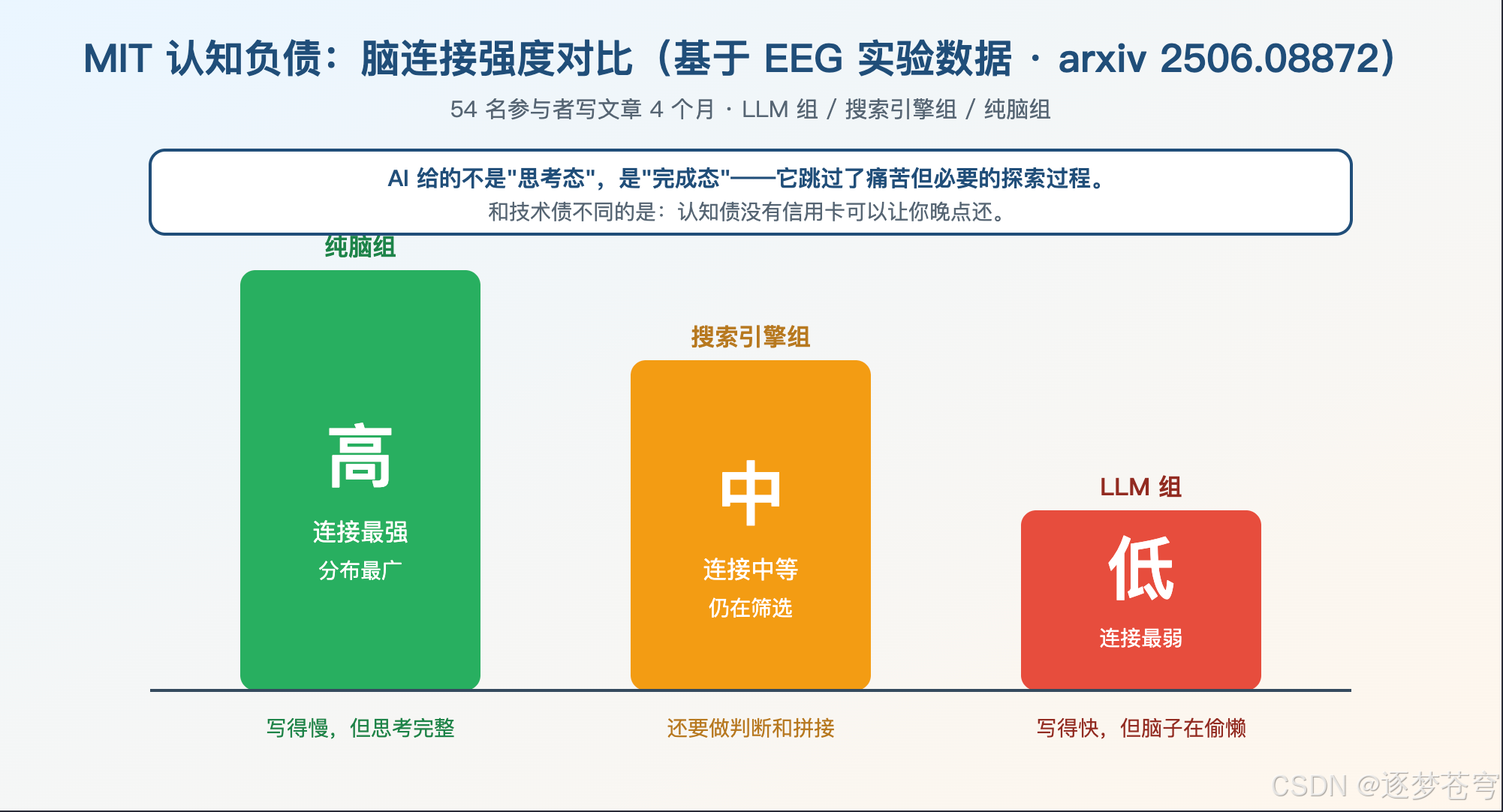
4.1、研究本身
2025 年 6 月,MIT Media Lab 发布了一篇预印本论文(arxiv 2506.08872,作者 Nataliya Kosmyna 等),标题非常直白:《Your Brain on ChatGPT: Accumulation of Cognitive Debt》。
实验设计简洁到不能再简洁:
- 54 名参与者,分为三组——LLM 组、搜索引擎组、纯脑组;
- 每组在相同条件下做四轮写作任务;
- 全程用 EEG 监测大脑活动,再用 NLP + 真人教师 + AI 评审三层评分。
EEG 的结果非常清楚:纯脑组的脑连接最强、分布最广;搜索组中等;LLM 组最弱。
研究者起了一个特别贴切的名字:Cognitive Debt——认知负债。
4.2、为什么我专门拎出来讲
技术债(Technical Debt)每个程序员都懂——欠下的迟早要还。但研究者特别强调:认知负债最危险的地方在于,它没有信用卡可以让你晚点还。你不会某天突然发现"哦我欠了 3 个月的思考",你会发现的是——你越来越习惯于不思考。
我对这件事的判断是:
AI 给你的不是"思考态",是"完成态"。它跳过了那个痛苦但必要的探索过程。
这件事在写作里发生,在 AI Coding 里也在发生:
- 写作里,你少了"卡壳 → 推敲 → 拆解 → 拼回去"的过程;
- Coding 里,你少了"看不懂报错 → 翻文档 → 试出来 → 形成 mental model"的过程。
这两个被跳过的过程,恰好就是判断力和系统思维长出来的地方。 你跳过得越多,你的判断力就越浅;判断力越浅,你越要靠 AI;越靠 AI,跳过得越多——这就是 § 3 那个焦虑闭环的真正燃料。
4.3、还债的唯一方式
只有一个:重新做一些 AI 帮不了你的事——刻意地、有意识地。
具体到日常:
- 每天给自己留一个"AI 隔离时段"——不超过两小时也行,但不能没有;
- 这段时间用来做"AI 没法替你做"的事——读论文做笔记、推一个数学证明、把一个复杂业务从头到尾自己画一遍;
- 不是反对 AI,是保留你大脑的"原生肌肉"不萎缩。
5、护城河堆栈:宽度 / 深度 / 沉淀

这一节是全文的骨架。我把 AI 时代的个人护城河拆成三层:宽度、深度、沉淀。三层的特征非常不同——上面被 AI 替代得最快,下面被 AI 替代得最慢。
5.1、第三层:宽度——已经被 AI 抹平的那部分
宽度的定义:所有人花一周就能学会的东西。
具体包括:
- 各种 prompt 模板;
- 各种 Agent 框架(LangChain、CrewAI、Autogen、Coze);
- 各种 AI 工具(Cursor、Windsurf、各种 IDE 插件);
- 各种 API 调用方式。
宽度从前是壁垒,是因为获取成本高——你要读文档、要跑通环境、要排错。但 AI 把宽度的获取成本拉到了接近 0:你想学一个新框架,让 Claude Code 给你跑个 demo,半小时就上手。
当一件事的获取成本是 0,它就不再是壁垒。它只是基线。
数据上也能看出来这件事的剧烈程度:根据 21 经济报道的统计,2026 年 2 月中国大模型日均 token 调用量已经突破 1.8 万亿,相比 2024 年初的千亿级别上涨了一个数量级。"会用 AI"在这个量级里已经是基础水平,不是差异化。
5.2、第二层:深度——AI 真的帮不了你的那部分
深度的定义:你在某个具体问题上的"判断密度"。
举几个具体的例子:
- 同样写一个 RAG 系统,浅的人选一个 chunk size 跑通就行;深的人会问"我的 query 类型是什么、答案分布是什么、应该用 sparse 还是 dense、要不要 rerank、cold start 怎么办"。
- 同样做一个产品功能,浅的人按需求文档写;深的人会问"这个需求的真实用户场景是什么、为什么用户上一版没用这个功能、加了这个会不会拖累其他指标"。
- 同样看一份财报,浅的人看营收增速;深的人看应收账款周转天数和现金流的背离。
深度不是知识量,是判断密度——为什么这么做、不这么做会怎样、什么时候这条规则会失效。
为什么 AI 在这一层弱?因为AI 没有"为什么",只有"是什么"。它能告诉你 chunk size 一般取多少,但它没法告诉你"在这个特定项目里你为什么应该违背一般规则"。
这就是为什么有判断力、有专业深度、有科研能力的人——他们的相对优势不仅没有被 AI 拉小,反而拉大了。因为底下那些靠宽度自证价值的人被一次性挤平了。
5.3、第一层:沉淀——把今天变成明天的杠杆
沉淀的定义:每做完一件事,能不能把它变成下次的资产。
我把过去半年看到的人分成两类:
| 类型 | 特征 | 三年后的差距 |
|---|---|---|
| 单次工作型 | 做完一件事就扔,下次重新来过 | 三年后还是和今天一样 |
| 资产工作型 | 每件事都沉淀成项目+博客+skill | 三年后有一套别人偷不走的资产 |
我自己执行这一层的方式叫"三重输出":每做完一件事,必须沉淀成三个维度——
- 项目代码:消耗品(容易过期,6 个月可能就被新工具替代);
- 博客文章:品牌(中等保鲜,能在 1-3 年内持续带流量);
- skill / 脚本 / 工作流:杠杆(最长尾,每次复用都是省下来的时间)。
只做项目代码而不沉淀的人,做完一年就是"我做过几个项目";做三重输出的人,做完一年是"我有一套别人偷不走的资产"。这个差别会在第三年开始指数级显现。
这背后的数学很简单:
三年差距 = 单年勤奋 × 沉淀率^3
每年同样勤奋、但沉淀率从 10% 提到 50%,三年后差距是 125 倍——不是 5 倍。绝大部分人的三年差距,不是来自勤奋差距,是来自沉淀率差距。
5.4、三层的关系
宽度是基线,深度是差异化,沉淀是复利。
真正的护城河 = 深度 × 沉淀。
只做宽度的人累但没赚到;只做深度的人值钱但不可复用;只做沉淀但没深度的人是空中楼阁。三层堆起来才是完整的工程师护城河。
6、K 字型人才结构:为什么是中间消失?
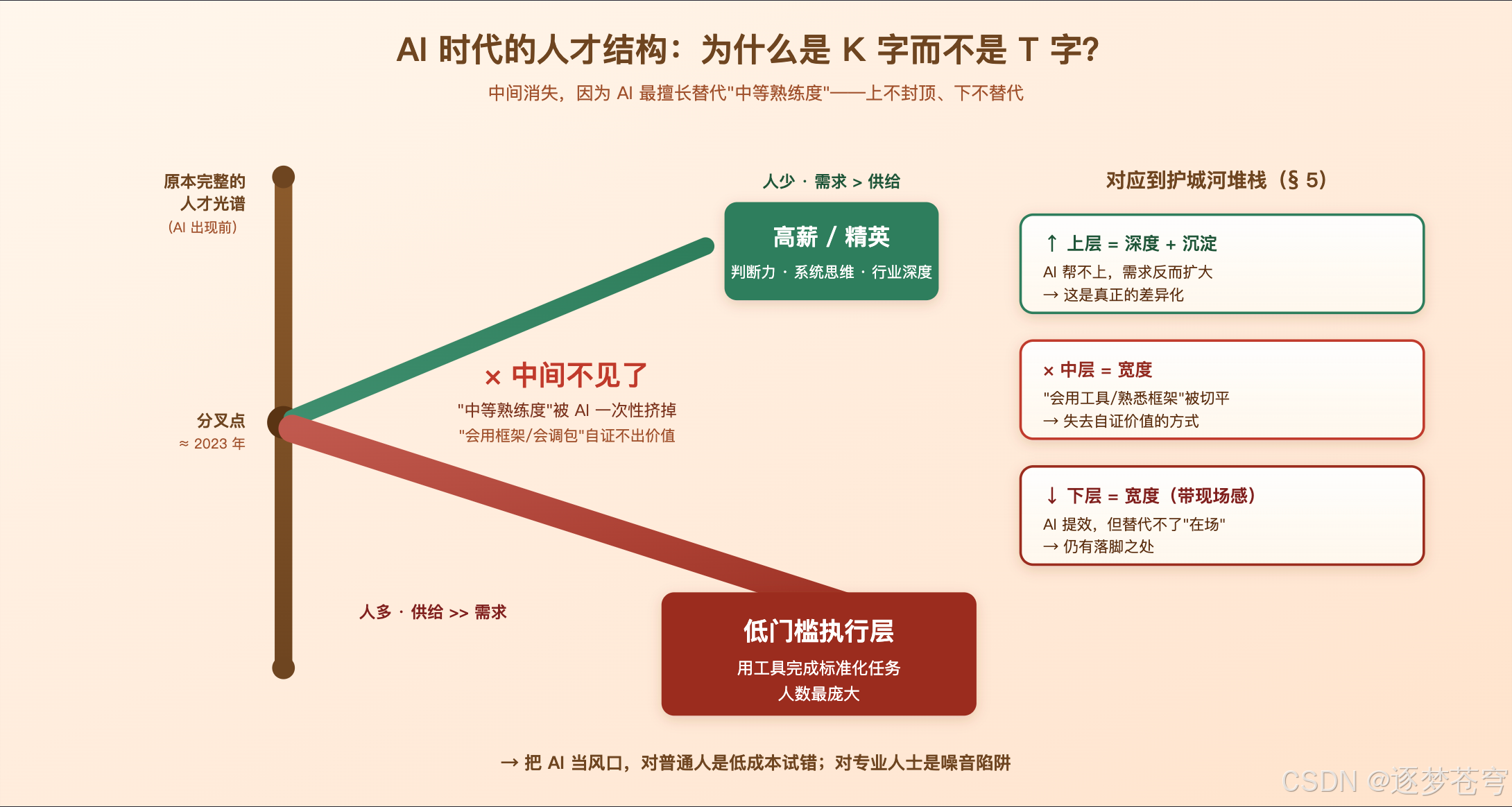
6.1、被反复说但很少说清楚的一件事
这一波 AI 起来以后,K 字型人才结构是被讨论最多的话题之一——上面一支精英、下面一支低门槛执行者,中间这一段不见了。
但少有人讲清楚为什么是中间消失。
我的判断是:AI 最擅长替代的不是入门也不是顶尖,是"中等熟练度"——也就是那种"知道怎么做、但每次都是按部就班做"的工作。
| 层级 | 典型工作 | 对应到 § 5 的堆栈 | AI 影响 |
|---|---|---|---|
| 上 | 把模糊问题想清楚、做权衡、理解复杂组织 | 深度层 + 沉淀层 | AI 帮不上,需求反而扩大 |
| 中 | 写"标准业务代码"、“标准报告”、“标准方案” | 宽度层 | 被 AI 一刀切平 |
| 下 | 数据整理、内容生产、文件处理、简单搜集 | 宽度层(但有现场感) | AI 提效,但替代不了"在场" |
中间这层人最难受的地方在于:他们过去自证价值的方式是"我会用框架/我熟悉这一行/我做过 N 个类似项目"——而这些恰好都是宽度层。当 AI 把宽度变成 100% 标配,这层人的护城河瞬间蒸发。
6.2、对专业人士的预警
我特别想点一下"专业人士"这个群体——硕士、博士、以及那些在某个领域已经苦读十几年的人。
把 AI 当风口对普通人是低成本试错;对专业人士是噪音陷阱。
普通人没什么好失去的,多试错碰运气,正期望值。专业人士不一样——你十几年寒窗苦读积累出来的深度,是你最大的护城河。如果你跑去和所有人一起拼宽度,你是在用自己最贵的东西去换最便宜的东西。
7、商业上同样的规律:从不确定性到确定性
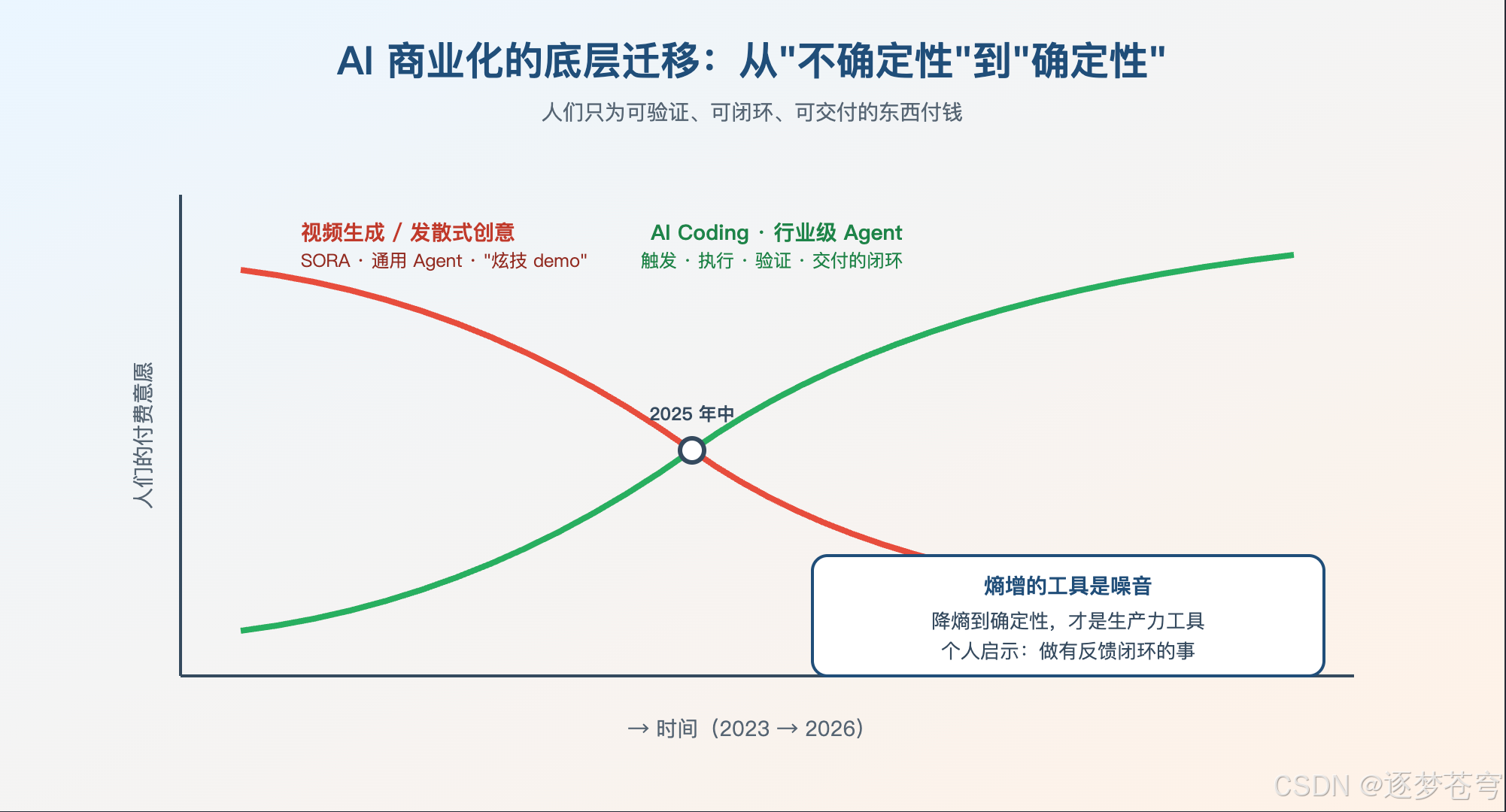
7.1、为什么 AI Coding 火?
不是因为它最强。是因为它能闭环。
把过去两年所有 AI 方向的产品摆出来比一下:
| 方向 | 是否闭环 | 是否可验证 | 商业化进展 |
|---|---|---|---|
| AI Coding(Claude Code / Cursor / Codex) | ✅ 强闭环 | ✅ 跑得起来就是成功 | 强劲,企业端快速渗透 |
| 行业级 Agent(医疗、法律、金融) | ⚠️ 半闭环 | ⚠️ 需要专业判断 | 中等,看垂直能不能切深 |
| 视频生成 / 通用 Agent | ❌ 弱闭环 | ❌ 主观评价 | 收缩,热度回调 |
背后有一条非常重要的规律——人们只为确定性付钱。
7.2、从工程师视角看:闭环就是触发器
我自己有一条决策模型叫"事件驱动 > 盘中决策"——凡是需要你高频盯着的事情都不可持续;凡是有"触发 → 执行 → 验证"闭环的事情都能跑长。
放到 AI 这一波也成立:
- 通用 Agent 看着炫,但它没有清晰的触发条件;
- AI Coding 看起来朴素,但触发清晰(有需求)→ 执行清晰(生成代码)→ 验证清晰(跑得起来)→ 交付清晰(合并 PR)。
清晰的闭环本身就是商业化的护城河。这一条对个人选事情同样适用。
7.3、对个人选事情的启示
去年和今年看到的一个反复出现的现象是:很多个人 Agent 创业团队,前三个月特别热闹,后六个月销声匿迹。原因不复杂:他们做的是发散的工具,不是收敛的闭环。
启示也很简单:
- 挑事情时优先挑有反馈闭环的——14 天内能看到结果好坏的事;
- 远离纯发散的事——做一年都没法告诉自己到底做没做成的事。
这条启示和 § 5 的护城河堆栈是同一回事的两面:沉淀的前提是闭环,不闭环的事情你沉淀不下来——只能扔。
8、行动指南:今晚就能做的三件事
文章绕了七节,最后浓缩成三个动作。每个都是反共识的——之所以反共识,是因为它们和当下大多数人的做法相反。
8.1、动作一:砍掉宽度
停止追新工具。 不是不学,是给自己一个上限——比如"每周最多花 2 小时学新工具,超过这个时间停手"。
为什么要砍:你越追,你的"差异化空间"越小。现在不缺工具熟练度,缺的是用工具去打透一个具体问题的耐心。
8.2、动作二:选一个深度切口
挑一件事——只挑一件——它必须满足三个条件:
- 你比别人多懂的那一寸——不一定多懂十寸,多懂一寸就行;
- 能耦合你过去的积累(专业、行业、过往项目)——你的城墙在哪你就在哪挖;
- 有 14 天能验证的闭环——不能是"做一年才知道值不值"的事。
这件事就是你接下来 3-12 个月的主战场。不要再开新坑。
8.3、动作三:强制三重输出
每做完一件事,强制问自己三个问题:
- 项目:跑通了吗?能不能给别人 demo?
- 博客:这件事值得写一篇吗?没写之前不算结束。
- skill / 脚本:下次还会用到的部分,能不能封装成可调用的资产?
这三个问题加起来,是你沉淀率从 10% 提到 50% 的唯一办法。
而沉淀率,是 § 5 那个三年差距 125 倍公式里唯一你能控制的变量。
9、写在最后
文章写到这里,回到一开始那句话:
AI 时代不是机会在变多,而是差异化空间在收缩——所有人最容易做到的事,都不再是壁垒。
如果一个事 AI 能做、所有人都能做、获取成本接近 0,它就不可能是你的护城河。
护城河永远在三个地方:
- AI 帮不了你的判断(深度);
- 别人偷不走的资产(沉淀);
- 耦合你过去积累的、独特视角的切口(认知差)。
最后一句话送给所有正在焦虑的同行(也包括我自己):
浮躁的人会越来越多,踏实深耕的人反倒越有机会。
风口要看,但不要追——你追不过基座模型的迭代速度。
做自己的确定性,让深度和沉淀替你做时间的复利。
如果这篇文章在你某个迷茫的瞬间帮你停下来想了 5 分钟,那就够了——这是 AI 帮不了你的 5 分钟,也是你最值钱的 5 分钟。
参考资料:
- Kosmyna, N. et al., Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task, MIT Media Lab, arxiv 2506.08872 (2025).
- 21 经济报道 / 经济观察网(2026.03):中国大模型日均 token 调用量在 2026 年 2 月突破 1.8 万亿,周调用量首次超过美国。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 15
15 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)