LLM工具调用面试篇2
3. 大模型的 Function Call 能力是怎么训练出来的?
Function Call 的能力主要靠两个训练阶段来培养,这两个阶段解决的是不同的问题。
第一个是 SFT,就是给模型喂大量「包含工具调用的完整对话样本」,每条样本覆盖工具定义、用户问题、模型应该输出的结构化 JSON 调用、工具执行结果、最终答案,让模型通过模仿学会整套流程。但光有 SFT 不够,模型可能学得过激,遇到什么问题都想调工具。
第二个阶段是 RLHF,通过人类标注「哪种回答更好」来训练奖励模型,再用强化学习调整主模型,让它学会「能直接回答的就直接回答,需要实时数据才去调工具」这个边界感。
一句话总结:SFT 教会怎么调,RLHF 教会什么时候调。
很多人以为 Function Call 是大模型「聪明」之后自然就会的东西,其实不是。就算是 GPT-4,如果没有经过工具调用的专项训练,它遇到「北京今天天气怎么样」这个问题,顶多也就输出一句「我需要查询天气数据」,这是在描述一个意图,而不是在输出可以被程序解析和执行的结构化 JSON。这两件事之间有本质的差距。
为什么预训练学不会这件事?关键原因是预训练语料里压根没有「标准工具调用 JSON」这种模式。预训练喂给模型的是互联网上的海量文本,里面有代码、有文档、有对话,但几乎没有「给定一组工具 schema,该在什么场景输出什么 JSON」这样的成对样本。
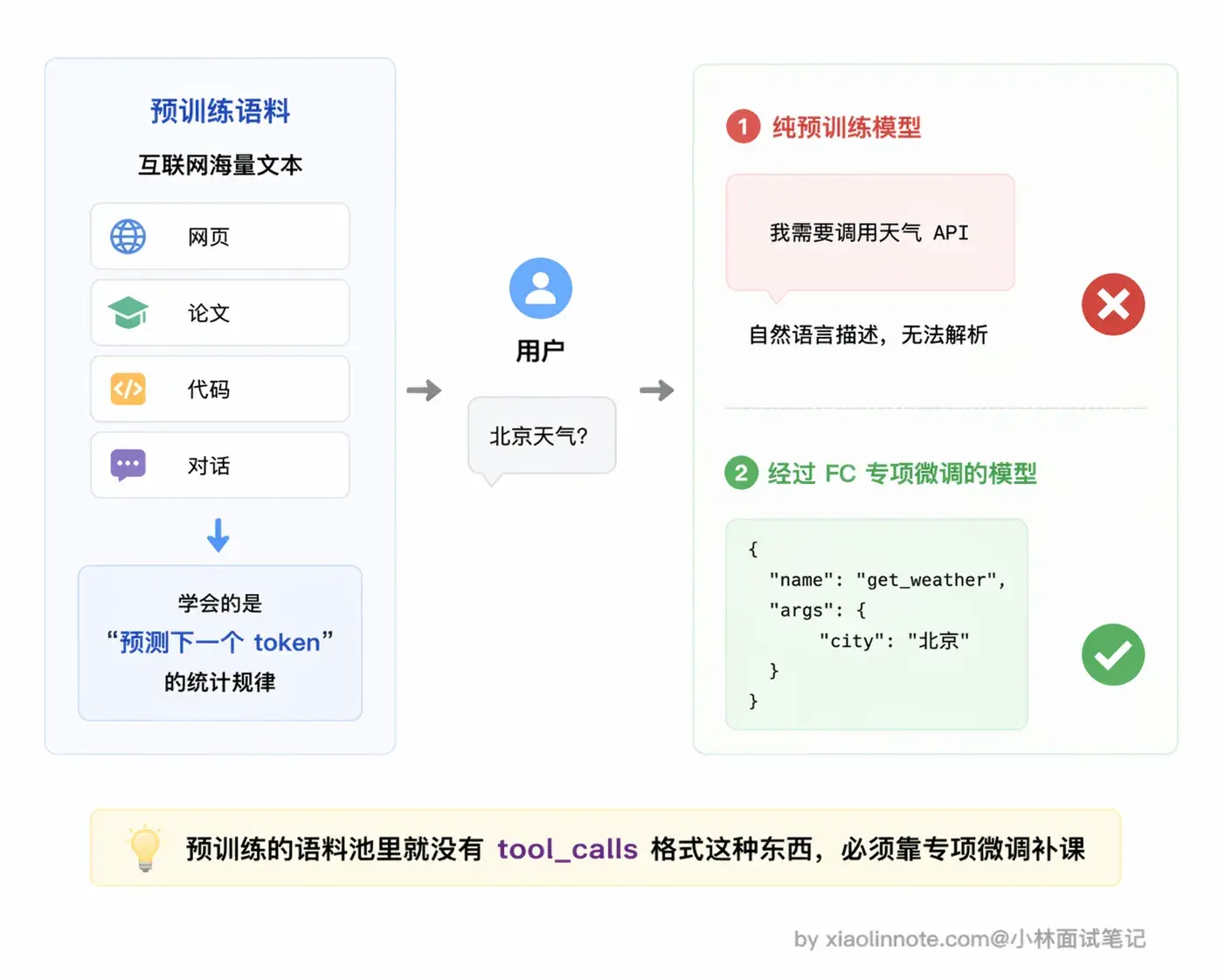
模型在预训练期间的所有权重更新,都是基于「预测下一个最可能的 token」这个目标,它记住的是人类文字里的统计规律,而「遇到天气问题就输出一段固定格式的 tool_calls JSON」不是人类文字里自然存在的模式,权重里根本没有相关经验可以调用。所以这件事必须靠专项微调来补。
Function Call 的核心训练分两个阶段,每个阶段解决不同的问题,缺一不可。
阶段一:SFT,让模型「学会怎么调」
SFT(Supervised Fine-Tuning,监督微调)的核心动作很简单:给模型喂大量正确示例,让它通过模仿来学习。对 Function Call 能力来说,就是构造「包含完整工具调用流程的对话样本」,一条样本里包含所有角色的消息。
一条完整的训练样本大概是这样的结构:首先是 system 消息,里面注入了工具的定义,工具叫什么名字、是干什么用的、接受哪些参数。模型是从这里「认识」工具的,就像你给新员工一份工具手册,告诉他公司有哪些系统可以用。接着是 user 消息,就是用户的提问,比如「北京今天天气怎么样」。
然后是关键的一步:assistant 的消息不是自然语言,而是结构化的 JSON 调用请求,类似 {"tool_calls": [{"name": "get_weather", "arguments": {"city": "北京"}}]},这是「正确答案」,是模型通过训练需要学会输出的内容。之后是 tool 角色的消息,是工具执行后返回的结果,比如「晴天,15°C,东北风 3 级」。最后 assistant 再出现一次,根据工具结果给出最终的自然语言答案。
这套完整的对话结构覆盖了整个调用链路。模型通过反向传播(backpropagation)来学习:给定样本里的正确 JSON 调用,当模型输出的内容偏离这个正确答案时,损失函数就会产生惩罚信号,梯度往回传,一点点调整模型内部的参数权重,让下次输出更接近正确格式。
大量样本反复训练,模型就把这套「看到工具定义 + 看到用户问题 -> 输出规范 JSON」的模式「记住」了。就像背单词,看一遍不够,反复遇到、反复纠错,最终形成了肌肉记忆。
训练数据需要覆盖哪些场景
训练数据的多样性直接决定了 Function Call 能力的上限,不能只有「正常调一个工具」这一种情况。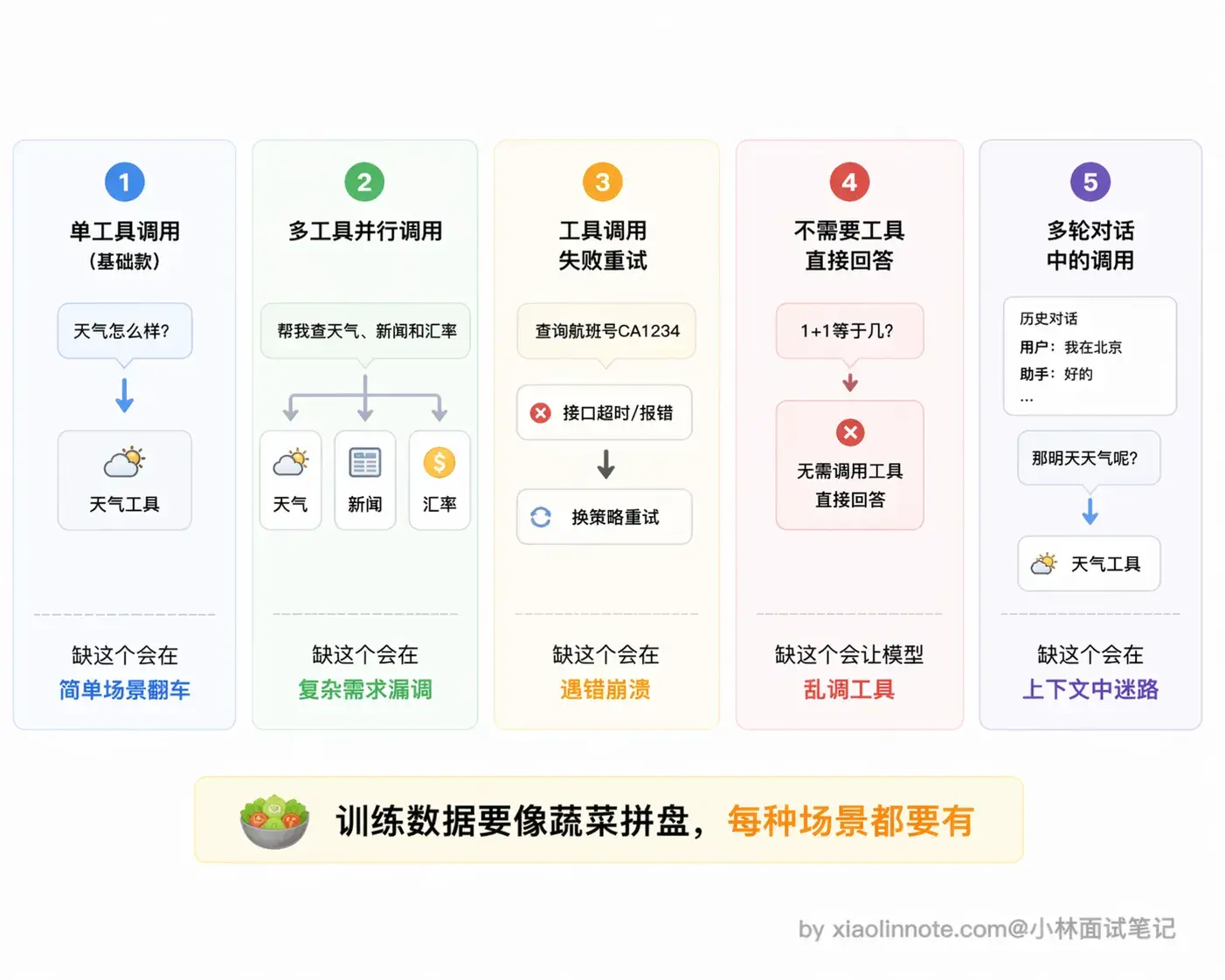
好的训练数据至少要覆盖这几类场景。最基础的当然是单工具调用,一个问题对应一个工具,这是入门款。但光有这个远远不够,还需要多工具并行调用的样本,比如用户问「帮我查北京和上海的天气」,模型应该一次性输出两个调用请求而不是傻乎乎地一个一个来,如果训练数据里没见过这种场景,模型就不知道可以并行。
另一个容易忽略但非常关键的场景是工具调用失败后的处理。现实中工具不可能百分百成功,API 超时、参数格式不对、权限不足,各种错误都有可能出现,模型要能识别错误信息并换个方式处理,而不是直接崩掉或者傻傻地重复同样的调用。
还有一类场景很多人想不到:不需要调工具、直接回答。这个其实非常重要,「1+1 等于几」「帮我总结这段话」这类问题完全不需要工具,模型得学会判断「我能自己解决,不用调」。如果训练数据里全是「调用工具」的正例,模型就会形成「遇到问题就调工具」的惯性,该直接回答的时候也去调,画蛇添足。
最后是多轮对话中的工具调用,上下文里已经有过工具结果,模型要能正确理解和引用之前的结果,而不是无视历史重新调用。这些场景的覆盖程度,直接影响模型在实际使用中的表现,缺哪个就会在哪个场景下翻车。
训练数据从哪来
构造 Function Call 训练数据主要有两种方式。
第一种是人工标注,雇标注员,给定用户问题和工具定义,让他们写出正确的调用示例。这种方式质量好,因为人写的样本准确度有保障,但成本极高,通常只用于核心种子数据的构造,没法大规模扩展。
第二种是模型自动生成,业界也叫 Self-Instruct 或 Distillation(蒸馏)。核心思路是用一个已经具备 Function Call 能力的强模型(比如 GPT-4)批量生成训练样本,再人工抽查质量。这是现在业界的主流做法,成本低、量大,但有一个隐患:如果上游模型本身生成了错误的样本,下游模型就会把这个错误一起学进去,业界叫做「模型蒸馏的幻觉传递」。所以抽查质量这一步不能省,不然相当于在教模型学错误答案。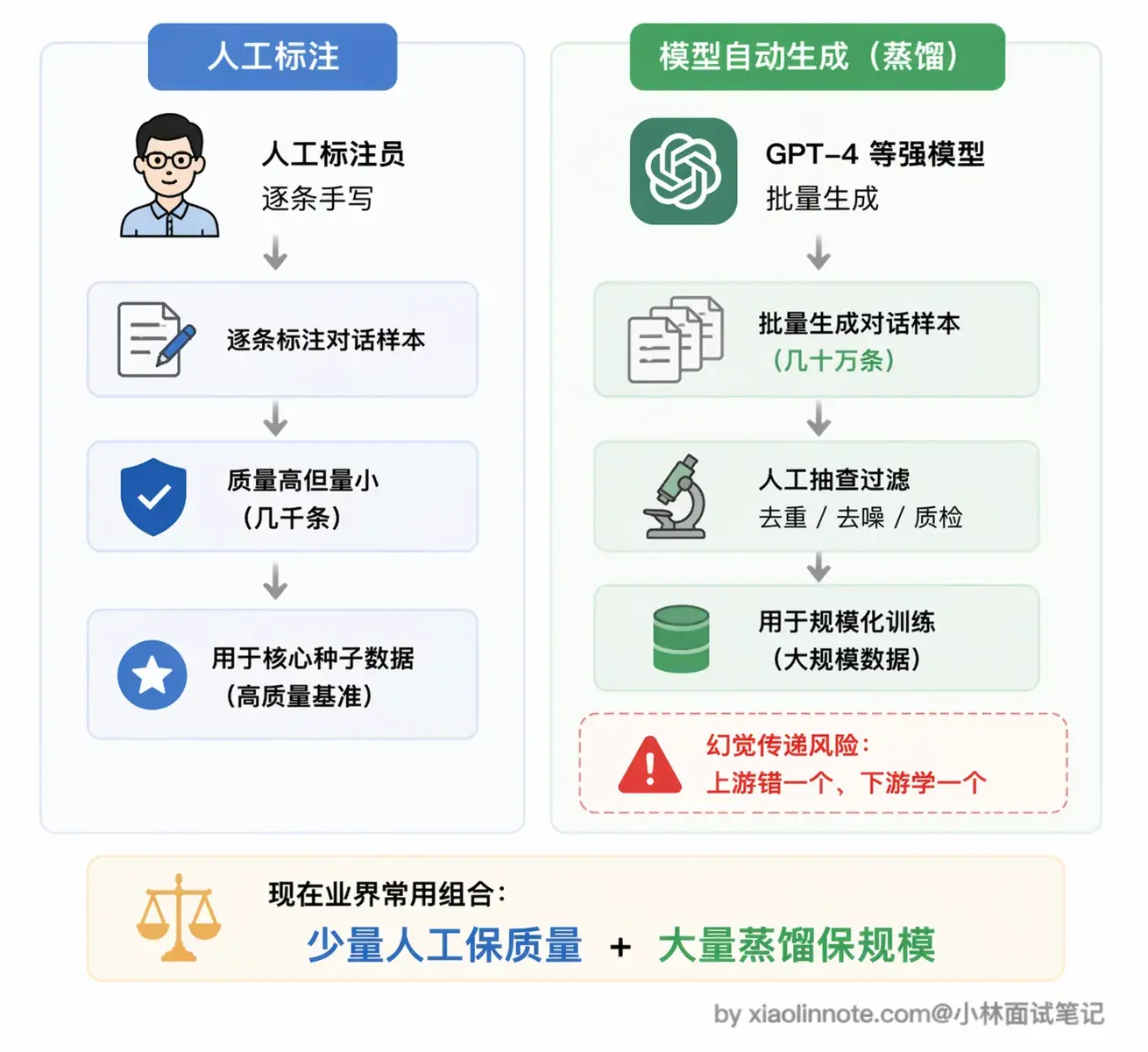
阶段二:RLHF,对齐「该不该调」的边界感
SFT 之后,模型已经学会了「怎么调工具」,但还有一个问题没解决:什么时候应该调工具,什么时候直接回答。
SFT 的训练样本都是「正确调用」的例子,模型看多了,可能学得有点偏激,遇到什么问题都想调工具,不管有没有必要。
「1+1 等于几」不应该调计算器,直接回答 2 就行;「帮我总结这段文字」完全不需要任何工具,直接做就行;只有「北京今天天气」这类需要实时数据的问题才应该调。
这种「能直接回答就直接回答,需要外部数据才去调」的边界感,SFT 很难教好,因为光靠固定的正确样本没法覆盖所有边界情况。RLHF 就是来解决这个问题的。
RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习)的流程分四步。
-
第一步是生成多样回答。对同一个问题,让模型生成多种回答,有直接回答的,有调了工具的,有调了工具但参数填错的,故意覆盖各种情况。
-
第二步是人类标注打分。标注员对这些回答进行排序,比如「北京今天天气怎么样」这道题,调了天气工具的回答排第一,因为不调工具就没法给出准确的实时数据;「1+1 等于几」这道题,直接回答 2 的排第一,调计算器工具的反而是画蛇添足,排末尾。
-
第三步是训练奖励模型。用这批打分排序的数据,单独训练一个神经网络,叫做「奖励模型」(Reward Model,RM)。奖励模型学会了一件事:给定一个问题和一种回答,预测人类会给这个回答多少分。它不直接回答用户,只负责打分,相当于一个专门评判「哪种回答更好」的裁判。
-
第四步是用强化学习调整主模型。拿奖励模型的打分信号,通过 PPO(Proximal Policy Optimization,近端策略优化)等强化学习算法持续调整主模型的参数,让主模型越来越倾向于输出「奖励模型打高分」的回答。
你可能会好奇,为什么偏偏是 PPO?
强化学习算法那么多,选 PPO 有两个很务实的理由:一是它相对稳定,训练过程不容易崩(传统策略梯度算法很容易因为单步更新太大把模型直接调废);二是它内置了一个 KL 散度约束,强迫新模型和旧模型的输出分布不要差得太远,这样就不会出现「为了讨好奖励模型,模型把自己训成只会重复几句套话的怪胎」这种退化情况。RLHF 本质上要让模型在「追求高奖励」和「保持语言能力」之间走钢丝,PPO 在这个平衡上是目前公认好用的工具。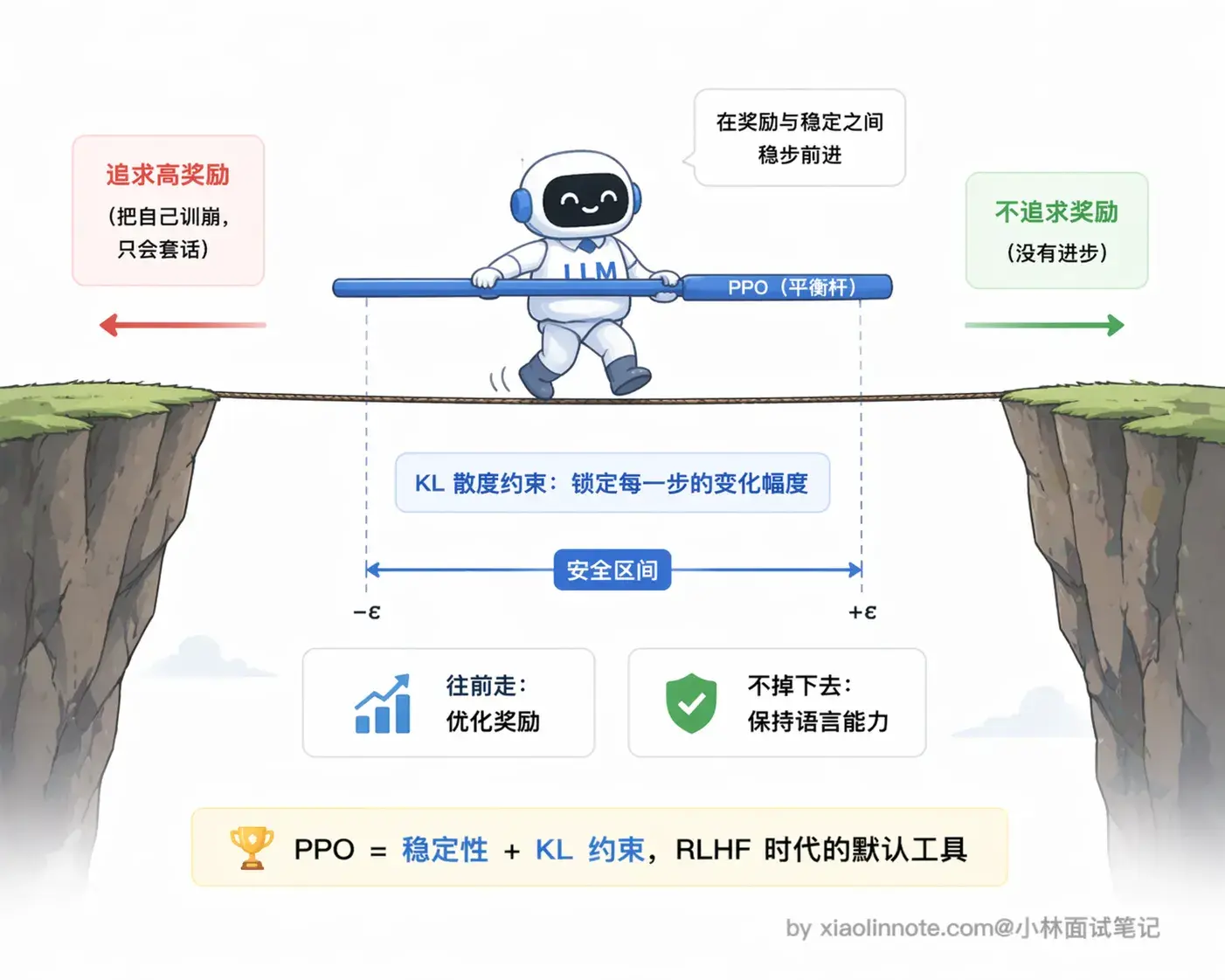
经过足够多的迭代,模型就学会了那种边界感:该调工具时调,能直接回答时不折腾。
RLAIF:用 AI 代替人工打分
RLHF 最大的痛点是人工标注成本极高,标注员需要专业背景,打分慢、价格贵,很难大规模扩展。
RLAIF(Reinforcement Learning from AI Feedback)是它的改进版。你可以这么理解:RLHF 是请一群专业的人类评委来给模型的回答打分,质量很高但请评委的成本也很高;RLAIF 就是换成了一个「AI 评委」,用更强的 AI 模型(比如 GPT-4)来代替人类标注员做这个打分的活儿,成本能低 10-100 倍,速度也快得多。
不过代价也很明显:「AI 的偏见会传递」。如果打分的 AI 本身对某些场景的判断有偏差或者盲区,这些偏差也会被学进去。打个比方,如果 AI 评委觉得「遇到数学题都应该调计算器工具」,那被它训练的模型也会学到这个倾向,哪怕有些简单算术不用调工具。所以打分 AI 的质量很关键,选什么模型来当评委、怎么设计评分标准,都需要仔细考虑。现在业界很多模型训练都在混用 RLHF 和 RLAIF,在关键数据上用人工保质量,量大的地方用 AI 提效率,两者互补。
两个阶段各司其职
SFT 解决的是「会不会」的问题,RLHF 解决的是「该不该」的问题。
只有 SFT 而没有 RLHF 的模型,可能遇到什么问题都冲动地调工具;反过来,只有 RLHF 而没有 SFT,模型连工具调用的格式都输不出来,奖励信号根本没地方发力。
两个阶段配合起来,才能训练出「知道怎么调、也知道什么时候该调」的工具使用能力。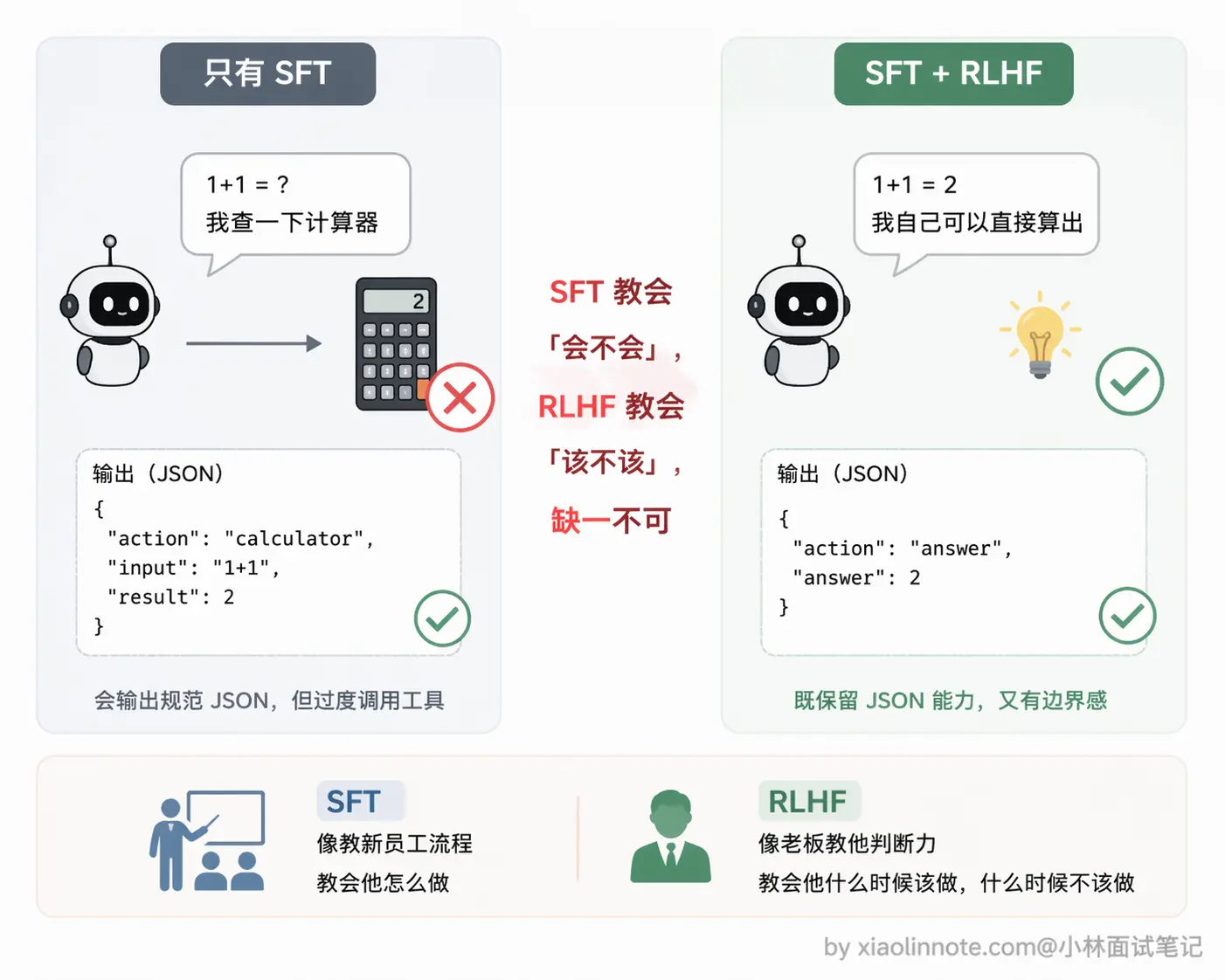
面试回答这道题,要把两个训练阶段讲清楚。
SFT 阶段通过「system 工具定义 + user 问题 + assistant JSON 调用 + tool 执行结果 + assistant 最终回答」这样的完整对话样本来训练,让模型通过反向传播学会整套流程。
RLHF 阶段通过人类对多种回答的偏好排序训练奖励模型,再用 PPO 等强化学习算法调整主模型,建立「该不该调」的边界感。
训练数据来源也要提到:人工标注质量高但成本高用于种子数据,模型自动生成(Self-Instruct / Distillation)成本低量大但要注意幻觉传递的风险。
一句话总结:SFT 教会怎么调,RLHF 教会什么时候调。
4. 什么是 MCP(模型上下文协议)?讲讲它的核心内容?
MCP 是 Anthropic 在 2024 年底推出的开放协议,我理解它主要解决的是「模型接工具太碎片化」的问题。
在 MCP 出现之前,每接一个新工具都要单独写集成代码、处理认证、适配格式,而且这套代码和具体模型强绑定,换个模型就得重写,非常繁琐。
MCP 的思路是把这件事标准化:工具提供方按协议实现一个 Server,任何支持 MCP 的 AI 客户端就能直接接进来,一次实现到处复用。
协议定义了三类能力:Tools 用于执行有副作用的操作,Resources 是只读数据,Prompts 是提示词模板,底层通信用 JSON-RPC 2.0。
我把它理解成给「AI 接工具」这件事定了一套行业标准。
没有 MCP 之前,接工具有多麻烦
想象你要给 Claude 接入 GitHub 工具。你得手写 GitHub API 的调用代码、处理认证(OAuth token 怎么传)、处理各种返回格式、把 API 响应转成模型能理解的格式……好不容易接好了。
结果过了两个月,Claude 升了个版,接口有变化,你的对接代码得改。更麻烦的是,你同时接了十个工具,每个工具都有自己的一套对接代码,各自的格式、认证方式、错误处理逻辑都不一样。现在产品方说,这套工具也要给 Cursor 用,不好意思,你得重写一遍,因为 Cursor 和 Claude Desktop 的接入方式完全不同。
这就是 MCP 出现之前,AI 工具生态的真实状态:碎片化、难复用、强绑定。每个工具、每个模型都是一座孤岛,接一个新工具就要重新搭一座桥。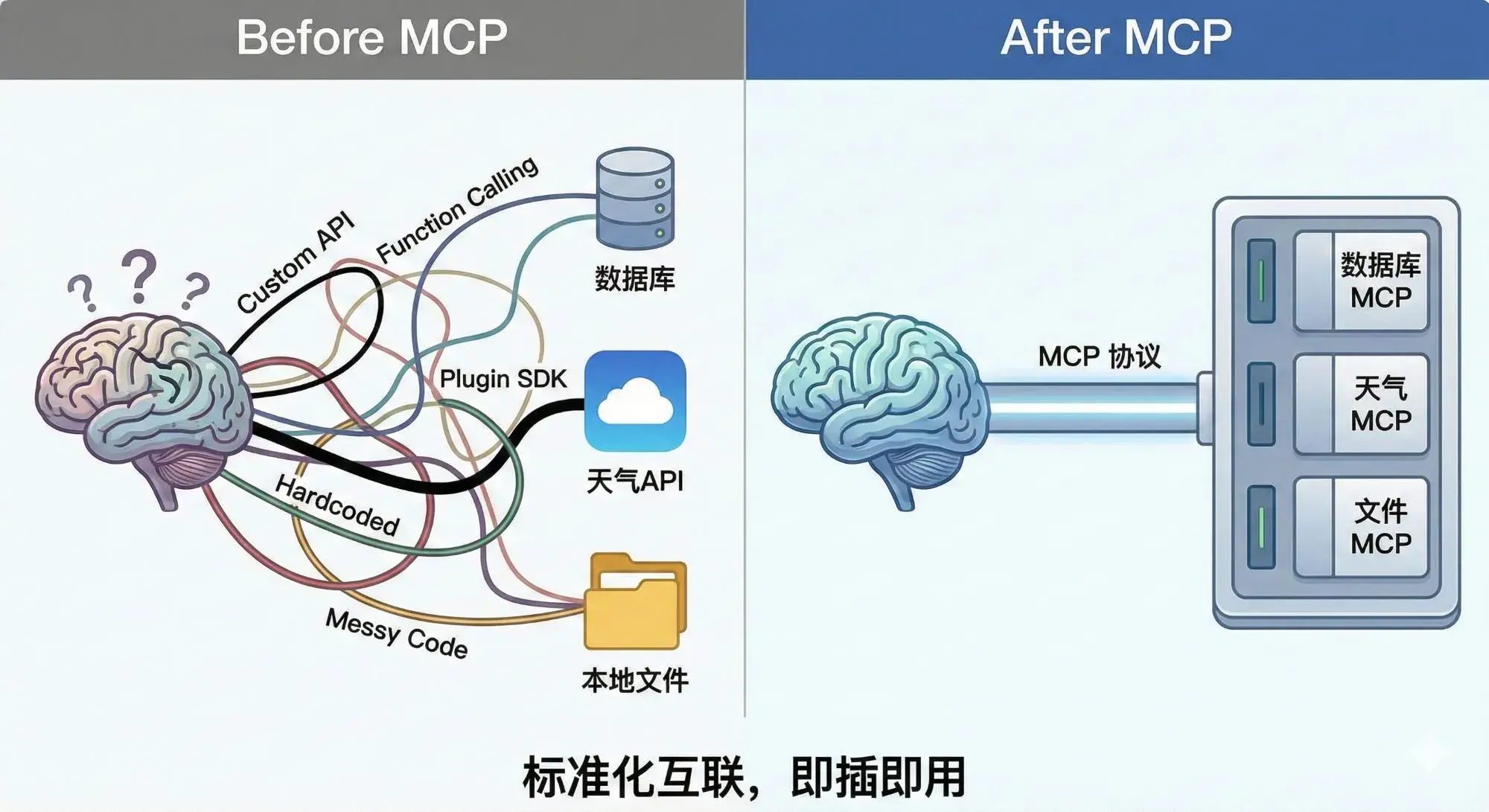
MCP 的核心思路,定一套行业标准接口
MCP(Model Context Protocol,模型上下文协议)的设计思路,可以用 USB 接口来类比。在 USB 标准出现之前,鼠标用这个接口、键盘用那个接口、打印机又是另一个,换台电脑就要愁接口不兼容。USB 出现之后,所有外设统一接口,任何设备插到任何电脑都能工作,设备厂商只需要做一次适配,全球所有 USB 电脑都能用。
MCP 做的是同一件事:为「AI 接工具」这件事定了一套统一的协议标准。工具提供方(比如 GitHub 官方)按 MCP 规范实现一个 MCP Server,里面封装好各种操作。任何支持 MCP 的 AI 客户端,Claude Desktop、Cursor、各种 Agent 框架,都能直接连上这个 Server,自动发现里面的工具并使用,不需要写任何定制化对接代码。工具只需要实现一次,到处复用。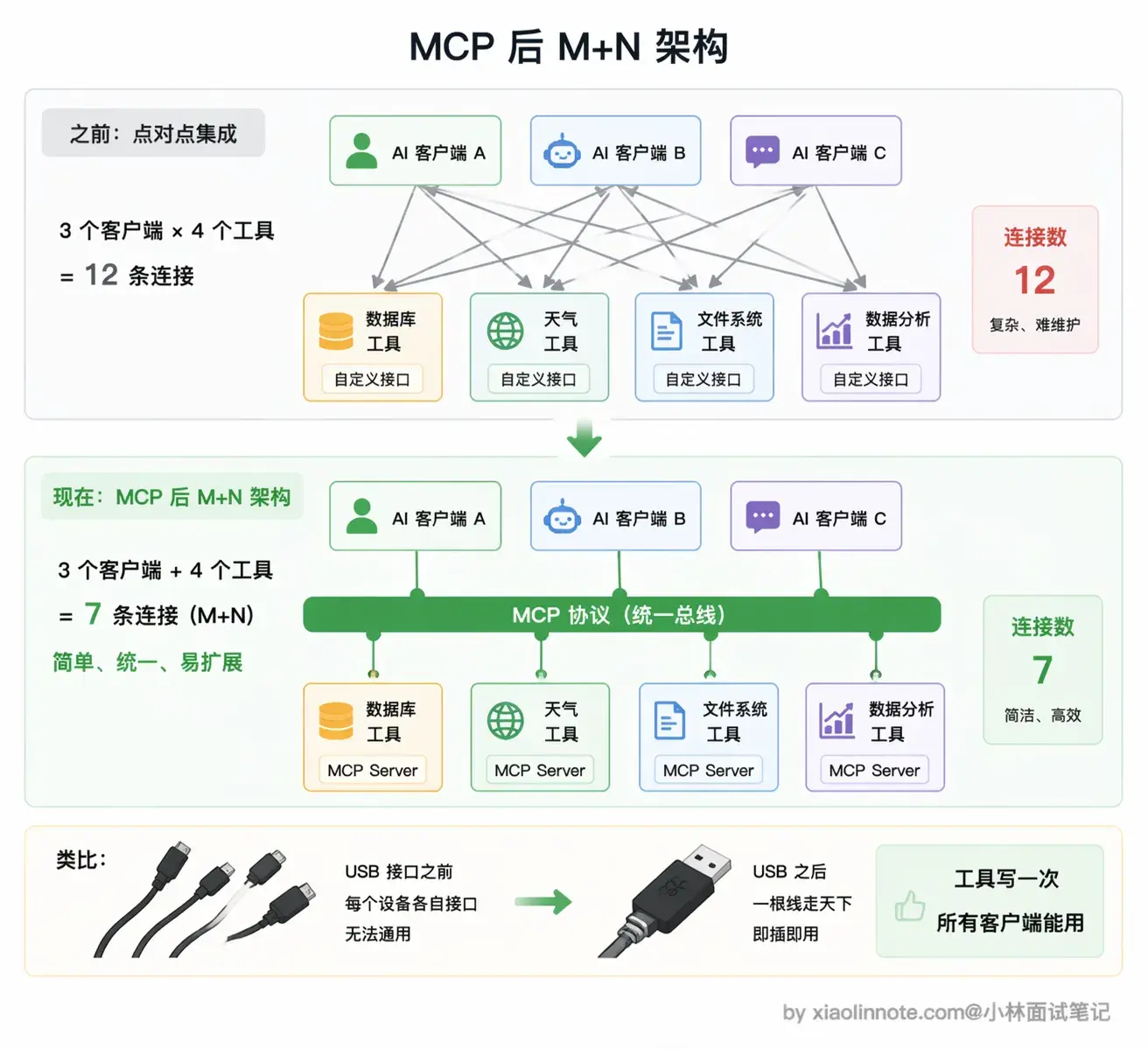
MCP 的 Client-Server 架构
MCP 采用标准的 Client-Server 架构。
Server 是工具的实现方。比如 GitHub 官方维护一个 GitHub MCP Server,里面封装了「列出 PR」「创建 Issue」「搜索仓库」「查看 Diff」等操作;Client 是 AI 应用那一侧,比如 Claude Desktop 或 Cursor,连上 Server 之后就自动获得了这些工具能力。
一个 Client 可以同时连接多个 Server。你把文件系统 Server + GitHub Server + PostgreSQL Server 都接上,模型就同时拥有了操作本地文件、读写代码仓库、查询数据库这三套工具能力,而你不需要写任何对接代码,只需要在配置文件里加几行 JSON,重启后 Claude 自动发现并使用这些工具。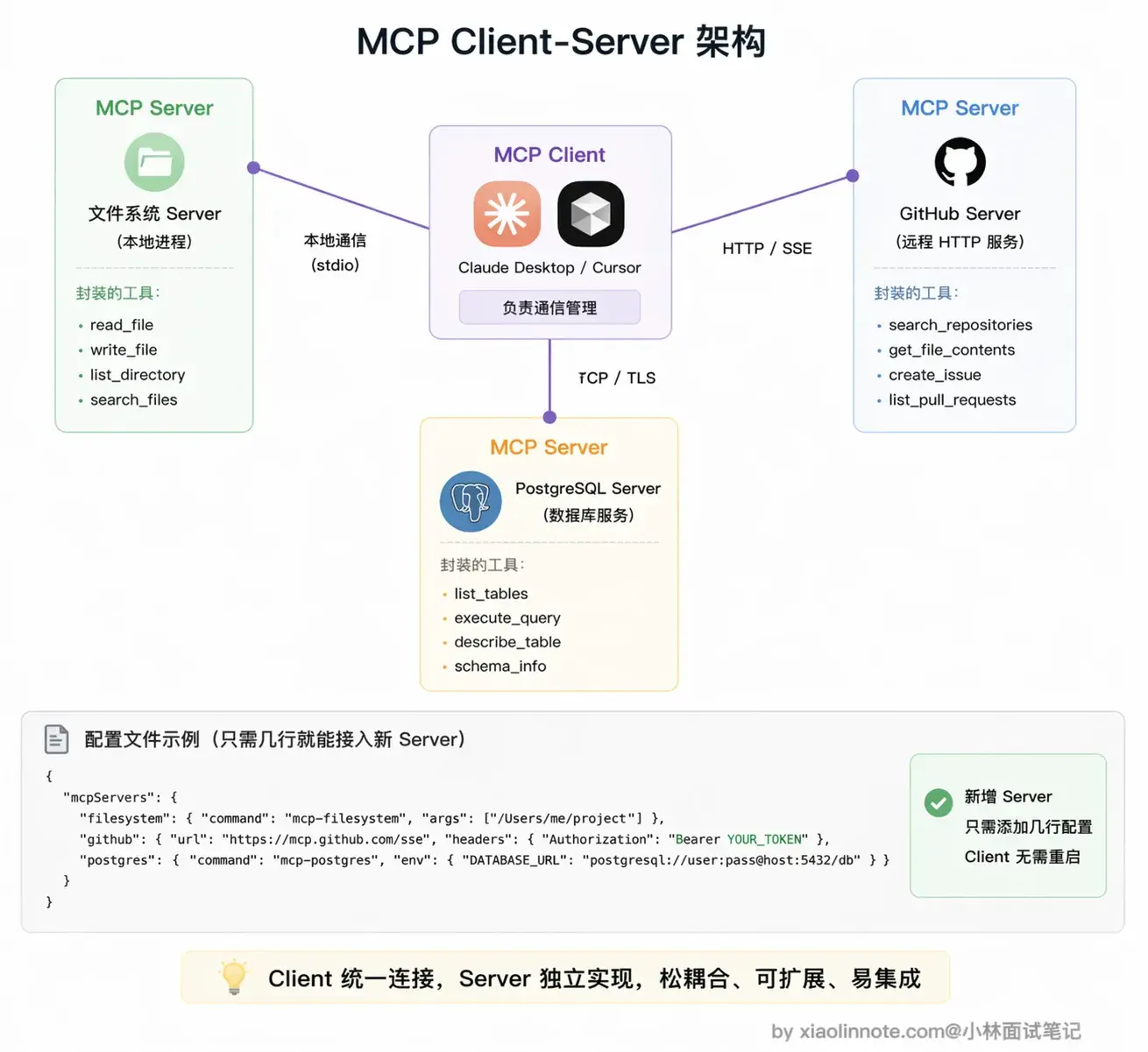
三类核心能力,Tools、Resources、Prompts
MCP Server 可以向 Client 暴露三类能力,各有各的定位。
先说 Tools(工具),这是最核心的能力,对应 Function Calling 里的「函数」。Tools 的本质是「有副作用的操作」,什么叫有副作用?就是执行之后会改变外部世界的状态。创建文件、提交代码、发送 Slack 消息、调用第三方 API,这些都属于 Tools,因为执行完之后环境发生了变化,而且往往不可逆。正因为如此,Tools 通常需要用户授权确认才能执行,不能让模型想调就调。
再说 Resources(资源),它和 Tools 最本质的区别就一个字:只「读」。Resources 不会改变任何东西,只是把数据提供给模型看。读取日志文件、查询数据库记录、获取文档内容,都属于 Resources 的范畴。你可以把 Resources 理解成「工具的资料室」,模型可以进去查资料,但不能修改里面的东西。正因为只读、无副作用,Resources 可以更宽松地暴露给模型,不需要像 Tools 那样谨慎授权。
最后是 Prompts(提示模板),这个能力很多人容易忽略,但在团队协作场景下特别有用。Prompts 就是预定义的提示词模板,带参数占位符,解决的是「每次都要手写重复 prompt」的问题。举个例子,你的团队有一套固定的代码审查标准 prompt,接受「编程语言」和「代码内容」两个参数,调用时只需传入参数值,就能自动展开成完整的提示词,不用每次从头写。把公司积累的优质 prompt 封装成 MCP Prompts,所有人都能复用,统一标准,这在实际工程中很实用。
底层通信,JSON-RPC 2.0 是什么
理解 MCP 的底层,先要知道 JSON-RPC 是什么。
JSON-RPC 是一种轻量级的远程函数调用协议,用 JSON 格式来表达「调用」这件事。核心非常简单:客户端发一个 JSON 请求,里面说清楚「调哪个方法、参数是什么、这次请求的 ID 是多少」;服务端执行完,返回一个 JSON 响应,里面是执行结果或者错误信息。用 JSON 而不是二进制格式,好处是易读、易调试、语言无关,任何编程语言都能轻松实现。MCP 用的是它的 2.0 版本(JSON-RPC 2.0),相比 1.0 加了批量请求、通知消息等功能。
在传输层,MCP 支持两种方式。
第一种是 stdio(标准输入输出),Server 作为本地子进程运行,Client 通过管道和它通信,Server 从 stdin 读消息,把结果写到 stdout。这种方式适合本地工具,不需要网络,启动快、延迟低,Claude Desktop 接本地 MCP Server 用的就是这种方式。
第二种是 Streamable HTTP,Server 作为 HTTP 服务部署在远程,Client 通过 HTTP 连接和它通信。这种方式适合远程部署的工具服务,或者需要多个 Client 共享同一个 Server 的场景,比如团队共用一个部署在服务器上的数据库 MCP Server,所有人的 AI 客户端都连同一个地址就行。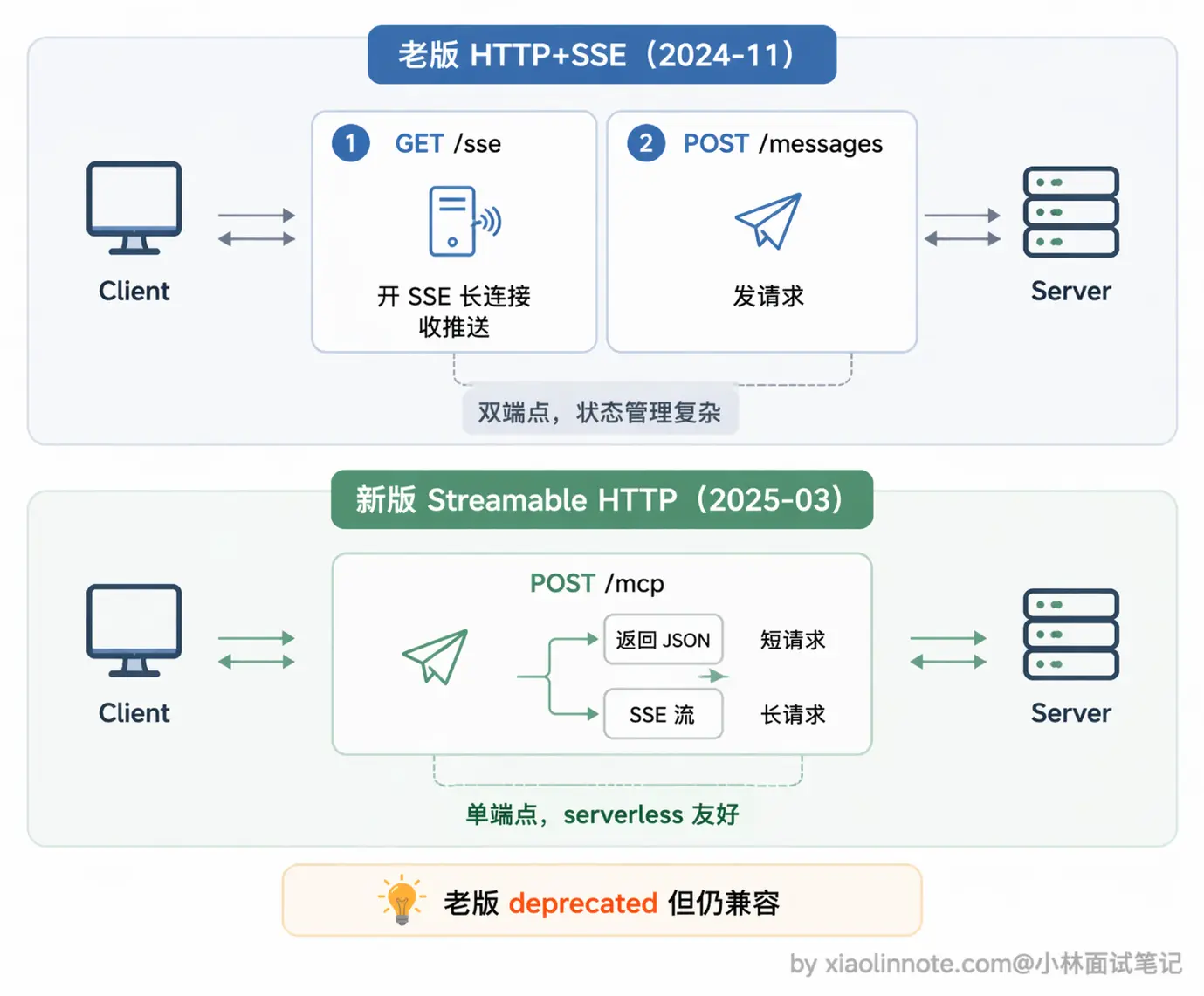
这里有个演进要说清楚:MCP 早期版本(2024-11-05 规范)用的是「HTTP + SSE」双端点方案,一个 GET 端点开 SSE 长连接接收推送,一个 POST 端点发请求,两个端点绑在一起工作。2025 年 3 月的规范更新里,这套方案被改成了 Streamable HTTP(老的 HTTP+SSE 被标记为 deprecated,但仍保留向后兼容)。
Streamable HTTP 并不是「抛弃 SSE」,而是把原来的两个端点合并成一个 /mcp 端点。Client 用 POST 发请求,Server 根据情况灵活返回:短请求直接回一个普通 JSON 响应,长请求则把这个 HTTP 响应升级为 SSE 流,持续推送中间结果。架构更简洁,部署也更友好(一个端点就够,serverless 环境也能跑),本质还是 HTTP 加 SSE,只是用法变了。
MCP 生态发展这么快,背后的原因是什么
MCP 是 Anthropic 在 2024 年底发布的,发布后发展速度很快,主要有两个原因。
第一个原因是极低的实现门槛。Anthropic 开源了协议规范和多语言 SDK(Python、TypeScript 都有),写一个最简单的 MCP Server 不到 30 行代码,任何有基础编程经验的人都能上手。协议文档也写得清晰,社区很快就爆发出大量贡献。你想想,一个新技术如果上手成本很高,再好的设计也很难推广开,MCP 在这一点上做得很聪明。
第二个原因是头部工具第一时间跟进。GitHub、Slack、PostgreSQL、Puppeteer(浏览器自动化)、Google Maps 等高频工具都有了官方或社区维护的 MCP Server,开发者不需要自己写,直接用现成的就行。接一个新工具,在 Claude Desktop 的配置文件里加几行 JSON,重启后 Claude 自动发现并使用,整个过程零代码。当生态里可用的工具足够多,开发者就更愿意采用这套协议,形成了正向循环。
目前 Claude Desktop、Cursor、Windsurf 等主流 AI 工具都内置了 MCP 支持。对开发者来说,MCP 把「给 AI 接工具」这件事的门槛从「写一堆对接代码」降到了「改一行配置」,这才是它被快速采用的核心原因。
5. MCP 由哪几部分组成?
MCP 由三层组成,可以从角色、能力、协议三个维度来理解。
角色层有三个:Host 是 AI 应用本身(比如 Claude Desktop),Client 是 Host 里负责和 Server 通信的模块,Server 是工具提供方实现的独立进程,一个 Host 可以同时连多个 Server。
能力层定义了 Server 能暴露三类东西:Tools 是有副作用的操作(比如创建文件、调 API),Resources 是只读数据(比如读取文档内容),Prompts 是预定义的提示词模板。
协议层是底层通信:消息格式统一用 JSON-RPC 2.0,传输方式支持 stdio(本地子进程通信)和 Streamable HTTP(远程 HTTP 连接)两种,早期的 HTTP+SSE 双端点方案在 2025 年 3 月的规范更新里被标记为 deprecated。
这三层合在一起,就是 MCP 的完整组成。
先建立整体感:三层来看就清楚了
很多人第一次接触 MCP 会被各种概念搞乱,什么 Host、Client、Server、Tools、Resources、Prompts、JSON-RPC、stdio、SSE……一堆名词扔过来,确实容易懵。其实你只要把它拆成三层来看就清楚了:第一层是角色架构,搞清楚谁和谁在通信;第二层是能力类型,搞清楚 Server 能暴露什么东西给模型用;第三层是传输协议,搞清楚消息是怎么传的。
这三层各自独立、互不耦合,合在一起就是 MCP 的完整骨架。下面我一层一层拆开来讲。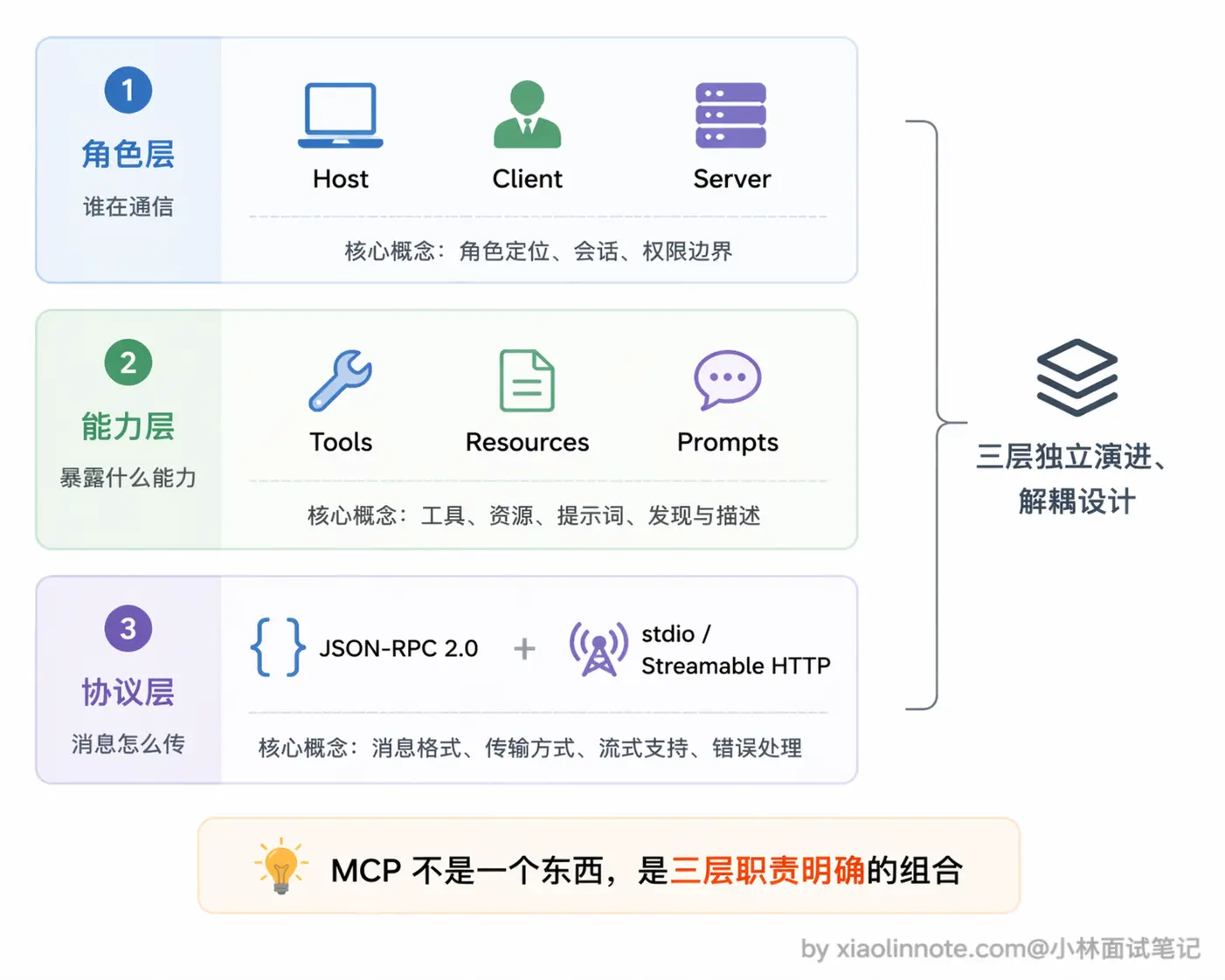
第一层:角色架构,Host / Client / Server
MCP 定义了三个角色,弄清楚每个角色负责什么是理解整个系统的关键。
先说 Host。Host 是整个系统的宿主,也就是你在用的 AI 应用本身,比如 Claude Desktop、Cursor、Windsurf。Host 负责启动和管理所有 MCP Client,控制连哪些 Server、什么时候断开连接,是整个 MCP 系统的调度中心。你可以把 Host 理解成一家公司,它决定要和哪些外部供应商(Server)合作,并派出自己的联络员(Client)去对接。
再说 Client。Client 是 Host 内部的连接模块,一个 Client 对应一个 Server 连接。它负责三件事:初始化和 Server 的连接、向 Server 查询「你有哪些工具/资源/模板」(能力发现)、把模型的调用请求转发给 Server 并把结果带回来。Client 是 Host 派出的「驻场联络员」,专门负责和某一个 Server 打交道,Host 本身不直接和 Server 说话。
最后是 Server。Server 是工具提供方实现的独立进程,对外暴露自己的工具、资源和提示词模板。Server 完全不关心上面是哪个 Host 在用它,只需要按 MCP 协议响应 Client 的请求就行。这也是 MCP 的核心价值所在:Server 写一次,任何支持 MCP 的 Host 都能直接用,GitHub 的官方 MCP Server 不需要分别为 Claude Desktop 和 Cursor 各写一份。
三者的关系用图来看是这样的: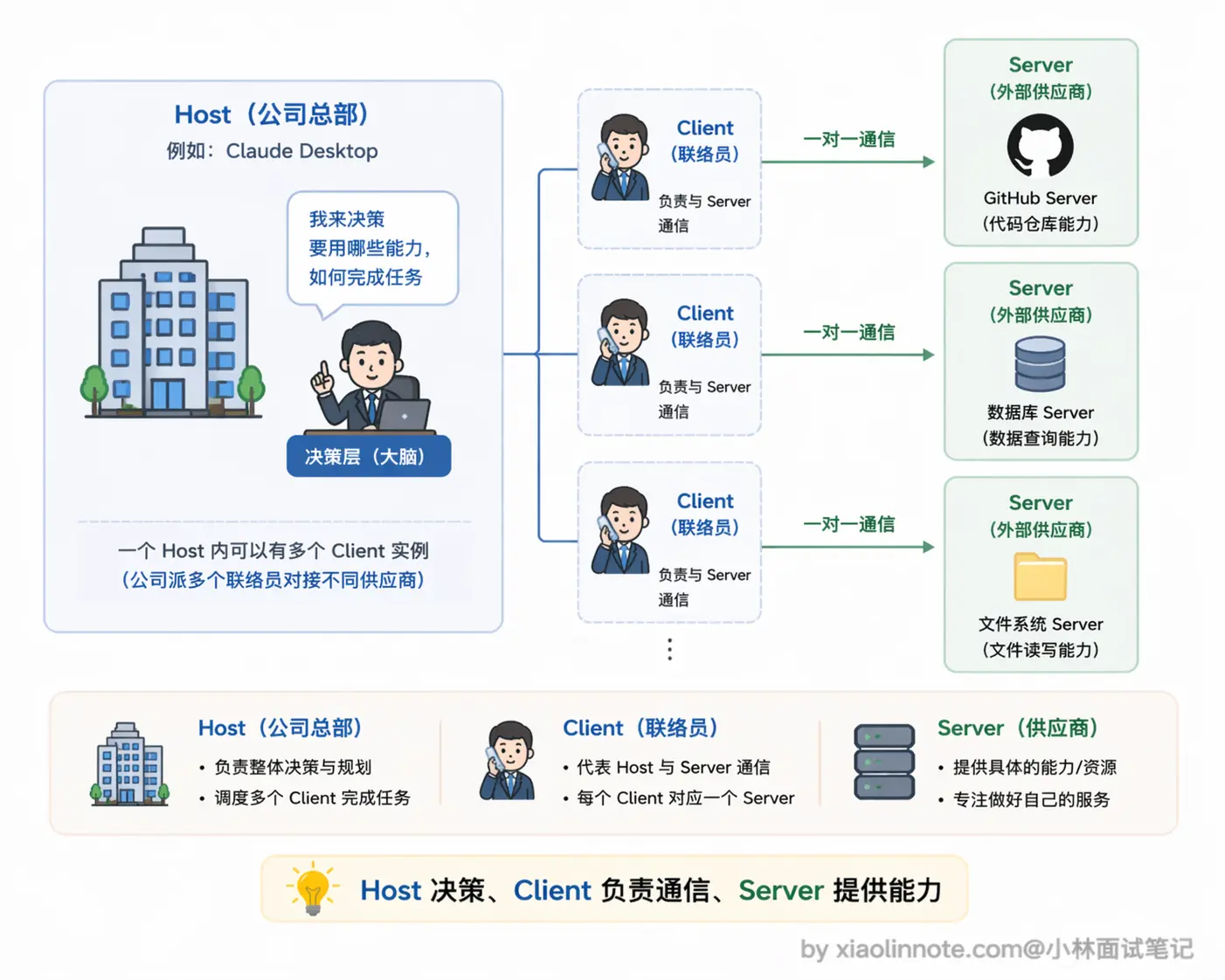
一个 Host 同时连多个 Server,模型就同时拥有了所有这些工具能力,而应用代码完全不需要为此多写一行。
第二层:能力类型,Tools / Resources / Prompts
理解了角色分工,接下来看 Server 到底能暴露什么给 Client。很多人以为 Server 就只提供「工具」,其实不止,MCP 定义了三类能力,每类解决不同的需求,设计上有明确的职责分工。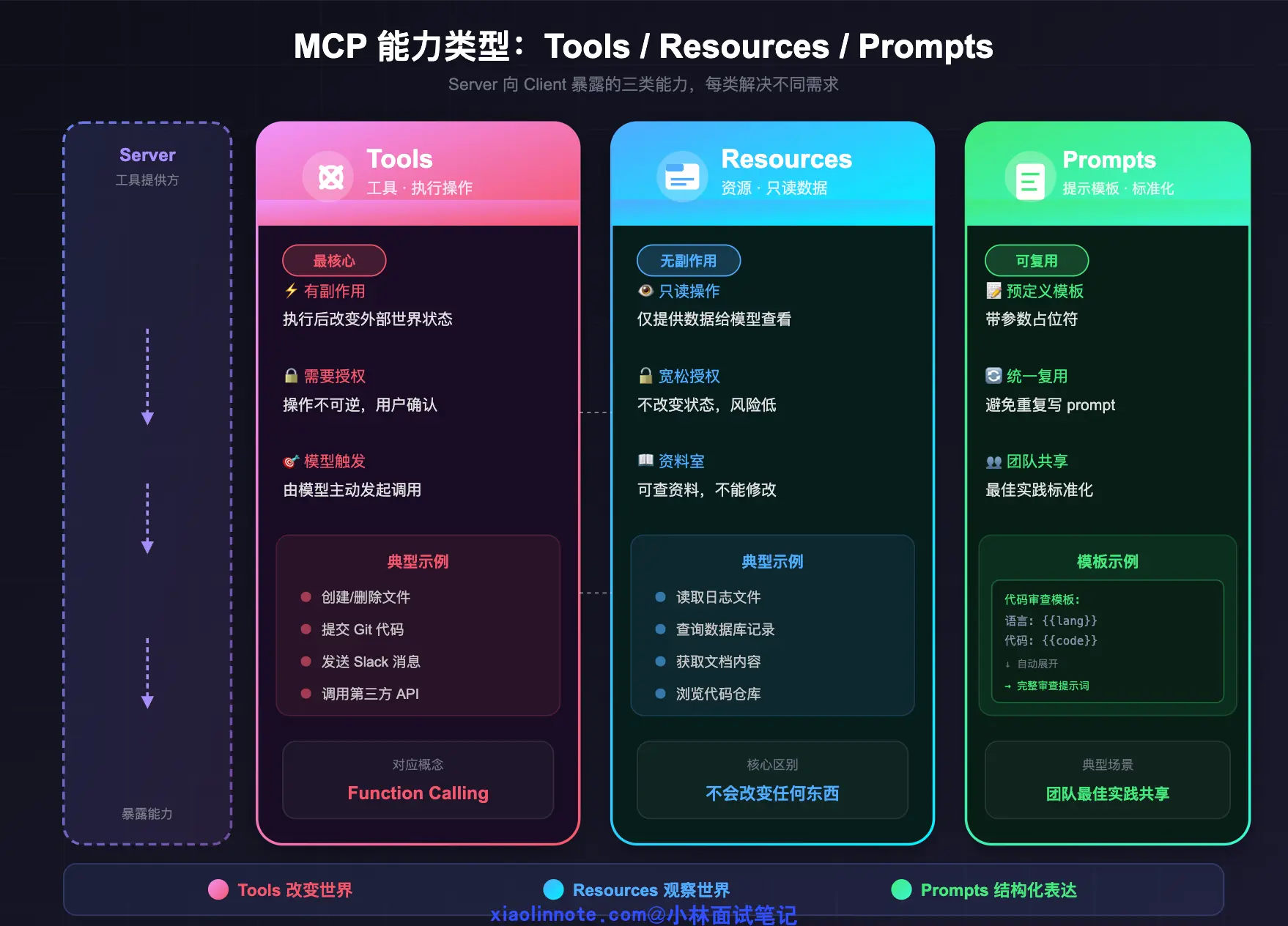
第一类是 Tools(工具),这是最核心、使用最频繁的能力,对应的是有副作用的操作,执行之后会改变外部世界的状态。创建文件、提交代码、发送 Slack 消息、调用第三方 API,都属于 Tools。由模型主动触发,执行有不可逆性,所以通常需要用户授权确认。Tools 对应 Function Calling 里「函数」的概念,只是在 MCP 框架下被标准化打包了。
第二类是 Resources(资源),这是只读数据,没有任何副作用,只是把数据提供给模型看。读取日志文件、查询数据库记录、获取文档内容,都是 Resources。和 Tools 最本质的区别是什么呢?Resources 不会改变任何东西,可以更宽松地暴露,不需要像 Tools 那样谨慎授权。你可以把 Resources 理解成「工具的资料室」,可以进去查资料,但不能修改里面的东西。
第三类是 Prompts(提示模板),这是预定义的提示词模板,带参数占位符。它解决的是「每次都要手写重复 prompt」的问题。比如把团队固定的代码审查标准封装成模板,接受「编程语言」和「代码内容」两个参数,调用时只需传参,自动展开成完整提示词,不用每次从头写。这个能力特别适合团队内部的最佳实践共享,把积累的优质 prompt 模板化,所有人统一复用,标准也更一致。
三者的本质区别可以这样记:Tools 改变世界,Resources 观察世界,Prompts 结构化表达。
第三层:传输协议,JSON-RPC 2.0 + 传输方式
Client 和 Server 之间的通信由两部分组成:消息格式和传输方式,这两层是解耦的。
消息格式统一用 JSON-RPC 2.0。每条消息是一个 JSON 对象,格式固定:Client 发请求时说清楚「调哪个方法、参数是什么、这次请求的 ID 是多少」,Server 返回响应时带上执行结果或错误信息,通过 ID 匹配请求和响应。用 JSON 格式的好处是易读、易调试、任何编程语言都能实现,不管 Server 是 Python 写的还是 TypeScript 写的,消息格式是一样的。
// Client 向 Server 查询工具列表
{"jsonrpc": "2.0", "id": 1, "method": "tools/list", "params": {}}
// Server 返回工具列表
{"jsonrpc": "2.0", "id": 1, "result": {"tools": [{"name": "read_file", ...}]}}
// Client 请求调用某个工具
{"jsonrpc": "2.0", "id": 2, "method": "tools/call", "params": {"name": "read_file", "arguments": {"path": "/tmp/log.txt"}}}那消息格式定了,怎么传呢?MCP 支持两种传输方式,适合不同的部署场景。
第一种是 stdio(标准输入输出),Server 作为本地子进程运行,Host 通过操作系统的管道和它通信,Server 从 stdin 读请求、把结果写到 stdout。这种方式适合本地工具,不需要网络,延迟极低,也没有端口占用和网络安全问题,Claude Desktop 接本地 MCP Server 走的就是这种方式。
第二种是 Streamable HTTP,Server 作为 HTTP 服务独立部署,Client 通过 HTTP 连接和它通信。这种方式适合远程部署的场景,支持多个 Client 共享同一个 Server,比如团队共用一个部署在服务器上的数据库 MCP Server,所有人连同一个服务,不需要各自本地跑一份。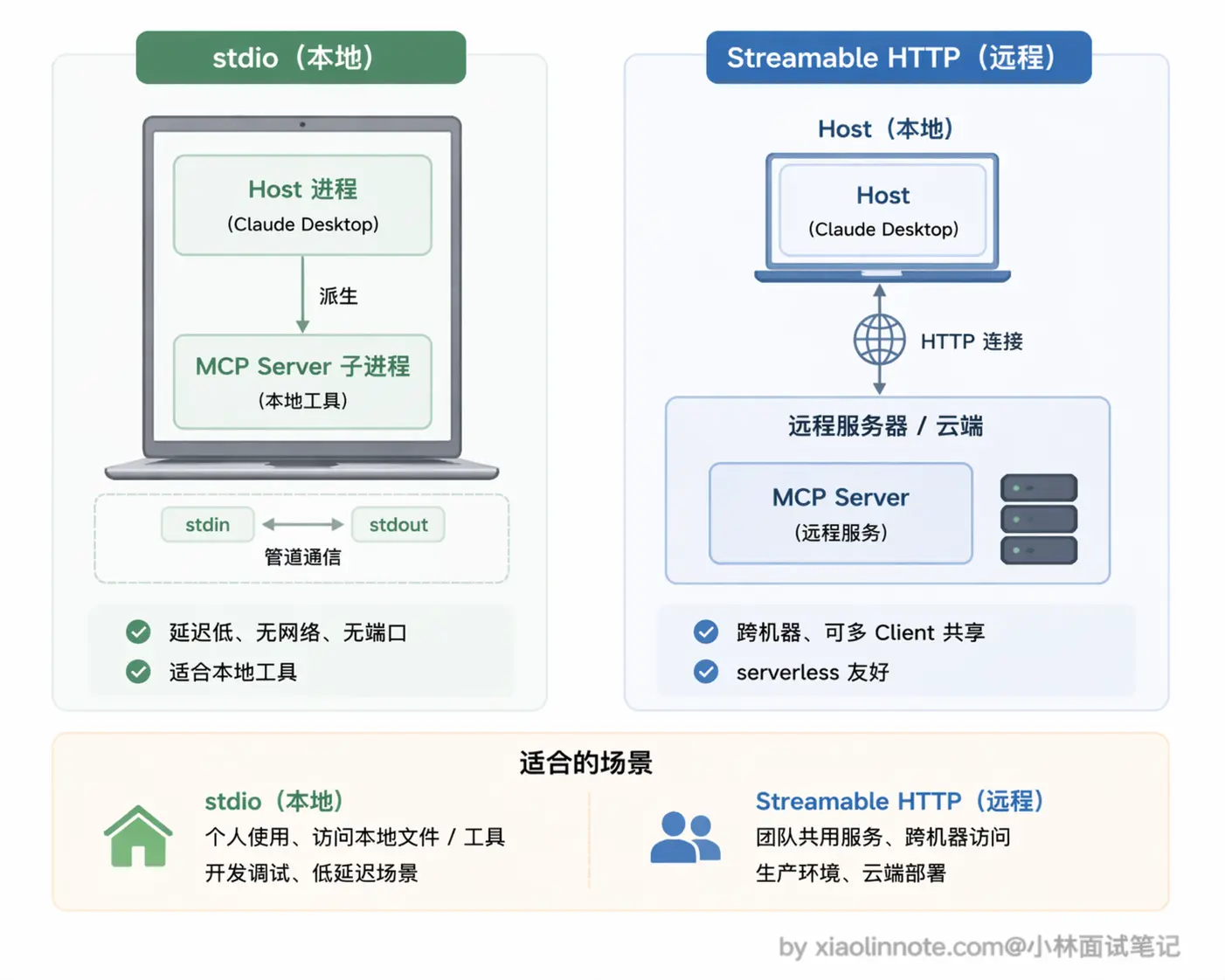
这里有个演进要说清楚:MCP 早期(2024-11-05 规范)的远程传输方案叫「HTTP + SSE」,是双端点结构,一个 GET 端点开 SSE 接收 Server 推送,一个 POST 端点用来发请求。这套方案在 2025 年 3 月的规范更新里被改成了单端点的 Streamable HTTP(老的 HTTP+SSE 被标记为 deprecated,但保留向后兼容)。
Streamable HTTP 并不是抛弃 SSE,而是把双端点合并成一个 /mcp。Client 用 POST 发请求,Server 根据情况灵活返回:短请求直接回普通 JSON,长请求则把 HTTP 响应升级为 SSE 流持续推送中间结果。这样一个端点就能干完所有事,对负载均衡器和 serverless 环境都更友好。
这里有一个很重要的设计点:消息格式(JSON-RPC 2.0)和传输方式(stdio / Streamable HTTP)是解耦的,同一套 JSON-RPC 消息可以跑在任意传输层上,切换传输方式不影响上层的工具调用逻辑。这个设计让 MCP Server 既可以轻量地作为本地进程运行,也可以作为正式的微服务部署,实现方式灵活但协议层始终一致。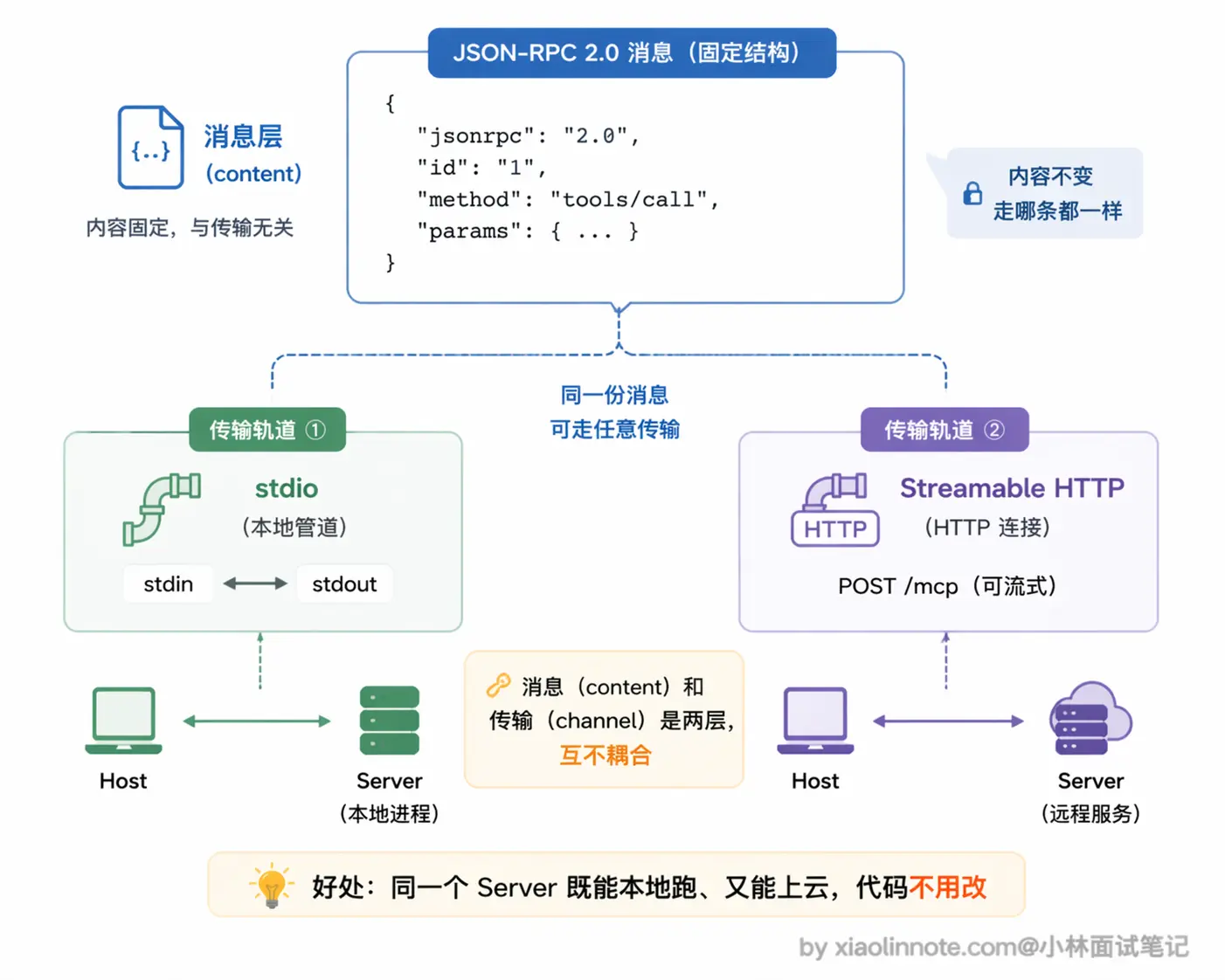
面试回答这道题,第一个要点是三层结构要说清楚:角色层(Host / Client / Server)、能力层(Tools / Resources / Prompts)、协议层(JSON-RPC 2.0 + stdio / Streamable HTTP)。
特别是 Host 和 Client 的区别,Host 是宿主应用本身,Client 是 Host 内部负责和 Server 通信的模块,一个 Host 可以同时连多个 Server,这个一对多的关系是 MCP 的核心设计。
第二个容易踩的雷是把 Server 暴露的能力全归为「工具」。Tools、Resources、Prompts 三者职责分明,Tools 有副作用、改变外部状态,Resources 是只读数据、没有副作用,Prompts 是提示词模板。面试时说清楚三者的区别,尤其是 Tools 和 Resources 的本质差异(有无副作用),会让面试官觉得你真正理解了 MCP 的设计意图,而不是只停留在表面。
第三个要提到的是协议层的解耦设计:消息格式和传输方式是独立的,JSON-RPC 2.0 定义了消息长什么样,stdio 和 Streamable HTTP 定义了消息怎么传,两者互不耦合,这也是 MCP 灵活性的来源。
6. MCP 和 Function Calling 有什么区别?有没有实际跑过 MCP?
我理解这两者不是竞争关系,解决的不是同一层面的问题。
Function Calling 是「调用语言」,定义的是模型怎么表达「我要调哪个函数、参数是什么」;MCP 是「工具生态协议」,定义的是工具怎么标准化打包、注册和被 AI 客户端发现。
MCP 底层其实还是用 Function Calling 来触发工具调用,只是在它之上加了一套工具管理框架,让工具实现一次、到处复用。
打个比方:Function Calling 像 HTTP 请求格式,MCP 像 REST API 的设计规范加服务注册发现机制,两者是不同层次的东西。
关于实际跑过的经验,我用 Claude Desktop 配过文件系统和 GitHub 的 MCP Server,在配置文件里加几行就能用,Claude 会自动发现工具,完全不用写对接代码。
Function Calling 有了,为什么还需要 MCP?
很多人第一次看到 MCP 会有一个直觉困惑:Function Calling 不是已经能调工具了吗,模型想用工具直接定义 schema 就行,为什么还要再搞一个协议出来?
这个困惑的根源,是把「能调工具」和「管好工具」混在一起了。这两件事完全是不同层次的问题。
有一个很好的类比可以帮你理解:HTTP 协议出来之后,我们已经能在网络上传数据了,为什么还需要 REST API 规范?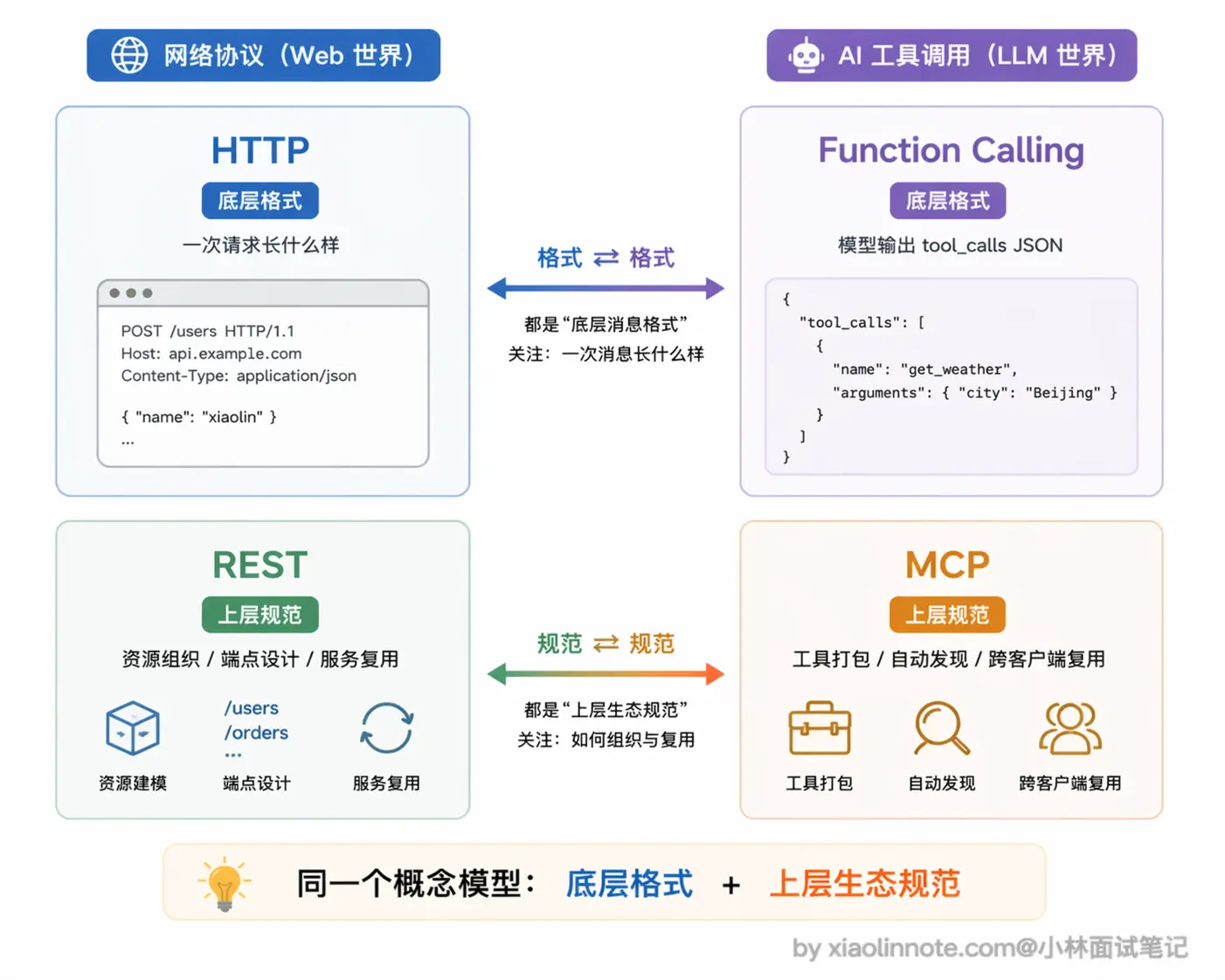
因为 HTTP 解决的是「怎么传」(一次请求长什么样、用什么方法、怎么编码),REST 解决的是「怎么组织和管理」(资源怎么命名、端点怎么设计、状态怎么表达、多个服务之间怎么复用同一套约定),两者是不同层次的事。
Function Calling 和 MCP 也是同样的关系:Function Calling 管「一次函数调用请求长什么样」,MCP 管「一堆工具怎么被组织、发现、跨项目复用」。前者是格式,后者是规范+生态约定,少了谁这套机制都运转不起来。
Function Calling 解决的是「一次调用」的格式问题
从开发者视角看,Function Calling 回答的是这几个问题:工具定义用什么格式传给模型?模型想调工具时怎么表达「我要调哪个函数、参数是什么」?工具执行结果怎么喂回对话?
它定义的是单次调用的消息格式,仅此而已。每次使用,开发者都要手动写工具的 schema 定义,手动写调用逻辑,手动处理结果。Function Calling 本身没有任何工具管理、工具发现、跨项目复用的概念。
Function Calling 的痛点,每次都是一次性的
那「每次手动」到底有多痛?你可能觉得复制一份 schema 也没多大工作量,但工具一多、项目一多,问题就暴露出来了。
假设你在 A 项目里定义了 10 个工具的 schema 和对接逻辑。现在 B 项目也要用这些工具,怎么办?把那 10 个 schema 定义复制过来,把对接逻辑重写一遍。好,写完了。但 A 项目用的是 Claude API,B 项目换成了 GPT-4,两边的 Function Calling 格式不完全一样,又得各自维护一套适配代码。这还没完,如果某个工具的接口改了呢?你得去每个用到它的项目里逐一更新,漏改一处就是 bug。
把这个账算一下你就知道痛点的规模了:假设你团队里有 5 个应用,每个应用要接 8 个工具,也就是 40 份工具对接代码在维护。某天 GitHub API 的某个字段变了,你要在 5 个地方同步改,只要其中一个忘了,那个应用在凌晨报警;再假设你要从 Claude 迁到 GPT-4,这 40 份代码里的 Function Calling 格式全要重新适配一遍,整个组的季度就这么交代了。
有没有发现问题?同一个工具,换个项目就要重新对接一遍,每次都是一次性的手工活。这就是 Function Calling 解决不了的核心问题:工具的管理、复用和跨平台兼容。
MCP 解决的是「工具生态」的问题
既然痛点是「每个应用各自维护一套工具定义」,那解决思路也就很自然了:把工具做成独立的标准化服务,谁要用就来连,不用每次都重写一遍。这就是 MCP 的核心思路。
工具提供方实现一个 MCP Server,这个 Server 是一个独立运行的进程,对外暴露标准接口,告诉外界「我有哪些工具、每个工具怎么调用」。任何支持 MCP 的 AI 客户端连上来,就能自动发现和使用里面的工具,完全不需要手写任何对接代码。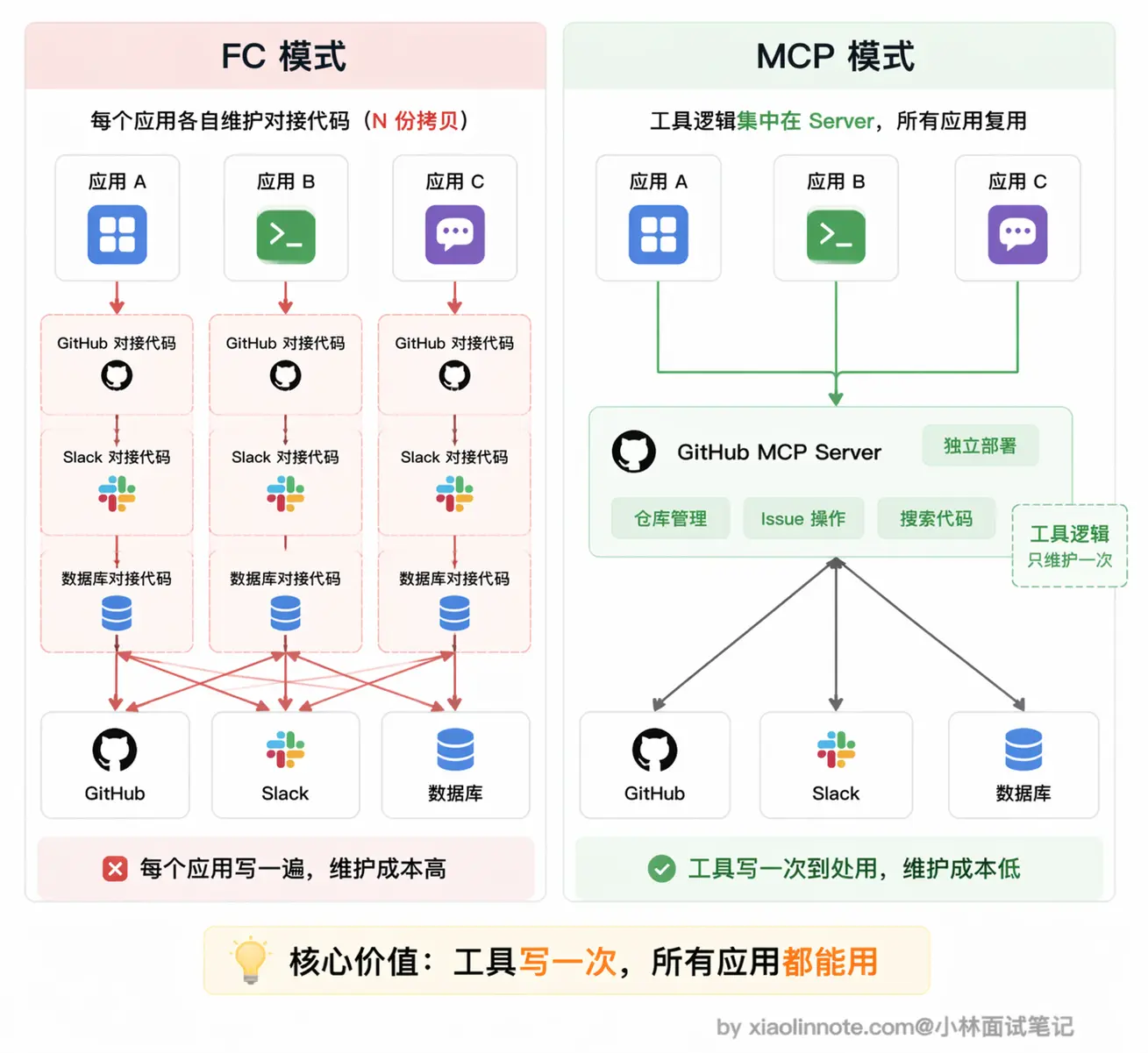 这带来的改变是质的:工具只需要实现一次,所有 AI 客户端都能用。GitHub 的官方 MCP Server 写好之后,不管你用 Claude Desktop、Cursor 还是自己写的 Agent,连上去就能用,不需要各自维护一份 GitHub API 的调用代码。这才是 MCP 的真正价值。
这带来的改变是质的:工具只需要实现一次,所有 AI 客户端都能用。GitHub 的官方 MCP Server 写好之后,不管你用 Claude Desktop、Cursor 还是自己写的 Agent,连上去就能用,不需要各自维护一份 GitHub API 的调用代码。这才是 MCP 的真正价值。
最关键的联系,MCP 底层依然靠 Function Calling 驱动
这是很多人没想清楚的一点:MCP 不是 Function Calling 的替代品,而是建立在 Function Calling 之上的。
当 MCP Client 连上一个 Server 之后,会自动向 Server 拉取所有工具的定义(调用 list_tools 接口),然后把这些定义转换成模型原生的 Function Calling 格式传给模型。模型依然通过输出 tool_calls 来表达「我要调哪个工具」,MCP Client 再把这个请求路由到对应的 Server 去执行,拿到结果后以 tool 消息的形式喂回对话。
从模型的视角来看,它完全感知不到 MCP 的存在,它以为自己只是在做普通的 Function Calling,根本不知道背后有一套 Server 在运行。MCP 的所有「魔法」都发生在宿主程序层:工具的自动发现、schema 的格式转换、调用请求的路由、执行结果的返回,全都在这一层默默完成。
这也意味着一件事:如果模型本身不支持 Function Calling,MCP 就完全没办法用,因为这个「翻译层」失效了。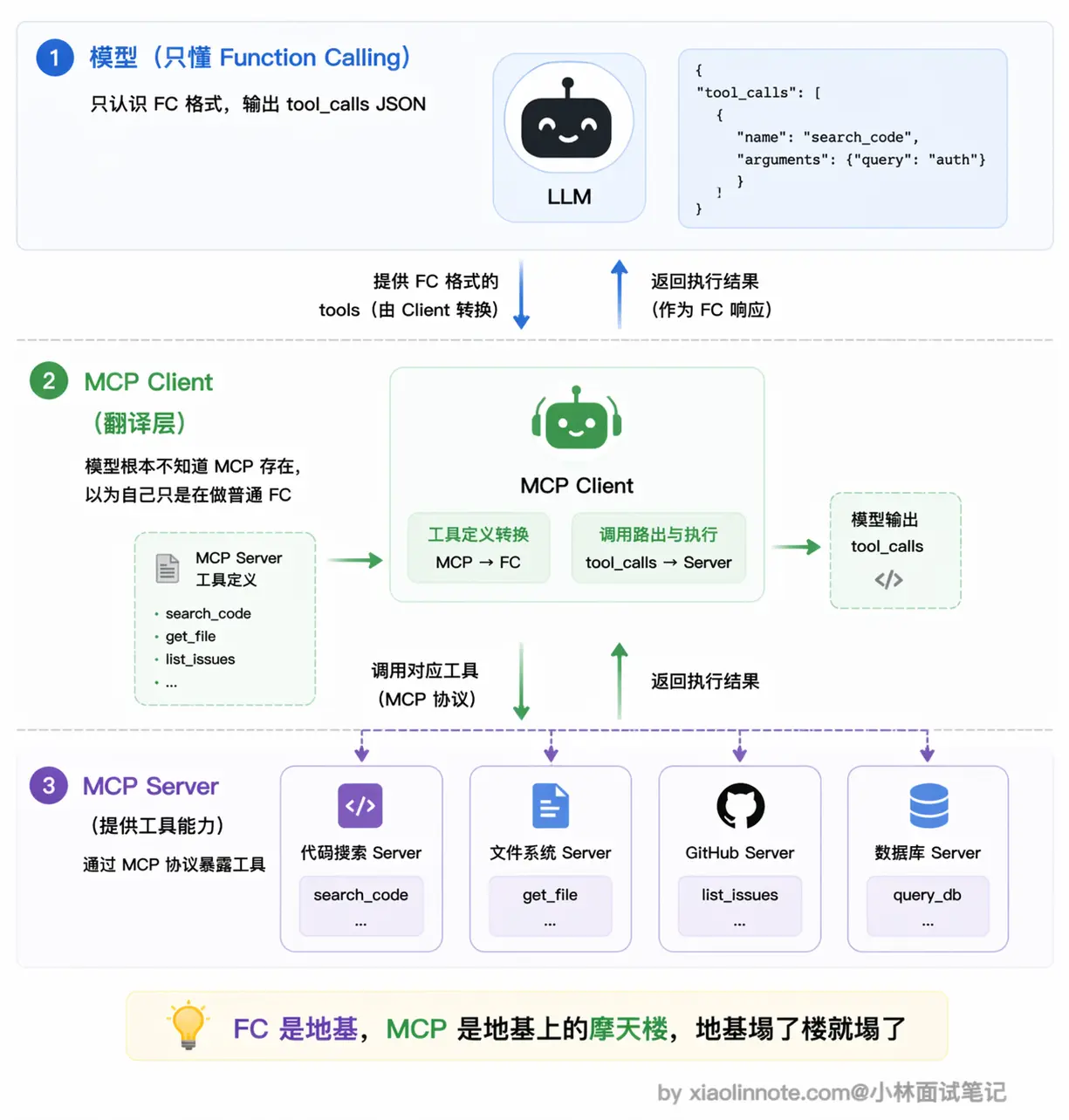
实际体验,接入一个 MCP Server
以 Claude Desktop 接入文件系统 MCP 为例。只需要编辑 claude_desktop_config.json,加入如下配置:
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/Users/yourname/Documents"
]
}
}
}这几行配置告诉 MCP Client:用 npx 这个命令启动文件系统 Server,把 /Users/yourname/Documents 目录作为允许访问的范围。command 和 args 组合起来就是启动 Server 进程的命令行,MCP Client 会把它作为子进程启动,通过标准输入输出和它通信。
配好之后重启 Claude Desktop,它会自动启动这个 Server 进程,自动发现里面提供的工具。然后你直接问 Claude「帮我读一下 Documents 里的 report.md」,Claude 会自动调用文件系统工具完成任务,全程你没写一行对接代码。
如果想自己写一个 MCP Server,其实也很简单。核心就三步:首先用 @app.list_tools() 装饰器告诉 Client 这个 Server 提供哪些工具及其参数格式,然后用 @app.call_tool() 装饰器实现每个工具的真实执行逻辑,最后用 stdio 方式运行,让 Client 能通过管道和它通信。
完整的代码如下:
import asyncio
from mcp.server import Server
from mcp.server.stdio import stdio_server
from mcp.types import Tool, TextContent
# 1. 创建一个 Server 实例,名字叫 "calculator"
app = Server("calculator")
# 2. 定义工具列表 (告诉 Client 我有什么功能)
@app.list_tools()
async def list_tools() -> list[Tool]:
return [
Tool(
name="add_numbers",
description="计算两个数字的和",
inputSchema={
"type": "object",
"properties": {
"a": {"type": "number", "description": "第一个数字"},
"b": {"type": "number", "description": "第二个数字"}
},
"required": ["a", "b"]
}
)
]
# 3. 实现工具的具体逻辑
@app.call_tool()
async def call_tool(name: str, arguments: dict) -> list[TextContent]:
if name == "add_numbers":
a = arguments.get("a", 0)
b = arguments.get("b", 0)
result = a + b
# 返回结果,必须是 TextContent 格式
return [
TextContent(
type="text",
text=f"计算结果: {result}"
)
]
# 如果工具名不认识,返回错误
return [TextContent(type="text", text=f"未知工具: {name}")]
# 4. 启动 Server (使用标准输入输出模式)
async def main():
async with stdio_server() as (read_stream, write_stream):
await app.run(
read_stream,
write_stream,
app.create_initialization_options()
)
if __name__ == "__main__":
asyncio.run(main())整个 Server 加起来不超过 30 行代码,Anthropic 开源的 MCP SDK 把底层通信都封装好了。
然后编辑你的 claude_desktop_config.json,添加这个 Python 服务:
{
"mcpServers": {
"calculator": {
"command": "python",
"args": [
"/path/to/your/calculator_server.py"
]
}
}
}注意这里的路径要改成你自己实际存放文件的绝对路径,如果你的系统中 Python 命令是 python3,也要把 command 对应改过来。
配好之后重启 Claude Desktop,直接输入「帮我算一下 25 加 17 等于多少」,Claude 就会自动调用你写的 add_numbers 工具并返回结果。整个过程你只写了工具逻辑本身,所有的通信、发现、调用路由都由 MCP 框架搞定了。
什么时候选哪个
如果只是临时给自己的应用接一两个工具,Function Calling 就够用了,简单直接,不需要引入额外的进程和协议。
但如果工具多了、需要跨项目复用、或者想直接用社区里已有的成熟 Server(GitHub、数据库、浏览器自动化都有现成的),MCP 就值得上了。接一个新工具就是在配置文件里加几行,重启后自动生效,比手写对接代码省事很多。
做 Agent 系统的话更应该考虑 MCP。工具来源杂、数量多,如果全靠手写 Function Calling 来维护,工具定义代码会散落在各处,很难管理。MCP 的自动发现和统一管理能让架构干净很多,新增工具不需要改主程序逻辑,接上 Server 就行。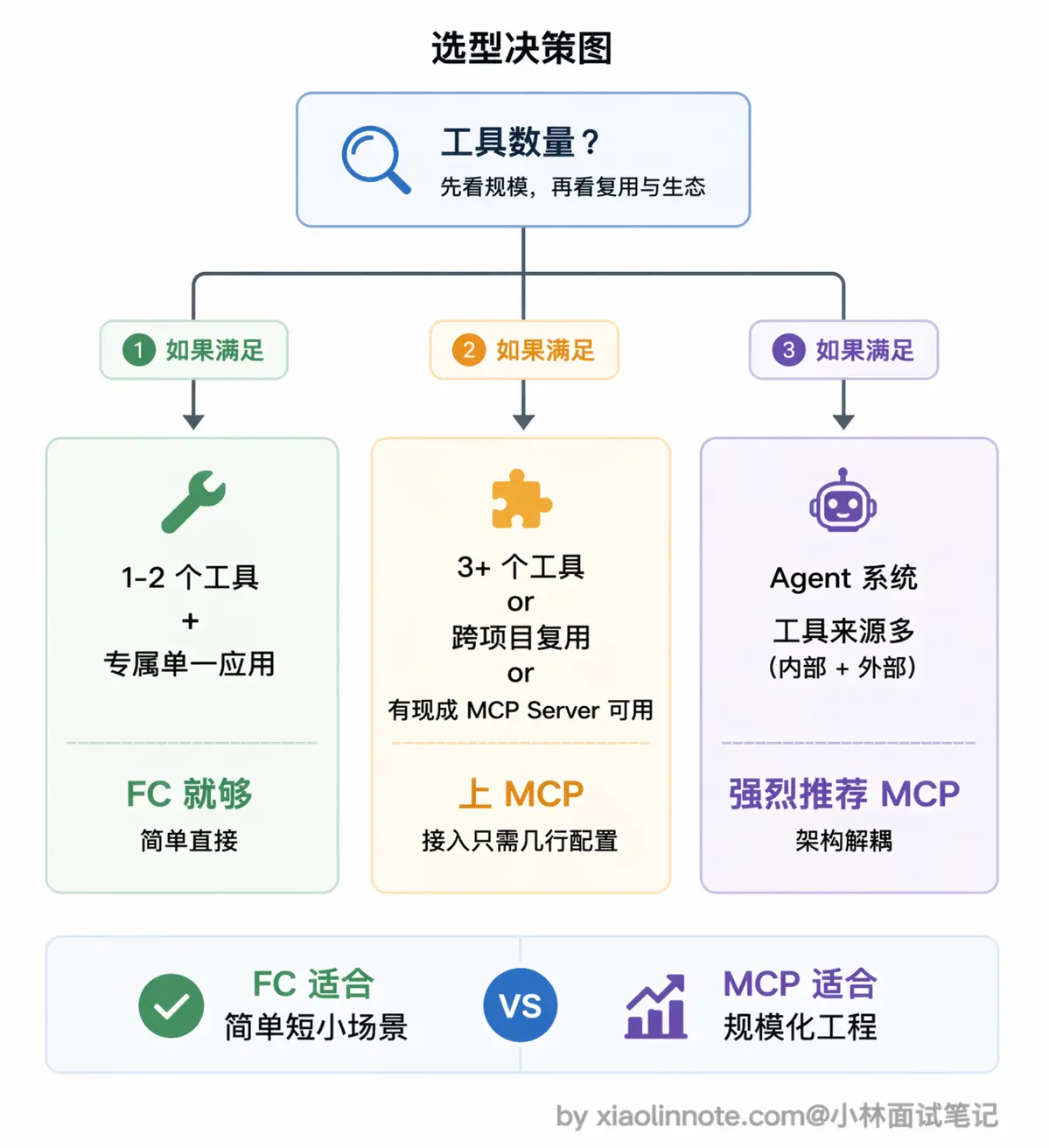
面试回答这道题,第一个必须说清楚的点是:Function Calling 解决的是单次调用的消息格式问题,MCP 解决的是工具生态的标准化管理和复用问题,两者是不同抽象层次的东西。
第二个关键点是:MCP 底层依然靠 Function Calling 驱动,模型根本感知不到 MCP 的存在,所有的工具发现、schema 转换、调用路由都发生在宿主程序层。
如果能再补充实际跑过 MCP 的经验就更好了,比如在 Claude Desktop 里配置过哪些 MCP Server、接入流程是什么样的,这些实操细节能让面试官看到你不是只背概念。要避免的误区是:不要说 MCP 就是「换了个写法的 Function Calling」,也不要说两者是竞争关系,它们是上下层的配合关系。
7. Function Calling 也属于工具调用,请问什么场景下使用 Function Calling,什么场景下使用 MCP?
如果只是给单个应用接一两个工具、场景临时、不需要复用,Function Calling 就够了,简单直接,不需要引入额外的进程和配置。
但只要工具需要跨项目或跨团队复用、或者数量多了管理麻烦、或者社区已经有现成的 MCP Server 可以直接配置,MCP 就值得上了。
判断的核心问题只有一个:这个工具会不会在这个应用之外被用到?会的话,把它封装成 MCP Server 是更长远的选择。
此外,做 Agent 系统的话更应该选 MCP,工具来源多、数量大,手写 Function Calling 的维护成本会让代码变得难以管理。
先建立一个直觉:内嵌 vs 独立
Function Calling 的工具是「内嵌」在应用代码里的,工具定义(schema)和调用逻辑都直接写在你的项目代码中,工具和应用绑在一起,应用换了就要重写一遍。
MCP 的工具是「独立」的,封装成一个独立运行的进程,对外暴露标准接口,任何支持 MCP 的 AI 客户端都能连上来直接用。工具的生命周期和应用解耦,可以独立部署、独立维护、一次实现到处复用。
这个「内嵌 vs 独立」的本质区别,直接决定了两者各自适合的场景。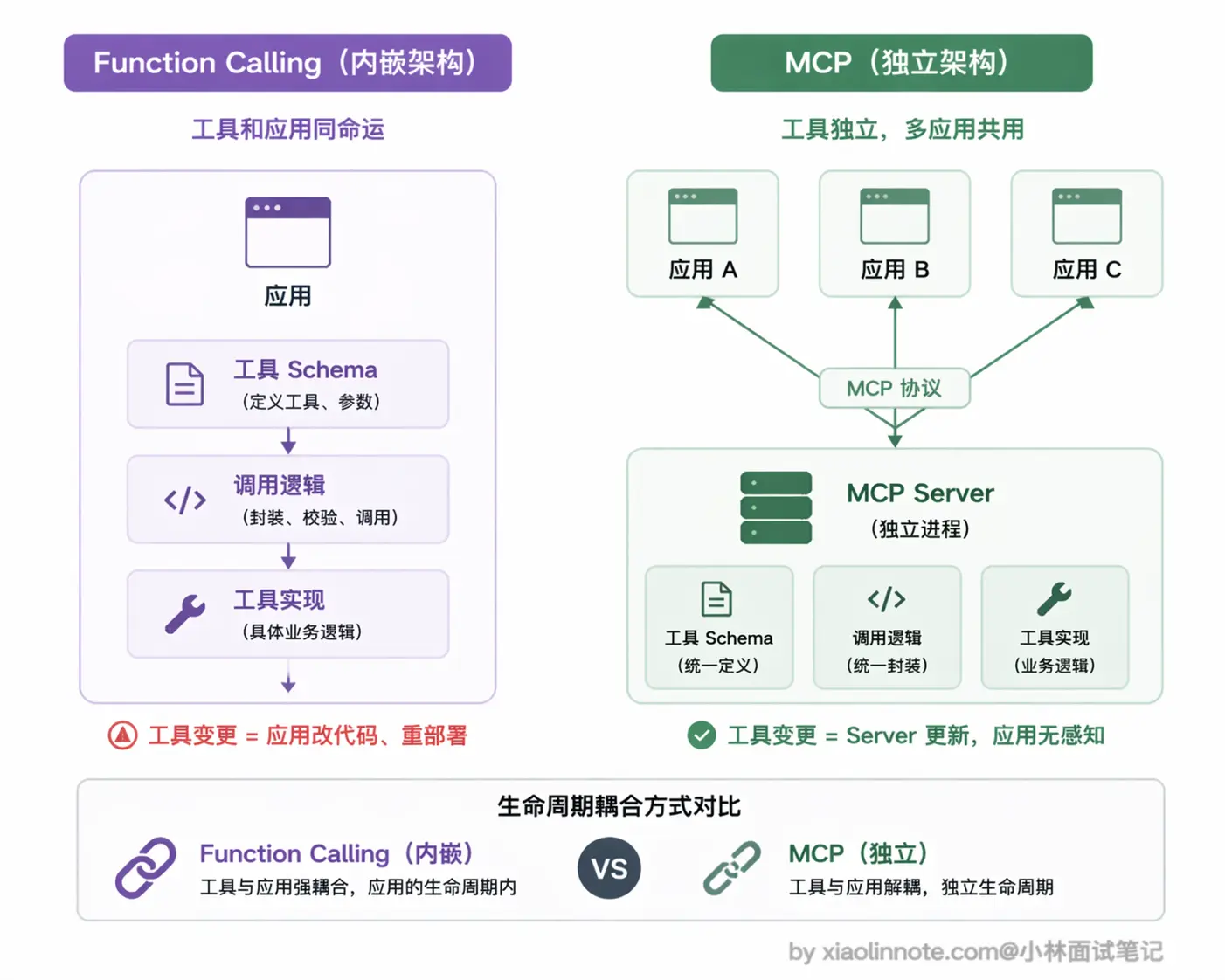
Function Calling 的适用场景
什么时候用 Function Calling 就够了?简单来说,就是「轻量、临时、不需要复用」的场景。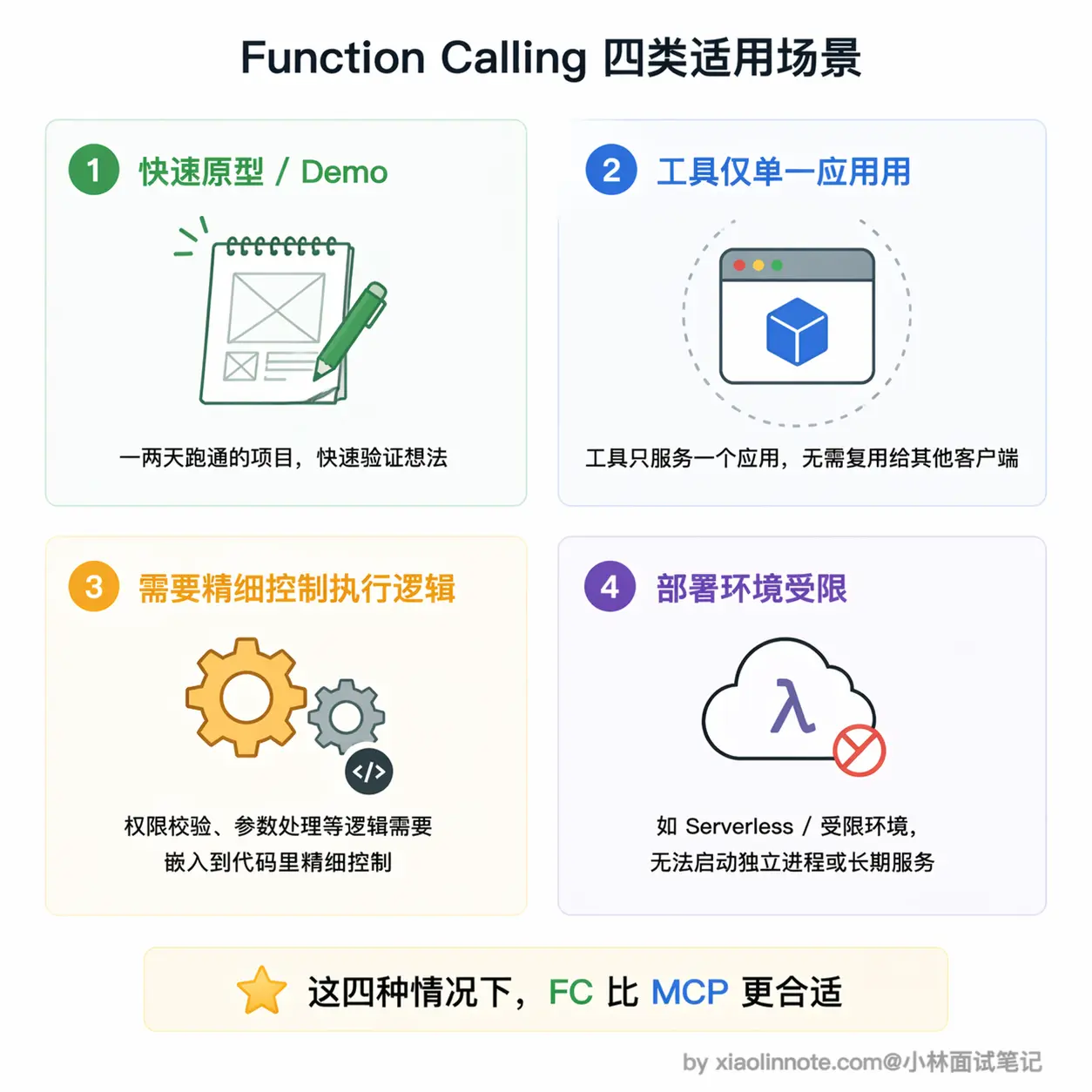
最典型的就是做快速原型和 Demo。你的目标是跑通一个想法或做演示,直接在代码里定义 schema 和调用逻辑就行,不需要启动任何额外进程,也不需要额外配置。这种场景下搞 MCP 完全没必要,你花在搭 Server 上的时间可能会超过原型本身的价值。
再比如工具只为这一个应用服务的情况。假设你在做一个内部工具,里面有一个查本公司私有数据库的接口,这个接口绝不会被任何其他地方用到,那用 Function Calling 把逻辑直接写在项目里反而更清晰,何必额外维护一个独立的 MCP Server 进程呢?
还有一种情况是你需要对工具的执行逻辑做精细控制。Function Calling 的调用逻辑完全在你的代码里,想加权限校验、参数二次处理、特殊错误处理、调用链路追踪,都可以直接嵌进去。MCP Server 是独立进程,这类定制逻辑要额外传递或约定,不如直接写在调用代码里方便。
最后还有一个容易被忽略的因素:部署环境的限制。某些受限的云环境或 Serverless 平台不允许启动子进程,stdio 模式的 MCP Server 就没法用了。这种情况只能退回 Function Calling,工具逻辑都写在主进程里,反而是最稳妥的选择。
MCP 的适用场景
那什么时候该上 MCP 呢?一句话概括:只要工具不是「自己用、用一次就扔」,MCP 基本都值得考虑。
最核心的场景就是工具需要跨项目或跨团队复用。想想看,同一套 GitHub 操作工具,你自己的 Claude Desktop 要用、同事的 Cursor 要用、团队的 CI/CD Agent 也要用。如果用 Function Calling,意味着三处各维护一份 schema 和调用代码,工具接口一变就要同步改三处,漏改一个就出 bug。MCP 的做法就优雅多了:工具封装成独立 Server,任何人在配置文件里加几行就能接进来用,维护的责任在 Server 那一侧,所有客户端自动受益。
还有一个特别务实的理由:社区已经有现成的 MCP Server 了。GitHub、Slack、PostgreSQL、Puppeteer、Google Maps 这类高频工具,都有经过测试、文档完整的官方或社区 MCP Server。你不需要自己写一遍,直接配置就能用:
// 在 claude_desktop_config.json 里加几行,一行工具代码都不用写
{
"mcpServers": {
"github": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-github"]
}
}
}这种情况下还用 Function Calling 手写 GitHub API 的调用代码,那就是重复造轮子了,完全没必要。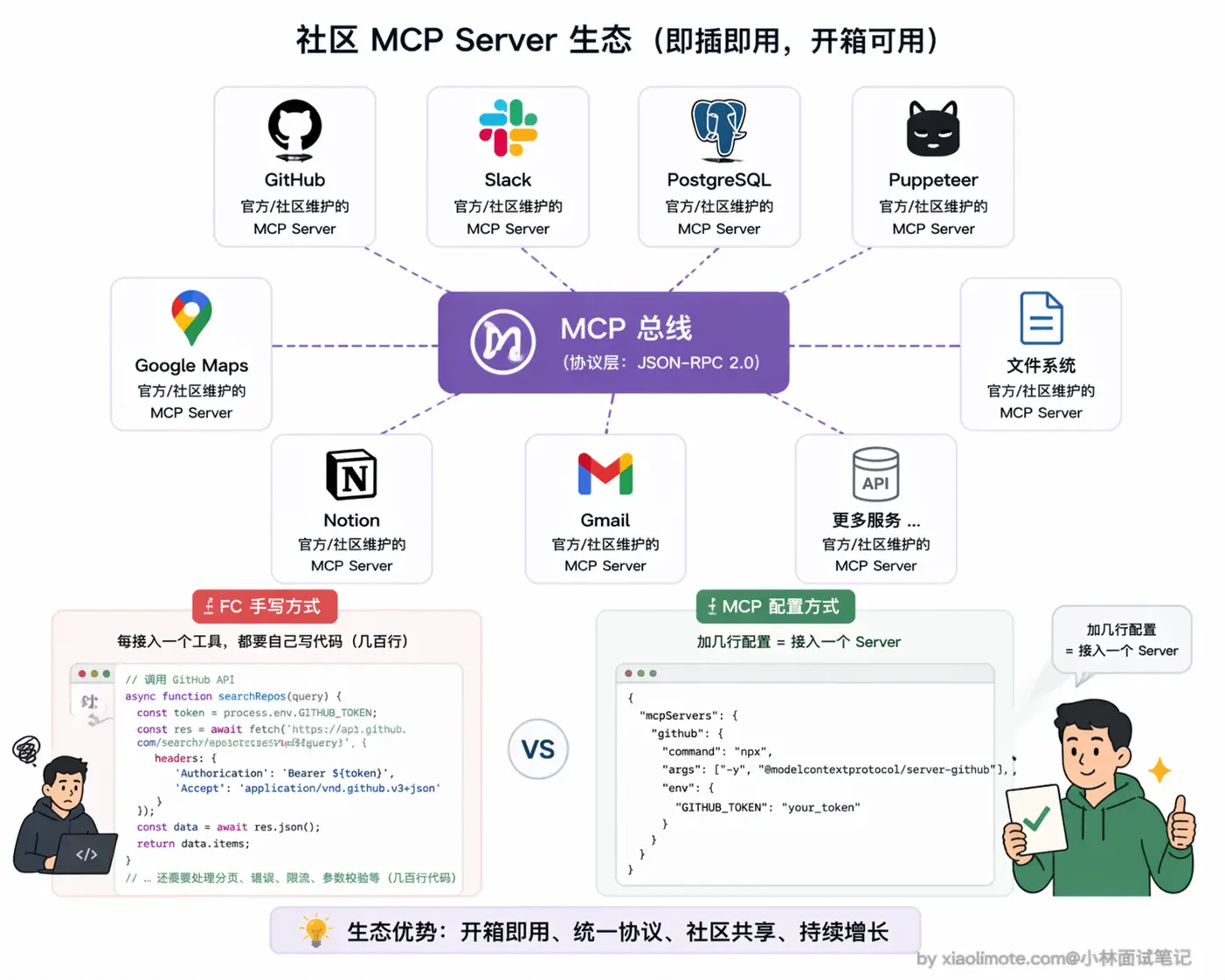
另外,当工具规模起来、MCP 的管理优势就很明显了。这里不想给一个绝对的数字门槛(比如「超过 3 个就要上 MCP」),因为实际判断要看几个维度综合:工具的复杂度(每个工具的 schema 和调用逻辑是几行还是几十行)、团队规模(是一个人维护还是多人协作)、变更频率(工具接口经常改还是基本稳定)。如果你的工具平均复杂度不低、团队里好几个人都在碰这些代码、接口还时不时调整,那就算只有 5 个工具也会很快把你拖进维护泥潭。反过来,两个极其简单、几乎不动的工具,没必要为它们引入一套独立 Server。
为什么工具多了 Function Calling 就会难维护?因为工具的 schema 定义和调用逻辑会散落在代码各处,新加一个工具要改应用代码,工具有 bug 也要进应用代码改,出问题时定位链路很长。MCP 的自动发现机制正好解决这个问题,主程序不感知具体工具,只连 Server,新增工具只需要在 Server 里加实现,主程序完全不需要改动。
最后,如果你在构建 Agent 系统,MCP 几乎是必选项。Agent 系统的工具需求往往多样、来源复杂,可能同时需要代码执行、文件系统、数据库、外部 API 等各类工具。全靠 Function Calling 的话,工具 schema 会成为 Agent 代码里最难维护的部分。MCP 让 Agent 可以按需连不同的 Server,工具来源模块化,Agent 的核心逻辑和工具管理完全解耦,架构干净很多。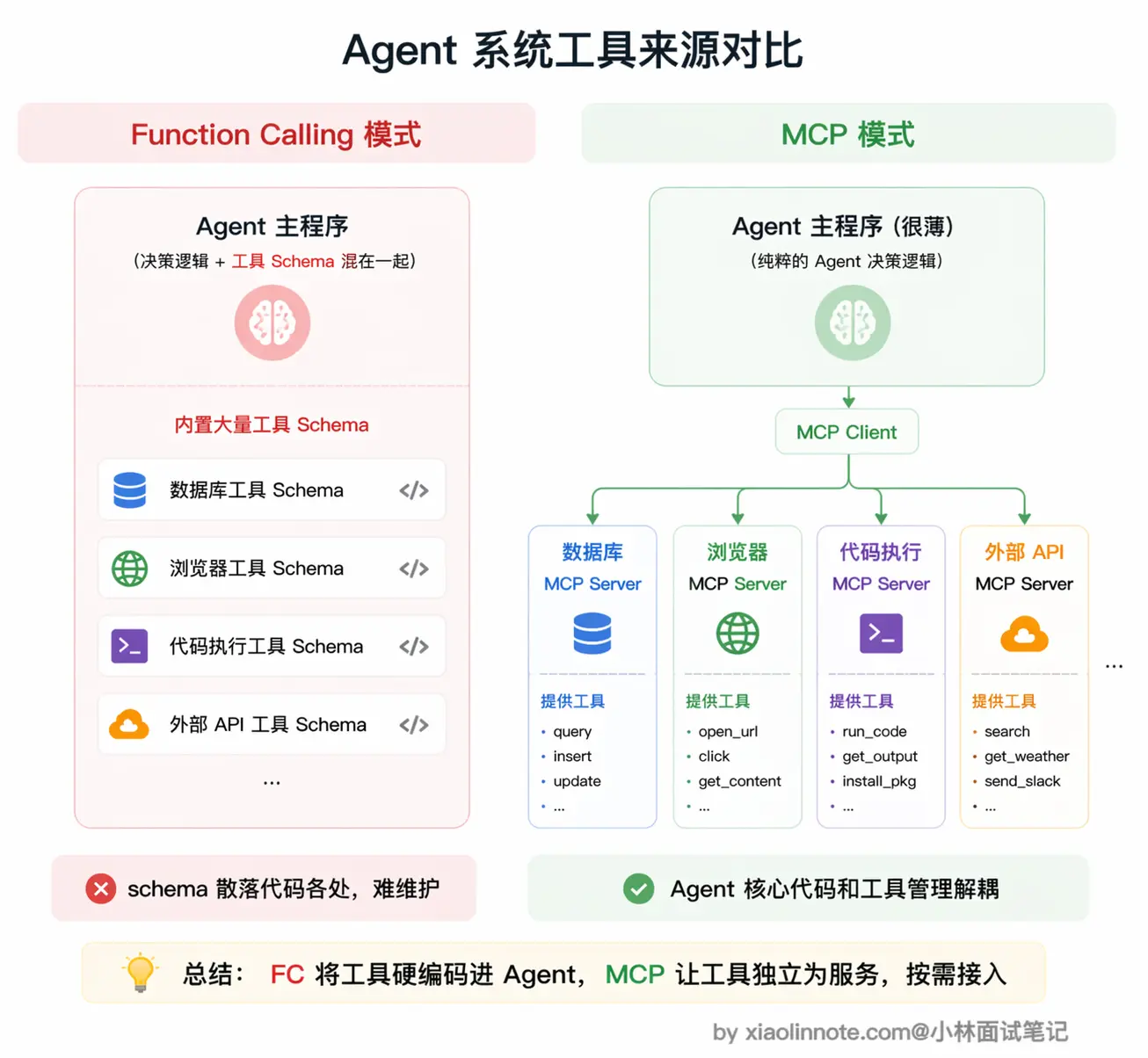
一个实用的判断方法
碰到「用 Function Calling 还是 MCP」这个选择题,其实不需要纠结太久,按几个问题依次过一遍就清楚了。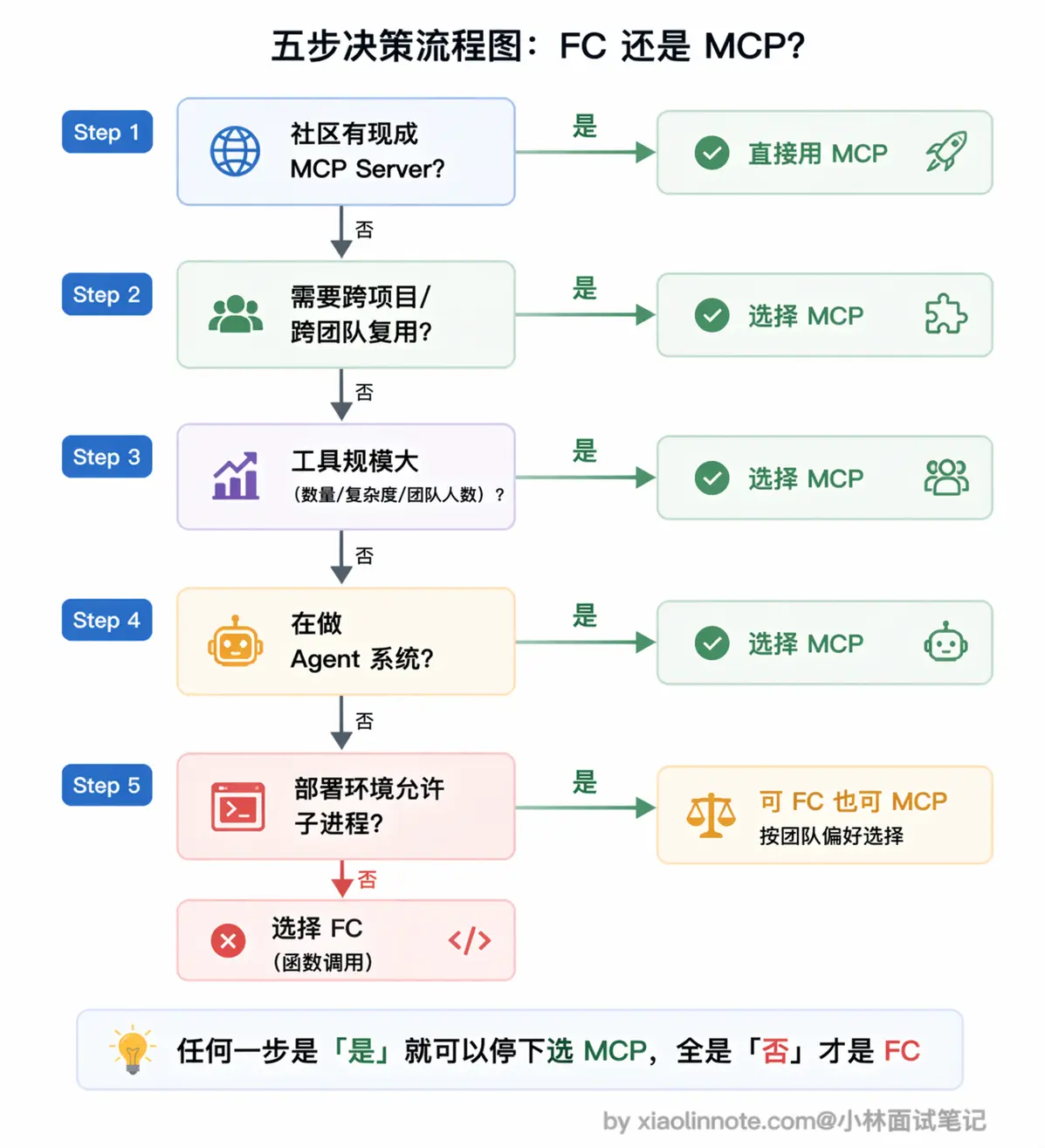
首先看社区有没有现成的 MCP Server,有的话直接用,不要重复造轮子,这是最省事的路径。
如果没有现成的,那就看这个工具需不需要在多个项目或多人之间复用,需要复用就选 MCP,一次封装到处用。
接着综合看工具数量、复杂度、团队规模和变更频率,只要规模一上来(不一定是数字门槛,而是「感觉到散乱」的那个拐点),用 MCP 统一管理会比散落在代码各处的 Function Calling 清爽很多。
然后考虑你是在做正式的 Agent 系统还是 Demo 原型,正式系统选 MCP 更利于长期维护,Demo 的话 Function Calling 上手更快。
最后别忘了检查部署环境,如果平台不允许启动子进程,那 Function Calling 就是更稳妥的选择。
总结成一句话:「只用自己、只用一次、不需要复用」才适合 Function Calling,其他情况优先考虑 MCP。两者不是竞争关系,MCP 底层本来就是靠 Function Calling 驱动的,选哪个取决于你的工程需求,而不是技术层面的优劣。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)