Papermind平台搭建(三):深度阅读功能的实现
摘要:
在上周完成了Langgraph架构基础上,本周完成深度阅读功能的实现,目的在于基于用户上传的文献,我们可以在完成PDF解析后,调用该功能,完成对该篇文献的深度理解, 辅助用户快速理解文献,以及掌握核心创新点,理解复杂的数学公式推导,实验设计等等。本功能的实现需要依托论文全文注入功能的实现,只有我们的agent能看到文献的全貌才能实现真正的深度阅读,而全文文献的注入由我们其他组员完成,不在此博客中过多描述
一、为什么需要深度阅读功能
我们毕竟做的是一个学术文献阅读平台,那自然来说最主要的核心功能便是文献的阅读,很常见的一种辅助阅读功能是QA功能(该功能我们亦有实现),但是QA功能存在问题就是,针对一般性的提问和回答,由我们用户端提出的quarry。rag和embedding模型会定位一些相关的片段返回给我们的后端agent部分,这就容易出现一个问题就是agent只能拿到部分的片段进行回答,并不知道全貌,所以回答出来的答案质量得不到保证,同时即使我们让agent得到了文献的全貌,但是如何保证ai回答文的真实性?如何保证ai的回答没有幻觉产生?这些都是我们的平台需要解决的问题
同时由于常规的QA功能仅仅只是我们提问,由ai来作答,而我们的深度阅读功能则是希望于,我们的agent可以像一个老师,由ai对全文文献深刻正确的理解一遍,然后把理解的内容输出出来,再由用户去理解复杂的数学公式推导,核心实验是怎么做的,对比实验是和谁对比,对实验部分进行拆解等等。以此来让用户在借助我们深度阅读的功能基础上可以快速理解文献的核心,知道公式是如何推导的,创新点创新在哪等等
1.1三级协同的深度理解设计
我们想让深度阅读功能能完全正确反映文献的内容,没有幻觉产生,同时,能够对文献中的方法原理,数学推导,实验的设计等等做出深刻的理解与解释,方便用户进行快速理解,因此我们此功能设计成了三层模式,先由一个ai扮演阅读者的角色,让他去针对文献的方法部分,数学原理,以及实验设计做出严格的推导,然后再把输出的结果返回给另一个ai,让他拿着上一个ai的结果去逐句逐点比对原文是否有依据, 并给出可信度,之后如果通过,再由最后一个ai对于分析结果提出一些思考的问题(增加提问的问题目的也是在于帮助用户进入更深层的思考,同时也许能启发用户想到其他的创新处)。
1.2关于深度阅读功能是应该agent还是prompt套壳
在做这个功能的时候我也有思考这个问题,我们这个功能到底是由agent来完成的,还是只是prompt套壳api来完成,也就是说我们这个功能到底能否被认为是一个agent呢?根据我对agent的理解以及学习,agent应该是具备如下的特点:
普通的 API 调用是线性的:
一般来说是如下的流程:用户输入 -> Prompt 包装 -> LLM 输出 -> 结束。
而 Agent 的核心在于自动推理与行动的循环:
目标 -> 思考 -> 行动 -> 观察结果 -> 修正推理 -> 再次行动... 直到任务完成
关键区别在于agent在于可以自主修正自己的推理,同时可以有一些行动产生,而LLM包装则是只输出文本
同时agent和LLM包装还有一个区别是,agent会使用工具调用:也就是说他能够知道什么时候应该去查询goole,什么时候应该跑代码等等。
总结来说的话:
agent应该至少具备如下
1. 自主性:不需要用户干预,自己决定下 N 步操作
2. 反应性:遇到错误能自己调整策略
3. 目标导向:关注的是"完成任务而不是生成一段文本
因此我们的深度阅读功能如果只是prompt的简单包装与三级串行调用,那么我想我们的这个功能确实不应该被认为是由agent完成的,而仅仅是提示词+LLM的api调用,但是我们的设计中有一个关机制:幻觉检查的条件循环,该机制引入了控制流,让得我们不仅仅只是prompt chain,而是一定意义上来说也是一个agent
1.3 拓扑结构
我们整个深度阅读的拓扑结构如下所示
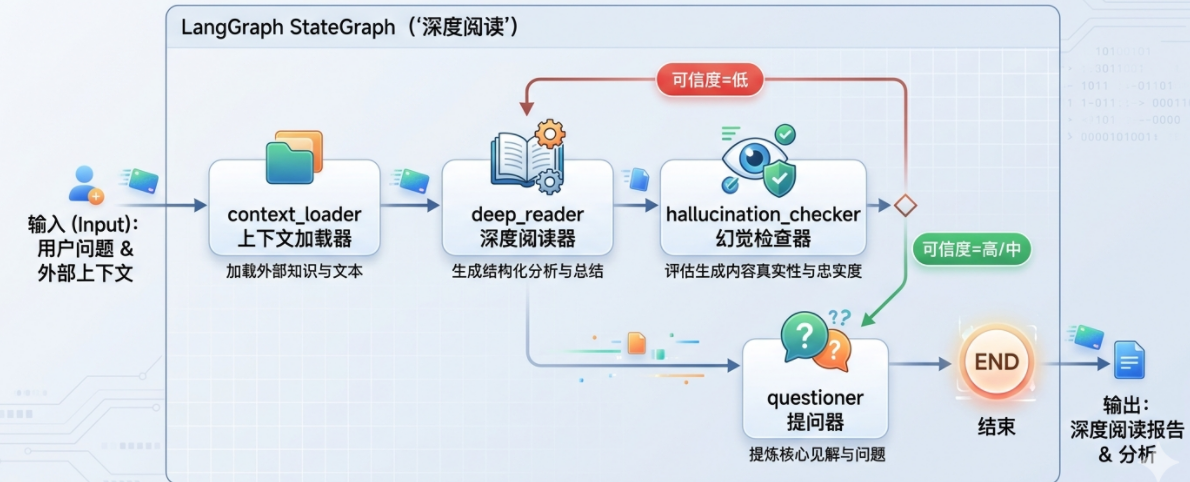
可以看到我们在考虑这个功能的时候,其实是有循环条件的,当上层的输出传到检查器,由检查器来进行原文定位依据,同时再考虑置信度,如果可信度低则由重新传回上层,也就是说我们在Langgraph图编排中,对这个功能加入了一个条件边,让得深度阅读器的结果不仅仅只是走prompt chain,还会根据条件边来自主决定之后的循环条件,因此我们可以认为我们的这个功能是一个简单的agent而非是简单的prompt chain
我们有三个节点,每个节点其实都可以认为是一个简单的agent,他们各自的职责和输入输出如下所示:
表格内容
| 模块名称 | 功能描述 | 输入来源 | 输出结果 |
|---|---|---|---|
| deep_reader | 系统性拆解论文 | paper_context | deep_analysis |
| hallucination_checker | 逐条验证分析是否有原文支撑 | deep_analysis + paper_context | hallucination_report + credibility |
| questioner | 生成深层思考问题 | hallucination_report | deep_questions |
我们认为我们这个功能是agent关键在于 hallucination_checker到 deep_reader之间的条件边:
def _check_credibility(state: AgentState) -> str:
credibility = state.get("credibility", "high")
retry_count = state.get("retry_count", 0)
if credibility == "low" and retry_count <= 1:
return "retry" // 回到 deep_reader 重新分析
return "continue" // 继续到 questioner
graph.add_conditional_edges("hallucination_checker", _check_credibility, {
"retry": "deep_reader",
"continue": "questioner",
})
这是我们引入了条件边之后,输出的答案才会进行自己修正与自我调用,而不会吧把有问题的答案直接输出给用户
二、agent的实现细节
2.1deep_reader的双模式设计
deep_reader采用双模式设计,确保论文分析的准确性和可迭代性。首次分析模式对论文全文进行系统性拆解,重写模式则根据幻觉检查反馈修正分析结果。
2.2首次分析模式
接收论文全文,从方法原理、数学推导、实验设计三个维度进行深度拆解。系统会生成初始分析结果,为后续检查提供基础。
2.3重写模式
当幻觉检查发现问题后,deep_reader会被回调,接收上一轮的分析结果和幻觉检查反馈。针对有问题的部分进行修正,确保分析的准确性。通过retry_count限制重试次数,避免无限循环。
def deep_reader_node(state, settings):
hallucination_report = state.get("hallucination_report", "")
retry_count = state.get("retry_count", 0)
if hallucination_report and retry_count > 0:
messages = [
{"role": "system", "content": _REWRITE_SYSTEM},
{"role": "user", "content": f"之前的分析:\n{state['deep_analysis']}\n\n幻觉反馈:\n{hallucination_report}\n\n论文原文:\n{paper_context}"},
]
else:
messages = [
{"role": "system", "content": _SYSTEM},
{"role": "user", "content": f"请对以下论文进行系统性深度拆解:\n\n{paper_context}"},
]
state["retry_count"] = retry_count + 1
幻觉检查的结构化输出
幻觉检查的关键在于生成可解析的输出。通过固定格式的可信度评分,确保程序能够准确提取检查结果。
可信度评分格式
要求LLM在输出的最后一行包含固定格式的可信度评分:[可信度: 高]、[可信度: 中]或[可信度: 低]。
解析函数
从末尾扫描输出,提取可信度评分。这种方法比JSON格式更可靠,避免了LLM在复杂格式上的错误。
def _parse_credibility(report: str) -> str:
for line in reversed(report.splitlines()):
if "[可信度:" in line or "[可信度:" in line:
if "低" in line: return "low"
if "中" in line: return "medium"
if "高" in line: return "high"
return "medium"
基于已验证结论的提问机制
questioner的设计确保问题建立在已验证的分析基础上,避免因错误前提导致无效提问。
提问顺序
先进行幻觉检查,验证分析结果的准确性。基于已验证的结论生成问题,确保问题的合理性和相关性。
优势
避免了因未验证分析导致的错误提问,提高了问答环节的效率和准确性。
三、Langgraph的状态编排
LangGraph StateGraph 机制解析
StateGraph 是 LangGraph 中用于管理多节点工作流状态的核心机制,通过共享状态对象实现节点间数据传递。
AgentState 状态设计
状态对象采用 TypedDict 定义,支持动态字段扩展:
class AgentState(TypedDict, total=False):
paper_id: str
paper_context: str # 论文全文
deep_analysis: str # deep_reader 的输出
hallucination_report: str # hallucination_checker 的输出
deep_questions: str # questioner 的输出
credibility: str # "high" / "medium" / "low"
retry_count: int # 循环计数器
自动状态合并特性
节点执行后自动合并新状态到全局状态,后续节点可直接访问所有历史数据。这种设计实现以下优势:
- 消除显式参数传递
- 降低节点间耦合度
- 支持动态字段扩展
图构建示例
构建流程展示条件分支和循环控制:
def build_deep_reading_graph(settings):
graph = StateGraph(AgentState)
graph.add_node("context_loader", partial(context_loader_node, settings=settings))
graph.add_node("deep_reader", partial(deep_reader_node, settings=settings))
graph.add_node("hallucination_checker", partial(hallucination_checker_node, settings=settings))
graph.add_node("questioner", partial(questioner_node, settings=settings))
graph.set_entry_point("context_loader")
graph.add_edge("context_loader", "deep_reader")
graph.add_edge("deep_reader", "hallucination_checker")
graph.add_conditional_edges("hallucination_checker", _check_credibility, {
"retry": "deep_reader",
"continue": "questioner",
})
graph.add_edge("questioner", END)
return graph
关键控制模式
条件分支通过 add_conditional_edges 实现:
_check_credibility函数返回路由决策- 支持循环逻辑(retry→deep_reader)
- 支持终止条件(continue→questioner→END)
节点开发规范
单个节点只需关注局部状态:
def deep_reader_node(state: AgentState, settings):
# 仅需读取paper_context
context = state["paper_context"]
# 只需写入deep_analysis
return {"deep_analysis": analyze(context)}
四、编码开发
41.prompt
最后由我们设计好我们的功能模式,以及我们的层级架构,最后的编码工作交给claude opus4.6完成,我们的初次prompt如下:
请你先仔细阅读我们当前代码的架构,我们已有Langgraph架构,请你在此基础上完成下一个功能的开发,需要由你完成一个agent驱动的深度阅读功能,具体的架构图如我给你的图所示(我们提前手写画在纸上,并交给gemini生成了一个规范的ai能读懂的架构,并将gemini根据我们手写架构渲染后的规范图交给了claude),帮我们完成这个深度阅读功能,开发过程要求你遵守软件开发的范式,开闭原则等等,同时对于你开发过程中的疑问,需要先像我提问,然后由我给出你下一步的执行意见,记住不能私自进行抉择,同时不知道的地方,不要自主决定如何修改,现在请你根据我给你的架构图,完成这个功能的开发
当然开发肯定不是一次就能通过,开发过程中也遇到了不少的问题,包括前端页面崩溃,等等一系列问题,我们的解决办法是根据报错让ai先查出可能的问题,然后简单的问题由ai直接修复,复杂问题我们先进行备份处理,然后再交由ai处理,此功能从ai开始编码到完成大概花费2个小时左右,包括了调试测试等一些列操作:
4.2功能展示:
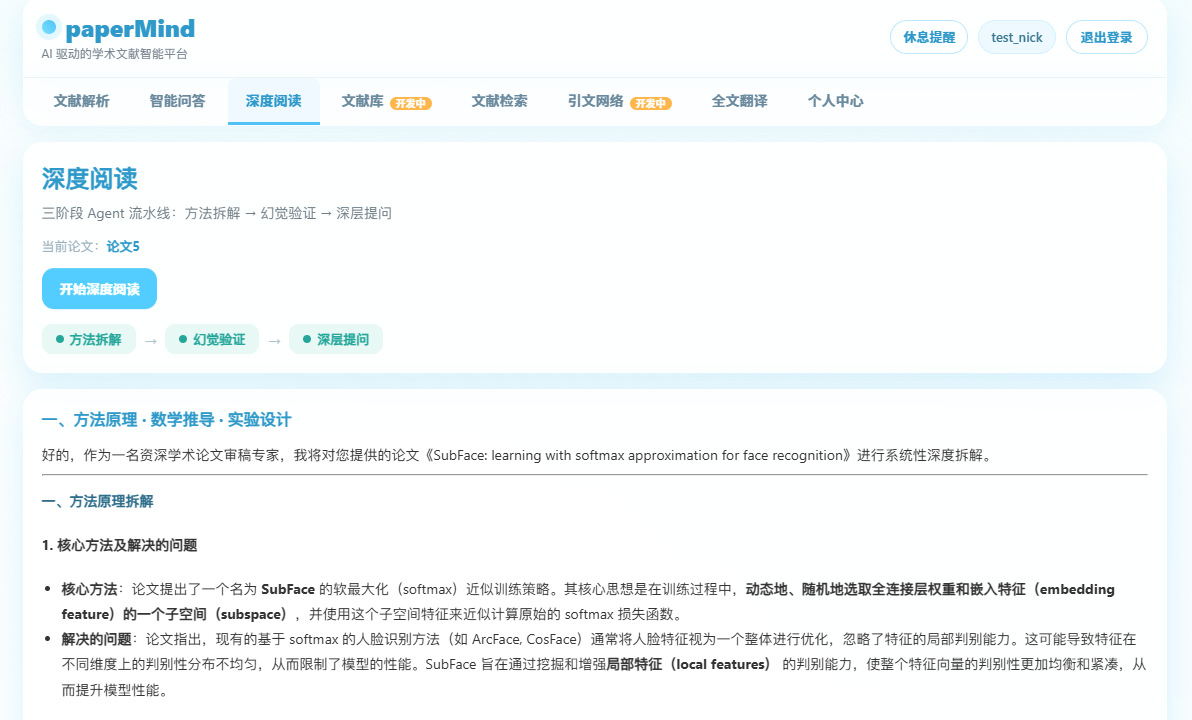


这篇文献是我们小组提前阅读过的一篇文献,我们检测了基于这篇文献的数学推导过程以及深度解析出来的要点,我们认为和我们理解的不差,至少他所说的在我们检查来看是正确的
至此,我们的深度阅读功能第一版本算是完成,有待优化的地方将会在所有功能开发完成后再逐细节进行优化

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)