机器学习-第二章 KNN算法
标题 第二章 KNN算法
目录
KNN算法简介
KNN思想、分类和回归问题处理流程
KNN算法API介绍
分类、回归实现
距离度量
常用距离计算方法
特征预处理
归一化 标准化 鸢尾花识别案例
超参数选择方法
交叉验证、网格搜索、手写数字识别
学习目标
1.理解k近邻算法的思想
2.知道k近邻算法分类流程
3.知道k近邻算法回归流程4
1.KNN算法简介
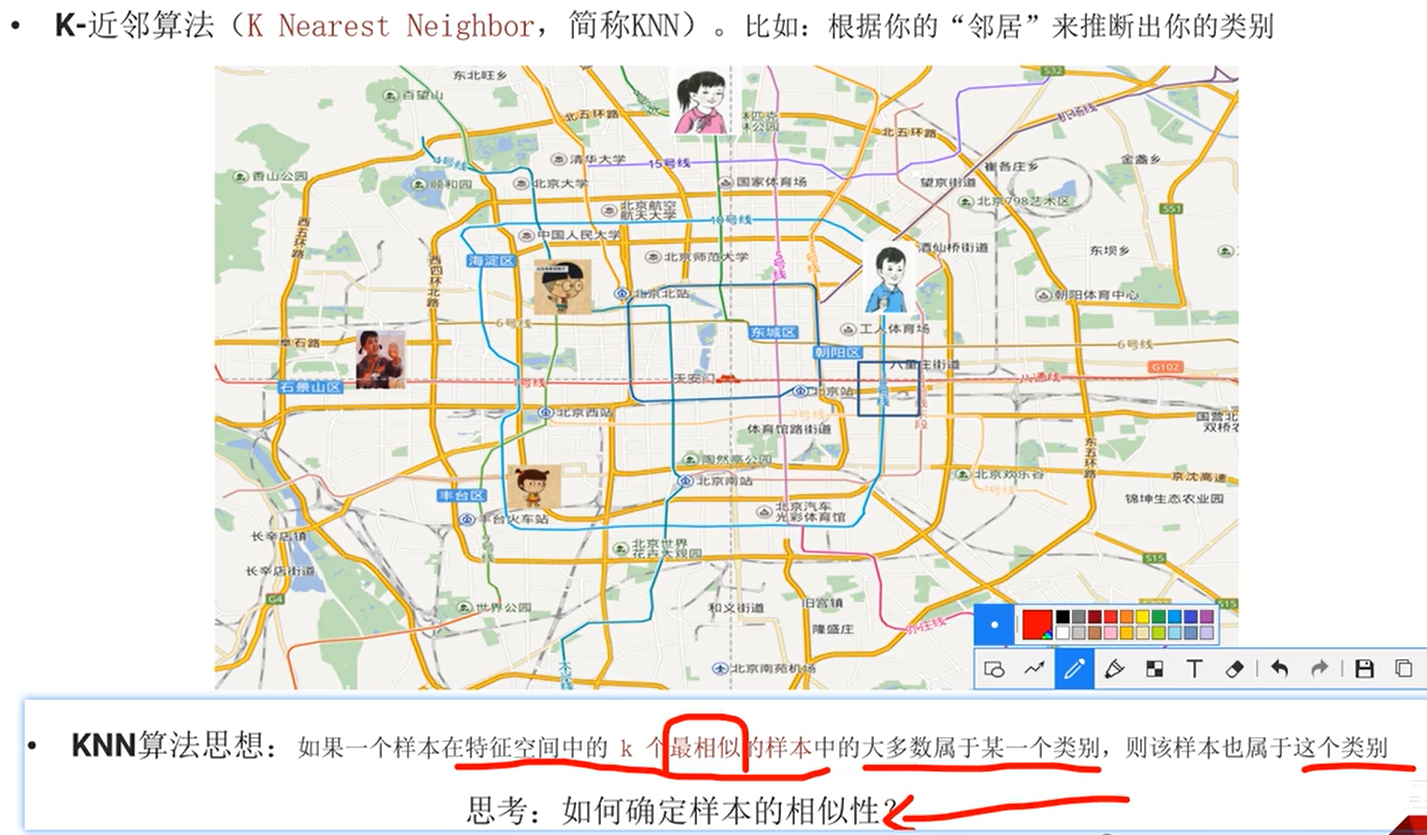
KNN算法思想:如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别
2.k近邻算法
样本相似性:样本都是属于一个任务数据集的。样本距离越近则越相似。
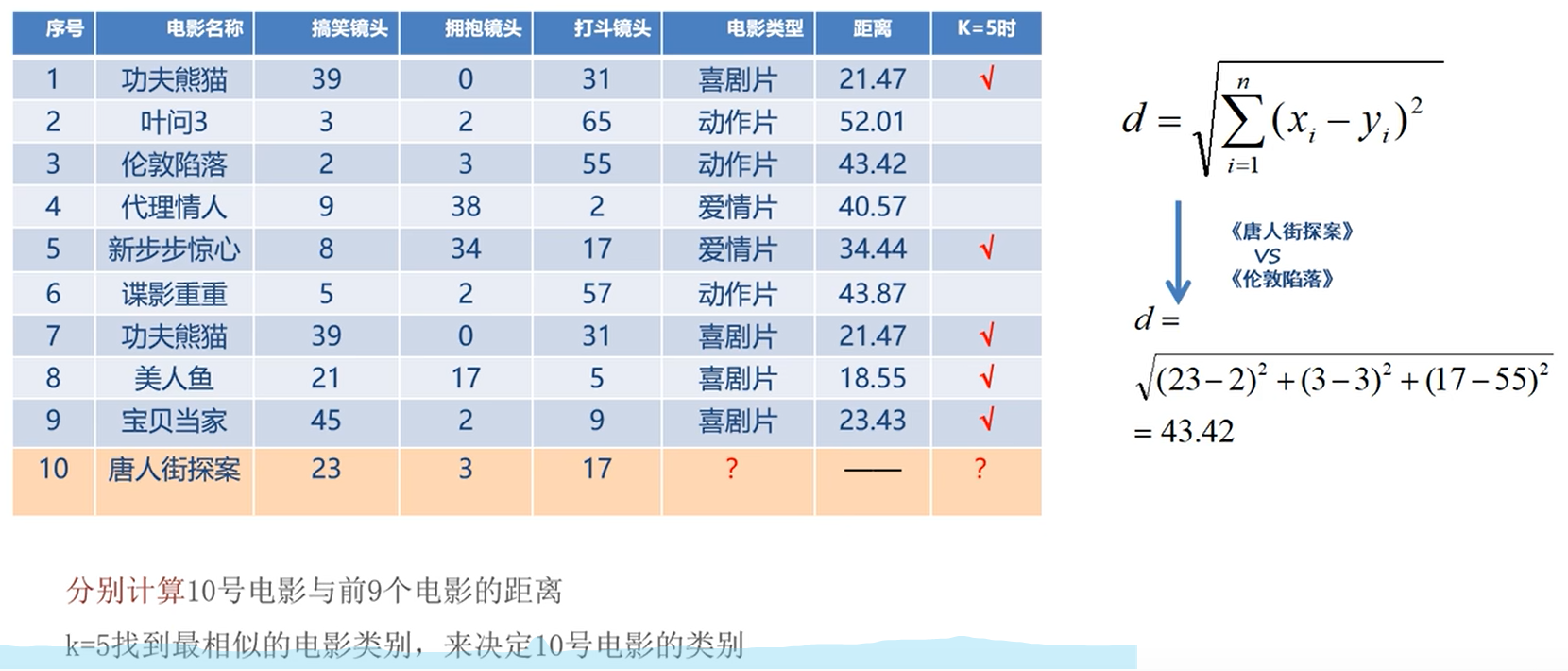
利用k近邻算法预测电影类型。
欧氏距离:对应维度差值平方和,开平方根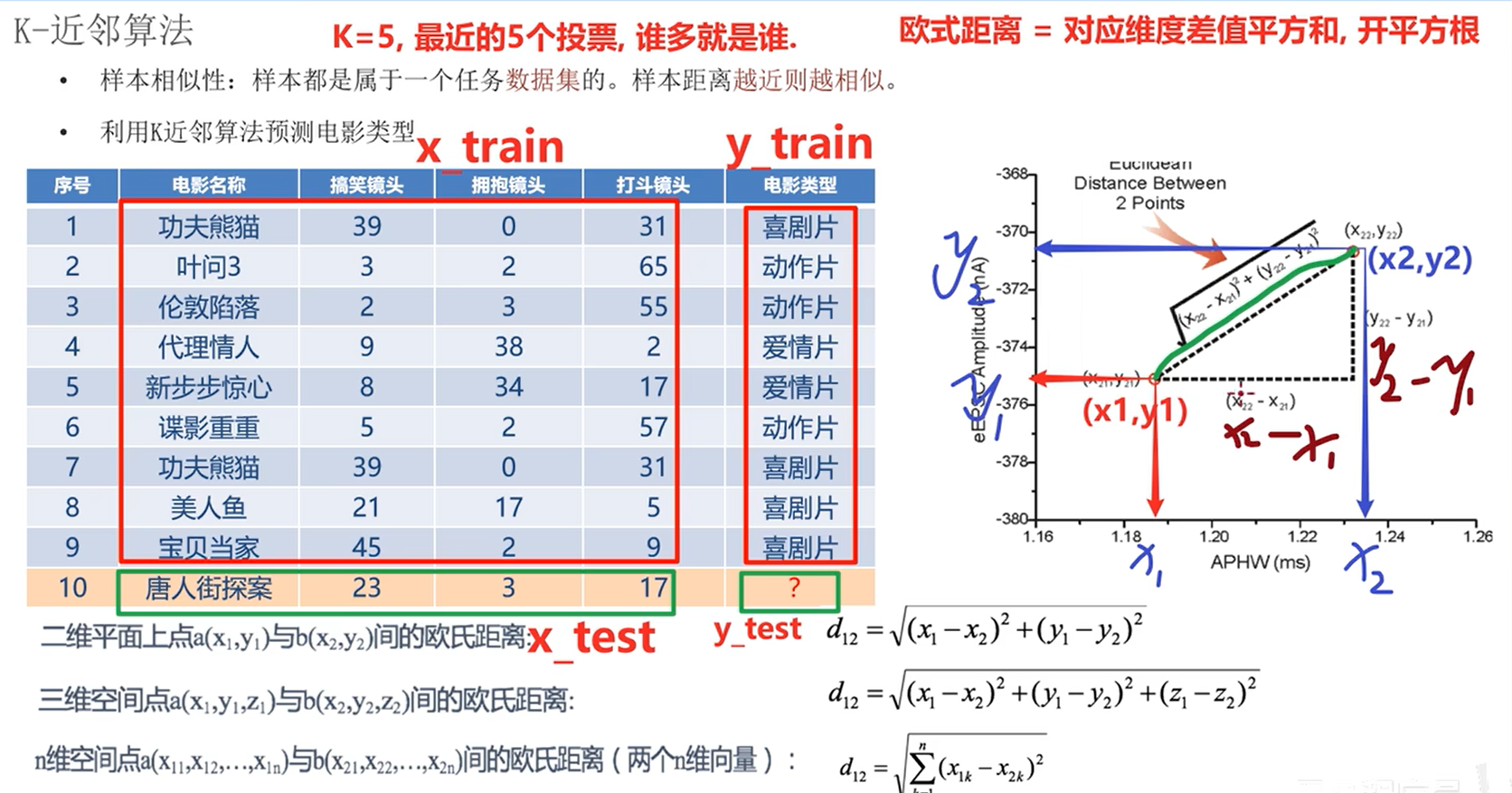
3.K值选择
k值小了,过拟合–数据量少,容易学到脏数据
用较小领域中的训练实例进行预测
容易受异常点影响
k值减小就意味着整体模型变得复杂,容易发生过拟合
k值大了,欠拟合–模型变得简单
用较大领域中的训练实例进行预测
受到样本均衡的问题
k值增大就意味着整体模型变得简单,容易发生欠拟合
举例:K=N,N为训练样本,无论实例输入什么,只会按训练集只能怪最多的类别选择
4.解决的问题
分类问题、回归问题
1.相同点:都是有监督学习,欧氏距离
2.不同:
分类–投票 --标签不连续
回归–均值–标签连续
3.算法思想:若一个样本在特征空间中的k个最相似的样本大多数属于某个类别,则该样本也属于这个类别
总结
2. KNN算法API
k nearest neighbor
学习目标 掌握分类api/回归api
1.分类API
"""
KNN算法介绍(K Nearest Neighbors),k近邻算法
原理:
基于欧氏距离计算 测试集和每个训练集之间的距离,然后更具距离升序排序,找到近邻的k个样本
基于k个样本投票,票数多的就作为最终预测结果---》分类问题
基于k个样本计算平均值,作为最终预测结果---》回归问题
实现思路
1.分类问题
适用于:有特征、有笔阿斯哦钱,且标签是不连续的--练得
2.回归问题
适用于:有特征、有标签、且标签是连续的
KNN算法分类问题 思路如下是
1.计算测试集和每个训练样本之间的距离
2.基于距离进行升序pair
3.找到最近的k个样本
4.k个样本进行投票
5.票数多的结果,作为预测结果
代码实现思路
1导包
2.准备数据集(训练集和测试集)
3.创建(KNN分类模型)模型对象
4.模型训练
5.模型预测
"""
# 1导包
from sklearn.neighbors import KNeighborsClassifier
# 2.准备数据集(训练集和测试集)
# train :训练集
# test:测试集
# neighbors:最近邻的邻居数
x_train = [[0], [1], [2], [3]] #训练集的特征数据
y_train = [0, 0, 1, 1] #训练集的标签数据
x_test = [[5]] #测试集的特征数据
# 3.创建(KNN分类模型)模型对象
# estimator :估计其,模型对象,也可以用变量名model做接收
estimator = KNeighborsClassifier(n_neighbors=4) # 0
estimator = KNeighborsClassifier(n_neighbors=3) # 1
# 4.模型训练
# 传入:训练集的特征数据、训练集的标签数据
estimator.fit(x_train, y_train)
# 5.模型预测
# 传入:测试集的特征数据,获取到预测结果(测试集的标签,y_test)
y_pre = estimator.predict(x_test)
# 6.打印数据结果
print(f'预测结果为:{y_pre}')
2.回归API
"""
KNN算法介绍(K Nearest Neighbors),k近邻算法
原理:
基于欧氏距离计算 测试集和每个训练集之间的距离,然后更具距离升序排序,找到近邻的k个样本
基于k个样本投票,票数多的就作为最终预测结果---》分类问题
基于k个样本计算平均值,作为最终预测结果---》回归问题
实现思路
1.分类问题
适用于:有特征、有笔阿斯哦钱,且标签是不连续的--练得
2.回归问题
适用于:有特征、有标签、且标签是连续的
KNN算法回归问题 思路如下是
1.计算测试集和每个训练样本之间的距离
2.基于距离进行升序排序
3.找到最近的k个样本
4.基于k个样本的标签计算平均值
5.将上述计算出来的平均值,作为最终的预测结果
代码实现思路
1导包
2.准备数据集(训练集和测试集)
3.创建(KNN分类模型)模型对象
4.模型训练
5.模型预测
总结:
k值过小,容易受到异常值影响,且会导致模型学到大量的“脏特征”,导致出现:过拟合
k值过大,模型会变得简单,容易发生欠拟合。
"""
# 1导包
from sklearn.neighbors import KNeighborsRegressor #KNN算法的回归模型
# 2.准备数据集(训练集和测试集)
# 开根号: 14.53 14.28 1 2.236
# 平方和:211 204 1 5
# 差值:(3,11,9)(2,10,10)(0,1,0)(1,0,2)
# k=3 0.2 0.3 0.4 均值 0.3
x_train = [[0,0,1], [1,1,0],[3,10,10],[4,11,12]] #训练集的特征数据,因为特可以有多个特征,所以是一个二维数组
y_train = [0.1, 0.2, 0.3, 0.4] #训练集的标签数据,因为标签是连续的,所以是一个一维数组
x_test = [[3,11,10]] #测试集的特征数据
# x_test = [[3,110003,10333]] #k过大
# 3.创建(KNN分类模型)模型对象
estimator =KNeighborsRegressor(n_neighbors=3)
# estimator =KNeighborsRegressor(n_neighbors=4)
# 4.模型训练
# 传入:训练集的特征数据、训练集的标签数据
estimator.fit(x_train, y_train)
# 5.模型预测
y_pre = estimator.predict(x_test) #特征需要传入一个二维数组
# 6.打印数据结果
print("预测结果:", y_pre)
3.距离度量
1.欧氏距离
常见距离公式
两点在空间中的距离一般指的都是欧式距离
欧氏距离=对应维度差值平方和,开平方根
二维平面 d=
三维空间
n维空间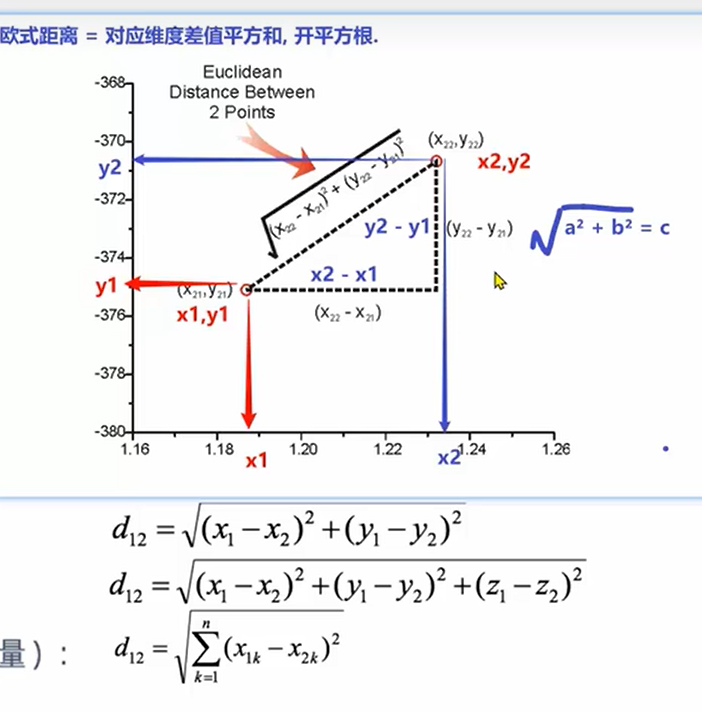
2.曼哈顿距离 也称为城市街区距离
欧氏距离=对应维度差值平方和,开平方根
曼哈顿距离=对应维度差值的绝对值之和
只能横平竖直的走
(0,0)(6,6)
曼哈顿距离:6+6=12
欧氏距离:6*6+6*6 开根 =6*1.414=8.46
3.切比雪夫距离
国际象棋中,可以横竖斜着走
=对应维度值差值的绝对值,求最大值
(1,2)(5,5)
5-1=4 5-2=3 4>3 =4
4.闵式距离
不是一种新的距离的度量方式
是对多个距离公式的概括性表述

4.特征预处理
1.为什么做归一化、标准化
特征的单位或者大小相差太大,或者某个特征的方差相比其他的特征要大出几个数量及,容易影响(支配)目标结果,使得一些模型(算法)无法学到其他特征。
归一化:
API:
1.sklearn.preprocessing.MinMaxScaler
feature_range 缩放区间
2.fit_transform(x) 训练加转换 适合第一次 训练集
transform 适合训练集
"""
案例:演示特征预处理 --归一化
回顾:特征工程目的 和 步骤
目的:
利用专业的背景知识和技巧处理数据,用于提升模型的性能
步骤
1.特征提取
2.特征预处理 归一化 标准化
3.特征降维
4.特征选择
5.特征组合
特征预处理之 归一化介绍:
目的:
防止因为量纲单位问题,导致特征列的放差值相差较大,影响模型最终结果
所以通过公式把 哥猎德值 映射到【0,1】区间
公式:
x'=(当前值-该列最小值)/(该列最大值-该列最小值)
x''=x'*(mx-mi)+mi
公式解析:
x‘ 基于公式算出来的结果
x’‘ 最终的结果
mx 区间的最大值
mi 区间的最小值
弊端
容易受到最大值和最小值的影响,所以他一般用于处理小数据集
"""
#导包
from sklearn.preprocessing import MinMaxScaler #归一化对象
# 1.准备数据集(归一化之前的原数据)
x_train = [[90,2,10,40],[60,4,15,45],[75,3,13,46]]
# 2.创建归一化对象
# 参数 feature_range=(0,1) 指定归一化后的数据区间
# 默认区间是【0,1】,如果就是这个区间,可以省略不写
# transfer = MinMaxScaler(feature_range=(3,5))
transfer = MinMaxScaler()
#3.对原数据集进行归一化处理
x_train_new = transfer.fit_transform(x_train)
# 4.打印处理后的数据
print("归一化处理后的数据为:", x_train_new)
标准化
数据标准化 :通过对原始数据进行标准化 ,转换为均值为0标准 差为1的正态分布的数据
正态分布:
是一种改成分布,也叫高斯分布,钟形分布
正态分布记作N(μ,σ)
μ决定了其位置,标准差决定了分布的幅度
μ=0, σ=1,正态分布是标准正态分布
方差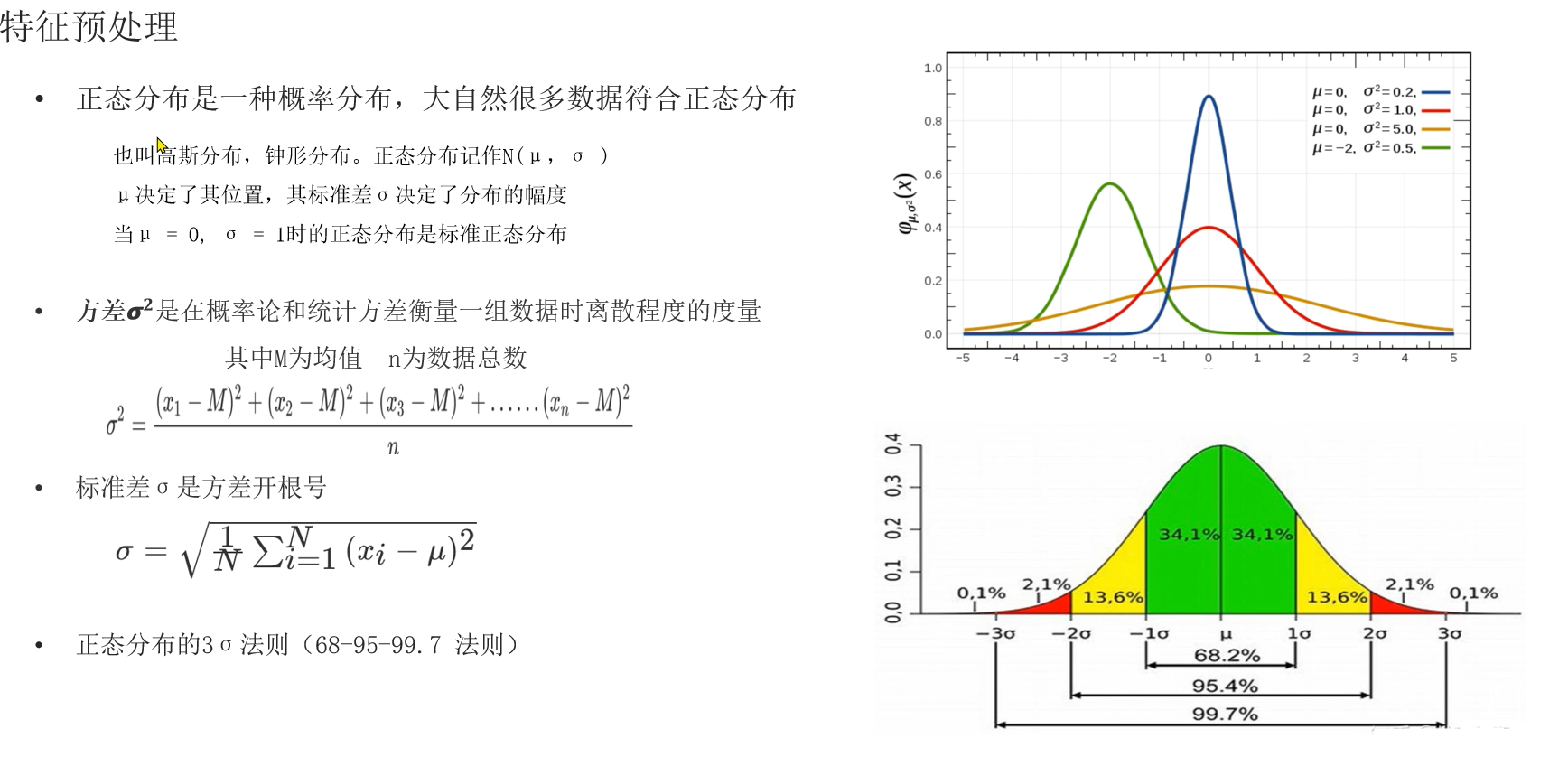
API
"""
案例:演示特征预处理 --标准化
回顾:特征工程目的 和 步骤
目的:
利用专业的背景知识和技巧处理数据,用于提升模型的性能
步骤
1.特征提取
2.特征预处理 归一化 标准化
3.特征降维
4.特征选择
5.特征组合
特征预处理之 标准化介绍:
目的:
防止因为量纲单位问题,导致特征列的方差值相差较大,影响模型最终结果
所以通过公式把 各列的值 映射到 均值为0 标准差为1 的 正态分布序列
公式:
x'=(当前值-该列平均值)/ 该列的标准差
应用场景
适用于大数据集的处理
结论:
无论是归一化还是标准化,目的都是为了解决量纲单位问题,导致模型评估较低等问题
回顾:
方差计算公式:该列每个值和该列均值的差的平方和的平均值
标准差:方差开平方根
"""
#导包
from sklearn.preprocessing import StandardScaler #标准化对象
# 1.准备数据集(标准化之前的原数据)
x_train = [[90,2,10,40],[60,4,15,45],[75,3,13,46]]
# 2.创建标准化对象
transfer = StandardScaler()
#3.对原数据集进行归一化处理
x_train_new = transfer.fit_transform(x_train)
# 4.打印处理后的数据
print("标准化处理后的数据为:", x_train_new)
# 5.打印数据集的均值和方差和标准差
print("数据集的均值为:", transfer.mean_)
print("数据集的方差为:", transfer.var_)
print("数据集的标准差为:", transfer.std_)
5. 案例:利用KNN算法对鸢尾花分类
花萼 sepal 长和宽
花瓣 petal 长和宽
0 1 2 三种鸢尾花

"""
案例:通过KNN算法 实现 鸢尾花 的 分类
回顾:机器学习的研发流程
1.加载数据
2.数据预处理
3.特征工程
提取 预处理
4.模型训练
5.模型评估
6.模型预测
"""
"""
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
"""
#导包
from sklearn.datasets import load_iris #加载鸢尾花测试集的
import seaborn as sns
import pandas as pd
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split #分割训练集和测试集的
from sklearn.preprocessing import StandardScaler #数据标准化的
from sklearn.neighbors import KNeighborsClassifier #KNN算法 分类对象
from sklearn.metrics import accuracy_score #模型评估的 计算模型预测的准确率
# 1. 定义函数 加载鸢尾花数据集,并查看数据集
def dm01_loadiris():
#1.加载鸢尾花数据集
iris_data = load_iris()
# 2. 查看数据集
# print(f'数据集{iris_data}') #字典
# print(f'数据集类型{type(iris_data)}') #<class 'sklearn.utils._bunch.Bunch'>
# 3. 查看数据集所有的键
print(f'数据集所有的键{iris_data.keys()}')
#数据集所有的键dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
# 4. 查看数据集的键对应的值
# print(f'具体的数据:{iris_data.data[:5]}') #有150条数据,每条数据有四个特征,我们只看前五条
# print(f'具体标签:{iris_data.target[:5]}') #有150条数据,每条数据有1个标签,我们只看前五条
print(f'具体的数据:{iris_data.data}') #有150条数据,每条数据有四个特征
print(f'具体标签:{iris_data.target}') #有150条数据,每条数据有1个标签
print(f'标签名称:{iris_data.target_names}') #['setosa' 'versicolor' 'virginica']
print(f'数据集的特征名称:{iris_data.feature_names}') #['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
# print(f'数据集的描述:{iris_data.DESCR}')
# print(f'数据集的frame:{iris_data.frame} ') #None
# print(f'数据集的filename:{iris_data.filename}') #iris.csv
# print(f'数据集的data_module:{iris_data.data_module}') #klearn.datasets.data
# 2.定义函数,绘制数据集的散点图
def dm02_show_iris():
# 1. 加载鸢尾花数据集
irir_data = load_iris()
# 2. 把鸢尾花的数据集转换成DataFrame
irir_df = pd.DataFrame(data=irir_data.data, columns=irir_data.feature_names)
# 3. 给数据集添加标签
irir_df['label']=irir_data.target
print(irir_df)
# 4. 通过seaborn绘制散点图
# 参1:数据集 参2:x轴 参3:y轴 参4:标签 参5:是否显示回归线
sns.lmplot(data=irir_df,x='sepal length (cm)', y='sepal width (cm)', hue='label', fit_reg=True)
# 5. 设置标题 显式
plt.title('iris_data')
plt.tight_layout () #自动调整子图参数,以使得整个图像边界紧贴着子图
plt.show()
# 3.定义函数 切分训练集和测试集
def dm03_split_train_test():
# 1. 加载鸢尾花数据集.
iris_data = load_iris()
# 2. 数据的预处理 :从150个特征和标签中,按照8:2的比例,切分训练集和测试集.
# random_state:随机种子相同,训练集和测试集的切分结果相同
# 返回值:训练集的特征数据、测试集的特征数据、训练集的标签数据、测试集的标签数据
x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=22)
# 3. 打印切割后的结果
print(f'训练集特征数据:{x_train},个数:{len(x_train)}') #120条,每条数据有4个特征
print(f'训练集标签数据:{y_train},个数:{len(y_train)}') #120条,每条数据有1个标签
print(f'测试集特征数据:{x_test},个数:{len(x_test)}') #30条,每条数据有4个特征
print(f'测试集标签数据:{y_test},个数:{len(y_test)}') #30条,每条数据有1个标签
# 4.定义函数,实现鸢尾花完整案例 --》加载数据集,数据预处理,特征工程,模型训练,模型评估,模型预测
def dm04_iris_test():
# 1. 加载数据集
iris_data = load_iris()
# 2. 数据预处理
x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=22)
# 3.特征工程
# 思考一:特征提取:因为源数据是4个特征,所以不需要进行特征提取
# 思考二:特征预处理:因为源数据是连续的,所以不需要进行特征预处理,但是加入代码更完善
# 3.1 创建标准化对象
transfer = StandardScaler()
# 3.2 对数据列进行标准化处理
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4.模型训练
# 4.1 创建模型对象
estimator = KNeighborsClassifier(n_neighbors=5)
# 4.2 具体的模型训练动作
estimator.fit(x_train, y_train)
# 5.模型预测
#场景1: 对刚才切分的30条测试集进行预测
# 5.1直接预测,预测结果保存在y_pre中
y_pre = estimator.predict(x_test)
# 5.2打印预测结果
print(f'预测结果:{y_pre}')
# 场景2:对新数据集进行测试
#5.1 自定义测试数据集
my_data =[[7.8,2.1,3.9,1.6]]
# 5.2 对数据集进行标准化处理
my_data = transfer.transform(my_data) #只有第一次是fit_transform
# 5.3 预测新数据集
y_pre_new = estimator.predict(my_data)
print(f'预测结果:{y_pre_new}')
# 5.4 查看数据集,每种分类的预测结果
y_pre_proba = estimator.predict_proba(my_data)
print(f'预测概率:{y_pre_proba}') #预测概率:[[0. 0.6 0.4]] --->对应的0分类的概率为0 1分类的概率为0.6 2分类的概率为0.4
# 6.模型评估
# 方式一:直接评估,基于:训练集的特征 和 训练集的标签
print(f'准确率:{estimator.score(x_test, y_test)}') #准确率:0.93
# 方式二:基于:测试集的特征 和 测试集的标签
print(f'准确率:{accuracy_score(y_test, y_pre)}') #准确率:0.93
# 5.测试
if __name__ == '__main__':
# dm01_loadiris()
# dm02_show_iris()
# dm03_split_train_test()
dm04_iris_test()
6.超参数训练方法
1.什么是交叉验证
是一种数据集的分割方法,将训练集划分为n份,拿一份做验证集(测试集)、其他n-1份做训练集
2.交叉验证法原理:将数据集划分为cv=4 份
第一次:把第一份做验证集,其他数据做训练
第二次: 把第二份做验证集,其他数据做训练
…训练四次 做四次评估
使用训练集+验证集多次评估,取平均值做交叉验证为模型得分
若k=5模型得分最好,再使用全部训练集(训练集+验证集)对k=5模型在训练一遍,再使用测试集对k=5模型做评估。
3.网格搜索
为什么需要网格搜索?
模型有很多超参,能力存在很大差异。需要手动产生很多超参数组合,来训练模型
每组超参数都蚕蛹交叉验证评估,最后选出最优参数组合建立模型
- 网格搜索时模型调参的有力工具
- 只需要将若干参数传给网格搜索对象,它自动帮我们完成不同超参数的组合、模型训练、模型评估,最终返回一组最优参数
API
sklearn.model_selection.GridSearchCV(estimator,param_grid=None,cv=None)
estimator:估计器对象
param_grid:估计器参数
cv:几折
fit:输入训练数据
score:准确率
结果分析
bestscore_:
"""
交叉验证解释
原理
把数据分成n份,例如4份,也叫4折交叉验证
第一次:把第一份数据作为测试集,其他座位训练集,训练模型,模型预测,获取准确率--》准确率1
第2次:把第2份数据作为测试集,其他座位训练集,训练模型,模型预测,获取准确率--》准确率2
第3次:把第3份数据作为测试集,其他座位训练集,训练模型,模型预测,获取准确率--》准确率3
第4次:把第4份数据作为测试集,其他座位训练集,训练模型,模型预测,获取准确率--》准确率4
然后计算上述四次准确率的平均值 作为:模型的最终准确率
假设第四次最好--准确率最高,则:用全部数据(训练集+测试集)训练模型,再次用测试集对模型测试
目的:
为了让模型的最终验证结果更准确
网格搜索
目的/作用
寻找最优超参
原理:
接受超参可能出现的值,然后针对超参的每个值进行交叉验证,获取最优 超参数组合
超参数:
需要用户手动录入数据,不同超参数组合,肯呢个会影响模型的最终测评结果
大白话解释
"""
#导包
from sklearn.datasets import load_iris #加载鸢尾花测试集的
import seaborn as sns
import pandas as pd
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split,GridSearchCV #分割训练集和测试集的,寻找最优超参的(网格搜索+交叉验证)
from sklearn.preprocessing import StandardScaler #数据标准化的
from sklearn.neighbors import KNeighborsClassifier #KNN算法 分类对象
from sklearn.metrics import accuracy_score #模型评估的 计算模型预测的准确率
# 1 . 定义函数 加载鸢尾花数据集,并查看数据集
iris_data = load_iris()
# 2. 数据预处理
x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=22)
# 3. 特征工程
# 3.1 创建标准化对象
transfer = StandardScaler()
# 3.2 对数据列进行标准化处理
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4 模型训练
# 4.1 创建模型对象 KNN
estimator = KNeighborsClassifier(n_neighbors=5)
# 4.2 定义字典,记录超参出现的情况
param_dict = {'n_neighbors':[i for i in range(1,11)]}
# 4.3 创建GridSearchCV对象--》寻找最优超参,使用网格搜索+交叉验证
# 参数1:要计算最优超参的模型对象
# 参数2:该模型超参可能出现的值
# 参数3:交叉验证的次数,这里的4折表示,每个超参组合,都进行4次交叉验证。这里共计4*10=40次交叉验证
# 返回值 :estimator->处理后的超参对象
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=4)
# 4.4 具体的模型训练
estimator.fit(x_train, y_train)
# 4.5 打印最优超参组合
print(f'最优超参组合:{estimator.best_params_}')
print(f'最优超参组合对应的准确率:{estimator.best_score_}')
print(f'模型预测结果:{estimator.predict(x_test)}')
print(f'模型预测结果:{estimator.cv_results_}')
print(f'模型预测结果:{estimator.best_estimator_}')
# 5.模型评估
# 5.1 获取最优超参的模型对象
# estimator = estimator.best_estimator_
estimator = KNeighborsClassifier(n_neighbors=3)
# 5.2 模型训练
estimator.fit(x_train, y_train)
# 5.3 模型预测
y_pre = estimator.predict(x_test)
# 5.4 模型评估
print(f'准确率:{accuracy_score(y_test, y_pre)}')
7. 利用KNN算法手写数字识别
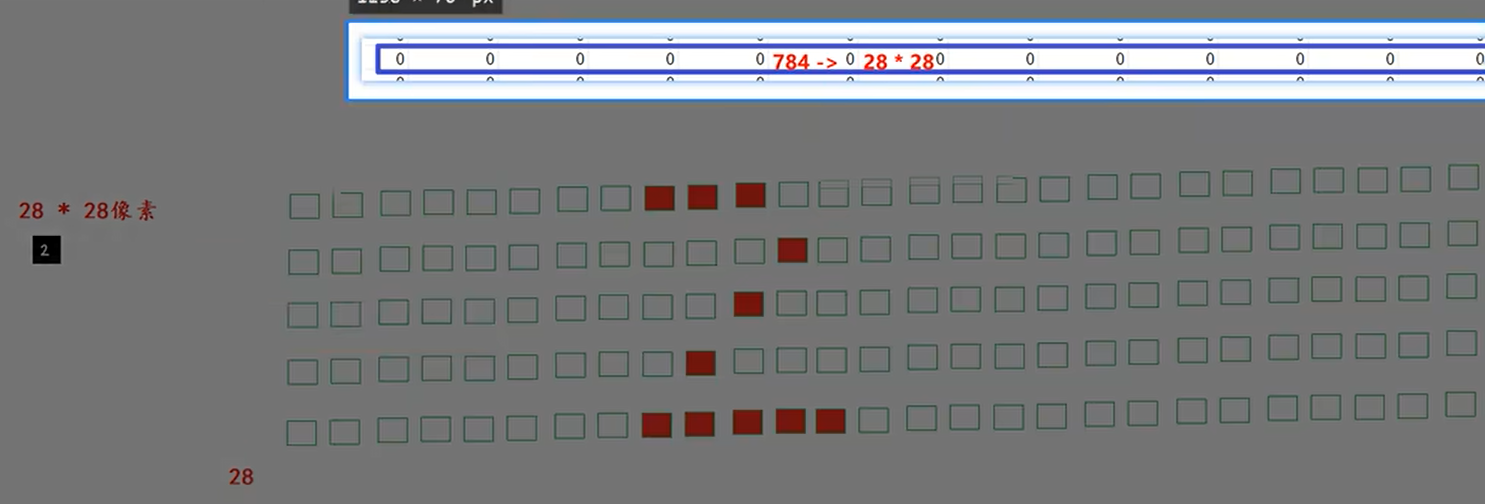
1.数据介绍 train.csv 和 test.csv 包含从0-9的手写数字识别
2.每个图片2828,784个像素
0–纯黑
1–纯白
代码实现
1.加载数据
2.拿到特征、标签
3.特征reshape 2828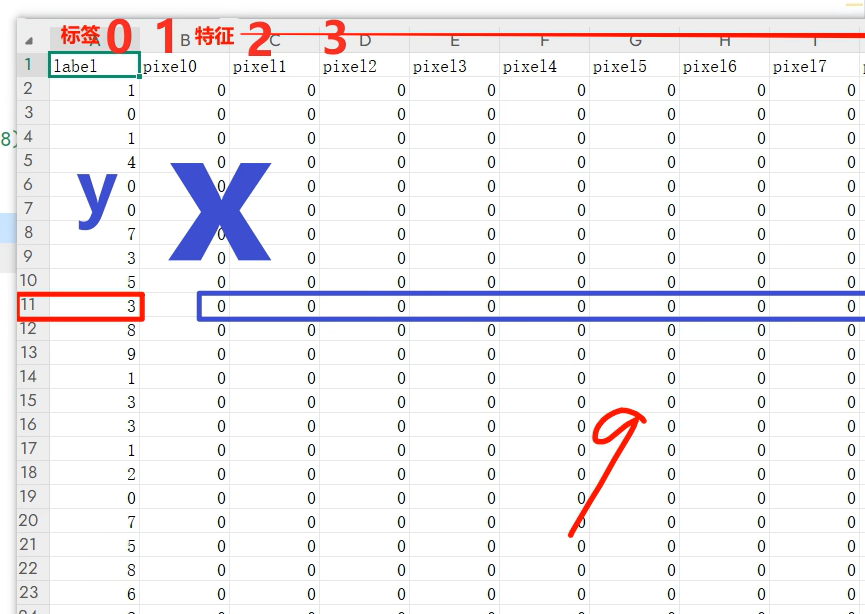
"""
案例:演示KNN算法 识别图片 即:手写数字识别案例
介绍:
每张图片都是由28*28像素组成的,即:我们的csv文件中的每一行都有784个像素点,表示图片(每个像素的颜色)。
最终构成图像
"""
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import joblib
from collections import Counter
# 忽略警告
import warnings
warnings.filterwarnings('ignore',module='sklearn') #参1:忽略警告 警告级别 参2:模块名称 参3:过滤条件
# 1.定义函数,接受用户传入的所有,展示该索引对应的图片
def show_digit(idx):
# 1.读取数据集 获取元数据
df = pd.read_csv('./data/手写数字识别.csv')
# print(df) #(42000行*785列)
# 2.判断传入的索引是否越界
if idx > len(df)-1 or idx<0:
print('索引越界!')
return
# 3.走这里,说明没有越界,就正常获取数据
x = df.iloc[:,1:] #,前所有行 ,后第一列后
y = df.iloc[:,0]
#4.查看数据传入的索引对应的图片 是几?
print(f'该图片对应的数字式:{y.iloc[idx]}')
#5.查看下 用户传入的索引对应的图片的形状
print(x.iloc[idx].shape)
print(x.iloc[idx].values)
# 6. 把(784,)转换成(28,28)
x=x.iloc[idx].values.reshape(28,28)
print(x)
# 7. 具体的绘制灰度图的动作
plt.imshow(x,cmap='spring_r') #灰度图
plt.axis('off') # 不显示坐标轴
plt.show()
#2.[掌握] 定义函数,训练模型,并保存训练好的模型
def train_model():
# 1. 加载数据集
df = pd.read_csv('./data/手写数字识别.csv')
# 2. 数据预处理
#2.1 拆分出特征列
x = df.iloc[:,1:]
# 2.2 拆分出标签列
y = df.iloc[:,0]
# 2.3 打印特征和标签的形状
print(x.shape) # (42000, 784)
print(y.shape) # (42000,)
print(f'y的标签值分布:{Counter(y)}')
# 2.4 对特征列(拆分前)进行 归一化.
# x = x/255.0
x = x
# 2.5 拆分训练集和测试集.
# 参1:特征列 参2:标签列 参3:测试集所占比例 参4:随机数种子 参5:参考y轴比例进行切分,保持数据均衡
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.2,random_state=0,stratify=y)
# 3.模型训练
# 3.1 创建模型对象
estimator = KNeighborsClassifier(n_neighbors=3)
# 3.2 模型训练
estimator.fit(x_train,y_train)
# 4.模型评估
print(f'准确率:{estimator.score(x_test,y_test)}')
print(f'准确率:{accuracy_score(y_test,estimator.predict(x_test))}') #alt+enter 自动导包
# 5.保存模型
# 参数1:模型对象 参数2:保存的文件名
joblib.dump(estimator,'./my_model/手写数字识别.pkl') #pickle文件:python(pandas)的独有文件格式
print('模型保存成功!')
#3.定义函数,测试模型
def test_model(): #pytest
# 1.加载图片
x = plt.imread('./data/demo.png') #28*28
# 2.绘制图片
plt.imshow(x,cmap='gray')
# plt.axis('off') #不显示坐标轴
# plt.show()
#3.加载模型
estimator = joblib.load('./my_model/手写数字识别.pkl')
print('模型加载成功!')
# 4.模型预测
# print(x.shape)
# print(x.reshape(1,784).shape)
# print(x.reshape(1,-1).shape)
#4.2 具体的转换动作
# x = x.reshape(1,-1)/255.0
x = x.reshape(1,-1)
# 4.3 模型预测
print(f'预测结果为:{estimator.predict(x)}')
#4.
if __name__ == '__main__':
# show_digit(9)
# train_model()
test_model()

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 19
19 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)