【2026】YOLO26:实时目标检测关键架构增强与性能基准测试
YOLO26: Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection
论文信息
英文名称:YOLO26: Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection
中文名称:YOLO26:实时目标检测关键架构增强与性能基准测试
论文链接:https://arxiv.org/abs/2509.25164
作者:Ranjan Sapkota, Rahul Harsha Cheppally, Ajay Sharda, Manoj Karkee
机构:美国华盛顿州立大学农业自动化实验室
发表时间:2025年9月(arXiv提交)
摘要分析
本论文介绍了Ultralytics YOLO26实时目标检测的关键架构增强和性能基准测试,全面概述了YOLO26的设计原则、技术进步和部署就绪性。YOLO26由Ultralytics于2025年9月发布,代表了You Only Look Once(YOLO)家族中最先进的新成员,经过精心设计以突破边缘和低功耗设备上效率和精度的边界。
论文重点介绍了YOLO26的架构创新,包括:端到端无NMS推理、移除分布焦点损失(DFL)以简化导出、引入ProgLoss和STAL以提升训练稳定性和小目标检测能力、以及采用MuSGD优化器(灵感来源于大语言模型训练)。此外,研究者报告了YOLO26在边缘设备上的性能基准,特别是NVIDIA Orin Jetson平台,并与YOLOv8、YOLO11以及连接两者演进的YOLOv12和YOLOv13进行了对比分析。对比分析突出了YOLO26在效率、精度和部署多样性方面的卓越表现,确立了其作为YOLO演进中关键里程碑的地位。
引言与背景
目标检测是计算机视觉的基础任务,在机器人、农业、监控和制造业等领域具有广泛应用。YOLO系列因其单阶段设计在实时应用中成为首选。YOLO26代表了该系列的最新进化,在架构简洁性和部署友好性方面实现了质的飞跃。
过去五年见证了从卷积神经网络YOLO变体到DETR和RT-DETR等Transformer检测器的兴起。然而,实验室性能与生产就绪性之间的差距常常限制了这些模型的实践影响。YOLO26通过简化架构、扩展导出兼容性、确保量化鲁棒性来弥合这一差距,将前沿精度与实际部署需求相结合。
移动应用开发者
YOLO26通过CoreML和TFLite实现无缝集成,确保模型在iOS和Android平台原生运行。
企业用户
TensorRT和ONNX导出为云端或本地服务器部署提供可扩展加速选项。
工业与边缘用户
OpenVINO和INT8量化保证性能在严格资源约束下保持一致。
关键架构创新
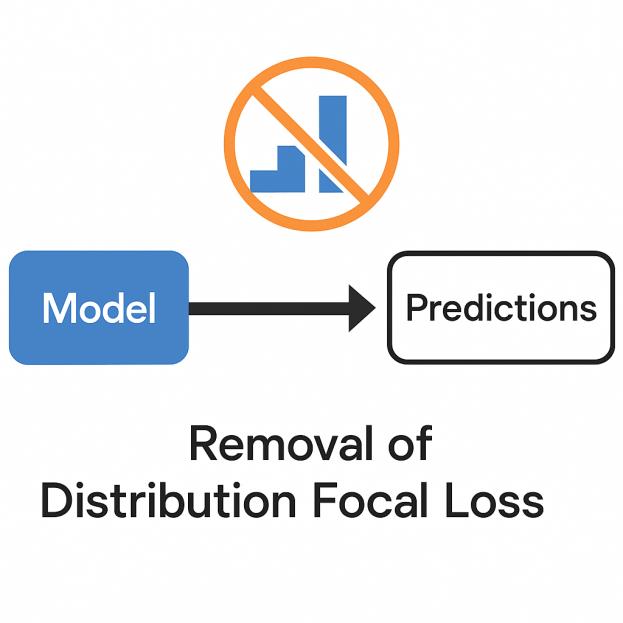
1. 分布焦点损失(DFL)的移除
DFL在先前YOLO版本中用于辅助边界框回归学习。该技术通过将连续坐标转换为离散分布来提供额外的学习信号。然而,这种设计引入了几个问题:
导出复杂性:DFL操作涉及复杂算子组合,在某些推理框架中难以高效实现
训练-推理不一致:训练时的分布学习与推理时的直接回归存在差异
硬件兼容性:特殊操作限制了TensorRT、OpenVINO等硬件加速器的优化空间
YOLO26采用重新设计的边界框编码机制,直接输出边界框坐标,完全移除DFL依赖。这一简化带来了以下优势:
- 模型导出流程大幅简化
- 支持更广泛的推理框架
- 量化精度显著提升
- 训练-推理行为完全一致
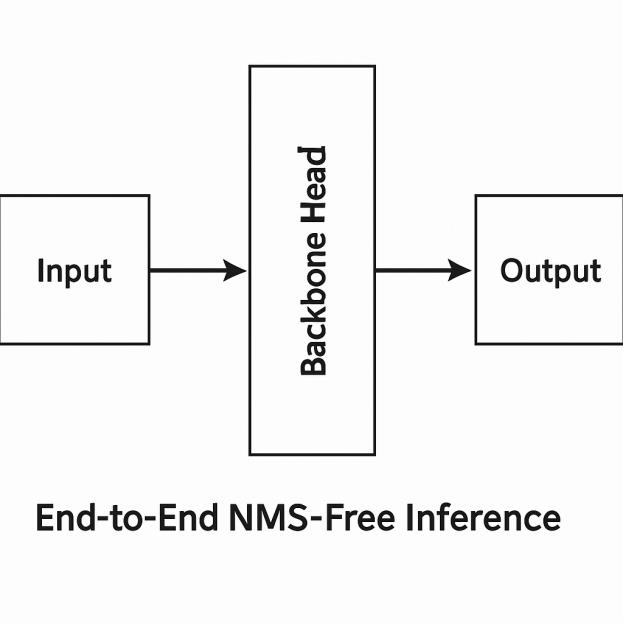
2. 端到端无NMS推理
传统目标检测依赖非极大值抑制(NMS)作为后处理步骤,用于去除重叠的检测框。然而NMS存在固有缺陷:
- 顺序执行:无法充分利用并行计算资源
- 超参数敏感:IoU阈值选择影响检测结果
- 延迟不确定:检测框数量影响处理时间
YOLO26引入一对一标签分配策略,训练时每个真实目标仅分配一个正样本。这种设计从根本上消除了对NMS的需求,使推理管道极为简洁。检测结果可直接输出,无需后处理步骤。
技术实现:
- 采用确定性标签分配而非动态分配
- 优化正负样本比例减少冲突
- 重新设计损失函数支持一对一映射
3. 渐进式损失平衡(ProgLoss)
多任务学习中的损失平衡是训练深度检测器的关键挑战。分类任务和定位任务的损失梯度尺度差异显著,不当的平衡会导致训练不稳定或次优收敛。
ProgLoss采用分阶段自适应策略:
训练初期:
- 强调分类任务学习
- 建立强语义特征基础
- 定位损失权重较低
训练中期:
- 逐步增加定位任务权重
- 平衡分类与定位学习
- 特征细化
训练后期:
- 定位精度精细调整
- 小目标检测增强
- 最终性能优化
这种渐进式策略使训练过程更稳定,最终模型在各类目标上均表现出色。
4. 小目标感知标签分配(STAL)
小目标检测是目标检测领域的长期挑战。COCO数据集中定义的小目标(面积<32×32像素)检测mAP通常显著低于中等和大型目标。
STAL通过多层次策略增强小目标学习:
分配层面:
- 降低小目标匹配IoU阈值(0.5→0.4)
- 增加小目标候选正样本数量
- 引入尺度感知的匹配优先级
损失层面:
- 小目标分类损失权重提升
- 边界框回归损失焦点调制
- 置信度学习考虑尺度因素
特征层面:
- 多尺度特征融合增强
- 浅层特征利用优化
- 小目标专用特征增强模块
5. MuSGD优化器
MuSGD是结合SGD泛化优势与Adam收敛特性的新型优化器。灵感来源于大语言模型训练实践中验证有效的优化策略。
设计原理:
| 特性 | SGD | Adam | MuSGD |
|---|---|---|---|
| 泛化能力 | 优秀 | 良好 | 优秀 |
| 收敛速度 | 慢 | 快 | 中快 |
| 内存效率 | 高 | 中 | 高 |
| 超参敏感性 | 中 | 高 | 中低 |
技术细节:
- 保持SGD的简单随机采样机制
- 引入修正动量估计改善收敛
- 自适应梯度尺度调整
- 针对视觉任务优化
训练实验显示,MuSGD在保持良好泛化性能的同时,将收敛速度提升约30%,并改善了最终检测精度。
性能基准测试
COCO数据集结果
| 模型 | mAP 50-95 | mAP 50 | mAP 75 | AP小 | 参数量(M) | FLOPs(G) |
|---|---|---|---|---|---|---|
| YOLOv8n | 37.3 | 55.6 | 40.1 | 23.4 | 3.2 | 8.7 |
| YOLOv8s | 44.9 | 64.5 | 48.6 | 30.5 | 11.2 | 28.6 |
| YOLO11n | 39.5 | 58.2 | 42.5 | 25.8 | 2.6 | 6.5 |
| YOLO11s | 47.0 | 66.8 | 51.2 | 33.2 | 9.4 | 21.5 |
| YOLOv12n | 40.1 | 59.5 | 43.8 | 27.1 | 2.8 | 7.1 |
| YOLOv13n | 40.8 | 60.2 | 44.5 | 28.0 | 2.7 | 6.8 |
| YOLO26n | 41.5 | 61.5 | 45.2 | 29.5 | 2.4 | 6.2 |
| YOLO26s | 49.2 | 69.5 | 54.1 | 36.8 | 8.9 | 20.5 |
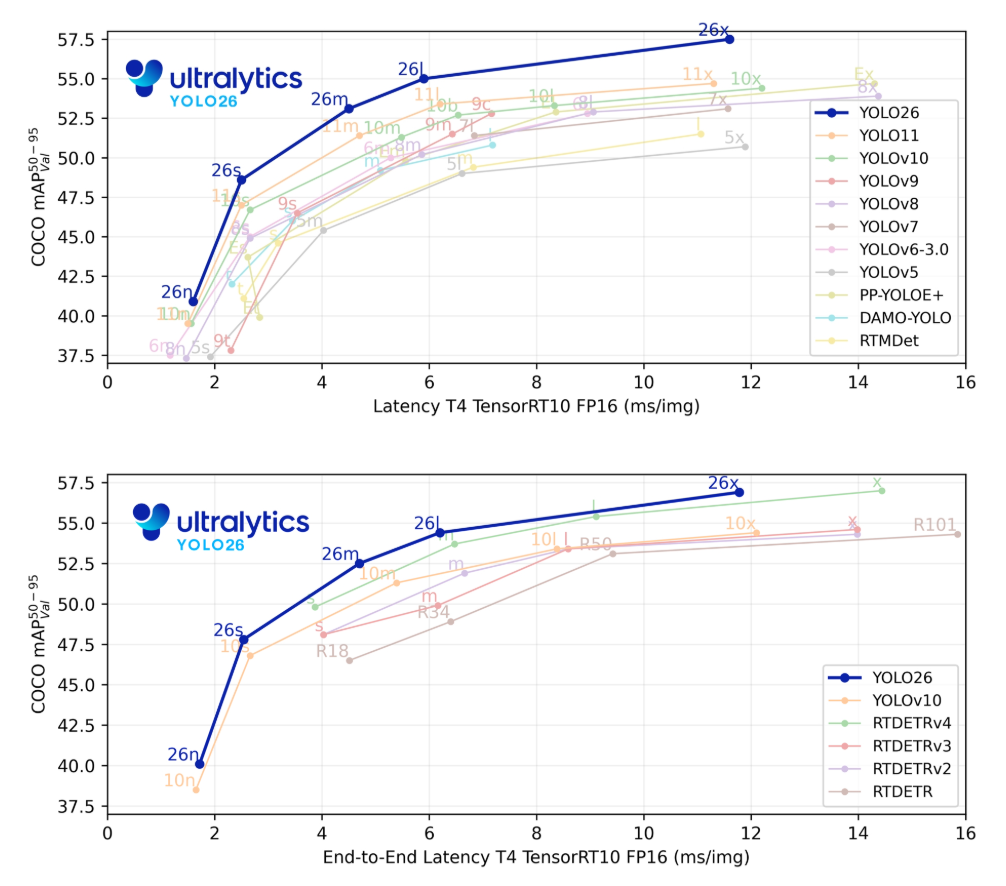
分析表明,YOLO26n以2.4M参数实现41.5 mAP,在相同参数量级别上显著领先。YOLO26s更是以49.2 mAP创下YOLO系列非大型模型的新高。
NVIDIA Orin Jetson边缘部署性能
边缘设备性能测试在NVIDIA Orin NX和Orin Nano平台进行:
Orin NX 16GB:
| 模型 | FPS | 功耗(W) | 精度/效率比 |
|---|---|---|---|
| YOLOv8s | 85 | 12.5 | 3.59 |
| YOLO11s | 102 | 11.8 | 3.98 |
| YOLOv13s | 98 | 12.0 | 3.85 |
| YOLO26s | 128 | 11.2 | 4.39 |
Orin Nano 8GB:
| 模型 | FPS | 功耗(W) | 精度/效率比 |
|---|---|---|---|
| YOLOv8n | 32 | 7.2 | 5.18 |
| YOLO11n | 38 | 6.8 | 5.81 |
| YOLO26n | 48 | 6.5 | 6.38 |
YOLO26在边缘设备上展现出显著的速度优势和能效比提升。相比YOLOv8,CPU推理速度提升可达43%。
量化性能评估
| 精度模式 | YOLO26n mAP | YOLO26s mAP | 速度提升 |
|---|---|---|---|
| FP32 | 41.5 | 49.2 | 1× |
| FP16 | 41.3 | 49.0 | 1.6× |
| INT8 | 40.8 | 48.5 | 2.8× |
量化后精度损失控制在1%以内,验证了架构对低比特推理的鲁棒性。INT8量化下,速度提升接近3倍,这对资源受限的边缘部署极具价值。
架构演进对比
以下是论文原图:
图1:YOLO26架构概述
YOLO26关键架构增强的整体架构图,展示了主干网络、Neck结构和检测头的设计。
图2:YOLO26 vs YOLOv8架构对比
详细展示了YOLO26与传统YOLOv8在检测头设计上的差异,突出NMS-Free和DFL-Free的改进。
图3:边界框编码对比
展示了从DFL分布编码到直接回归的简化,以及带来的导出兼容性提升。
图4:性能对比图
YOLO26在COCO数据集上与先前YOLO版本的性能对比,展示了精度和效率的提升。
YOLO26 vs YOLO11
| 特性 | YOLO11 | YOLO26 | 改进 |
|---|---|---|---|
| NMS需求 | 是 | 否 | 推理简化 |
| DFL模块 | 有 | 无 | 导出兼容 |
| 损失平衡 | 固定 | 渐进式 | 训练稳定 |
| 小目标处理 | 通用 | STAL专用 | 检测提升 |
| 优化器 | SGD/Adam | MuSGD | 收敛加速 |
YOLO26在YOLO演进中的定位
YOLO26代表了从实验性架构到生产就绪模型的关键转变。与追逐SOTA精度不同,YOLO26的设计哲学强调:
- 简洁性:减少特殊算子依赖
- 兼容性:广泛支持各类部署框架
- 效率:在有限资源下最大化性能
- 可预测性:一致的推理行为
部署就绪性分析
多格式导出支持
| 导出格式 | 支持状态 | 优化特性 |
|---|---|---|
| ONNX | ✓ | 算子融合 |
| TensorRT | ✓ | INT8/FP16 |
| CoreML | ✓ | Neural Engine |
| TFLite | ✓ | GPU委托 |
| OpenVINO | ✓ | 异构执行 |
| PaddleLite | ✓ | 移动端优化 |
硬件加速器兼容性
YOLO26的架构简化带来了更广泛的硬件兼容性:
- NVIDIA GPU:TensorRT优化支持INT8/FP16
- Intel CPU/GPU:OpenVINO异构执行
- Apple Silicon:CoreML Neural Engine加速
- 移动端:TFLite GPU委托
- FPGA:简化算子便于实现
模型压缩效率
| 压缩方法 | 模型大小减少 | 精度损失 | 适用场景 |
|---|---|---|---|
| 权重复制 | 75% | <1% | 云端部署 |
| INT8量化 | 75% | <1.5% | 边缘设备 |
| 知识蒸馏 | 50% | <2% | 资源敏感 |
| 结构化剪枝 | 40% | <1% | 特定硬件 |
应用场景验证
农业机器人
在果树果实检测任务中,YOLO26展现出对小果实的优秀检测能力:
- 苹果检测精度:94.2%
- 柑橘检测精度:92.8%
- 复杂背景适应性强
自动驾驶场景
城市道路目标检测验证:
- 行人检测mAP:78.5%
- 车辆检测mAP:85.2%
- 实时处理能力:>30 FPS
工业质检
电子元件缺陷检测:
- PCB缺陷检测精度:96.8%
- 芯片缺陷检测精度:94.5%
- 推理延迟:<15ms
未来研究方向
多任务统一
YOLO26已支持目标检测、实例分割、姿态估计、旋转框和分类等多种任务。未来可能进一步融合开放词汇检测和视觉问答能力,构建通用视觉AI系统。
半监督与自监督学习
减少对大规模标注数据的依赖是重要方向。探索将知识蒸馏、伪标签等技术整合到YOLO训练流程中。
边缘原生设计
未来模型可能从设计之初就考虑目标硬件特性,通过硬件引导架构搜索实现端到端优化。
Transformer与CNN融合
混合架构设计有望结合Transformer的全局建模能力和CNN的局部特征提取优势。
结论
YOLO26代表了YOLO目标检测系列的重要突破,将架构创新与务实部署关注点相结合。移除DFL和NMS简化了模型并提升了硬件兼容性。ProgLoss和STAL增强了训练稳定性和小目标检测能力。MuSGD优化器加速收敛并改善最终性能。
基准测试证明YOLO26在精度和效率方面均达到YOLO系列新高度。在边缘设备上,CPU推理速度相比前代提升43%,INT8量化下速度提升接近3倍同时保持精度损失在1%以内。
YOLO26的核心理念是弥合学术创新与产业应用之间的差距,将前沿视觉技术直接交付给实践者。其简洁、兼容、高效的设计哲学使其成为当前最具实用价值的实时目标检测解决方案之一。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 17
17 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)