医患沟通评价系统(5)——降低对话延迟调研
当前架构及缺陷
当前已初步实现AI对话,架构如下:
前端生成音频--->后端音频转文字--->后端文字LLM--->后端文字转音频--->前端读取音频并播放
这样会带来以下几个延迟瓶颈:
- 非流式输出。必须生成完整对话才能输出给前端,造成极其严重的延迟(约10s)
- 文件锁。因为是将WAV音频存在电脑本地,读写文件会有文件锁的延迟
拟解决方案如下:
- 将LLM改为流式输出。后端通过SSE将音频传给前端,前端进行播放
- 消灭文件锁和磁盘延迟,消灭本地文件读写、改用全内存流式/字节流传输
实现步骤
LLM、TTS流式输出
开启deepseek流式输出,通过标点符号切片,并同时将切片传输给TTS进行文字转语音
调研发现,阿里云TTS返回的是 Base64 编码的原始 PCM,为防止读写文件造成的磁盘延迟,直接将Base64编码的字符串发给前端
此时实现:前端发送Base64编码音频->千问ASR语音转文字->Deepseek LLM+千问TTS流式输出 ->将Base64音频发送给前端
前端SSE接受数据
前后端通信使用SSE,遗憾的是,普通的 VaRest 插件或 UE5 蓝图 HTTP 节点是不支持 SSE 的
于是我编写了一个SSE异步接收数据的C++程序,并通过蓝图形式暴露接口。图中ConnectToSSE即为编写的函数,一旦接收到后端发出的信号,立刻通过委托形式进行下一步处理
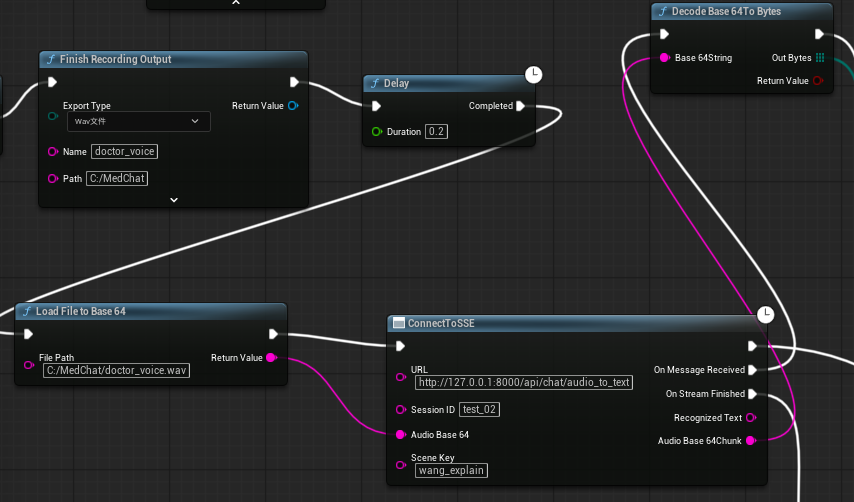
前端Base64转SoundWave
此时后端发来的Base64已接受到前端,为了避免读写数据造成的延迟,我们需要将Base64转化为UE5自带的SoundWave进行音频播放和唇形同步。
非常遗憾的是,翻遍了资料没有实现此功能的插件,甚至连实现方法和教程都没有,依旧只能自己摸索。
经过调研,应该通过如下方式进行转化:
Base64->解码成二进制->SoundWave
第一步:Base64解码为二进制,这个UE5有底层API实现,轻轻松松
第二步:完蛋了。
首先我们要知道Audio2Face 插件在底层有一个硬性限制:它需要对音频进行实时的多线程代理分析(CreateSoundWaveProxy),而虚幻引擎官方代码明确规定:程序化音频(Procedural)不允许创建分析代理!所以使用RuntimeAudioImporter插件进行生成Wave这条路被堵死了,因为该插件生成的是程序化音频。
因此,我需要去了解SoundWave的底层架构,自行去构建一个SoundWave进行传输。
SoundWave中有两个数据结构,分别为RawPCMData和RawData,二者功能及区别如下:
RawPCMData:UE音频组件调用,播放音乐
RawData:Audio2Face插件调用,唇形同步,并且要求WAV格式。
因此,二进制数据要同时注入这两个Buffer,才能够正常使用。
效果以及下一步目标
实现流式输出后,对话延迟从10s以上降低到了约3s,是可容忍的对话延迟。
下一步要进行角色肢体动作的制作,从提高沉浸感的角度侧面降低对话延迟带来的负面感受。
以及优化唇形同步带来的性能问题。当前16GB内存的笔记本运行程序非常卡,64GB台式运行基本流畅。下一步需要调研是否有更低性能要求的唇形同步方案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)