MiniMind代码复现实战总结
文章目录
前言
本文对MiniMind的代码复现的过程进行了详细描述,并记录了自己在此过程中的心得体会,形成一篇实战总结。
作者:张硕 中国科学院大学人工智能学院 自动化研究所
课程:自然语言处理
时间:2026.4.25
摘要
本实验基于开源项目 MiniMind,在单张 NVIDIA RTX 3090 上,从零开始完整复现了一个参数量仅为 63.91M 的轻量级中文大语言模型。实验严格遵循“预训练(Pretrain) + 有监督微调(SFT)”的标准两阶段范式,总训练时长约 4 小时。实验后,模型在开放性中文问答中展现出了一定的常识与生成能力,并在 C-Eval 评测集上取得了 22.88% 的准确率。本报告详细记录了环境配置、数据集预处理、模型架构学习、训练监控、推理测试及客观评测的全过程,并对 eval_llm.py 等核心推理代码进行了深入分析。
一、 项目背景与源码学习
1.1 MiniMind 项目简介
MiniMind 是一个旨在用极低成本从零训练小语言模型的教程式开源项目。它的代码完全基于 PyTorch 原生实现,不依赖 transformers 等高层封装的训练接口,非常适合用来深入理解大模型的底层运作机制。
1.2 核心推理代码学习笔记(eval_llm.py)
在开始训练前,我首先研读了项目的推理脚本 eval_llm.py,以理解模型的加载和交互逻辑。
-
双模式加载:脚本通过
--load_from参数支持两种模型加载方式。一种是加载原生 PyTorch 保存的.pth权重(对应model模式),另一种是直接使用AutoModelForCausalLM加载 HuggingFace 格式的模型。这种设计让同一份推理代码可以兼容自己的预训练权重和转换后的标准格式。 -
LoRA 热插拔:在
init_model函数中,我看到如果在加载原生权重时指定了--lora_weight,脚本会先后调用apply_lora(model)和load_lora(...)来自动注入 LoRA 适配器。这展示了 PEFT 技术在实际应用中的灵活性。 -
自适应思考:代码通过
open_thinking参数和tokenizer.apply_chat_template(..., open_thinking=bool(...))实现了对显式推理链的控制。这让我理解了,所谓的“思考模型”能力可以直接通过模板注入<think>标签来开关,而不必训练两个单独模型。 -
生成参数控制:
model.generate接口中使用了do_sample=True、top_p=0.95、temperature=0.85和repetition_penalty=1。这些标准参数控制着模型输出的随机性和多样性,是防止生成内容单调重复的关键。
1.3 模型结构学习(model_minimind.py)
通过查阅项目文档和配置,我梳理了 MiniMind 的架构,其对齐了 Qwen3 的设计思路:
-
小体积,大智慧:模型总参数仅 63.91M,其中可训练参数 63.912M。这比 GPT-3 小了约 2700 倍,使其能在消费级显卡上轻松训练。
-
核心配置:从
model_config.txt可知,模型采用 8 层 Transformer Decoder,隐藏层维度 768,配备 8 个 Query 头和 4 个 Key-Value 头(GQA,分组查询注意力),词表大小 6400,支持的最大序列长度为 32768。
-
现代化技术:模型使用了 RMSNorm 进行归一化、SwiGLU 作为激活函数、RoPE 作为位置编码,这些都是当前主流大模型的标配。
二、实验环境搭建
在实验环境配置中,我准备了所有必需的软件依赖。从 env_versions.txt 记录的版本信息可以看出,本实验的核心框架均采用了较新的稳定版本。

三、数据集准备与格式分析
3.1 数据集概览
我使用了项目推荐的 mini 级别数据用于快速复现。从 dataset_info.txt 确认,核心的两个数据文件大小分别为 1.2GB 和 1.7GB。

-
预训练集 (
pretrain_t2t_mini.jsonl): 1.2GB,约 39,695 条样本。 -
微调集 (
sft_t2t_mini.jsonl): 1.7GB,约 56,608 条样本。
3.2 数据格式理解
通过分析 data_sample_pretrain.txt 和 data_sample_sft.txt,我了解了两种数据的前处理方式。


-
预训练数据:是最简洁的
{"text": "..."}格式,直接将原始文本拼接起来进行“下一个词预测”。样例中包含了对诗歌、故事、问答等混合文本,这种多样性有助于模型学习广泛的语言模式。 -
SFT 数据:采用了标准的多轮对话格式,包含
role(如user,assistant)和content。特别值得注意的是,数据中已经包含了reasoning_content字段,这表明项目方在指令微调阶段就引入了思考链数据,让模型学会在内部推理后再生成答案。
四、预训练阶段
4.1 训练命令与过程
我进入 trainer 目录,执行了预训练脚本,并使用 tee 命令将完整的终端输出保存为 pretrain.log。
cd trainer
python train_pretrain.py 2>&1 | tee ../report_materials/logs/pretrain.log
4.2 训练日志分析与 Loss 曲线
从 pretrain.log 可以看到,模型初始(Step 100)的交叉熵损失高达 7.5223,说明模型此时对输出基本是随机猜测。随着训练进行,损失值稳步下降。
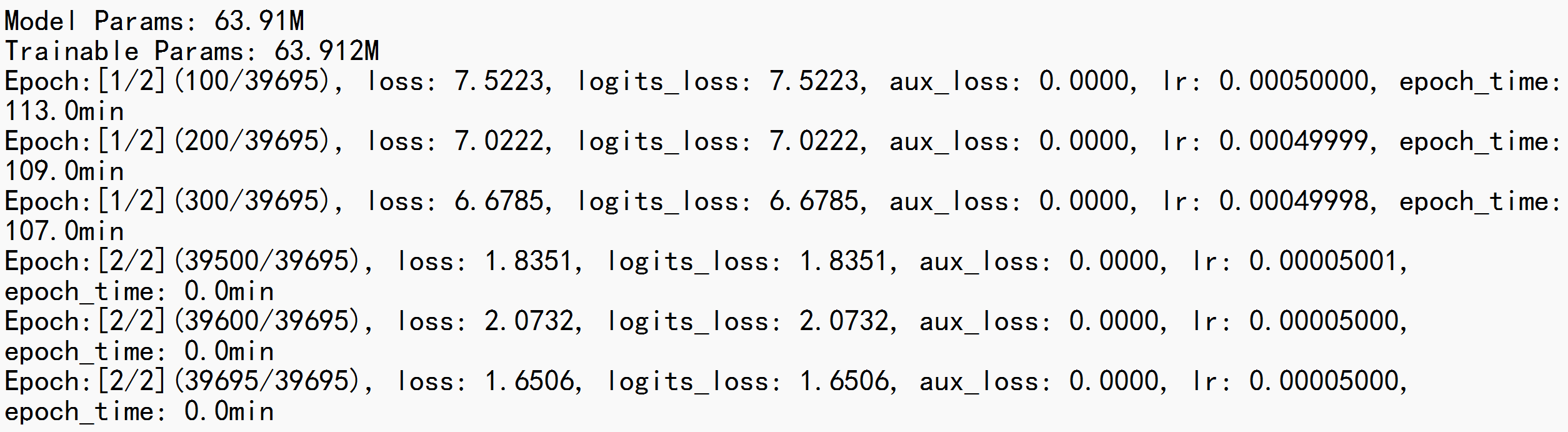
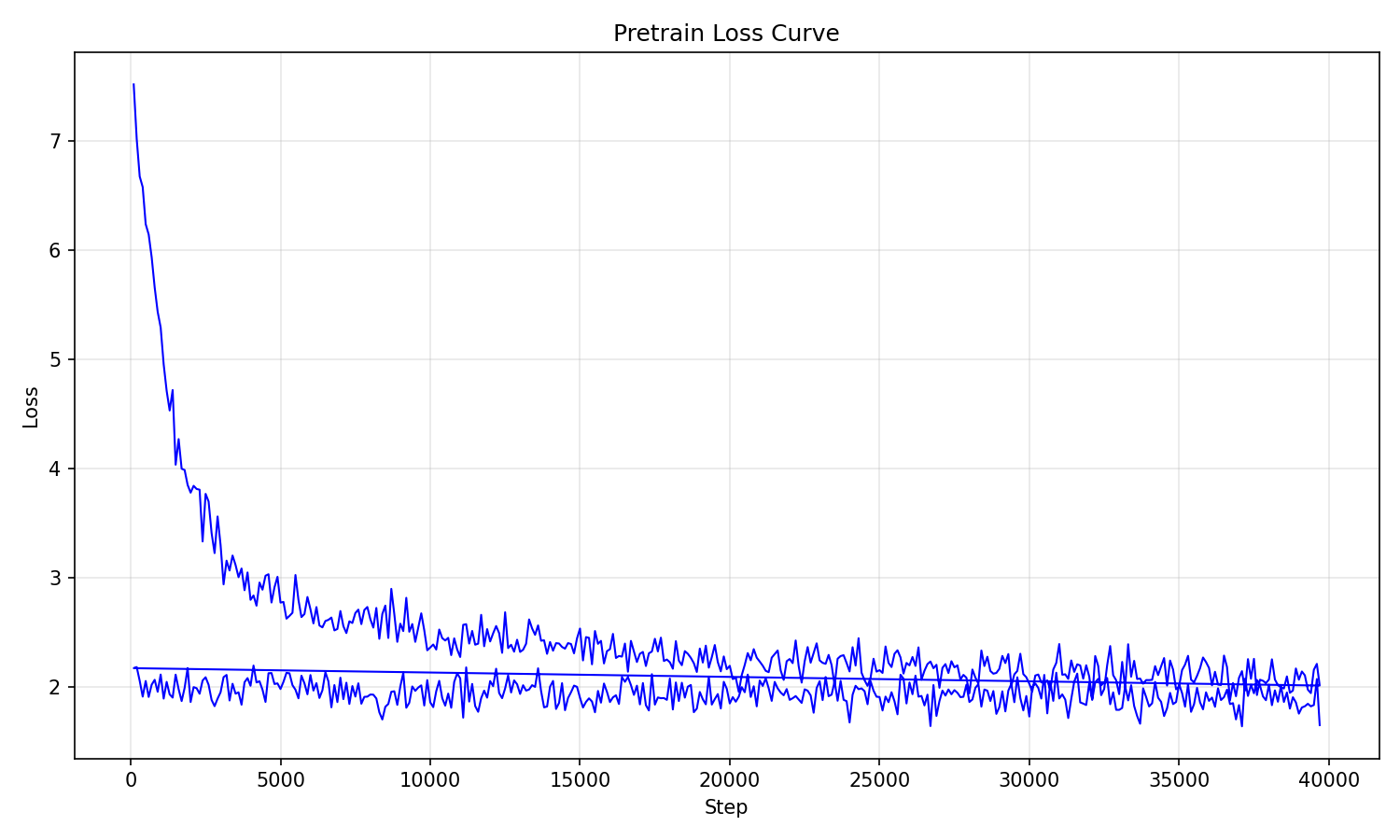
上图是根据 pretrain_loss.csv 中提取的 Step 和 Loss 数据绘制而成的预训练损失曲线。结合日志和曲线,我将整个训练过程划分为几个阶段:
-
快速下降期 (Step 0 - 10,000): Loss 从 7.52 急剧下降到 2.36 左右。模型迅速学会了基础的词汇、语法和简单常识。
-
缓慢收敛期 (Step 10,001 - 39,695,Epoch 1 后段): Loss 在 2.0 - 2.7 之间震荡,下降趋势变缓,模型开始学习更复杂的语义模式。
-
稳定精调期 (Epoch 2): Loss 进一步降低,在 1.7 - 2.1 的区间内窄幅震荡。到训练结束时(Step 39695),最终 loss 收敛于 1.6506。
最终,一个 132MB 的预训练基础权重 pretrain_768.pth 被保存在 out 目录下。
五、 有监督微调阶段
5.1 训练命令与过程
预训练完成后,我紧接着在同一目录下启动了 SFT 训练。
python train_full_sft.py 2>&1 | tee ../report_materials/logs/sft.log
5.2 训练日志分析与 Loss 曲线
SFT 阶段的初始 loss 仅为 2.1096,远低于预训练初始,这表明预训练权重为模型提供了极好的初始化。
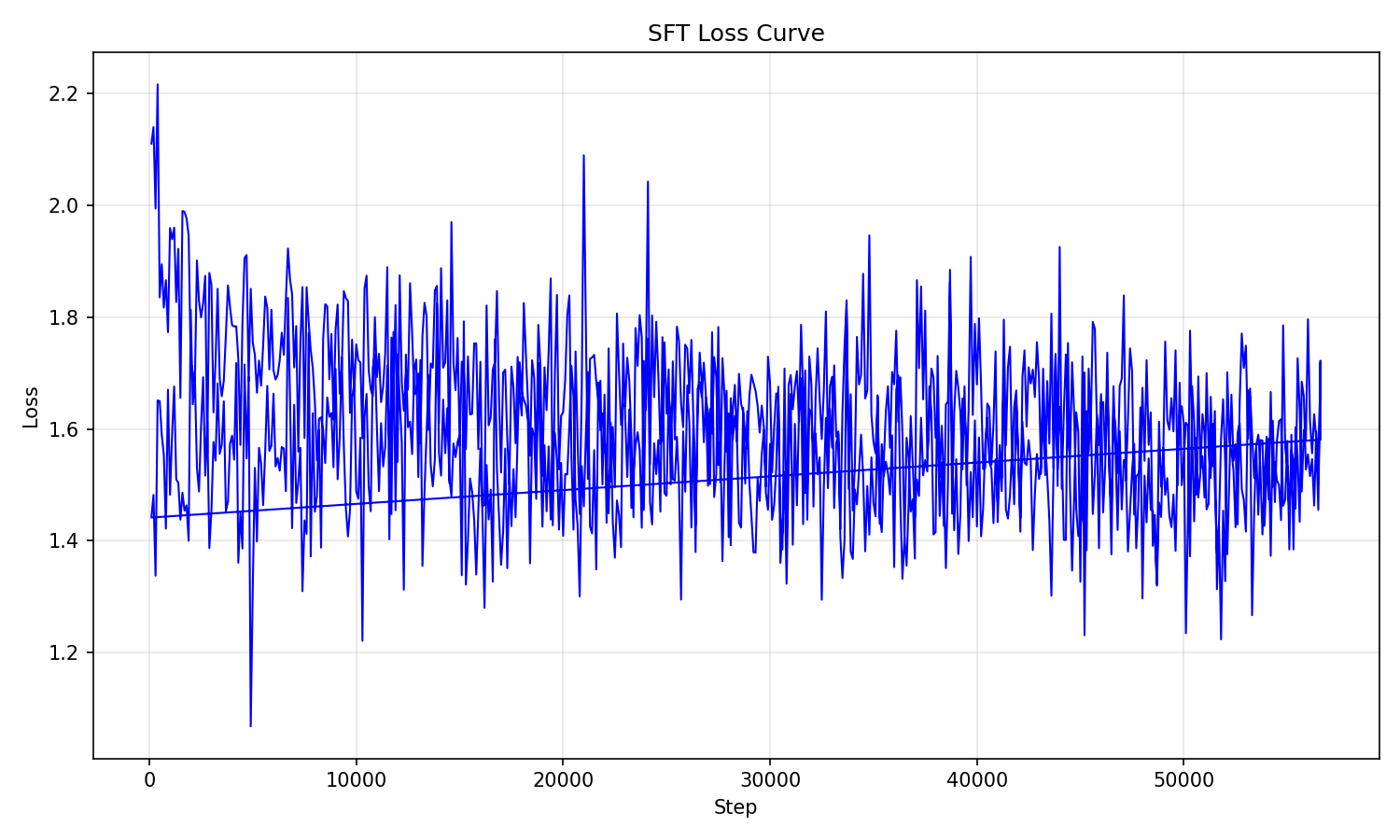
上图由 sft_loss.csv 生成。与预训练平滑下降的曲线不同,SFT 的 loss 曲线呈现出以下几个特点:
-
起点低,波动大:损失值全程在 1.2 到 2.2 之间剧烈波动。这是因为 SFT 数据由各式各样的指令和回答组成,不同样本的学习难度差异很大。
-
快速收敛,震荡中学习:模型Loss很快下降到1.5附近,并在Epoch 1和Epoch 2的整个训练过程中保持这种震荡状态,没有发生明显的过拟合(Loss突然回升)。
-
最终结果:经过两个 epoch 的训练,最终 loss 定格在 1.7165。
训练结束后,我得到了最终可对话的模型权重 full_sft_768.pth。
六、 结论
为了直观评价模型性能,我使用最终权重 full_sft 运行了 eval_llm.py,并设计了一组涵盖知识、代码、常识、逻辑、创意的问题进行测试。完整的对话记录已保存在 dialogue_test.txt 中。以下是核心问答片段的详细分析:
6.1 知识问答:“为什么天空是蓝色的?”

评价:模型展现出了对“瑞利散射”相关概念的理解痕迹。它正确地指出了天空颜色与大气分子和光的散射有关,虽然表述中存在一些事实混淆(如将蓝色归因于分子颜色),但作为仅62M参数的模型,其输出表现出了初步的科学知识。
6.2 代码生成:“请用Python写一个计算斐波那契数列的函数”

评价:模型展现出了代码生成的能力。函数逻辑基本正确,但代码风格上存在冗余(循环内append了两次),这在小模型上非常典型,体现了它在理解代码时更侧重模式模仿而非严密逻辑。
6.3 常识与概念:“解释什么是机器学习”

评价:这是一个非常典型且高质量的回答。模型清晰、通顺地定义了机器学习的核心概念,并列举了数据、算法、评估等关键组件,连贯性表现相当出色。
6.4 创意推荐:“推荐一些中国的美食”

评价:回答非常成功。列举的美食种类丰富、准确,展现了模型在其知识范围内良好的归纳和表达能力。
6.5 语境理解与建议:“如果明天下雨,我应该如何出门”

评价:这是一个非常典型的小模型对话“跑题”案例。用户的问题是针对“下雨天”这一具体情境寻求出门建议,但模型的回答完全偏离了这一核心约束。
从回答的开头可以看出,模型似乎捕捉到了“天气”和“季节”这两个关键词,但随后它就陷入了一个固定的模板——开始机械地按春、夏、秋、冬四个季节罗列户外活动建议,并且内容中存在大量重复(如秋季和夏季都被列举了两次)。整个回答完全没有提到“雨伞”、“雨衣”、“防滑”、“交通安全”或“室内活动替代方案”等与下雨场景直接相关的内容。
这个案例暴露了小模型在上下文精确理解和逻辑约束保持方面的明显缺陷。它更像是在进行“天气-季节-活动”的自由联想,而无法将“下雨”这个关键条件始终绑定在生成的每一句话上。这也是小模型在对话中经常出现“答非所问”、“牛头不对马嘴”现象的根本原因——它记住了常见的语言模式,但缺乏对具体约束条件的严密推理和追踪能力。
总体评价:63.91M 的 MiniMind 模型已经具备了相当的基础知识、代码生成和一定的概念解释能力,其流畅度令人惊喜。但其在严肃的逻辑推理和长篇论述方面仍有明显不足,容易产生事实错误和偏题情况。
七、 客观评测:C-Eval 基准测试
为量化模型在中文知识上的能力,我使用 lm-evaluation-harness 在 C-Eval 验证集上进行了评测,结果保存在 ceval_result.txt 中。
-
模型路径:
./minimind-3(由full_sft_768.pth转换得到) -
综合得分:acc = 22.88%
评测结果表明,模型在52个细分学科上的表现并不均衡。表现最好的学科是艺术学(45.45%)、离散数学(37.50%),而表现最差的学科是法学(4.35%)。这种差异很可能与预训练数据中各学科知识的分布有关。
八、 实验成果与总结
8.1 成果输出
本次实验从零开始完整复现了 MiniMind 小语言模型的训练全流程,所有核心产出均有序保存在 report_materials 和 out 目录下。实验的最终模型权重为 out/full_sft_768.pth,文件大小 132MB,这是经过预训练和指令微调两阶段训练后得到的可直接用于对话推理的完整模型参数。其前一阶段的预训练权重 out/pretrain_768.pth 同样为 132MB,见证了这一基础模型从零开始的完整学习历程。在训练过程中,所有终端输出均通过 tee 命令实时保存为日志文件,从中我使用 sed 正则表达式精准提取了每一步的 Loss 值,生成了 pretrain_loss.csv 和 sft_loss.csv 两个结构化数据文件,并由 matplotlib 库直接通过命令行渲染为两张 PNG 格式的损失曲线图——pretrain_loss.png 清晰展示了模型从初始 Loss 7.52 快速下降至最终 1.65 的完整收敛轨迹,而 sft_loss.png 则记录了指令微调阶段 Loss 在 1.2 至 2.2 区间内剧烈震荡、逐步适应的学习过程。为了验证模型的真实对话能力,我执行了自动化测试脚本,将所有问答交互完整保存为 dialogue_test.txt,其中既包含了模型在知识问答和代码生成任务上的流畅表现,也忠实记录了诸如“下雨天出门建议”等暴露小模型上下文理解缺陷的典型跑题案例。在客观评测维度上,ceval_result.txt 详细记载了模型在 C-Eval 验证集 52 个学科上的表现,最终取得 22.88% 的综合准确率,其中艺术学(45.45%)和离散数学(37.50%)表现最好。此外,环境版本信息(env_versions.txt)、模型配置详情(model_config.txt)、数据集样本(data_sample_pretrain.txt 和 data_sample_sft.txt)等辅助文件也为报告的完整性和可复现性提供了坚实支撑。至此,从环境搭建、数据处理、模型训练、效果测试到客观评测的全部实验环节均已形成闭环,所有产出物整齐归档。
8.2 心得体会
成本与能效的极致:用一杯奶茶的预算和看一部电影的时间,就能从零训练出一个能完整对话、能写简单代码的 AI 模型。这极大地降低了 LLM 的研究门槛,也让开源精神和技术普惠的理念得到了生动体现。
阶段训练是核心:预训练阶段教给模型的是庞大的“世界知识”,而 SFT 阶段则是教会模型如何运用这些知识去“理解指令并回答问题”。两者的分工明确且必要。
小模型的边界:通过对话和评测,我清晰地感受到了小模型(<100M)的能力边界。它在知识陈述和简单生成上表现出色,但逻辑推理和多步思考是它的致命短板,这也是未来优化和引入 RLAIF 等增强学习的目标。
全流程复现的宝贵性:亲手运行 train_*.py 脚本并分析日志,远比仅仅阅读论文和教程让人印象深刻。理论与实践的结合,让我对大语言模型的内部运作有了更深层次的理解。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)