个人用如何本地化部署模型
本文的方法,适用于如果你只是想体检一下和自己的私有本地部署模型对话,图新鲜感,那么可以部署一套玩一玩,但如果是奔着日常使用,比如写代码,甚至是做一个聊天小助手等等这类需求,且没有自己的训练模型能力的话,就不要部署了,直接用官方的deepseek或者豆包就可以
不要听网上那些无脑吹本地部署的瞎说瞎吹,简单来讲网上那些本地化部署的各种资料在“异化”模型训练的重要性,举个通俗的例子来讲,模型就像养一个孩子,从它的胚胎时期选择架构开始,到未来投入使用,你要对它的培养是不能停的,你不给它资源让它成长,它就会定个在一个状态下,就和方仲永一样,当然这个成长对于使用者来讲,通常是丰富他的知识库,对于模型本身的厂家来讲,通常是底层优化算法和自然语言处理方式等偏架构
本质上,无论是个人在消费级硬件低成本的部署,还是在服务器上部署,使用的都是一个训练好的GGUF向量压缩模型包,通过LLM工具运行,但联网搜索本身不是模型自己的能力,而是智能体工具以嵌入式的方式提供的辅助能力,至于怎么搜?搜什么?怎么返回结果?这些是智能体工具以模型为大脑的综合能力体现
如果你仍然选择往下看本文的内容,要提前说明的是。本文以体验为目的,所以在给模型喂数据这一步用的是工具自带的功能,但它有一个命中率问题,正常企业级部署要给模型喂数据,通常的手段是要在较好的算力条件下,基于已有的 gguf模型,将需要喂的数据处理成对话json,然后跑出一个权重偏移文件,这个文件就相当于一个脑细胞,需要将它和原来的gguf模型,再次合并成一个新的gg uf模型,就成了最终的私人助手之类的这些各式各样的上层应用
本文采用,LM Studio + AnythingLLM + searXNG 在Windows系统中本地部署,安装包在官网下载即可,注意下载Windows版本的,别下成MacOS或者Linux的
LM Studio-》 https://lmstudio.ai/
AnythingLLM-》 https://docs.useanything.com/installation-desktop/overview
searXNG 通过 docker 安装,所以你需要一台Linux虚拟机
除了部署工具,你还需要在 https://www.modelscope.cn/home 这个模型站中下载一个你想用的模型,注意搜索时使用 xxxx-gguf ,且需要支持LLM的,说白了就是没有任何其他包装架构,你看到类似text、enx等等都不要下,用不了,也不要下载deepseek-r1,这个模型的模型包对于个人电脑来讲很大,下载小参数的还不如直接下载其他模型,比如我这里用的是qwen3-gguf,在你电脑内存的承受范围内就可以,下载后把它放到一个全英文,最少有二级路径的路径下,之所以最少二级,第一级会被工具识别为作者名称,第二级识别为模型名字,路径名可以自定义
首先安装LM Studio,安装完时候双击打开
第一次打开,会有一个信息收集的弹窗,点右上角的skip关掉就行,随后正式进入工具如下
点击上图右下角小齿轮,进入设置,改语言为中文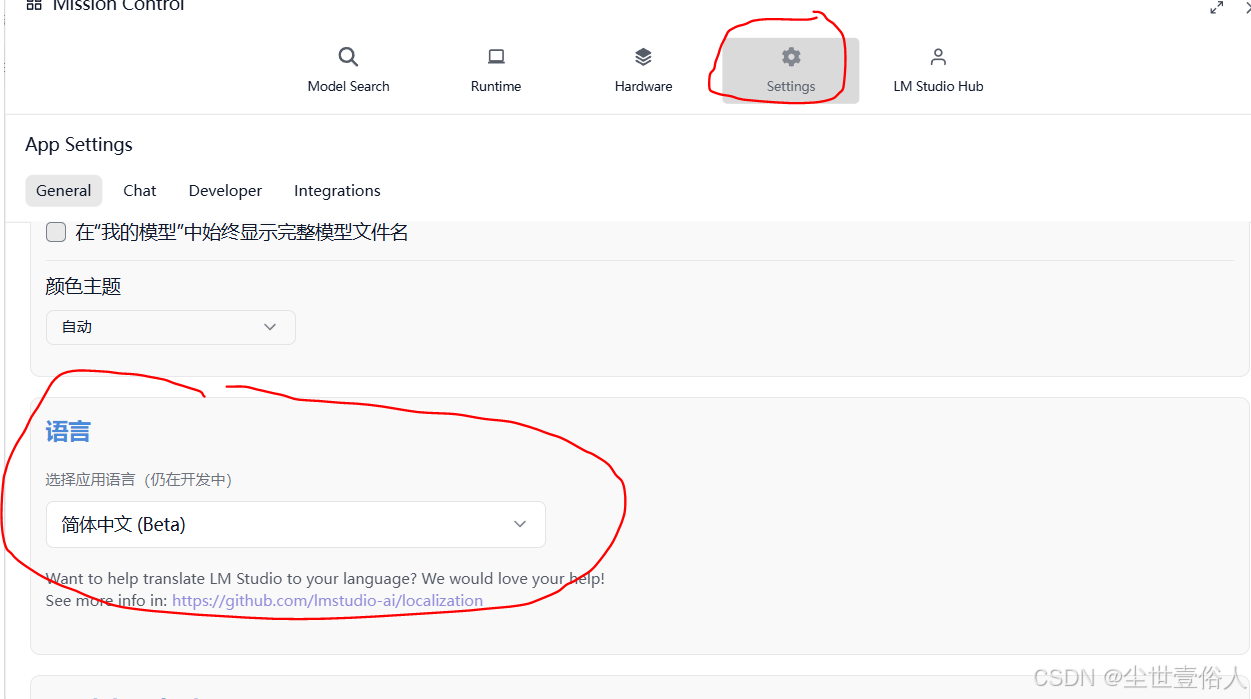
并且取消默认的自动更新环境
第首次执行软件,通常会自动下载两个东西,一个是嵌入式对话模型text-embedding-nomic-embed-text-v1.5,另一个是运行环境 llama.cpp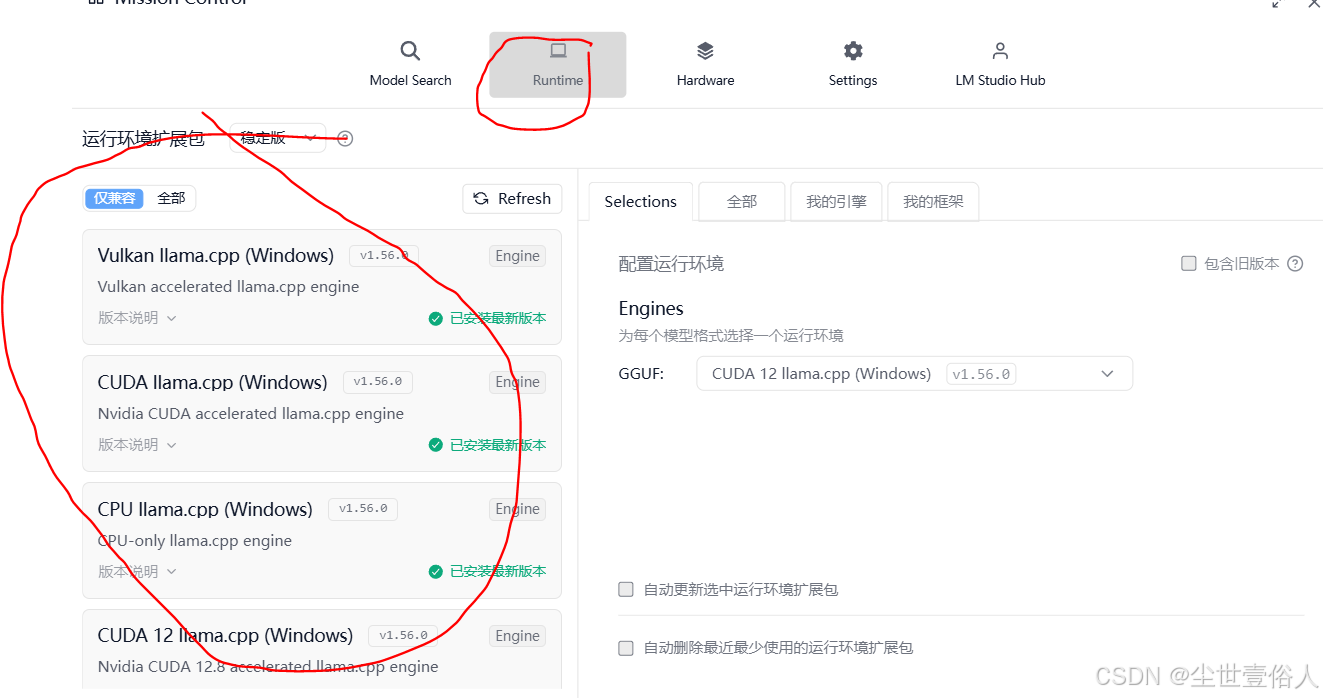
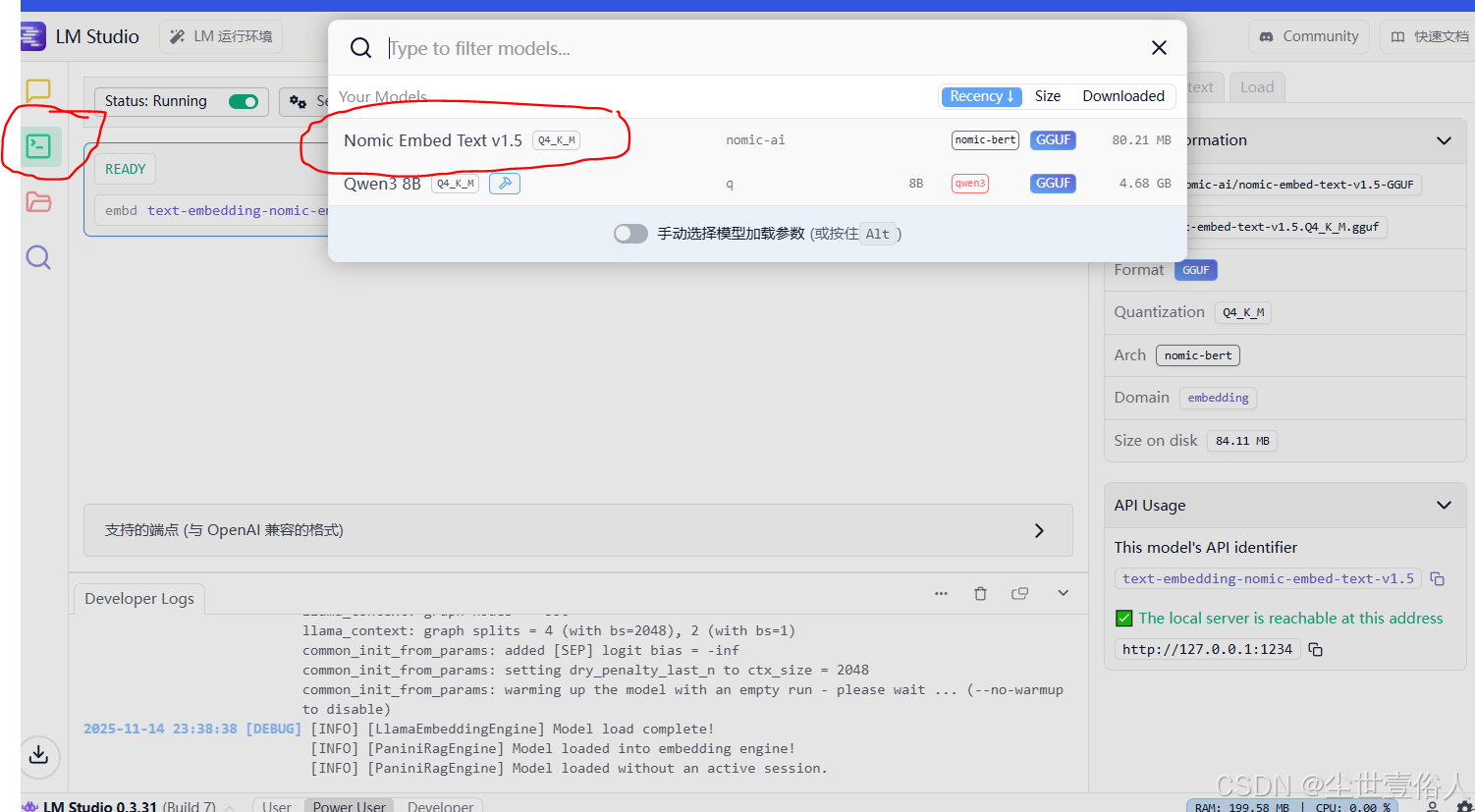
通常这两个东西在首次启动会自己安装,如果没有的话llama.cpp在设置中有下载按钮,嵌入模型在左侧那个放大镜里搜索,放大镜中可以直接搜索其他模型,但这里下载较慢,嵌入模型就80M左右无所谓,对话模型比较大,下载会很慢
上面的没问题后,点击文件夹图标,更改模型存放路径为你放模型的路径,注意选择到倒数第二级就行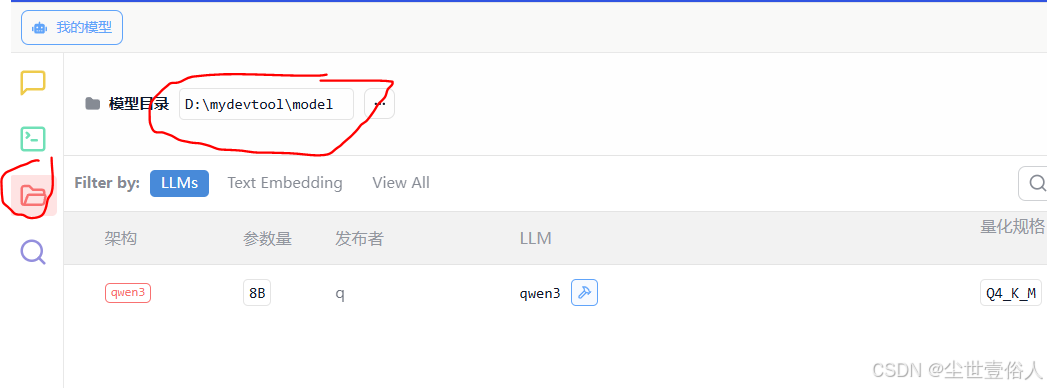
随后看一下,模型加载资源,除了GPU资源其他的默认,GPU中文翻译有问题,并不是要卸载,尽量不要拉满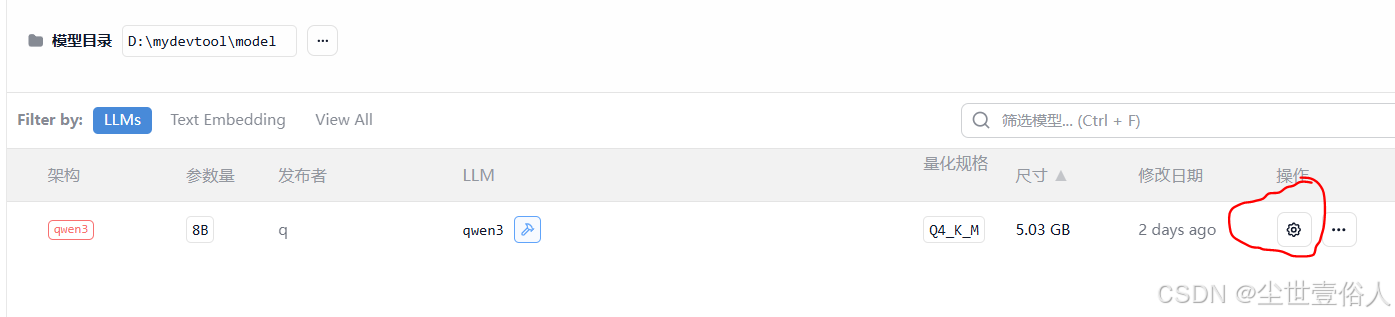
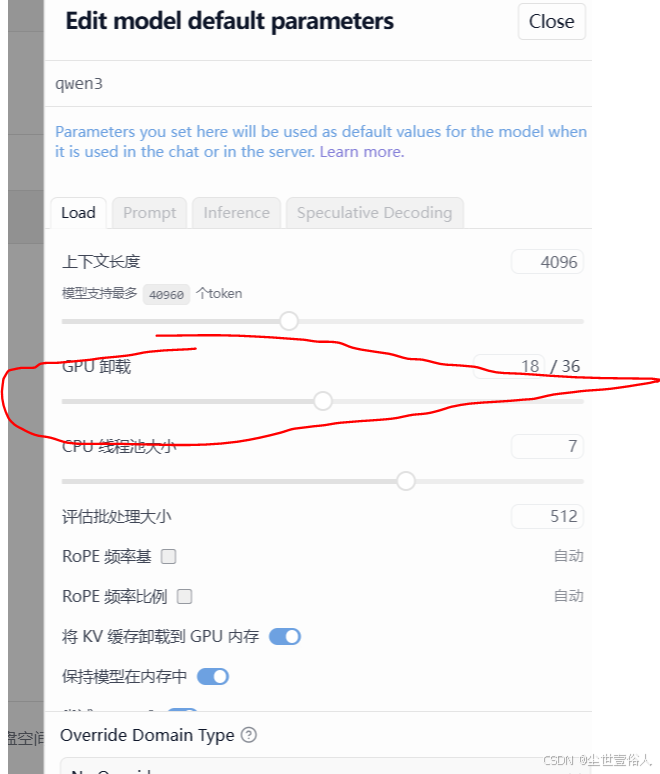
现在你就可以吊起模型对话了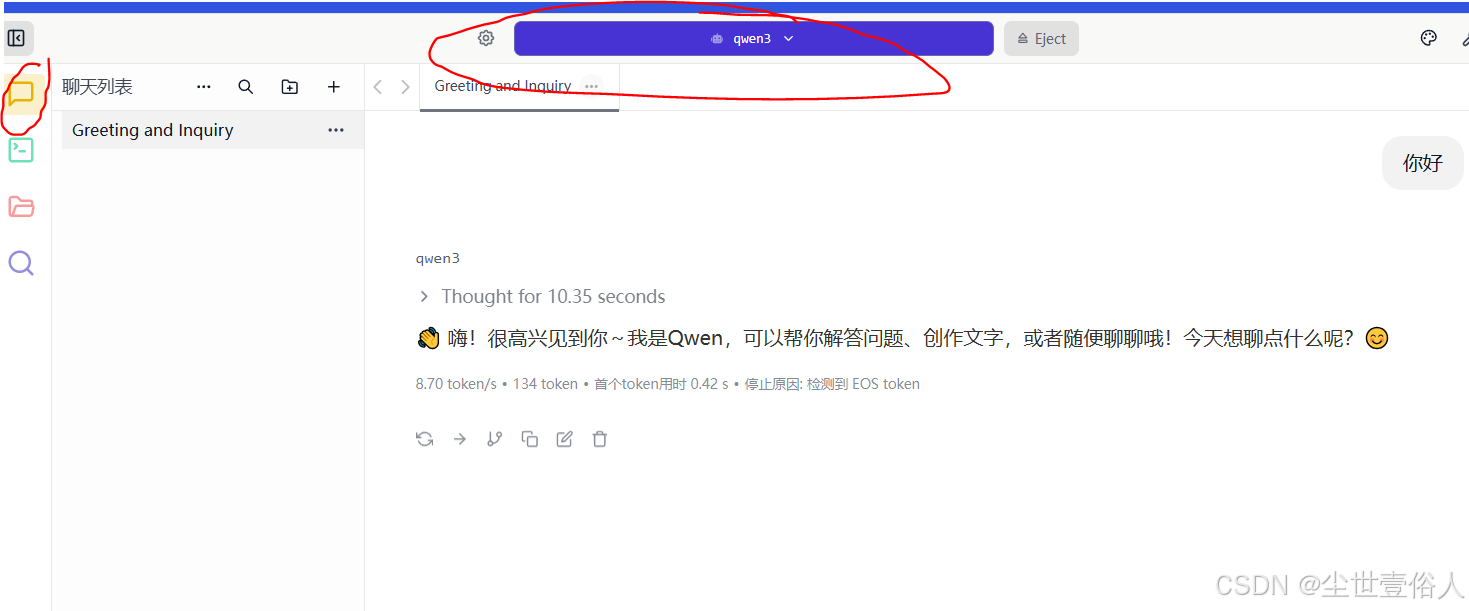
现在开始部署联网搜索需要的插件,后面工具会通过标准的OpenAi格式接口去访问联网搜索插件。docker的安装见https://blog.csdn.net/dudadudadd/article/details/128176347,docker安装SearXNG需要一些前置配置,首先改docker的配置文件
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"experimental": false,
"features": {
"buildkit": true
},
"registry-mirrors": [
"https://docker.1panel.dev",
"https://docker.fxxk.dedyn.io",
"https://docker.xn--6oq72ry9d5zx.cn",
"https://docker.m.daocloud.io",
"https://a.ussh.net",
"https://docker.zhai.cm"
]
}
重启docker后,拉取官方的镜像,并启动一个searxng容器
docker pull searxng/searxng
docker run --rm -d -p 8080:8080 -v "/opt/searxng:/etc/searxng" -e "BASE_URL=http://localhost:8080/" -e "INSTANCE_NAME=searxng" searxng/searxng
启动容器后,在宿主机的/opt/searxng会生成对应的本地卷里面是searxng配置文件
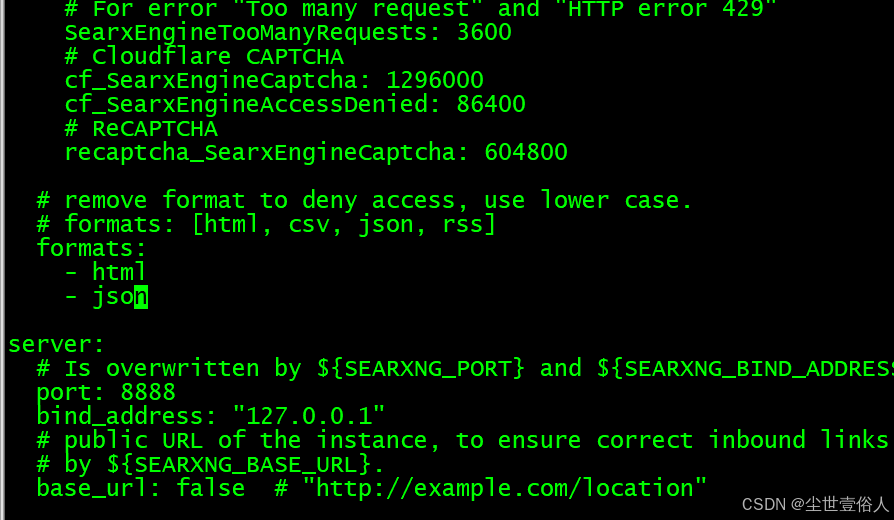
在 search.formats 部分(大约在第 30 行),添加 - json 配置项
改完配置重启这个docker容器 docker restart <container-id>
随后在Windows浏览器中访问docker宿主机的8080端口
在首选项中更改语言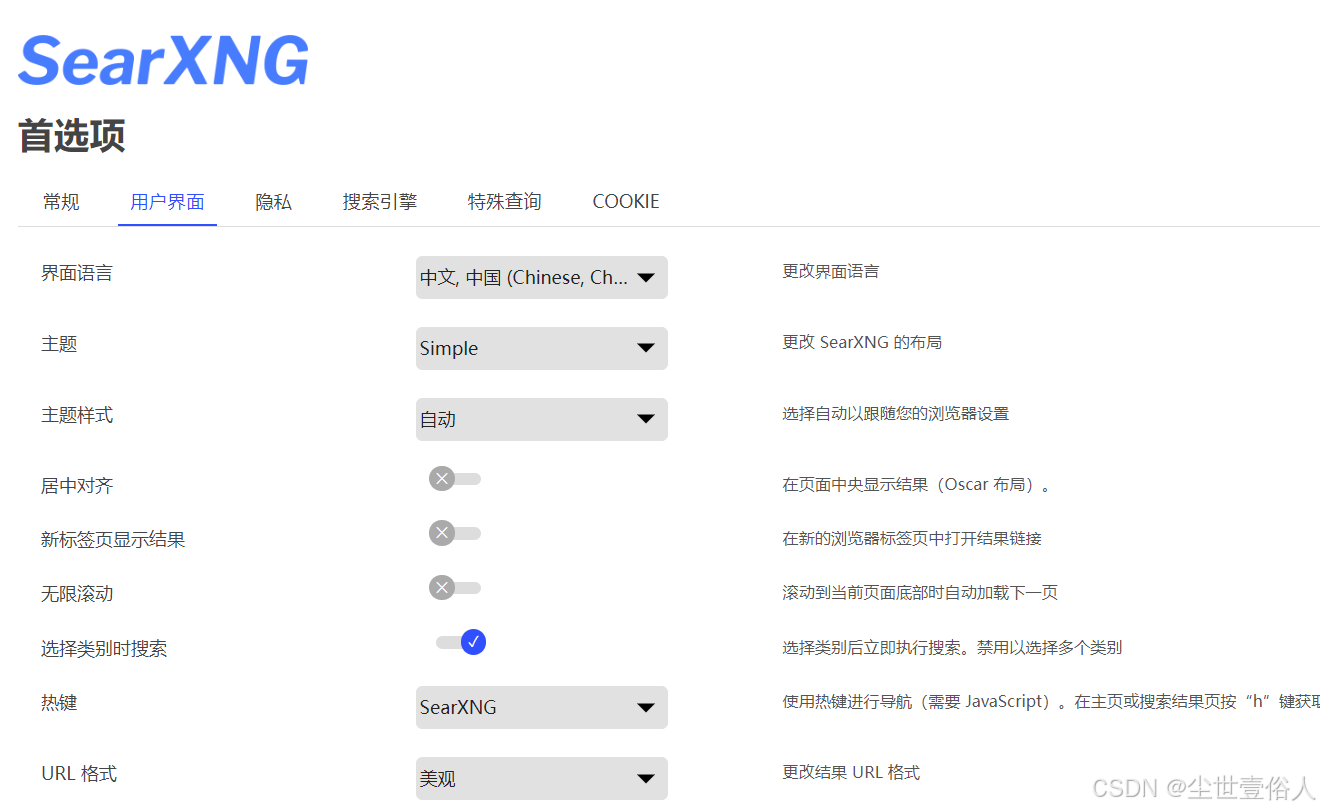
在搜索引擎中除了 bing 和 baidu 其他的全关掉!!!一定要全关掉,不然会导致搜索错误
最后,不要忘记点左下角的保存,保存后搜索一下不报错,并且使用接口访问能返回json数据即可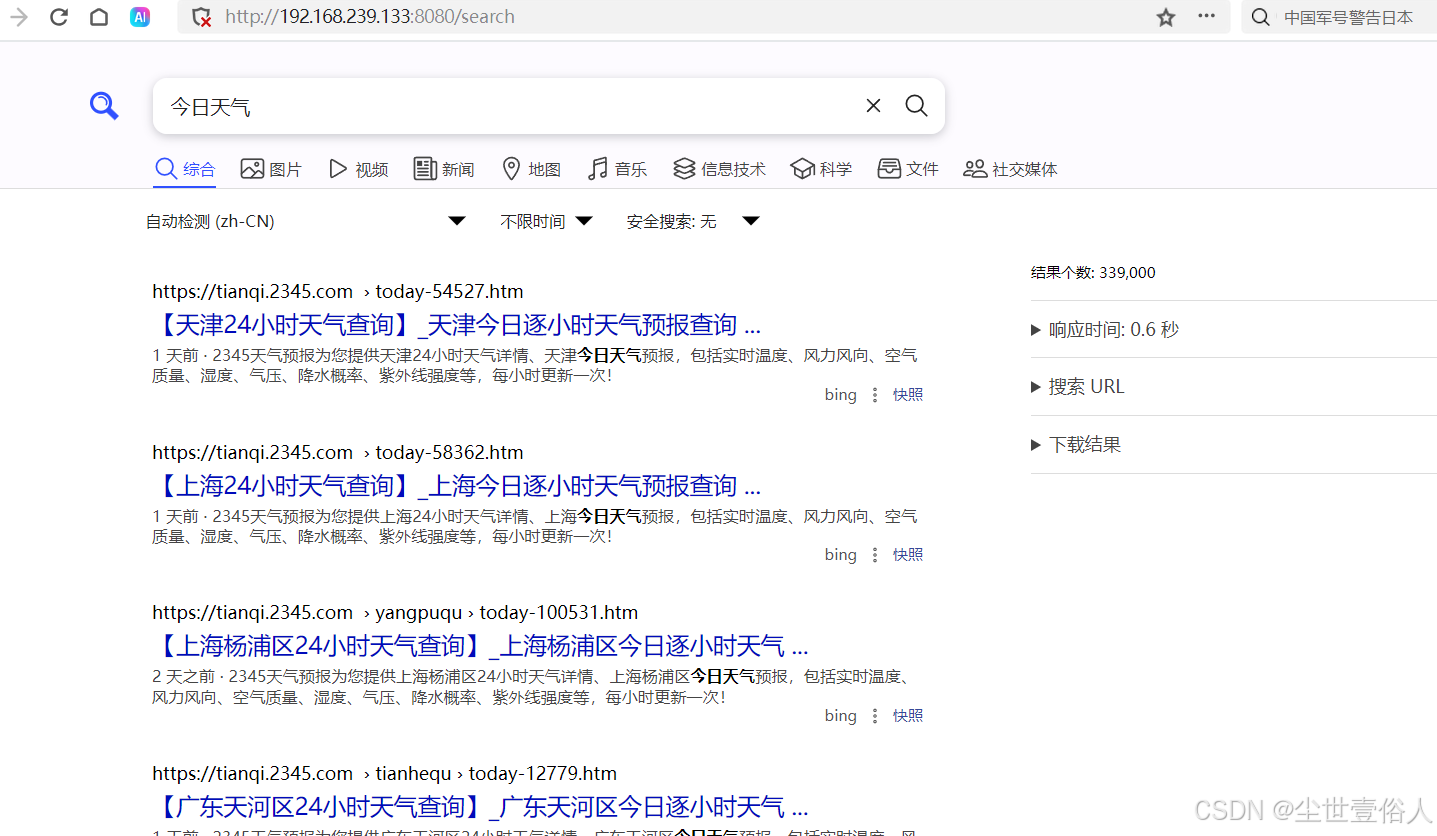
调用接口 http://192.168.239.133:8080/search?q=llm&format=json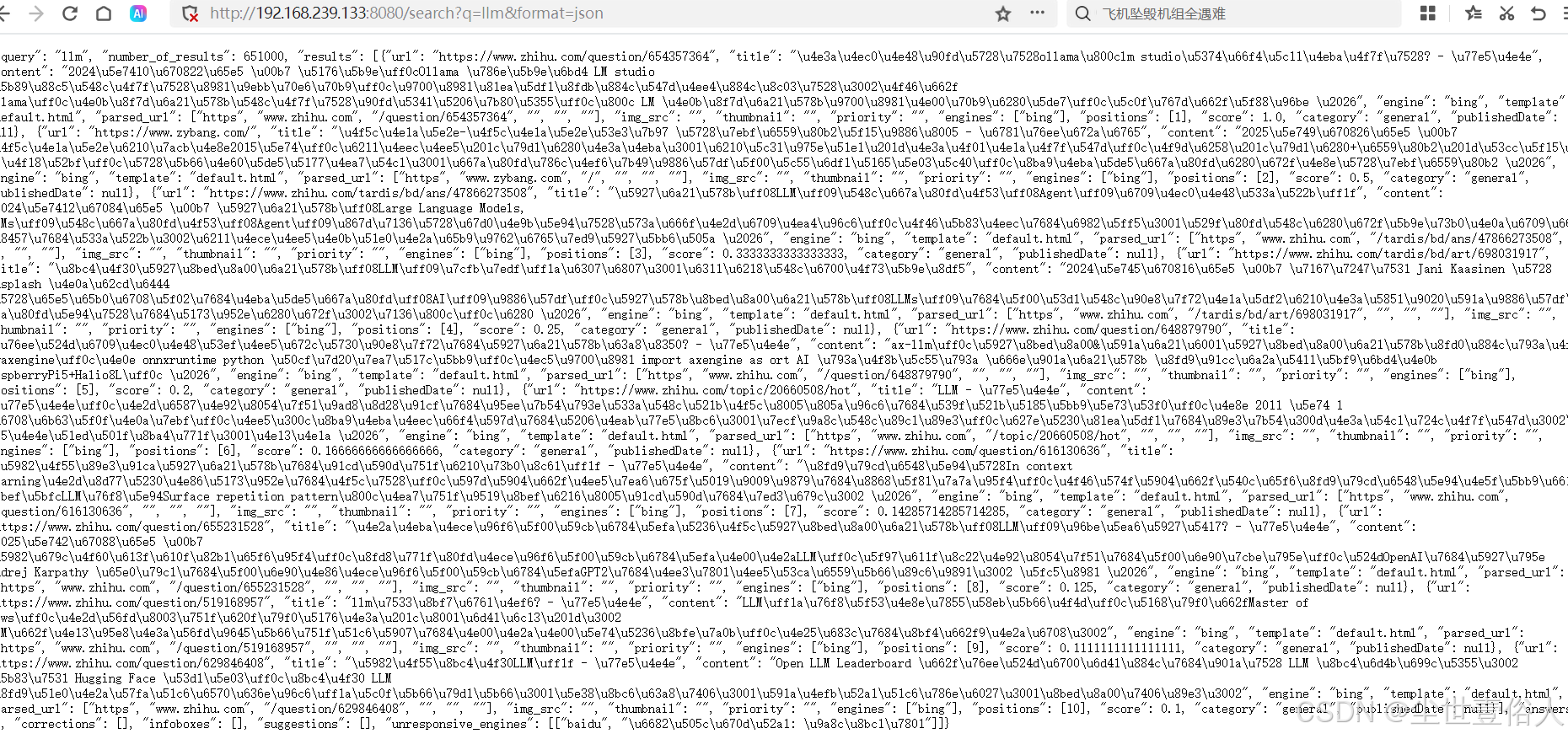
现在回到 LM Studio 中,在开发者界面加载你的对话模型和嵌入式模型,并启动API接口服务即可, LM Studio 就可以先最小化了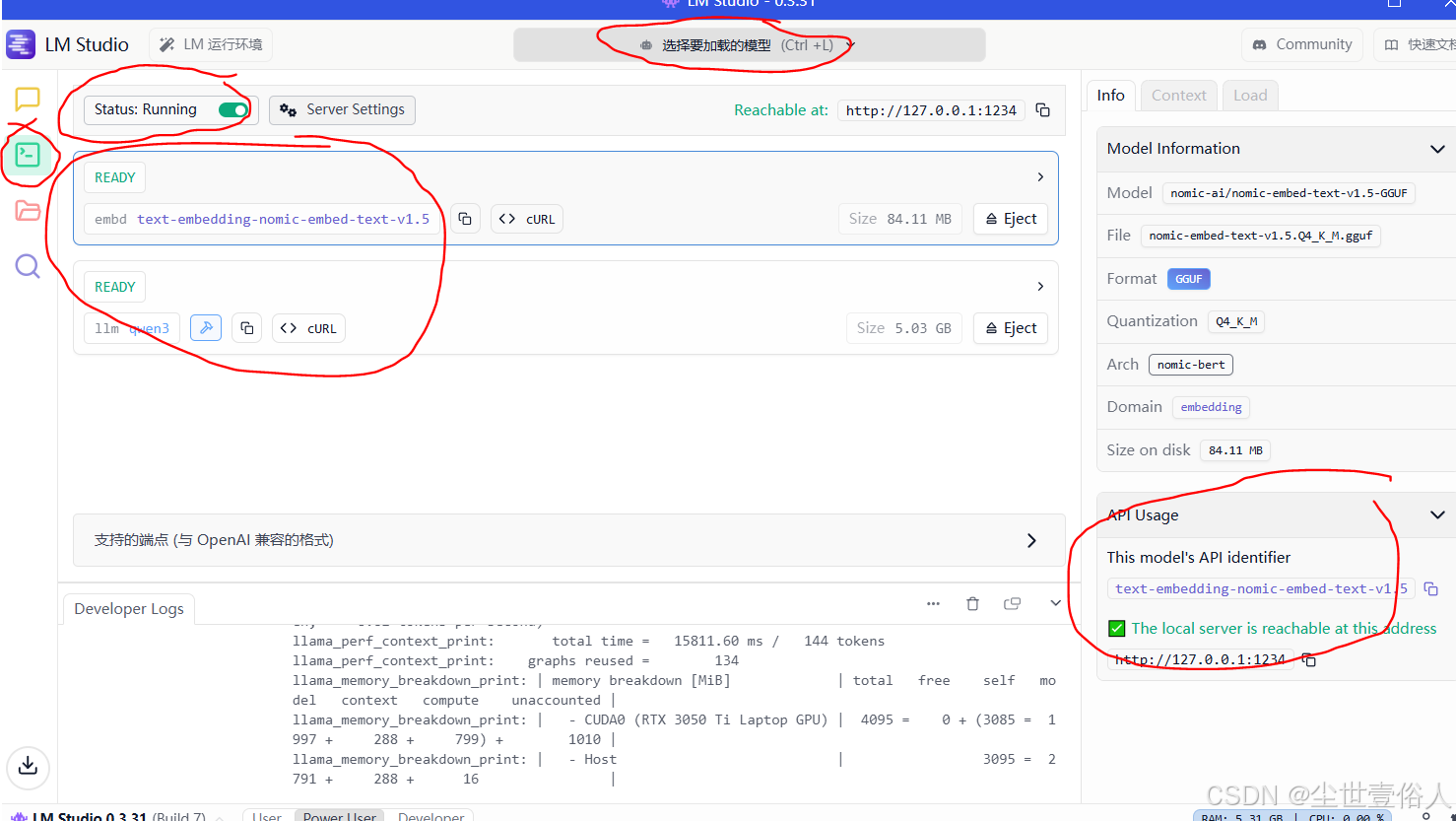
现在可以安装 Anything LLM ,按照好后创建工作区,并设置嵌入器、模型服务接口为LM Studio的、以及网络搜索插件
Anything LLM 第一次启动,也会收集一些信息,不用写一路点击向右箭头,直到输入工作区名称后即可
点击设置,选择LLM为LM Studio,下面的模型在你输入接口后才会加载并选择你自己的对话模型,接口的ip见LM Studio开发者界面,默认是端口1234,接口路径 /v1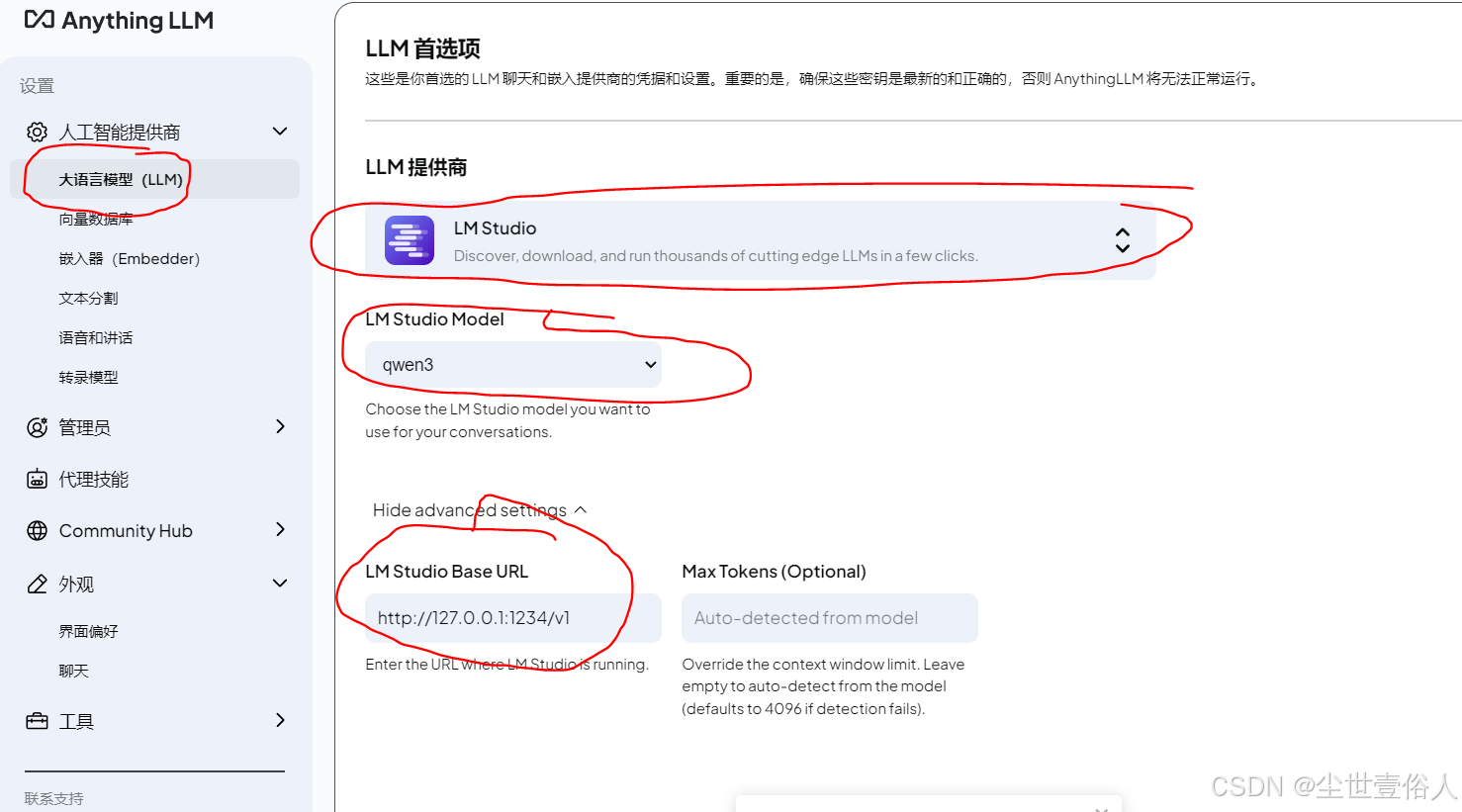
之后嵌入器也是一样的套路,不过模型选择的是上面说到的嵌入模型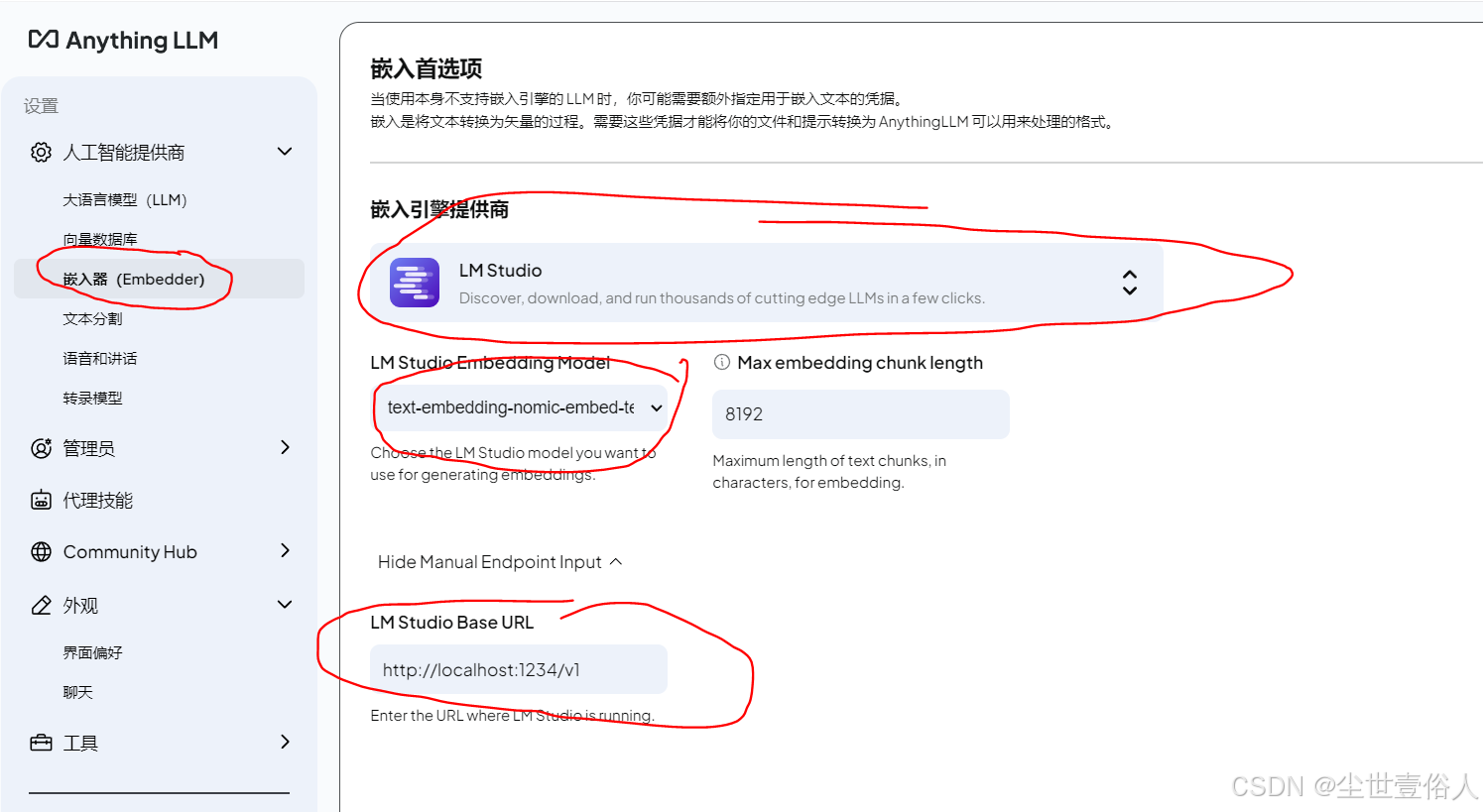
之后是网络搜索的插件
最后你就可以在 Anything LLM 中,将你想要的嵌入式文件内容挂载在工作区,和模型对话时会参考,挂载如果在左侧鼠标放在工作区上面有个上传按钮
后面的对话就在 Anything LLM 中进行,默认是不联网,只使用模型自身的原始数据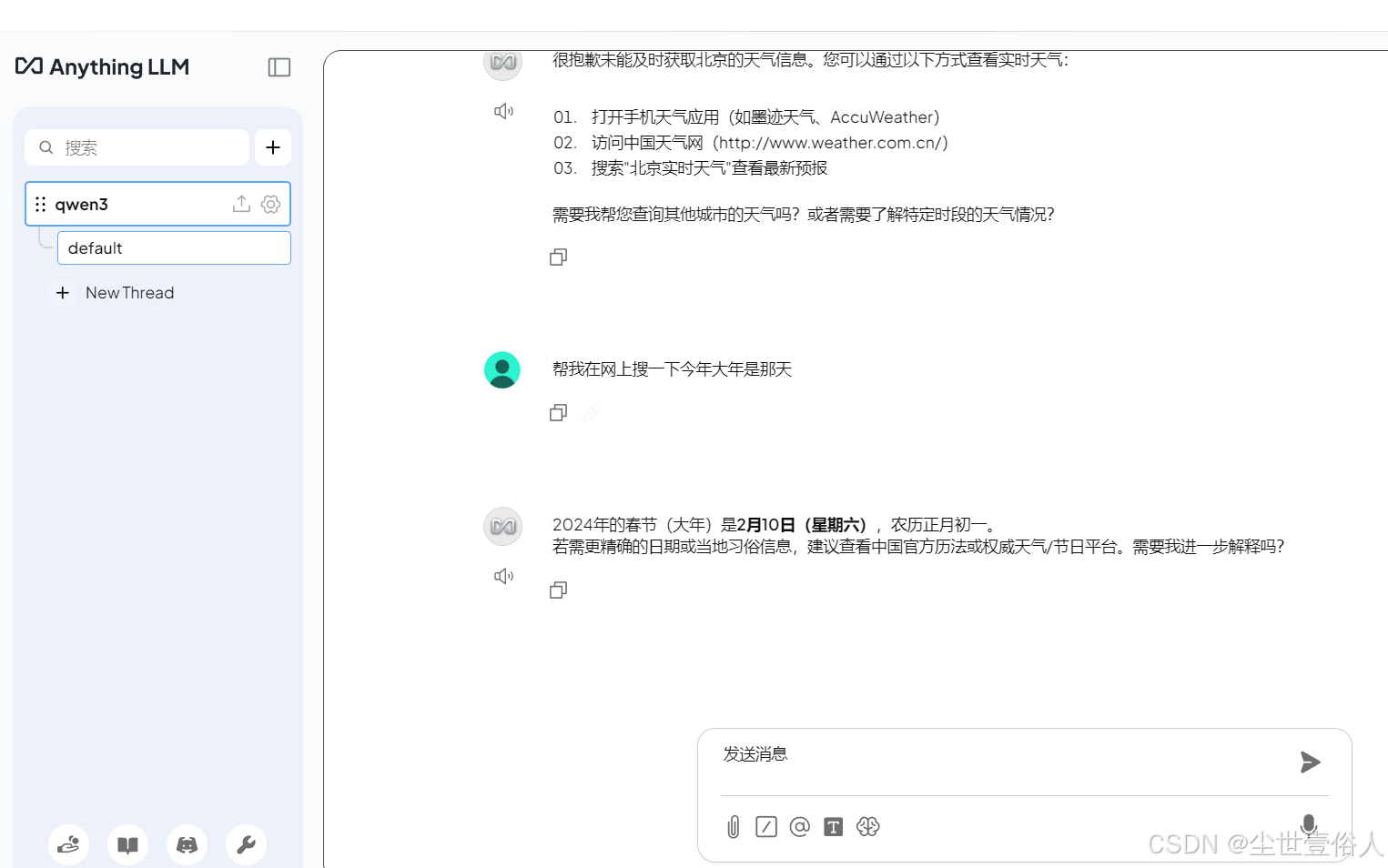
需要联网搜索,需要输入一次 @Agent 后面是你的内容,输入一次后,后面发送话语就不用了
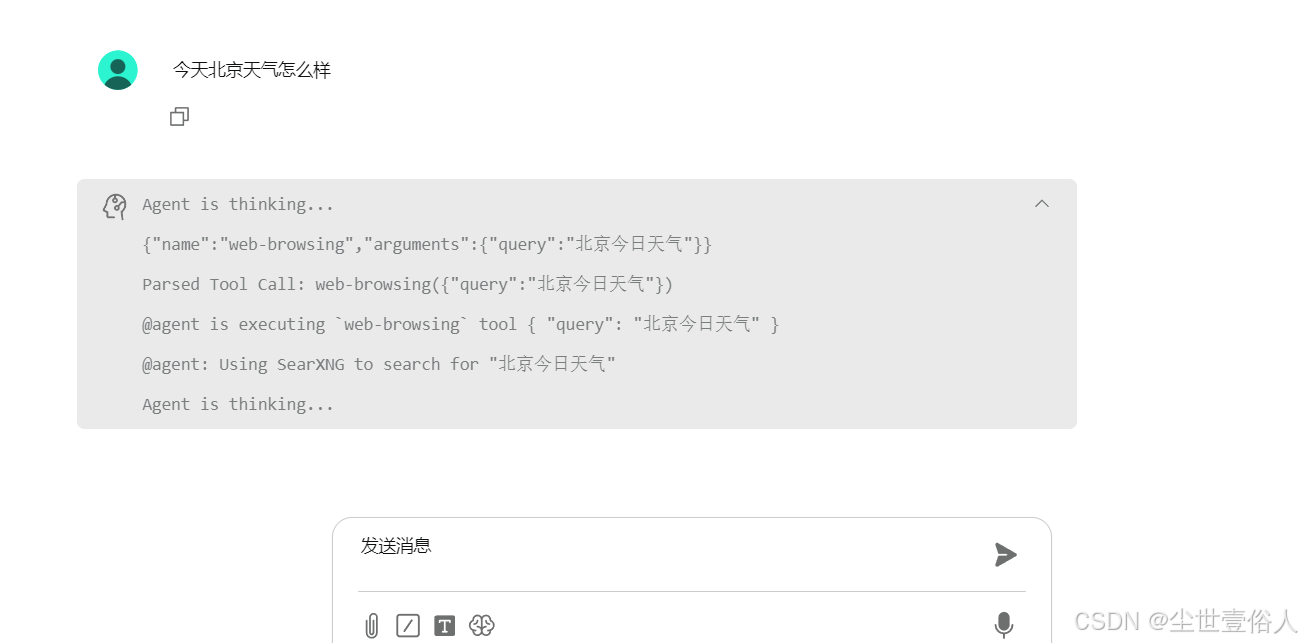
如果你想,你也可以自己开发一个对话页面,这也是其他公司自己搞AI产品的常见手段,我这里给大家提供一个核心功能代码,样式和多会话控制就需要你自己去实现了
<!DOCTYPE html>
<html>
<head>
<script src="https://code.jquery.com/jquery-3.6.0.min.js"></script>
</head>
<body>
<div id="chat" style="max-width: 600px; margin: 0 auto;">
<div id="messages" style="height: 400px; border: 1px solid #ccc; overflow-y: auto; padding: 10px;"></div>
<input type="text" id="userInput" style="width: 70%; padding: 10px;" placeholder="输入消息...">
<button onclick="sendMessage()" style="padding: 10px;">发送</button>
<button onclick="stopMessage()" style="padding: 10px;">停止</button>
<div id="loading" style="display: none;max-width: 600px;height: 100px;overflow-y: auto;">AI正在思考...</div>
</div>
<script>
//历史对话数组
let conversationHistory = [];
//展示对话消息的框子
let megs = $('#messages') ;
//存储当前AI返回的流式答复
let buffer = [] ;
// buffer的下表
let index = 0 ;
//发送消息文本框的jqeury对象
let input = $('#userInput');
//AI思考的盒子
let ai_think = $('#loading');
//AI正式回答内容的盒子
let aiMessage = null;
//发送请求的xhr对象
let xhr = null;
//准备一个扫尾方法,下面复用,flag用来表示是否要把当前的会话加入历史内容数组中,如果是手动中断就不用
function xhrStop (flag) {
if (flag){
conversationHistory.push({ role: "assistant", content: buffer.join('') })
}else{
aiMessage.append('回话停止!')
}
buffer = [] ;
index = 0 ;
aiMessage = null;
xhr = null;
scrollToBottom();
};
function sendMessage() {
//如果存在一个正在触发的请求则什么都不发生
if (xhr != null) return;
//获取消息
let message = input.val().trim();
if (!message) return;
//恢复空值,并显示AI思考中
input.val('');
ai_think.show();
// 用户的消息推到信息框中,并放在历史对话数组中,user是OpenAI接口标准中的用户标签
megs.append('<div style="text-align: right; margin: 10px 0;white-space: pre-wrap;"><strong>你:</strong> ' +message + '</div>');
conversationHistory.push({ role: "user", content: message });
// 创建AI消息框子
let aiMessageId = 'ai_msg_' + Date.now();
megs.append('<div id="' + aiMessageId + '" style="margin: 10px 0;white-space: pre-wrap;"><strong>AI:</strong> </div>');
aiMessage = $('#'+aiMessageId);
/* 使用XMLHttpRequest进行流式请求(更好的兼容性)
不直接用ajax的原因是所有请求本身都是以流的形式运作,其他开发场景我们不会去关注流的发送和接收过程
因为日常开发流只在发送或者响应时触发一次,而且是个完整的Json体
但,AI接口的流式响应,它是一个陆续返回多次的流响应,如果你非要用ajax并把响应写在success里
会发现一个很有意思的点,就是无法做到流式接收,这是因为success是在所有流接收完成时触发一次
而作为被ajax封装的XMLHttpRequest,它的onprogress是每接收一次流响应的数据就触发一次
ajax倒是也能自定义xhr,但开发复杂度非常不友好
*/
xhr = new XMLHttpRequest();
xhr.open('POST', 'http://192.168.150.1:1234/v1/chat/completions');
//发送json格式数据,同时希望接收的返回也是json
xhr.setRequestHeader('Content-Type', 'application/json');
xhr.setRequestHeader('Accept', 'application/json');
/*
处理响应流返回的数据,接口会在一次请求的响应流中,已多个数据块的形式返回AI思考的过程以及最终的回答
此时数据块的切分通俗理解就是日常说话的断句,AI已经给你处理好了
但要注意一个问题,流返回的内容会拼接到xhr.responseText后面 \n 分割
而不是复写xhr.responseText,因此需要一个responseTextLastLen步长辅助解析结果
*/
let responseTextLastLen = 0
xhr.onprogress = function(event) {
//只获取本次新增的数据,并记录步长
let data = xhr.responseText.slice(responseTextLastLen).trim().split('\n')
responseTextLastLen = xhr.responseText.length
data.forEach(line => {
//去掉前6个字符也就是“data: ”部分,并把字符串转换为json对象,从而拿出语言内容
if (line.startsWith('data: ') && line !== 'data: [DONE]'){
let choices = JSON.parse(line.slice(6)).choices
choices.forEach(choice => {
//语言内容又分为三种情况
let delta = choice.delta
//思考内容
if ( 'reasoning_content' in delta ){
ai_think.append(delta.reasoning_content)
}
//答复内容
if ( 'content' in delta ){
//思考内容的盒子恢复初始化状态
ai_think.html('AI正在思考...')
ai_think.hide();
aiMessage.append(delta.content)
buffer[index] = delta.content
index += 1
}
//第三种情况是data: [DONE]前的最后一行里面的内容通常是空的所以不做处理
scrollToBottom();
})
}
})
};
//一次请求完全结束后,扫尾工作
xhr.onload = function(){
xhrStop(true);
}
xhr.onerror = function() {
console.log('XHR请求出现错误')
};
//触发请求发送
xhr.send(JSON.stringify({
model: "qwen3",//用接口服务中的那个模型
messages: conversationHistory,//历史会话数组
stream: true,//流式响应
temperature: 0.7 //恢复的创造性因子,取值通常是0-1,值越大,恢复的多变情感越深
}));
scrollToBottom();
}
//中断本次回复
function stopMessage(){
if(xhr != null && xhr.readyState !== XMLHttpRequest.DONE) {
xhr.abort()
xhrStop(false)
xhr = null
}
}
//这个方法将相关信息框的滚动条设置到最下方
var top_megs = 0
var top_ai_think = 0
function scrollToBottom() {
if ( megs[0].scrollHeight != top_megs ){
megs[0].scrollTop = megs[0].scrollHeight | 0
top_megs = megs[0].scrollHeight
}
if ( ai_think[0].scrollHeight != top_ai_think ){
ai_think[0].scrollTop = ai_think[0].scrollHeight | 0
top_ai_think = ai_think[0].scrollHeight
}
}
// 在文本框中触发回车发送
$('#userInput').keypress(function(e) {
if (e.which == 13) sendMessage();
});
</script>
</body>
</html>
当然如果你要自己写页面,你要注意的是如果涉及文件,lm studio提供的AI对话接口本身是不支持文件上传的,如果你实在想自己玩一玩,只能是自己把文件内容读取出来,成为发给AI话语中的一部分,总之很麻烦!很麻烦!
至于你在使用其他的官方对话模型,比如豆包、deepseek、或者是gpt,它们的上传,是完整的模型环境下,有专门存储文件的架构以及接口,并且每个文件都有文件id,可以让你和模型对话时调用
上面这个代码调用的是LM Studio的,如果你使用AnythingLLM的,它也提供了兼容OpenAi接口的接口,但是通常不调用,因为它也是去调用模型提供服务的,除非你要用它的智能体(Agent),和LM Studio不一样的是,需要在开发者API中设置一个Key,随后改一下接口地址就好了,请求时把Key放在header中的Authorization里面就行
不过话说回来,其实后面自己写接口调用页面这部分内容,只是给大家做一个扩展,让大家知道什么叫流式响应,和常规的批响应区别在哪里,以及对和模型对话有一个基本概念,让大家对底层运转有一个基本的认识,而不是局限于常用到的官方可视化交互界面上看到的肉眼直观的那些东西。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 25
25 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)