大语言模型让数据平台插上“自然语言”翅膀,人人都是数据分析师!
大语言模型(LLM)正在推动数据平台经历一场静默革命,为其装上自然语言接口。从数据摄取到分析的10层技术栈中,LLM在多个层面带来颠覆性变化:自动化生成连接器、文本转SQL、聊天式BI分析、语义层简化等,极大提升效率。数据团队角色从“写SQL”转向“设计系统”,数据使用门槛大幅降低。LLM作为助手增强数据治理、安全、可观测性等层,但不取代基础设施层。最终实现人人可用自然语言轻松获取数据洞察,数据团队需转向构建让任何人都能回答问题的基础。
当AI开始理解数据,数据平台正在经历一场静默的革命,大语言模型正在给数据平台装上自然语言接口,曾经需要专业分析才能触碰的数据洞察,如今用自然语言就能轻松获取。
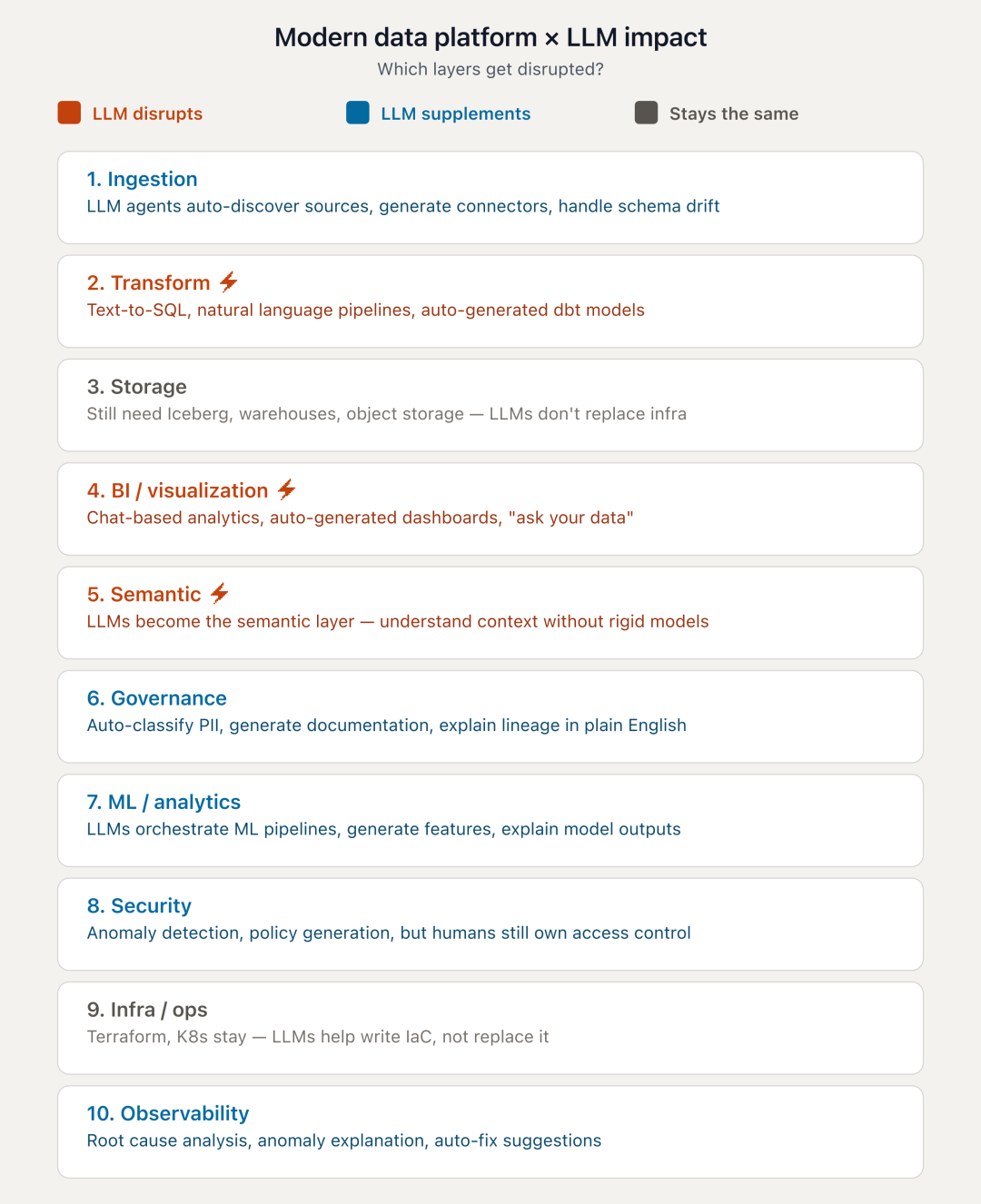
图:LLM对现代数据平台10层技术栈的影响程度
📌 核心要点
颠覆性变化(3层):自然语言部分替代手动转换;BI/可视化层被聊天分析取代;语义层因AI原生理解上下文而变得简化
AI增强(5层):数据摄取、治理、ML/分析、安全、可观测性——AI作为助手提升效率
不受影响(2层):存储层、基础设施/运维层保持不变——它们仍是基础
AI智能体横跨各层:不取代基础设施,而是作为控制中枢,协调各类工具和API完成任务
🧩 数据平台的「十层楼」
现代数据平台从原始数据到业务洞察的完整路径,包含10个层级:
数据摄取(Ingestion)— 数据导入(Kafka, Fivetran, Airbyte)
数据转换(Transform)— 清洗建模(dbt, Spark, Airflow)
存储(Storage)— 持久化(Snowflake, BigQuery, Iceberg)
BI/可视化— 数据展示(Tableau, Looker, Power BI)
语义层(Semantic Layer)— 指标定义(dbt metrics, Cube)
数据治理(Governance)— 权限文档(Unity Catalog, DataHub)
ML/分析— 建模分析(MLflow, PyTorch)
安全(Security)— 数据保护(masking, encryption, access control)
基础设施/运维— 运营支撑(Terraform, Kubernetes)
可观测性(Observability)— 监控(Great Expectations, Monte Carlo)
🔥 关键变化:逐层解析
第1层:数据摄取 — AI辅助生成连接器
大语言模型可以在几分钟内起草CDC配置和Airbyte连接器
模式漂移(Schema Drift)自动检测和映射更新
简单数据源:自建可能比托管服务更划算
过去:构建连接器需要数周
现在:LLM在几小时内起草配置
第2层:数据转换 — 最大的效率提升
Text-to-SQL(文本转SQL):80%的临时查询可正确生成
自然语言描述需求 → 自动生成dbt模型
数据工程师角色:从「写SQL」转向「设计系统+审查AI智能体生成的代码」
第3层:存储 — 不变的基础
Iceberg已成为开放表格式的事实标准
大语言模型是查询层,不取代存储层
元数据越好,AI分析越准确
发展方向:列描述、认证指标、数据血缘(Data Lineage)、PII分类
第4层:BI/可视化 — 「仪表板时代」终结
聊天分析直接回答问题,无需构建仪表板(Dashboard)
Snowflake Cortex / Databricks Genie 达到95%准确率
当仪表板变成代码,大语言模型可以生成整个报表层
第5层:语义层 — 被严重低估的变革
过去:花数周定义什么是「收入」——处理边缘情况、货币转换、财政日历
现在:大语言模型原生理解上下文,按需推断定义
复杂语义层(Semantic Layer)模型维护负担大幅下降
关键指标仍需要治理,但80%的临时问题可以不需要预定义模型
第6层:数据治理 — AI驱动,人类控制
自动PII检测(12+类型)
自动生成列描述和文档
自然语言血缘查询:「这个收入数字从哪来?」
数据管理员角色:从「手动标记10,000个列」转变为「审查和批准AI生成的分类」
第7层:ML/分析 — 副驾驶,不是替代品
特征工程(Feature Engineering):描述预测问题,从特征存储获取候选特征
管道编排:自然语言指令编译为Airflow DAG
模型解释:「为什么模型拒绝了这笔贷款?」用自然语言回答,而不是SHAP值
MLOps仍然需要,PyTorch不会消失
第8层:安全 — 更智能的检测,人类控制
异常检测:发现异常访问模式,标记可疑查询
策略生成:自然语言需求 → 访问策略
人类掌控密钥 — "AI给了我访问权限"不是可接受的审计跟踪
第9层:基础设施/运维 — 更好的工具,相同的基础
大语言模型帮助编写基础设施即代码(IaC)
优秀的配对程序员,但Kubernetes不会消失
CI/CD、监控、成本管理仍然需要
第10层:可观测性 — 用自然语言分析根因
根因分析:「为什么管道在凌晨3点失败了?」
异常解释:「数据量下降40%——可能是由于上游源中断」
自动修复建议:「模式已更改——这是迁移脚本」
趋势:可观测性正在扩展到AI输出
📊 总结:变与不变
| 层级 | 影响程度 | 说明 |
|---|---|---|
| 数据摄取 | 补充 | AI辅助生成连接器 |
| 数据转换 | 颠覆(部分替代) | Text-to-SQL大幅提升效率 |
| 存储 | 无变化 | 仍是基础层 |
| BI/可视化 | 颠覆 | 聊天分析崛起 |
| 语义层 | 颠覆 | AI原生理解上下文 |
| 数据治理 | 补充 | 自动分类、生成文档 |
| ML/分析 | 补充 | AI辅助特征工程 |
| 安全 | 补充 | 异常检测 |
| 基础设施/运维 | 无变化 | 工具变,基础不变 |
| 可观测性 | 补充 | 自然语言根因分析 |
3层被颠覆,5层被补充,2层无变化
💡 核心观点
最大的转变不是技术性的,而是:谁能使用数据。
自然语言将门槛降至零
数据团队从「回答问题」转变为「构建让任何人回答问题的基础」
AI将实现自主工具调用并执行轻量级工作流,以完成具体任务
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献138条内容
已为社区贡献138条内容

所有评论(0)