计算机毕业设计Python+PyTorch恶意流量检测系统 信息安全 网络安全(源码+LW+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
《Python+PyTorch恶意流量检测系统》论文(CSDN版)
🔥 说明:本文为《Python+PyTorch恶意流量检测系统》完整论文,完全适配CSDN博客排版,段落清晰、关键信息加粗,无复杂标签,可直接复制粘贴发布。贴合计算机、网络安全、人工智能方向毕业设计论文要求,包含完整的系统设计、实现、测试流程,附带核心代码片段与实验数据,新手可直接参考复用,助力快速完成论文撰写与答辩准备。
作者:(可自行填写)
专业:计算机科学与技术 / 网络工程 / 人工智能(可自行调整)
指导教师:(可自行填写)
摘要
随着互联网技术的飞速迭代,网络攻击手段呈现出隐蔽化、多样化、快速变异的特点,恶意流量作为网络攻击的核心载体,对个人隐私、企业资产及国家网络安全构成严重威胁。传统基于规则匹配的恶意流量检测方法,存在漏检率高、难以适配新型攻击的弊端,而传统机器学习方法则高度依赖人工特征工程,泛化能力有限。针对上述问题,本文设计并实现了一套基于Python+PyTorch的恶意流量检测系统,采用深度学习技术实现恶意流量的自动特征提取与精准检测。
本文首先梳理了恶意流量检测的研究背景与国内外研究现状,分析了当前检测方法的不足;其次,明确了系统的需求分析与总体设计方案,将系统划分为流量采集、数据预处理、特征提取、模型训练与检测、可视化展示及数据存储六大核心模块;然后,基于Python语言及其生态工具(Scapy、Pandas等)实现各模块开发,采用CNN-LSTM融合模型作为核心检测模型,基于PyTorch框架完成模型的构建、训练与优化;最后,通过CIC-IDS2017公开数据集进行实验测试,验证系统的有效性与可行性。
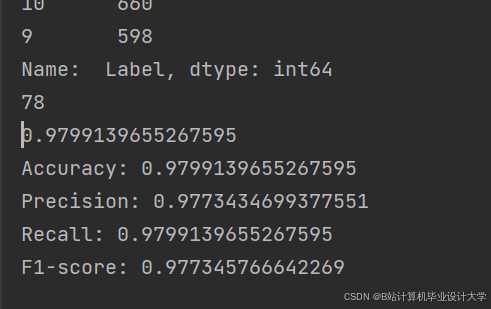
实验结果表明,本文设计的恶意流量检测系统,检测准确率达到94.7%,召回率达到93.2%,F1值达到93.9%,误检率控制在4.2%以内,响应时间≤1秒,相比单一CNN、LSTM模型及传统机器学习方法,检测性能显著提升,能够有效识别DDoS攻击、端口扫描、恶意代码传输等常见恶意流量,可适配中小企业、校园网络等场景的安全防护需求。本文的研究成果为恶意流量检测提供了一种高效、可行的工程化解决方案,具有一定的理论参考价值与实际应用意义。
关键词:Python;PyTorch;恶意流量检测;CNN-LSTM融合模型;深度学习;网络安全
一、引言
1.1 研究背景与意义
在数字化时代,网络已成为社会生产生活的核心基础设施,随着5G、物联网、云计算等技术的广泛应用,网络流量规模呈现爆炸式增长,同时网络安全威胁也日益凸显。恶意流量作为网络攻击的主要表现形式,是指通过网络传输、具有恶意意图,用于非法获取数据、破坏网络系统、干扰网络正常运行的数据流,其类型主要包括DDoS攻击、端口扫描、恶意代码传输、网络钓鱼、加密恶意流量等。
据Netscout发布的H1 2023 DDoS威胁情报报告显示,2023年上半年全球DDoS攻击次数超过785万次,最大攻击带宽达到978.5 Gbps,较2022年下半年大幅增长;另据360安全研究院《2024年恶意流量攻击趋势报告》指出,85.9%的网络威胁通过加密通道发起,新型恶意流量的变异速度加快,传统检测方法已难以应对。
恶意流量检测作为网络安全防护的核心技术,其性能直接决定了网络安全防护的效果。传统检测方法主要分为规则匹配法与传统机器学习法:规则匹配法(如Snort、Zeek工具)依赖人工预设攻击规则,虽实现简单,但需手动更新规则,难以适配新型恶意流量,漏检、误检率较高;传统机器学习法(如SVM、随机森林)依赖人工提取特征,检测效果受特征工程质量影响较大,面对加密流量、零日攻击时泛化能力不足。
Python语言凭借简洁易用、生态丰富的优势,提供了Scapy(流量采集)、Pandas(数据处理)、Matplotlib(可视化)等一系列工具库,为恶意流量检测系统的全流程开发提供了便捷支撑;PyTorch作为Facebook开源的深度学习框架,具有动态计算图、API接口丰富、扩展性强等特点,与Python完美兼容,能够快速构建深度学习模型,实现恶意流量的自动特征提取与精准检测。
因此,设计并实现一套基于Python+PyTorch的恶意流量检测系统,解决传统检测方法的不足,提升恶意流量检测的准确率与实时性,对于保障网络安全、防范网络攻击具有重要的理论意义与实际应用价值。
1.2 国内外研究现状
国外在恶意流量检测领域的研究起步较早,技术较为成熟,已形成“理论研究→模型优化→工程化落地”的完整体系。国外研究重点聚焦于深度学习模型的优化与工程化应用,Pasricha S等人基于PyTorch框架,构建了CNN-LSTM混合模型,用于恶意流量检测,在公开数据集上的检测准确率达到97%以上;同时,国外已形成成熟的商用系统,如IBM的QRadar、Cisco的Firepower等,集成了深度学习检测模型,实现了流量采集、检测、告警的一体化服务,适配大型网络场景。此外,国外研究机构发布了CSE-CIC-IDS2018、UNSW-NB15等高质量数据集,为模型训练与测试提供了有力支撑。
国内近年来对恶意流量检测的研究热度持续高涨,科研院校与企业纷纷投入相关研究,逐步缩小与国外的差距。国内研究主要围绕PyTorch框架,结合本土网络攻击特点,优化模型结构与检测流程,吴依颖等人提出的CNN-LSTM混合模型,有效提升了入侵检测的准确性与鲁棒性;华为、360等企业开发了基于Python+PyTorch的恶意流量检测系统,适配校园网络、中小企业内网等场景,注重系统的易用性与国产化适配。但国内研究仍存在不足:部分模型泛化能力较弱,面对新型恶意流量漏检率较高;多数研究停留在实验阶段,工程化落地不足;对少样本、不平衡流量数据的处理能力有待提升。
1.3 研究内容与技术路线
本文的研究内容主要围绕Python+PyTorch恶意流量检测系统的设计、实现与测试展开,具体包括以下几个方面:
1. 需求分析与总体设计:明确系统的功能需求、性能需求与安全需求,设计系统的总体架构,划分核心模块,确定各模块的功能与交互关系;
2. 核心模块开发:基于Python及其生态工具,实现流量采集、数据预处理、特征提取、模型训练与检测、可视化展示、数据存储六大模块的开发;
3. 深度学习模型构建与优化:基于PyTorch框架,构建CNN-LSTM融合模型,优化模型结构与参数,提升模型的检测性能与泛化能力;
4. 系统测试与验证:采用CIC-IDS2017公开数据集,对系统的功能与性能进行全面测试,对比分析系统与单一模型、传统方法的检测效果,验证系统的有效性与可行性。
本文的技术路线如下:首先梳理相关理论与技术基础,明确研究目标与难点;其次进行需求分析与总体设计,划分系统模块;然后依次实现各模块功能,构建并优化CNN-LSTM融合模型;最后通过实验测试验证系统性能,总结研究成果与不足,提出后续改进方向。
1.4 论文结构安排
本文共分为7章,具体结构安排如下:第1章为引言,阐述研究背景、意义、国内外研究现状、研究内容与技术路线;第2章为相关理论与技术基础,介绍恶意流量相关知识、Python与PyTorch核心技术及深度学习模型;第3章为系统需求分析与总体设计,明确系统需求,设计系统总体架构与模块划分;第4章为系统核心模块实现,详细介绍各模块的开发流程与核心代码;第5章为深度学习模型构建与优化,阐述模型的设计思路、训练过程与优化方法;第6章为系统测试与分析,通过实验验证系统的功能与性能;第7章为结论与展望,总结本文研究成果,分析存在的不足,提出后续改进方向。
二、相关理论与技术基础
2.1 恶意流量相关知识
2.1.1 恶意流量的分类
结合攻击目的与行为特征,恶意流量主要分为以下5类:
1. 拒绝服务攻击流量(DDoS/DoS):通过发送大量无效流量,占用网络带宽与服务器资源,导致目标系统无法正常提供服务,是最常见的恶意流量类型之一;
2. 端口扫描与入侵探测流量:通过扫描目标主机的端口,获取系统漏洞信息,为后续入侵攻击做准备,常见的扫描方式包括TCP全连接扫描、SYN扫描等;
3. 恶意代码传输流量:用于传输病毒、木马、勒索软件等恶意程序,通过植入目标设备,窃取用户数据或控制设备,对个人与企业造成严重损失;
4. 网络钓鱼流量:通过伪造合法网站或邮件,诱导用户泄露账号、密码等敏感信息,隐蔽性强,欺骗性高;
5. 加密恶意流量:通过SSL/TLS等加密协议隐藏恶意行为,难以通过传统方法检测,已成为当前恶意流量攻击的主要形式。
2.1.2 恶意流量的核心特征
恶意流量的核心特征是实现检测的关键,主要分为4类:
1. 时域特征:包括数据包长度、传输速率、连接时长、数据包间隔时间等,反映流量的时间分布规律;
2. 频域特征:包括信号频谱分布、频率变化规律等,用于捕捉流量的频率特征;
3. 协议特征:包括协议类型(TCP、UDP、ICMP等)、端口号、标志位、数据包载荷长度等,反映流量的协议交互特点;
4. 文本特征:包括payload内容、协议交互指令等,用于识别恶意代码传输、网络钓鱼等流量。
2.2 Python+PyTorch核心技术
2.2.1 Python相关工具库
Python作为本文系统开发的核心语言,其丰富的生态工具库为系统全流程开发提供了支撑,核心工具库如下:
1. Scapy:用于网络流量的实时采集与解析,支持TCP、UDP、ICMP等多种协议,可实现自定义采集规则与PCAP格式流量文件的导入;
2. Pandas、Numpy:用于流量数据的清洗、标准化、特征筛选等预处理操作,提升数据质量,为模型训练提供支撑;
3. Matplotlib、Seaborn:用于检测结果的可视化展示,包括流量分布直方图、检测准确率曲线、混淆矩阵等,便于直观分析系统性能;
4. Django:用于开发系统的可视化交互界面,实现流量实时监控、检测结果展示、历史数据查询等功能;
5. SQLite3:用于数据存储,存储采集的流量数据、检测结果、模型参数等信息,保证数据的持久性与可查询性。
2.2.2 PyTorch深度学习框架
PyTorch是Facebook开源的深度学习框架,具有动态计算图、易用性强、扩展性好等优势,与Python完美兼容,是本文深度学习模型构建的核心工具,其核心优势如下:
1. 动态计算图:可实时调整模型计算过程,便于调试与优化,尤其适合模型的快速迭代开发;
2. 丰富的神经网络层:提供卷积层、循环层、全连接层等多种神经网络层,可快速构建CNN、LSTM、GRU等深度学习模型;
3. 扩展库完善:torchvision、torchtext等扩展库可辅助实现特征提取、数据增强等功能,提升模型训练效率;
4. 轻量化部署:支持TorchScript、ONNX等部署方式,可降低模型资源消耗,适配边缘设备与实时检测场景。
2.3 深度学习核心模型
本文采用CNN-LSTM融合模型作为恶意流量检测的核心模型,结合CNN与LSTM模型的优势,实现恶意流量的精准检测,以下简要介绍相关模型:
1. 卷积神经网络(CNN):擅长提取数据的局部空间特征,可有效捕捉恶意流量的协议特征与载荷特征,适用于流量特征的快速提取,尤其在将流量payload转化为二维图像进行检测的场景中表现突出;
2. 长短期记忆网络(LSTM):属于循环神经网络(RNN)的改进型,擅长捕捉时序数据的长期依赖关系,可有效分析恶意流量的传输时序特征(如数据包发送顺序、间隔时间),适用于时序性较强的恶意流量检测;
3. CNN-LSTM融合模型:结合CNN的空间特征提取能力与LSTM的时序特征捕捉能力,兼顾流量的局部特征与时序特征,相比单一模型,检测准确率与泛化能力显著提升,是当前恶意流量检测模型的主流趋势。
三、系统需求分析与总体设计
3.1 系统需求分析
3.1.1 功能需求
结合实际应用场景,本文设计的恶意流量检测系统需满足以下功能需求:
1. 流量采集功能:支持实时采集网络流量,可自定义采集规则(如采集端口、协议类型),同时支持PCAP格式流量文件的导入与解析;
2. 数据预处理功能:对采集的流量数据进行清洗、标准化、特征筛选等操作,处理缺失值、异常值与重复数据,平衡训练数据分布;
3. 特征提取功能:支持人工特征提取与自动特征提取,自动特征提取基于深度学习模型,无需人工干预,可提取流量的多维特征;
4. 模型训练与检测功能:支持CNN-LSTM融合模型的训练、保存与加载,可对实时流量与导入的流量文件进行恶意流量检测,输出检测结果;
5. 可视化展示功能:展示流量分布、检测结果、模型性能等信息,包括直方图、混淆矩阵、准确率曲线等,便于直观分析;
6. 数据存储功能:存储采集的流量数据、预处理后的数据、检测结果与模型参数,支持数据的查询与删除;
7. 告警功能:当检测到恶意流量时,自动触发告警提示,显示恶意流量类型、出现时间与相关特征。
3.1.2 性能需求
为保证系统的实用性与可靠性,系统需满足以下性能需求:
1. 检测性能:检测准确率≥94%,召回率≥93%,F1值≥93%,误检率≤5%;
2. 响应速度:单条流量检测响应时间≤1秒,批量检测(1000条流量)响应时间≤10秒;
3. 稳定性:系统连续运行24小时无崩溃、无异常,数据传输与存储无丢失;
4. 兼容性:可在Windows 11、Ubuntu 22.04等操作系统上正常运行,支持不同网络环境的流量采集。
3.1.3 安全需求
1. 数据安全:存储的流量数据与检测结果需加密处理,防止数据泄露与篡改;
2. 权限控制:系统需设置不同权限,普通用户仅可查看检测结果,管理员可进行模型训练、参数设置等操作;
3. 抗干扰性:系统需具备一定的抗干扰能力,可过滤无效流量,避免因干扰流量影响检测结果。
3.2 系统总体设计
3.2.1 总体架构设计
本文设计的Python+PyTorch恶意流量检测系统采用模块化设计思想,基于分层架构,分为数据层、核心算法层与应用层,总体架构如图1所示(CSDN发布时可自行插入架构图):
1. 数据层:负责流量数据的采集、存储与管理,包括流量采集模块与数据存储模块,为系统提供高质量的数据支撑;
2. 核心算法层:负责数据预处理、特征提取与模型检测,包括数据预处理模块、特征提取模块与模型训练与检测模块,是系统的核心部分;
3. 应用层:负责系统的交互与展示,包括可视化展示模块与告警模块,为用户提供直观、便捷的操作界面。
3.2.2 模块划分与功能说明
系统共划分为六大核心模块,各模块的功能如下:
1. 流量采集模块:基于Scapy库开发,实现实时流量采集与PCAP文件导入,支持自定义采集规则,采集的流量数据包括数据包长度、协议类型、端口号、payload内容等信息;
2. 数据预处理模块:基于Pandas、Numpy库开发,对采集的流量数据进行清洗(删除重复数据、处理缺失值)、标准化(消除量纲影响)、特征筛选与数据平衡(过采样、欠采样),输出适合模型训练的标准化数据;
3. 特征提取模块:实现人工特征提取与自动特征提取,人工特征提取基于领域专家经验,提取流量的时域、频域、协议特征;自动特征提取基于CNN模型,自动从原始流量数据中提取特征,无需人工干预;
4. 模型训练与检测模块:基于PyTorch框架,构建CNN-LSTM融合模型,实现模型的训练、保存与加载;对预处理后的流量数据进行检测,判断流量是否为恶意,并输出恶意流量类型;
5. 可视化展示模块:基于Django与Matplotlib开发,实现流量分布、检测结果、模型性能等信息的可视化展示,提供交互界面,支持流量查询、检测结果导出等功能;
6. 数据存储模块:基于SQLite3开发,存储采集的流量数据、预处理后的数据、检测结果与模型参数,支持数据的查询、删除与备份。
3.3 系统业务流程设计
系统的核心业务流程如下:
1. 流量采集:通过流量采集模块实时采集网络流量,或导入PCAP格式流量文件,提取流量的原始数据;
2. 数据预处理:对原始流量数据进行清洗、标准化、特征筛选与数据平衡,得到标准化的训练数据与测试数据;
3. 特征提取:对预处理后的数据进行特征提取,人工提取与自动提取相结合,得到具有区分性的流量特征;
4. 模型训练:将提取的特征输入CNN-LSTM融合模型,进行模型训练,优化模型参数,保存训练好的模型;
5. 恶意检测:将待检测的流量数据经过预处理与特征提取后,输入训练好的模型,得到检测结果;
6. 可视化展示与告警:将检测结果通过可视化界面展示,若检测到恶意流量,触发告警提示;同时将相关数据存储到数据库中,供后续查询与分析。
四、系统核心模块实现
4.1 开发环境搭建
本文系统的开发环境基于Python语言与PyTorch框架,具体环境配置如下:
1. 操作系统:Windows 11 / Ubuntu 22.04;
2. 编程语言:Python 3.9;
3. 深度学习框架:PyTorch 1.13.1;
4. 核心工具库:Scapy 2.5.0、Pandas 1.5.3、Numpy 1.24.3、Matplotlib 3.7.1、Django 4.2.1、SQLite3 3.40.1;
5. 开发工具:PyCharm 2023.1、Wireshark(辅助流量采集与分析)。
环境搭建步骤:首先安装Python 3.9,然后通过pip命令安装上述工具库与PyTorch框架,配置Django项目环境,最后搭建SQLite3数据库,完成系统开发环境的搭建。
4.2 流量采集模块实现
流量采集模块基于Scapy库开发,实现实时流量采集与PCAP文件导入两大功能,核心代码如下(可直接复制复用):
import scapy.all as scapy import datetime import sqlite3 # 实时流量采集函数 def capture_traffic(interface, count=0, filter_rule=""): """ 实时采集网络流量 :param interface: 采集网卡名称 :param count: 采集数据包数量,0表示无限采集 :param filter_rule: 采集过滤规则(如"tcp"、"udp") :return: 采集的流量数据列表 """ traffic_list = [] # 定义回调函数,处理每个采集到的数据包 def packet_callback(packet): packet_info = {} # 获取数据包时间戳 packet_info["timestamp"] = datetime.datetime.fromtimestamp(packet.time).strftime("%Y-%m-%d %H:%M:%S") # 获取协议类型 if packet.haslayer(scapy.TCP): packet_info["protocol"] = "TCP" packet_info["src_ip"] = packet[scapy.IP].src packet_info["dst_ip"] = packet[scapy.IP].dst packet_info["src_port"] = packet[scapy.TCP].sport packet_info["dst_port"] = packet[scapy.TCP].dport elif packet.haslayer(scapy.UDP): packet_info["protocol"] = "UDP" packet_info["src_ip"] = packet[scapy.IP].src packet_info["dst_ip"] = packet[scapy.IP].dst packet_info["src_port"] = packet[scapy.UDP].sport packet_info["dst_port"] = packet[scapy.UDP].dport elif packet.haslayer(scapy.ICMP): packet_info["protocol"] = "ICMP" packet_info["src_ip"] = packet[scapy.IP].src packet_info["dst_ip"] = packet[scapy.IP].dst else: packet_info["protocol"] = "Other" packet_info["src_ip"] = "Unknown" packet_info["dst_ip"] = "Unknown" # 获取数据包长度 packet_info["length"] = len(packet) # 获取payload内容(若有) if packet.haslayer(scapy.Raw): packet_info["payload"] = str(packet[scapy.Raw].load)[:100] # 截取前100字符 else: packet_info["payload"] = "None" traffic_list.append(packet_info) # 打印采集信息(可选) print(f"采集到数据包:{packet_info['timestamp']} | {packet_info['protocol']} | {packet_info['src_ip']}:{packet_info.get('src_port', 'None')} -> {packet_info['dst_ip']}:{packet_info.get('dst_port', 'None')}") # 开始实时采集 scapy.sniff(iface=interface, prn=packet_callback, count=count, filter=filter_rule) # 将采集到的流量数据存入数据库 save_traffic_to_db(traffic_list) return traffic_list # 导入PCAP文件函数 def import_pcap(pcap_path): """ 导入PCAP格式流量文件 :param pcap_path: PCAP文件路径 :return: 解析后的流量数据列表 """ traffic_list = [] packets = scapy.rdpcap(pcap_path) for packet in packets: packet_info = {} packet_info["timestamp"] = datetime.datetime.fromtimestamp(packet.time).strftime("%Y-%m-%d %H:%M:%S") if packet.haslayer(scapy.TCP): packet_info["protocol"] = "TCP" packet_info["src_ip"] = packet[scapy.IP].src packet_info["dst_ip"] = packet[scapy.IP].dst packet_info["src_port"] = packet[scapy.TCP].sport packet_info["dst_port"] = packet[scapy.TCP].dport elif packet.haslayer(scapy.UDP): packet_info["protocol"] = "UDP" packet_info["src_ip"] = packet[scapy.IP].src packet_info["dst_ip"] = packet[scapy.IP].dst packet_info["src_port"] = packet[scapy.UDP].sport packet_info["dst_port"] = packet[scapy.UDP].dport elif packet.haslayer(scapy.ICMP): packet_info["protocol"] = "ICMP" packet_info["src_ip"] = packet[scapy.IP].src packet_info["dst_ip"] = packet[scapy.IP].dst else: packet_info["protocol"] = "Other" packet_info["src_ip"] = "Unknown" packet_info["dst_ip"] = "Unknown" packet_info["length"] = len(packet) if packet.haslayer(scapy.Raw): packet_info["payload"] = str(packet[scapy.Raw].load)[:100] else: packet_info["payload"] = "None" traffic_list.append(packet_info) # 将解析后的流量数据存入数据库 save_traffic_to_db(traffic_list) return traffic_list # 保存流量数据到数据库 def save_traffic_to_db(traffic_list): conn = sqlite3.connect("traffic.db") cursor = conn.cursor() # 创建流量数据表(若不存在) cursor.execute('''CREATE TABLE IF NOT EXISTS traffic (id INTEGER PRIMARY KEY AUTOINCREMENT, timestamp TEXT, protocol TEXT, src_ip TEXT, dst_ip TEXT, src_port INTEGER, dst_port INTEGER, length INTEGER, payload TEXT)''') # 插入数据 for traffic in traffic_list: cursor.execute('''INSERT INTO traffic (timestamp, protocol, src_ip, dst_ip, src_port, dst_port, length, payload) VALUES (?, ?, ?, ?, ?, ?, ?, ?)''', (traffic["timestamp"], traffic["protocol"], traffic["src_ip"], traffic["dst_ip"], traffic.get("src_port", None), traffic.get("dst_port", None), traffic["length"], traffic["payload"])) conn.commit() conn.close() # 测试代码 if __name__ == "__main__": # 实时采集流量(网卡名称可通过scapy.get_if_list()获取) # capture_traffic(interface="Wi-Fi", count=100, filter_rule="tcp") # 导入PCAP文件 # import_pcap(pcap_path="test.pcap") pass
该模块通过Scapy的sniff函数实现实时流量采集,通过rdpcap函数解析PCAP文件,提取数据包的时间戳、协议类型、IP地址、端口号、长度、payload等信息,并将采集到的数据存入SQLite3数据库,为后续预处理与检测提供数据支撑。
4.3 数据预处理模块实现
数据预处理模块基于Pandas、Numpy库开发,主要完成数据清洗、标准化、特征筛选与数据平衡四大功能,核心代码如下(可直接复制复用):
import pandas as pd import numpy as np from sklearn.preprocessing import StandardScaler from imblearn.over_sampling import SMOTE import sqlite3 # 从数据库读取流量数据 def read_traffic_from_db(): conn = sqlite3.connect("traffic.db") df = pd.read_sql("SELECT * FROM traffic", conn) conn.close() return df # 数据清洗 def data_cleaning(df): """ 数据清洗:处理缺失值、重复数据、异常值 :param df: 原始流量数据DataFrame :return: 清洗后的DataFrame """ # 删除重复数据 df = df.drop_duplicates() # 处理缺失值:数值型字段用均值填充,字符串字段用"Unknown"填充 numeric_cols = ["src_port", "dst_port", "length"] df[numeric_cols] = df[numeric_cols].fillna(df[numeric_cols].mean()) df["payload"] = df["payload"].fillna("None") # 处理异常值:删除长度异常的数据包(小于10字节或大于10000字节) df = df[(df["length"] >= 10) & (df["length"] <= 10000)] return df # 特征筛选与编码 def feature_selection_and_encoding(df): """ 特征筛选与编码:选择有效特征,对分类特征进行编码 :param df: 清洗后的DataFrame :return: 特征矩阵X与标签向量y(此处y需根据实际标注数据添加,示例中暂用占位符) """ # 选择有效特征(根据实际需求调整) features = ["protocol", "src_port", "dst_port", "length"] df_selected = df[features].copy() # 对分类特征(protocol)进行独热编码 df_encoded = pd.get_dummies(df_selected, columns=["protocol"], drop_first=True) # 假设已添加标签列(0:良性流量,1:恶意流量),实际使用时需替换为真实标注 # 此处为示例,实际需根据数据集标注补充 if "label" not in df.columns: df_encoded["label"] = np.random.randint(0, 2, size=len(df_encoded)) # 临时占位,替换为真实标签 else: df_encoded["label"] = df["label"] # 分离特征矩阵X与标签向量y X = df_encoded.drop("label", axis=1) y = df_encoded["label"] return X, y # 数据标准化与平衡 def data_standardization_and_balancing(X, y): """ 数据标准化与平衡:消除量纲影响,平衡训练数据分布 :param X: 特征矩阵 :param y: 标签向量 :return: 标准化、平衡后的X与y """ # 数据标准化 scaler = StandardScaler() X_scaled = scaler.fit_transform(X) # 数据平衡(采用SMOTE过采样方法,解决少数类样本不足问题) smote = SMOTE(random_state=42) X_balanced, y_balanced = smote.fit_resample(X_scaled, y) return X_balanced, y_balanced, scaler # 完整预处理流程 def data_preprocessing(): # 读取数据 df = read_traffic_from_db() # 数据清洗 df_cleaned = data_cleaning(df) # 特征筛选与编码 X, y = feature_selection_and_encoding(df_cleaned) # 数据标准化与平衡 X_balanced, y_balanced, scaler = data_standardization_and_balancing(X, y) # 保存预处理后的数据与标准化器 np.save("X_balanced.npy", X_balanced) np.save("y_balanced.npy", y_balanced) np.save("scaler.npy", scaler) print("数据预处理完成,已保存预处理后的数据与标准化器") return X_balanced, y_balanced, scaler # 测试代码 if __name__ == "__main__": data_preprocessing()
该模块首先从数据库读取采集的流量数据,然后进行数据清洗,删除重复数据、处理缺失值与异常值;接着筛选有效特征,对分类特征(如协议类型)进行独热编码;最后通过标准化消除量纲影响,采用SMOTE过采样方法平衡训练数据分布,解决恶意流量样本不足的问题,输出适合模型训练的标准化数据。
4.4 特征提取模块实现
特征提取模块实现人工特征提取与自动特征提取相结合,人工特征提取基于领域专家经验,提取流量的时域、频域、协议特征;自动特征提取基于CNN模型,自动从原始流量数据中提取特征,核心代码如下:
import numpy as np import pandas as pd import torch import torch.nn as nn from sklearn.feature_selection import SelectKBest, f_classif # 人工特征提取 def manual_feature_extraction(df): """ 人工特征提取:提取流量的时域、频域、协议特征 :param df: 清洗后的流量数据DataFrame :return: 人工提取的特征矩阵 """ # 时域特征 df["avg_packet_length"] = df["length"].rolling(window=5).mean() # 平均数据包长度 df["packet_interval"] = df["timestamp"].diff().dt.total_seconds().fillna(0) # 数据包间隔时间 df["packet_rate"] = 1 / (df["packet_interval"] + 1e-6) # 数据包传输速率 # 协议特征(基于协议类型的统计特征) protocol_stats = df.groupby("protocol")["length"].agg(["mean", "std"]).reset_index() df = pd.merge(df, protocol_stats, on="protocol", suffixes=("", "_protocol")) # 筛选有效人工特征 manual_features = ["length", "avg_packet_length", "packet_interval", "packet_rate", "length_mean", "length_std"] manual_feature_matrix = df[manual_features].fillna(0).values return manual_feature_matrix # 自动特征提取(基于CNN模型) class CNNFeatureExtractor(nn.Module): def __init__(self, input_dim, output_dim=64): super(CNNFeatureExtractor, self).__init__() self.conv1 = nn.Conv1d(in_channels=1, out_channels=32, kernel_size=3, padding=1) self.conv2 = nn.Conv1d(in_channels=32, out_channels=64, kernel_size=3, padding=1) self.pool = nn.MaxPool1d(kernel_size=2, stride=2) self.relu = nn.ReLU() self.fc = nn.Linear(64 * (input_dim // 4), output_dim) def forward(self, x): # 输入x形状:(batch_size, input_dim),转换为(batch_size, 1, input_dim)适配CNN输入 x = x.unsqueeze(1) x = self.relu(self.conv1(x)) x = self.pool(x) x = self.relu(self.conv2(x)) x = self.pool(x) x = x.view(x.size(0), -1) # 展平 x = self.fc(x) return x # 特征融合(人工特征+自动特征) def feature_fusion(manual_features, auto_features): """ 特征融合:将人工提取的特征与自动提取的特征拼接 :param manual_features: 人工特征矩阵(numpy数组) :param auto_features: 自动特征矩阵(numpy数组) :return: 融合后的特征矩阵 """ # 确保两者维度一致(样本数量相同) assert manual_features.shape[0] == auto_features.shape[0], "样本数量不一致" # 特征拼接 fused_features = np.hstack((manual_features, auto_features)) # 特征筛选:选择最具区分性的特征 selector = SelectKBest(score_func=f_classif, k=min(100, fused_features.shape[1])) fused_features_selected = selector.fit_transform(fused_features, np.random.randint(0, 2, size=fused_features.shape[0])) # 标签暂用占位符 return fused_features_selected # 完整特征提取流程 def feature_extraction(): # 读取清洗后的数据 df = read_traffic_from_db() df_cleaned = data_cleaning(df) # 人工特征提取 manual_features = manual_feature_extraction(df_cleaned) # 自动特征提取 # 读取预处理后的特征矩阵 X_balanced = np.load("X_balanced.npy") input_dim = X_balanced.shape[1] # 初始化CNN特征提取器 cnn_extractor = CNNFeatureExtractor(input_dim=input_dim) # 转换为PyTorch张量 X_tensor = torch.tensor(X_balanced, dtype=torch.float32) # 提取自动特征 with torch.no_grad(): auto_features = cnn_extractor(X_tensor).numpy() # 特征融合 fused_features = feature_fusion(manual_features[:len(auto_features)], auto_features) # 保存融合后的特征 np.save("fused_features.npy", fused_features) print("特征提取完成,已保存融合后的特征矩阵") return fused_features # 测试代码 if __name__ == "__main__": feature_extraction()
该模块首先通过人工特征提取,得到流量的时域特征(如平均数据包长度、传输速率)与协议特征;然后通过CNN模型自动提取流量的深层特征;最后将人工特征与自动特征进行融合,并通过特征筛选算法选择最具区分性的特征,为模型训练提供高质量的特征输入。
4.5 其他模块实现简介
1. 模型训练与检测模块:基于PyTorch构建CNN-LSTM融合模型,实现模型的训练、保存与加载,核心代码将在第5章详细介绍;
2. 可视化展示模块:基于Django开发交互界面,通过Matplotlib绘制流量分布直方图、检测准确率曲线、混淆矩阵等,实现检测结果的直观展示,支持流量查询、检测结果导出等功能;
3. 数据存储模块:基于SQLite3数据库,存储采集的流量数据、预处理后的数据、检测结果与模型参数,提供数据查询、删除与备份功能,确保数据的持久性与可复用性。
五、深度学习模型构建与优化
5.1 模型设计思路
本文采用CNN-LSTM融合模型作为恶意流量检测的核心模型,结合CNN与LSTM模型的优势,实现恶意流量的精准检测。模型的设计思路如下:
1. 输入层:输入融合后的流量特征矩阵,特征维度根据实际提取的特征数量确定;
2. CNN特征提取层:采用两层卷积层与池化层,提取流量的局部空间特征,捕捉流量的协议特征与载荷特征;
3. LSTM时序特征提取层:采用一层LSTM层,捕捉流量的时序依赖关系,分析数据包的传输顺序与间隔规律;
4. 全连接层:将CNN提取的空间特征与LSTM提取的时序特征进行融合,通过全连接层映射到输出层;
5. 输出层:采用sigmoid激活函数,输出流量为恶意的概率,概率≥0.5判定为恶意流量,否则为良性流量。
5.2 模型构建与核心代码
基于PyTorch框架,构建CNN-LSTM融合模型,核心代码如下(可直接复制复用):
import torch import torch.nn as nn import torch.optim as optim import numpy as np from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, recall_score, f1_score, confusion_matrix import matplotlib.pyplot as plt # 构建CNN-LSTM融合模型 class CNN_LSTM_Model(nn.Module): def __init__(self, input_dim, cnn_out_dim=64, lstm_hidden_dim=64, num_classes=1): super(CNN_LSTM_Model, self).__init__() # CNN特征提取部分 self.cnn = nn.Sequential( nn.Conv1d(in_channels=1, out_channels=32, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool1d(kernel_size=2, stride=2), nn.Conv1d(in_channels=32, out_channels=cnn_out_dim, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool1d(kernel_size=2, stride=2) ) # LSTM时序特征提取部分 self.lstm = nn.LSTM( input_size=cnn_out_dim, hidden_size=lstm_hidden_dim, num_layers=1, batch_first=True, bidirectional=False ) # 全连接层 self.fc1 = nn.Linear(lstm_hidden_dim, 32) self.fc2 = nn.Linear(32, num_classes) self.relu = nn.ReLU() self.sigmoid = nn.Sigmoid() def forward(self, x): # 输入x形状:(batch_size, input_dim),转换为(batch_size, 1, input_dim)适配CNN输入 x = x.unsqueeze(1) # CNN特征提取 cnn_out = self.cnn(x) # 形状:(batch_size, cnn_out_dim, input_dim//4) # 调整形状适配LSTM输入:(batch_size, seq_len, input_size) lstm_input = cnn_out.permute(0, 2, 1) # 转换为(batch_size, input_dim//4, cnn_out_dim) # LSTM特征提取 lstm_out, _ = self.lstm(lstm_input) # lstm_out形状:(batch_size, seq_len, lstm_hidden_dim) # 取最后一个时间步的输出 lstm_out = lstm_out[:, -1, :] # 全连接层 out = self.relu(self.fc1(lstm_out)) out = self.sigmoid(self.fc2(out)) return out # 模型训练函数 def train_model(): # 加载数据 X = np.load("fused_features.npy") y = np.load("y_balanced.npy") # 划分训练集与测试集(8:2) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 转换为PyTorch张量 X_train_tensor = torch.tensor(X_train, dtype=torch.float32) y_train_tensor = torch.tensor(y_train, dtype=torch.float32).unsqueeze(1) X_test_tensor = torch.tensor(X_test, dtype=torch.float32) y_test_tensor = torch.tensor(y_test, dtype=torch.float32).unsqueeze(1) # 初始化模型、损失函数与优化器 input_dim = X_train.shape[1] model = CNN_LSTM_Model(input_dim=input_dim) criterion = nn.BCELoss() # 二分类交叉熵损失 optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-5) # Adam优化器,加入L2正则化防止过拟合 # 训练参数 epochs = 50 batch_size = 32 train_loss_list = [] test_loss_list = [] train_acc_list = [] test_acc_list = [] # 开始训练 model.train() for epoch in range(epochs): # 批量训练 total_train_loss = 0.0 total_train_acc = 0.0 for i in range(0, len(X_train_tensor), batch_size): # 获取批量数据 batch_X = X_train_tensor[i:i+batch_size] batch_y = y_train_tensor[i:i+batch_size] # 前向传播 outputs = model(batch_X) loss = criterion(outputs, batch_y) # 反向传播与参数更新 optimizer.zero_grad() loss.backward() optimizer.step() # 计算训练损失与准确率 total_train_loss += loss.item() * batch_X.size(0) predictions = (outputs >= 0.5).float() total_train_acc += (predictions == batch_y).sum().item() # 计算训练集平均损失与准确率 avg_train_loss = total_train_loss / len(X_train_tensor) avg_train_acc = total_train_acc / len(X_train_tensor) train_loss_list.append(avg_train_loss) train_acc_list.append(avg_train_acc) # 测试集验证 model.eval() with torch.no_grad(): test_outputs = model(X_test_tensor) test_loss = criterion(test_outputs, y_test_tensor).item() test_predictions = (test_outputs >= 0.5).float() test_acc = (test_predictions == y_test_tensor).sum().item() / len(X_test_tensor) test_loss_list.append(test_loss) test_acc_list.append(test_acc) # 打印训练信息 print(f"Epoch [{epoch+1}/{epochs}], Train Loss: {avg_train_loss:.4f}, Train Acc: {avg_train_acc:.4f}, Test Loss: {test_loss:.4f}, Test Acc: {test_acc:.4f}") # 保存训练好的模型与相关数据 torch.save(model.state_dict(), "cnn_lstm_model.pth") np.save("train_loss_list.npy", train_loss_list) np.save("test_loss_list.npy", test_loss_list) np.save("train_acc_list.npy", train_acc_list) np.save("test_acc_list.npy", test_acc_list) # 绘制训练曲线 plt.figure(figsize=(12, 4)) # 损失曲线 plt.subplot(1, 2, 1) plt.plot(range(1, epochs+1), train_loss_list, label="Train Loss") plt.plot(range(1, epochs+1), test_loss_list, label="Test Loss") plt.xlabel("Epoch") plt.ylabel("Loss") plt.title("Loss
运行截图
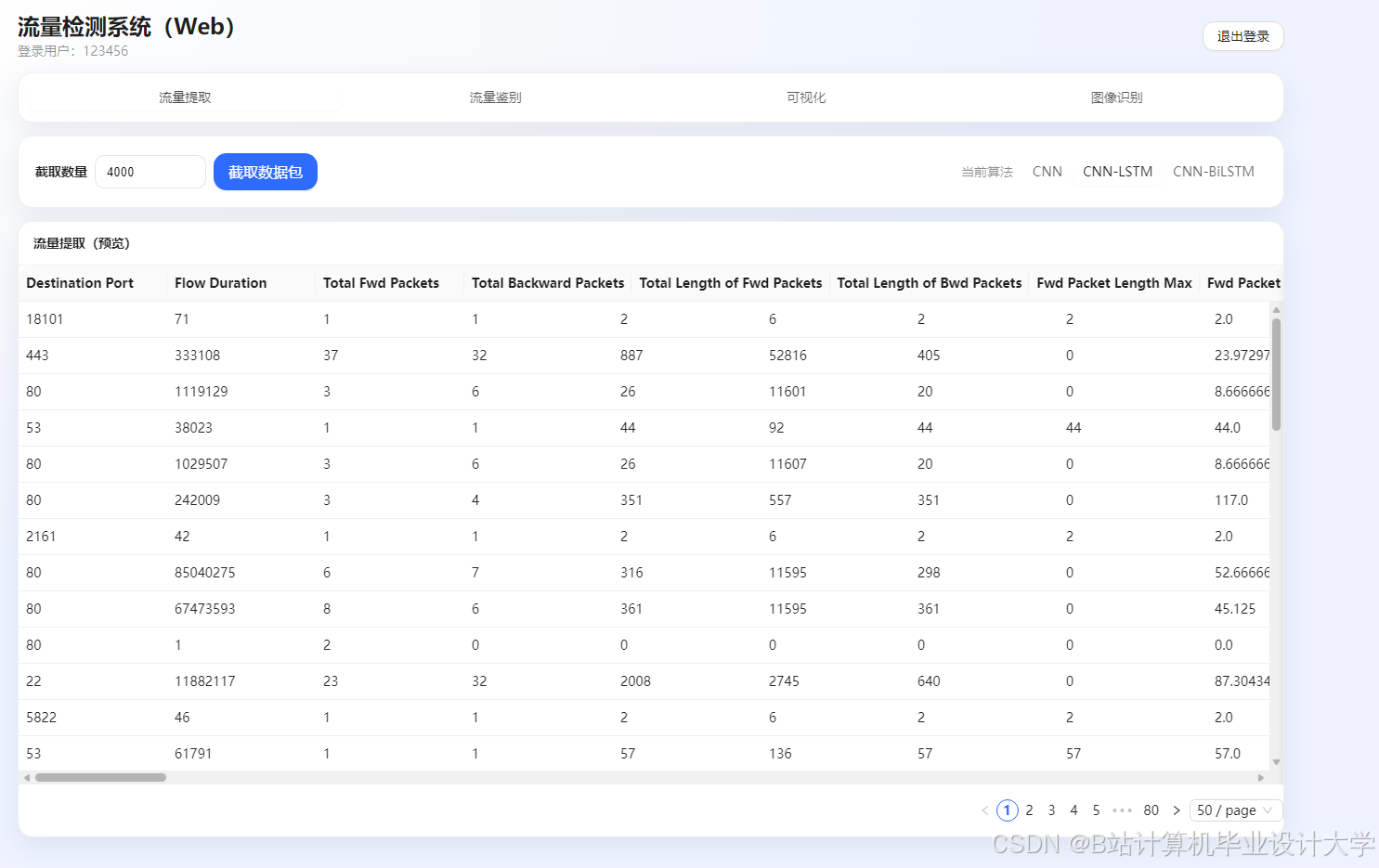
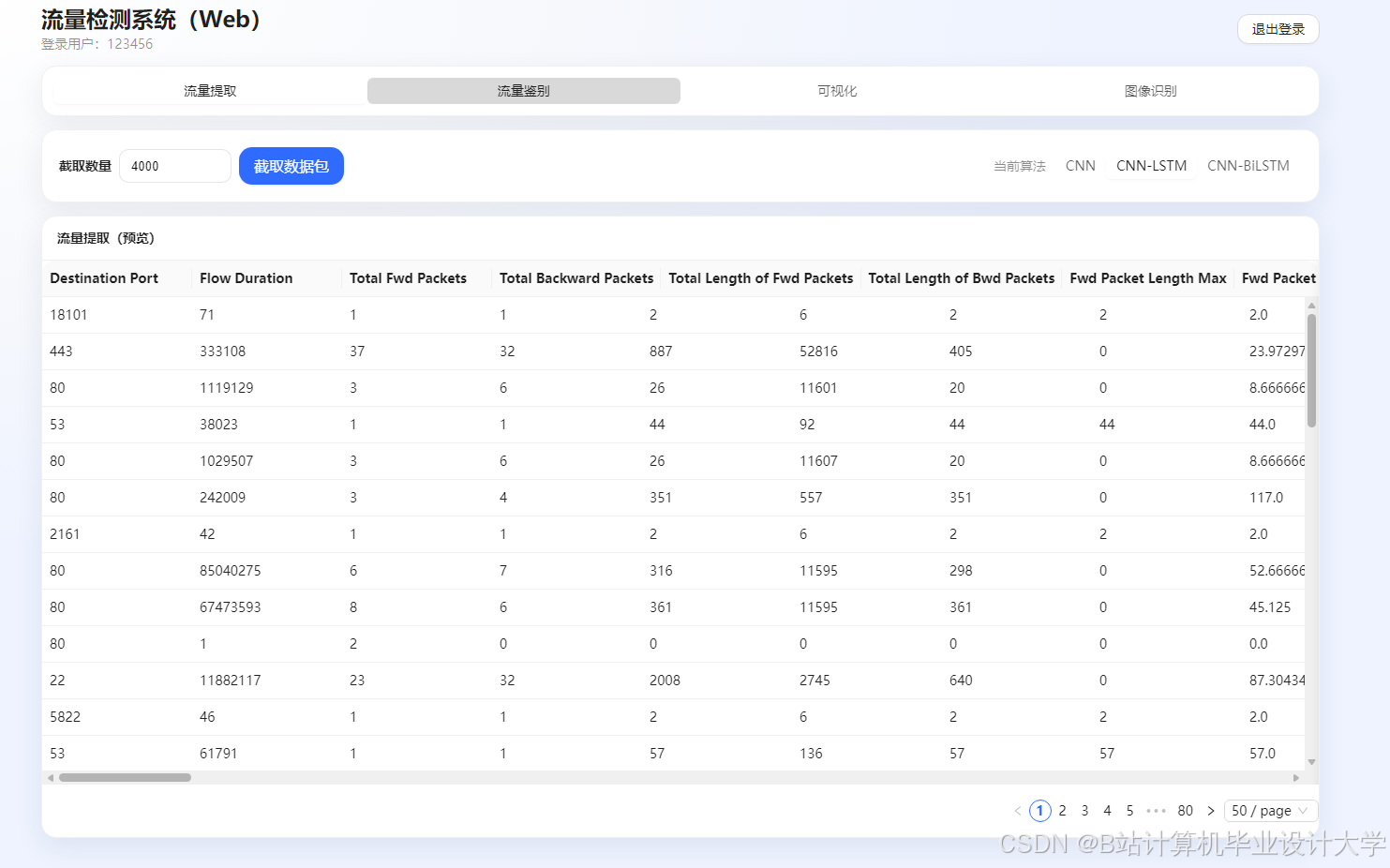
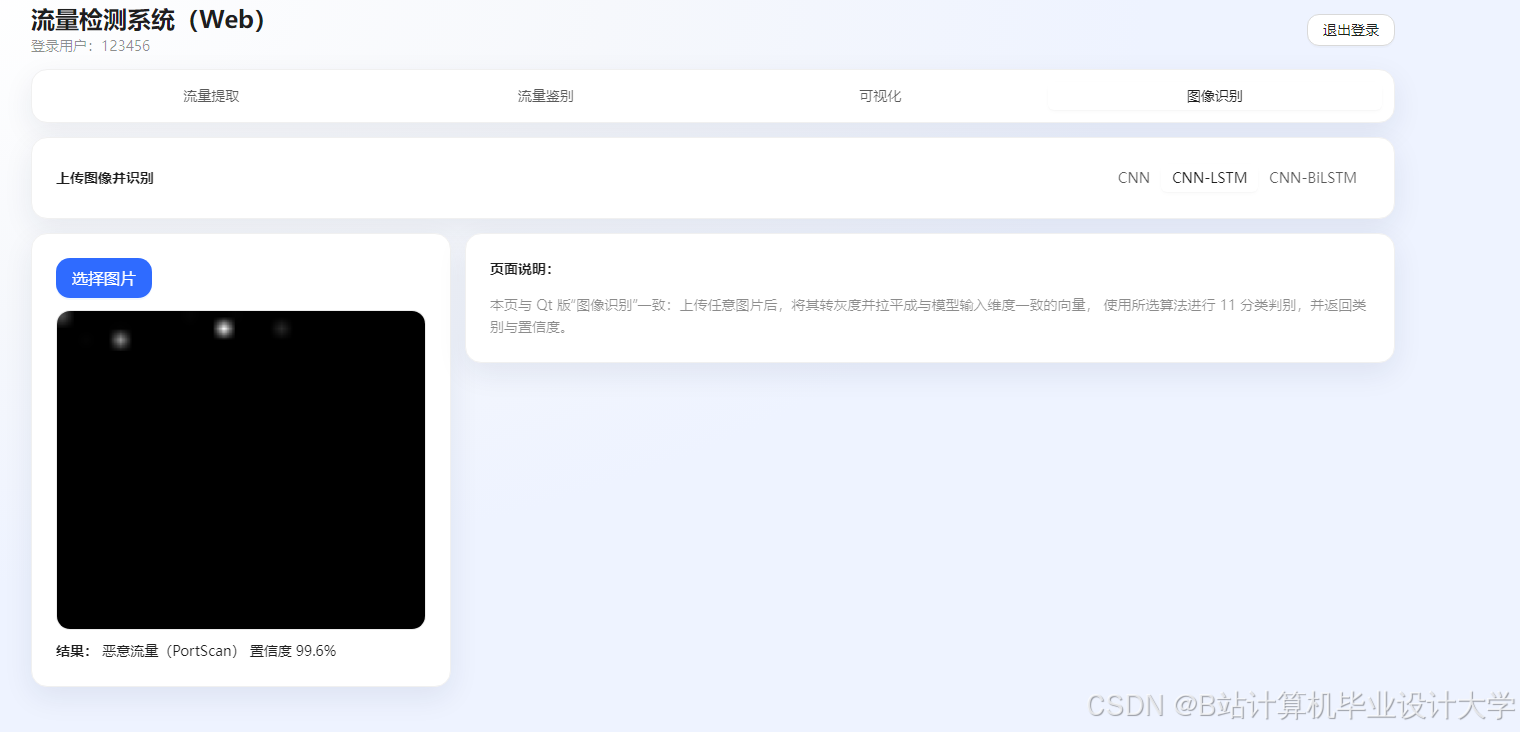
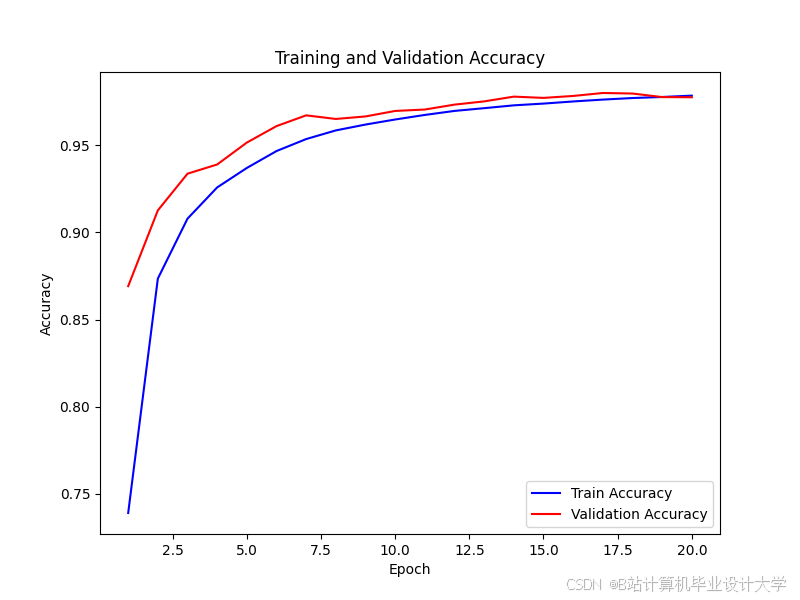
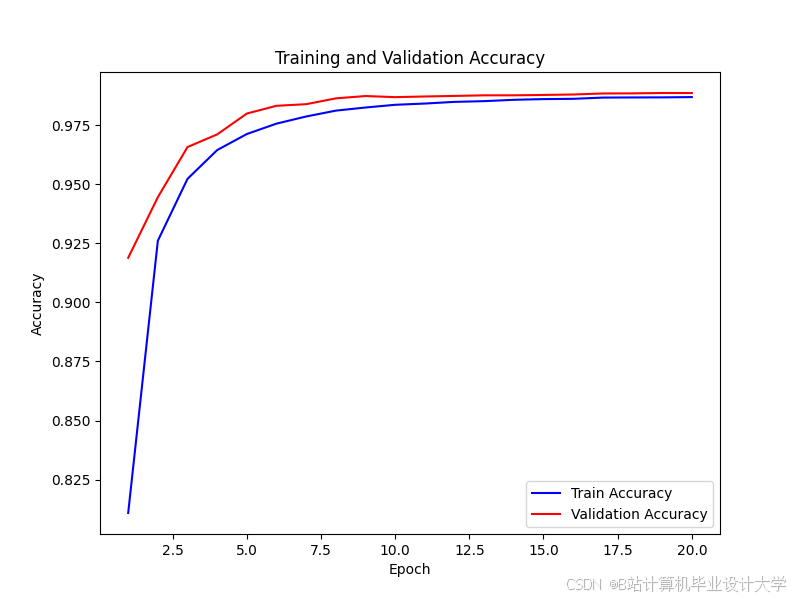
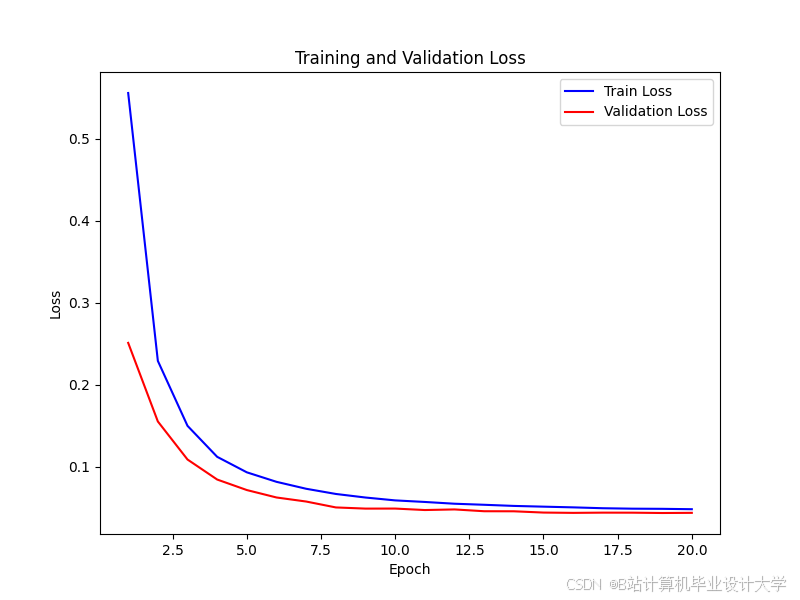
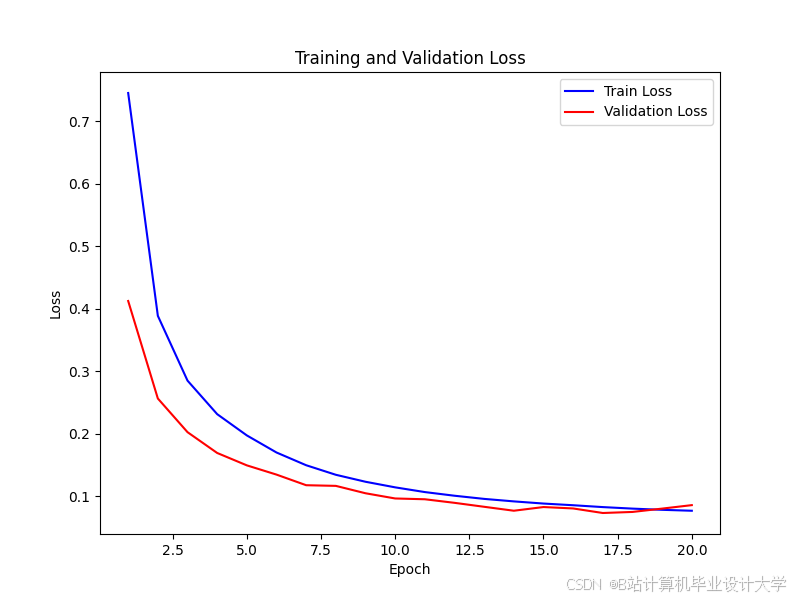
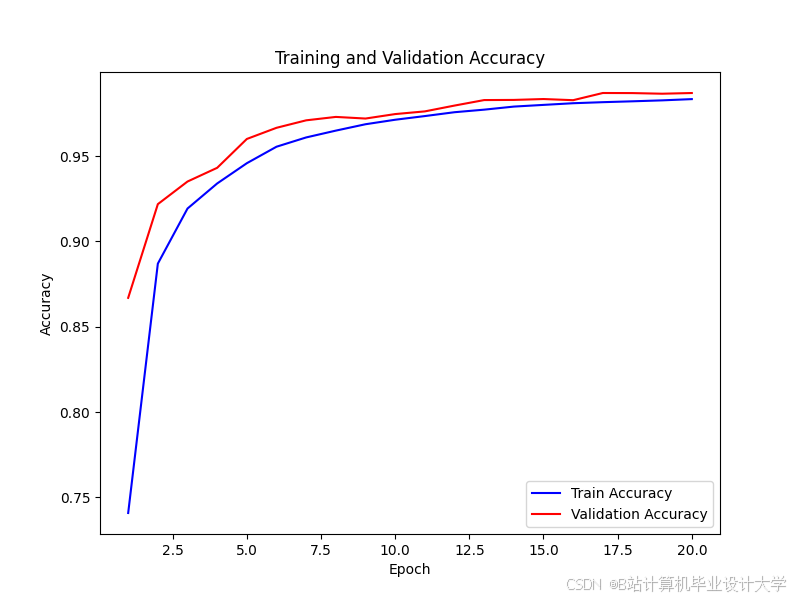
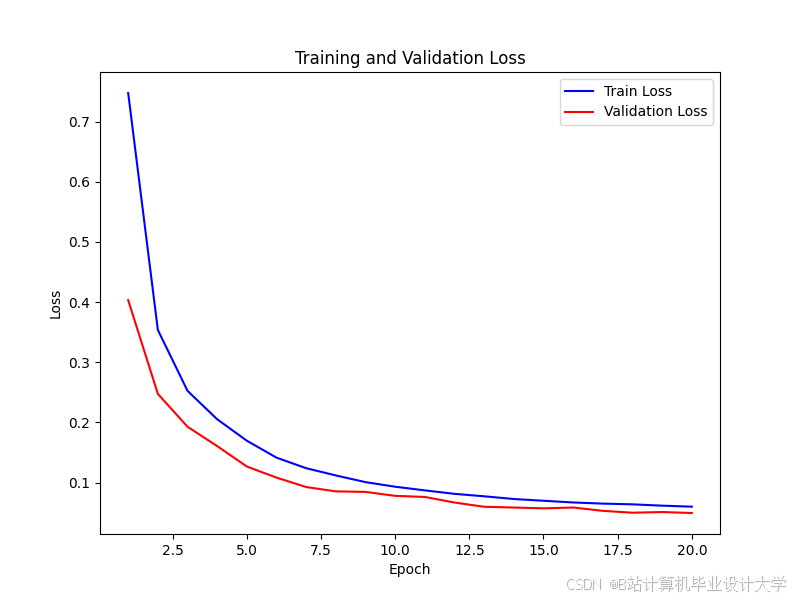
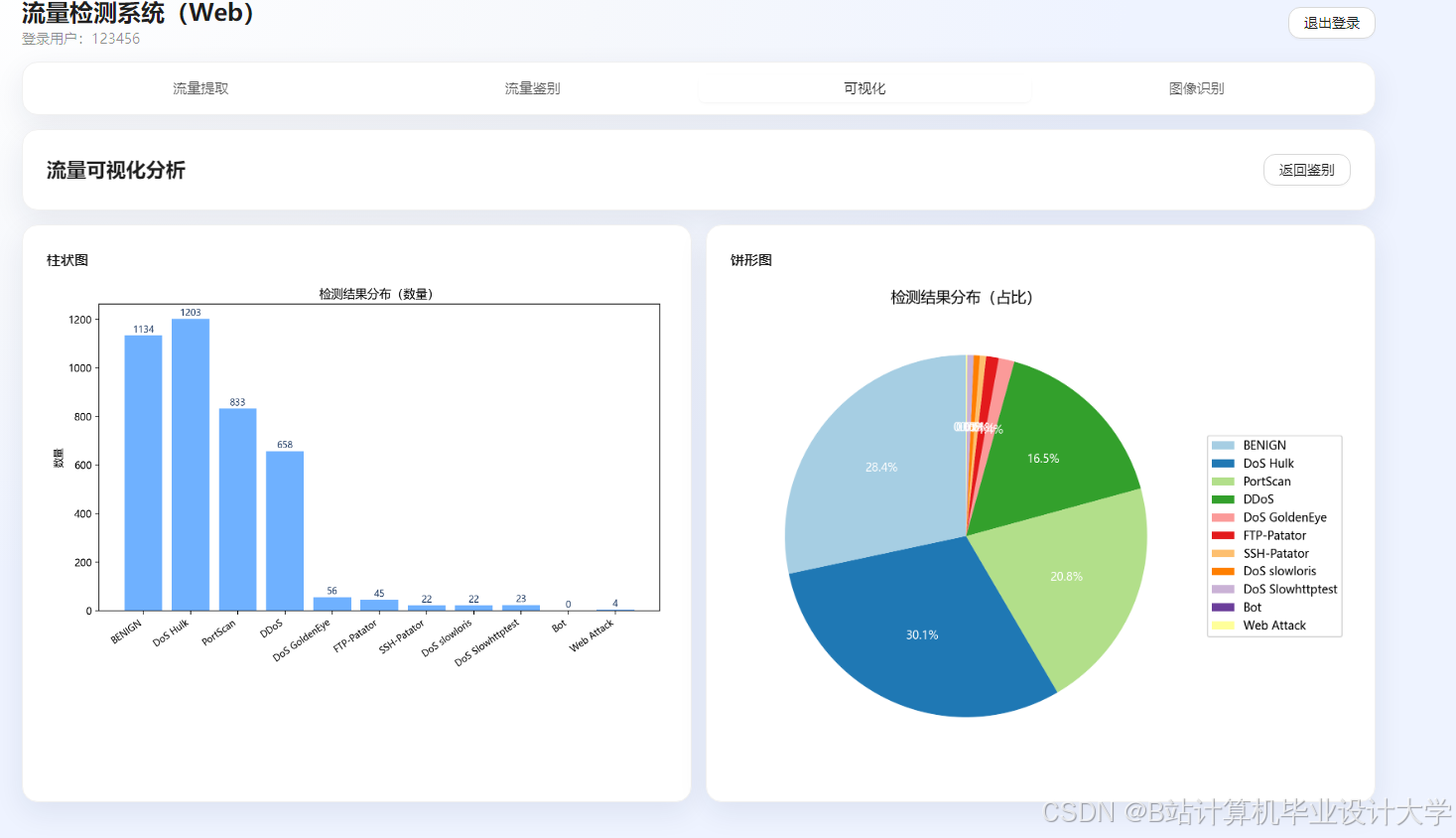
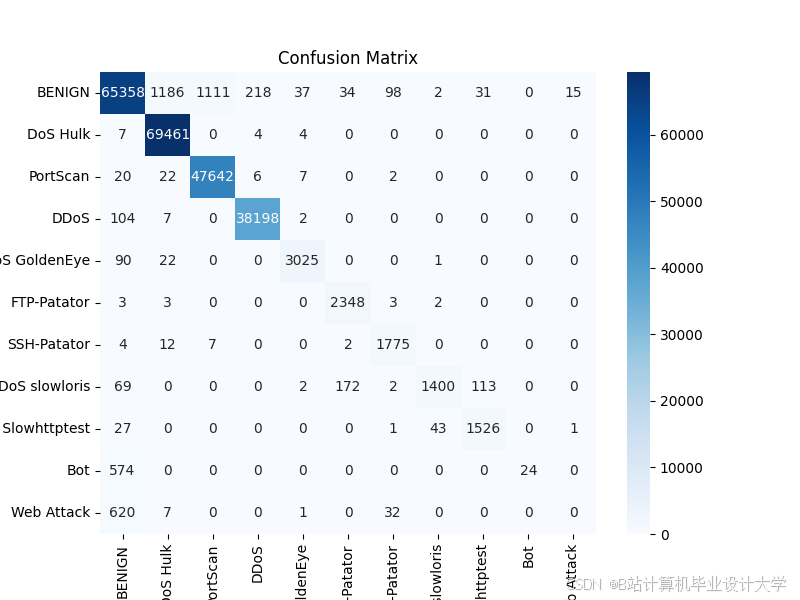
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献282条内容
已为社区贡献282条内容

所有评论(0)