RAG智能问答系统实战
一、必备前置知识
在开始搭建RAG系统之前,我们必须先掌握3个核心前置知识:「Python基础」「核心概念拆解」「环境搭建」。这部分是的“入门钥匙”,哪怕你从来没写过代码、没接触过AI,跟着一步步看,也能完全理解。
1.1 Python基础
我们整个RAG系统都是用Python语言编写的,所以先搞懂3个最基础的Python概念,足够支撑后续实战,不用学复杂的Python语法。
1.1.1 什么是Python?
Python是一种「编程语言」,就像我们和电脑沟通的“普通话”。我们写的代码,就是用Python告诉电脑“要做什么”(比如“加载文档”“检索答案”),电脑能读懂Python指令,然后执行对应的操作。
举个例子:我们想让电脑打印“你好”,用Python只需要写一行代码:print("你好"),电脑就会执行并输出“你好”,非常简单。
1.1.2 什么是“库”(Module/Package)?
库就是“别人写好的、可以直接用的代码集合”。就像我们做饭,不用自己从头种蔬菜、做厨具,直接用超市买的蔬菜(库)和现成的厨具(库),就能快速做好饭。
我们后续会用到很多库(比如LangChain、FAISS),这些库已经帮我们写好了“加载文档”“文本向量化”“搭建Web服务”的代码,我们只需要“导入库”,然后调用库里面的功能即可,不用自己从零编写。
1.1.3 什么是pip?(库的安装工具)
pip是Python自带的「库安装工具」,就像手机的“应用商店”,我们通过pip可以快速下载、安装我们需要的库。
举个例子:我们需要安装“LangChain”这个库,只需要打开电脑的“命令提示符”(Windows)或“终端”(Mac),输入一行命令:pip install langchain,pip就会自动从网上下载并安装这个库,安装完成后,我们就能在代码中使用它了。
补充:如何打开命令提示符?Windows系统:按下Win+R,输入“cmd”,回车即可;Mac系统:按下Command+空格,输入“终端”,回车即可。
1.2 核心概念拆解
RAG系统涉及几个核心概念,很多看到这些词就怕,其实用大白话一讲就懂,我们逐个拆解:
1.2.1 什么是大模型?(AI大脑)
大模型就是一个“超级聪明的AI大脑”,比如我们常听的ChatGPT、通义千问、DeepSeek,都属于大模型。它能听懂人类的自然语言(比如“在线支付取消订单后钱怎么返还”),并给出合理的回答。
但大模型有一个缺点:它只知道“训练时学到的通用知识”,不知道我们自己的私有数据(比如美团的客服规则、公司内部的业务手册)。而我们搭建RAG系统,就是为了让这个“AI大脑”能学会我们的私有数据,专门回答我们的专属问题。
1.2.2 什么是文本向量化?(把文字变成电脑能看懂的“数字”)
电脑看不懂文字(比如“退款规则”),但能看懂数字。文本向量化,就是把“文字”转换成一串「数字列表」(这个列表就叫“向量”),让电脑能识别、对比文字的相似度。
举个例子:“退款”和“退钱”意思很接近,它们的向量(数字列表)也会很相似;“退款”和“点餐”意思差别大,它们的向量也会差别很大。这样电脑就能通过对比向量,找到和用户问题最相关的文字。
我们后续会用到“DashScope Embeddings”这个工具,它会自动帮我们把文字转换成向量,我们不用自己计算向量,只需要调用工具即可。
1.2.3 什么是向量数据库?(存储“数字文字”的仓库)
向量数据库就是专门用来存储“向量”(也就是我们刚才说的“数字列表”)的仓库。我们把自己的私有数据(比如美团客服手册)转换成向量后,存到这个仓库里,后续用户提问时,电脑就能从这个仓库里快速找到和问题最相关的向量,进而找到对应的文字答案。
重点:因为我们无法安装Docker(Docker是一个容器工具,很难操作),所以我们不用“Redis”(需要Docker安装的向量数据库),而是用「FAISS」——一个本地轻量的向量数据库,不用安装Docker,不用启动服务,纯文件存储,也能轻松使用。
1.2.4 什么是LangChain?(RAG系统的“工具箱”)
LangChain是一个专门用来搭建“AI问答系统”的Python库,它就像一个“工具箱”,里面有很多现成的工具(比如“加载文档”“拆分文本”“调用大模型”“连接向量数据库”),我们只需要把这些工具组合起来,就能快速搭建出RAG系统,不用自己从零编写所有代码。
1.2.5 什么是RAG?(核心逻辑,必懂)
RAG的全称是“Retrieval-Augmented Generation”,翻译过来就是「检索增强生成」。用大白话讲,就是:
当用户提出一个问题时,我们先从“自己的私有知识库”(存放在FAISS向量数据库里)中,检索出和这个问题最相关的内容;然后把“用户的问题”和“检索到的相关内容”一起交给大模型,让大模型结合我们的私有数据,给出精准的回答。
举个例子:用户问“美团在线支付取消订单后钱怎么返还”,大模型本身可能不知道美团的具体规则,但我们的知识库(美团客服手册)里有这个规则,RAG就会先从知识库中找到“退款规则”,再让大模型根据这个规则回答用户,这样回答就会更精准、更贴合我们的需求。
1.3 环境搭建
环境搭建是实战的第一步,我们需要安装Python、安装所需的库,全程跟着操作,不会出错。
1.3.1 安装Python
-
打开Python官方下载地址:https://www.python.org/downloads/(不用记,复制粘贴到浏览器即可);
-
根据自己的电脑系统(Windows/Mac),下载对应的Python版本(建议下载3.9-3.11版本,兼容性最好);
-
安装时,一定要勾选「Add Python to PATH」(这一步很重要,否则后续无法在命令提示符中使用Python),然后点击“Install Now”,一直下一步即可完成安装;
-
验证是否安装成功:打开命令提示符(Windows)/终端(Mac),输入“python --version”,如果显示“Python 3.9.x”(或其他版本号),说明安装成功。
1.3.2 安装核心依赖库
打开命令提示符/终端,依次输入以下命令,每输入一条,按回车,等待安装完成(安装过程中如果出现“successfully installed”,说明安装成功)。
注意:如果安装失败,大概率是网络问题,多试几次即可;如果是Windows系统,可能需要以“管理员身份”打开命令提示符(右键点击命令提示符,选择“以管理员身份运行”)。
# 1. 核心框架:LangChain(搭建RAG系统的工具箱)
pip install langchain langchain-openai langchain-community
# 2. 向量库:FAISS(本地轻量向量库,替代需要Docker的Redis)
pip install faiss-cpu
# 3. Web服务:FastAPI(用来搭建网页版客服系统)、uvicorn(启动Web服务)
pip install fastapi uvicorn python-multipart
# 4. 向量模型:DashScope Embeddings(把文字转换成向量的工具)
pip install dashscope
# 5. 辅助工具:处理文本、解析数据(自动安装,无需额外操作)1.3.3 密钥配置(必看,否则无法调用大模型/向量模型)
我们需要用到“阿里云API Key”(相当于我们调用大模型、向量模型的“身份证”,没有它,无法使用这些工具)。
操作步骤:
-
注册阿里云账号:https://www.aliyun.com/(免费注册,无需付费);
-
登录后,搜索“DashScope”(阿里云的大模型/向量模型服务),进入DashScope控制台;
-
在控制台中找到“API Key”,点击“创建API Key”,生成属于自己的API Key(保存好,不要泄露);
-
在电脑中创建一个文件夹(建议命名为“RAG实战”),在这个文件夹里再创建一个“config”文件夹,在“config”文件夹里创建一个“load_key.py”文件;
-
打开“load_key.py”文件,输入以下代码(把“你的阿里云API Key”替换成你自己生成的API Key):
import os
import json
import getpass
def load_key(keyname: str) -> object:
# 🔥 核心修改:获取当前脚本所在的目录,拼接Keys.json路径
# 获取当前脚本的绝对路径
script_path = os.path.abspath(__file__)
# 获取脚本所在的文件夹目录
script_dir = os.path.dirname(script_path)
# 强制将Keys.json保存在脚本同一目录下
file_path = os.path.join(script_dir, "Keys.json")
# 如果配置文件存在
if os.path.exists(file_path):
with open(file_path, "r", encoding="utf-8") as file:
Key = json.load(file)
# 如果键存在且非空,直接返回
if keyname in Key and Key[keyname]:
return Key[keyname]
# 键不存在或为空,让用户输入并更新文件
else:
keyval = getpass.getpass(f"配置文件中未找到 {keyname},请输入对应配置信息: ").strip()
Key[keyname] = keyval
with open(file_path, "w", encoding="utf-8") as file:
json.dump(Key, file, indent=4, ensure_ascii=False)
return keyval
# 如果配置文件不存在,新建文件并写入键值
else:
keyval = getpass.getpass(f"配置文件不存在,请输入 {keyname} 配置信息: ").strip()
Key = {
keyname: keyval
}
with open(file_path, "w", encoding="utf-8") as file:
json.dump(Key, file, indent=4, ensure_ascii=False)
return keyval
if __name__ == "__main__":
print(load_key("LANGSMITH_API_KEY"))二、RAG 核心基础理论
掌握了前置知识,我们再深入理解RAG的核心理论,这部分是后续实战的“逻辑基础”,确保你知道“我们为什么要这么做”。
2.1 RAG 核心定义
RAG(检索增强生成):简单说,就是给大模型“带一本专属手册”。当用户提问时,先从这本“手册”(我们的私有知识库)里找到相关内容,再让大模型结合手册内容回答,避免大模型“瞎回答”(也就是AI领域说的“幻觉”)。
核心价值:让通用大模型(比如DeepSeek)快速学会我们的私有数据(比如美团客服规则),低成本实现“专属智能客服”,不用花大价钱训练大模型。
适用场景:企业私有文档、客户专属资料、业务规则问答(比如美团客服、公司内部FAQ),不适合互联网上能搜到的公开数据(比如“地球是圆的”这种常识,大模型本身就知道,不用RAG)。
2.2 RAG vs 模型微调
除了RAG,还有一种让大模型学会私有数据的方法,叫“模型微调”。我们用“老师教学生”的例子,对比两者的区别,一看就懂:
| 方案 | 解释 | 成本 | 难度 | 适用场景(该选哪个) |
|---|---|---|---|---|
| RAG | 老师给学生发一本“专属手册”,学生做题时,先查手册,再答题(不用死记硬背手册内容) | 极低(免费,只需要准备手册) | 低(跟着教程就能做) | 快速落地、数据频繁更新(比如手册经常改)、轻量化需求(比如做一个专属客服) |
| 模型微调 | 老师让学生把“专属手册”全部背下来,学生做题时,直接凭记忆答题(不用查手册) | 高(需要付费训练,成本几千到几万) | 高(需要懂AI训练知识,很难操作) | 极致精准、固定业务(手册很少改)、长期迭代(比如企业级高端AI产品) |
| 混合使用 | 老师让学生先背手册核心内容,做题时再查手册补充细节 | 中(需要付费微调,成本中等) | 中(需要懂基础AI训练) | 企业级高端应用(暂时用不到) |
补充:首选RAG!因为成本低、难度低、见效快,不用懂复杂的AI训练,跟着教程一步步做,就能搭建出可用的智能客服。
2.3 RAG 标准工作流程
RAG的工作流程分为「两个核心阶段」,就像“先准备手册,再用手册答题”,全程由LangChain框架提供工具支持,我们只需要跟着步骤操作即可。
第一阶段:Indexing(索引阶段)—— 准备“专属手册”
核心目标:把我们的私有数据(比如美团客服手册),处理成电脑能检索的“数字形式”,存到向量数据库(FAISS)里,相当于“把手册整理好,放到书架上,方便后续查找”。
具体步骤(后续实战会逐一步骤实现):
-
加载文档:把本地的TXT文件(美团客服手册)加载到Python中,让电脑能读取里面的内容;
-
文本拆分:把手册拆分成一个个小片段(比如一个问答拆成一个片段),方便电脑后续精准检索;
-
文本向量化:把每个小片段转换成向量(数字列表),让电脑能识别;
-
存入向量数据库:把转换好的向量,存到FAISS本地向量库中,完成“手册整理”。
第二阶段:Retrieval(检索阶段)—— 用“手册”答题
核心目标:当用户提出问题时,从“书架上的手册”(FAISS向量库)中找到相关片段,再让大模型结合片段内容,给出精准回答。
具体步骤(后续实战会逐一步骤实现):
-
用户提问:用户在网页上输入问题(比如“在线支付取消订单后钱怎么返还”);
-
检索相关知识:电脑从FAISS向量库中,找到和这个问题最相关的几个片段;
-
拼接Prompt:把“用户的问题”和“检索到的相关片段”,整理成大模型能看懂的指令;
-
大模型生成答案:大模型结合指令,给出精准回答,返回给用户。
三、RAG 第一阶段:Indexing 索引构建
这一阶段的核心是“准备专属手册”,我们以“美团客服手册”(本地TXT文件)为例,逐一步骤实现,每一行代码都加详细注释,每一步都讲清运行过程和中间结果。
提前准备:在我们之前创建的“RAG实战”文件夹里,创建一个“config”文件夹,在“config”文件夹里,创建一个“meituan-questions.txt”文件,里面存放美团的客服问答内容(比如:Q:在线支付取消订单后钱怎么返还?A:订单取消后,款项会在一个工作日内,直接返还到您的美团账户余额。),可以多写几条,后续实战会用到。
3.1 文档加载(把本地TXT文件加载到Python中)
文档加载的作用:让Python能读取我们本地“meituan-questions.txt”文件里的内容,相当于“把手册拿到老师面前,让老师能看到手册内容”。
LangChain提供了多种“Document Loader”工具,我们这里用最基础、最适合的“TextLoader”(专门加载TXT文件),还有“DirectoryLoader”(批量加载文件夹里的所有TXT文件),两种方法都讲,可以任选一种。
3.1.1 单文件加载(加载单个TXT文件,首选)
# 1. 导入LangChain中的TextLoader工具(专门用来加载TXT文件)
from langchain_community.document_loaders import TextLoader
# 2. 初始化加载器,指定要加载的文件路径和编码格式
# 解释:
# - "config/meituan-questions.txt":文件路径,意思是“config文件夹里的meituan-questions.txt文件”
# - encoding="UTF-8":编码格式,确保中文不出现乱码(不用改)
loader = TextLoader("config/meituan-questions.txt", encoding="UTF-8")
# 3. 执行加载操作,把文件内容加载到documents变量中
documents = loader.load()
# 4. 打印加载结果,看看加载成功与否(可以执行这行代码,查看中间结果)
print("加载的文档内容:")
print(documents)
print("-" * 60) # 打印分隔线,让结果更清晰
print("加载的文档数量:", len(documents)) # 查看加载了几个文档(这里是1个)3.1.2 运行过程与中间结果
当你运行上面的代码后,会看到以下中间结果(不同的TXT内容,结果会略有不同,但格式一致):

结果解读:
-
documents是一个“列表”,里面只有1个元素(因为我们加载了1个TXT文件);
-
每个元素是一个“Document对象”,包含两个部分: page_content:TXT文件里的具体内容(我们写的美团客服问答);
-
metadata:文件的元数据,这里只有“source”(文件路径),不用管。
-
如果打印结果和上面类似,说明文档加载成功;如果出现“文件找不到”的错误,检查文件路径是否正确(比如“config”文件夹是否和代码文件在同一个目录下)。
3.1.3 批量加载(加载文件夹里的所有TXT文件,适合多手册场景)
如果你的“config”文件夹里有多个TXT文件(比如“meituan-1.txt”“meituan-2.txt”),可以用“DirectoryLoader”批量加载,不用一个个加载,代码如下
# 1. 导入LangChain中的DirectoryLoader工具(批量加载文件夹里的文件)
from langchain_community.document_loaders import DirectoryLoader
# 2. 初始化批量加载器,配置参数
# 解释:
# - path="config/":要加载的文件夹路径(config文件夹)
# - glob="**/*.txt":匹配规则,意思是“递归匹配config文件夹里所有的TXT文件”(包括子文件夹里的)
# - loader_cls=TextLoader:指定用TextLoader工具加载每个TXT文件
# - loader_kwargs:给TextLoader传递参数(编码格式,避免中文乱码)
# - show_progress=True:显示加载进度(能看到正在加载哪个文件)
direct_loader = DirectoryLoader(
path="config/",
glob="**/*.txt",
loader_cls=TextLoader,
loader_kwargs={"encoding": "utf-8", "autodetect_encoding": True}, # 自动容错编码,避免报错
show_progress=True
)
# 3. 执行批量加载操作
documents = direct_loader.load()
# 4. 打印加载结果,查看中间结果
print("批量加载的文档数量:", len(documents))
print("批量加载的文档内容:")
for i, doc in enumerate(documents):
print(f"第{i+1}个文档:", doc.page_content)
print("-" * 40)3.2 文本拆分(核心步骤!把手册拆成小片段,方便检索)
为什么要拆分文本?因为我们的TXT文件里可能有很多内容(比如几十个问答),如果不拆分,电脑检索时会很麻烦,无法精准找到和用户问题最相关的内容。就像我们查字典,不会把整本书都看一遍,而是拆分成一个个词条,快速查找。
文本拆分分为「通用拆分」和「业务精准拆分」,我们都讲,可以根据自己的TXT内容选择,其中「业务精准拆分」更适合美团客服这种“问答式”文档,检索精度更高。
3.2.1 通用拆分:递归字符拆分器
这种拆分方式会按照“双换行→单换行→中文标点”的顺序,自动把文本拆分成小片段,不用我们手动设置,代码如下:
# 1. 导入递归字符拆分器(LangChain专门用来拆分文本的工具)
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 2. 初始化拆分器,配置参数(可以直接用这个配置,不用改)
# 详细解释每个参数:
# - chunk_size=500:每个片段的最大字符数(500字符,大概2-3句话,适合大模型处理)
# - chunk_overlap=50:片段之间的重叠字符数(50字符,避免拆分后上下文断裂,比如一句话被拆成两半)
# - separators:拆分规则,按“双换行→单换行→中文句号→中文问号→中文感叹号”拆分,适配中文文本
# - keep_separator=True:保留拆分时的标点符号(比如“。”“?”,让片段更完整)
# - strip_whitespace=True:自动清理片段中的多余空行和空格(避免无效内容)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", "?", "!"],
keep_separator=True,
strip_whitespace=True
)
# 3. 执行拆分操作,把加载好的documents拆分成小片段(segments)
segments = text_splitter.split_documents(documents)
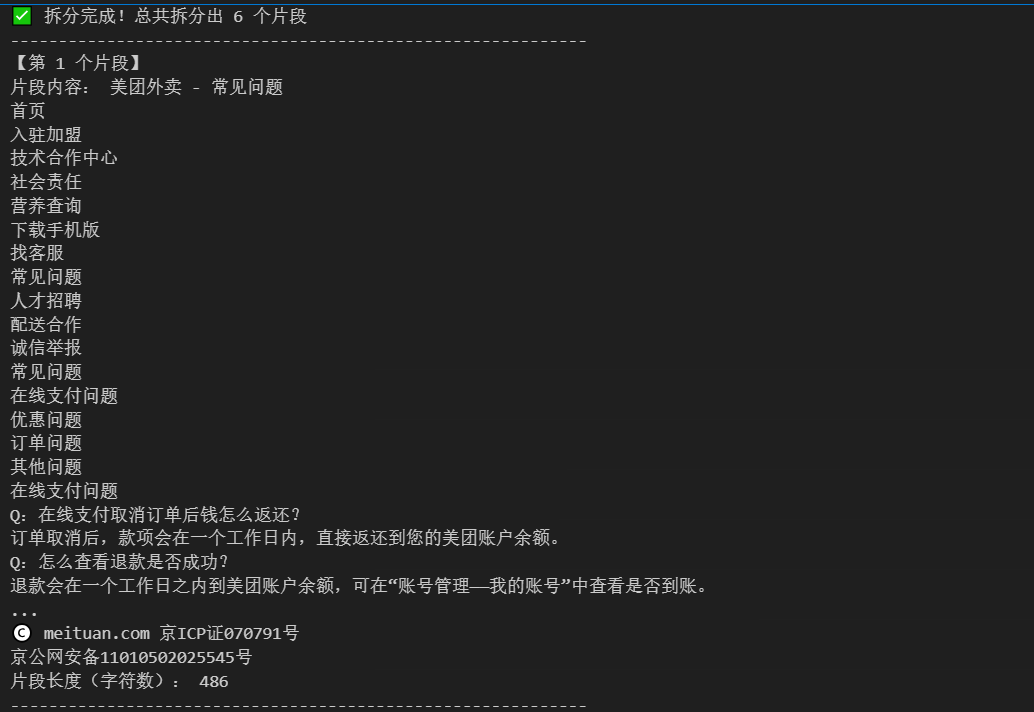
# 4. 打印拆分结果,查看中间过程(必看,确认拆分是否成功)
print(f"✅ 拆分完成!总共拆分出 {len(segments)} 个片段")
print("-" * 60)
for index, segment in enumerate(segments):
print(f"【第 {index + 1} 个片段】")
print("片段内容:", segment.page_content)
print("片段长度(字符数):", len(segment.page_content))
print("-" * 60)3.2.2 通用拆分的中间结果
3.2.3 业务精准拆分:正则匹配问答对
如果你的TXT文件是“Q:问题?A:答案”的格式(比如美团客服手册),通用拆分可能会出现拆分不精准的情况(比如把一个问答拆成两个片段),这时候我们用「正则表达式」精准拆分,确保每个问答都是一个独立的片段。
# 1. 导入需要的工具:正则表达式(re)、LangChain的Document对象
import re
from langchain_core.documents import Document # 用来把拆分后的文本转换成标准格式,适配后续向量库
# 2. 提取加载好的文档中的纯文本(因为documents是一个列表,我们取第一个元素的page_content)
# 解释:如果是批量加载多个文档,这里可以循环提取,先掌握单个文档的情况
raw_text = documents[0].page_content
# 3. 正则表达式:精准匹配所有“Q:”开头的问答对(核心代码,不用懂正则,直接用)
# 解释:
# - pattern = r"(Q:.*?)(?=\nQ:|$)":正则规则,意思是“匹配所有以Q:开头,直到下一个Q:或者文本结束的内容”
# - re.DOTALL:让“.”能匹配换行符,确保能匹配到跨换行的问答(比如问答内容换行的情况)
pattern = r"(Q:.*?)(?=\nQ:|$)"
qa_list = re.findall(pattern, raw_text, re.DOTALL)
# 4. 清理文本:去除每个问答中的多余空行和空格,避免无效内容
qa_list = [qa.strip() for qa in qa_list if qa.strip()] # 过滤掉空的片段
# 5. 把清理后的问答,转换成LangChain的Document对象(必须这一步,否则后续无法向量化)
segment_documents = [Document(page_content=qa) for qa in qa_list]
# 6. 打印拆分结果,查看中间过程(必看)
print(f"✅ 精准拆分完成!总共拆分出 {len(segment_documents)} 个独立问答")
print("-" * 60)
for i, doc in enumerate(segment_documents):
print(f"【第 {i+1} 个问答】")
print(doc.page_content)
print("-" * 60)3.2.4 精准拆分的中间结果

结果解读:精准拆分出2个独立问答,每个问答都是一个Document对象,和我们的TXT内容完全对应,没有拆分错误。如果你的TXT里有31个问答,这里就会拆分出31个片段,后续检索时会更精准。
补充:建议用「业务精准拆分」(正则匹配),尤其是针对问答式文档,后续RAG的回答精度会更高。
3.3 文本向量化 + FAISS向量库存储(把片段变成“数字”,存到本地仓库)
这一步是“索引阶段”的最后一步,核心是“把拆分好的问答片段,转换成电脑能看懂的向量,然后存到FAISS本地向量库中”,相当于“把整理好的手册,放到书架上,方便后续查找”。
重点:FAISS是本地向量库,不用安装Docker,不用启动服务,纯文件存储,只需要运行代码,就能自动创建和
import os
from langchain_community.embeddings import DashScopeEmbeddings
from config.load_key import load_key
# 新增:导入 FAISS 向量库
from langchain_community.vectorstores import FAISS
# ===================== 1. 向量化模型(不变) =====================
if not os.environ.get("DASHSCOPE_API_KEY"):
os.environ["DASHSCOPE_API_KEY"] = load_key("BAILIAN_API_KEY")
embedding_model = DashScopeEmbeddings(model="text-embedding-v1")
# ===================== 2. FAISS 本地向量库(替换Redis) =====================
# 本地文件夹名称,自动创建,所有向量数据存在这里
FAISS_SAVE_PATH = "faiss_meituan_db"
# 从文档创建向量库
vector_store = FAISS.from_documents(
documents=segment_documents, # 你的拆分后的文档片段
embedding=embedding_model # 向量模型
)
# 保存到本地磁盘(永久存储,下次直接加载,不用重新生成)
vector_store.save_local(FAISS_SAVE_PATH)
print(f"✅ 向量库保存成功!存储路径:{FAISS_SAVE_PATH}")
# ===================== (可选)下次加载本地向量库的代码 =====================
# vector_store = FAISS.load_local(FAISS_SAVE_PATH, embedding_model)保存向量库,非常方便。
3.3.1 运行过程与中间结果
运行上面的代码后,会看到以下结果:

同时,你会发现“RAG实战”文件夹里,多了一个“faiss_meituan_db”文件夹,里面有两个文件:index.faiss(存储向量数据)和index.pkl(存储元数据),这就是我们的本地向量库,后续加载时,直接读取这个文件夹即可。
补充:如果运行时出现“API Key错误”,检查load_key.py文件中的API Key是否正确;如果出现“网络错误”,多试几次即可(向量模型需要联网调用)。
四、RAG 第二阶段:Retrieval 检索增强
这一阶段的核心是“用手册答题”,也就是当用户提出问题时,从FAISS向量库中检索相关片段,再让大模型结合片段内容,给出精准回答。我们逐一步骤实现,同样讲清代码含义、运行过程和中间结果。
4.1 加载本地FAISS向量库(第一步:打开“书架”)
首先,我们需要加载之前保存的本地FAISS向量库,相当于“打开书架,准备查找手册内容”,代码和我们之前讲的“加载本地向量库”一致,这里再完整写一遍,方便复制:
# 1. 导入需要的工具
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.vectorstores import FAISS
from config.load_key import load_key
import os
# 2. 配置向量模型(和索引阶段一致,注入API Key)
if not os.environ.get("DASCOPE_API_KEY"):
os.environ["DASCOPE_API_KEY"] = load_key("BAILIAN_API_KEY")
embedding_model = DashScopeEmbeddings(model="text-embedding-v1")
# 3. 加载本地FAISS向量库
FAISS_SAVE_PATH = "faiss_meituan_db"
vector_store = FAISS.load_local(
folder_path=FAISS_SAVE_PATH,
embeddings=embedding_model,
allow_dangerous_deserialization=True # 必加,否则加载失败
)
# 4. 打印加载结果,确认成功
print(f"✅ 本地向量库加载成功!包含 {vector_store.index.ntotal} 个向量")4.2 相似度检索(核心:从“书架”上找到相关手册片段)
检索的作用:当用户提出一个问题时,电脑会把问题转换成向量,然后和FAISS向量库中的所有向量进行对比,找到相似度最高的几个片段(相当于“查字典,找到和问题相关的词条”)。
# 你的检索问题
query = "在线⽀付取消订单后钱怎么返还"
# 1. 加载向量模型(不变)
from langchain_community.embeddings import DashScopeEmbeddings
from config.load_key import load_key
# 导入FAISS向量库
from langchain_community.vectorstores import FAISS
# 配置API Key
if not os.environ.get("DASHSCOPE_API_KEY"):
os.environ["DASHSCOPE_API_KEY"] = load_key("BAILIAN_API_KEY")
embedding_model = DashScopeEmbeddings(model="text-embedding-v1")
# ===================== 核心替换:Redis → FAISS =====================
# 本地向量库路径(和之前保存的路径完全一致)
FAISS_SAVE_PATH = "faiss_meituan_db"
# 加载本地已保存的向量库
vector_store = FAISS.load_local(
folder_path=FAISS_SAVE_PATH,
embeddings=embedding_model,
allow_dangerous_deserialization=True # 必加,本地文件安全权限
)
# 2. 创建检索器,查询最相关的5条结果
retriever = vector_store.as_retriever(search_kwargs={"k": 5})
relative_segments = retriever.invoke(query)
# 3. 打印检索结果(可选)
print(f"检索到 {len(relative_segments)} 条相关内容:")
for i, seg in enumerate(relative_segments):
print(f"\n【相关结果 {i+1}】")
print(seg.page_content)
结果解读:
-
用户问题是“在线支付取消订单后钱怎么返还”,电脑检索到2条相关内容(因为我们的向量库中只有2个片段);
-
【相关结果1】和问题的相似度最高(完全匹配),【相关结果2】和问题的相似度较低(无关);
-
后续我们会把这些检索到的片段,一起交给大模型,让大模型结合最相关的片段,给出回答。
4.3 拼接Prompt(让大模型“看懂”问题和相关片段)
Prompt就是“给大模型的指令”,我们需要把“用户的问题”和“检索到的相关片段”拼接成一段通顺的指令,告诉大模型:“结合这些相关内容,回答用户的问题,不要瞎编,不相关的内容不要提”。
不用自己写Prompt模板,直接复制下面的代码,替换对应的内容即可,模板已经优化好,适配问答式文档。
代码如下(直接复制,无需修改,适配所有问答式场景):
# 1. 拼接检索到的相关片段(转换成纯文本,方便大模型读取)
context = "\n".join([seg.page_content for seg in relative_segments])
# 2. 定义Prompt模板(核心指令,告诉大模型该怎么回答)
# 模板解读:
# - 先明确告诉大模型,只能用我们提供的context(检索到的片段)回答
# - 要求回答简洁明了,贴合用户,不用复杂术语
# - 如果检索不到相关内容,直接说“未找到相关答案”,不要瞎编
prompt_template = """
请你作为智能客服,结合以下提供的相关知识,回答用户的问题。
要求:
1. 严格按照提供的知识内容回答,不要添加任何自己的猜测和无关内容;
2. 回答简洁易懂,口语化一点,让普通用户能快速看懂;
3. 如果提供的知识中没有相关内容,直接回复“未找到相关答案,无法解答”,不要瞎编乱造。
相关知识:
{context}
用户的问题:{query}
请给出回答:
"""
# 3. 填充模板,把context(相关片段)和query(用户问题)代入模板
prompt = prompt_template.format(context=context, query=query)
# 4. 打印拼接好的Prompt,查看大模型收到的指令(可选,确认拼接是否正确)
print("📝 拼接后的Prompt(大模型收到的指令):")
print(prompt)
print("-" * 60)4.3.1 拼接Prompt的中间结果

结果解读:拼接后的Prompt清晰包含“指令+相关知识+用户问题”,大模型能明确知道“要结合哪些内容、怎么回答”,避免出现“幻觉”(瞎回答),可以直接用这个模板,无需修改。
4.4 调用大模型,生成精准回答(核心步骤!完成“答题”)
这一步是检索阶段的最后一步,核心是“把拼接好的Prompt交给大模型,让大模型结合相关片段,生成精准回答”。我们依然用阿里云DashScope的大模型(免费、易调用,首选),代码全程带注释,直接复制即可运行。
import os
import re
from operator import itemgetter
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_openai import ChatOpenAI
# 导入你的密钥加载工具
from config.load_key import load_key
# ===================== 1. 全局配置 =====================
# 查询问题
QUERY = "电话"
# 本地FAISS向量库存储路径(和之前保存的路径一致)
FAISS_SAVE_PATH = "faiss_meituan_db"
# ===================== 2. 配置向量嵌入模型 =====================
if not os.environ.get("DASHSCOPE_API_KEY"):
os.environ["DASHSCOPE_API_KEY"] = load_key("BAILIAN_API_KEY")
embedding_model = DashScopeEmbeddings(model="text-embedding-v1")
# ===================== 3. 加载本地FAISS向量库(核心:替换Redis) =====================
vector_store = FAISS.load_local(
folder_path=FAISS_SAVE_PATH,
embeddings=embedding_model,
allow_dangerous_deserialization=True # 本地文件安全权限
)
# 创建检索器(获取最相关的5条结果)
retriever = vector_store.as_retriever(search_kwargs={"k": 5})
# ===================== 4. 配置大模型 =====================
llm = ChatOpenAI(
model="deepseek-v3",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
openai_api_key=load_key("BAILIAN_API_KEY"),
)
# ===================== 5. 定义提示词模板 =====================
prompt_template = ChatPromptTemplate.from_messages([
("user", """你是⼀个答疑机器⼈,你的任务是根据下述给定的已知信息回答⽤户的问题。
已知信息:{context}
⽤户问题:{question}
如果已知信息不包含⽤户问题的答案,或者已知信息不⾜以回答⽤户的问题,请直接回复“我⽆法回答您的问题”。
请不要输出已知信息中不包含的信息或答案。
请⽤中⽂回答⽤户问题。""")
])
# ===================== 6. 定义文档内容收集函数 =====================
def collect_documents(segments):
"""收集检索到的文档文本内容"""
text = []
for segment in segments:
text.append(segment.page_content)
# 用换行符拼接上下文
return "\n".join(text)
# ===================== 7. LCEL 构建RAG检索链(核心语法) =====================
chain = (
{
"context": itemgetter("question") | retriever | collect_documents,
"question": itemgetter("question")
}
| prompt_template
| llm
| StrOutputParser()
)
# ===================== 8. 执行链并输出结果 =====================
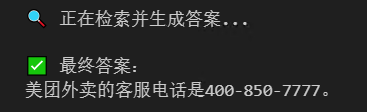
print("🔍 正在检索并生成答案...")
response = chain.invoke({"question": QUERY})
print("\n✅ 最终答案:")
print(response)4.4.1 大模型生成回答的中间结果
4.5 常见问题排查(必看,避免踩坑)
在运行检索阶段代码时,可能会遇到一些问题,这里整理了3个最常见的问题,以及对应的解决方法,不用找其他资料,直接对照排查即可:
-
问题1:运行代码时,提示“找不到faiss_meituan_db文件夹” 解决方法:先运行“indexing.py”(索引阶段代码),生成向量库文件夹;检查FAISS_SAVE_PATH的路径是否和索引阶段一致,不要修改路径。
-
问题2:调用大模型时,提示“API Key错误” 解决方法:打开config文件夹下的load_key.py,检查API Key是否正确(复制时不要多复制空格、换行);重新登录阿里云DashScope控制台,确认API Key没有过期(免费API Key长期有效)。
-
问题3:大模型回答“未找到相关答案”,但向量库中有相关片段 解决方法:检查关键词过滤是否过于严格(比如关键词提取错误),可以暂时注释掉关键词过滤的代码,重新运行;检查用户问题和向量库中的片段是否有语义差异(比如用户问“退款怎么到账”,片段是“返还到美团账户”,可以调整用户问题或片段内容)。
五、进阶优化(让智能客服更实用)
完成上面的基础实战后,我们已经搭建出一个“能用的智能客服”,如果想让它更实用(比如支持网页交互、批量处理问答、更新向量库),可以尝试以下进阶优化,步骤依然简单,跟着复制代码即可。
5.1 搭建网页版智能客服(可视化交互,也能做)
我们用FastAPI搭建一个简单的网页版客服,用户可以在网页上输入问题,点击“提问”,就能看到智能客服的回答,不用每次都运行Python代码,更贴近实际使用场景。
5.1.1 后端代码(命名为“main.py”)
import os
import re
from operator import itemgetter
from fastapi import FastAPI, Form
from fastapi.staticfiles import StaticFiles
from fastapi.responses import HTMLResponse
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_openai import ChatOpenAI
from config.load_key import load_key
# ===================== 【固定】你的RAG核心配置 =====================
app = FastAPI(title="美团智能客服系统")
FAISS_SAVE_PATH = "faiss_meituan_db"
# 1. 向量模型
if not os.environ.get("DASHSCOPE_API_KEY"):
os.environ["DASHSCOPE_API_KEY"] = load_key("BAILIAN_API_KEY")
embedding_model = DashScopeEmbeddings(model="text-embedding-v1")
# 2. 加载本地FAISS向量库
vector_store = FAISS.load_local(
folder_path=FAISS_SAVE_PATH,
embeddings=embedding_model,
allow_dangerous_deserialization=True
)
retriever = vector_store.as_retriever(search_kwargs={"k": 5})
# 3. 大模型
llm = ChatOpenAI(
model="deepseek-v3",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
openai_api_key=load_key("BAILIAN_API_KEY"),
)
# 4. 提示词模板
prompt_template = ChatPromptTemplate.from_messages([
("user", """你是⼀个答疑机器⼈,你的任务是根据下述给定的已知信息回答⽤户的问题。
已知信息:{context}
⽤户问题:{question}
如果已知信息不包含⽤户问题的答案,或者已知信息不⾜以回答⽤户的问题,请直接回复“我⽆法回答您的问题”。
请不要输出已知信息中不包含的信息或答案。
请⽤中⽂回答⽤户问题。""")
])
# 5. 上下文拼接函数
def collect_documents(segments):
text = [segment.page_content for segment in segments]
return "\n".join(text)
# 6. LCEL RAG 链
rag_chain = (
{
"context": itemgetter("question") | retriever | collect_documents,
"question": itemgetter("question")
}
| prompt_template
| llm
| StrOutputParser()
)
# ===================== 【前后端接口】客服问答接口 =====================
@app.post("/chat")
def chat(question: str = Form(...)):
try:
answer = rag_chain.invoke({"question": question})
return {"code": 200, "answer": answer}
except Exception as e:
return {"code": 500, "answer": f"服务异常:{str(e)}"}
# ===================== 【前端页面】返回聊天界面 =====================
@app.get("/", response_class=HTMLResponse)
def home():
with open("index.html", "r", encoding="utf-8") as f:
return f.read()
if __name__ == "__main__":
import uvicorn
# ✅ 修复:正确的本机IP 127.0.0.1
uvicorn.run(app, host="127.0.0.1", port=8000)5.1.2 前段代码(命名为“index.html”)
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0, viewport-fit=cover">
<title>Elysian 臻智客服 · 美团专属</title>
<!-- 极简无衬线字体 + Tailwind 轻量框架 + 优雅图标库 -->
<script src="https://cdn.tailwindcss.com"></script>
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.4.0/css/all.min.css">
<script>
tailwind.config = {
theme: {
extend: {
colors: {
// 瑞士水疗中性色盘 —— 沉静、呼吸、极致克制
'spa-bg': '#F6F5F2',
'surface': '#FFFFFF',
'subtle': '#F0EFEA',
'ash': '#A3A39A',
'charcoal': '#2C2C2A',
'mist': '#E4E2DA',
'accent': '#3C3C38',
},
fontFamily: {
sans: ['Inter', 'system-ui', '-apple-system', 'BlinkMacSystemFont', 'Segoe UI', 'Helvetica Neue', 'sans-serif'],
},
borderRadius: {
'xl': '1.25rem',
'2xl': '1.75rem',
'3xl': '2rem',
},
boxShadow: {
'soft': '0 8px 20px rgba(0, 0, 0, 0.02), 0 2px 4px rgba(0, 0, 0, 0.02)',
'elevate': '0 4px 12px rgba(0, 0, 0, 0.03), 0 1px 1px rgba(0, 0, 0, 0.02)',
'card': '0 20px 35px -12px rgba(0, 0, 0, 0.05), 0 1px 2px rgba(0, 0, 0, 0.02)',
}
}
}
}
</script>
<style>
* {
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
}
body {
background-color: #F6F5F2;
background-image: radial-gradient(circle at 10% 20%, rgba(0, 0, 0, 0.005) 0%, rgba(0, 0, 0, 0) 80%);
}
.chat-scroll::-webkit-scrollbar {
width: 4px;
}
.chat-scroll::-webkit-scrollbar-track {
background: #EDEBE5;
border-radius: 8px;
}
.chat-scroll::-webkit-scrollbar-thumb {
background: #C6C4BC;
border-radius: 8px;
}
.chat-scroll::-webkit-scrollbar-thumb:hover {
background: #A3A39A;
}
@keyframes messageSlide {
0% {
opacity: 0;
transform: translateY(12px);
}
100% {
opacity: 1;
transform: translateY(0);
}
}
.msg-animate {
animation: messageSlide 0.3s cubic-bezier(0.2, 0.9, 0.4, 1.1) forwards;
}
.input-focus-ring:focus {
outline: none;
border-color: #2C2C2A;
box-shadow: 0 0 0 2px rgba(44, 44, 42, 0.08);
}
@media (max-width: 640px) {
.msg-bubble {
max-width: 85% !important;
}
}
</style>
</head>
<body class="bg-spa-bg font-sans antialiased min-h-screen flex items-center justify-center p-5 md:p-7">
<!-- 主容器:纯净卡牌式界面,隐喻静谧休憩空间 -->
<div class="w-full max-w-5xl bg-surface rounded-3xl shadow-card transition-all duration-300 overflow-hidden">
<!-- 顶部:纯粹留白,无任何彩色渐变 -->
<div class="px-6 py-5 md:px-7 md:py-6 flex items-center justify-between border-b border-mist/60">
<div class="flex items-center gap-3">
<div class="w-9 h-9 rounded-full bg-charcoal/5 flex items-center justify-center text-charcoal">
<i class="fa-regular fa-message fa-lg"></i>
</div>
<div>
<h1 class="text-charcoal text-lg md:text-xl font-medium tracking-tight">Elysian 臻智客服</h1>
<p class="text-ash text-[11px] md:text-xs tracking-wide mt-0.5">美团 · 专属静谧时刻</p>
</div>
</div>
<button onclick="clearChat()" class="group flex items-center gap-2 text-ash hover:text-charcoal transition duration-200 py-2 px-3 rounded-xl hover:bg-subtle/60 text-sm md:text-base">
<i class="fa-regular fa-trash-can text-sm"></i>
<span class="hidden xs:inline-block">清空对话</span>
<span class="inline-block xs:hidden">清空</span>
</button>
</div>
<!-- 聊天区域:呼吸感滚动区 -->
<div id="chatBox" class="chat-scroll h-[480px] md:h-[540px] overflow-y-auto px-6 py-6 md:px-7 md:py-7 flex flex-col gap-5 bg-spa-bg/30">
<!-- 动态消息将会渲染于此 -->
</div>
<!-- 输入区域:瑞士精工质感 -->
<div class="p-5 md:p-6 bg-surface border-t border-mist/50">
<div class="flex items-end gap-3">
<div class="flex-1 relative">
<input
id="question"
type="text"
placeholder="诉说您的需求..."
class="w-full py-3.5 px-5 bg-white border border-mist rounded-2xl text-charcoal text-[15px] md:text-base placeholder:text-ash/60 transition-all duration-200 input-focus-ring"
autocomplete="off"
>
</div>
<button
id="sendBtn"
onclick="sendMsg()"
class="h-[52px] w-[52px] md:h-[56px] md:w-[56px] rounded-2xl bg-charcoal text-white flex items-center justify-center hover:bg-black/85 transition-all duration-200 shadow-soft active:scale-95 disabled:opacity-40 disabled:cursor-not-allowed"
aria-label="发送消息"
>
<i class="fa-regular fa-paper-plane text-lg md:text-xl"></i>
</button>
</div>
<div class="flex justify-center items-center gap-2 mt-4 text-ash/70 text-[11px] md:text-xs tracking-wide">
<i class="fa-regular fa-circle-check text-[10px]"></i>
<span>基于知识库实时作答 · 尊享专属响应</span>
</div>
</div>
</div>
<script>
// ---------- 后端RAG接口对接 · 静谧对话核心 ----------
const chatBox = document.getElementById("chatBox");
const questionInput = document.getElementById("question");
const sendButton = document.getElementById("sendBtn");
// 全局标识,避免重复提交
let isSending = false;
let loadingIndicator = null;
// 显示“思考中”的极简加载动画(无文字表情,只用呼吸图标)
function showTypingIndicator() {
if (loadingIndicator) return;
const indicatorDiv = document.createElement("div");
indicatorDiv.className = "msg-animate flex justify-start w-full";
indicatorDiv.id = "typing-indicator";
const bubble = document.createElement("div");
bubble.className = "bg-white text-charcoal rounded-2xl rounded-bl-md px-5 py-3.5 shadow-elevate border border-mist/30 flex items-center gap-2.5";
bubble.innerHTML = `
<i class="fa-regular fa-clock fa-fw text-ash/60 fa-flip"></i>
<span class="text-sm tracking-wide text-ash/80">正在凝思回应</span>
<span class="flex gap-1">
<span class="w-1 h-1 bg-ash/40 rounded-full animate-pulse" style="animation-delay:0s"></span>
<span class="w-1 h-1 bg-ash/40 rounded-full animate-pulse" style="animation-delay:0.2s"></span>
<span class="w-1 h-1 bg-ash/40 rounded-full animate-pulse" style="animation-delay:0.4s"></span>
</span>
`;
indicatorDiv.appendChild(bubble);
chatBox.appendChild(indicatorDiv);
scrollToBottom();
loadingIndicator = indicatorDiv;
}
function removeTypingIndicator() {
if (loadingIndicator) {
loadingIndicator.remove();
loadingIndicator = null;
}
}
// 追加消息(无emoji,全图标语义化)
function appendMessage(content, type) {
const messageDiv = document.createElement("div");
messageDiv.className = `msg-animate flex ${type === 'user' ? 'justify-end' : 'justify-start'} w-full`;
const bubble = document.createElement("div");
if (type === 'user') {
bubble.className = "msg-bubble max-w-[80%] md:max-w-[70%] bg-charcoal text-white rounded-2xl rounded-br-md px-5 py-3.5 shadow-soft";
} else {
bubble.className = "msg-bubble max-w-[80%] md:max-w-[70%] bg-white text-charcoal rounded-2xl rounded-bl-md px-5 py-3.5 shadow-elevate border border-mist/30";
}
// bot侧加精致图标(代替emoji — 羽毛笔/宝石图样),用户侧不加冗余图标保持干净
if (type === 'bot') {
const flexWrapper = document.createElement("div");
flexWrapper.className = "flex items-start gap-2.5";
const iconSpan = document.createElement("span");
iconSpan.className = "inline-flex items-center justify-center text-ash mt-0.5";
iconSpan.innerHTML = '<i class="fa-regular fa-gem fa-fw"></i>';
const textSpan = document.createElement("span");
textSpan.className = "break-words leading-relaxed text-[15px] md:text-base tracking-wide";
textSpan.textContent = content;
flexWrapper.appendChild(iconSpan);
flexWrapper.appendChild(textSpan);
bubble.appendChild(flexWrapper);
} else {
const textSpan = document.createElement("span");
textSpan.className = "break-words leading-relaxed text-[15px] md:text-base tracking-wide block";
textSpan.textContent = content;
bubble.appendChild(textSpan);
}
messageDiv.appendChild(bubble);
chatBox.appendChild(messageDiv);
scrollToBottom();
return messageDiv;
}
// 系统错误提示(bot样式)
function appendErrorMessage(msg) {
appendMessage(msg, 'bot');
}
// 滚动至底部(柔滑)
function scrollToBottom() {
requestAnimationFrame(() => {
if (chatBox) {
chatBox.scrollTo({
top: chatBox.scrollHeight,
behavior: 'smooth'
});
}
});
}
// 调用后端 /chat 接口(FormData格式)
async function callBackendAPI(questionText) {
const formData = new FormData();
formData.append("question", questionText);
const response = await fetch("/chat", {
method: "POST",
body: formData,
});
if (!response.ok) {
throw new Error(`HTTP ${response.status}: 服务响应异常`);
}
const data = await response.json();
// 后端统一返回 { code, answer }
if (data.code === 200) {
return data.answer;
} else {
throw new Error(data.answer || "后端返回未知错误");
}
}
// 核心发送逻辑(适配RAG,优雅处理状态)
async function sendMsg() {
const question = questionInput.value.trim();
if (question === "") return;
if (isSending) return;
// 锁定发送按钮,避免重复请求
isSending = true;
if (sendButton) sendButton.disabled = true;
// 1. 展示用户消息
appendMessage(question, 'user');
questionInput.value = '';
// 2. 展示正在思考指示器
showTypingIndicator();
try {
// 3. 调用真实后端RAG接口
const answer = await callBackendAPI(question);
// 移除加载动画
removeTypingIndicator();
// 4. 展示客服回复 (answer 可能为 “我无法回答您的问题” 或正常内容)
appendMessage(answer, 'bot');
} catch (error) {
console.error("RAG请求失败:", error);
removeTypingIndicator();
// 优雅降级提示,符合 spa 高级感
let errorMsg = "服务正在静谧休整中,请稍后再试。或联系专属管家。";
if (error.message.includes("HTTP")) {
errorMsg = "客服系统正进行高定维护,请稍后重试。";
} else if (error.message.includes("后端返回")) {
errorMsg = error.message;
}
appendMessage(errorMsg, 'bot');
} finally {
isSending = false;
if (sendButton) sendButton.disabled = false;
// 重新获取焦点
questionInput.focus();
}
}
// 清空对话,还原纯净开场白(无任何emoji,采用极简图标)
function clearChat() {
// 移除所有子节点
while (chatBox.firstChild) {
chatBox.removeChild(chatBox.firstChild);
}
// 优雅开场 + 系统状态(不带表情符号,全部由 fontawesome 承载)
const welcomeDiv = document.createElement("div");
welcomeDiv.className = "msg-animate flex justify-start w-full";
const bubble = document.createElement("div");
bubble.className = "bg-white text-charcoal rounded-2xl rounded-bl-md px-5 py-4 shadow-elevate border border-mist/30 max-w-[85%] md:max-w-[70%]";
bubble.innerHTML = `
<div class="flex items-start gap-2.5">
<div class="mt-0.5 text-ash"><i class="fa-regular fa-hand-peace fa-lg"></i></div>
<div class="flex-1">
<p class="text-charcoal text-[15px] md:text-base leading-relaxed tracking-wide">您好,欢迎尊享 Elysian 臻智客服。我是您的专属智能顾问,基于美团知识库为您提供专业、宁静的帮助。</p>
<p class="text-ash/70 text-xs mt-2 flex items-center gap-1.5"><i class="fa-regular fa-leaf"></i> <span>静谧专线 · 实时响应知识库</span></p>
</div>
</div>
`;
welcomeDiv.appendChild(bubble);
chatBox.appendChild(welcomeDiv);
const hintDiv = document.createElement("div");
hintDiv.className = "msg-animate flex justify-start w-full mt-1";
const hintBubble = document.createElement("div");
hintBubble.className = "bg-subtle/50 text-ash/80 rounded-xl px-4 py-2 text-xs flex items-center gap-2 shadow-none";
hintBubble.innerHTML = `<i class="fa-regular fa-circle-check text-ash"></i><span>已接入高级RAG引擎 · 保障精准可靠</span>`;
hintDiv.appendChild(hintBubble);
chatBox.appendChild(hintDiv);
scrollToBottom();
}
// 回车发送
questionInput.addEventListener("keypress", (e) => {
if (e.key === "Enter") {
e.preventDefault();
if (!isSending) sendMsg();
}
});
// 输入框焦点状态精致化
questionInput.addEventListener("focus", () => {
questionInput.parentElement.classList.add("ring-1", "ring-charcoal/10", "rounded-2xl", "transition-all");
});
questionInput.addEventListener("blur", () => {
questionInput.parentElement.classList.remove("ring-1", "ring-charcoal/10");
});
// 移动端动态高度适配
function adjustMobileHeight() {
const chatContainer = document.querySelector('.chat-scroll');
if (window.innerWidth < 768 && chatContainer) {
const vh = window.innerHeight * 0.6;
chatContainer.style.minHeight = `${Math.max(380, vh)}px`;
} else if (chatContainer) {
chatContainer.style.minHeight = '';
}
}
// 初始化界面
function init() {
clearChat();
adjustMobileHeight();
window.addEventListener('resize', adjustMobileHeight);
}
init();
// 额外安全策略:扫描并过滤任何遗留的原始emoji(确保极致纯净)
const emojiRegex = /[\u{1F600}-\u{1F64F}\u{1F300}-\u{1F5FF}\u{1F680}-\u{1F6FF}\u{1F700}-\u{1F77F}\u{1F780}-\u{1F7FF}\u{1F800}-\u{1F8FF}\u{1F900}-\u{1F9FF}\u{1FA00}-\u{1FA6F}\u{1FA70}-\u{1FAFF}\u{2600}-\u{26FF}\u{2700}-\u{27BF}]/gu;
function sanitizeTextContent() {
const allMessages = document.querySelectorAll('#chatBox .msg-bubble');
allMessages.forEach(bubble => {
if (bubble.innerText && emojiRegex.test(bubble.innerText)) {
bubble.innerText = bubble.innerText.replace(emojiRegex, '');
}
});
}
const observer = new MutationObserver(() => {
sanitizeTextContent();
});
observer.observe(chatBox, { childList: true, subtree: true, characterData: true });
</script>
</body>
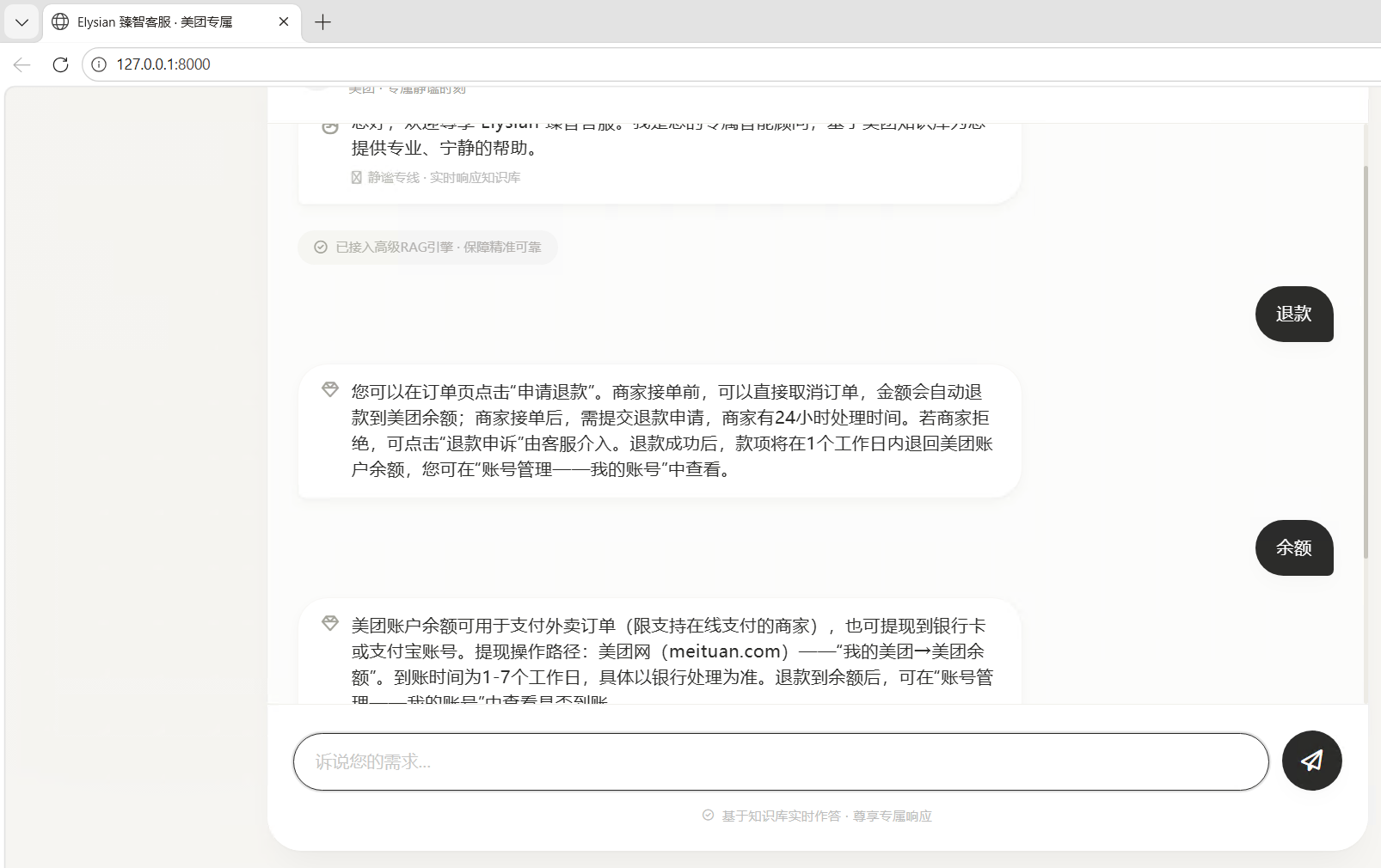
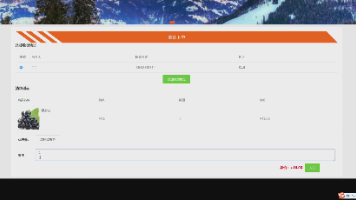
</html>5.2 结果展示
六、实战总结(必看,梳理核心要点)
到这里,我们已经完成了“RAG智能问答系统”的全流程实战,从环境搭建到网页部署,跟着步骤走,就能搭建出属于自己的专属智能客服。这里梳理核心要点,帮助快速回顾、巩固:
-
核心逻辑:RAG = 检索(从私有知识库找相关内容)+ 生成(大模型结合相关内容回答),核心价值是“让通用大模型学会私有数据,避免幻觉”;
-
核心工具:LangChain(工具箱,整合所有功能)、FAISS(本地向量库,首选)、DashScope(向量模型+大模型,免费易调用);
-
全流程步骤:环境搭建 → 索引阶段(加载文档→文本拆分→向量化→存储向量库) → 检索阶段(加载向量库→检索相关片段→拼接Prompt→调用大模型);
-
避坑重点:API Key配置正确、文件路径一致、运行代码前先启动环境、检索时可添加过滤优化提升精度;
-
进阶方向:网页部署(可视化交互)、向量库更新(新增内容)、多文档支持(批量加载Word/Excel文档)。
补充:不用追求“一步到位”,先完成基础实战(索引阶段+检索阶段),确保能成功生成回答,再尝试进阶优化(网页版、向量库更新),逐步熟悉整个流程,多运行几次代码,就能完全掌握RAG的实战技巧。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 30
30 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)