【论文阅读】TwinBrainVLA:通过非对称MoT释放通用VLMs在具身任务中的潜力
·
快速了解部分
基础信息(英文):
- 题目: TwinBrainVLA: Unleashing the Potential of Generalist VLMs for Embodied Tasks via Asymmetric Mixture-of-Transformers
- 时间: 2026.01
- 机构: HIT等
- 3个英文关键词: Vision-Language-Action (VLA), Catastrophic Forgetting, Mixture-of-Transformers (MoT)
1句话通俗总结本文干了什么事情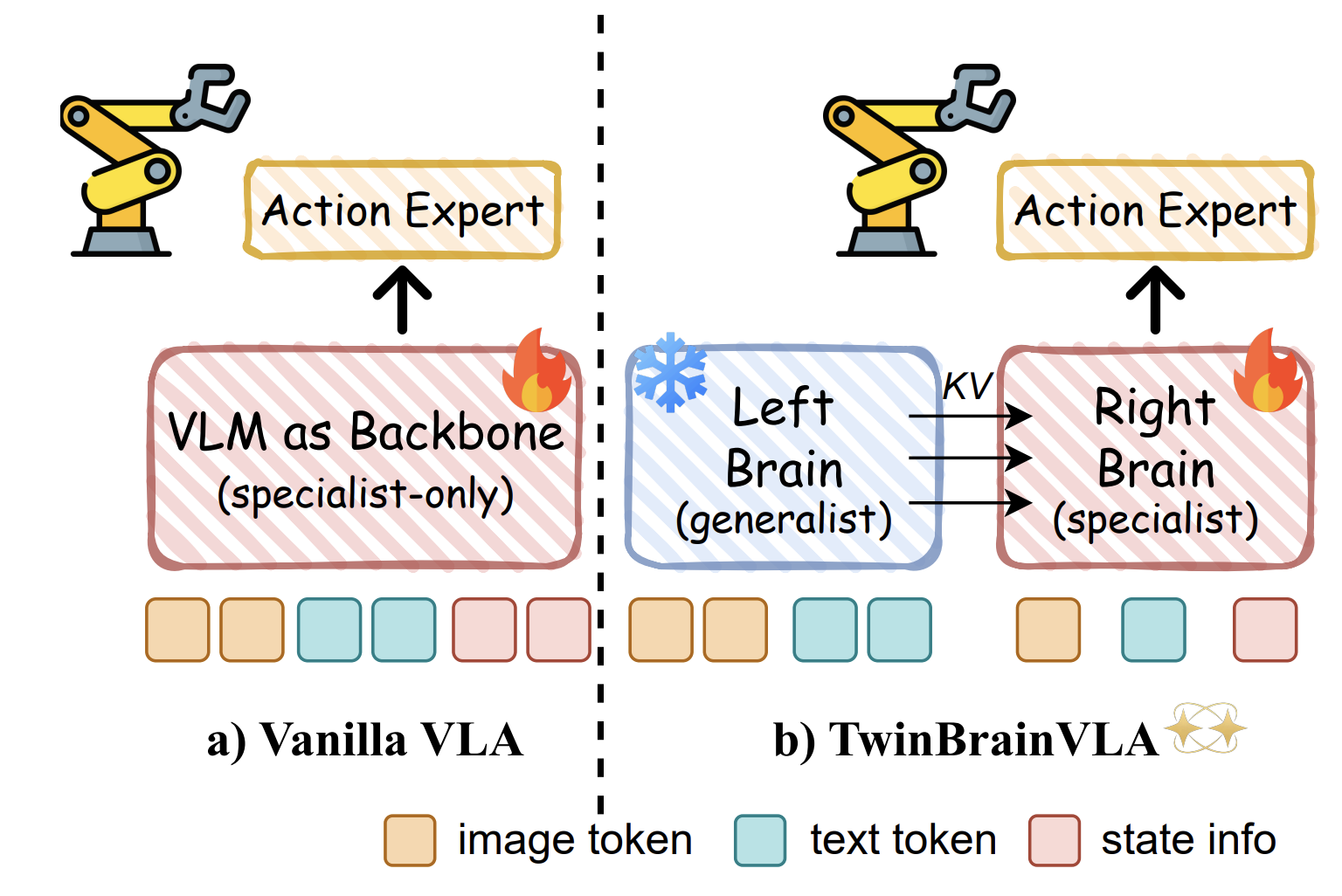
为了解决机器人学动作时把“脑子”学傻了的问题,作者给模型造了两个“脑半球”:一个冻住不动专门负责看和理解(左脑),一个专门负责动手(右脑),让右脑随时向左脑“抄作业”,从而既能动又能懂。
研究痛点:现有研究不足 / 要解决的具体问题
现有的 VLA 模型在针对机器人任务进行微调时,会发生严重的灾难性遗忘。即为了适应机械臂的控制,模型破坏了预训练 VLM 原有的通用视觉理解能力,导致机器人虽然学会了动,但看不懂复杂指令或新物体了。
核心方法:关键技术、模型或研究设计(简要)
提出 TwinBrainVLA 架构,包含两个同构的 VLM 通路:
- 冻结的“左脑”:保持 VLM 的通用能力不变。
- 可训练的“右脑”:结合本体感知状态,专门学习控制。
- AsyMoT 机制:一种非对称的混合 Transformer 机制,允许右脑在每一层动态查询并融合左脑的语义特征。
深入了解部分
作者想要表达什么
作者认为,要让机器人真正智能,不能为了学“动作”而牺牲“理解”。通过结构上的解耦(双脑设计),可以在不破坏预训练知识的前提下,让机器人学会精细操作,实现“用通才的大脑思考,用专家的肢体行动”。
相比前人创新在哪里
- 结构创新:不同于以往试图通过混合数据(Co-Training)来缓解遗忘,本文直接从架构上将“语义理解”与“运动控制”物理隔离。
- 交互机制:提出了 AsyMoT,不同于 Cross-Attention,它允许右脑在自注意力的同时融合左脑信息,且是单向的(右脑查左脑),保证了左脑的纯净性。
解决方法/算法的通俗解释
想象一个刚毕业的医学生(预训练 VLM)。
- 传统方法:让他直接去外科做手术(微调),做着做着,他忘了基础医学理论,变成了只会开刀不懂病理的工匠。
- 本文方法 (TwinBrainVLA):给他配了一个资深老教授(左脑,冻结不动),老教授只负责看书、看片子、讲理论。学生(右脑)在手术台上动手,但每动一刀之前,都随时问老教授:“老师,这个位置是什么神经?”。这样学生既练了手艺,又时刻有理论支撑。
解决方法的具体做法
- 双路并行:初始化两个一样的 VLM。左脑全程参数冻结(Frozen);右脑加入 State Encoder(处理关节角度等),参数可更新。
- AsyMoT 融合:在 Transformer 的每一层,右脑计算自己的 Query,但 Key 和 Value 是由“左脑的特征 + 右脑的特征”拼接而成的。这样右脑的每一次计算都“看”到了左脑的通用知识。
- 动作输出:右脑的输出特征送入一个基于 Flow Matching 的 Action Expert(Diffusion Transformer)来生成连续的动作轨迹。
基于前人的哪些方法
- VLA 范式:延续了将 VLM 扩展为 VLA 的主流路线。
- Flow Matching:使用了类似 π0\pi_0π0 的流匹配技术作为动作生成头。
- Mixture-of-Transformers (MoT):借鉴了 MoT 的多模态交互思想,并改为了非对称形式。
实验设置、数据、评估方式、结论
- 数据:Open X-Embodiment (OXE) 数据集(Bridge-V2, Fractal 等)。
- 基准:SimplerEnv (OOD 测试), RoboCasa (24个桌面任务), LIBERO, 以及 Franka 真机实验。
- 结论:
- 在 SimplerEnv 上,TwinBrainVLA (Qwen3-VL-4B) 平均成功率 64.5%,显著高于 Isaac-GR00T-N1.6 (57.1%) 和 Vanilla VLA。
- 在 RoboCasa 上,平均成功率 54.6%,优于所有 Baseline。
- 真机实验证明其在 OOD(换物体颜色)和长程任务(Pick-All)上泛化性更强。
提到的同类工作
- OpenVLA:开源 VLA 基座。
- π0\pi_0π0 / π0.5\pi_{0.5}π0.5:Google/Physical Intelligence 的流匹配 VLA 模型。
- Isaac-GR00T:NVIDIA 的具身智能模型。
- ChatVLA / VLM2VLA:尝试通过混合数据训练来缓解遗忘的工作。
和本文相关性最高的3个文献
- OpenVLA (Kim et al., 2024):本文主要的强 Baseline 之一,代表了标准的 VLA 微调范式。
- Mixture-of-Transformers (Liang et al., 2025):本文核心交互机制 AsyMoT 的灵感来源。
- π0\pi_0π0 (Black et al., 2024):本文动作生成头(Action Expert)及流匹配技术的主要参考对象。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)