大厂面试必考:RAG 怎么答才能让面试官觉得你“深不可测”?
最近和几个在阿里、美团做大模型应用的朋友聊天,发现现在面试 AI 工程师或者架构师,RAG(检索增强生成) 几乎是必考题。
很多人回答 RAG 流程时,往往只会说:“不就是先检索、后生成吗?” 如果你这么答,面试官大概率会心里暗想:“又是一个看两天文档就来面试的。”
真正落地过生产级 RAG 系统的同学都知道,从“跑通 Demo”到“工业级可用”,中间隔着十个重排序(Rerank)和无数个分块策略(Chunking Strategy)。
今天,我带大家拆解一套满分面试思路,把 RAG 流程讲出“工程深度”。
一、 别只盯着生成,离线索引才是底座
很多同学一聊 RAG 就直接从用户提问开始,其实离线阶段(Indexing)的设计最能体现功底。
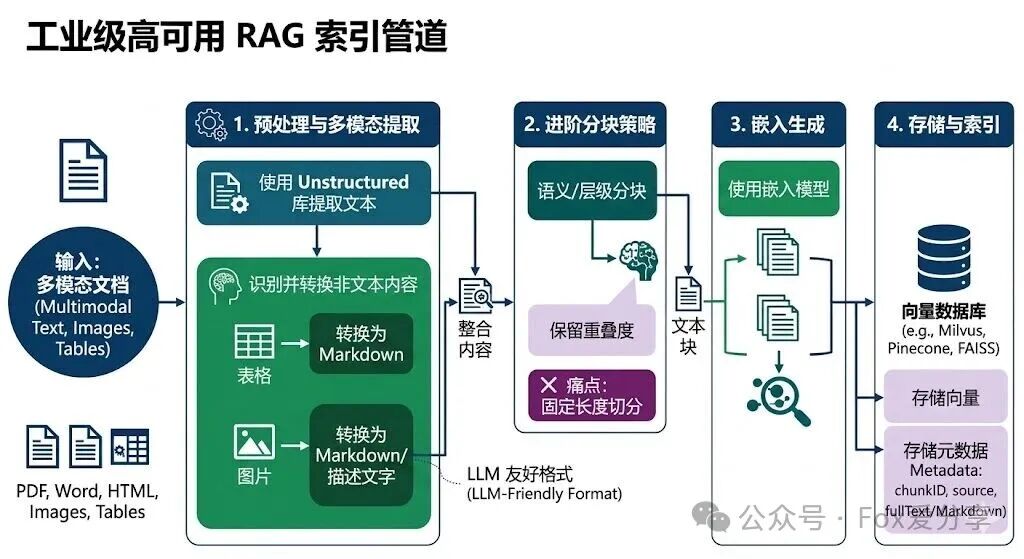
一个高可用的索引管道,绝不是简单的 Document -> Split -> Store:
-
清洗与分块(Chunking):
-
痛点:固定长度切分(比如 512 token)会把一句话拦腰截断。
-
进阶答法:我会根据文档的语义结构进行递归切分,甚至保留一定的 Overlap(重叠度),确保检索时不会丢失上下文。
-
-
多模态索引:
-
如果文档里有大量表格和图片怎么办?这里可以提一下利用
Unstructured库提取表格,或者用 Markdown 格式存储,因为它对 LLM 最友好。
-
二、 在线链路:从“召回”到“重排”的艺术
面试官最喜欢听的是:“你是如何解决检索不准的问题的?”
这时,你需要抛出 RAG 的“黄金四步法”:
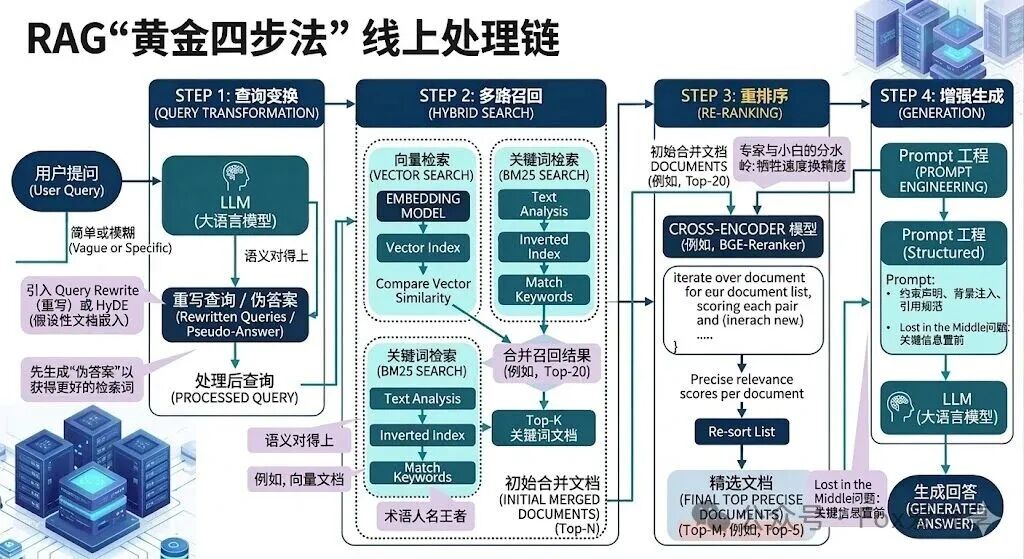
1. 查询变换(Query Transformation)
用户的问题往往很模糊。比如用户问“那那个策略怎么配?”,系统根本搜不到。
-
黑话点:我会引入 Query Rewrite(重写) 或者 HyDE(假设性文档嵌入)。先让大模型根据问题生成一个“伪答案”,再用这个伪答案去搜知识库,效果往往比直接搜问题好得多。
2. 多路召回(Hybrid Search)
-
避坑指南:别迷信向量检索(Vector Search)。
-
架构师观点:在处理特定术语(如产品型号、人名)时,传统的 BM25(关键词检索) 依然是王者。我会采用 向量检索 + 关键词检索 的多路召回模式,确保“既要语义对得上,又要词汇对得上”。
3. 核心杀手锏:重排序(Rerank)
这是区分高手和小白的分水岭。
-
逻辑:初次检索(召回)为了快,通常用向量相似度,但它并不代表逻辑相关。
-
实战做法:我会取召回的 Top-20 个文档,丢给一个 Cross-Encoder 模型(如 BGE-Reranker) 进行二次打分,最后只取最精准的 Top-5 喂给大模型。
三、 提示词工程:别让模型“胡言乱语”
检索到了高质量内容,如果 Prompt 写得烂,模型还是会产生“幻觉”。
一个专业的 RAG Prompt 模板通常包含三部分:

-
约束声明:明确要求“只能根据给定的参考资料回答,不知道就说不知道”。
-
背景注入:将 Rerank 后的精选片段注入。
-
引用规范:要求模型在回答中注明引用了哪篇文档,方便用户回溯。
Fox 提示: 这里的技巧是处理 “Lost in the Middle” 问题。如果参考资料太长,要把最重要的信息放在开头或结尾,模型才不容易忘。
四、 闭环评估:你凭什么说你的 RAG 变强了?
如果面试官问:“你优化了系统,怎么量化评估?”你若答“我觉得效果变好了”,面试就悬了。
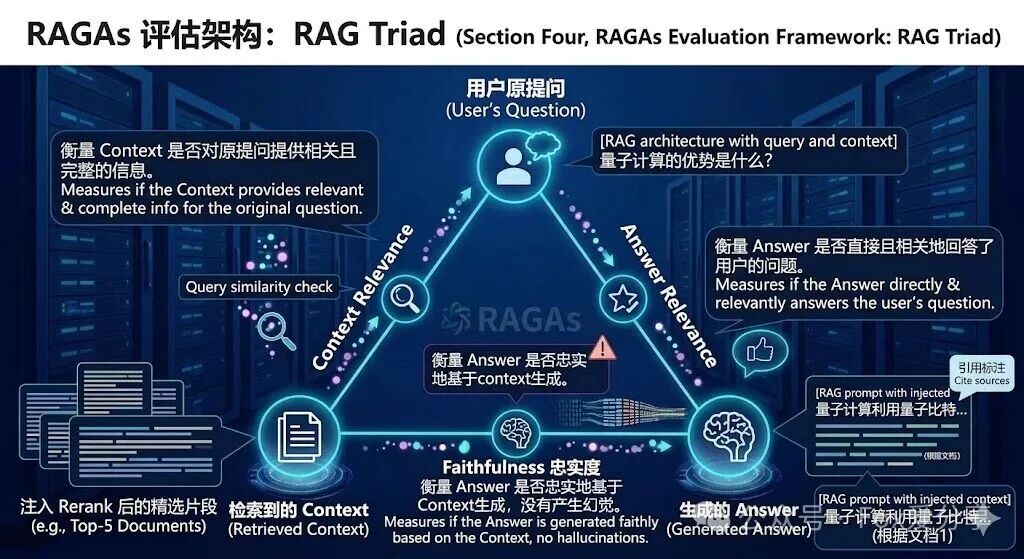
你需要提到 RAGAs 评估框架。它有三个核心指标(RAG Triad):
-
Context Relevance(检索相关性):搜出来的东西对不对?
-
Faithfulness(忠实度):回答是不是根据搜出来的东西写的,有没有瞎编?
-
Answer Relevance(回答相关性):回答是不是用户真正想要的?
五、 RAG 面试核心总结(直接背诵版)
1. 一句话定义(定调子)
“RAG(检索增强生成)本质上是为大模型提供了一个动态更新的外部知识库。它通过‘先检索相关片段,后辅助生成回答’的方式,有效解决了大模型的幻觉问题和知识时效性问题。”
2. 五大核心流程(讲链路)
您可以按照“入、搜、精、产、评”这五个字来组织:
-
离线索引 (Indexing):对文档进行语义分块 (Chunking),通过 Embedding 模型向量化后存入向量数据库(如 Milvus/Pinecone)。
-
查询变换 (Query Transform):对用户模糊的提问进行 Query Rewrite(重写) 或 HyDE(假设性文档),提升检索意图的精准度。
-
多路召回 (Hybrid Search):采用向量检索(语义)+ BM25(关键词)的双路召回,平衡长尾词和语义理解。
-
重排序 (Rerank):【核心高分点】使用 Cross-Encoder 模型对召回的 Top-20 文档进行精排,选出最相关的 Top-5 喂给模型。
-
增强生成 (Generation):将精选片段嵌入 Prompt 模板,并加入“请根据资料回答”的约束,最终由大模型输出答案。
3. 三大优化杀手锏(秀深度)
如果面试官问怎么优化,直接甩出这三点:
-
分块策略:不采用固定长度,而是采用语义分块加 Overlap(重叠),保证上下文不丢失。
-
精排环节:引入 Reranker 模型。召回决定下限,重排决定上限。
-
评估闭环:采用 RAGAs 框架,通过“上下文相关性、忠实度、回答相关性”三个维度(RAG Triad)进行量化评估。
写在最后
RAG 流程不是一条直线,而是一个不断震荡优化的循环。
在面试中,我们要表达的观点是:没有完美的算法,只有最适合业务场景的工程权衡(Trade-off)。 比如:为了追求极速,我们可以牺牲一点 Rerank 的精度;为了处理私有数据,我们可能需要自建 Embedding 模型。
如果你能按这个逻辑答下来,面试官眼中看到的不是一个只会调 API 的码农,而是一个能落地、懂深度、有闭环思维的架构师。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)