2.2 NUMA 与页面迁移:把页面搬到正确的地方
本篇目标:理解 Linux 如何在进程运行过程中把页面从一个 NUMA 节点迁移到另一个 NUMA 节点,同时保持用户虚拟地址不变。我们将从 NUMA 拓扑与内存访问延迟出发,深入
migrate_pages()的核心流程、migration entry 的作用、自动 NUMA balancing 的 hinting fault 机制,并说明这些经典 MM 迁移能力如何为后续 HMM 的 CPU ↔ 设备内存迁移打基础。
1. 承上启下:页表能遍历,页面也能搬家
第 6 篇我们学习了 walk_page_range():内核提供一个通用框架,把“沿着页表树走一遍”这件事抽象出来,让不同子系统通过回调解释每个页表项。
但遍历页表只是“看见页面”。很多场景下,内核还需要移动页面:
- 进程被调度到另一个 NUMA 节点的 CPU 上,原来的内存变成远端访问
- 内存热拔除时,要把即将下线节点上的页面搬走
- 内存规整(compaction)时,要移动页面以腾出连续物理内存
- 内存分层(DRAM/PMEM/CXL)中,要把热页提升到更快的节点
- HMM 中,要把页面在 CPU 内存和设备内存之间迁移
页面迁移的目标很清晰:
虚拟地址不变,物理位置改变。
迁移前:
用户虚拟地址 VA ──PTE──→ Node 1 上的物理页 PFN A
迁移后:
用户虚拟地址 VA ──PTE──→ Node 0 上的新物理页 PFN B
用户程序看到的 VA 不变;内核在背后移动物理内容并更新 PTE。
这件事看起来像“memcpy + 改 PTE”,但真正难点在并发:迁移过程中,其他 CPU 可能正在访问这个页面,文件系统可能正在回写这个页面,GUP 可能 pin 住这个页面,页表里可能有多个进程共享映射它。
所以 Linux 的页面迁移是一套完整协议,而不是简单拷贝。
2. NUMA:内存不是同一种距离
NUMA(Non-Uniform Memory Access)系统中,CPU 和内存被组织成多个节点(node)。每个节点通常有自己的 CPU、内存控制器和本地 DRAM。
双节点 NUMA 系统:
┌─────────────────────┐ ┌─────────────────────┐
│ Node 0 │ │ Node 1 │
│ │ │ │
│ CPU0 CPU1 CPU2... │ │ CPU8 CPU9 CPU10... │
│ │ │ │ │ │
│ Local DRAM │ │ Local DRAM │
└────────┬────────────┘ └────────┬────────────┘
│ │
└────────── Interconnect ────────┘
CPU 访问本地节点内存最快,访问远端节点内存需要经过互连总线,延迟更高、带宽更低。
同一个进程:
线程运行在 Node 0 的 CPU 上
访问 Node 0 内存:local access,低延迟
访问 Node 1 内存:remote access,高延迟
这就是页面迁移的第一动机:把页面搬到经常访问它的 CPU 附近。
2.1 为什么不直接固定在本地节点
理想情况下,页面第一次分配时就应该分配到最合适的节点。但现实并不这么稳定:
- 调度器会移动任务:线程可能从 Node 0 CPU 被调度到 Node 1 CPU
- 负载会变化:不同线程在不同阶段访问不同数据
- 内存策略会变化:
mbind()、cpuset、mempolicy 可能改变允许节点 - 内存压力会变化:本地节点可能不足,需要从其他节点分配
- 共享页面很复杂:多个线程/进程在不同节点访问同一页
所以 Linux 既需要“初始分配策略”,也需要“运行时纠偏机制”。页面迁移就是纠偏的核心工具。
3. 页面迁移的基本目标
官方文档 Documentation/mm/page_migration.rst 对页面迁移的定义很准确:
Page migration allows moving the physical location of pages between nodes in a NUMA system while the process is running. This means that the virtual addresses that the process sees do not change.
翻译成我们熟悉的 MM 术语:
- VMA 不变
- 虚拟地址不变
- 用户态指针不变
- 页面内容不变
- 变化的是 PTE 指向的 PFN
迁移可以由多种入口触发:
| 触发来源 | 典型场景 | 迁移原因 |
|---|---|---|
move_pages() |
用户态指定一批地址迁移到目标节点 | MR_SYSCALL |
mbind() / mempolicy |
改变内存策略并要求移动页面 | MR_MEMPOLICY_MBIND |
| compaction | 整理内存,腾出连续物理页 | MR_COMPACTION |
| memory hotplug | 节点/内存块下线前搬走页面 | MR_MEMORY_HOTPLUG |
| memory failure | 硬件错误页隔离 | MR_MEMORY_FAILURE |
| NUMA balancing | 页面被频繁远端访问 | MR_NUMA_MISPLACED |
| memory tiering / reclaim demotion | 冷页降级或热页提升 | MR_DEMOTION |
| DAMON | 基于访问监控做冷热迁移 | MR_DAMON |
这些入口不同,但最终很多都会汇聚到同一个核心函数:migrate_pages()。
4. migrate_pages() 的调用模型
migrate_pages() 声明在 include/linux/migrate.h:
int migrate_pages(struct list_head *l, new_folio_t new, free_folio_t free,
unsigned long private, enum migrate_mode mode, int reason,
unsigned int *ret_succeeded);
它的参数体现了一个重要设计:迁移核心不负责决定目标页从哪里来。
| 参数 | 含义 |
|---|---|
l |
待迁移 folio 链表 |
new |
分配目标 folio 的回调 |
free |
迁移失败时释放目标 folio 的回调,可为 NULL |
private |
传给 new/free 的私有数据 |
mode |
迁移模式:是否允许阻塞、等待写回等 |
reason |
迁移原因,用于统计和策略分支 |
ret_succeeded |
成功迁移的 base page 数 |
典型调用长这样:
LIST_HEAD(pagelist);
// 1. 调用者先收集并隔离待迁移 folio
// 2. 提供目标页分配回调
ret = migrate_pages(&pagelist, alloc_migration_target, NULL,
private, MIGRATE_SYNC, MR_SYSCALL, &nr_succeeded);
// 3. 失败的 folio 需要 putback_movable_pages()
4.1 迁移模式:异步、轻同步、同步
include/linux/migrate_mode.h 定义了迁移模式:
enum migrate_mode {
MIGRATE_ASYNC,
MIGRATE_SYNC_LIGHT,
MIGRATE_SYNC,
};
| 模式 | 行为 |
|---|---|
MIGRATE_ASYNC |
尽量不阻塞,拿不到锁/遇到写回就跳过 |
MIGRATE_SYNC_LIGHT |
可以等一些短暂锁,但不等待代价很高的 I/O |
MIGRATE_SYNC |
可以阻塞等待,尽量完成迁移 |
自动 NUMA balancing 通常使用 MIGRATE_ASYNC,因为它是后台优化,不应该为了迁移一个页长时间卡住用户线程。
5. 第一步:隔离待迁移 folio
迁移前,调用者需要把候选 folio 从 LRU 上隔离出来。文档把这列为第一步:
folio_isolate_lru(folio);
隔离的作用有两个:
- 防止页面消失:隔离会增加引用计数,保证迁移期间 folio 不会被释放
- 防止回收/扫描干扰:页面暂时离开 LRU,kswapd、reclaim、compaction 等路径不会同时处理它
迁移候选页:
LRU 链表
│
├─ folio A
├─ folio B ← 选中
└─ folio C
隔离后:
LRU 链表 migrate list
│ │
├─ folio A └─ folio B
└─ folio C
自动 NUMA balancing 的准备函数 migrate_misplaced_folio_prepare() 就会做这件事:
// mm/migrate.c(简化)
if (!folio_isolate_lru(folio))
return -EAGAIN;
node_stat_mod_folio(folio,
NR_ISOLATED_ANON + folio_is_file_lru(folio), nr_pages);
它还会过滤掉一些不适合迁移的页面,比如:
- 多进程共享的可执行文件页(很可能是共享库)
- 脏文件页(异步迁移下不值得等待/回写)
- 目标节点水位不足的情况
6. 第二步:分配目标 folio
迁移不是“把物理页移动到另一个地址”,而是:
- 在目标节点分配一个新 folio
- 把旧 folio 的内容和元数据搬过去
- 把映射从旧 folio 切到新 folio
- 释放旧 folio
目标 folio 的分配由 new_folio_t 回调负责:
typedef struct folio *new_folio_t(struct folio *folio,
unsigned long private);
通用分配器是 alloc_migration_target():
struct folio *alloc_migration_target(struct folio *src,
unsigned long private);
它会根据源 folio 的属性选择合适的目标:
- 普通页:按目标 nid 分配普通 movable page
- THP/large folio:尝试按相同 order 分配大页
- hugetlb:走 hugetlb 专用分配路径
- 目标节点未指定时:默认沿用源页节点
自动 NUMA balancing 使用自己的目标分配函数:
static struct folio *alloc_misplaced_dst_folio(struct folio *src,
unsigned long data)
{
int nid = (int)data;
int order = folio_order(src);
gfp_t gfp = __GFP_THISNODE;
if (order > 0)
gfp |= GFP_TRANSHUGE_LIGHT;
else
gfp |= GFP_HIGHUSER_MOVABLE | __GFP_NOMEMALLOC |
__GFP_NORETRY | __GFP_NOWARN;
return __folio_alloc_node(gfp, order, nid);
}
这里的 __GFP_THISNODE 很关键:自动 NUMA 迁移就是要把页搬到指定节点,如果目标节点分配不到,就宁可失败,也不要悄悄 fallback 到别的节点。
7. 第三步:把 PTE 临时替换成 migration entry
迁移过程中最关键的问题是:旧页内容正在拷贝到新页,用户线程如果此时访问怎么办?
Linux 的答案是:把所有映射旧页的 PTE 临时替换成 migration entry。
migration entry 是一种特殊的 non-present PTE,编码方式复用了 swap entry 框架:
// include/linux/swapops.h
static inline swp_entry_t make_readable_migration_entry(pgoff_t offset)
{
return swp_entry(SWP_MIGRATION_READ, offset);
}
static inline swp_entry_t make_writable_migration_entry(pgoff_t offset)
{
return swp_entry(SWP_MIGRATION_WRITE, offset);
}
其中 offset 存的是源页面 PFN。
普通 PTE:
Present=1 | PFN=old page | flags
迁移期间:
Present=0 | type=SWP_MIGRATION_* | offset=old PFN | flags
迁移完成:
Present=1 | PFN=new page | flags
这和 swap entry 很像,但语义不同:
| 类型 | 页面内容在哪里 | fault 时怎么处理 |
|---|---|---|
| swap entry | 磁盘 swap 分区/文件 | 从 swap 读回 |
| migration entry | 正在迁移的旧/新 folio 协议中 | 等迁移完成,再重试 fault |
| device private entry | 设备私有内存,如 GPU VRAM | 迁回 CPU 或由设备处理 |
try_to_migrate() 通过 rmap 找到所有映射该 folio 的 PTE,并把它们替换成 migration entry。关键逻辑在 mm/rmap.c:
// mm/rmap.c(简化)
if (writable)
entry = make_writable_migration_entry(page_to_pfn(subpage));
else if (anon_exclusive)
entry = make_readable_exclusive_migration_entry(page_to_pfn(subpage));
else
entry = make_readable_migration_entry(page_to_pfn(subpage));
if (pte_young(pteval))
entry = make_migration_entry_young(entry);
if (pte_dirty(pteval))
entry = make_migration_entry_dirty(entry);
swp_pte = swp_entry_to_pte(entry);
set_pte_at(mm, address, pvmw.pte, swp_pte);
7.1 为什么要保留 young/dirty 等状态
迁移不能丢失原 PTE 的语义:
- 原来可写,迁移后仍应可写
- 原来 dirty,迁移后不能忘记它被修改过
- 原来 young/accessed,迁移后活跃度信息应尽量保留
- 原来 uffd-wp/soft-dirty,也要带过去
所以 migration entry 不只是“请等待”的占位符,它还携带恢复 PTE 所需的状态。
8. 第四步:拷贝内容、搬迁 mapping、恢复 PTE
migrate_pages() 内部会把迁移拆成两个阶段:
migrate_folio_unmap():锁住旧页/新页,处理写回,设置 migration entry,把旧页从映射中摘出来migrate_folio_move():移动 mapping,拷贝内容和 flags,恢复 PTE,释放旧页
简化流程如下:
migrate_pages()
└─ migrate_pages_batch()
├─ migrate_folio_unmap()
│ ├─ 分配 dst folio
│ ├─ 锁 src folio
│ ├─ 等待/跳过 writeback
│ ├─ 锁 dst folio
│ └─ try_to_migrate(src) // PTE → migration entry
│
├─ try_to_unmap_flush() // 批量 TLB flush
│
└─ migrate_folios_move()
└─ migrate_folio_move()
├─ move_to_new_folio()
├─ folio_add_lru(dst)
├─ remove_migration_ptes(src, dst)
├─ unlock dst/src
└─ folio_put(src)
8.1 move_to_new_folio() 做什么
move_to_new_folio() 会根据页面类型调用不同迁移方法:
// mm/migrate.c(简化)
if (!mapping)
rc = migrate_folio(mapping, dst, src, mode);
else if (mapping_inaccessible(mapping))
rc = -EOPNOTSUPP;
else if (mapping->a_ops->migrate_folio)
rc = mapping->a_ops->migrate_folio(mapping, dst, src, mode);
else
rc = fallback_migrate_folio(mapping, dst, src, mode);
常见情况:
- 匿名页:通过 swap address space 的
migrate_folio路径迁移 - 文件页:优先使用文件系统
address_space_operations->migrate_folio - 没有专用回调:使用 fallback 路径拷贝内容
- 特殊 movable page:使用
movable_operations
8.2 remove_migration_ptes():把用户映射切到新页
迁移成功后,页表里不能继续留着 migration entry。remove_migration_ptes(src, dst, ...) 会再次通过 rmap 找到 migration entry,把它们恢复成指向新 folio 的 present PTE。
迁移期间访问:
CPU 访问 VA
↓
PTE 是 migration entry
↓
page fault
↓
migration_entry_wait()
↓
等待迁移完成并重试
迁移完成后:
migration entry → present PTE(new PFN)
↓
CPU 重试访问成功
这就是 migration entry 的核心价值:它把“正在迁移”的临界区暴露给 fault 路径,让并发访问变成等待和重试,而不是读到半迁移状态。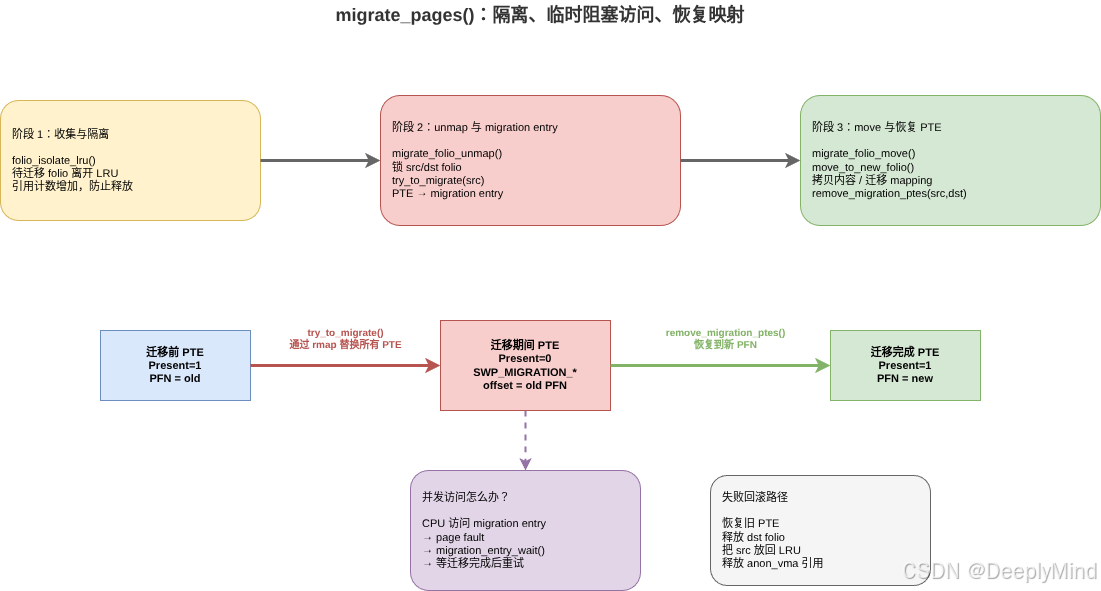
9. 失败和回滚:迁移不是总能成功
页面迁移经常失败,这是正常情况,不是异常。
常见失败原因:
| 原因 | 表现 |
|---|---|
| 页被锁住 | MIGRATE_ASYNC 下拿不到锁就跳过 |
| 正在 writeback | 异步/轻同步模式通常不等待 |
| 页被 pin | GUP、DMA、长期 pin 会让引用计数无法降到可迁移状态 |
| 文件系统不支持 | 没有合适的 migrate_folio 或返回错误 |
| 目标节点内存不足 | 目标 folio 分配失败 |
| THP 迁移失败 | 可能尝试 split 后迁移 base pages |
| 映射复杂 | mapcount/refcount 不满足迁移条件 |
失败时内核必须回滚:
- 如果已经设置了 migration entry,要恢复成指向旧页的 PTE
- 如果已经分配了目标页,要释放目标页
- 如果旧页已被隔离,要放回 LRU 或调用 putback
- 如果拿了 anon_vma 引用,要释放引用
migrate_folio_undo_src() 和 migrate_folio_undo_dst() 就负责这些清理路径。
10. 自动 NUMA balancing:用 hinting fault 找到“谁在访问谁”
到这里我们理解了“如何迁移页面”。接下来问题是:内核怎么知道页面放错地方了?
自动 NUMA balancing 的思路很巧:
- 后台周期性扫描进程的一部分 VMA
- 把一批 PTE 改成 NUMA hinting PTE(通常表现为 protnone)
- CPU 下次访问这些地址时触发缺页异常
- fault 路径记录“哪个 CPU/任务访问了哪个节点的页面”
- 如果页面节点和访问 CPU 节点不匹配,就尝试迁移
自动 NUMA balancing:
task_numa_work()
↓
change_prot_numa()
↓
PTE 临时变成 NUMA hinting PTE
↓
用户线程再次访问
↓
do_numa_page()
↓
统计 hinting fault + 判断是否迁移
↓
migrate_misplaced_folio()
这个机制的关键是:它用“轻微打断”换取访问位置的采样信息。不是每次访问都记录,那样开销太大;而是周期性地让一部分页面触发 fault,从 fault 中推断访问热点。
10.1 task_numa_work():周期性扫描 VMA
调度器会为任务安排 task_numa_work()。它会检查扫描间隔、VMA 是否适合迁移,然后调用:
// kernel/sched/fair.c(简化)
nr_pte_updates = change_prot_numa(vma, start, end);
change_prot_numa() 在 mm/mempolicy.c:
unsigned long change_prot_numa(struct vm_area_struct *vma,
unsigned long addr,
unsigned long end)
{
struct mmu_gather tlb;
long nr_updated;
tlb_gather_mmu(&tlb, vma->vm_mm);
nr_updated = change_protection(&tlb, vma, addr, end, MM_CP_PROT_NUMA);
tlb_finish_mmu(&tlb);
return nr_updated;
}
它不是把页面换出,也不是解除映射,而是把 PTE 改成一种会触发 NUMA hinting fault 的形式。
10.2 do_numa_page():访问时判断是否 misplaced
当 CPU 访问 NUMA hinting PTE 时,fault 路径最终进入 do_numa_page():
// mm/memory.c(简化)
folio = vm_normal_folio(vma, vmf->address, pte);
nid = folio_nid(folio);
target_nid = numa_migrate_check(folio, vmf, vmf->address,
&flags, writable, &last_cpupid);
if (target_nid == NUMA_NO_NODE)
goto out_map;
if (migrate_misplaced_folio_prepare(folio, vma, target_nid))
goto out_map;
pte_unmap_unlock(vmf->pte, vmf->ptl);
if (!migrate_misplaced_folio(folio, target_nid)) {
flags |= TNF_MIGRATED;
task_numa_fault(last_cpupid, target_nid, nr_pages, flags);
return 0;
}
这里有三个关键动作:
numa_migrate_check():记录 NUMA hinting fault,并通过 mempolicy 判断目标节点migrate_misplaced_folio_prepare():检查是否适合迁移,并隔离 foliomigrate_misplaced_folio():调用migrate_pages()把页面搬到目标节点
如果不迁移,do_numa_page() 也会把 PTE 恢复成正常可访问状态,让程序继续运行。
10.3 迁移页面还是迁移任务
自动 NUMA balancing 不只是迁移页面,也会影响调度器放置任务。
task_numa_fault() 会记录:
- 哪个任务访问了哪个节点的内存
- 访问是本地还是远端
- 页面是否共享
- 是否发生迁移
调度器后续通过 task_numa_placement() 选择任务的 preferred node。也就是说,NUMA balancing 同时有两种纠偏手段:
页面靠近任务:
migrate_misplaced_folio() 把页面迁到访问它的节点
任务靠近页面:
sched_setnuma() 调整任务 preferred node
对于私有匿名页,迁移页面通常有效;对于大量共享页,移动任务或保持共享缓存可能更合理。

11. migration entry 与 swap/device entry 的关系
到目前为止,我们已经见过三类 non-present PTE:
| entry | 页面在哪里 | 触发访问时 |
|---|---|---|
| swap entry | 磁盘 swap | do_swap_page() 换入 |
| migration entry | 迁移过程中 | 等待迁移完成,重试 fault |
| device private entry | 设备私有内存 | 迁回 CPU 或由设备协作处理 |
它们都利用了 PTE 的一个共同事实:Present=0 不一定表示“非法地址”,也可能表示“页面暂时不在普通 CPU PTE 可直接访问的位置”。
Present=0 的 PTE:
┌──────────────────────────────────────────────┐
│ type 字段决定语义 │
├──────────────────────────────────────────────┤
│ SWP_* → swap entry │
│ SWP_MIGRATION_* → migration entry │
│ SWP_DEVICE_* → device private entry │
│ SWP_PTE_MARKER → marker / guard / uffd │
└──────────────────────────────────────────────┘
这也是为什么第 5 篇讲 swap entry、第 7 篇讲 migration entry、第 13 篇再讲 device private/exclusive entry:它们共享同一类“非驻留 PTE 编码思想”。
12. 与 HMM 的联系
HMM 的设备内存迁移并不是凭空发明的一套机制,它借鉴并复用了经典页面迁移的很多思想。
12.1 相同点
| 经典 NUMA 迁移 | HMM 设备迁移 |
|---|---|
| CPU DRAM Node A → CPU DRAM Node B | CPU DRAM ↔ GPU VRAM / device private memory |
| 虚拟地址不变 | 虚拟地址不变 |
| 迁移期间用 migration entry 阻塞访问 | 设备私有页用 device private entry 表示 CPU 不可直接访问 |
| rmap 找到所有 PTE | rmap 同样用于替换/恢复 PTE |
新旧页面都有 struct page |
ZONE_DEVICE 让设备页也有 struct page |
| fault 时等待或重试 | CPU 访问设备页时 fault 并迁回 |
12.2 不同点
| 方面 | NUMA 页面迁移 | HMM 设备迁移 |
|---|---|---|
| 目标 | 另一个 CPU NUMA 节点 | 设备私有内存或 coherent device memory |
| 拷贝方式 | CPU copy / 文件系统 migrate_folio | 设备 DMA / driver callback |
| PTE 最终状态 | present PTE 指向 CPU PFN | device private entry 或迁回 CPU present PTE |
| 协调对象 | CPU 页表、LRU、rmap | CPU 页表 + 设备页表 + MMU notifier |
| 触发来源 | NUMA hinting fault、mempolicy、compaction | GPU page fault、driver migration、HMM API |
后续第 14 篇 migrate_vma 会看到更直接的连接:HMM 不是直接使用普通 migrate_pages() 完成设备迁移,而是使用面向设备的三阶段框架:
migrate_vma_setup()
migrate_vma_pages()
migrate_vma_finalize()
但理解 migrate_pages() 和 migration entry 后,再看 migrate_vma 会容易很多:它们解决的是同一个根问题——在并发访问存在的情况下,安全地改变一个虚拟地址背后的物理承载位置。
13. 实验:观察 NUMA 和页面迁移
13.1 查看 NUMA 拓扑
# 查看 NUMA 节点和 CPU/内存分布
numactl --hardware
# 或查看 sysfs
ls /sys/devices/system/node/
cat /sys/devices/system/node/node0/cpulist
cat /sys/devices/system/node/node0/meminfo
13.2 查看进程页面分布
# 查看当前 shell 的 NUMA 映射
cat /proc/$$/numa_maps
# 观察某个进程
cat /proc/<pid>/numa_maps
numa_maps 会展示 VMA 中页面分布在哪些节点,例如:
7f... anon=1024 dirty=1024 N0=128 N1=896 kernelpagesize_kB=4
这表示该 VMA 的匿名页大多在 Node 1。
13.3 查看自动 NUMA balancing 开关
cat /proc/sys/kernel/numa_balancing
# 0: disabled
# 1: normal NUMA balancing
# 2: memory tiering mode
注意:是否支持 NUMA balancing 取决于内核配置和架构。单节点机器上看不到明显效果。
13.4 手动绑定 CPU/内存做对比
# 在 Node 0 CPU 上运行,但内存从 Node 1 分配
numactl --cpunodebind=0 --membind=1 ./your_workload
# 查看远端内存访问和 numa_maps
cat /proc/<pid>/numa_maps
如果启用了自动 NUMA balancing,长时间运行后可能看到部分热页被迁移到访问它们的节点。
14. 本篇关键代码路径
| 文件 | 核心内容 |
|---|---|
Documentation/mm/page_migration.rst |
页面迁移官方说明与高层流程 |
include/linux/migrate.h |
migrate_pages()、new_folio_t、migrate_vma 相关声明 |
include/linux/migrate_mode.h |
迁移模式与迁移原因枚举 |
mm/migrate.c |
页面迁移核心:隔离、unmap、move、恢复 PTE、NUMA misplaced 迁移 |
mm/rmap.c |
try_to_migrate() 通过 rmap 把 PTE 替换成 migration entry |
include/linux/swapops.h |
migration entry 的编码与等待接口 |
mm/memory.c |
do_numa_page() NUMA hinting fault 处理 |
mm/mempolicy.c |
mpol_misplaced()、change_prot_numa() |
kernel/sched/fair.c |
task_numa_work()、task_numa_fault()、任务 NUMA placement |
15. 下篇预告
2.3:MMU Notifier(上):KVM 催生的页表变化通知
本篇我们看到:页面迁移会修改 CPU 页表,迁移期间还会把 PTE 替换成 migration entry。对于只看 CPU 页表的普通进程来说,fault 和 TLB flush 足以维持一致性。
但如果还有一个外部设备或虚拟机维护了自己的“影子页表”呢?CPU 页表变化时,它怎么知道要同步失效?
下一篇进入 MMU Notifier:从 KVM 的 EPT/NPT 同步问题出发,理解内核如何把页表变化通知给外部订阅者。这正是 HMM 让 GPU 页表和 CPU 页表保持一致的关键基础。
16. 思考题
-
页面迁移为什么不能只做
memcpy(old, new)然后改一个 PTE?并发访问、共享映射和页表锁分别带来什么问题? -
migration entry 和 swap entry 都是 Present=0 的 PTE。它们的共同点和关键区别是什么?
-
自动 NUMA balancing 为什么要周期性制造 NUMA hinting fault?为什么不在每次内存访问时记录访问节点?
-
哪些页面不适合自动 NUMA 迁移?为什么共享库文件页、脏文件页、被长期 pin 的页会比较麻烦?
-
HMM 设备迁移为什么需要 ZONE_DEVICE 页面也有
struct page?这和 rmap、migration/device entry 有什么关系?
📚 关联阅读

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)