【2026】从注视到洞察:一种用于检测面对面协作学习中注视行为的可扩展人工智能方法
从注视到洞察:一种用于检测面对面协作学习中注视行为的可扩展人工智能方法
Gaze to Insight: A Scalable AI Approach for Detecting Gaze Behaviours in Face-to-Face Collaborative Learning
1. 论文基本信息
| 项目 | 内容 |
|---|---|
| 英文标题 | Gaze to Insight: A Scalable AI Approach for Detecting Gaze Behaviours in Face-to-Face Collaborative Learning |
| 中文标题 | 从注视到洞察:一种用于检测面对面协作学习中注视行为的可扩展人工智能方法 |
| 论文链接 | https://arxiv.org/abs/2604.03317 |
2. 摘要分析
2.1 研究背景与问题
注视行为(Gaze Behaviour)是协作学习中重要的非语言线索,能够反映学生的注意力分布、参与程度和小组动态。已有研究表明,基于注视的指标(如联合视觉注意力、注视重叠和注视同步)与协作质量和学习成果密切相关。具体而言:
- 联合视觉注意力(JVA):反映学生对同一对象或人物的共同关注,支持知识建构、解释和协作问题解决
- 注视目标:同伴注视通常与社交性、互动性协作相关;个人设备注视则反映更个性化或任务导向的行为
然而,获取真实教育场景中的注视数据面临重大挑战:
- 手动视频编码:逐帧标注注视目标,耗时耗力,难以规模化或提供实时反馈
- 穿戴式眼动追踪设备:虽然精确,但具有侵入性、成本高、需要复杂校准,难以在动态教室环境中大规模部署
2.2 现有方法的局限性
监督式机器学习方法(如CNN、随机森林)虽然有潜力,但存在两大核心问题:
- 标注数据依赖:需要大量标注数据才能训练,而从教室场景获取标注数据集非常困难
- 跨配置鲁棒性不足:模型通常在精心策划的数据集或受控实验室环境中训练,缺乏光照、遮挡或小组配置的多样性,导致在真实教室环境中泛化能力差
2.3 研究贡献
本文提出的可扩展AI方法利用预训练和基础模型,无需人工标注数据即可自动检测面对面协作学习中的注视行为。主要贡献包括:
- 消除标注依赖:利用基础模型,无需大量手动标注数据集进行模型训练,更适合现实世界部署
- 跨配置鲁棒性:在不同条件、配置和小组规模下表现一致
- 性能提升:相比先前研究(如Zhou等人的F1=0.675),实现了更高的检测精度
- 模块化设计:管道各组件功能明确,增强了系统级透明度
3. 研究现状
3.1 注视行为在教育中的应用
注视行为分析在教育领域已有广泛研究:
- Zhou等人(2022):识别了四种注视目标(同伴、笔记本电脑、导师、其他物体),证明不同注视分布对应不同水平的共享理解
- Schneider和Pea(2013):证明实时联合视觉感知能增强协作学习和协作质量
- Schneider等人(2018):利用移动眼动追踪器捕捉协作学习中的联合视觉注意力
3.2 自动化注视检测技术
从视频中推断注视的视觉方法正在兴起:
| 研究 | 方法 | 性能 |
|---|---|---|
| Zhou等人(2023) | 对象检测模型+YOLOE +时空模型 | F1=0.675(2类注视) |
| Muller等人(2018) | 无训练模型检测眼神接触 | 准确率54% |
| Wu等人(2023) | 无监督方法检测眼神接触 | 准确率71.88% |
| Stiefelhagen等人(2002) | 会议焦点注意力分析 | 准确率73.9% |
| Chong等人(2020) | 视频中注视目标检测 | 准确率83.3% |
3.3 基础模型在视觉任务中的应用
近年来,预训练基础模型在计算机视觉领域取得突破性进展:
- DINOv2:大规模预训练视觉Transformer,提供强大的场景级视觉表征
- YOLO系列:实时目标检测模型,YOLO11用于头部检测,YOLOE-26支持开放词汇检测
- Gaze-LLE:基于大规模学习编码器的注视估计模型,将注视估计表述为场景级预测任务
4. 创新点分析
4.1 技术创新
(1)多模型协同的注视检测管道
本文提出的方法整合三种预训练模型形成完整管道:
输入视频帧
↓
┌─────────────────────────────────────┐
│ YOLO11头部检测与跟踪模块 │
│ (Head Tracking Module) │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ Gaze-LLE注视估计模块 │
│ (Frozen DINOv2 + Transformer) │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ YOLOE-26物体检测模块 │
│ (Laptop, Tablet, Phone) │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 注视目标分配 │
│ (直接几何映射) │
└─────────────────────────────────────┘
↓
注视行为输出(S/L/O)
(2)无需标注数据的方法论
与监督学习方法不同,本方法利用预训练模型的泛化能力,无需针对特定教育场景进行大规模标注:
| 对比维度 | 监督学习方法 | 本文方法 |
|---|---|---|
| 标注需求 | 大量人工标注 | 无需标注 |
| 场景适应 | 特定场景训练 | 零样本适应 |
| 数据效率 | 低(需要66%+数据) | 高(无需训练数据) |
| 跨配置鲁棒性 | 差 | 优秀 |
(3)头部跟踪的自适应训练策略
针对特定小组的头部跟踪,采用小样本自适应策略:
- 采样20帧随机帧
- 根据小组规模和桌子中心距离过滤头部边界框
- 以桌子中心为基准顺时针分配人物ID
- 人工检查ID一致性
- 生成训练文件训练YOLO11模型
- 训练集与验证集比例7:3
4.2 应用创新
(1)教育场景适配
- 针对教育相关物体(笔记本电脑、平板、手机)进行定制化检测
- 注视行为分类(S-学生、L-笔记本电脑、O-其他)与学习成果关联
- 支持小组协作质量分析和实时反馈
(2)可扩展部署
- 仅需一台标准2D RGB摄像头
- 从专业硬件转向通用硬件,大幅降低成本
- 支持多教室、跨机构同时部署
5. 数据集分析
5.1 数据集来源与采集
| 属性 | 描述 |
|---|---|
| 采集时间跨度 | 三个学年的研究生课程 |
| 协作任务 | 使用Miro协作平台设计教育挑战的技术解决方案 |
| 小组规模 | 4人或5人围绕T型桌 |
| 设备支持 | 导师现场指导 |
| 采集设备 | Intel RealSense 435i摄像头(1080p, 30FPS) |
| 采集位置 | 桌一端,非侵入式 |
| 伦理批准 | 已获机构伦理批准,学生知情同意 |
5.2 数据集划分
| 数据集 | 小组规模 | 视频时长 | 帧数 | 特点 |
|---|---|---|---|---|
| Dataset 1 | 5人组 | ~2.5小时 | 标注帧 | 较复杂场景 |
| Dataset 2 | 4人组 | ~3小时 | 标注帧 | 相对简单场景 |
| Dataset 3 | 混合组 | ~5.5小时 | 标注帧 | 混合配置 |
5.3 注视行为标注
标注工具:CVAT(计算机视觉标注工具)
标注协议:
| 类别 | 描述 | 教育意义 |
|---|---|---|
| S (Student) | 学生看向同组同伴 | 反映社交互动、协作参与 |
| L (Laptop) | 学生看向笔记本电脑 | 反映任务导向、个人工作 |
| O (Other) | 其他注视(手机、导师、白板、离题方向) | 反映导师寻求、离题行为 |
标注质量控制:
- 初始1000帧双重编码
- Cohen’s Kappa = 0.784(高一致性)
- 剩余帧独立标注
5.4 数据分布
| 数据集 | Student (S) | Laptop (L) | Other (O) |
|---|---|---|---|
| Dataset 1 | 13,926 | 3,569 | 921 |
| Dataset 2 | 18,522 | 7,037 | 1,471 |
| Dataset 3 | 32,448 | 10,606 | 2,392 |
数据不平衡分析:
- Student类占比最高(约71%)
- Laptop类次之(约23%)
- Other类最少(约5%),类别不平衡影响检测性能
6. 算法结构详解
6.1 系统整体架构
系统包含四个核心模块,形成完整的注视检测管道:
6.1.1 头部跟踪模块(Head Tracking Module)
输入:原始视频帧
输出:带人物ID的头部边界框
关键技术:
-
头部检测:YOLO11m模型
- 使用150张自定义标注图像训练
- 标注从类似教育场景的前数据集采样
- 涵盖多样化光照条件和学生外观
- 边界框定义:头顶到下巴,耳朵到耳朵
-
ID分配策略:
- 提取20帧随机帧
- 按小组规模(N)和桌子中心距离过滤
- 以桌子中心为基准顺时针分配"Person 1, 2, 3…"
- 人工验证ID一致性
-
模型训练:
- 训练集:验证集 = 7:3
- YOLO11-based头跟踪模型
6.1.2 注视估计模块(Gaze-LLE Model)
输入:视频帧 + 头部位置
输出:注视热力图 → 注视点坐标
模型架构:
RGB帧
↓
┌─────────────────────────────────────┐
│ Frozen Scene Encoder │
│ (DINOv2 Vision Transformer) │
│ - 编码整个场景 │
│ - 无需单独的头部/场景编码器 │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ Head-Position Prompt │
│ - 学习到的头部位置提示 │
│ - 注入场景特征图对应空间区域 │
│ - 针对目标个体调整表征 │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ Lightweight Gaze Decoder │
│ (Transformer-based) │
│ - 生成概率注视热力图 │
│ - 峰值响应 = 最终注视点 │
└─────────────────────────────────────┘
↓
注视点坐标
核心思想:将注视估计表述为场景级预测任务,以头部空间位置为条件
6.1.3 物体检测模块(Object Detection)
输入:视频帧
输出:教育相关物体的边界框
检测目标:
| 物体类别 | 教育意义 |
|---|---|
| Laptop | 主要协作工具,任务焦点 |
| Tablet | 辅助学习设备 |
| Phone | 潜在干扰源/离题指标 |
模型:YOLOE-26
- 预训练开放词汇目标检测模型
- 支持文本提示
- 无需针对任务微调
6.1.4 注视目标分配(Gaze Object Assignment)
输入:注视点坐标 + 物体边界框
输出:注视行为类别(S/L/O)
分配规则:
| 情况 | 规则 |
|---|---|
| 注视点落在边界框内 | 分配给对应物体/人物 |
| 注视点落在多个框内 | 分配给中心点最近的物体 |
| 注视点不在任何框内 | 不分配注视目标 |
7. 图表分析
7.1 系统管道图(Fig. 1)

图表分析:
Fig. 1展示了本文提出的注视检测系统完整管道。系统从视频帧输入开始,分为两条并行路径:
-
上方路径(头部跟踪):
- Input Image → Head Tracking Module (YOLO11-based) → Gaze-LLE Model → Gaze Object Assignment
-
下方路径(物体检测):
- Input Image → Object Detection Model (YOLOE-26) → Gaze Object Assignment
-
最终输出:
- Gaze Object → Gaze Object (S/L/O分类)
设计亮点:
- 模块化设计,每个组件功能明确
- YOLOE-26的开放词汇检测能力支持灵活扩展检测目标
- 直接几何映射简化了注视分配逻辑
7.2 头部跟踪流程图(Fig. 2)

图表分析:
Fig. 2以4人小组为例,详细展示了头部跟踪的自适应训练流程,包含5个步骤:
| 步骤 | 描述 | 输出 |
|---|---|---|
| 1 | 预训练YOLO11获取初始头部边界框 | 6个边界框 |
| 2 | 按小组规模N=4过滤,选取靠近中心的头部 | 4个边界框 |
| 3 | 20帧顺时针分配Person 1-4标签 | 带标签帧 |
| 4 | 使用20帧训练YOLO11m头跟踪模型 | 训练完成 |
| 5 | 对剩余帧推理,获取带标签边界框 | 所有帧跟踪结果 |
关键创新:
- 小样本自适应:仅需20帧即可训练针对特定小组的跟踪模型
- 基于桌面中心的几何约束过滤
- 顺时针ID分配提供一致的人物标识
7.3 性能对比图(Fig. 4 & Fig. 5)
7.3.1 分类性能(Fig. 4)
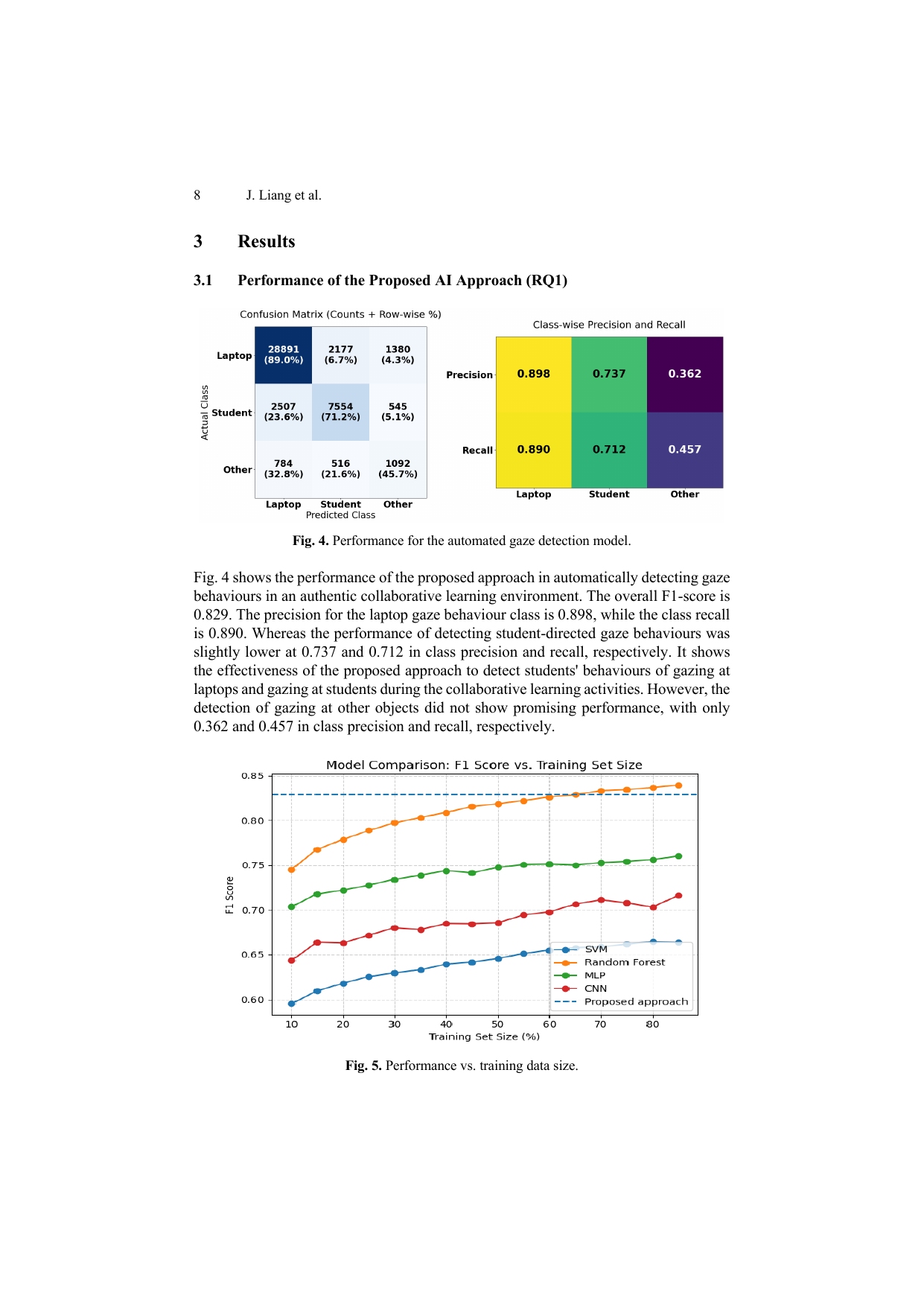
图表分析:
Fig. 4展示了本文方法在Dataset 3上的分类性能,包含两部分:
(1)混淆矩阵:
| 实际\预测 | Laptop | Student | Other |
|---|---|---|---|
| Laptop | 28,891 (89.0%) | 2,177 (6.7%) | 1,380 (4.3%) |
| Student | 2,507 (23.6%) | 7,554 (71.2%) | 545 (5.1%) |
| Other | 784 (32.8%) | 516 (21.6%) | 1,092 (45.7%) |
(2)分类别精确率和召回率:
| 指标 | Laptop | Student | Other |
|---|---|---|---|
| Precision | 0.898 | 0.737 | 0.362 |
| Recall | 0.890 | 0.712 | 0.457 |
性能解读:
- 整体F1 = 0.829,表现优异
- Laptop类:最高性能(Precision=0.898, Recall=0.890)
- 原因:笔记本电脑尺寸较大、位置稳定,易于检测和映射
- Student类:中等性能(Precision=0.737, Recall=0.712)
- 挑战:学生头部可能被遮挡、姿势变化
- Other类:最低性能(Precision=0.362, Recall=0.457)
- 原因:类别高度异质(导师、平板、手机、离题),基于规则的映射难以处理
7.3.2 训练数据规模影响(Fig. 5)
图表分析:
Fig. 5展示了不同训练数据比例下各方法的F1分数变化:
| 训练数据比例 | RF | CNN | MLP | SVM | 本文方法 |
|---|---|---|---|---|---|
| 10% | ~0.55 | ~0.50 | ~0.52 | ~0.48 | 0.829 |
| 30% | ~0.68 | ~0.58 | ~0.62 | ~0.55 | 0.829 |
| 50% | ~0.75 | ~0.65 | ~0.68 | ~0.60 | 0.829 |
| 66% | ~0.83 | ~0.70 | ~0.73 | ~0.65 | 0.829 |
| 90% | ~0.84 | ~0.72 | ~0.76 | ~0.68 | 0.829 |
关键发现:
- SVM/CNN/MLP始终低于本文方法(无论训练数据量)
- Random Forest在66%数据量时超越本文方法(约29,994条标注)
- 本文方法性能恒定(无需训练数据)
- 数据效率优势明显:节省了65%标注工作量
7.4 跨配置鲁棒性对比(Table 2 & Fig. 6)

7.4.1 性能表格(Table 2)
| 数据集 | RF | CNN | MLP | SVM | 本文方法 |
|---|---|---|---|---|---|
| Dataset 1 (4人组) | 0.877 | 0.860 | 0.886 | 0.822 | 0.856 |
| Dataset 2 (5人组) | 0.759 | 0.645 | 0.701 | 0.591 | 0.810 |
| Dataset 3 (混合) | 0.837 | 0.703 | 0.756 | 0.665 | 0.829 |
性能稳定性分析:
| 指标 | 本文方法 | Random Forest | SVM |
|---|---|---|---|
| F1标准差 | ~0.023 | ~0.060 | ~0.116 |
| 性能下降幅度 | 5.4% | 13.5% | 27.4% |
关键发现:
- 简单场景(Dataset 1):监督方法表现更好
- 复杂场景(Dataset 2):本文方法显著优于所有监督方法(p<0.001)
- 混合场景(Dataset 3):本文方法第二优,仅次于RF
- 稳定性:本文方法跨配置性能最稳定
7.4.2 场景示例图(Fig. 6)

图表分析:
Fig. 6展示了不同协作配置下的注视检测示例,包括:
| 场景类型 | 特点 | 检测挑战 |
|---|---|---|
| 4人组 | 相对简单,遮挡较少 | 基准场景 |
| 5人组 | 复杂度增加,遮挡更频繁 | 头部检测、注视分配 |
| 混合组 | 跨配置泛化测试 | 综合挑战 |
| 遮挡场景 | 面部被遮挡 | 头部检测鲁棒性 |
| 姿势变化 | 学生姿势不同 | 头部定位准确性 |
图中元素:
- 不同颜色边框标注不同人物(Person 1, 2, 3…)
- 彩色线条表示检测到的注视方向
- 清晰展示注视目标映射结果
8. 实验设计与结果分析
8.1 研究问题
| RQ | 问题描述 | 对应实验 |
|---|---|---|
| RQ1 | AI注视检测管道能否高精度预测学生注视行为? | Experiment 1 |
| RQ2 | 训练数据规模如何影响监督基线相对于本文方法的性能? | Experiment 2 |
| RQ3 | 本文方法在不同协作配置下的鲁棒性如何? | Experiment 3 |
8.2 评估指标
| 指标 | 描述 | 选择理由 |
|---|---|---|
| Precision | 精确率 | 衡量预测准确性 |
| Recall | 召回率 | 衡量检出完整性 |
| F1-score | 精确率与召回率的调和平均 | 在不平衡数据集上比准确率更可靠 |
| Friedman test | 非参数统计检验 | 评估多方法/多配置差异显著性 |
8.3 实验结果汇总
8.3.1 RQ1:整体性能
| 类别 | Precision | Recall | F1-score |
|---|---|---|---|
| Laptop | 0.898 | 0.890 | ~0.894 |
| Student | 0.737 | 0.712 | ~0.724 |
| Other | 0.362 | 0.457 | ~0.404 |
| Overall | - | - | 0.829 |
对比已有研究:
| 研究 | 方法 | 性能 |
|---|---|---|
| Zhou (2023) | 对象检测+时空模型 | F1=0.675, 准确率66.57% |
| Muller (2018) | 无训练模型 | 准确率54% |
| Wu (2023) | 无监督方法 | 准确率71.88% |
| Stiefelhagen (2002) | 焦点注意力分析 | 准确率73.9% |
| 本文 | 预训练基础模型 | F1=0.829 |
8.3.2 RQ2:数据效率
关键结论:
- SVM/CNN/MLP在所有数据比例下始终低于本文方法
- Random Forest在66%数据量(约29,994条标注)时超越本文方法
- 本文方法实现相同性能节省了约65%的标注工作量
8.3.3 RQ3:跨配置鲁棒性
| 统计检验 | 结果 |
|---|---|
| Friedman test | 数据集间存在显著差异 |
| Dataset 1对比 | 本文方法显著低于监督方法 (p<0.001) |
| Dataset 2对比 | 本文方法显著优于所有监督方法 (p<0.001) |
| Dataset 3对比 | 本文方法第二优,仅次于RF (p<0.01) |
9. 教育实践意义
9.1 可扩展性(Scalability)
| 传统方法 | 本文方法 |
|---|---|
| 专业眼动追踪设备 | 标准2D RGB摄像头 |
| 高成本、复杂校准 | 低成本、即插即用 |
| 单点部署 | 多教室、跨机构规模化 |
9.2 数据效率(Data Efficiency)
- 消除大规模标注依赖
- 支持快速部署到新协作学习环境
- 降低人力成本和时间开销
9.3 实时反馈潜力
潜在应用场景:
- 会话级摘要:活动结束后几分钟内生成注视行为比例报告
- 实时干预:当小组同伴注视显著下降时,提示教师进行引导
10. 局限性与未来方向
10.1 本文局限
| 局限 | 影响 | 说明 |
|---|---|---|
| 输入特征不对称 | 基线比较不完全公平 | 监督方法使用17个关键点,本文使用完整RGB场景 |
| Other类性能弱 | 影响全面性 | 仅占5%标注,类别不平衡 |
| 注视类别有限 | 洞察深度受限 | 缺少导师、共享材料等类别 |
10.2 未来研究方向
- 丰富Other类别:细分为导师导向、离题等子类
- 扩展注视分类:纳入导师注视、共享材料注视等
- 多模态LLM集成:利用面部表情、姿势、任务信息进行上下文感知分配
- 实时系统优化:提升处理速度,支持近实时分析
11. 总结
11.1 核心贡献
本文提出了一种利用预训练基础模型的可扩展AI方法,用于检测面对面协作学习中的注视行为,无需人工标注数据即可达到F1=0.829的优异性能。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 17
17 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)