论文阅读:Retrieval-based objects and relations prompt for image captioning
Retrieval-based objects and relations prompt for image captioning(RORPCap/基于检索的对象和关系提示图片说明)相似图片的描述句子里隐含丰富语义,此论文先把这些语义检索出来,再抽取其中最关键的对象词和关系词,作为 prompt 去引导语言模型生成描述。
创新点:
1. 用“检索到的关键词”替代“完整检索句子”,不同于以往一些检索式图像描述方法会直接把检索到的整句文本作为辅助信息输入模型,RORPCap 不直接吃整句,而是只提取对象词和关系词,把真正对图像描述有帮助的信息留下来;
2. 设计了 OREM 模块,专门提取对象与关系,此模块不只适用于本文模型。
3. 用 Mamba 代替传统 Transformer 做映射网络,在保证表示能力的同时,提高序列建模效率,进一步压缩训练时间。
主要框架:
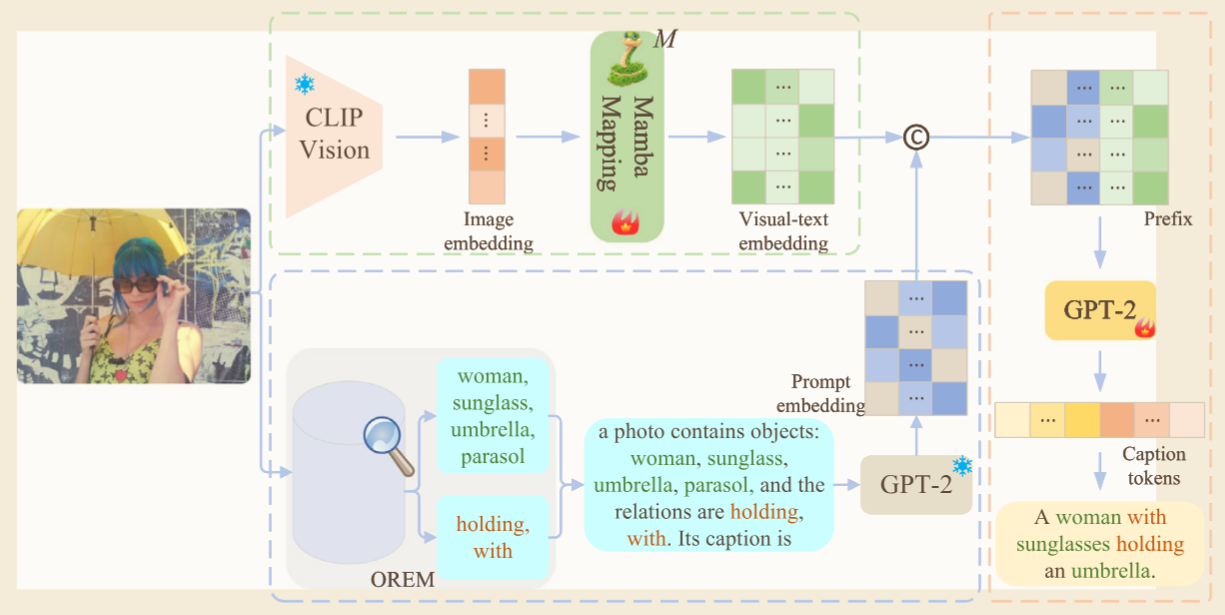
先检索相似文本并抽取对象词/关系词,形成 prompt;再把图像特征经过 CLIP 和 Mamba 映射成视觉-文本向量;然后把这两部分拼成 prefix;最后用 GPT-2 根据这个 prefix 生成图像描述。
1.OREM(Objects and relations extraction model)
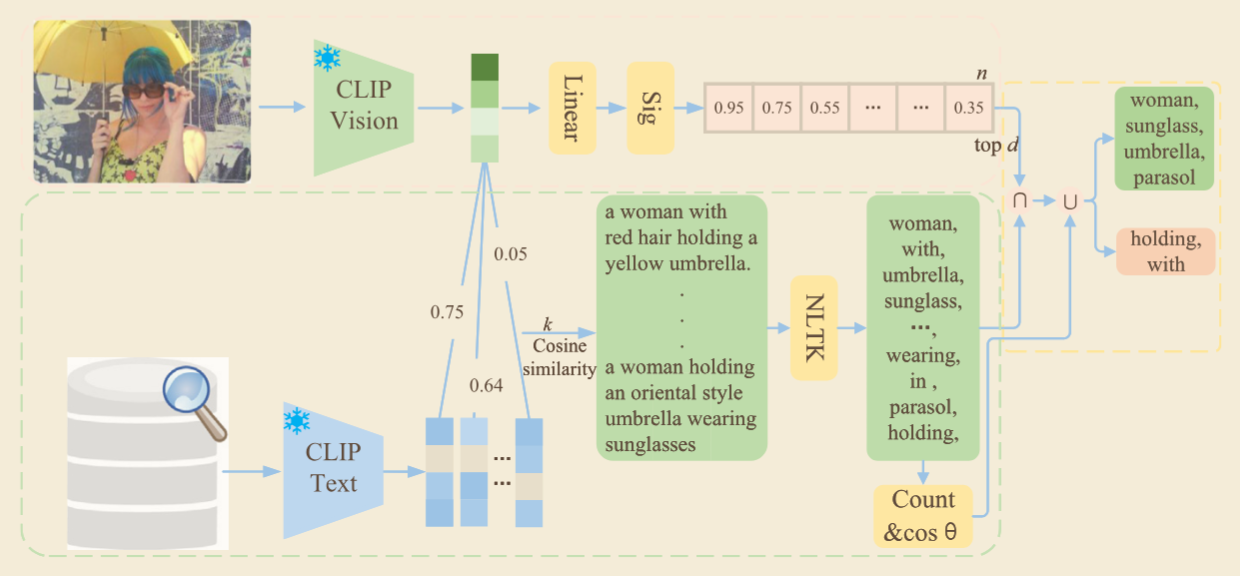
此检索模块并不是简单地“检索一下文本”,而是做了更细的筛选:先通过 CLIP 把图像和文本映射到共享空间;检索 top-k 相似句子;使用 NLTK 做词性标注,只保留名词、动词、动名词、介词等更有用的词;再结合高频词打分、对象词与图像相似度阈值、关系词频率等规则做二次筛选。
补充:
NLTK 是一个 Python 的自然语言处理工具包,简单说,它是做文本处理时很常用的一个库,能做这些事:
1.分词:把一句话拆成一个个单词
2.词性标注:判断一个词是名词、动词、形容词等
3.去停用词:去掉 like、the、is 这类高频但信息量低的词
4.词干提取 / 词形还原:把不同形式的词归一
5.句法分析、文本分类等基础 NLP 操作
2.Mamba映射网络
此模块主要作用是把“看见的内容”翻译成“语言模型能理解的前缀表示”,使用的经典Mamba模块,在 RORPCap 中,Mamba 映射网络用于将 CLIP 提取的图像嵌入映射为适配 GPT-2 的 图像-文本编码对。其核心机制是:针对序列中每个位置,先通过线性投影生成输入相关的动态参数;再将连续状态空间模型离散化;随后通过递推公式融合历史状态与当前输入,得到隐藏状态;最后通过动态读出和残差项生成输出。该输出作为视觉分支的前缀表示,与文本 prompt embedding 拼接后形成 prefix,用于条件化 GPT-2 的自回归生成。
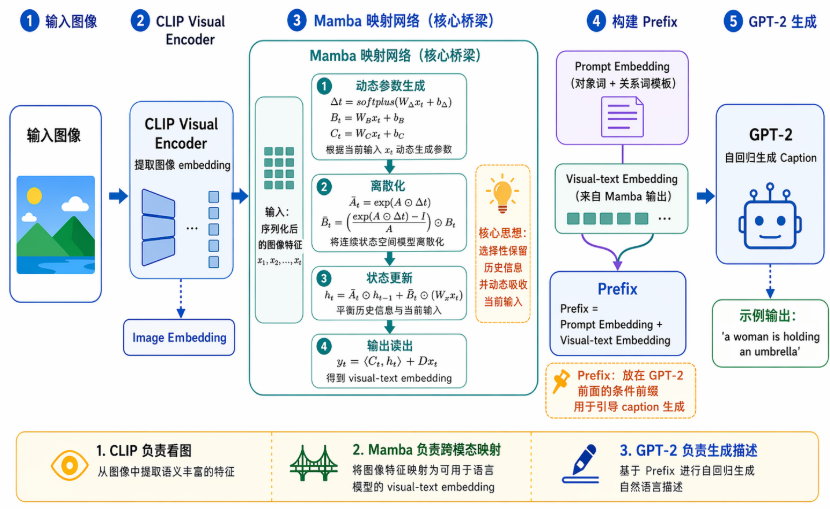
本周内容:
将此片论文中的OREM模块加入了BLIP模型之中,并得到了论文中的效果,对象词比关系词更稳定、更容易进入生成文本;
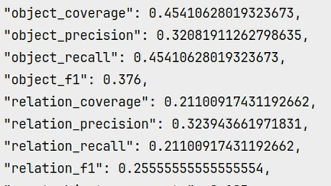
进而又将原有变电站数据集采用此模型进行训练,得到的相关结果展示如下:
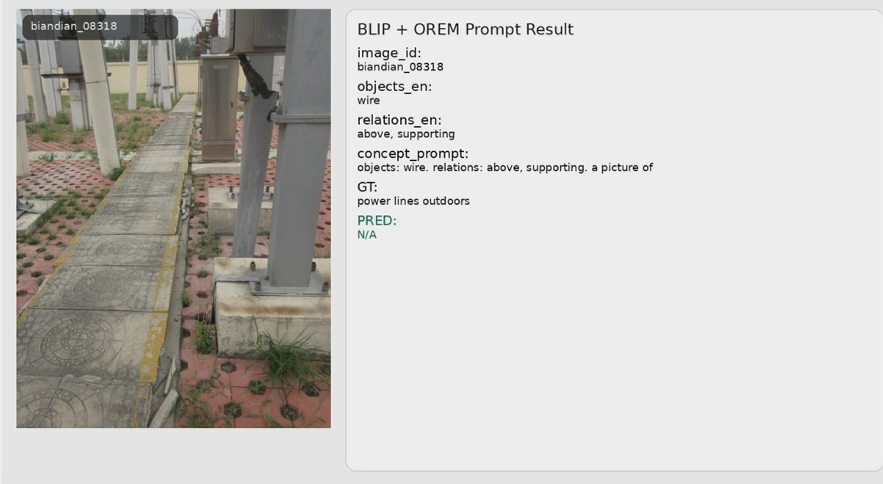

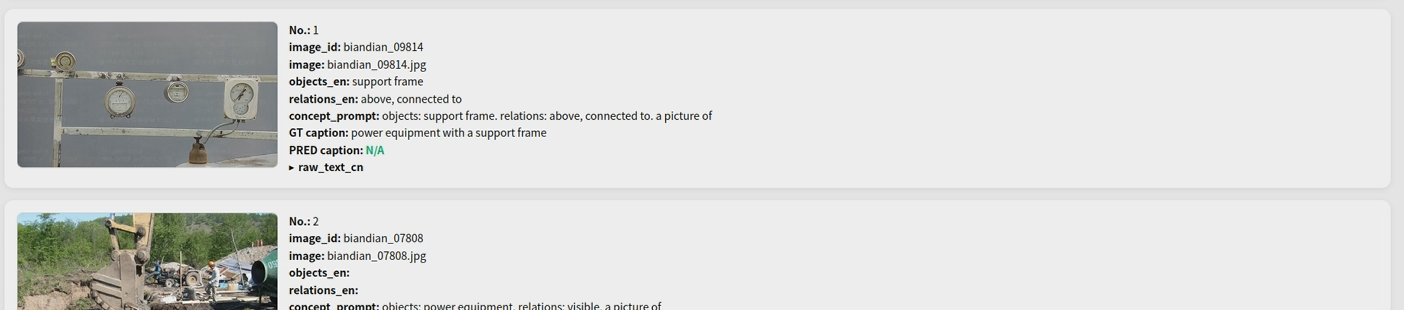
但对齐方面还不太完善,因为原始的图片无描述,用大模型生成的描述格式上对不上,后续还需改进。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)