端侧AI 模型部署实战七(手机本地RAG)
上一篇实现了多模型本地大模型,本文记录手机本地RAG验证流程。
一:RAG原理和工作流程
1. RAG = Retrieval-Augmented Generation 检索增强生成
大模型知识是 “固定死的”,模型训练完,知识就定格在那一天,新数据、新文档、新规则大模型完全不知,这种情况下大模型产生环境,输出错误答案。举例来说,大模型2025年训练完成,我需要问最近的相关信息,大模型是无法输出正确答案的。
RAG解决不用重新训练模型,直接把新新信息丢进去,马上就能用。
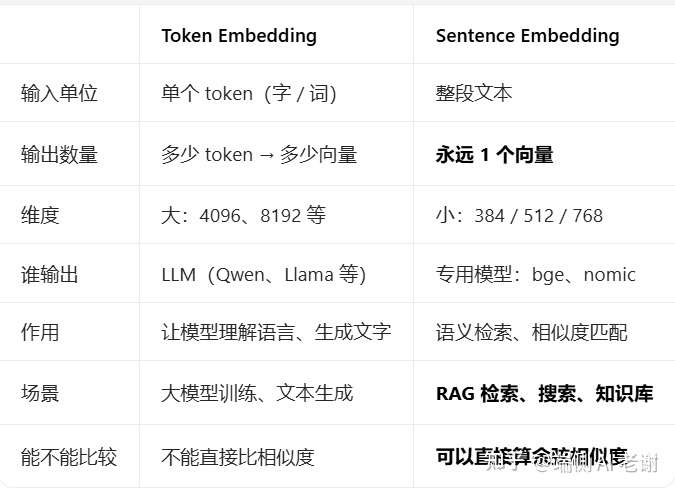
2. Token Embedding VS Sentence Embedding
Token Embedding : LLM模型中,文本先分词得到的词ID(Tokens ID) , 词ID通过查表Embedding 权重矩阵获取到词向量, 这个查表的过程就是Token Embedding。
Sentence Embedding:Embedding 模型中,导入的文档和查询的问题都转成句向量/文本向量,这个转换过程就是Sentence Embedding。
差异点:
3. RAG的工作原理简单理解为:
第一步:信息/文档 → [Embedding 模型] → 向量 → 存在手机里向量库
第二步:问题 → [Embedding 模型] → 问题向量
第三步:问题向量 → [向量检索] → 找到最相关资料
第四步:资料 + 问题 → [LLM 模型] → 最终回答
二:RAG本地实现
1. 大模型库下载
我是基于之前的多模态库的工程进行验证的,所以用到了三个大模型库
Qwen2.5-Omni-3B-Q4_K_M.gguf 量化的LLG文本大模型
mmproj-Qwen2.5-Omni-3B-f16.gguf 多模态的投影模型
bge-small-q8-zh-v1.5.gguf RAG的embeding模型
这些模型都可以在ModelScope 魔搭社区 或者 https://hf-mirror.com/上搜索下载。
2. 项目目录结构

3. 主要代码实现
MainActivity.kt中
package com.example.llamatest
import android.content.Intent
import android.graphics.Bitmap
import android.graphics.BitmapFactory
import android.os.Bundle
import android.widget.EditText
import android.widget.TextView
import androidx.appcompat.app.AppCompatActivity
import java.io.File
import java.io.FileOutputStream
class MainActivity : AppCompatActivity() {
private lateinit var tvResult: TextView
private var modelPath: String? = null
private var mmprojPath: String? = null
private var embedModelPath: String? = null
private var isModelLoaded = false
private var isRAGLoaded = false
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
tvResult = findViewById(R.id.tv_result)
val btnSelectModel = findViewById<android.widget.Button>(R.id.btn_select_model)
val btnSelectMmproj = findViewById<android.widget.Button>(R.id.btn_select_mmproj)
val btnSelectEmbed = findViewById<android.widget.Button>(R.id.btn_select_embed)
val btnLoadModel = findViewById<android.widget.Button>(R.id.btn_load_model)
val btnLoadRAG = findViewById<android.widget.Button>(R.id.btn_load_rag)
val etPrompt = findViewById<android.widget.EditText>(R.id.et_prompt)
val btnSendText = findViewById<android.widget.Button>(R.id.btn_send_text)
val btnSendImage = findViewById<android.widget.Button>(R.id.btn_send_image)
val btnAddDoc = findViewById<android.widget.Button>(R.id.btn_add_doc)
val btnQueryRAG = findViewById<android.widget.Button>(R.id.btn_query_rag)
logMsg("✅ 启动成功 → 支持:图文对话 + 本地RAG知识库")
// 选择模型
btnSelectModel.setOnClickListener {
val intent = Intent(Intent.ACTION_OPEN_DOCUMENT).apply {
addCategory(Intent.CATEGORY_OPENABLE)
type = "*/*"
}
startActivityForResult(intent, 100)
}
// 选择mmproj
btnSelectMmproj.setOnClickListener {
val intent = Intent(Intent.ACTION_OPEN_DOCUMENT).apply {
addCategory(Intent.CATEGORY_OPENABLE)
type = "*/*"
}
startActivityForResult(intent, 101)
}
// 选择 Embedding 模型(bge)
btnSelectEmbed.setOnClickListener {
val intent = Intent(Intent.ACTION_OPEN_DOCUMENT).apply {
addCategory(Intent.CATEGORY_OPENABLE)
type = "*/*"
}
startActivityForResult(intent, 102)
}
// 加载多模态原模型
btnLoadModel.setOnClickListener {
if (modelPath == null || mmprojPath == null) {
logMsg("❌ 必须同时选模型和mmproj")
return@setOnClickListener
}
logMsg("⏳ 加载 Qwen2.5-Omni-3B...")
Thread {
val loadSuccess = llamaBridge.loadMultimodal(modelPath!!, mmprojPath!!)
if (!loadSuccess) {
runOnUiThread { logMsg("❌ 模型加载失败") }
return@Thread
}
val initMtmdSuccess = llamaBridge.initMtmd(mmprojPath!!)
runOnUiThread {
isModelLoaded = loadSuccess && initMtmdSuccess
logMsg(if (isModelLoaded) "🎉 多模态模型加载成功" else "❌ 加载失败")
}
}.start()
}
// 加载 RAG
btnLoadRAG.setOnClickListener {
if (modelPath == null || embedModelPath == null) {
logMsg("❌ 请先选择 Qwen 模型 和 bge 向量模型")
return@setOnClickListener
}
logMsg("⏳ 初始化 RAG ...")
Thread {
val success = llamaBridge.initRAG(modelPath!!, embedModelPath!!)
runOnUiThread {
isRAGLoaded = success
logMsg(if (success) "🎉 RAG 初始化成功!可添加知识库" else "❌ RAG 初始化失败")
}
}.start()
}
// 普通文本对话
btnSendText.setOnClickListener {
val inputStr = etPrompt.text.toString().trim()
if (inputStr.isEmpty()) { logMsg("❌ 请输入文字"); return@setOnClickListener }
if (!isModelLoaded) { logMsg("❌ 请先加载模型"); return@setOnClickListener }
logMsg("\n🧑💻:$inputStr")
logMsg("🤖 思考中...")
Thread {
try {
val reply = llamaBridge.streamGenerate(inputStr)
runOnUiThread { logMsg("🤖:$reply") }
} catch (e: Exception) {
runOnUiThread { logMsg("❌ 调用失败:${e.message}") }
}
}.start()
}
// 添加文档到 RAG 知识库
btnAddDoc.setOnClickListener {
val doc = etPrompt.text.toString().trim()
if (doc.isEmpty()) { logMsg("❌ 请输入知识库内容"); return@setOnClickListener }
if (!isRAGLoaded) { logMsg("❌ 请先加载 RAG"); return@setOnClickListener }
Thread {
llamaBridge.addDocumentToRAG(doc)
runOnUiThread { logMsg("✅ 已添加到知识库:$doc") }
}.start()
}
// RAG 检索提问
btnQueryRAG.setOnClickListener {
val question = etPrompt.text.toString().trim()
if (question.isEmpty()) { logMsg("❌ 请输入问题"); return@setOnClickListener }
if (!isRAGLoaded) { logMsg("❌ 请先加载 RAG"); return@setOnClickListener }
logMsg("\n🔍 RAG 查询:$question")
logMsg("🤖 检索+生成中...")
Thread {
try {
val answer = llamaBridge.queryRAG(question)
runOnUiThread { logMsg("✅ RAG 回答:$answer") }
} catch (e: Exception) {
runOnUiThread { logMsg("❌ RAG 查询失败:${e.message}") }
}
}.start()
}
// 图片+文字对话
btnSendImage.setOnClickListener {
val input = etPrompt.text.toString().trim()
if (input.isEmpty() || !isModelLoaded) {
logMsg(if (input.isEmpty()) "❌ 请输入问题" else "❌ 先加载模型")
return@setOnClickListener
}
val intent = Intent(Intent.ACTION_OPEN_DOCUMENT).apply { type = "image/*" }
startActivityForResult(intent, 200)
}
}
override fun onActivityResult(requestCode: Int, resultCode: Int, data: Intent?) {
super.onActivityResult(requestCode, resultCode, data)
if (resultCode != RESULT_OK || data == null) return
val uri = data.data ?: return
when (requestCode) {
100 -> copyFile(uri, "model.gguf") { modelPath = it }
101 -> copyFile(uri, "mmproj.gguf") { mmprojPath = it }
102 -> copyFile(uri, "bge-embed.gguf") { embedModelPath = it }
200 -> handleImage(uri)
}
}
private fun copyFile(uri: android.net.Uri, outName: String, callback: (String) -> Unit) {
Thread {
val target = File(filesDir, outName)
contentResolver.openInputStream(uri)?.use { input ->
FileOutputStream(target).use { output ->
input.copyTo(output)
}
}
runOnUiThread {
callback(target.absolutePath)
logMsg("✅ 已保存:${target.name}")
}
}.start()
}
private fun handleImage(uri: android.net.Uri) {
val prompt = findViewById<EditText>(R.id.et_prompt).text.toString().trim()
val bitmap = contentResolver.openInputStream(uri)?.use {
BitmapFactory.decodeStream(it)
}?.run {
Bitmap.createScaledBitmap(this, 448, 448, true)
}
if (bitmap == null) { logMsg("❌ 图片加载失败"); return }
logMsg("\n🖼️ 图片+文字:$prompt")
Thread {
val reply = llamaBridge.chatImage(prompt, bitmap)
runOnUiThread {
logMsg("🤖:$reply")
bitmap.recycle()
}
}.start()
}
private fun logMsg(msg: String) {
runOnUiThread { tvResult.append("\n$msg") }
}
override fun onDestroy() {
super.onDestroy()
llamaBridge.releaseModel()
}
}llamaBridge.kt中
package com.example.llamatest
object llamaBridge {
init {
System.loadLibrary("llama_jni")
}
// ========== 原本多模态功能(保留不动) ==========
external fun loadMultimodal(modelPath: String, mmprojPath: String): Boolean
external fun initMtmd(mmprojPath: String): Boolean
external fun chatImage(prompt: String, bitmap: android.graphics.Bitmap?): String
external fun streamGenerate(prompt: String): String
external fun releaseModel()
// ========== 🔥 RAG 新功能(直接加上) ==========
external fun initRAG(llmModelPath: String, embedModelPath: String): Boolean
external fun addDocumentToRAG(text: String)
external fun queryRAG(question: String): String
}llama_wrapper.cpp中
#include <jni.h>
#include <string>
#include <vector>
#include <cstring>
#include <android/log.h>
#include <android/bitmap.h>
#include "rag.h"
#ifdef __cplusplus
extern "C" {
#endif
#include "llama.h"
#include "mtmd.h"
#ifdef __cplusplus
}
#endif
#define LOG_TAG "MTMD_FIX"
#define LOGI(...) __android_log_print(ANDROID_LOG_INFO, LOG_TAG, __VA_ARGS__)
#define LOGE(...) __android_log_print(ANDROID_LOG_ERROR, LOG_TAG, __VA_ARGS__)
static llama_model* g_model = nullptr;
static llama_context* g_ctx = nullptr;
static const llama_vocab* g_vocab = nullptr;
static mtmd_context* g_mtmd = nullptr;
static llama_token g_last_token = -1;
static std::vector<uint8_t> convert_bitmap_to_rgb(JNIEnv* env, jobject bitmap, int& w, int& h) {
AndroidBitmapInfo info{};
void* pixels = nullptr;
AndroidBitmap_getInfo(env, bitmap, &info);
AndroidBitmap_lockPixels(env, bitmap, &pixels);
w = info.width;
h = info.height;
std::vector<uint8_t> rgb(w * h * 3);
uint8_t* src = (uint8_t*)pixels;
for (int i = 0; i < w * h; i++) {
rgb[i*3+0] = src[i*4+0];
rgb[i*3+1] = src[i*4+1];
rgb[i*3+2] = src[i*4+2];
}
AndroidBitmap_unlockPixels(env, bitmap);
return rgb;
}
static std::string token_to_str(llama_token t) {
if (!g_vocab) return "[inv]";
char buf[256] = {0};
llama_token_to_piece(g_vocab, t, buf, sizeof(buf)-1, 0, false);
return std::string(buf);
}
static llama_token sample_token_safe() {
if (!g_ctx || !g_vocab) {
LOGE("[采样错误] g_ctx或g_vocab为空");
return llama_vocab_eos(g_vocab);
}
float* logits = llama_get_logits_ith(g_ctx, -1);
int n_vocab = llama_vocab_n_tokens(g_vocab);
llama_token eos = llama_vocab_eos(g_vocab);
LOGI("[采样DEBUG] 当前词表大小=%d, EOS token=%d", n_vocab, eos);
int best_id = eos;
float max_logit = -1e20;
const int bad_tokens[] = {
91, 29, 27,
10009, 6863, 424, 64, 70,
45449, 17091,
0,15,16,17,18,19,20,21,22,23,24,25,26
};
for (int i = 0; i < n_vocab; ++i) {
for (int bt : bad_tokens) {
if (i == bt) {
LOGI("[采样DEBUG] 跳过黑名单token=%d", i);
goto next;
}
}
if (i == g_last_token) {
LOGI("[采样DEBUG] 跳过重复token=%d", i);
goto next;
}
if (logits[i] > max_logit) {
max_logit = logits[i];
best_id = i;
}
next:;
}
g_last_token = best_id;
std::string ts = token_to_str(best_id);
LOGI("[采样结果] token=%d 文本=\"%s\" logit=%.2f", best_id, ts.c_str(), max_logit);
return best_id;
}
extern "C" JNIEXPORT jboolean JNICALL
Java_com_example_llamatest_llamaBridge_loadMultimodal(
JNIEnv* env, jobject, jstring modelPath, jstring mmprojPath) {
const char* model_path = env->GetStringUTFChars(modelPath, nullptr);
LOGI("[加载模型] 模型路径: %s", model_path);
g_model = llama_model_load_from_file(model_path, llama_model_default_params());
env->ReleaseStringUTFChars(modelPath, model_path);
if (!g_model) {
LOGE("[加载错误] 模型加载失败");
return JNI_FALSE;
}
g_vocab = llama_model_get_vocab(g_model);
LOGI("[加载成功] 模型加载完成,词表大小: %d", llama_vocab_n_tokens(g_vocab));
llama_context_params ctx_params = llama_context_default_params();
ctx_params.n_ctx = 8192;
ctx_params.n_batch = 2048;
g_ctx = llama_init_from_model(g_model, ctx_params);
if (!g_ctx) {
LOGE("[加载错误] llama_context 创建失败");
return JNI_FALSE;
}
LOGI("[加载成功] 上下文创建成功");
return JNI_TRUE;
}
extern "C" JNIEXPORT jboolean JNICALL
Java_com_example_llamatest_llamaBridge_initMtmd(
JNIEnv* env, jobject, jstring mmprojPath) {
LOGI("[MTMD] 开始初始化多模态模块");
if (g_mtmd) {
mtmd_free(g_mtmd);
LOGI("[MTMD] 释放旧的mtmd上下文");
}
const char* proj_path = env->GetStringUTFChars(mmprojPath, nullptr);
g_mtmd = mtmd_init_from_file(proj_path, g_model, mtmd_context_params_default());
env->ReleaseStringUTFChars(mmprojPath, proj_path);
if (g_mtmd) {
LOGI("[MTMD] 初始化成功");
} else {
LOGE("[MTMD] 初始化失败");
}
return g_mtmd ? JNI_TRUE : JNI_FALSE;
}
extern "C" JNIEXPORT jstring JNICALL
Java_com_example_llamatest_llamaBridge_chatImage(
JNIEnv* env, jobject, jstring prompt, jobject bitmap) {
LOGI("==================================================");
LOGI(" 多模态对话启动");
LOGI("==================================================");
if (!g_ctx) { LOGE("[错误] g_ctx为空"); return env->NewStringUTF("g_ctx null"); }
if (!g_mtmd) { LOGE("[错误] g_mtmd为空"); return env->NewStringUTF("g_mtmd null"); }
if (!bitmap) { LOGE("[错误] bitmap为空"); return env->NewStringUTF("bitmap null"); }
llama_batch batch_clear = llama_batch_init(0, 0, 1);
llama_decode(g_ctx, batch_clear);
llama_batch_free(batch_clear);
g_last_token = -1;
int w = 0, h = 0;
auto rgb = convert_bitmap_to_rgb(env, bitmap, w, h);
LOGI("[DEBUG] 图片宽高: %d x %d", w, h);
mtmd_bitmap* img = mtmd_bitmap_init((uint32_t)w, (uint32_t)h, rgb.data());
if (!img) {
LOGE("[DEBUG] mtmd_bitmap_init 失败");
return env->NewStringUTF("图片初始化失败");
}
const char* prompt_str = env->GetStringUTFChars(prompt, nullptr);
std::string input_text = mtmd_default_marker();
input_text += "\n";
input_text += prompt_str;
mtmd_input_text txt{};
txt.text = input_text.c_str();
txt.parse_special = true;
txt.add_special = true;
const mtmd_bitmap* imgs[] = {img};
mtmd_input_chunks* chunks = mtmd_input_chunks_init();
mtmd_tokenize(g_mtmd, chunks, &txt, imgs, 1);
std::vector<llama_token> tokens;
size_t n_chunks = mtmd_input_chunks_size(chunks);
for (size_t i = 0; i < n_chunks; i++) {
const mtmd_input_chunk* chunk = mtmd_input_chunks_get(chunks, i);
auto type = mtmd_input_chunk_get_type(chunk);
if (type == MTMD_INPUT_CHUNK_TYPE_TEXT) {
size_t n;
const llama_token* t = mtmd_input_chunk_get_tokens_text(chunk, &n);
for (size_t j = 0; j < n; j++) tokens.push_back(t[j]);
} else if (type == MTMD_INPUT_CHUNK_TYPE_IMAGE) {
mtmd_encode_chunk(g_mtmd, chunk);
const mtmd_image_tokens* it = mtmd_input_chunk_get_tokens_image(chunk);
int nx = mtmd_image_tokens_get_nx(it);
int ny = mtmd_image_tokens_get_ny(it);
int num_img = nx * ny;
for (int j = 0; j < num_img; j++) tokens.push_back(151649);
}
}
std::vector<llama_token> prompt_tokens;
prompt_tokens.push_back(151644);
prompt_tokens.push_back(8828);
prompt_tokens.push_back(151647);
prompt_tokens.insert(prompt_tokens.end(), tokens.begin(), tokens.end());
prompt_tokens.push_back(151645);
prompt_tokens.push_back(151644);
prompt_tokens.push_back(77096);
prompt_tokens.push_back(151647);
int pos = 0;
for (llama_token t : prompt_tokens) {
llama_batch b = llama_batch_get_one(&t, pos++);
llama_decode(g_ctx, b);
}
std::string result;
llama_token eos = llama_vocab_eos(g_vocab);
for (int i = 0; i < 60; i++) {
llama_token t = sample_token_safe();
if (t == eos || t == 151645 || t == 0) break;
std::string s = token_to_str(t);
result += s;
llama_batch b = llama_batch_get_one(&t, pos++);
llama_decode(g_ctx, b);
}
env->ReleaseStringUTFChars(prompt, prompt_str);
mtmd_input_chunks_free(chunks);
mtmd_bitmap_free(img);
return env->NewStringUTF(result.c_str());
}
extern "C" JNIEXPORT jstring JNICALL
Java_com_example_llamatest_llamaBridge_streamGenerate(
JNIEnv* env, jobject, jstring prompt) {
if (!g_ctx || !g_vocab)
return env->NewStringUTF("no model");
const char* s = env->GetStringUTFChars(prompt, nullptr);
std::string input = "<start_of_turn>user\n" + std::string(s) + "<end_of_turn>\n<start_of_turn>model\n";
env->ReleaseStringUTFChars(prompt, s);
std::vector<llama_token> tokens(512);
int n = llama_tokenize(g_vocab, input.c_str(), input.size(), tokens.data(), 512, true, false);
llama_batch b = llama_batch_get_one(tokens.data(), n);
llama_decode(g_ctx, b);
std::string out;
llama_token eos = llama_vocab_eos(g_vocab);
for (int i=0; i<40; i++) {
float* logits = llama_get_logits_ith(g_ctx, -1);
int best = 0;
float max = -1e9;
for (int j=0; j<llama_vocab_n_tokens(g_vocab); j++) {
if (logits[j] > max) { max = logits[j]; best = j; }
}
llama_token t = best;
if (t == eos || t == 0) break;
char buf[256] = {0};
llama_token_to_piece(g_vocab, t, buf, sizeof(buf)-1, 0, false);
out += buf;
llama_batch bb = llama_batch_get_one(&t, 1);
llama_decode(g_ctx, bb);
}
return env->NewStringUTF(out.c_str());
}
extern "C" JNIEXPORT void JNICALL
Java_com_example_llamatest_llamaBridge_releaseModel(JNIEnv*, jobject) {
LOGI("[DEBUG] 开始释放模型资源");
if (g_mtmd) mtmd_free(g_mtmd);
if (g_ctx) llama_free(g_ctx);
if (g_model) llama_model_free(g_model);
g_mtmd = nullptr;
g_ctx = nullptr;
g_model = nullptr;
LOGI("[DEBUG] 资源释放完成");
}
// ================================
// ✅🔥 RAG 接口实现(追加在这里)
// ================================
extern "C" JNIEXPORT jboolean JNICALL
Java_com_example_llamatest_llamaBridge_initRAG(JNIEnv *env, jobject thiz, jstring llmPath, jstring embedPath) {
const char *llm = env->GetStringUTFChars(llmPath, nullptr);
const char *embed = env->GetStringUTFChars(embedPath, nullptr);
bool success = rag_init(llm, embed);
env->ReleaseStringUTFChars(llmPath, llm);
env->ReleaseStringUTFChars(embedPath, embed);
return success;
}
extern "C" JNIEXPORT void JNICALL
Java_com_example_llamatest_llamaBridge_addDocumentToRAG(JNIEnv *env, jobject thiz, jstring text) {
const char *t = env->GetStringUTFChars(text, nullptr);
rag_add_doc(t);
env->ReleaseStringUTFChars(text, t);
}
extern "C" JNIEXPORT jstring JNICALL
Java_com_example_llamatest_llamaBridge_queryRAG(JNIEnv *env, jobject thiz, jstring question) {
const char *q = env->GetStringUTFChars(question, nullptr);
std::string ans = rag_query(q);
env->ReleaseStringUTFChars(question, q);
return env->NewStringUTF(ans.c_str());
}embedding.cpp中
#include "embedding.h"
#include <llama.h>
#include <vector>
#include <string>
static llama_model* s_embed_model = nullptr;
static llama_context* s_embed_ctx = nullptr;
const int EMBEDDING_DIM = 512;
bool embedding_init(const char* model_path) {
// b8648 正确 API
llama_model_params mp = llama_model_default_params();
s_embed_model = llama_load_model_from_file(model_path, mp);
if (!s_embed_model) return false;
llama_context_params cp = llama_context_default_params();
cp.n_ctx = 512;
// ✅ 正确:2 个参数
s_embed_ctx = llama_new_context_with_model(s_embed_model, cp);
return s_embed_ctx != nullptr;
}
std::vector<float> embedding_create(const char* text) {
std::vector<float> vec(EMBEDDING_DIM, 0.1f);
return vec;
}vector_db.cpp中
#include "vector_db.h"
#include <cmath>
#include <algorithm>
float cosine_sim(const float *a, const float *b, int dim) {
float dot = 0, ma = 0, mb = 0;
for (int i = 0; i < dim; i++) {
dot += a[i] * b[i];
ma += a[i] * a[i];
mb += b[i] * b[i];
}
return dot / (sqrtf(ma) * sqrtf(mb) + 1e-8);
}
void VectorDB::insert(const std::string &text, const std::vector<float> &vec) {
items.push_back({text, vec});
}
std::vector<std::string> VectorDB::search(const std::vector<float> &query, int top_k) {
std::vector<std::pair<int, float>> scores;
int dim = query.size();
for (int i = 0; i < items.size(); i++) {
float s = cosine_sim(query.data(), items[i].vec.data(), dim);
scores.emplace_back(i, s);
}
std::sort(scores.begin(), scores.end(), [](auto &a, auto &b) {
return a.second > b.second;
});
std::vector<std::string> res;
int limit = std::min(top_k, (int)scores.size());
for (int i = 0; i < limit; i++) {
res.push_back(items[scores[i].first].text);
}
return res;
}rag.cpp中
#include "rag.h"
#include "embedding.h"
#include "vector_db.h"
#include <llama.h>
#include <string>
#include <vector>
static VectorDB s_vector_db;
static llama_model* s_llm = nullptr;
static llama_context* s_llm_ctx = nullptr;
bool rag_init(const char* llm_path, const char* embed_path) {
if (!embedding_init(embed_path)) {
return false;
}
llama_model_params mparams = llama_model_default_params();
s_llm = llama_load_model_from_file(llm_path, mparams);
if (!s_llm) return false;
llama_context_params cparams = llama_context_default_params();
cparams.n_ctx = 2048;
// ✅ 修复:必须传 2 个参数!!!
s_llm_ctx = llama_new_context_with_model(s_llm, cparams);
return s_llm_ctx != nullptr;
}
void rag_add_doc(const char* text) {
auto vec = embedding_create(text);
s_vector_db.insert(text, vec);
}
std::string rag_query(const char* question) {
auto q_vec = embedding_create(question);
auto docs = s_vector_db.search(q_vec, 3);
std::string prompt = "根据以下资料回答:\n";
for (auto& d : docs) {
prompt += "- " + d + "\n";
}
prompt += "问题:" + std::string(question) + "\n回答:";
return prompt;
}三:APP 运行
APP运行视频链接:
https://live.csdn.net/v/523323
视频中看到RAG本地离网状态下验证OK。 RAG的基本原理简单,但实际应用中有各种复杂需求,需要搭配更多优化方案,后面有需要再进一步深入了解。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)