DeepSeek-V4百万上下文开源,Agent开发的天花板被推高了吗?
结合2026斯坦福AI报告与近期行业动态,解析DeepSeek-V4的Agent能力、长上下文架构以及它对开发者生态的真实影响。
一、这次发布到底更新了什么
4月24日,DeepSeek正式发布了V4预览版,同步开源权重和技术报告。这不是一次常规的版本迭代,几个关键变化值得开发者认真关注。
百万上下文来了
1M tokens,换算成中文大约是70-80万字,可以装下整部《三体》三部曲还有富余。
这个能力的实现靠的是全新的注意力机制设计。DeepSeek在token维度做了压缩处理,结合DSA稀疏注意力(DeepSeek Sparse Attention),在不显著增加算力成本的前提下实现了超长上下文。从官方公布的曲线来看,相比传统full attention方案,V4的计算量和显存占用随上下文长度增长的速度明显更平缓。
这对于做Agent开发的团队来说意义重大。之前Agent的上下文窗口普遍在128K到200K之间,处理复杂的多步骤任务时经常需要RAG或分段记忆来做补充。1M上下文意味着很多场景下可以省掉这层额外工程。
Agent能力专项优化
DeepSeek官方明确表示V4针对Claude Code、OpenClaw、CodeBuddy等主流Agent产品做了适配优化。在Agentic Coding评测中,V4-Pro达到了当前开源模型的最佳水平。
更值得关注的是内部评测数据:使用体验优于Sonnet 4.5,交付质量接近Opus 4.6非思考模式。虽然与Opus 4.6思考模式仍有差距,但作为开源模型能达到这个水平,本身就是一个信号——开源模型在Agent场景下的可用性已经有了质的提升。
双版本策略
V4-Pro对标顶级闭源模型,数学、STEM、竞赛代码评测中表现突出。世界知识测评大幅领先其他开源模型,仅稍逊于Gemini-Pro-3.1。
V4-Flash参数规模更小,推理能力接近Pro版,但世界知识储备和复杂Agent任务上有差距。在简单Agent任务上与Pro版旗鼓相当,面向对成本更敏感或对响应速度有要求的场景。
API接口变更需要注意
现有的deepseek-chat和deepseek-reasoner两个接口名将在三个月后(2026-07-23)停用,需要迁移至deepseek-v4-pro或deepseek-v4-flash。目前这两个旧接口名指向的是V4-Flash版本。
正在使用DeepSeek API的项目需要尽快排查调用代码,修改model_name参数。如果项目中同时用到了思考模式,需要注意reasoning_effort参数的设置方式。
二、放在行业背景下看
2026年斯坦福AI指数报告有几组数据可以用来对照这次发布。
95%的顶尖模型来自企业而非高校。 DeepSeek这次开源+企业级Agent优化的组合拳,正是这一趋势的体现。开源模型的竞争力不仅体现在benchmark分数上,更体现在对实际开发场景的支持深度。斯坦福报告同时指出,中国在开源生态和论文专利方面表现强劲,DeepSeek-V4也是这个趋势的延续。
AI编程能力已达SWbench 100%通过率,但Agent能力才刚刚起步。 斯坦福报告提出的"巨齿前沿"概念仍然适用——模型在某些标准化任务上已超人类,但在复杂的多步骤Agent任务上仍有明显不足。DeepSeek-V4的Agent专项优化正是针对这一差距。
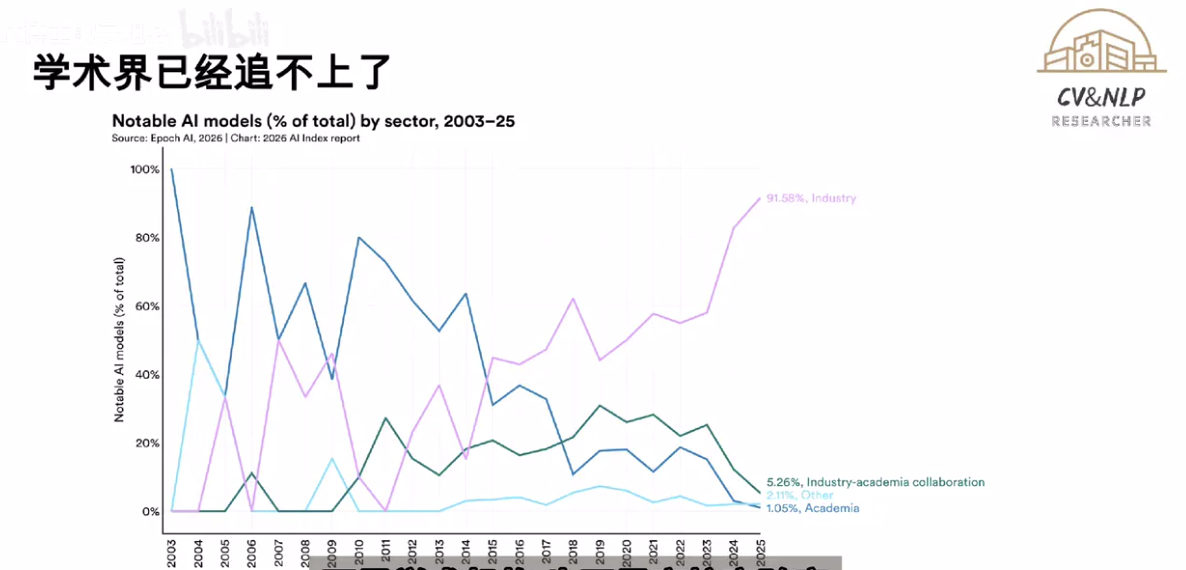
算力需求3年暴涨30倍,效率创新成为关键。 此前AI日报也提到,全球AI光模块市场今年增长57.6%达到260亿美元,AMD研发MI500芯片采用CPO技术传输速度突破19.6TB/秒。在算力供给日趋紧张的背景下,DSA稀疏注意力这种架构层面的创新,比单纯堆算力更有意义。
全球Agent竞赛正在加速。 谷歌布林亲自组建DeepMind精英团队提升Gemini编程能力,谷歌内部强制推行AI编码工作流。亚马逊与Anthropic签下千亿美元长约提供5GW Trainium芯片算力。DeepSeek-V4在这个节点加强Agent能力,目标很明确。
三、对开发者意味着什么
上下文工程的成本降低
以前做Agent开发,上下文管理是最磨人的环节之一。模型窗口就那么大,怎么塞prompt、怎么截断历史记录、怎么在关键信息丢失时通过RAG补偿——这些都是绕不开的工程问题。
1M上下文不能完全消除这些问题,但能显著降低它们的频率。整份项目的核心代码库可以一次塞进Agent的"工作记忆",不需要频繁做RAG召回。对于代码审查、大规模重构、跨文件分析这类任务,体验提升是很明显的。
API迁移的时间窗口
三个月的时间说长不长说短不短。如果项目里直接硬编码了deepseek-chat或deepseek-reasoner,建议尽快改成可配置的变量,避免到时候手忙脚乱。
如果项目依赖的是这两个旧接口在思考模式和非思考模式之间的自动切换逻辑,迁移后需要手动指定model_name和reasoning_effort参数。对于复杂Agent场景,官方建议使用思考模式并将reasoning_effort设为max。
信息量本身也在爆炸
DeepSeek发布、斯坦福报告、谷歌布林亲自带队、亚马逊千亿投资——这些信息对开发者来说都是需要消化的。
我自己的经验是,不要试图全部看完。判断优先级比执行更重要。对于确定要深读的内容,我会找视频或播客形式的深度解读来辅助理解,因为很多技术博主会在视频里把论文核心和实战经验揉在一起讲,比纯文字效率高。
但我不会从头到尾看完一整段视频。我的做法是把视频链接丢到Ai好记里,它会自动把视频转成图文笔记,PPT画面截取出来,对应的文字对齐好,不同说话人也区分标记。我需要回顾某个技术细节时直接在笔记里搜就行,不用再拖进度条。

最常用的是划线总结功能。看笔记时遇到不懂的概念或感兴趣的术语,直接划线,AI会基于视频上下文给出解释和追问。比暂停、截图、打开搜索引擎、筛选结果快了太多。
对于需要快速了解的内容,比如这次DeepSeek-V4的API文档变更,我会用精华速览功能,AI几秒提炼全篇要点,不用逐行翻。
这套流程帮我省下了不少时间,省下来的时间用来写代码和做判断,而不是消耗在"看完"这件事上。
四、总结
DeepSeek-V4的发布,不是某个单项指标的突破,而是一系列工程创新的整合:更高效的注意力机制、面向Agent的专项优化、开源生态的持续投入。对于做Agent开发的团队来说,这是一次值得跟进的技术迭代。
斯坦福报告说AI能力的分布是不均匀的。找到最匹配你方向的工具和模型,把精力花在最有价值的地方,比追逐每个热点更值得。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)