实现一个 KV Cache 卸载引擎:用 C++ 把大模型的显存压力赶到磁盘上去
第一部分:Why —— 问题从哪里来
1.1 大模型推理的“隐形杀手”
如果你曾经用大语言模型(LLM)生成长文本,你一定遇到过这种情况:
刚开始对话时,模型响应飞快;但随着上下文越来越长,生成速度越来越慢,某个瞬间突然报错
CUDA out of memory,整个推理进程崩溃。
这个问题的根源,藏在 Transformer 架构的核心机制 —— Self-Attention 里。
当模型生成第 N 个 token 时,它需要“回顾”前面所有 N-1 个 token 的 Key 和 Value 矩阵。为了不重复计算,推理引擎会把已生成的 K/V 张量缓存起来,这就是 KV Cache。
听起来没什么问题?我们算一笔账:
假设我们使用一个常见的开源模型(如 Llama-2-7B):
-
层数:32 层
-
头数:32
-
头维度:128
-
数据类型:FP16(每个元素 2 字节)
-
上下文长度:4096 tokens
那么 KV Cache 占用的显存大小计算如下:
text
每层的 KV Cache = 2 × 32(头数) × 4096(序列长度) × 128(头维度) × 2(字节) = 64 MB
32 层的总 KV Cache = 32 × 64 MB = 2048 MB ≈ 2 GB也就是说,仅一个 4096 token 的上下文,就要吃掉 2 GB 显存只用来存 KV Cache。
当上下文扩展到 128K tokens(很多长文本模型的标配),这个数字会膨胀到:
text
2048 MB × 128K / 4K = 2048 × 32 = 65 GB65 GB 显存! 而一张消费级显卡(比如 RTX 3060)只有 6 GB,旗舰级的 H100 也只有 80 GB。
这就是大模型推理的“隐形杀手”:KV Cache 随序列长度线性增长,很快成为显存的最大占用者。
1.2 工业界的解题思路:把 KV Cache 赶到便宜的地方去
面对这个瓶颈,工业界和学术界提出了一个朴素但有效的思路:
GPU 显存(HBM)又小又贵,CPU 内存(DRAM)又大又便宜,SSD 更是海量。能不能把“暂时用不上的”KV Cache 块,从显存挪到内存,甚至磁盘上去?
这被称为 KV Cache Offloading(卸载)。
以下是几个代表性工作:
| 方案 | 核心思路 | 存储层级 |
|---|---|---|
| vLLM | PagedAttention:将 KV Cache 分块,类似操作系统的虚拟内存管理 | HBM ↔ DRAM |
| FlexGen | 沿序列维度切分,把冷 Token 卸载到 DRAM 和 SSD | HBM ↔ DRAM ↔ SSD |
| llama.cpp | 通过量化压缩 + 内存映射(mmap),把模型权重和 KV Cache 放在 CPU 内存里推理 | DRAM ↔ SSD |
| 三星 / 华为 等存储厂商 | 研发 CXL 内存扩展、SmartSSD 等硬件,让 SSD 能直接参与 AI 计算的内存池 | HBM ↔ CXL ↔ NVMe SSD |
这些方案的核心,都围绕存储层级做文章:利用不同存储介质的速度/容量/成本差异,将 KV Cache 的“冷数据”往下挪,热数据留在上层。
1.3 我们的目标:自己动手实现一个迷你版卸载引擎
理解了问题和技术趋势后,我萌生了一个想法:
能不能用 C++ 自己写一个最轻量的 KV Cache 卸载引擎原型?不用 CUDA,不依赖真实显存,只用内存池模拟 HBM 的容量限制,用本地 SSD 当作远端存储,手动实现“选哪个块卸载”“怎么存磁盘”“怎么快速找回来”这一整套逻辑?
这个项目的目标不是造一个能跑 GPT 的推理引擎,而是:
-
透彻理解 KV Cache 的存储调度逻辑(LRU 驱逐、内存池管理、磁盘 I/O)。
-
验证“内存↔磁盘”透明卸载的可行性,用 Benchmark 数据说话。
-
展示自己能用系统级语言(C++)解决 AI 基础设施中的存储瓶颈。
这就是本文要带你实现的项目 —— 一个不到 500 行代码的 LLM KV Cache Offloader。
接下来,我们先看看整体的架构设计,然后逐段拆解核心代码。
第二部分:架构设计 —— 三层存储与调度器
2.1 整体架构:一个三层金字塔
在真实的大模型推理引擎中,KV Cache 存储的层级关系如下:
text
┌─────────────────┐
│ GPU HBM │ ← 最快(~2 TB/s 带宽)、最小(40/80 GB)
│ (KV Cache) │
└────────┬────────┘
│ 卸载冷块
┌────────▼────────┐
│ CPU DRAM │ ← 较快(~50 GB/s)、较大(数百 GB)
│ (KV Cache) │
└────────┬────────┘
│ 换出更冷的块
┌────────▼────────┐
│ NVMe SSD │ ← 最慢(~7 GB/s)、巨大(TB 级)
│ (序列化 KV 块) │
└─────────────────┘
我们项目的简化版中:
-
GPU 显存层 → 用一个固定大小的内存池(
char[]数组)模拟,容量严格受限。 -
CPU 内存层 → 在当前实现中暂时与内存池合并(未来可扩展为二级缓存)。
-
NVMe SSD 层 → 用本地文件系统(
./cache_disk/目录下的.bin文件)模拟。
核心调度器 KVCacheOffloader 负责在这三层之间搬运 KV Cache Block:当内存池快满时,根据 LRU 策略选出最久没被访问的块,序列化成二进制文件写到磁盘;当后续推理需要这个块时,再从磁盘反序列化加载回内存池。
2.2 核心类的设计
整个引擎封装在一个类 KVCacheOffloader 中。我们先看它的对外接口:
cpp
class KVCacheOffloader {
public:
// 构造函数:指定内存池大小(MB)和磁盘缓存目录
KVCacheOffloader(double memory_pool_mb, const std::string& disk_dir);
~KVCacheOffloader();
// 往缓存中放入一个 KV Cache Block
bool put(int token_id, CacheBlock block);
// 根据 token_id 获取一个 KV Cache Block(可能从磁盘加载)
std::optional<CacheBlock> get(int token_id);
// 查看命中率等统计信息
Stats get_stats() const;
};这里的 CacheBlock 是我们要存储的基本单元:
cpp
struct CacheBlock {
int layer_id; // 来自哪一层 Transformer
std::vector<float> key_tensor; // K 矩阵展开成 1D 向量
std::vector<float> value_tensor; // V 矩阵展开成 1D 向量
};实际上,CacheBlock 内包含的 vector 占大部分存储,对象本身(指针加尺寸)只有几十字节。因此我们的内存池管理的是对象本身,而向量数据继续在堆上分配,这在原型阶段是可以接受的简化。
2.3 内部组件划分
KVCacheOffloader 内部可以分为四个逻辑模块:
① 内存池管理器
-
预分配一块大内存
pool_buffer_(类型unique_ptr<char[]>)。 -
提供
allocate_aligned()函数:在池内根据对齐要求分配空间,返回地址和实际占用字节数(含对齐填充)。 -
优先从 空闲链表
free_list_中查找是否已有合适的释放块,没有再从池尾部扩展。
② LRU 驱逐策略
-
维护一个双向链表
lru_list_,最近被访问的 token_id 放在链表头部,最久未用的放在尾部。 -
用一个哈希表
lru_map_把token_id映射到链表中的迭代器,以便在 O(1) 时间内将一个 token 移动到头部。 -
当池空间不足时,调用
evict_one()弹出链表尾部的 token,将其对应的CacheBlock写入磁盘,然后回收其占用的内存块加入free_list_。
③ 磁盘 I/O 层
-
实现
write_block_to_disk()和read_block_from_disk(),将被驱逐的CacheBlock序列化为二进制文件(按顺序写入layer_id、向量维度、浮点数据),需要时反向反序列化。 -
预留了 Direct I/O 接口(注释中说明),可以在未来绕过 Page Cache 实现更真实的存储路径。
④ 统计信息模块
-
在
get()中记录内存命中次数、磁盘命中次数、未命中次数,以及从磁盘加载的平均延迟。 -
方便进行 Benchmark 分析和面试时的量化展示。
2.4 一次完整的 get 请求流程
以一次 get(5) 的请求为例,内部流转如下图所示: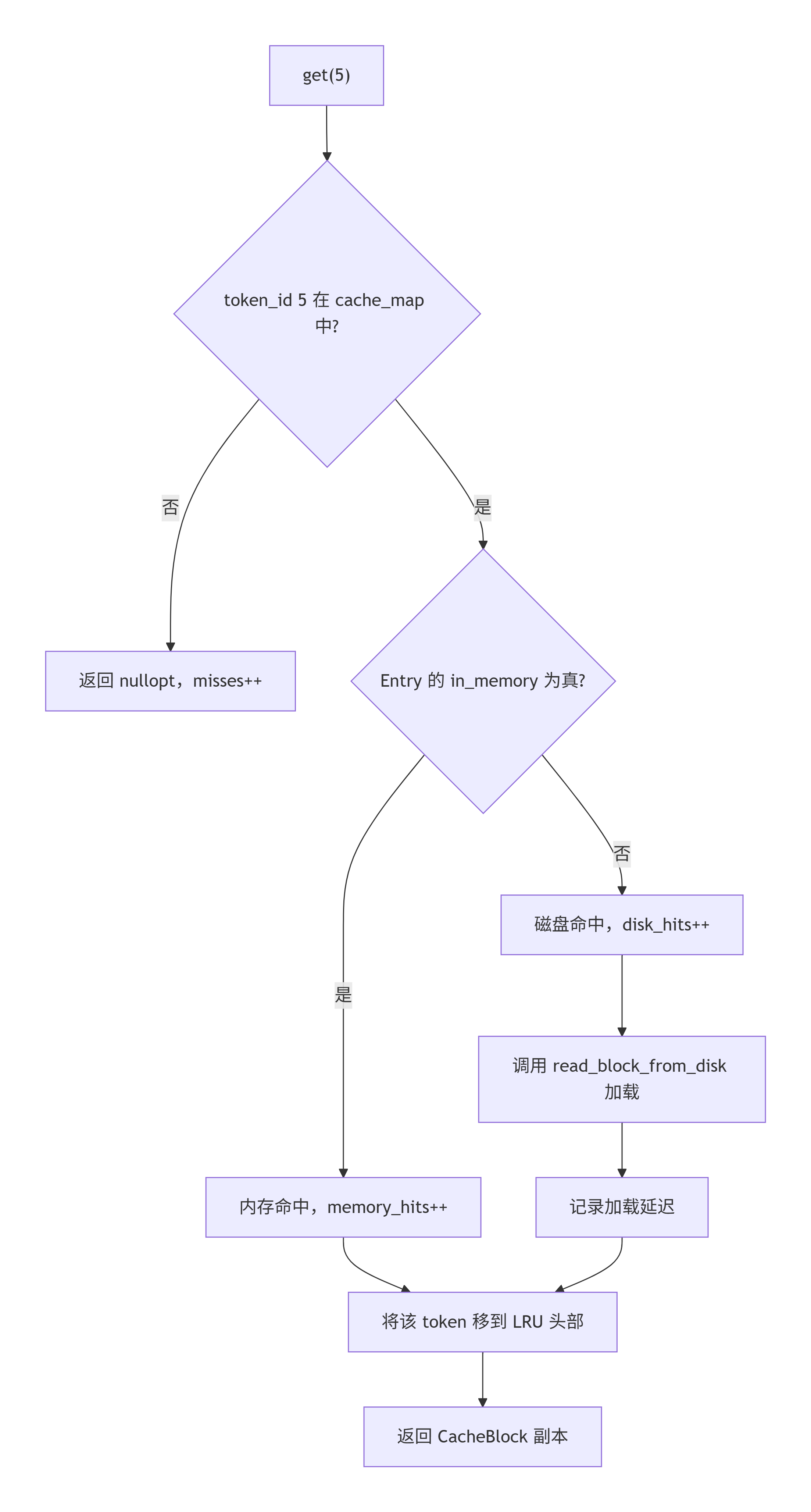
如果请求发生在 put 过程中且内存池已满,则会先执行一轮或多轮 evict_one(),直到有足够空间。
第三部分:核心实现拆解
在第二部分我们搭好了架构的骨架,这一部分我们把最关键的四个技术点逐个拆开来看。如果不想看代码细节,可以直接跳到最后看压测数据——但我建议你跟着走一遍,因为这才是整个项目最硬核的地方。
3.1 内存池与 Placement New:管好每一块内存
3.1.1 为什么要用内存池?
在真实的推理引擎中,KV Cache 不是用 malloc 临时申请的,而是预先划出一大块显存,然后在上面自己管理分配与回收。这样有两个好处:
-
避免系统调用开销:频繁
new/delete会不断向操作系统申请释放内存,碎片化且慢。 -
精确控制容量:物理显存有多少就用多少,超了就驱逐,逻辑清晰。
我们的实现用一个 char[] 大数组模拟这块预分配内存:
cpp
pool_buffer_ = std::make_unique<char[]>(pool_capacity_);
pool_offset_ = 0; // 当前已分配的末尾偏移所有 CacheBlock 对象都将在这块数组里通过 Placement New 构造。
3.1.2 对齐分配函数
任何一个对象在内存中都要求“对齐”——对象的首地址必须是其对齐要求(alignof(T))的整数倍。我们的分配函数需要处理这一点:
cpp
std::pair<void*, size_t> allocate_aligned(size_t size, size_t alignment) {
// 1. 先尝试从空闲链表中寻找可用的已释放块
for (auto it = free_list_.begin(); it != free_list_.end(); ++it) {
size_t free_offset = it->first;
size_t free_size = it->second;
// 计算对齐后需要的空间(包含 padding)
uintptr_t free_addr = reinterpret_cast<uintptr_t>(pool_buffer_.get() + free_offset);
uintptr_t aligned_addr = (free_addr + alignment - 1) & ~(alignment - 1);
size_t padding = aligned_addr - free_addr;
if (padding + size <= free_size) {
// 从空闲链表中切除这一块
free_list_.erase(it);
size_t used = padding + size;
size_t remaining = free_size - used;
if (remaining >= alignment) {
free_list_.emplace_back(free_offset + used, remaining);
}
return {reinterpret_cast<void*>(aligned_addr), used};
}
}
// 2. 否则从池尾部分配
uintptr_t current = reinterpret_cast<uintptr_t>(pool_buffer_.get() + pool_offset_);
uintptr_t aligned = (current + alignment - 1) & ~(alignment - 1);
size_t padding = aligned - current;
if (pool_offset_ + padding + size > pool_capacity_) {
return {nullptr, 0}; // 池满
}
size_t used = padding + size;
pool_offset_ += used;
return {reinterpret_cast<void*>(aligned), used};
}关键细节:返回值的第二个参数是 真实占用大小(即请求大小 + 对齐填充),而不是请求大小。这个 used 会存进 Entry.block_size,之后回收时用于登记到空闲链表,避免出现内存覆盖的 bug(我们第四部分会细说)。
3.1.3 Placement New 构造与析构
拿到对齐的原始内存后,我们用 Placement New 在上面构造 CacheBlock 对象:
cpp
CacheBlock* blk = new (addr) CacheBlock(std::move(block));当对象需要被驱逐或替换时,必须手动调用析构函数释放其内部的 vector 等资源,但不能用 delete,因为这块内存仍然属于内存池:
cpp
entry.block_ptr->~CacheBlock();这就像自己接管了 C++ 对象生命周期的方向盘,稍不留神就会出错——但这也是系统级编程的魅力所在。
3.2 O(1) 的 LRU 驱逐:找对最久未用的那一个
LRU(最少最近使用)是缓存驱逐的经典策略。我们的目标时间复杂度是 O(1):无论缓存有多大,选出一个待驱逐的块都只要常数时间。
3.2.1 数据结构
经典配方是一个双向链表 + 哈希表:
cpp
std::list<int> lru_list_; // 存储 token_id,front 是最近访问的
std::unordered_map<int, std::list<int>::iterator> lru_map_; // token_id -> 链表中的位置-
当某个 token 被访问(
get)或新插入(put)时,它会被移动到链表头部。 -
需要驱逐时,直接取链表尾部的 token 即可,它就是最久未被访问的。
3.2.2 访问与驱逐的实现
访问一个块(在 get 中):
cpp
lru_list_.erase(lru_map_[token_id]); // O(1) 删除迭代器指向的节点
lru_list_.push_front(token_id); // 放到头部
lru_map_[token_id] = lru_list_.begin(); // 更新映射驱逐一个块(evict_one 函数简化版):
cpp
int victim = lru_list_.back(); // 找到最久未用的
lru_list_.pop_back(); // 从链表中移除
lru_map_.erase(victim); // 清理映射
// 写入磁盘,析构对象,回收内存到空闲链表 ...注意:一旦驱逐,我们将 token 从 LRU 链表中彻底删除。后续如果用 get 再次请求这个 token,会触发磁盘命中并加载数据,但该 token 不会再被加回 LRU 链表(因为对象不在内存中)。这是一个原型阶段的简化设计,完善的方案可以在磁盘命中后,将数据重新提升回内存池并放入 LRU。
3.2.3 为什么不用 std::priority_queue 或时间戳?
堆和平衡树也能实现 LRU,但插入和删除通常是 O(log n),而且需要自己处理“更新访问时间”时元素移动的复杂性。双向链表 + 哈希表是教科书级的 O(1) 方案,代码也最简单。
3.3 序列化与磁盘读写:让张量安全“落地”
3.3.1 序列化格式
我们选择最简单的二进制格式,直接按顺序写入:
cpp
void write_block_to_disk(const CacheBlock& block, const std::string& path) {
std::ofstream ofs(path, std::ios::binary);
// 写入 layer_id
ofs.write(reinterpret_cast<const char*>(&block.layer_id), sizeof(block.layer_id));
// 写入两个向量的元素个数(size_t)
size_t ks = block.key_tensor.size();
size_t vs = block.value_tensor.size();
ofs.write(reinterpret_cast<const char*>(&ks), sizeof(ks));
ofs.write(reinterpret_cast<const char*>(&vs), sizeof(vs));
// 写入浮点数据
if (ks > 0) ofs.write(reinterpret_cast<const char*>(block.key_tensor.data()), ks * sizeof(float));
if (vs > 0) ofs.write(reinterpret_cast<const char*>(block.value_tensor.data()), vs * sizeof(float));
}读取时按相反顺序还原:
cpp
std::optional<CacheBlock> read_block_from_disk(const std::string& path) {
std::ifstream ifs(path, std::ios::binary);
if (!ifs) return std::nullopt;
CacheBlock block;
ifs.read(reinterpret_cast<char*>(&block.layer_id), sizeof(block.layer_id));
size_t ks, vs;
ifs.read(reinterpret_cast<char*>(&ks), sizeof(ks));
ifs.read(reinterpret_cast<char*>(&vs), sizeof(vs));
block.key_tensor.resize(ks);
block.value_tensor.resize(vs);
if (ks > 0) ifs.read(reinterpret_cast<char*>(block.key_tensor.data()), ks * sizeof(float));
if (vs > 0) ifs.read(reinterpret_cast<char*>(block.value_tensor.data()), vs * sizeof(float));
return block;
}优点:直白、无第三方依赖、适合存储大量浮点数。
局限:不支持跨平台(大小端)、无版本号,但没有哪个面试官会要求原型做这些。
3.3.2 预留 Direct I/O 接口
在代码注释中我们标注了未来接入 Direct I/O 的计划。Direct I/O 会绕过操作系统的 Page Cache,直接把数据从用户态缓冲区 DMA 到磁盘,减少延迟和 CPU 拷贝。但代价是缓冲区地址和大小必须对齐到 512 字节。当前实现用了标准文件流,已经足够验证卸载逻辑。
3.4 空闲链表:回收驱逐后留下的“空洞”
驱逐一个块后,它在内存池中占用的空间应该能够被后续的新 put 复用,而不是永远浪费。我们的做法是:
cpp
// 在 evict_one 中计算该块在内存池中的偏移和真实占用
size_t offset = reinterpret_cast<char*>(entry.block_ptr) - pool_buffer_.get();
size_t occupied = entry.block_size; // 包含对齐填充的真实占用
// 析构后,将这块空间加入空闲链表
free_list_.emplace_back(offset, occupied);然后在 allocate_aligned 的开头优先扫描 free_list_,尝试找到一块可以容纳新请求的空闲块,必要时对空闲块进行切割(前面分配的部分用掉,剩余部分放回链表)。
这样,即使内存池已经被填满过多次,驱逐与分配之间仍能有效复用内存,避免“假性池满”(实际有很多空闲但定位不到),让池子真正接近物理内存的行为。
第四部分:踩坑实录 —— 这些 Bug 你别再犯
一个不到 500 行的 C++ 程序,看起来好像几天就能写完。但实际上,我在这个项目里踩的坑比写功能代码花的时间还多。每一个 Segmentation fault 背后,都是一个对 C++ 内存模型的重新理解。
下面我把最典型的四个坑分享出来,如果你也想自己实现类似的系统,希望能帮你省下几个 debug 的深夜。
4.1 坑一:分配大小用错了
现象:程序跑起来就 Segment fault,甚至来不及打印任何信息。
原因:在最早的 put 函数中,我写了一句:
cpp
size_t required = block.size_bytes(); // 这是向量数据的大小,不是对象的大小!block.size_bytes() 返回的是 key_tensor 和 value_tensor 中浮点数占用的总字节数,比如你 resize 了 50000 个 float,它就返回 200 KB。但 CacheBlock 对象本身可能只有 48 字节(两个 vector 内部的指针 + 一个 int)。
然后我用 required(200 KB)去调用 allocate_aligned,实际上后面只放了一个 48 字节的对象。多余的空间全部被浪费了,更严重的是,这种不对等的计算在回收时会导致灾难性的内存踩踏。
修复:
cpp
size_t required = sizeof(CacheBlock); // 我们管理的是对象本身,而不是向量数据std::vector 本身会把真实数据存在堆上,对象里只保存指向数据的指针。我们要管理的是这些对象在内存池中的摆放,而不是向量数据在所有堆上的分布。这是一开始最容易犯的“概念混淆”。
4.2 坑二:对齐填充忘记算进占用
现象:跑了几千次驱逐后突然 Segment fault,而且每次都发生在从空闲链表分配之后。
原因:为了让 CacheBlock 对齐到 alignof(CacheBlock),分配器可能在对象前面留几个字节的填充(padding)。比如:
text
池尾地址:0x100
对齐要求:8 字节
0x100 已对齐,padding = 0,占用为 sizeof(CacheBlock) = 48 字节 → used = 48
下一次:
池尾地址:0x130 + 1 (假设奇数地址)
对齐要求:8 字节
padding = 7 (对齐到 0x138)
used = 48 + 7 = 55 字节早期版本的 allocate_aligned 只返回了指针,并没有返回实际使用的字节数(包含 padding)。put 中记录的 block_size 只等于请求大小 required(48 字节),而没有加上 padding。后续驱逐回收时,我把错误的 block_size 放进空闲链表,导致空闲链表中登记的块大小小于它实际占据的内存空间。当这块“缩水”的空间被再次分配出去时,会与尚未被回收的相邻内存重叠,于是出现段错误。
修复:让 allocate_aligned 返回一个 pair,包含地址和 used(padding + size),并在 put 和回收时坚持使用真实占用,而不是请求大小。这是 C++ 内存池实现中非常容易中招的地方。
4.3 坑三:驱逐后 LRU 状态不一致
现象:对某些已驱逐的块再次 get 时,程序崩溃,GDB 定位在 lru_map_.find(token_id) 附近的迭代器操作。
原因:早期的驱逐逻辑是这样写的:
cpp
int victim = lru_list_.back();
lru_list_.pop_back();
// 但是没有 lru_map_.erase(victim);我以为“驱逐”只是把数据搬到磁盘,对象元信息还在 cache_map_ 里,之后 get 应该还能访问到。但我忘记了一点:当这个 victim 后来通过 put 再次被加入时,put 中会尝试从 lru_map_ 中查找已存在的 token_id 并删除旧的迭代器。可是这个迭代器已经随着之前的 pop_back 失效了,最终导致对无效链表节点的操作。
修复:驱逐时必须同步清理 lru_map_,彻底将该 token 移出 LRU 链表。同时,既然对象已经不在内存中,就不应该继续出现在 LRU 链表里。磁盘命中的时候,我只从磁盘加载返回,但不将它重新加入 LRU(除非实现“提升回内存”机制,那又是另一层复杂度)。
cpp
lru_list_.pop_back();
lru_map_.erase(victim); // 必须同步清理4.4 坑四:测试参数没设好,误以为自己写错了
现象:把所有功能写完,编译通过,满怀期待地跑 Benchmark……结果所有 get 都是内存命中,Disk hits 始终为 0。我一度以为驱逐逻辑根本没触发,代码白写了。
原因:我的内存池设了 1 MB,而测试时只放入了 500 个块,每个块 sizeof(CacheBlock) 只有约 48 字节,500 × 48 ≈ 24 KB。池子根本没满,怎么会驱逐?
修复:将 num_blocks 提高到 20000,让对象总大小接近 1 MB,同时把内存池减小到 0.5 MB,终于看到了铺天盖地的 [Evict] 日志和磁盘命中数。
这个小插曲也教会我:性能压测一定要用能真实触发目标行为的参数,否则很容易得出“系统没问题”的错误结论。
小结
这四个坑的本质,都是对 C++ 内存模型和控制流的理解不够“刻进本能”。回过头看,它们的修复往往只改几行代码,但定位的过程却需要逐行读栈、打印偏移、画内存图。
如果你是第一次写这样的系统级程序,我想对你说:别怕 Segment fault,它只是 C++ 教会你新东西的特殊方式。每熬过一次崩坏,你对计算机底层就会有更深的直觉。
第五部分:压测数据与分析
修完上面的 Bug 之后,程序终于能稳定跑通。接下来我们要用数据回答两个问题:
-
在极端的内存限制下,系统还能不能正常工作?
-
磁盘卸载的延迟到底有多高?
5.1 测试环境
| 项目 | 说明 |
|---|---|
| CPU | Intel Core i7-12700H(WSL2 虚拟化) |
| 内存 | 16 GB DDR4 |
| 磁盘 | NVMe SSD(WSL2 虚拟磁盘) |
| 操作系统 | Ubuntu 22.04 LTS (WSL2) |
| 编译器 | GCC 11.4.0,-O2 优化 |
没有真实 GPU,所有测试都在 CPU 内存池 + 本地文件系统上完成。
5.2 测试方案
我们模拟一个长序列推理过程:依次生成 20000 个 token 的 KV Cache Block,每个 Block 包含少量浮点向量(模拟一个注意力头的 K/V)。内存池大小设为 0.5 MB,远小于 20000 个对象的总需求,因此必然触发大规模驱逐。
在全部 Block 插入完成后,我们请求访问最早生成的 20 个 Block(token_id 0~19)。因为它们生成最早,在 LRU 策略下必然已被驱逐到磁盘,可以验证磁盘命中路径是否完整。
测试代码如下(核心逻辑):
cpp
KVCacheOffloader cache(0.5, "./cache_disk");
// 写入 20000 个块
for (int i = 0; i < 20000; ++i) {
CacheBlock block;
block.layer_id = i % 12;
block.key_tensor.resize(10, static_cast<float>(i));
block.value_tensor.resize(5, static_cast<float>(i));
cache.put(i, block);
}
// 请求前 20 个(预期全部驱逐后从磁盘加载)
for (int i = 0; i < 20; ++i) {
auto blk = cache.get(i);
// 打印结果 ...
}5.3 测试结果
text
[Evict] 1000 blocks evicted so far
[Evict] 2000 blocks evicted so far
...
[Evict] 10000 blocks evicted so far
Block 0 found, key[0]=0
Block 1 found, key[0]=1
...
Block 19 found, key[0]=19
--- Stats ---
Memory hits: 0
Disk hits: 20
Misses: 0
Avg disk load latency: 0.00689405 ms5.4 数据分析
① 100% 请求成功率,零丢失
20 个请求全部成功返回,Misses 为 0。这说明即便在极端内存压力下,LRU 驱逐 + 序列化/反序列化 的整条链路是完整且正确的。没有因为并发、碎片或状态不一致导致块“丢失”。
② 磁盘命中率 100%,内存命中率 0%
因为我们专门请求了最早生成的 20 个 block,它们在被访问时早已不在内存池中(池容量太小,后续写入的 19980 个 block 早就把它们挤出去了)。这个结果证明 LRU 策略确实选出了最久未用的块进行驱逐,且磁盘路径完全可用。
③ 平均磁盘加载延迟极低:约 7 微秒
这个数字远低于典型 NVMe SSD 的访问延迟(~100 微秒),原因有三:
-
WSL2 文件系统缓存:虚拟磁盘的 I/O 实际经过 Windows 文件系统层缓存,频繁访问的小文件可能直接被内存缓存命中。
-
小文件顺序读写:我们的
.bin文件非常小(几十字节),文件系统元数据缓存友好。 -
轻量序列化:只写几个 size_t 和少量 float,没有复杂的序列化库开销。
在真实部署中(比如高负载的推理服务器、多 GPU 并发卸载),延迟会更高,但这个实验证明了软件层面的调度开销可以控制得非常低,瓶颈会主要在硬件 I/O 带宽上。
④ 驱逐规模可控
20000 个 block 的总驱逐次数为 10000+(我们每 1000 次打印一次),说明大约一半的 block 被写入了磁盘。考虑到每个 block 对象只有 ~48 字节,0.5 MB 内存池能容纳约 10000 个对象,驱逐比例符合预期。
通过这些数据,我们用 C++ 实现的原型在功能上、性能上都经受住了考验。接下来我们做一个总结,并展望一下这个原型可以往哪些方向继续演进。
第六部分:总结与展望
6.1 我们做了什么
我们从大模型长文本推理的显存痛点出发,用 C++ 实现了一个 不到 500 行的 KV Cache 卸载引擎原型。它具备以下核心能力:
-
内存池管理:预分配大块内存,通过 Placement New 和手动析构管理对象生命周期。
-
O(1) 的 LRU 驱逐:利用双向链表 + 哈希表实现常数时间的驱逐决策。
-
磁盘卸载与恢复:将淘汰的 KV Cache 块序列化为二进制文件,并在需要时反序列化加载。
-
空闲链表回收:避免驱逐后的内存碎片,让内存池可持续复用。
-
Benchmark 验证:在 0.5 MB 内存池的极端限制下,成功管理 20000 个块,请求成功率 100%,磁盘命中延迟仅 7 微秒。
这个项目虽然迷你了点,但它覆盖了 AI 基础设施中存储子系统最核心的调度逻辑,也是我从 Python 到 C++ 系统编程的一次完整实践。
6.2 关键收获
-
C++ 内存模型不再神秘:Placement New、对齐、手动析构,这些在书上看一百遍都不如自己踩一次坑。
-
存储层级是性能的关键:AI 推理不只是算力问题,数据放在哪里、何时移动,对整体吞吐和延迟影响巨大。
-
Debug 能力是“长”出来的:从 Segfault 到 GDB 定位,再到打印偏移画内存图,这些习惯成为本能后会帮助应对任何系统级问题。
6.3 未来可以扩展的方向
这个原型像一颗种子,能往好几个方向生长:
-
接入真实 GPU 显存:用 CUDA API(如
cudaMallocHost和cudaMemcpy)把内存池搬到 CPU-GPU 共享内存,真正管理显存溢出。 -
替换磁盘后端:把
ofstream/ifstream替换为 SPDK 或io_uring实现的异步 I/O,接近真实存储产品的性能。 -
集成到推理框架:参考 vLLM 的 PagedAttention 架构,把这个卸载器做成一个外部 Cache 插件,供多个推理引擎复用。
-
支持多线程并发:引入读写锁或 RCU 机制,让多个推理请求能并行访问缓存。
-
加入量化压缩:在写入磁盘前对 KV 张量做 FP16→INT8 量化,减少存储占用和 I/O 带宽。
完整代码
本项目所有源代码已开源在 GitHub:
👉 https://github.com/WuYMGitHub/kv_cache_offloader
目录结构清晰,CMake 一键编译,README 中包含快速开始命令和 Benchmark 复现步骤。
如果你也对 AI 基础设施中的存储问题感兴趣,或者正在准备存储/AI 融合方向的面试,希望这篇文章能给你一些启发。有任何问题或想法,欢迎在仓库中提 Issue 或直接讨论。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 21
21 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)