强化学习入门 I CS188 Note9 学习笔记
更好的阅读体验
Reinforcement Learning
Offline Planning and Online Planning
在先前的MDP中,我们完全知道了转移函数和奖励函数。这种在真正采取行动之前,就已经知道最优怎么做叫做离线规划( Offline planning ),现在Reinforcement Learning是在线规划,agent对真实世界一无所知,必须靠探索( exploration )来收集经验样本,逐步估计最优策略
Types of RL
强化学习分为两种类型:
- 基于模型的学习 (Model-based Learning):先用样本估计 T ^ \hat{T} T^和 R ^ \hat{R} R^,再用规划算法求解策略。
- 无模型学习 (Model-free Learning):不显式建模转移和奖励,直接估计值函数 V(s)或动作值函数 Q(s,a)
Model-Based Learning
基于模型的学习在判断转移函数时用概率来大致统计真实的转移函数值,判断奖励函数时直接取所观测到的r的平均值。看例子会更好理解
模型学习示例
状态集 S={A,B,C,D,E,x},x为终止态,折扣因子γ=1,经历了4个episode一共有12个样本
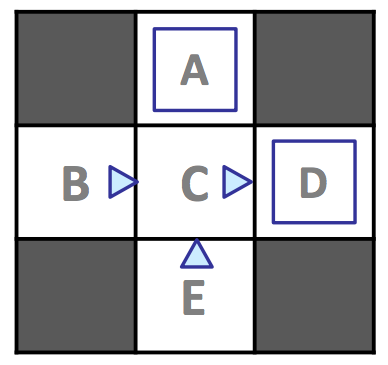

12个样本表格化的的计数结果如下
| s | a | s’ | count |
|---|---|---|---|
| A | exit | x | 1 |
| B | east | C | 2 |
| C | east | A | 1 |
| C | east | D | 3 |
| D | exit | x | 3 |
| E | north | C | 2 |
− T ^ ( A , exit , x ) = # ( A , exit , x ) # ( A , exit ) = 1 1 = 1 − R ^ ( A , exit , x ) = − 10 , − T ^ ( B , east , C ) = # ( B , east , C ) # ( B , east ) = 2 2 = 1 − R ^ ( B , east , C ) = − 1 , − T ^ ( C , east , A ) = # ( C , east , A ) # ( C , east ) = 1 4 = 0.25 − R ^ ( C , east , A ) = − 1 , − T ^ ( C , east , D ) = # ( C , east , D ) # ( C , east ) = 3 4 = 0.75 − R ^ ( C , east , D ) = − 1 , − T ^ ( D , exit , x ) = # ( D , exit , x ) # ( D , exit ) = 3 3 = 1 − R ^ ( D , exit , x ) = + 10 , − T ^ ( E , north , C ) = # ( E , north , C ) # ( E , north ) = 2 2 = 1 − R ^ ( E , north , C ) = − 1. \begin{align*} -\,\hat{T}\big(A,\text{exit},x\big) &= \dfrac{\#(A,\text{exit},x)}{\#(A,\text{exit})} = \dfrac{1}{1} = 1 &\quad& -\,\hat{R}\big(A,\text{exit},x\big) = -10,\\[6pt] -\,\hat{T}\big(B,\text{east},C\big) &= \dfrac{\#(B,\text{east},C)}{\#(B,\text{east})} = \dfrac{2}{2} = 1 &\quad& -\,\hat{R}\big(B,\text{east},C\big) = -1,\\[6pt] -\,\hat{T}\big(C,\text{east},A\big) &= \dfrac{\#(C,\text{east},A)}{\#(C,\text{east})} = \dfrac{1}{4} = 0.25 &\quad& -\,\hat{R}\big(C,\text{east},A\big) = -1,\\[6pt] -\,\hat{T}\big(C,\text{east},D\big) &= \dfrac{\#(C,\text{east},D)}{\#(C,\text{east})} = \dfrac{3}{4} = 0.75 &\quad& -\,\hat{R}\big(C,\text{east},D\big) = -1,\\[6pt] -\,\hat{T}\big(D,\text{exit},x\big) &= \dfrac{\#(D,\text{exit},x)}{\#(D,\text{exit})} = \dfrac{3}{3} = 1 &\quad& -\,\hat{R}\big(D,\text{exit},x\big) = +10,\\[6pt] -\,\hat{T}\big(E,\text{north},C\big) &= \dfrac{\#(E,\text{north},C)}{\#(E,\text{north})} = \dfrac{2}{2} = 1 &\quad& -\,\hat{R}\big(E,\text{north},C\big) = -1. \end{align*} −T^(A,exit,x)−T^(B,east,C)−T^(C,east,A)−T^(C,east,D)−T^(D,exit,x)−T^(E,north,C)=#(A,exit)#(A,exit,x)=11=1=#(B,east)#(B,east,C)=22=1=#(C,east)#(C,east,A)=41=0.25=#(C,east)#(C,east,D)=43=0.75=#(D,exit)#(D,exit,x)=33=1=#(E,north)#(E,north,C)=22=1−R^(A,exit,x)=−10,−R^(B,east,C)=−1,−R^(C,east,A)=−1,−R^(C,east,D)=−1,−R^(D,exit,x)=+10,−R^(E,north,C)=−1.
Model-Based Learning虽然简单直观,但是遇到状态很多的情况,多元组计数的繁琐会导致耗费内存过多,就引出了Model-Free Learning
Model-Free Learning
Model-Free Learning又分为被动强化学习( Passive Reinforcement Learning ), 主动强化学习( Active Reinforcement Learning )。两者的主要区别,就是被动强化学习的policy是固定的,而主动强化学习的policy不是固定的,它是根据用样本改进策略最终找到最优策略的。
被动强化学习包括了下文要说的Direct evaluation还有Temporal Difference Learning
主动强化学习包括了下文要说的Q-learning
Direction Evaluation
这是第一个被动强化学习,它的原理很简单。在任意一点,我们可以用从s得到的总效用除以s被访问的次数来计算任何状态s的估计值
依旧回顾一下前面的情景,折扣因子为1
from state D to termination we acquired a total reward of 10,
from state C we acquired a total reward of (−1) + 10 = 9,
and from state B we acquired a total reward of (−1) + (−1) + 10 = 8.
| s | Total Reward | Times Visited | V π ( s ) V^{\pi}(s) Vπ(s) |
|---|---|---|---|
| A | -10 | 1 | -10 |
| B | 16 | 2 | 8 |
| C | 16 | 4 | 4 |
| D | 30 | 3 | 10 |
| E | -4 | 2 | -2 |

一定一定要注意,这里的效用值是累计折扣回报,而不是单步的回报,所以说在计算状态B的效用值的时候要加上未来的回报。
根据图可以很容易发现一个问题,这种方法忽略的状态之间的转移关系,破坏了连续状态的一致性 例如 B和 E 在策略下都只有后继C,且奖励相同,按理来说 V π ( B ) = V π ( E ) V^{\pi}(B) = V^{\pi}(E) Vπ(B)=Vπ(E),但采样随机性导致 E恰好碰上一次负奖励,估值严重偏离,需要很多的样本才能消除这种误差
Temporal Difference Learning
相较与Direction Evaluation核心的改进就是agent会从每次经验中学习,而不是等到episode结束才平均。它利用了贝尔曼方程的思想,用当前对后继状态的估值来更新当前状态
首先初始化 V π ( s ) = 0 V^{\pi}(s) = 0 Vπ(s)=0,这个算法所采用的样本为 ( s , π ( s ) , s ′ , r ) (s,\ \pi(s),\ s',\ r) (s, π(s), s′, r),获得样本后进行如下计算,其中 α是学习率 (learning rate),0≤α≤1,通常随着时间衰减
sample = r + γ V π ( s ′ ) V π ( s ) ← ( 1 − α ) V π ( s ) + α ⋅ sample \begin{align*} \text{sample} &= r + \gamma V^{\pi}(s')\\ V^{\pi}(s) &\leftarrow (1-\alpha)\,V^{\pi}(s) + \alpha\cdot\text{sample} \end{align*} sampleVπ(s)=r+γVπ(s′)←(1−α)Vπ(s)+α⋅sample
上述公式可以写成下面的形式,提供了另外一种角度来理解,后面的多项式可以理解成sample和原价值的偏移量,控制的参数就是学习率
V π ( s ) ← V π ( s ) + α ( sample − V π ( s ) ) \begin{align*} V^{\pi}(s) &\leftarrow V^{\pi}(s) + \alpha\big(\text{sample} - V^{\pi}(s)\big) \end{align*} Vπ(s)←Vπ(s)+α(sample−Vπ(s))
根据上面写的式子,可以近似为下面的通式
x ˉ n = ( 1 − α ) ⋅ x ˉ n − 1 + α ⋅ x n \begin{align*} \bar{x}_n &= (1-\alpha)\cdot \bar{x}_{n-1} + \alpha \cdot x_n \end{align*} xˉn=(1−α)⋅xˉn−1+α⋅xn
通式展开可以得到
x ‾ n = x n + ( 1 − α ) ⋅ x n − 1 + ( 1 − α ) 2 ⋅ x n − 2 + … 1 + ( 1 − α ) + ( 1 − α ) 2 + … \begin{align*} \overline{x}_n &= \frac{x_n + (1-\alpha)\cdot x_{n-1} + (1-\alpha)^2\cdot x_{n-2} + \dots}{1 + (1-\alpha) + (1-\alpha)^2 + \dots} \end{align*} xn=1+(1−α)+(1−α)2+…xn+(1−α)⋅xn−1+(1−α)2⋅xn−2+…
观察分子不难发现,越新的样本占的权重越大,这实际上在反映一种客观事实,最新的行为反而更具有有参考价值。TD Learning相比Direction Evaluation更加的高效,同时收敛地更快
Q-Learning
这里介绍了一个具有里程碑意义的算法,直接学习最优动作函数即Q*( s, a )
理论方法
Q k + 1 ( s , a ) = ∑ s ′ T ( s , a , s ′ ) [ R ( s , a , s ′ ) + γ max a ′ Q k ( s ′ , a ′ ) ] \begin{align*} Q_{k+1}(s,a) &= \sum_{s'} T(s,a,s')\big[\,R(s,a,s') + \gamma \max_{a'} Q_k(s',a')\,\big] \end{align*} Qk+1(s,a)=s′∑T(s,a,s′)[R(s,a,s′)+γa′maxQk(s′,a′)]
这个公式是贝尔曼方程的変式,其需要T,R 这是Value Iteration的变体,不是实际的Q-learning
实际方法
sample = r + γ max a ′ Q ( s ′ , a ′ ) Q ( s , a ) ← ( 1 − α ) Q ( s , a ) + α ⋅ sample \begin{align*} \text{sample} &= r + \gamma \max_{a'} Q(s',a')\\ Q(s,a) &\leftarrow (1-\alpha)\,Q(s,a) + \alpha\cdot \text{sample} \end{align*} sampleQ(s,a)=r+γa′maxQ(s′,a′)←(1−α)Q(s,a)+α⋅sample
也可以写成有偏移量的形式
Q ( s , a ) ← Q ( s , a ) + α ⋅ (sample - Q(s, a)) \begin{align*} Q(s,a) &\leftarrow Q(s,a) + \alpha \cdot \text{(sample - Q(s, a))} \end{align*} Q(s,a)←Q(s,a)+α⋅(sample - Q(s, a))
这里一定要注意取未来的Q值是通过max来取的,这就保证了最优Q值。即便当前的行为不是最优的,依然会假设未来是最优的。这里就体现了Q-learning的一个很大的优点,Q-learning 可以在执行“次优甚至随机动作”的情况下,仍然学到最优策略,就是因为用的是max。行为可以是不保证最优,但学习目标始终是最优,这就叫做Off-policy Learning

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)