知识层:胶水编程范式
胶水编程(Glue Coding)是 Vibe Coding 体系中最核心的方法论范式之一。它主张几乎完全复用成熟开源组件,通过最小量的"胶水代码"将它们组合成完整系统——开发者不再从零生成代码,而是描述"连接方式",让 AI 担任模块间的桥梁工程师。本文档将从理念本质、核心原则、实践流程、约束铁律到真实案例,系统阐述这一范式如何从根本上解决 AI 辅助编程中的幻觉、复杂性和门槛三大顽疾。
范式定位:从"生成"到"连接"的根本性转变
胶水编程并非一种具体技术,而是一种工程哲学的范式转移。理解它的最佳方式,是将其置于三种编程范式的演进光谱中:
这三种范式之间存在递进关系,但胶水编程不是对前两者的否定,而是在 AI 时代对工程效率的二次优化。在传统 Vibe Coding 中,AI 被要求"发明"业务逻辑——这正是幻觉的温床;而胶水编程将 AI 的职责压缩到数据转换和接口适配,这是大语言模型最擅长、也最不容易出错的领域 胶水编程。
💡胶水编程的本质洞察:AI 最擅长的是"理解两份文档并写出 A→B 的转换",而非"从零发明一个完整系统"。 限制 AI 的职责范围,反而最大化了其产出质量。
三大痛点与对应解法
胶水编程之所以被称为"软件工程的银弹",在于它精准命中了传统 Vibe Coding 的三个结构性缺陷:
| 痛点维度 | 传统 Vibe Coding 的根源 | 胶水编程的解决机制 | 效果 |
|---|---|---|---|
| AI 幻觉 | AI 被要求"发明"不存在的 API 和逻辑 | 只使用经过社区验证的成熟库,AI 仅做文档阅读和接口对接 | 幻觉风险趋近于零 |
| 复杂性爆炸 | 项目越大,AI 生成的代码越难维护 | 每个模块背后是数千个 Issue、数百名贡献者、数年生产打磨 | 复杂性被社区吸收 |
| 入门门槛 | 需要深厚编程功底才能判断 AI 输出的正确性 | 只需描述"输入是什么、输出要什么" |
核心架构模型
胶水编程将任何软件系统抽象为三层结构,形成一个清晰的关注点分离:
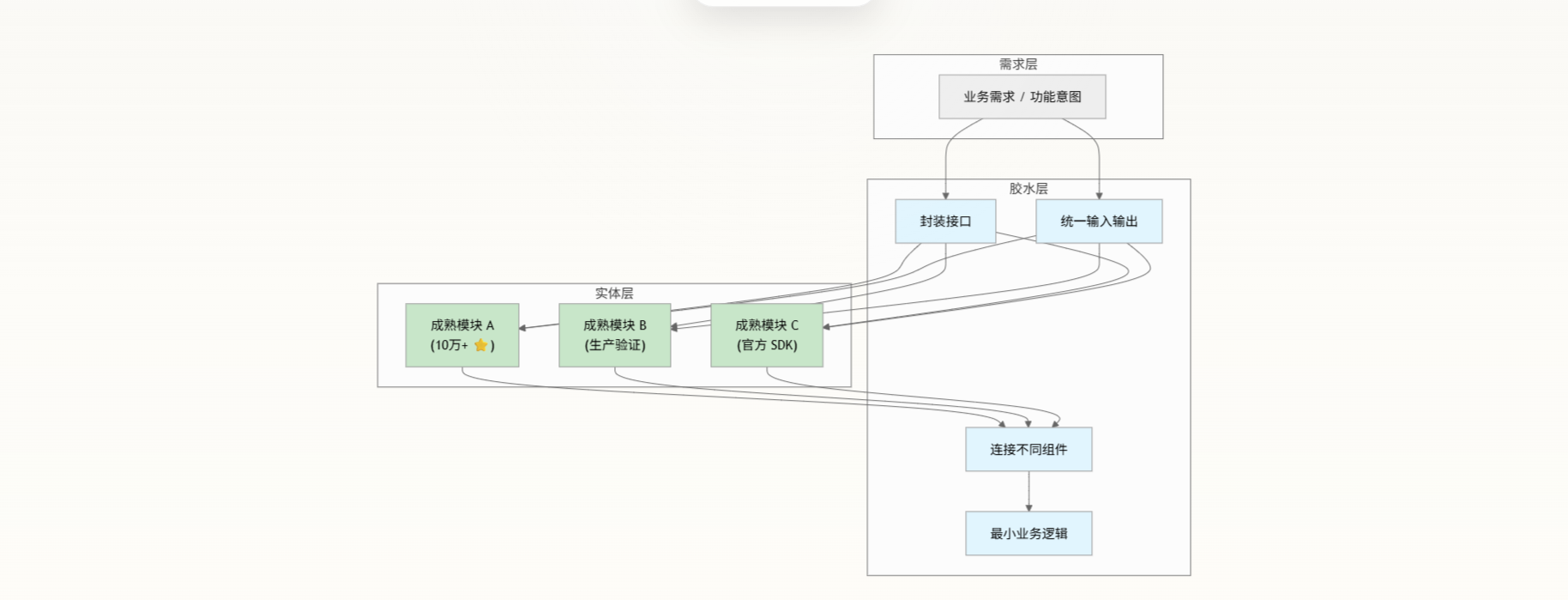
实体——成熟的开源项目、官方 SDK、久经考验的库。它们是不可变的黑盒,通过 services/、libs/、third_party/ 等目录以 submodule 或包管理器方式引入,绝对禁止修改其源码 通用项目架构模板。
胶水——AI 生成的最小连接代码,仅承担四种职责:组合、调用、封装、适配。它不包含任何核心算法或数据结构的实现,只负责数据在模块间的流转和格式转换 胶水编程。
功能——你描述的业务目标,通过实体与胶水的组合自然涌现。
五条核心原则
胶水编程的全部方法论可以浓缩为五条不可违反的原则,它们之间形成逻辑递进:
原则 1:凡是能不写的就不写,能少写的就少写
任何已有成熟实现的功能,都不应重新造轮子。这是胶水编程的原点,也是编程之道 中"最小复杂度"思想在工程实践中的直接体现 胶水编程。
原则 2:能 CV 就 CV——复用是工程美德
直接复制使用经过社区检验的代码属于正常的工程流程,而非偷懒。这与 DRY 原则一脉相承,但将复用的边界从"项目内"扩展到了"整个开源生态" 胶水编程。
原则 3:站在巨人的肩膀上
利用现成框架而非试图自己写一个"更好的轮子"。每个成熟模块背后都有 Issue 讨论历史、贡献者社区和生产环境验证——你不是在管理复杂性,你是在借用整个社区的质量保障体系 胶水编程。
原则 4:不修改原仓库代码
所有开源库应尽量保持不可变,作为黑盒使用。任何对第三方代码的修改都是维护债务的开端——一旦上游更新,你的修改就会成为冲突源 胶水编程。
原则 5:自定义代码仅限胶水层
你写的代码只承担组合、调用、封装、适配四类职责。当前项目仅允许承担业务流程编排、模块组合调度、参数配置与输入输出适配职责,禁止在此层实现任何依赖库已提供的同类功能 胶水编程, 强前置条件约束。
实践流程:六步闭环
胶水编程将传统的"写代码"流程替换为一个结构化的搜索-评估-组合流程:
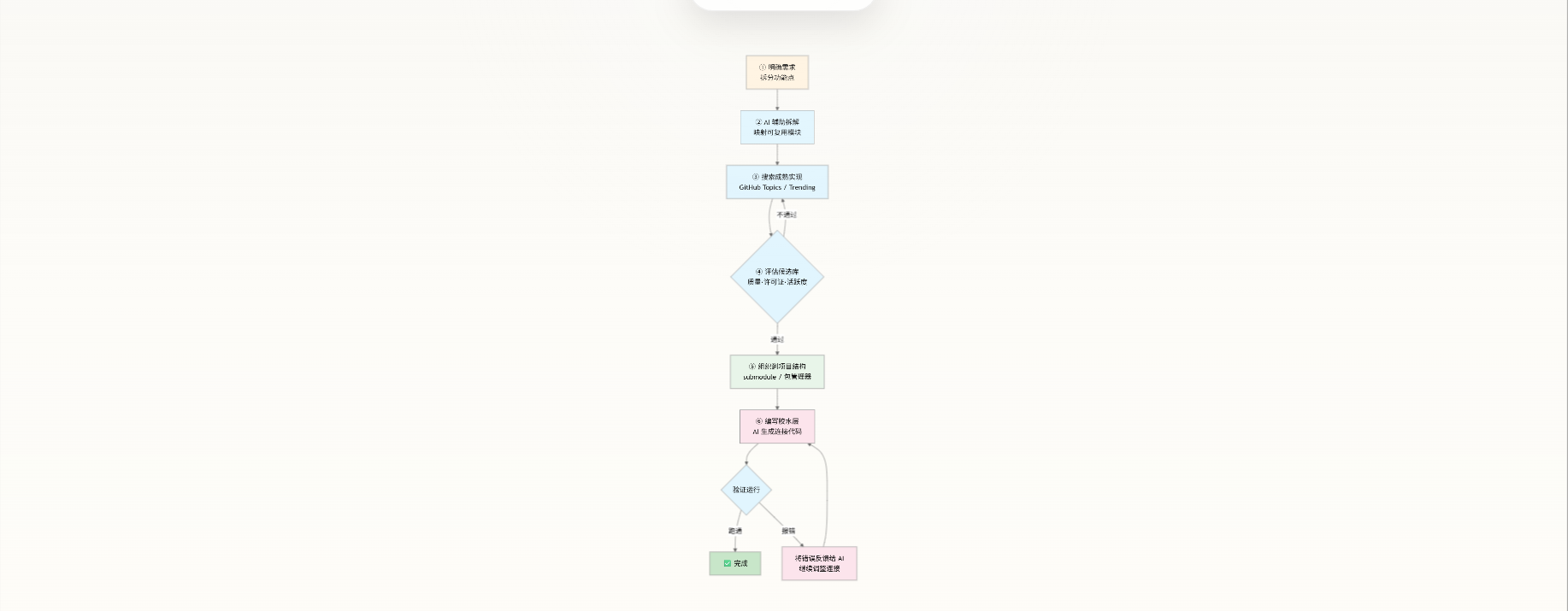
寻找轮子的方法
搜索成熟实现时,推荐使用 GitHub Topics 进行精准定位。让 AI 帮你分析需求对应的技术领域,推荐 Topic 关键词,然后浏览热门仓库 胶水编程:
| 典型需求 | 推荐 GitHub Topic | 搜索链接 |
|---|---|---|
| Telegram Bot | telegram-bot |
github.com/topics/telegram-bot |
| 数据分析 | data-analysis |
github.com/topics/data-analysis |
| AI Agent | ai-agent |
github.com/topics/ai-agent |
| CLI 工具 | cli |
github.com/topics/cli |
| Web 爬虫 | web-scraping |
github.com/topics/web-scraping |
进阶技巧包括组合多个 Topic 筛选(如 github.com/topics/python?q=telegram)、关注 GitHub Trending 发现热门新项目,以及利用 AI 的联网能力进行综合评估 胶水编程。
项目组织结构
选定模块后,按标准架构模板将其组织到项目中。参考 通用项目架构模板,典型结构包含:
services/—— 核心服务(胶水层主体)libs/—— 本地共享库third_party/—— 第三方依赖(以 submodule 形式引入)external/—— 外部服务客户端封装
所有依赖通过 Git submodule 或包管理器安装,保持与上游的可审计、可更新关系 通用项目架构模板, AGENTS.md。
胶水开发约束铁律:40 条不可违反的硬规则
胶水编程之所以能可靠运行,依赖于一套严格的约束体系。在 强前置条件约束 中,共定义了 23 条胶水开发专用约束 和 17 条系统性检查约束,合计 40 条铁律。以下按类别提炼关键约束:
💡这 40 条约束不是"建议"而是"审计标准"。项目评价以是否正确、完整站在成熟系统之上构建为唯一依据,而非代码量。任何违反都必须在代码审查中被拦截。
依赖完整性约束
| 约束编号 | 核心要求 | 违反后果 |
|---|---|---|
| 第 1 条 | 必须优先、直接、完整复用既有成熟仓库与生产级库 | 引入不可控的自研风险 |
| 第 3 条 | 不得对依赖库进行任何形式的功能裁剪、逻辑重写或降级封装 | 破坏上游质量保障 |
| 第 6 条 | 所有依赖路径必须真实存在并指向完整仓库源码 | 运行时加载失败 |
| 第 8 条 | 代码中必须直接导入完整依赖模块,不得进行子集封装或二次抽象 | 接口空洞化 |
伪集成防护约束
| 约束编号 | 核心要求 | 违反后果 |
|---|---|---|
| 第 10 条 | 所有被调用能力必须来自依赖库的真实实现,不得使用 Mock/Stub/Demo | 测试与生产不一致 |
| 第 11 条 | 不得存在占位实现、空逻辑或"先写接口后补实现"的情况 | 幻觉代码残留 |
| 第 15-16 条 | 所有导入的模块必须在运行期真实参与执行,不得存在"只导入不用"的伪集成 | 伪依赖膨胀 |
| 第 18 条 | 不得因路径配置错误导致加载到裁剪版、测试版或简化实现 | 静默降级 |
胶水编程 vs 传统开发:全景对比
| 维度 | 传统开发 | 传统 Vibe Coding | 胶水编程 |
|---|---|---|---|
| 功能实现方式 | 自己写 | AI 从零生成 | 复用开源 + AI 连接 |
| 核心工作量 | 大 | 中(审查量大) | 小(仅审查连接) |
| 幻觉风险 | 无(人写) | 高(AI 可能编造 API) | 极低(只做接口对接) |
| 开发速度 | 慢 | 快但返工多 | 极快且稳定 |
| 错误率 | 容易踩坑 | 高(不可预测) | 低(社区已踩过坑) |
| 维护成本 | 高 | 极高(AI 生成代码难维护) | 低(模块可独立替换升级) |
| 扩展方式 | 修改代码 | 重新生成 | 替换组件 |
| 对开发者的要求 | 深厚编程功底 | 能判断 AI 输出正确性 | 会描述需求和连接意图 |
| 核心理念 | "造轮子" | "让 AI 造轮子" | "组合轮子" |
典型应用场景与真实案例
适用场景矩阵
胶水编程尤其适合以下六类场景,它们共同的特点是已有成熟生态但组合逻辑因项目而异:
| 场景 | 说明 | 典型组合 |
|---|---|---|
| 快速原型开发 | 用最少代码验证产品假设 | 框架 + SDK + 模板引擎 |
| 小团队构建大系统 | 人数有限但功能复杂 | 多个微服务框架 + 消息队列 + 监控 |
| AI 应用 / 模型推理 | 推理框架生态成熟 | LangChain + HuggingFace + FastAPI |
| 数据处理流水线 | ETL 组件高度标准化 | pandas + airflow + postgresql |
| 内部工具开发 | 不需要极致性能 | Web 框架 + ORM + 认证库 |
| 系统集成 | 连接已有服务 | API 客户端 + 适配器 + 消息总线 |
案例:Polymarket 数据分析 Bot
需求:实时获取 Polymarket 预测市场数据,分析后推送到 Telegram 胶水编程。
| 方案 | 代码量 | 开发时间 | 关键风险 |
|---|---|---|---|
| 传统做法(从零编写爬虫、分析逻辑、Bot) | ~3000 行 | ~2 周 | 数据格式变更、异步逻辑 bug、API 限流 |
| 胶水做法 | ~50 行 | ~2 小时 | 仅接口适配点可能出错 |
胶水做法使用三个轮子:polymarket-py(官方 SDK)负责数据获取、pandas 负责数据分析、python-telegram-bot 负责消息推送。胶水代码仅承担数据格式转换和流程编排。相关提示词和实战文档见 polymarket-dev 案例集,其中包含专门的 胶水开发要求提示词 和完整性检查提示词。
与 Vibe Coding 哲学体系的关联
胶水编程并非孤立的方法论,它在 Vibe Coding 知识体系中扮演承上启下的角色:
- 向上承接 Vibe Coding 哲学原理 中"面向目的"的编程范式——开发者只描述意图,不关心实现细节。
- 向下支撑 AI Skills 技能库 的构建方式——每个 Skill 本质上就是对特定领域成熟组件的胶水封装。
- 横向关联 概念框架与语言层要素——看懂胶水代码需要掌握 L1-L4 层语言要素(基础语法、数据模型、类型系统、执行模型),但对 L5-L8 层的要求可以降到最低。
在 编程之道 的哲学框架中,胶水编程是"可组合性"原则的极致实践——小单元可组合,可组合即可复用,可复用即可演化。而 哲学方法论工具箱 中的"奥卡姆剃刀"(最小复杂度)和"实用主义"(以指标为准)方法,则为胶水编程提供了评估和取舍的理论工具。
总结与实践建议
能抄不写,能连不造,能复用不原创。
胶水编程是 Vibe Coding 的终极进化形态。它不是偷懒,而是工程智慧的最高体现——用最少的原创代码,撬动最大的生产力。如果你正在进入 Vibe Coding 体系,建议按以下路径逐步深入:
- 先读本文档,理解胶水编程的核心理念与约束铁律
- 查阅 概念框架与语言层要素,补充理解胶水代码所需的最低语言知识
- 浏览 AI Skills 技能库,观察胶水封装的实战范例(20 个现成技能覆盖数据库、加密货币、开发工具等领域)
- 研究 提示词库与云端表格,获取胶水开发专用的提示词模板
- 进阶学习 递归自优化元方法论,理解胶水编程如何嵌入持续自优化的开发闭环
"最好的代码就是没有代码。次好的代码则是胶水代码。"
下一章:递归自优化元方法论

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 17
17 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)