DeepSeek-V4 震撼登场!百万上下文免费开送,Agent能力直逼顶级闭源模型
摘要:2026年4月24日,DeepSeek正式发布V4预览版,并同步开源。新模型最大的亮点是将百万(1M)上下文作为所有官方服务的标配,同时大幅提升了Agent能力、世界知识和推理性能。V4系列包含Pro和Flash两个版本,Pro版本在多项评测中超越现有开源模型,比肩Gemini-Pro-3.1、Opus 4.6等顶级闭源模型;Flash版本则提供更快捷经济的API服务。本文将带你快速了解DeepSeek-V4的核心亮点、技术创新、使用方式及开源信息。
大家好!今天凌晨,DeepSeek扔出了一枚“核弹”——DeepSeek-V4预览版正式上线并开源!作为一名长期关注LLM进展的技术博主,我第一时间体验了这款新模型,只能说:真的太强了!
这次V4的发布,不仅仅是参数和分数的提升,更关键的是它标志着百万上下文正式进入普惠时代——从此,1M上下文不再是高阶付费用户的专享,而是DeepSeek所有官方服务的标配。
下面,我就为大家详细拆解DeepSeek-V4的核心亮点。
DeepSeek-V4-Pro:性能比肩顶级闭源模型
🚀 核心亮点速览
| 特性 | DeepSeek-V4-Pro | DeepSeek-V4-Flash |
|---|---|---|
| 总参数量 | 1.6T(万亿) | 284B(亿级) |
| 激活参数量 | 49B | 13B |
| 上下文长度 | 1M tokens(百万级) | 1M tokens(百万级) |
| Agent能力 | 开源模型最佳,体验优于Sonnet 4.5 | 简单任务与Pro相当,复杂任务有差距 |
| 世界知识 | 大幅领先开源模型,稍逊于Gemini-Pro-3.1 | 稍逊于Pro版本 |
| 推理性能 | 超越所有开源模型,比肩顶级闭源模型 | 接近Pro版本的推理能力 |
| 适用场景 | 复杂Agent、高难度推理、长文档分析 | 日常对话、快速响应、成本敏感型应用 |
| 价格 | 标准API定价 | 更快捷、经济的API服务 |
📊 核心技术参数深度对比
根据ModelScope上发布的模型信息,两款模型的具体参数如下:
| 模型 | 总参数量 | 激活参数量 | 上下文长度 | 精度 |
|---|---|---|---|---|
| DeepSeek-V4-Flash-Base | 284B | 13B | 1M | FP8 混合 |
| DeepSeek-V4-Flash | 284B | 13B | 1M | FP4 + FP8 混合* |
| DeepSeek-V4-Pro-Base | 1.6T | 49B | 1M | FP8 混合 |
| DeepSeek-V4-Pro | 1.6T | 49B | 1M | FP4 + FP8 混合* |
*FP4 + FP8 混合:MoE专家参数使用 FP4 精度;其余大部分参数使用 FP8。
基础模型评测对比
| 基准测试(指标) | DeepSeek-V3.2-Base | DeepSeek-V4-Flash-Base | DeepSeek-V4-Pro-Base |
|---|---|---|---|
| 激活参数量 | 37B | 13B | 49B |
| 总参数量 | 671B | 284B | 1.6T |
| 世界知识 | |||
| MMLU (EM) 5-shot | 87.8 | 88.7 | 90.1 |
| MMLU-Pro (EM) 5-shot | 65.5 | 68.3 | 73.5 |
| C-Eval (EM) 5-shot | 90.4 | 92.1 | 93.1 |
| 代码与数学 | |||
| HumanEval (Pass@1) 0-shot | 62.8 | 69.5 | 76.8 |
| GSM8K (EM) 8-shot | 91.1 | 90.8 | 92.6 |
| MATH (EM) 4-shot | 60.5 | 57.4 | 64.5 |
| 长上下文 | |||
| LongBench-V2 (EM) 1-shot | 40.2 | 44.7 | 51.5 |
从基础模型评测可以看出,V4-Pro-Base虽然在激活参数量上比V3.2增加了12B,但在MMLU-Pro上提升了8个百分点,长上下文能力更是提升了11.3个百分点,进步非常明显。
🧠 技术创新:前所未有的长上下文效率
DeepSeek-V4能轻松驾驭百万上下文,秘诀在于其全新的注意力机制:
- 混合注意力架构:结合压缩稀疏注意力(CSA)与重度压缩注意力(HCA),显著提升长上下文处理效率。在百万Token上下文场景下,DeepSeek-V4-Pro相比DeepSeek-V3.2仅需27%的单Token推理FLOPs和10%的KV缓存。
- 流形约束超连接(mHC):在传统残差连接基础上引入,增强跨层信号传播的稳定性,同时保留模型表达能力。
- Muon优化器:实现更快的收敛速度和更高的训练稳定性。
两款模型均在超过32T的多样化高质量Token上进行预训练,并经过全面的后训练流程(SFT + 基于GRPO的强化学习 + 在线策略蒸馏)。
🎯 Agent能力专项优化
V4针对当前主流的Agent框架(如Claude Code、OpenClaw、CodeBuddy等)做了深度适配和优化。在代码任务、文档生成等场景表现大幅提升。
官方内部员工已将V4-Pro作为日常使用的Agentic Coding模型,反馈使用体验优于Sonnet 4.5,交付质量接近Opus 4.6非思考模式。这绝对是一个值得开发者关注的信号。
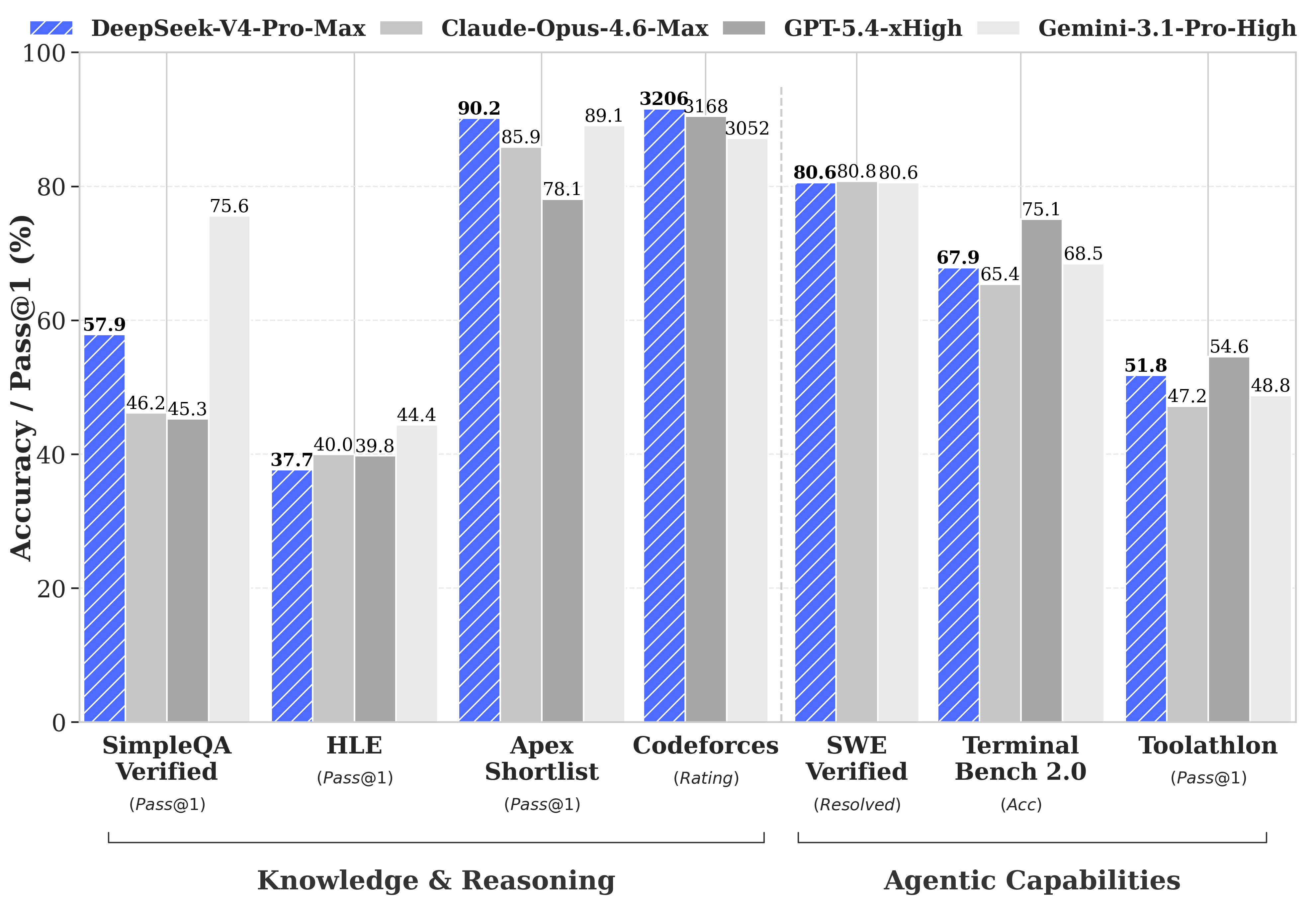
指令微调模型性能对比(Max模式)
| 基准测试 | Opus-4.6 Max | GPT-5.4 xHigh | Gemini-3.1-Pro High | DS-V4-Pro Max |
|---|---|---|---|---|
| MMLU-Pro | 89.1 | 87.5 | 91.0 | 87.5 |
| GPQA Diamond | 91.3 | 93.0 | 94.3 | 90.1 |
| LiveCodeBench | 88.8 | - | 91.7 | 93.5 |
| Codeforces Rating | - | 3168 | 3052 | 3206 |
| SWE Verified | 80.8 | - | 80.6 | 80.6 |
| Terminal Bench 2.0 | 65.4 | 75.1 | 68.5 | 67.9 |
V4-Pro Max在代码能力上已经超越所有对比模型,LiveCodeBench达到93.5%,Codeforces评分达到3206分,创下开源模型新高。
V4-Flash vs V4-Pro 不同模式对比
| 基准测试 | V4-Flash Non-Think | V4-Flash Max | V4-Pro Non-Think | V4-Pro Max |
|---|---|---|---|---|
| MMLU-Pro | 83.0 | 86.2 | 82.9 | 87.5 |
| GPQA Diamond | 71.2 | 88.1 | 72.9 | 90.1 |
| LiveCodeBench | 55.2 | 91.6 | 56.8 | 93.5 |
| MRCR 1M (长上下文) | 37.5 | 78.7 | 44.7 | 83.5 |
| SWE Verified | 73.7 | 79.0 | 73.6 | 80.6 |
Flash的Max模式表现惊人:在GPQA Diamond上从71.2跃升至88.1,LiveCodeBench从55.2飙升至91.6,长上下文能力翻倍。这说明通过增加推理预算,Flash可以接近甚至在某些任务上比肩Pro版本。
💻 如何使用DeepSeek-V4?
1. 网页端/App端
即日起,登录 chat.deepseek.com 或官方App,即可直接与DeepSeek-V4对话,免费体验1M超长上下文记忆。
2. API调用
API已同步更新,通过修改 model 参数调用:
deepseek-v4-prodeepseek-v4-flash
重要提醒:旧的 deepseek-chat 和 deepseek-reasoner 模型名将于 2026-07-24 停止使用。过渡期内,它们会分别指向v4-flash的非思考模式与思考模式。
V4支持三种推理强度模式:
| 推理模式 | 特点 | 典型应用场景 |
|---|---|---|
| Non-think | 快速、直观的响应 | 日常例行任务、低风险决策 |
| Think High | 有意识的逻辑分析,速度较慢但更准确 | 复杂问题求解、规划 |
| Think Max | 将推理能力发挥到极致 | 探索模型推理能力的边界 |
复杂Agent场景建议使用思考模式并设置强度为max。
3. 开源与本地部署
- 模型权重开源:HuggingFace合集 | ModelScope合集
- 技术报告:DeepSeek-V4技术报告PDF
本地部署建议:
- 采样参数设置:
temperature = 1.0, top_p = 1.0 - 对于 Think Max 推理模式,建议将上下文窗口至少设置为 384K tokens
💎 我的个人评测与展望
简单测试了几个长文档理解和复杂代码生成任务,V4-Pro的表现确实惊艳。百万上下文意味着你可以一次性丢入整个项目代码库、整套技术文档或一整本专业书籍,模型依然能准确捕捉细节并进行深度推理。
Flash版本在快速响应和成本上的优势也很明显。对于日常辅助编程、信息检索等任务,Flash完全够用,且经济性更好。
最让我惊喜的是Flash的Max模式——通过增加推理预算,它能在很多复杂任务上缩小与Pro版本的差距。这种灵活性让开发者可以在成本和质量之间做出更精细的权衡。
🔮 写在最后
DeepSeek在官方公告结尾引用了荀子的话:「不诱于誉,不恐于诽,率道而行,端然正己。」 这体现了团队坚持长期主义、踏实创新的决心。
从开源到免费百万上下文,再到性能比肩顶级闭源模型,DeepSeek正在重新定义AI服务的性价比门槛。作为开发者,我们乐见这样的技术进步与开放生态。
大家赶快去试试吧!体验后欢迎在评论区分享你的感受。如果这篇介绍对你有帮助,别忘了点赞、收藏、关注三连~
标签:#DeepSeek-V4 #百万上下文 #开源LLM
本文为原创内容,版权归作者所有,转载需注明出处。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)