零基础开始,一步步解释常见损失函数原理。
·
文章目录
什么是损失函数?
损失函数用于衡量模型预测值与真实值之间的差距。
- 想象一下你在学习投篮。你投出的球,有的离篮筐很近,有的很远。
- 你的目标:让球每次都正中篮筐。
- 衡量标准:你如何知道自己投得好不好?你会看“球离篮筐有多远”。这个“距离”就是你对自己这次投篮表现的评价。
- 在机器学习和神经网络中:
- 模型:就像一个正在学习投篮的新手。
- 目标:让模型的预测结果尽可能接近真实的答案。
- 损失函数:就是那个“衡量距离”的工具。它计算模型预测值与真实值之间的差距(即“损失”或“误差”)。损失值越小,说明模型预测得越准。
核心思想:神经网络学习的过程,就是通过不断地调整自身参数(就像调整投篮的力度和角度),来最小化这个损失函数的值。
损失函数的工作原理
以房价预测为例:
- 真实数据:一套房子实际售价是300万(真实值 t)。
- 模型预测:模型预测售价为290万(预测值 y)。
- 计算损失:损失函数计算290万和300万之间的差距(如10万)。模型根据损失值调整参数,逐步减小预测误差。
模型看到这个“10万”的损失后,就知道:“哦,我猜低了,下次要调高一点。”然后它内部会进行微调。下一次面对类似房子时,它可能就预测295万,损失变成5万,更接近了。如此反复,直到损失尽可能小。
回归任务损失函数
目标是让预测值 y 无限接近真实值 t。
平均绝对误差(MAE/L1 Loss)
- 公式:
L = 1 n ∑ i = 1 n ∣ y i − t i ∣ L = \frac{1}{n} \sum_{i=1}^n |y_i - t_i| L=n1∑i=1n∣yi−ti∣ - 原理:
- 计算每个样本的预测误差 ( y i − t i ) (y_i - t_i) (yi−ti)。
- 对这个误差取绝对值。同样保证了非负。
- 对所有样本的绝对误差求平均。
- 特点:对异常值更鲁棒(Robust)。因为误差是线性增长的,预测错100万,损失就是100万,不会被平方放大成1亿。这使得训练过程受异常数据干扰较小。
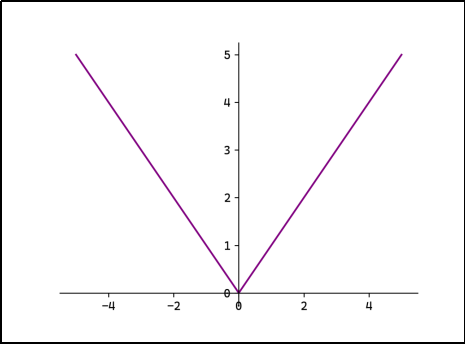
- 图示:文档中L1 Loss的曲线是一条V型折线,增长是匀速的。
均方误差(MSE/L2 Loss)
- 公式:
L = 1 n ∑ i = 1 n ( y i − t i ) 2 L = \frac{1}{n} \sum_{i=1}^n (y_i - t_i)^2 L=n1∑i=1n(yi−ti)2 - 原理:
- 先计算每个样本的预测误差 ( y i − t i y_i - t_i yi−ti)。
- 把这个误差平方。为什么平方?第一,保证结果永远是正数(距离没有负的);第二,放大了大的误差。如果你预测错了100万,平方后是1亿,这个巨大的数字会强烈地提醒模型:“你这个错得太离谱了!”
- 对所有样本的平方误差求平均。
- 特点:对异常值( outliers )非常敏感。因为平方会极大惩罚大误差,如果数据中有个别极端错误的值,会让损失剧烈波动,主导整个训练过程。
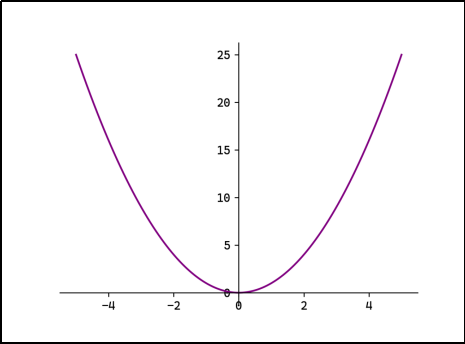
- 图示:文档中L2 Loss的曲线是一个向上的抛物线,误差越大,损失增长越快。
Smooth L1 Loss
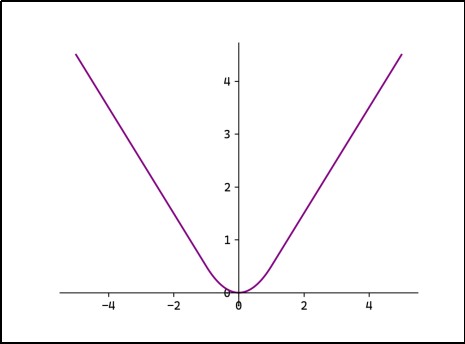
- 公式:分段函数,误差小时用平方项,误差大时用绝对值项。
- L = { − 1 2 ( y i − t i ) 2 if ∣ y i − t i ∣ < 1 ∣ y i − t i ∣ − 1 2 if ∣ y i − t i ∣ ≥ 1 L = \begin{cases} -\frac{1}{2} (y_i - t_i)^2 & \text{if } |y_i - t_i| < 1 \\ |y_i - t_i|-\frac{1}{2} & \text{if } |y_i - t_i| \geq 1 \end{cases} L={−21(yi−ti)2∣yi−ti∣−21if ∣yi−ti∣<1if ∣yi−ti∣≥1
- 原理:结合了MSE和MAE的优点。
- 当误差很小时(比如 ∣ y − t ∣ < 1 |y-t| < 1 ∣y−t∣<1),它像MSE一样,利用平方项的曲线性质,让梯度变-化更平滑,有利于模型精细调整。
- 当误差很大时(比如 ∣ y − t ∣ > = 1 |y-t| >= 1 ∣y−t∣>=1),它像MAE一样,转为线性增长,避免因平方而导致梯度爆炸(变得太大),对异常值不那么敏感。
- 特点:一种更实用、更稳定的选择,尤其在目标检测等领域常用。
分类任务损失函数
交叉熵误差(Cross Entropy Error)
- 公式(多分类):
L = − 1 n ∑ i = 1 n ∑ c = 1 C t i , c log ( y i , c ) L = -\frac{1}{n} \sum_{i=1}^n \sum_{c=1}^C t_{i,c} \log(y_{i,c}) L=−n1∑i=1n∑c=1Cti,clog(yi,c) - 特点:鼓励正确类别的预测概率最大化,适用于多分类任务。
- 原理(我们用例子理解):
假设一个三分类问题(猫、狗、鸟),某张图片的真实标签是“猫”。- 真实值 t :用 one-hot 编码 表示,即 [1, 0, 0](猫位置为1,其余为0)。
- 模型预测 y :经过Softmax函数后,得到三个类别的概率,比如 [0.7, 0.2, 0.1]。这表示模型认为有70%可能是猫。
- 计算损失:根据公式,我们只关心真实类别(猫)对应的那部分。t_{i,c} 只有在 c=“猫”时才等于1,其他为0。所以损失简化为 L = - log(0.7)。
- log函数的作用:预测概率 y 越接近1(完美预测),log(y) 越接近0,损失 -log(y) 就越小(接近0)。预测概率 y 越小(预测错误),log(y) 是一个很大的负数,-log(y) 就是一个很大的正数(损失很大)。
- 核心:它只盯着正确类别的预测概率,并惩罚低概率。概率为1时损失为0,概率为0时损失趋于无穷大。
二元交叉熵损失(Binary Cross-Entropy Loss)
- 公式:
L = − 1 n ∑ i = 1 n [ t i log ( y i ) + ( 1 − t i ) log ( 1 − y i ) ] L = -\frac{1}{n} \sum_{i=1}^n \left[ t_i \log(y_i) + (1 - t_i) \log(1 - y_i) \right] L=−n1∑i=1n[tilog(yi)+(1−ti)log(1−yi)] - 特点:适用于二分类任务,同时考虑正类和负类的预测情况。
- 原理:这是交叉熵在二分类(只有两个类别,如正/反,是/否)时的特例。
- 真实标签 t i t_i ti 通常是 0 或 1。
- 模型输出 y i y_i yi 是一个介于0到1之间的数(通常用Sigmoid函数得到),表示属于“正类”的概率。
- 公式解读:
- 如果真实标签是1 ( t i = 1 ) (t_i=1) (ti=1),公式后半部分为0,损失就是 − l o g ( y i ) -log(y_i) −log(yi),鼓励 y i y_i yi 靠近1。
- 如果真实标签是0 ( t i = 0 ) (t_i=0) (ti=0),公式前半部分为0,损失就是 − l o g ( 1 − y i ) -log(1 - y_i) −log(1−yi),鼓励 y i y_i yi 靠近0(即 1 − y i 1-y_i 1−yi 靠近1)。
- 它同时考虑了正类和负类的预测情况。
总结对比
| 任务类型 | 损失函数名称 | 核心思想 | 关键特点 |
|---|---|---|---|
| 回归 | 均方误差(MSE) | 惩罚大的误差(平方放大) | 对异常值敏感,梯度稳定 |
| 回归 | 平均绝对误差(MAE) | 平等对待所有误差(绝对值) | 对异常值鲁棒,在零点不可导 |
| 回归 | Smooth L1 Loss | 小误差精细调,大误差稳着来 | 平衡MSE和MAE,实践常用 |
| 分类 | 交叉熵误差 | 让正确类别的预测概率最大化 | 分类任务的标准选择,与Softmax绝配 |
| 分类 | 二元交叉熵 | 二分类版的交叉熵 | 用于二分类,与Sigmoid绝配 |
最终建议
- 分类问题(如图像分类):使用交叉熵损失(CrossEntropyLoss)。
- 回归问题(如房价预测):从均方误差(MSE)开始,若数据有异常值可尝试MAE或Smooth L1 Loss。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)