解读 PTO 通信指令集:昇腾多卡数据搬移的 N 种路径
PTO(Parallel Tile Operation)是昇腾 CANN 定义的一套面向 tile 编程的虚拟 ISA。如果你还不了解 PTO 的 Tile 概念和整体设计思路,推荐先阅读《浅谈昇腾虚拟指令集 PTO》系列。本文聚焦 PTO ISA 的通信扩展指令集——当计算从单卡走向多卡,数据搬运的故事就从”核内物流”升级成了”城际运输”。
一、单卡是工厂,多卡就是工业园区
前几篇文章里,我们把昇腾芯片比作一座精密的工业园区:矩阵单元是生产车间,片上 Buffer 是临时仓库。在单卡内部,MTE 就像车间和仓库之间的传送带。PTO 指令集就是这座园区的调度五线谱,让各个加速器有节奏地运转。
这个比喻在单卡内部很好用。但大模型训练从来不是一个人的事——8 张卡、64 张卡、上千张卡,每张卡都在算自己的那一份,然后把结果汇总。当数据需要跨卡时,“核内传送带”就必须升级为“跨厂区物流”。
问题来了:工厂和工厂之间,怎么运货?
想象一下,你是一个工业园区的物流调度员。园区里有几十座工厂,分布在不同的区域。有些工厂紧挨着,走廊里推个小车就到了;有些隔着几个街区,得叫专门的货车;有些在另一个城市,得走高速。
更头疼的是:每一代园区扩建,运输基础设施都在变。老园区只有电动三轮和小货车,新园区修了高速公路,最新的园区甚至建了专门的集散中心。
如果每次扩建,所有工厂的物流流程都要重写一遍,那还了得?
你需要的是一套统一的运单格式:不管底层走三轮还是走高速,运单上写的东西不变。 这就是 PTO 通信指令集要解决的问题。
二、昇腾芯片上的”N 种运输方式”
在展开 PTO 通信指令之前,先看看昇腾硬件到底提供了哪些跨卡运输通道。
先看一眼昇腾的”仓库体系”
数据在昇腾芯片里的存储是分层级的,就像一座工厂里有不同级别的仓库:
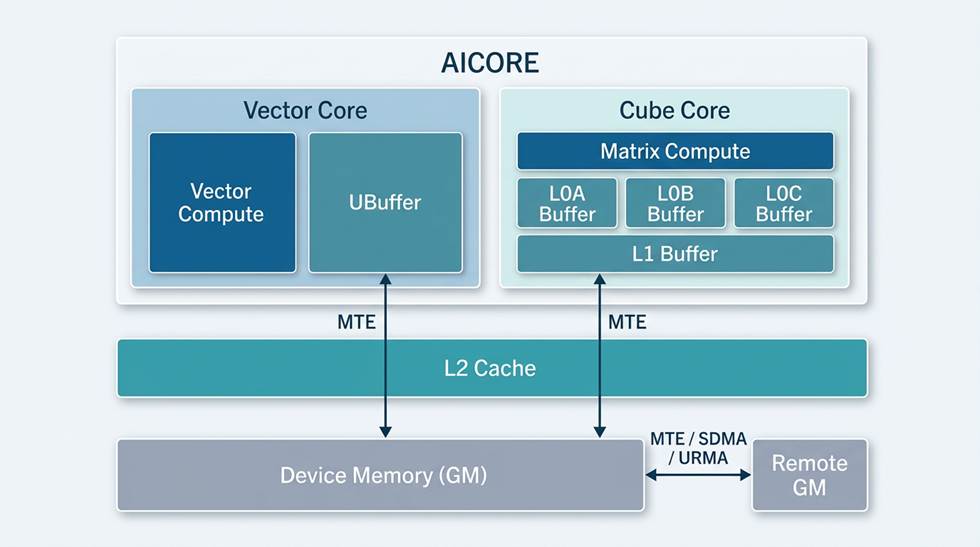
昇腾芯片的仓库体系与搬运路线
- GM(Global Memory):片上内存,容量最大,所有 AICore 共享,一般是跨卡通信的起点和终点。
- UBuffer(Unified Buffer):核内 SRAM,容量较小但速度极快,AIV(AI Vector单元)的向量计算和细粒度数据搬运都围绕它进行。
- L0A/L0B/L0C、L1:更靠近计算单元的缓存层级,主要用于矩阵乘的流水线。
本文探讨的跨卡通信,主要聚焦于“本地 GM 到远端 GM”这条主干道。(注:虽然昇腾系统也支持从本地 UBuffer 直接发货到远端 GM,但这属于 MTE 引擎的专属路线。为统一步调,下文主要围绕 GM 间的搬运展开。)
搬运引擎:谁来搬、怎么搬
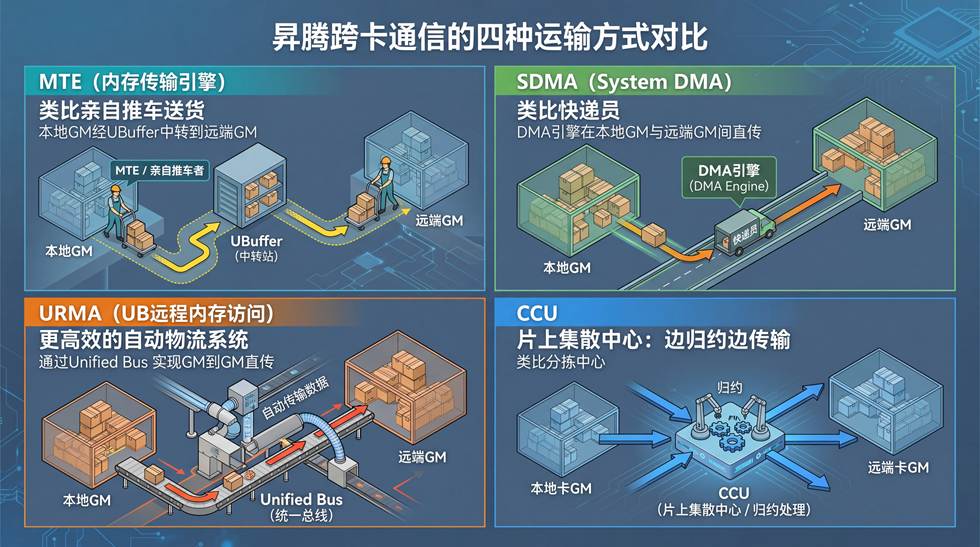
昇腾跨卡通信的四种运输方式对比
结合上图展示的“物流路线”,我们可以把昇腾上多种搬运引擎的核心差异梳理成一张详细的“运力配置表”:
|
技术名称 |
谁在搬 |
怎么搬 |
适合什么 |
代际 |
|
MTE |
AIV 亲自动手 |
经 UBuffer 中转,同步 |
灵活,支持 2D strided,tile 级精细控制 |
Ascend 910/950 全系列 |
|
SDMA |
委托专用 DMA 引擎 |
GM 直传,异步 |
大块连续数据,AIV 可以继续干别的 |
Ascend 910/950 全系列 |
|
URMA |
委托硬件 RDMA 引擎 |
GM 直传,异步 |
高带宽用户态 RDMA |
Ascend 950 |
|
CCU |
委托专用协处理器 |
片上 Reduce + 传输 |
集合通信硬件卸载 |
Ascend 950 |
打个比方:MTE 就像你亲自推着小车送货——灵活、精确、随叫随到(启动延迟极低),但你在送货的时候就干不了别的,这就是所谓的同步操作。SDMA/URMA 则像你把包裹交给快递员——你解放了双手可以继续干活,这就是所谓的异步操作。但叫快递员需要填单子、等揽收(存在较高的启动开销),如果是极小块的数据和较短的传输距离,可能还不如你自己送得快。CCU 是950代际新增的集合通信处理器单元,更像一个专门的分拣中心,你把货扔过去,它在内部完成归拢和分发。
注意最后一列——不同代际的芯片,搬运能力各有侧重。910系列有 MTE 和 SDMA,950 还新增了 URMA 和 CCU。
这就引出了 PTO 通信 ISA 的核心设计哲学:
一套运单,N 种运法。你填运单,按需选路。
三、亲自送货:TPUT / TGET
最朴素的跨卡搬运,就是用 MTE 引擎进行跨卡的GM到GM传输。数据的旅程是:
本地 GM → UBuffer tile(中转仓库)→ 远端 GM
就像你亲自推车送货:路线灵活、什么形状的 tile 都能搬、2D strided 布局也没问题。代价是你在搬货的时候没法干别的——MTE 是同步的,AIV 必须等搬完才能继续。
但它胜在哪儿都有——从 910 到 950,MTE 引擎全系列标配,是 PTO 通信的”保底路径”。
为什么不是直接 GM 到 GM?
因为 MTE 引擎的硬件通路,天生就是为了给计算核心喂数据设计的。它的读写通路是分离的:读指令(MTE2)只能把数据从 GM 搬进核内的 UBuffer,写指令(MTE3)只能从 UBuffer 搬回 GM。(注:MTE1 通常用于 L1 到 L0 的核内搬运)。
虽然多了一道中转,但这个过程 PTO 帮你全自动处理了:
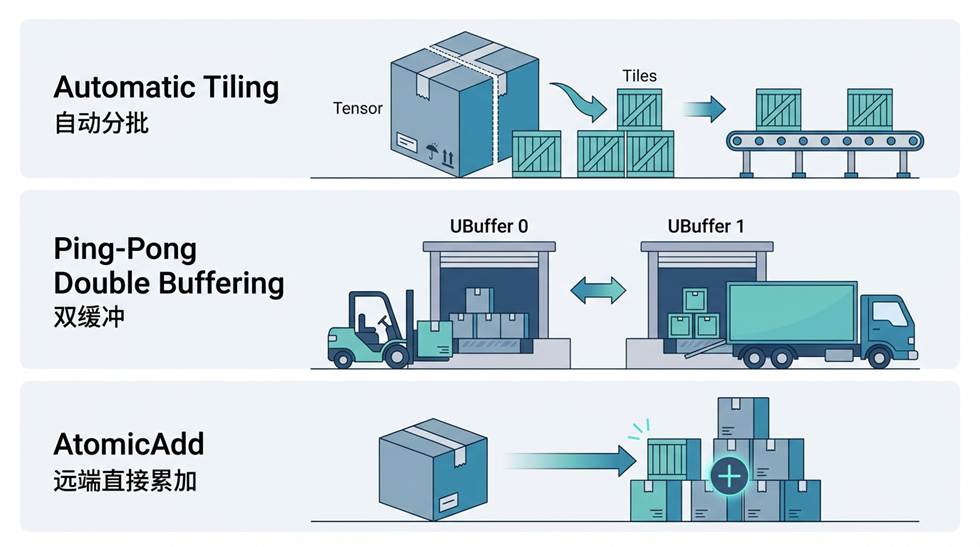
TPUT 的三大自动化搬运特性
- 货太多装不下? 自动分批。TPUT 会把超大 tensor 按行列切块(2D sliding),逐块搬运,对你完全透明。
- 想加快速度? 用两个中转仓库轮流装卸(Ping-Pong 双缓冲),当前这批在卸货的同时,下一批已经开始装了。
- 想在对面直接累加? 支持 AtomicAdd,远端那边收到数据直接加上去,不用先存再加。
注:以下接口示例以 PTOAS 风格伪代码展示,底层同样提供 C++ DSL。
# 最简单的远端写
pto.comm.tput(dst_gm, src_gm, staging_tile)
# 双仓库轮流装卸(Ping-Pong 双缓冲)
pto.comm.tput(dst_gm, src_gm, ping_tile, pong_tile)
# 远端直接累加(硬件原子加在目标侧完成)
pto.comm.tput(dst_gm, src_gm, staging_tile, atomic=AtomicAdd)三行代码,三种模式。底层调了多少个 MTE 指令、怎么切块、怎么流水线,全部被 TPUT 这一条 PTO 指令藏起来了。
这就是 PTO 通信指令和裸 MTE 调用的本质区别:你操作的不是底层搬运引擎,而是 tile 级的语义——“把这块数据搬到那边去”。
四、委托搬运:TPUT_ASYNC / TGET_ASYNC
同步路径的问题很明确:搬运期间,AIV 干等着。
你亲自推车去送货,送货的时候产线就停了,等你回来才能继续干活。对于追求高效率的大模型训推来说,这不能接受。
核心思想:把包裹交给快递员
异步路径的哲学很简单:别亲自送了,委托给专用的搬运引擎。 发完搬运指令,不用等搬运完成,你接着干你的活。等活儿干得差不多了,再去查一下”货到了没?“。
本地 GM → DMA 引擎(后台搬运)→ 远端 GM
数据不再经过 UBuffer 中转,而是在两端 GM 之间直传。“DMA 引擎”具体是哪个?这取决于你在哪一代芯片上、用哪条指令。
SDMA 路径
SDMA(System DMA) 是独立于 AICore 的专用 DMA 引擎。在PTO的设计里面,AIV 通过 TPUT_AYSNC 指令,把搬运任务转换成向 SDMA 硬件提交的传输描述符——相当于你把包裹和地址填好,交给快递员,然后回去继续工作。
# 叫一个快递员(构建会话)
# scratch_type 定义了这块剪贴板的规格(通常只需 256B 的极小 UBuffer 空间)
scratch = pto.alloc_tile(scratch_type)
session = pto.comm.build_async_session(scratch, workspace)
# 下发搬运单(立即返回,不等完成)
put_event = pto.comm.tput_async(dst, src, session)
# ... 你继续干活 ...
# 最后确认:货都到了吗?
pto.wait_async_event(put_event)这里有个细节值得一提:代码里的 scratch tile 并不是用来装货的“中转箱”,而是 AIV 和快递员(SDMA)交接用的“调度剪贴板”。AIV 在这块极小的 UBuffer 空间里填写发车指令(更新 Queue Tail)、查收回执(Polling Flags)。货物本身完全由快递员从本地 GM 直接拉到远端 GM。
URMA 路径(Ascend 950 新增)
到了昇腾 950,新增了 URMA(UB 远程内存访问,UB Remote Memory Access)——基于Unified Bus 灵衢互联能力的硬件用户态 RDMA。相当于园区升级了更高效的自动化物流系统。
对用户来说,URMA 和 SDMA 仍然是同一套异步接口:先建会话,再下发搬运单,最后 wait 或 test 完成态。真正选走 SDMA 还是 URMA,通常由更外层的引擎参数或目标平台决定。底层硬件机制的巨大差异被 PTO 的指令抽象完美地屏蔽掉了。 开发者只需要关心“货送到了没”,而不需要关心底层是怎么查收的。
还有一个很优雅的设计叫 Quiet 语义:你连续发了 10 张搬运单,最后只需要查最后一张的状态。如果最后一张到了,前面 9 张一定也到了。这就像是物流的“批量签收”,只要这批货的最后一个包裹扫码入库了,前面的包裹肯定已经在仓库里了。一次确认,全部生效。
把这些部件放到一张图里看,会更容易把”后台直传 + 会话控制 + Quiet 语义”三件事串起来:
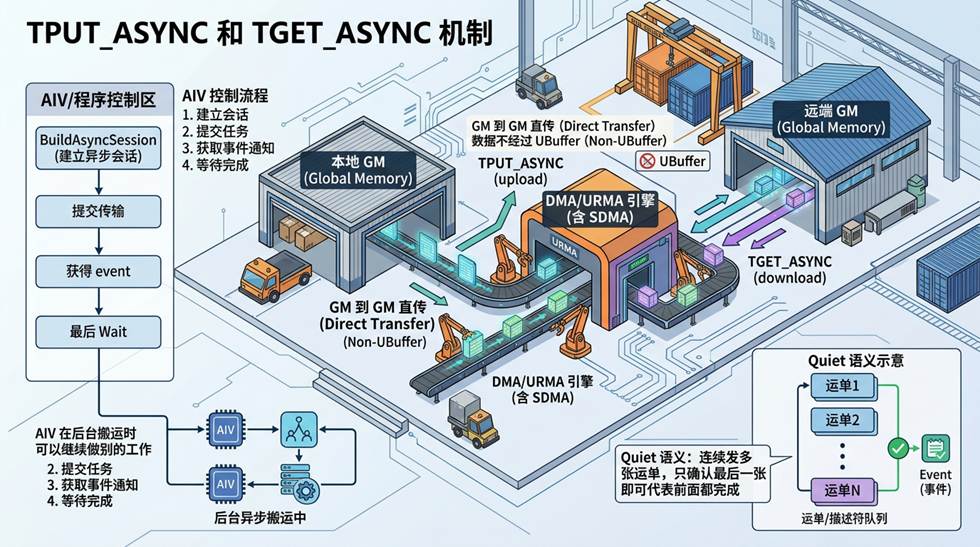
TPUT_ASYNC 和 TGET_ASYNC 机制图
核心设计:同一张运单,自动选路
现在问题来了:Ascend 910系列上该走 SDMA,Ascend 950上该走 URMA,程序员需要写两份代码吗?
不需要。
PTO 用了一套非常干净的编译期分派机制。以 TGET_ASYNC 的底层实现为例(简化):
template <DmaEngine engine = DmaEngine::SDMA>
AsyncEvent TGET_ASYNC_IMPL(dst, src, session)
{
if constexpr (engine == DmaEngine::SDMA) {
return SDMA_IMPL(dst, src, ...); // 所有平台走 SDMA
} else if constexpr (engine == DmaEngine::URMA) {
return URMA_IMPL(dst, src, ...); // Ascend 950 走 URMA
}
}if constexpr 是编译期分支——编译完成后,不走的分支直接消失,零运行时开销。TGET_ASYNC 在 Ascend 910/950 上都走 SDMA 后端,950 上还可以选择走 URMA。
这就是”一套运单,灵活选路”的技术实现。 同一行用户代码,底层走哪条路、是否需要回退,全部由编译宏和 if constexpr 自动决定。
五、信号指令:TNOTIFY / TWAIT / TTEST
光有搬运还不够。工厂之间需要协调:“我这批货发出去了,你可以开始用了”;“我在等你那边的原料,到了通知我”。
PTO 提供了三条信号指令,就像工厂之间的信号灯系统:
- TNOTIFY:给对方亮绿灯(“我搞定了”)
- TWAIT:盯着信号灯等(“你搞定了我再动”)
- TTEST:瞄一眼信号灯(“搞定没?没搞定我先干别的”)
信号支持原子累加和直接设置两种模式,比较条件支持 EQ/NE/GT/GE/LT/LE 六种。更精妙的是支持 2D Signal Grid——不是一盏灯,而是一整面信号墙,适合多 rank 多 tile 的复杂协同场景。
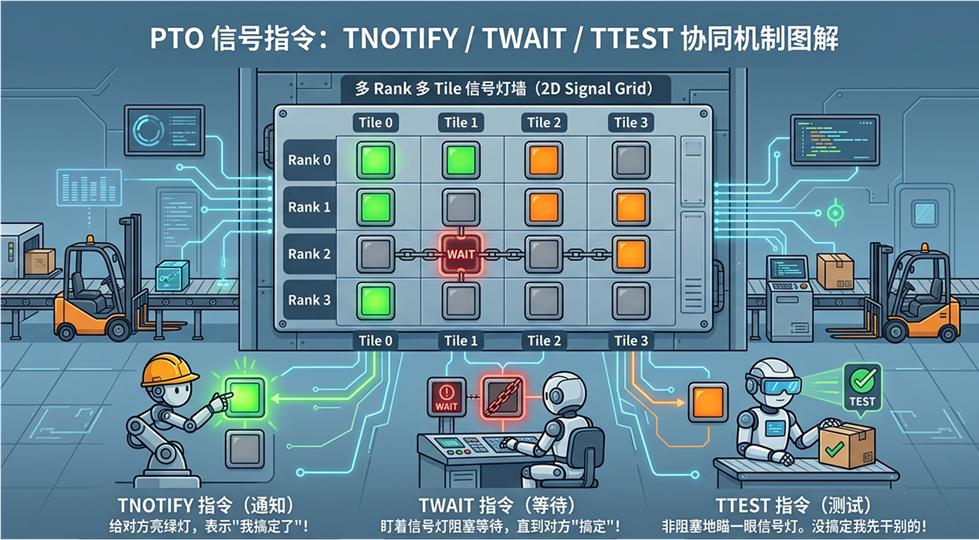
PTO 信号指令:TNOTIFY / TWAIT / TTEST
这三条指令和搬运指令组合起来,就构成了完整的跨卡通信协议。 后面的实操案例会展示它们如何像齿轮一样咬合在一起。
六、集散中心:走向 CCU 硬件卸载
前面说的 MTE、SDMA、URMA,本质上都是点对点搬运——从 A 搬到 B。但大模型训练中有一类操作更复杂:AllReduce——8 张卡各算了一份结果,需要全部加起来,再把总结果发给所有人。
传统做法是让 AIV 一个个搬、一个个加,拼装出 AllReduce 的效果。就像没有物流中心的年代,工厂之间互相派货车送货,然后各自手工汇总。
昇腾 950 带来了新的选择:CCU(Collective Communication Unit)。
CCU 是什么?
一句话:它是一个建在 IO-Die 上的专用集散中心。 它不是通用计算核心,而是专门做集合通信的硬件协处理器。
- 有自己的微码指令集(Load/Ctrl/Trans/Reduce 四类)
- 有自己的片上缓冲区(Memory Slice)
- 有硬件 Reduce 引擎,直接在片上做加法/取最大值
- 数据不用搬回 AICore,在集散中心内部就处理完了
关于 CCU 硬件架构的详细分析,推荐阅读《集合通信处理器(CCU)技术解读文档》。
PTO 怎么和 CCU 对接?
PTO 把 CCU 的使用拆成两段,就像你在物流平台上发快递:
- Host 侧(平台下单):编译 CCU kernel → 注册 → Launch,产出一个”取件码”(CcuDeviceSession)
- Device 侧(工厂协作):AIV 拿着取件码,给 CCU 亮绿灯(AIV_LAUNCH),CCU 干活,干完了亮回来(CCU_DONE)
AIV 不参与实际的搬运和归约——它只负责握手信号。 真正的重活全部由 CCU 硬件完成。
对于 GEMM_AR 这样的通算融合场景,协议变成了逐 tile 级的流水线握手:AIC 算完一个 tile → AIV 亮灯”这块 ready 了” → CCU 取走做 reduce → CCU 亮灯”这块搞定了” → AIV 继续下一块。这就像工厂的产线和集散中心之间实现了无缝对接,边生产边发货。
接口一致性
在 PTO 指令层面,CCU 路径和传统路径复用了相同的 API:
# 传统方式:AIV 自己搬
pto.comm.tbroadcast(group, src_gm, staging_tile)
# CCU 方式:加一个 session 参数,切换到硬件卸载
pto.comm.tbroadcast(group, src_gm, staging_tile, session=device_session)多传一个参数,搬运方式就从”自己动手”变成了”委托集散中心”。 目前 CCU 路径已完成 CPU-SIM 功能仿真验证,真实硬件平台的对接正在紧锣密鼓地进行中。
七、实操:GEMM + AllReduce,边算边搬
说了这么多运输方式,它们在实际场景中是怎么配合的?
以 pto-isa 仓库中的 GEMM AllReduce 融合算子为例。这是一个 8 卡场景:每张卡算一部分矩阵乘,然后把结果 AllReduce 汇总。
传统做法的问题
先算完 GEMM,再做 AllReduce。两个阶段完全串行。就像工厂先把一整批货全部生产完,堆在仓库里,再统一发货。产线空闲的时候物流在跑,物流空闲的时候产线在跑。两边互相等,谁都没吃饱。
PTO 的做法:边生产边发货
910B 的架构天然支持这种并行——24 个 AIC(计算核)和 24 个 AIV(通信核)物理独立,可以完全并行工作。
AIC 产线: [GEMM tile 0] [GEMM tile 1] [GEMM tile 2] ...
↓ ready ↓ ready ↓ ready
AIV 物流: [搬 tile 0] [搬 tile 1] [搬 tile 2] ...下图把这种”边算边搬”的流水线重叠关系画得更直观:

PTO 通算融合:GEMM 计算与 AllReduce 通信重叠示意
关键的 PTO 通信指令各司其职:
- TPUT<AtomicAdd>:ReduceScatter 阶段的搬运工具。AIV 把本地 GEMM 结果直接原子累加到 owner rank 的地址——硬件原子加在目标侧完成,省去了独立的 Reduce 步骤。
- TTEST:AIV 用它非阻塞地”瞄一眼”Ready Queue——“AIC 那边有新 tile 算完了吗?”有就搬,没有就用 TWAIT 硬件等待,避免空转。
- TNOTIFY + TWAIT:DeviceBarrier 的实现——block 0 用 TNOTIFY 通知所有远端 rank “我这一轮搞定了”,再用 TWAIT 等所有人都到齐。
实测收益:打破算子边界的红利
在 8 卡 910B 环境下(BF16 数据类型,M=5416, K=6144, N=1408),我们简单对比了传统串行和 使用PTO Tile指令实现计算-通信流水线的表现:
|
模式 |
耗时 |
说明 |
|
纯计算 |
365 us |
257 TFLOPS,98% 峰值利用率 |
|
先算后通(串行) |
743 us |
计算 368us + 通信 375us |
|
边算边搬(流水线) |
631 us |
加速 1.18x,31% 通信被掩盖 |
可以看到,高达 31% 的通信开销被成功“掩盖”在了计算过程中。这种级别的 Overlap 是传统的 Host 侧Kernel调度根本无法做到的。
这就是引入 Device 侧通信指令的核心价值:它彻底打破了算子边界的黑盒。 传统 Host 调度的最小单位是一整个算子——必须等矩阵乘全部算完,才能启动通信算子。而 PTO 将调度的权力下放到了 Kernel 内部,让开发者能以 Tile 为粒度,精确编排“算完一块、搬走一块”的微观流水线。当调度的粒度细化了一个数量级,性能优化的空间自然就豁然开朗了。
八、一套运单,跨三代硬件
回到开头的比喻:PTO 通信 ISA 就是那套跨越园区代际的“统一运单格式”。
用户代码:PyPTO 脚本 / PTOAS 代码/ C++ 算子代码(填写运单)
↓
PTOAS 编译层 / pto_comm_inst.hpp(运单受理窗口)
↓
pto_comm_instr_impl.hpp(编译期选路)
↓
NPU: MTE / SDMA / URMA / CCU | CPU: 仿真桩在这套体系下,十余条精简的通信指令,覆盖了从点对点到集合通信的完整场景:
|
类别 |
指令 |
类比 |
|
同步搬运 |
TPUT, TGET |
亲自推车 |
|
异步委托 |
TPUT_ASYNC, TGET_ASYNC |
叫快递员 |
|
信号协调 |
TNOTIFY, TWAIT, TTEST |
信号灯 |
|
集合操作 |
TGATHER, TSCATTER, TBROADCAST, TREDUCE |
分拣中心 |
而当这份“运单”下发到底层时,PTO 编译器会自动根据目标芯片的代际,将其映射到最优的硬件通路上。一张表看懂这种跨代兼容性:
|
平台 |
同步(亲自搬) |
异步(委托搬) |
集合通信 |
|
Ascend 910系列 |
MTE |
SDMA |
AIV 自己搬 |
|
Ascend 950 |
MTE |
SDMA / URMA |
CCU 硬件卸载 |
这意味着,你只需写一次代码,编译到不同平台时,PTO 就会自动为你选择最合适的硬件路径。
这就是 PTO 通信 ISA 的核心价值:它并不是生硬地外挂了一套通信 API,而是在 Tile 编程模型的土壤里,原生地长出了通信能力。计算与通信共享同一套 Tile 抽象、同一套事件同步机制、同一套跨代兼容架构。
从此,计算与通信不再是割裂的两个孤岛,而是统一编程模型下协同运转的精密齿轮——这正是大模型时代打破通信瓶颈、走向极致 Overlap 的必由之路。
PTO 通信 ISA 的代码已开源在 pto-isa 仓库,欢迎体验和反馈。
PTO ISA开源仓:https://gitcode.com/cann/pto-isa/tree/master/include/pto/comm
加入我们,以码会友:
微信社群:

飞书社群:


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)