LeCun和文心同发现:原生多模态是个偏科生

创新点
- 本文核心创新在于彻底摒弃基于预训练语言模型微调的范式,采用从 0 开始的统一多模态预训练方案,基于 Transfusion 框架将文本自回归预测与视觉流匹配扩散目标融合。
- 揭示视觉与语言的缩放不对称性并给出架构解法,通过 IsoFLOP 分析发现视觉远比语言更依赖数据,而混合专家(MoE)架构可自适应实现模态专家分化。
方法
本文采用从零开始受控预训练的实验思路,基于Transfusion统一框架,将文本的自回归下一词预测任务与视觉的流匹配扩散任务结合,在包含纯文本、视频、图文配对数据以及动作条件视频的多元混合数据上进行端到端训练,全程保持计算预算与超参数一致以控制变量,通过模块化消融实验分别拆解视觉表征、数据配比、模型架构与缩放规律的影响,同时采用IsoFLOP分析方法推导视觉与语言的缩放定律,借助固定计算预算下的参数与数据量扫点确定最优配比,并通过导航世界模型NWM的零样本规划与轨迹误差指标评估世界建模能力,结合文本困惑度、图像生成质量、VQA准确率等多维度指标完成全面评测,最终通过对MoE专家路由行为的量化分析揭示模态专业化的涌现规律。
统一多模态预训练整体框架与研究维度总览

本图整体分为上下两部分:上半部分清晰展示了模型的统一架构,采用单一解码器 - only Transformer 作为主干,同时处理文本与视觉两类信号,文本侧通过分词器做自回归下一词预测,视觉侧经由视觉编码器得到表征并采用流匹配 / 扩散做下一视觉状态预测,两套任务目标在统一框架内联合优化;下半部分则提炼出全文的五大核心研究维度,分别是视觉表征、数据组合、世界建模、架构设计与缩放规律,直观呈现本文从模型结构到训练机制、再到关键实验变量的完整研究脉络,既体现了以 Transfusion 为基础的文本 - 视觉一体化建模思路,也清晰说明全文围绕这一统一架构,系统探究视觉表征选型、多模态数据协同、世界建模能力涌现、MoE 架构设计以及视觉 - 语言缩放不对称性等核心问题,是理解整篇论文研究范式与实验逻辑的总纲图示。
多模态预训练四类训练数据示例

本图直观展示了本文统一多模态预训练所使用的四类核心训练数据样本,清晰呈现模型学习的信号来源。第一类为纯文本数据,取自大规模网页文本,用于维持语言建模能力;第二类为图文配对数据,包含图像与对应的描述性文本,是建立视觉与语言对齐关系的关键;第三类为动作数据,以文本形式表示导航位移、旋转等连续动作,用于支撑世界建模与具身预测任务;第四类为纯视频数据,以逐帧形式输入,提供无标注的真实世界时空动态信息。这四类数据共同构成多样化训练组合,支撑模型同时习得语言理解、视觉生成与理解、跨模态对齐以及物理世界预测等综合能力,也对应后文数据协同、世界建模等核心实验的数据源基础。
不同视觉表征在多模态任务上的性能对比
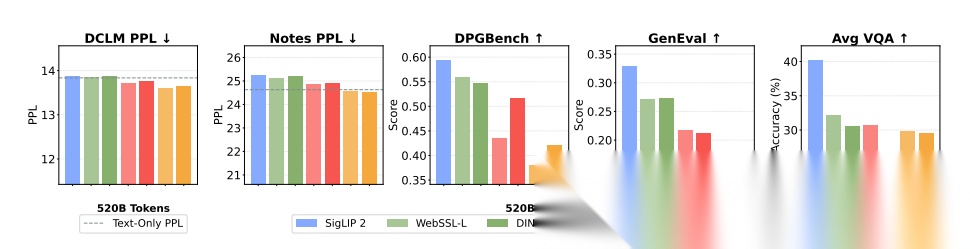
本图通过多维度指标对比了多种视觉表征在统一多模态预训练中的效果,核心验证RAE(以 SigLIP 2 为代表) 是兼顾视觉理解与生成的最优统一表征。图中对比了语义编码器(SigLIP 2、WebSSL‑L、DINOv2‑L)、VAE 类编码器(SD‑VAE、FLUX.1)以及原始像素输入等多种方案,在文本困惑度(PPL)、图像生成指标(DPGBench、GenEval)和视觉问答(VQA)准确率上全面评估:结果显示,基于 RAE 的 SigLIP 2 在视觉生成与理解任务上显著优于传统 VAE,同时文本困惑度与纯文本基线基本持平,而原始像素在理解上接近语义编码器但生成质量偏低,VAE 则在理解任务上明显弱于语义编码器。该图直接推翻 “理解与生成必须用双视觉表征” 的传统结论,证明单一高维语义表征即可同时支撑两类任务,为全文统一视觉表征设计提供核心实验依据。
实验

本表格主要对比了无共享专家、全局共享专家、模态专属共享专家三种 MoE 路由配置在统一多模态模型上的表现,以 DCLM 困惑度、Notes 困惑度、扩散损失、GenEval 生成分数为评测指标,结果显示全局共享专家相比无共享专家在各项指标上有小幅提升,而采用文本与视觉各自独立的模态专属共享专家策略能够取得最优效果,在降低文本困惑度与扩散损失的同时提升图像生成质量,充分说明为不同模态单独设置固定激活的共享专家可以更好地适配文本与视觉差异化的计算需求,进一步验证了模态专属容量分配对多模态联合训练的有效性,也为后续 MoE 架构的优化设计提供了直接的实验支撑。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献159条内容
已为社区贡献159条内容

所有评论(0)