深入浅出:AI数据决策
大家看到文章的名字,可能第一时间会有疑惑,AI数据决策?我们现在用的kimi、gpt、星火、天工等模型,不是都可以做吗?
其实这也是有区分的,刚刚上面说的那么模型,都是生成式AI,有可能出现错误、误导性信息,或者不符合理论的内容。
一般做AI数据决策的,都是用分析式AI,它的好处是针对特定的数据去做模式挖掘,数据挖掘,给你数据,寻找规律,不会给你生成数据。
分析式AI与生成式AI的区别是什么?
![[Pasted image 20260422145024.png]]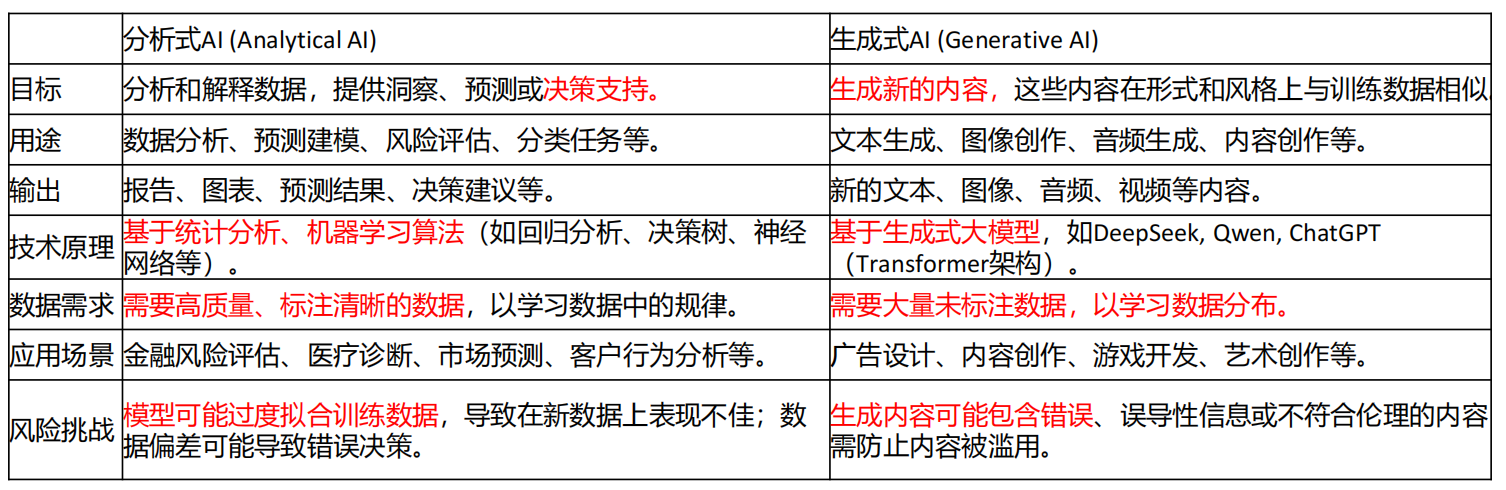
既然要做AI数据决策,那么我们就必须对分析式AI模型要有了解,才能知道,哪些数据要用哪些模型,并且能达到最好的效果。以下,我就简单介绍下十大经典模型,我相信大家也不是专门做模型开发的,包括我也一样,所以我们只需要知道简单的原理,包括怎么使用工具包即可。
经典模型算法
十大经典模型:
-
分类算法: C4.5,朴素贝叶斯(Naive Bayes),SVM,KNN,Adaboost,CART
举例:电商系统,用户买/不买商品,, -
聚类算法: K-Means,EM
举例:买的东西太多了,我分不过来,我来给他们进行分类/归类 -
关联分析: Apriori
举例:啤酒与尿片的故事,中年男子一般买啤酒的时候也会去买尿片,因为家里有孩子。 -
连接分析: PageRank
举例:网页权重的管理,google搜索,类似论文的参考文献,哪篇文字被引用多了,他的权重就大
机器学习算法工具包:

贝叶斯
贝叶斯原理:
- 贝叶斯为了解决一个叫“逆向概率”问题写了一篇文章,尝试解答在没有太多可靠证据的情况下,怎样做出更符合数学逻辑的推测
- “逆向概率”是相对“正向概率”而言
- 正向概率,比较容易理解,比如我们已经知道袋子里面有N个球,不是黑球就是白球,其中M个是黑球,那么把手伸进去摸一个球,就能知道摸出黑球的概率是多少 => 这种情况往往是上帝视角,即了解了事情的全貌再做判断
- 逆向概率,贝叶斯则从实际场景出发,提了一个问题:如果我们事先不知道袋子里面黑球和白球的比例,而是通过我们摸出来的球的颜色,能判断出袋子里面黑白球的比例么?
- 影响了接下来近200年的统计学理论
- 建立在主观判断的基础上:在我们不了解所有客观事实的情况下,同样可以先估计一个值
- 先验概率,通过经验来判断事情发生的概率
- 后验概率,就是发生结果之后,推测原因的概率
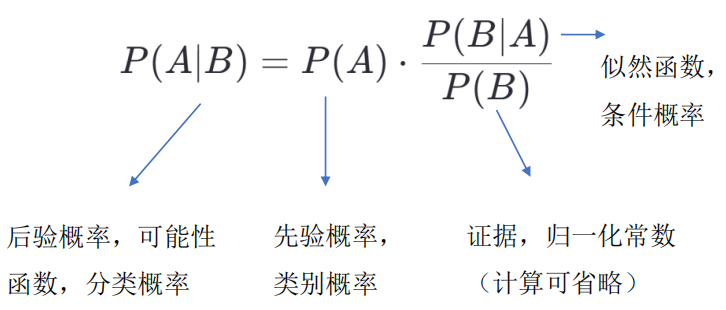
- 条件概率,P(A|B) 表示在事件 B 已经发生的前提下,事件 A发生的概率
- 似然函数,把概率模型的训练过程理解为求参数估计的过程。
比如,一个硬币在10次抛落中正面均朝上
=> 那么这个硬币是均匀的可能性是多少?
这里硬币均匀就是个参数,似然函数就是用来衡量这个模型的参数经过推导,贝叶斯推理告诉我们后验概率是与先验概率和似然函数成正比得,即
以一个小案例来讲解贝叶斯原理:
假设有一种病叫做“贝叶死”,它的发病率是万分之一,即10000 人中会有1个人得病。
现有一种测试可以检验一个人是否得病的准确率是99.9%,误报率(假阳)是0.1%
那么,如果一个人被查出来患有“叶贝死”,实际上患有的可能性有多大?
(查出患有“贝叶死”的准确率是99.9%,是不是实际上患“贝叶死”的概率也是99.9%?)
在10000个人中,还存在0.1%的误查的情况,也就是10个人没有患病但是被诊断成阳性。当然10000个人中,也确实存在一个患有贝叶死的人,他有99.9%的概率被检查出来。
可以粗算下,患病的这个人实际上是这11个人里面的一员,即实际患病比例是1/11≈9%
贝叶斯原理就是求解后验概率,
假设:A 表示事件 “测出为阳性”, B1 表示“患有贝叶死”,B2 表示“没有患贝叶死”。
患有贝叶死的情况下,测出为阳性的概率为P(A|B1)=99.9%,没有患贝叶死,但测出为阳性的概率为P(A|B2)=0.1%,患有贝叶死的概率为 P(B1)=0.01%,没有患贝叶死的概率P(B2)=99.99%。
那么我们检测出来为阳性,而且是贝叶死的概率
P(B1,A)=P(B1)*P(A|B1)=0.01%*99.9%=0.00999% ≈0.01%
P(B1,A)代表的是联合概率:
同样我们可以求得:
P(B2,A)=P(B2)*P(A|B2)=99.99%*0.1%=0.09999% ≈0.1%。
由此可以得出:
检查为阳性的情况下,患有贝叶死的概率,即P(B1|A)
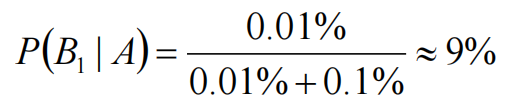
检查出是阳性的条件下,但没有患有贝叶死的概率为

0.01%+0.1%均出现在了P(B1|A)和P(B2|A)的计算中作为分母,称之为论据因子,也相当于一个权值因子。
我们可以总结出贝叶斯公式:
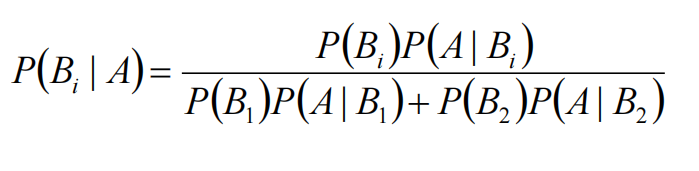
从而我们可以得到通用的贝叶斯公式:
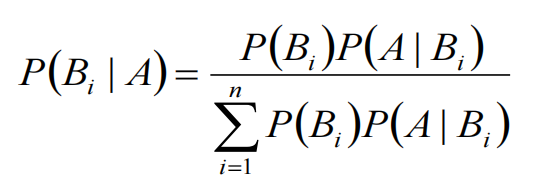
朴素贝叶斯
朴素贝叶斯:
- 一种简单但极为强大的预测建模算法
- 假设每个输入变量是独立的。这是一个强硬的假设,实际情况并不一定,但是这项技术对于绝大部分的复杂问题仍然非常有效
朴素贝叶斯模型由两种类型的概率组成:
- 每个类别的概率P(Cj)
- 每个属性的条件概率P(Ai|Cj)
什么是类别概率:
假设我有7个棋子,其中3个是白色的,4个是黑色的,那么棋子是白色的概率就是3/7,黑色的概率就是4/7 => 这个是类别概率
什么是条件概率:
假设我把这7个棋子放到了两个盒子里,其中盒子A里面有2个白棋,2个黑棋;盒子B里面有1个白棋,2个黑棋;那么在盒子A中抓到白棋的概率就是1/2,抓到黑棋的概率也是1/2,这个就是条件概率,也就是在某个条件(比如在盒子A中)下的概率。
训练朴素贝叶斯模型的过程:
在朴素贝叶斯中,我们要统计的是属性的条件概率,也就是假设取出来的是白色的棋子,那么它属于盒子A的概率是2/3
Step1: 先给出训练数据,以及这些数据对应的分类
Step2: 计算类别概率和条件概率
Step3: 使用概率模型(基于贝叶斯原理)对新数据进行预测
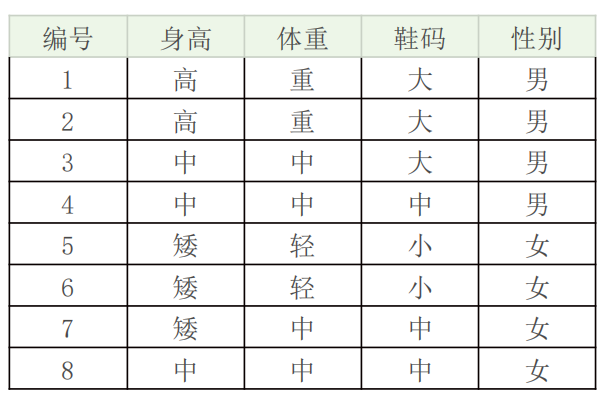
朴素贝叶斯分类(离散值):
如何根据身高,体重,鞋码,判断是否为男女,比如一个新的数据:身高“高”、体重“中”,鞋码“中” => 男 or 女?
求在A1(身高“高”)、A2(体重“中”)、A3(鞋码“中”)属性下,Cj(男 or 女)的概率?
计算公式:
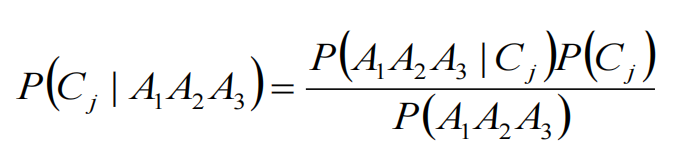
因为一共有2个类别,所以我们只需要求得 P(C1|A1A2A3) 和 P(C2|A1A2A3) 的概率即可,然后比较下哪个分类的可能性大,就是哪个分类结果分别求下这些条件下的概率:
P(A1|C1)=1/2, P(A2|C1)=1/2, P(A3|C1)=1/4
P(A1|C2)=0, P(A2|C2)=1/2, P(A3|C2)=1/2
所以P(A1A2A3|C1)=1/16, P(A1A2A3|C2)=0
因为P(A1A2A3|C1)P(C1)>P(A1A2A3|C2)P(C2),所以应该是C1类别,即男性。
朴素贝叶斯分类(连续值):
- 身高180、体重120,鞋码41,请问该人是男是女呢
- 可以假设男性和女性的身高、体重、鞋码都是正态分布,通过样本计算出均值和方差,也就是得到正态分布的密度函数。有了密度函数,就可以把值代入,算出某一点的值。
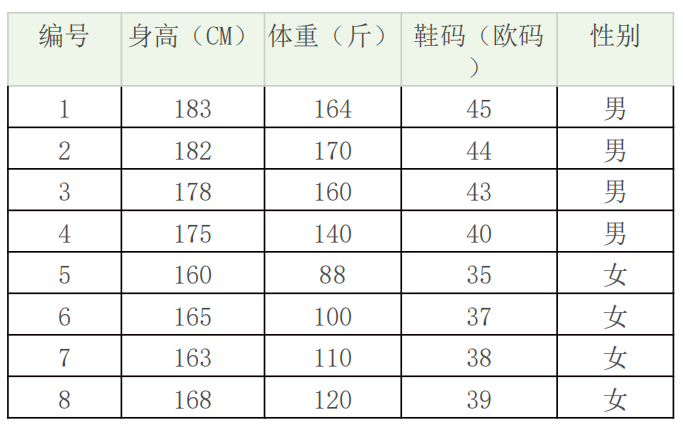
比如,男性的身高是均值179.5、标准差为3.697的正态分布。所以男性的身高为180的概率为0.1069。
同理可以计算得出男性体重为120的概率为0.000382324,男性鞋码为41号的概率为0.120304111。
P(A1A2A3|C1)=P(A1|C1)P(A2|C1)P(A3|C1)=0.1069 * 0.000382324 * 0.120304111=4.9169e-6
P(A1A2A3|C2)=P(A1|C2)P(A2|C2)P(A3|C2)=0.00000147489 * 0.015354144 * 0.120306074=2.7244e-9
很明显这组数据分类为男的概率大于分类为女的概率
Excel中的NORMDIST函数:
NORMDIST(x,mean,standard_dev,cumulative)
x:正态分布中,需要计算的数值;
Mean:正态分布的平均值;
Standard_dev:正态分布的标准差;
cumulative:取值为逻辑值,即False或True,决定了函数的形式
当为True时,函数结果为累积分布
当为False时,函数结果为概率密度
NORMDIST(180,179.5,3.697,0)=0.1069
Python中的概率密度:
stats.norm.pdf(x, mu, sigma)
返回参数为 μ 和 σ 的正态分布密度函数在x处的值
from scipy import stats
mu = 179.5
sigma = 3.697
x = 180
prob = stats.norm.pdf(x, mu, sigma)
print(prob)
朴素贝叶斯分类:
- 常用于文本分类,文本过滤、情感预测、推荐系统等,尤其是对于英文等语言来说,分类效果很好
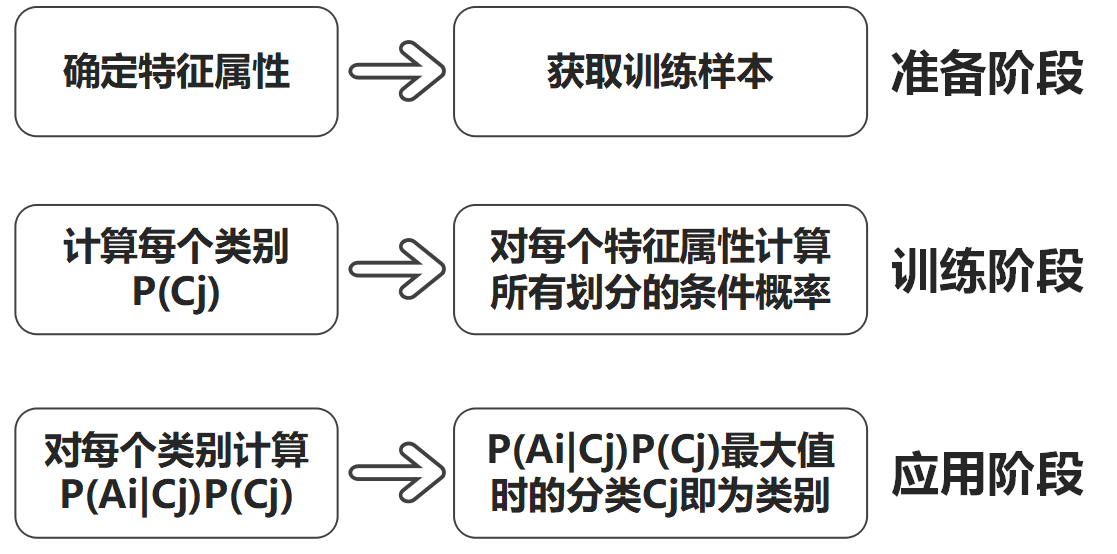
- 准备阶段,需要确定特征属性,属性值以及label => 训练集
- 训练阶段,输入是特征属性和训练样本,输出是分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率
- 应用阶段,使用分类器对新数据进行分类
sklearn工具使用:
- from sklearn.naive_bayes import GaussianNB
高斯朴素贝叶斯: 特征变量是连续变量,符合高斯分布,比如说人的身高,物体的长度
GaussianNB(priors=None) # 模型创建
priors,先验概率大小,如果没有给定,模型则根据样本数据自己计算(利用极大似然法)
查看模型对象的属性:
class_prior_:每个样本的概率
class_count_:每个类别的样本数量
theta_:每个类别中每个特征的均值
sigma_:每个类别中每个特征的方差
- from sklearn.naive_bayes import MultinomialNB
多项式朴素贝叶斯:特征变量是离散变量,符合多项分布,在文档分类中特征变量体现在一个单词出现的次数,或者是单词的TF-IDF值等
MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None)
alpha:先验平滑因子,默认等于1,当等于1时表示拉普拉斯平滑
fit_prior:是否去学习类的先验概率,默认是True
class_prior:各个类别的先验概率,如果没有指定,则模型会根据数据自动学习, 每个类别的先验概率相同,即类别数N分之一
模型对象的属性:
class_count_: 训练样本中各类别对应的样本数
feature_count_: 每个类别中各个特征出现的次数
- from sklearn.naive_bayes import BernoulliNB
伯努利朴素贝叶斯: 特征变量是布尔变量,符合0/1分布,在文档分类中特征是单词是否出现
BernoulliNB(alpha=1.0, fit_prior=True, class_prior=None)
alpha:平滑因子,与多项式中的alpha一致
fit_prior:是否去学习类的先验概率,默认是True
class_prior:各个类别的先验概率,如果没有指定,则模型会根据数据自动学习, 每个类别的先验概率相同,即类别数N分之一
模型对象的属性:
class_count_: 训练样本中各类别对应的样本数
feature_count_: 每个类别中各个特征出现的次数
- To Do 使用朴素贝叶斯进行mnist手写数字分类

决策树与随机森林
决策树:
- 决策树基本上就是把我们以前的经验总结出来
- 常见的决策树算法有C4.5、ID3和CART
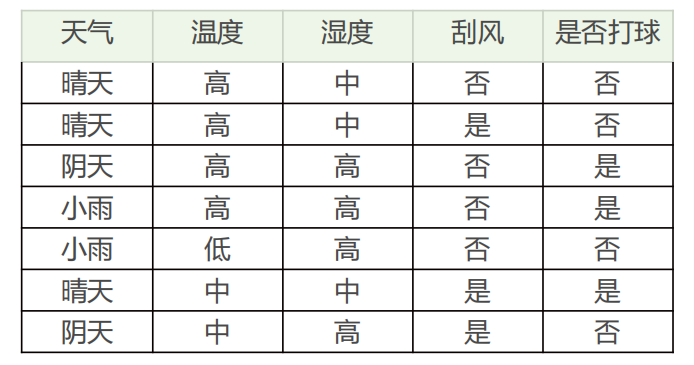
Thinking:如何构造一个判断是否去打篮球的决策树,将哪个属性(天气、温度、湿度、刮风)作为根节点是个关键问题
信息、熵以及信息增益:
- 引用香农的话来说,信息是用来消除随机不确定性的东西
- 对于机器学习中的决策树而言,如果带分类的事物集合可以划分为多个类别当中,则某个类(xi)的信息可以定义为
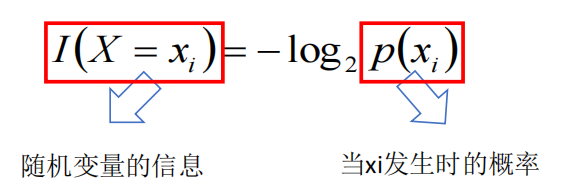
- 熵是约翰.冯.诺依曼建议使用的命名,熵=信息的期望值
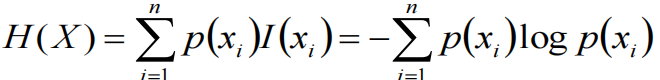
熵用来度量不确定性的,当熵越大,X=xi的不确定性越大
对于机器学习中的分类问题,熵越大 => 这个类别的不确定性大
- 信息增益在决策树算法中是用来选择特征的指标,信息增益越大,则这个特征的选择性越好
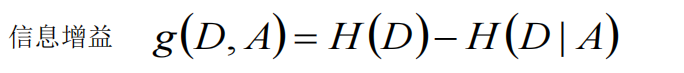
原有树的熵 H(D) 增加了一个分裂节点,使得熵变成了H(D|A)
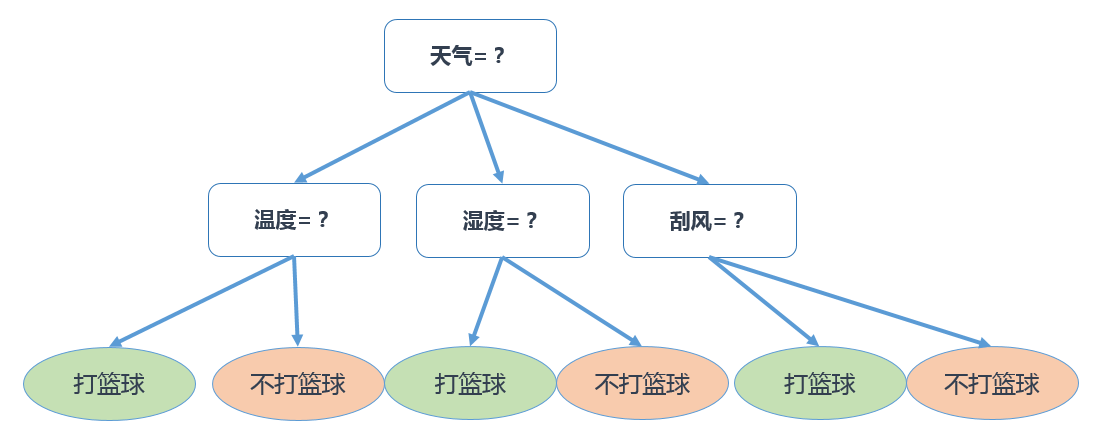
决策树工具:
from sklearn.tree import DecisionTreeClassifier
DecisionTreeClassifier(criterion=‘entropy’)
criterion,gini或者entropy,默认是基尼系数,后者是信息熵
max_depth,决策树最大深度,默认为None
min_samples_split,内部节点再划分所需最小样本数
max_leaf_nodes,最大叶子节点数
class_weight,类别权重
随机森林的生成:
- 森林中的每棵树都是独立的
- bagging思想,将若干个弱分类器的分类结果进行投票选择,从而组成一个强分类器
- bagging不用单棵决策树来做预测,增加了预测准确率,即不容易过拟合,减少了预测方差
- 如果训练集大小为N,对于每棵树而言,随机且有放回地,从训练集中的抽取N个训练样本(采样方式称为bootstrap sample),作为该树的训练集,每棵树的训练集都是不同的,而且里面包含重复的训练样本
- 如果每个样本的特征维度为M,指定一个常数m<<M,随机地从M个特征中选取m个特征子集,每次树进行分裂时从这m个特征中选择最优的
特征选择个数m(随机森林的参数):- m越大,树的相关性和分类能力会相应提升
- 如何选择最优的m是关键问题
- 每棵树都尽最大程度的生长,没有剪枝过程
- 每棵树都尽最大程度的生长,没有剪枝过程

随机森林分类效果(错误率):
- 森林中任意两棵树的相关性:相关性越大,错误率越大
- 森林中每棵树的分类能力:每棵树的分类能力越强,整个森林的错误率越低
随机森林 = 集成学习
工具:xgboost,lightgbm
过拟合的处理方式:
- 训练种增加早停法
- 对模型的系数进行惩罚,正则化项
- 去掉一些不重要的特征
随机森林工具:
from sklearn.ensemble import RandomForestClassifier
RandomForestClassifier(n_estimators=10, criterion=‘gini’)
n_estimators,森林中决策树的个数,默认为10
max_features,寻找最佳分割时需要考虑的特征数目,默认为auto,即max_features=sqrt(n_features)
criterion,gini或者entropy,默认是基尼系数,后者是信息熵
max_depth,决策树最大深度,默认为None
min_samples_split,内部节点再划分所需最小样本数
max_leaf_nodes,最大叶子节点数
class_weight,类别权重
SVM
SVM思想: 一些线性不可分的问题可能是非线性可分的,也就是在高维空间中存在分离超平面(separating hyperplane),使用非线性函数从原始的特征空间映射至更高维的空间,转化为线性可分问题
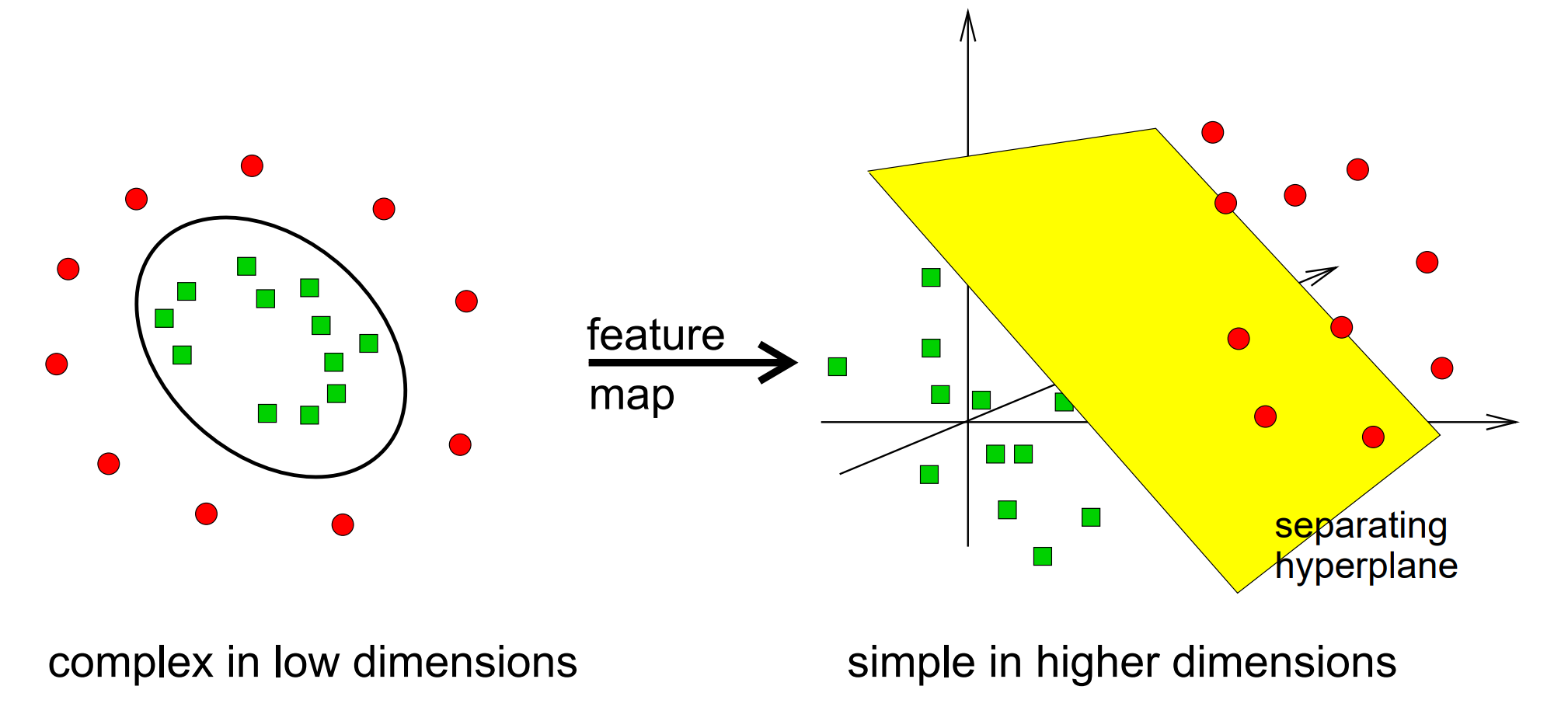
SVM工具:
- sklearn中支持向量分类主要有三种方法:SVC、NuSVC、LinearSVC
- sklearn.svm.SVC(C=1.0, kernel=‘rbf’, degree=3, gamma=‘auto’, coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=‘ovr’, random_state=None)
- sklearn.svm.NuSVC(nu=0.5, kernel=‘rbf’, degree=3, gamma=‘auto’, coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=‘ovr’, random_state=None)
- sklearn.svm.LinearSVC(penalty=‘l2’, loss=‘squared_hinge’, dual=True, tol=0.0001, C=1.0, multi_class=‘ovr’, fit_intercept=True, intercept_scaling=1, class_weight=None, verbose=0, random_state=None, max_iter=1000)
- SVC,Support Vector Classification,支持向量机用于分类
- SVR,Support Vector Regression,支持向量机用于回归
- 基于libsvm工具包实现,台湾大学林智仁教授在2001年开发的一个简单易用的SVM工具包
- SVC,C-Support Vector Classification,支持向量分类
- NuSVC,Nu-Support Vector Classification,核支持向量分类,和SVC类似,不同的是可以使用参数来控制支持向量的个数
- LinearSVC,Linear Support Vector Classification
常用参数:
- C,惩罚系数,类似于LR中的正则化系数,C越大惩罚越大
- nu,代表训练集训练的错误率的上限(用于NuSVC)
- kernel,核函数类型,RBF, Linear, Poly, Sigmoid,precomputed,默认为RBF径向基核(高斯核函数)
- gamma,核函数系数,默认为auto
- degree,当指定kernel为’poly’时,表示选择的多项式的最高次数,默认为三次多项式
- probability,是否使用概率估计
- shrinking,是否进行启发式,SVM只用少量训练样本进行计算
- penalty,正则化参数,L1和L2两种参数可选,仅LinearSVC有
- loss,损失函数,有‘hinge’和‘squared_hinge’两种可选,前者又称L1损失,后者称为L2损失
- tol: 残差收敛条件,默认是0.0001,与LR中的一致
线性支持向量分类,使用的核函数是linear libsvm中自带了四种核函数:线性核、多项式核、RBF以及sigmoid核、Kernel 核的选择技巧:
- 如果样本数量 < 特征数:
方法1:简单的使用线性核就可以,不用选择非线性核
方法2:可以先对数据进行降维,然后使用非线性核 - 如果样本数量 >= 特征数
可以使用非线性核,将样本映射到更高维度,可以得到比较好的结果
逻辑回归
逻辑回归:
- 假设数据服从伯努利分布
- 通过极大化似然函数的方法
- 运用梯度下降来求解参数
- 将数据进行二分类
逻辑回归的假设:
- 任何的模型都有自己的假设,在假设条件下才是适用的
- 假设1:数据服从伯努利分布
典型例子: 连续的掷n次硬币(每次实验结果不受其他实验结果的影响,即n次实验是相互独立的)
贝努力分布为离散型概率分布,如果成功,随机变量取值为1;如果失败,随机变量取值为0。成功概率记为p,失败概率为 q=1-p
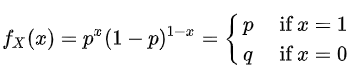
对应二分类问题,样本为正类的概率p,和样本为负类的概率q=1-p
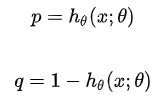
- 假设2:正类的概率由sigmoid函数计算,即
决策边界是线性 or 非线性?
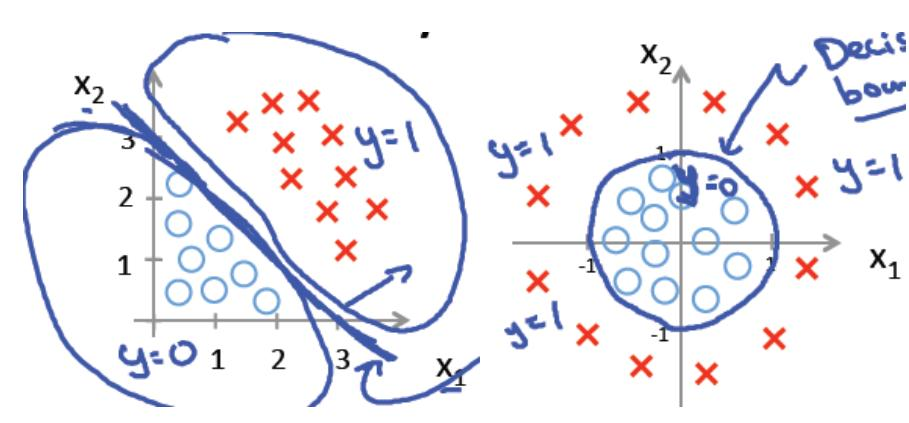
对于线性的决策边界: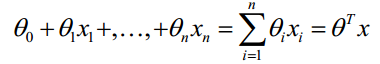
构造预测函数: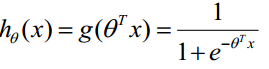
h0(x)表示结果为1的概率,对于输入x,分类结果为1和0的概率为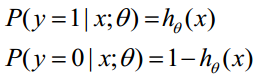
构造损失函数: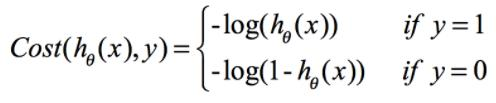

Cost函数与J函数是基于最大似然估计推导得到的
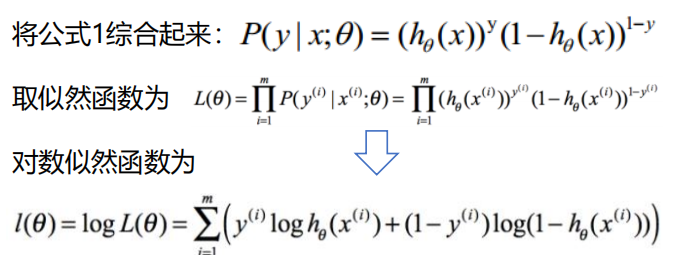
最大似然估计就是求使 取最大值时的θ,这里可以使用梯度上升法求解,也即对 使用梯度下降法求最小值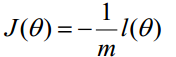
似然函数:
- 关于统计模型中的参数的函数,表示模型参数中的似然性
- 给定输出x时,关于参数θ的似然函数L(θ|x)等于给定参数θ后变量X的概率
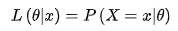
逻辑回归:
如何进行分类:设定一个阈值,判断正类概率是否大于该阈值,一般阈值是0.5,所以只用判断正类概率是否大于0.5即可
为什么会在训练中将高度相关的特征去掉?
1)可解释性更好
2)提高训练的速度,特征多了,会增大训练的时间
优点:
- 形式简单,模型的可解释性非常好
- 根据特征的权重可以得到不同的特征对最后结果的影响(某个特征的权重值高 => 这个特征对结果的影响大)
- 工程上的baseline,如果特征工程做的好,效果不会差
- 训练速度较快,计算量只和特征的数目相关
- 模型资源占用小,只需要存储各个维度的特征值
- 方便输出结果调整。逻辑回归可以很方便的得到最后的分类结果,因为输出的是每个样本的概率分数,我们可以很容易的对这些概率分数进行cut off,也就是划分阈值(大于某个阈值的是一类,小于某个阈值的是一类)
缺点:
- 准确率不是很高,形式简单,很难拟合数据的真实分布
- 很难处理样本不均衡问题
- 很难处理非线性数据,在不引入其他方法的情况下,只能处理线性可分的数据
- 逻辑回归本身无法筛选特征,可以采用gbdt来筛选特征,然后再用逻辑回归
分类与回归的区别
分类与回归是监督学习中的两大核心任务,二者既有联系又有区别:
- 输出类型
分类:预测离散类别标签(如“男/女”、“是/否”)。
回归:预测连续数值(如房价、资产金额)。 - 目标函数
分类常用交叉熵损失(Cross-Entropy),回归常用均方误差(MSE)。
分类与回归的内在联系是什么?
-
概率视角
分类的输出可视为类别的概率(如逻辑回归),而回归可通过阈值处理转化为分类(如预测概>0.5为一类)。 -
模型共享
某些模型(如朴素贝叶斯、决策树、SVM、逻辑回归、神经网络)通过调整输出层即可切换任务:- 分类:Softmax输出离散概率。
- 回归:线性输出连续值。
-
问题转化
回归问题可离散化为分类(如年龄预测→年龄段分类)。
某些分类任务(如有序分类)可视为回归的离散特例。
有序分类的类别具有明确的顺序关系(如“差/中/好”、“1~5星评分”),类别标签不仅是符号,还隐含了连续的潜在变量。
分类与回归的本质共性是什么?
均为从输入数据中学习映射关系 f(X)→Y,核心目标是最小化预测与真实值的差异。
分类与回归也在神经网络、机器学习内广泛使用,大家想了解的,可以去看下我之前写的文章 # 初识神经网络与机器学习 。
分类与回归是监督学习的一体两面,区别在于输出空间的性质,但二者共享模型框架和优化思想。实际应用中常相互转化或结合(如回归后分类)。
总结
-
机器学习包括监督学习,无监督学习,半监督学习,强化学习
-
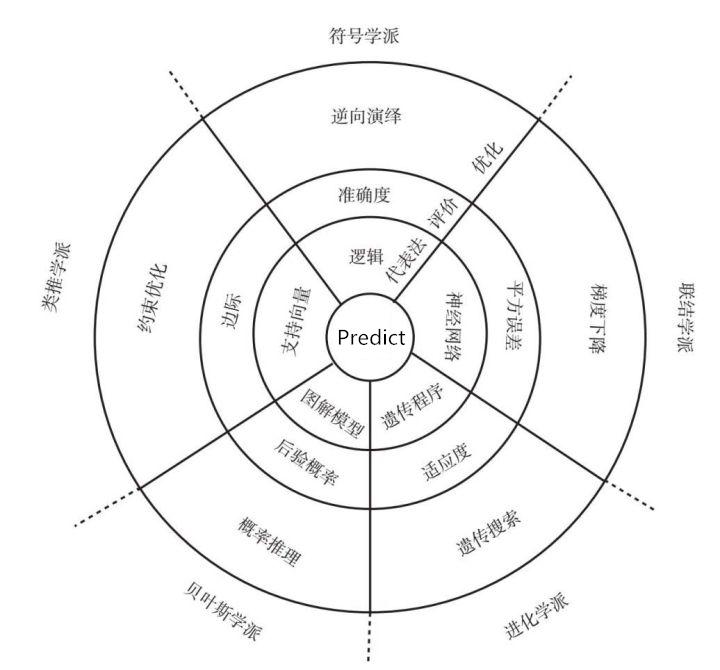
符号(因果)学派,认为事情都是有因果的,机器可以自己摸索出规律,典型代表为决策树
-
贝叶斯(概率)学派,因果之间不是必然发生,是有一定概率的,即P(A|B),典型代表为朴素贝叶斯
-
类推学派,通过类比可以让我们学习到很多未知的知识,所以我们需要先定义“相似度”,通过相似度进行发现
-
联结学派,模仿人脑神经元的工作原理,所有模式识别和记忆建立在神经元的不同连接方式上,典型代表为神经网络,深度学习
-
进化学派,上帝通过基因选择来适者生存,典型代表为遗传算法
案例:二手车价格预测
需求:预测二手车的交易价格。
数据来自某交易平台的二手车交易记录,
used_car_train.csv:15万条作为训练集,
used_car_test.csv:5万条作为测试集。
| Field | Description |
|---|---|
| SaleID | 交易ID,唯一编码 |
| name | 汽车交易名称,已脱敏 |
| regDate | 汽车注册日期,例如20160101,2016年01月01日 |
| model | 车型编码,已脱敏 |
| brand | 汽车品牌,已脱敏 |
| bodyType | 车身类型:豪华轿车:0,微型车:1,厢型车:2,大巴车:3,敞篷车:4,双门汽车:5,商务车:6,搅拌车:7 |
| fuelType | 燃油类型:汽油:0,柴油:1,液化石油气:2,天然气:3,混合动力:4,其他:5,电动:6 |
| gearbox | 变速箱:手动:0,自动:1 |
| power | 发动机功率:范围 [ 0, 600 ] |
| kilometer | 汽车已行驶公里,单位万km |
| notRepairedDamage | 汽车有尚未修复的损坏:是:0,否:1 |
| regionCode | 地区编码,已脱敏 |
| seller | 销售方:个体:0,非个体:1 |
| offerType | 报价类型:提供:0,请求:1 |
| creatDate | 汽车上线时间,即开始售卖时间 |
| price | 二手车交易价格(预测目标) |
| v系列特征 | 匿名特征,包含v0-14在内15个匿名特征 |
step1: 编写python代码,打开used_car_train_20200313.csv,打印前5行数据,显示全部列
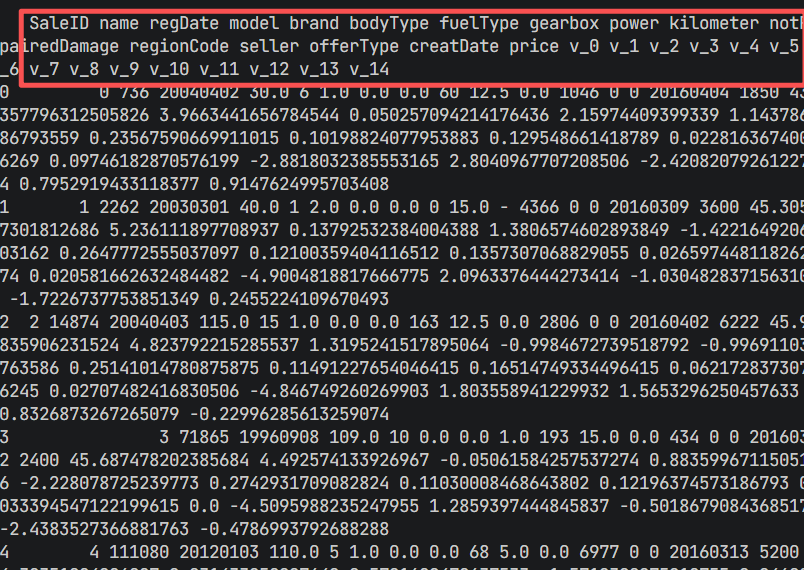
step2: 帮我整理数据表的字段含义,写入到.md
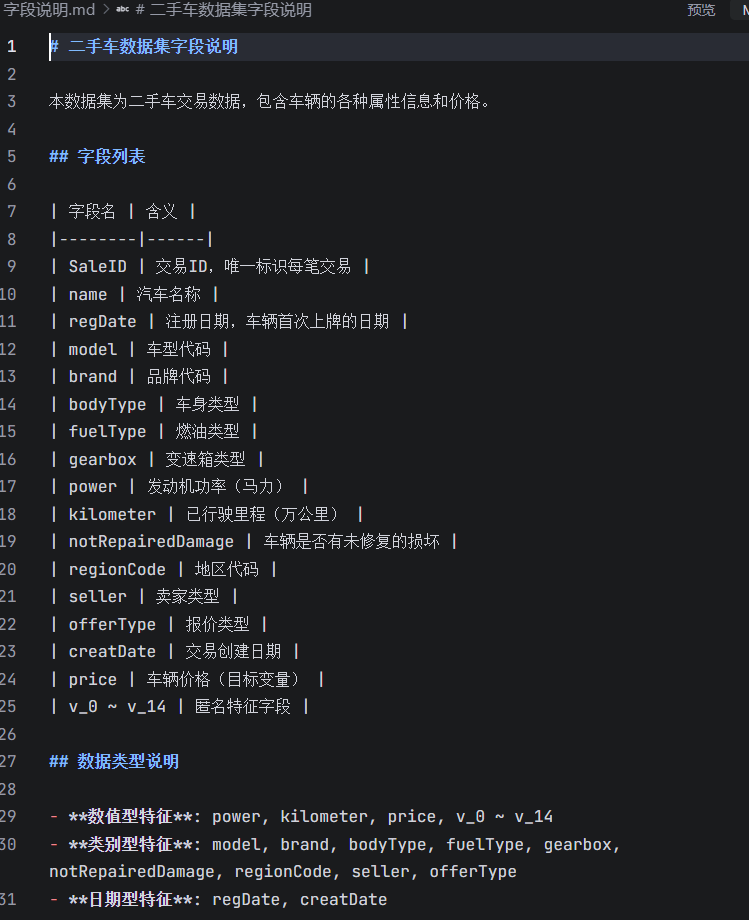
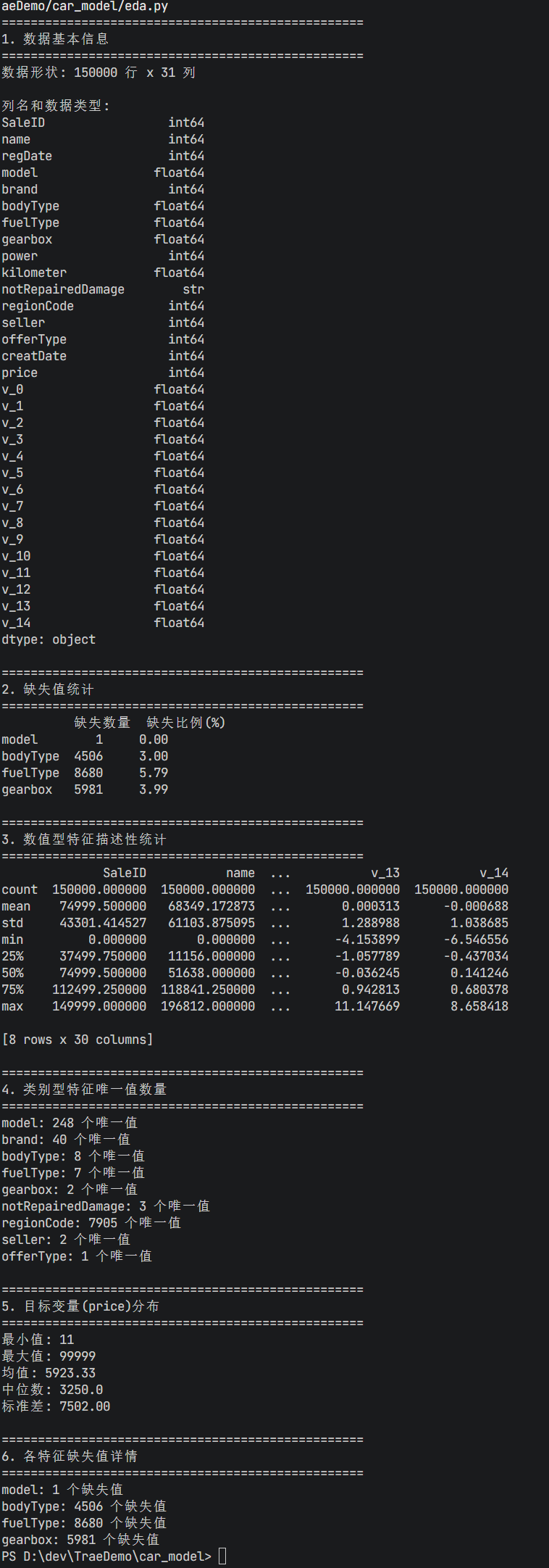
step3: 帮我做EDA
EDA (Explore Data Analysis) :探索性数据分析,AI会自主的选择特征进行分析
为什么要做EDA?
你要了解这个数据长什么样?数据有没有缺失,有没有异常值?
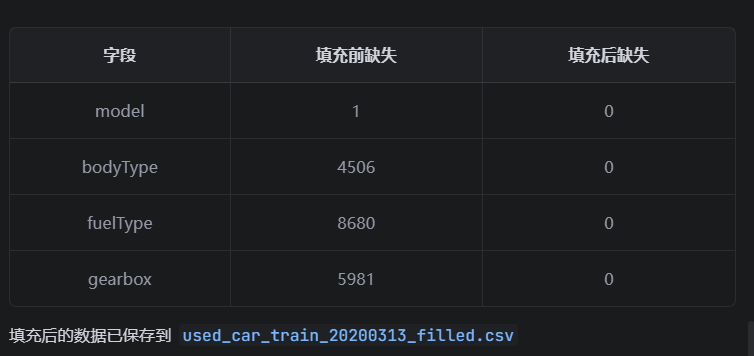
只有了解数据情况,才能进行相关处理,比如数据有缺失,就给它补全。
step4: 有缺失值的,帮我进行补全
step5: 我需要对price进行建模,使用XGBoost
这里需要注意:
对于日期变量regDate和creatDate进行处理,目前regDate和creatDate的格式类似 20000501。
编写新的python,使用训练集used_car_train_20200313_filled.csv进行训练,对测试集used_car_testB_20200421.csv进行预测,然后将预测结果保存到.csv,表头是SaleID,price,请参考used_car_sample_submit.csv的样式
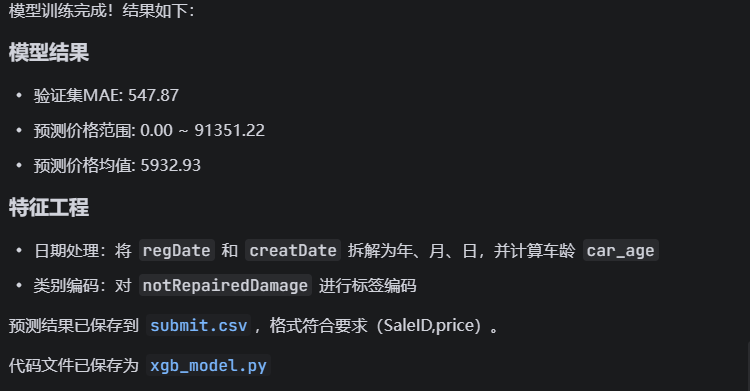
step6: MAE分数再优化,
我想对特征工程进行优化,包括:
1)车龄:creatDate - regDate
2)构造brand和price之间的统计特征
比如 brand_price_mean,brand_price_median,brand_price_std
3)kilometer / (creatDate - regDate)
类似这些特征,帮我写入到xgb_model2.py,然后用xgboost进行训练,使用训练集used_car_train_20200313_filled.csv进行训练,对测试集used_car_testB_20200421.csv进行预测,,然后将预测结果保存到.csv,表头是SaleID,price,请参考used_car_sample_submit.csv的样式
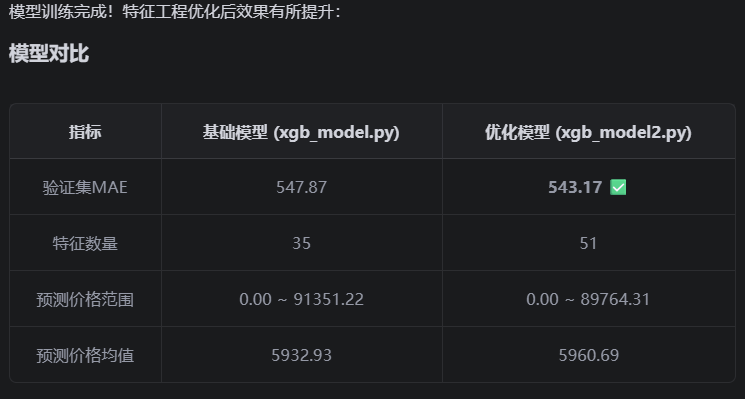
step7: 更换catboost模型,进行MAE分数优化,
catboost模型:针对分类特征,内置了一些优化方法
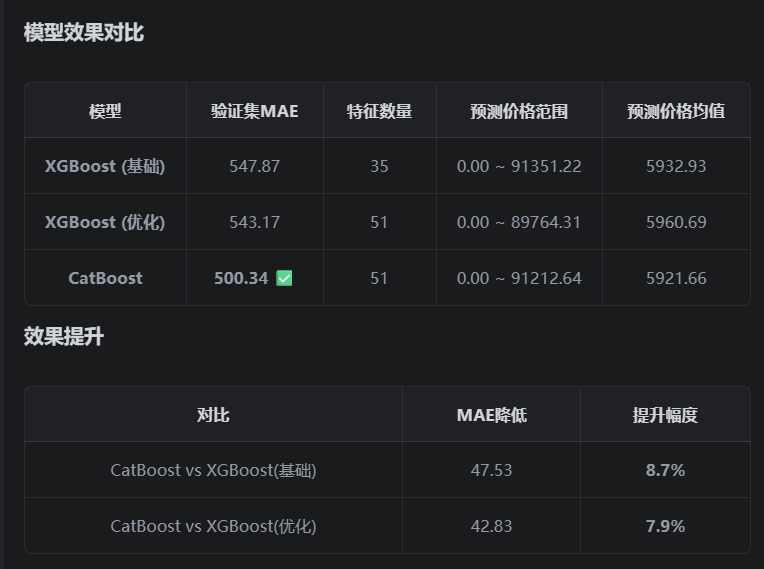
使用 catboost 进行训练,迭代次数可以是5000次,训练率可以是动态调整的,略低一些,写入到新的.py,其他的一致,使用训练集used_car_train_20200313_filled.csv进行训练,对测试集used_car_testB_20200421.csv进行预测,然后将预测结果保存到.csv,表头是SaleID,price,请参考used_car_sample_submit.csv的样式

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)