多模态大模型(VLM)技术&CLIP&MOCO
CLIP
之前分类网络都只能对固定类别进行分类。image net的1000类,这带来的问题有两个,一是训练好的模型只能对固定类别进行分类,不能迁移到其他类别。第二,固定好的类别需要根据类别来标注数据,费时费力。有没有一个视觉模型不用对数据进行标注就可以训练,并且可以对任意类别进行预测,不用事先固定分类的类别?在作者提出clip模型的同时,NLP那边正在进行着翻天覆地的变化。得益于transformer架构的提出,encoder部分成就了BERT,decoder部分成就了GPT。
首先看BERT模型,它的预测任务有两个,但都是自监督的,不需要人工标注数据。第一个任务是训练带掩码的语言模型,简单来说就是把一句话里面的部分词遮住,让模型根据上下文预测被遮住的词。第二个任务是给出两句话,让模型判断两句话是否在原文中是连续的这两个代理任务一个训练了模型对词语的理解能力,一个训练了模型对整个句子的理解能力,于是得到一个非常好的自然语言理解预训练。模型BERT解决了训练数据的标注问题,但是没有解决在下游任务上依然需要微调的问题。不论是单词级别的命名实体识别,还是句子级别的情绪识别,都还是需要加一层线性分类头进行微调。
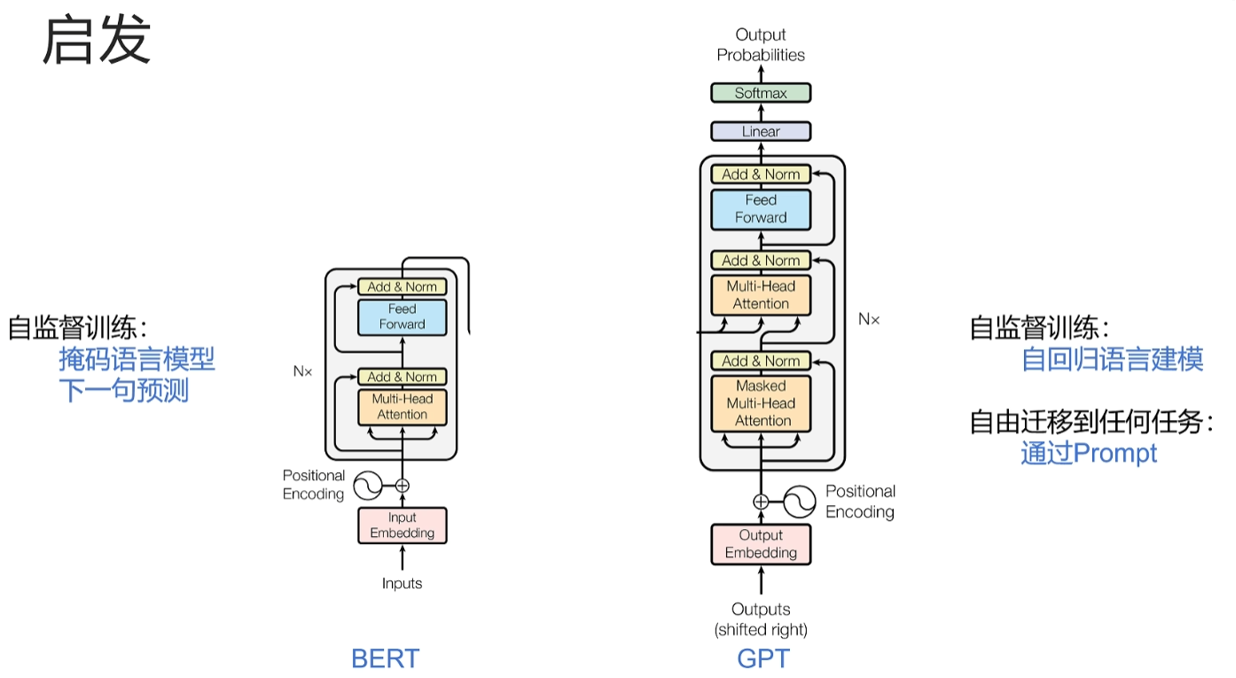
接下来看GPT模型,以GPT3为例,它的训练数据也不需要人工标注,他的任务就是文字接龙,根据前文预测下一个字。更重要的是,同时它也解决了模型迁移的问题。它通过prompt可以完成各种任务,包括翻译、情绪识别、命名、实体识别等你。只要把你的任务通过prompt告诉GPT3,它就能完成你的任务,不需要在下游任务上进行牵引学习了。GPT3是OpenAI的工作,clipOpenAI提出的,所以自然就想到是否能用自监督学习解决数据需要标注的问题,同时利用prompt来实现下游任务需要迁移学习的问题。
比如GPT3模型用的大量真实文本训练,他预测的就是真实的文本,这成就了GPT3令人惊叹的效果。OpenAI作为大公司,在训练clip时收集了4亿个文本图片,对其中光文本的量就和训练GPT2的文本相当。
刚开始OpenAI想到的是通过图片来预测文本,可是训练时发现训练太慢了,为什么呢?因为根据一个图片生成文本本来就是一个很难的任务。对于同一个图片,可以有无数种正确的答案。所以后来作者就改为右边的图片和文本的配对任务了。可以明显看到图文配对的任务相对简单,模型也更容易训练。

Clip做图片和文本配对也非常简单直接。文本通过一个text encode,图片通过一个image encode,然后分别得到文本的向量表示和图片的向量表示,再分别通过一个线性投射层投射到共同的一个多模态向量空间里。在这个向量空间里尽量拉近配对文本和图片的向量,而让不配对的文本和图片向量距离尽可能的远。这里的文本encode和图片encode你用什么模型都可以,只要能把图片和文本变成向量就行。
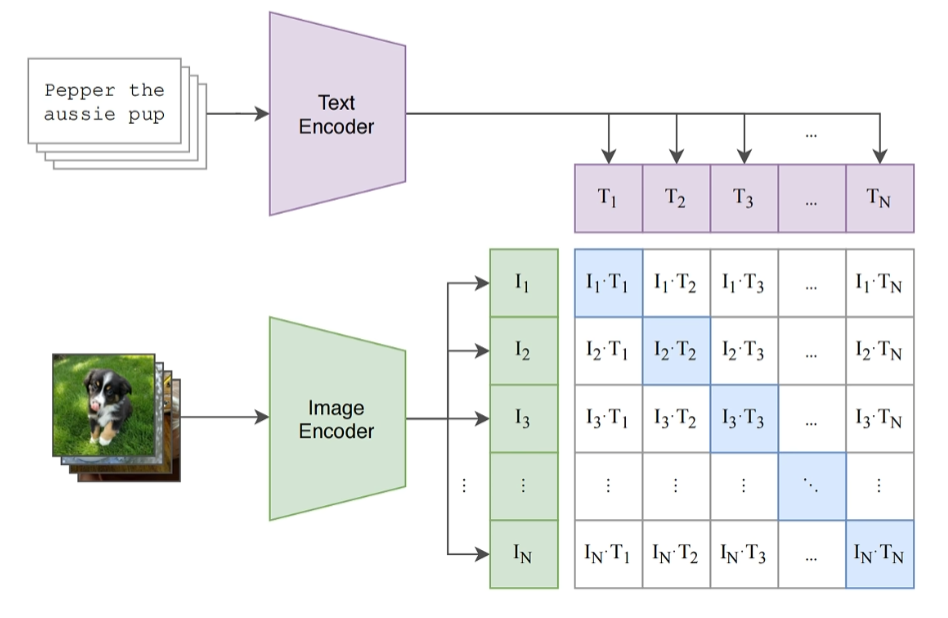
作者实验时对于图像编码器尝试了不同resnet和vit,最后作者还在VIT-L14这个模型上,在高分辨率下336乘336的图片上额外训练了一个epoch来提升性能。另外作者发现如果想通过扩大模型来提升精度,最好是在模型的深度、宽度、图像的分辨率上同时增加,这样收益最大,而不是把所有的计算量都增加在其中一项上。
对于文本编码器,作者采用了类似GPT的结构,每个token都只能看到自己前面的token,输入文本前边会加一个SOS token代表start of sentence,文本后边会增加一个EOS token表示end of sentence。然后拿最后一层EOS位置token的输出来作为整个句子的embedding。因为只有eos token可以看到整个序列的,其他token来总结整个句子的意思。需要注意的是,虽然这里模型结构类似于GPT,但是这里是作为编码器使用的,只提取最后一个US token的输出作为整个句子的编码。
文本编码器只有6300万的参数。作者发现文本编码器的大小对于clip整个模型的性能影响不大,所以没有尝试不同大小的文。编码器训练的batch size为32768,是一个非常大的batch size。而且从左边图上也可以看到,随着视觉编码器模型计算量的增大,clip模型的错误率是稳步减小的。而且因为是训练数据有4亿个图文,对数据量足够大,所以图片编码器和文本编码器都没有做预训练,直接从随机初始化开始训练图片,也没有做过多的图像增强,唯一做的就是随机裁剪。整个clip实现非常简单。
Clip模型的好处有哪些呢?第一,它利用了丰富的语义来作为监督信号,让模型可以学习图片里很多细节语义特征,做到真正的理解图片,能更好地泛化。第二,它是多模态的模型,连通了图片和文本,可以通过文本来查询图片。第三,它摆脱了图片分类必须是固定的类别,创新地提出了利用prompt来分类的方法,做到可以对任意类别进行分类。
MOCO
moco这个算法,它是一个对比学习算法。因为它的思想对很多其他后来的算法,包括多模态算法都有影响。moco是momentum contrast的缩写,也就是动量对比的意思。
对比学习是一种无监督的学习,通过正负样本对来学习他学习的样本,他学习的是样本的特征,表示学习到的这些样本特征在他们所在的特征空间里正例样本对生成的特征向量之间的距离要尽可能的近,复利样本对生成的特征向量之间的距离要尽可能的远。学到这些对样本的特征表示后,在下游任务上只需要经过简单的微调就能取得很好的效果。你可能不理解为什么对比学习是无监督的,不是还是需要人来准备正负样本对吗?这是因为正负样本对有很多方法可以简单的自动生成,不用人手工标注,所以也是无监督学习。
在对图像的对比学习里,可以通过实例判别来生成正负样本。假如我们有四张图片,首先通过图像增强,比如对图像进行拉伸旋转,生成一个新的图片。这个新生成的图片和原来的图片描述的语义并没有发生改变,所以他们是正样本,而原始图片和其他图片之间就是负样本对。
看在多模态对比学习里,假如你收集到很多图文对,那么每个图文对就是一个正样本对,而每个图片和其他图片对应的文本就构成了负样本对。对比学习和监督学习相比它的难点是什么呢?
监督学习它有固定的label模型,不断的调整自己的参数,让自己的输出越来越接近label。但是对比学习模型要为每个样本生成特征向量,要求正样本对的特征向量距离近,负样本对的特征向量距离远。对比学习对比两个样本向量都是模型生成的,而模型在训练过程中一直在调整参数,每次调整后对于原来同一个样本生成的特征也会变化,所以说对比学习没有一个固定的label可以学习,一切都是在变化中调整的。
对比学习没有固定的label带来的问题是,如果batch size太小,会造成学习困难。比如这里有一个batch里有一个正样本,对,三个负样本对,通过这个batch的训练,模型可以很好的区分正负样本。假设向量空间是这个圆,它们的向量都被分配到合适的位置上了,下一个batch的数据又来了。模型在这个batch上可以很好的把正负样本对进行区分,把每个样本生成的特征向量分布在这个向量空间上。但是此时模型看不到上一个batch的样本,它分配的向量位置可能和上一个batch分配的向量位置重合,让原本不是正样本对的两个样本距离很近。如果每次都可以拿所有的样本进行训练就好了,但是显存是有限的这是不可能的。

还有一种办法就是我们在内存中记录之前batch生成的向量。这些之前生成的向量不记录梯度计算loss时不进行后向传播,只是用来让模型更好的分配向量位置,这样这些向量就不会额外占用显存。
但这又会引入另一个问题,就是模型随着训练在一直变化,每个batch生成样本特征向量的模型是不同的,你不能拿过去模型生成的向量来调整现在的模型。所以对比学习想要效果好,就要同时满足两个条件。第一个,负例要尽可能的多,这样就能让模型把不同的样本在特征空间内尽可能的区分开来。
第二,负例要尽可能的一致,也就是最好是由同一个模型生成的。如果不是同一个模型生成的,也不要差别太大,不然训练就没有意义。Moco就是同时满足了上面两个条件,从而在视觉对比学习方面取得成功。
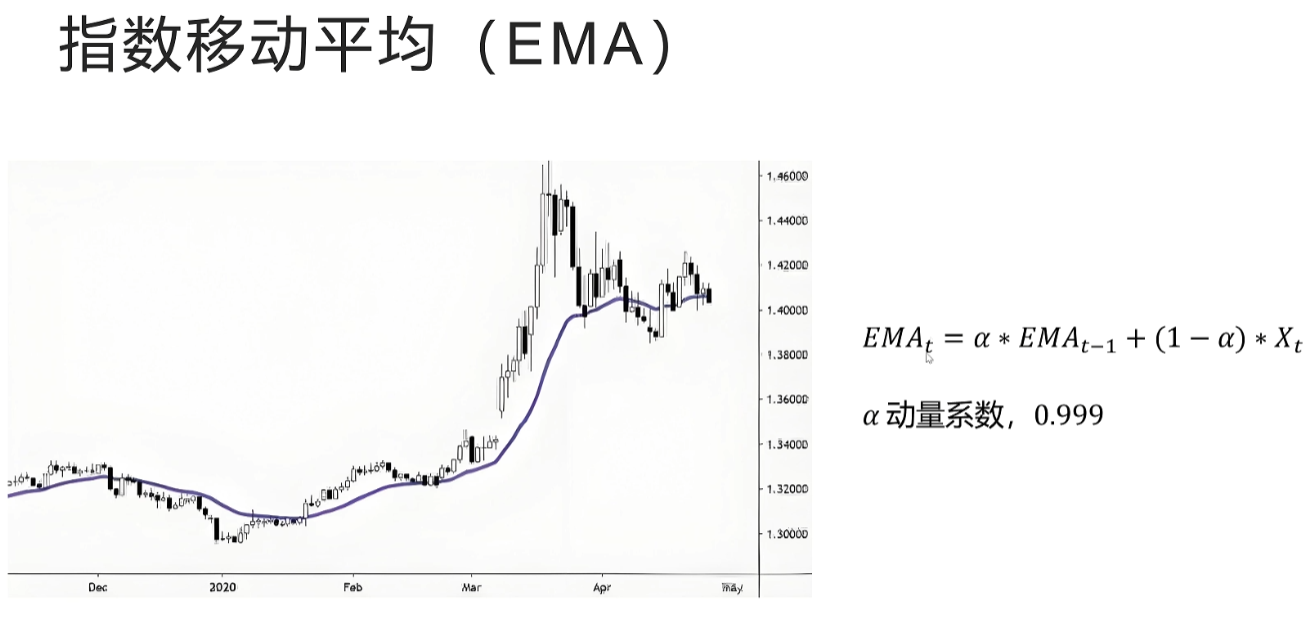
这里的动量指的是指数移动平均线EMA指数移动平均在股票分析里经常用到,股票价格每天波动很大,有没有一个可以反映股票长期趋势的指标呢?指数移动平均线就是一个很好的描述股票长期趋势的指标,它不会随着股票价格每天波动太大。可以看一下EMA的计算公式,它在T时刻指的值等于动量系数。阿尔法乘以它上一个时刻的值加上一减去阿尔法乘以它当前时刻的观察值。比如这里的观察值是当天股票的价格,阿尔法一般都是一个接近于一的值。仔细观察这个公式,你会发现它当前时刻的值大部分都是取决于上一个时刻自己的值,只有很小一部分取自当前的观察值,也就是它受自身的影响大受外界的影响小,所以很稳定。在moco里动量系数为0.999。
接下来我们看moco的做法,moco把图像对比学习看成是一个字典检索问题。每次有一个样本称为query,字典里有一个正样本,其他都是负样本,分别为K0、K1、K2等等。对比学习的任务就是根据一个query从一大堆K中找到唯一的那个正样本的k moko里会有一个队列,存着大量的负样本的key,每个batch都会给副样本队列里增加一些副样本的K之前讲过,每个batch模型训练后会发生变化,生成的副样本向量和之前batch生成的不一致,导致训练效果不好。
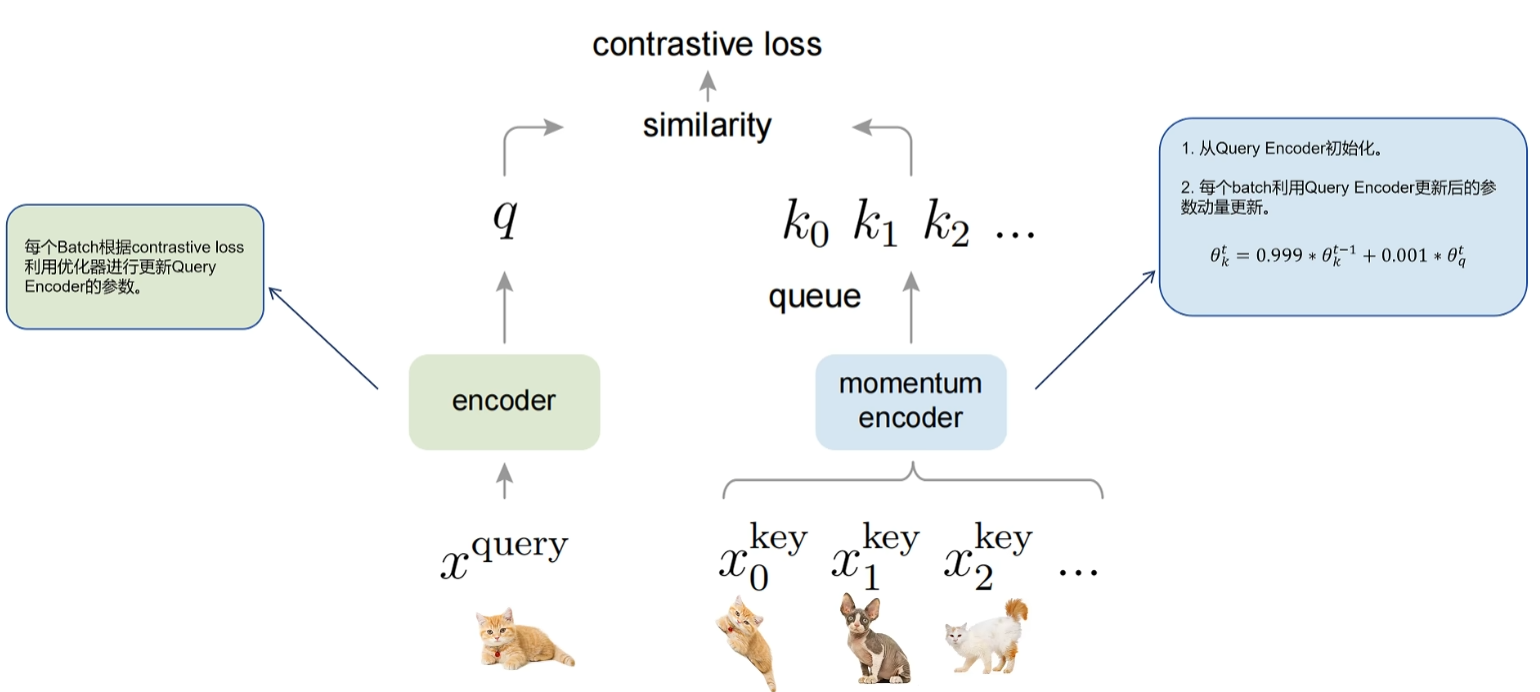
moco的做法是分成两个模型,一个是query模型,一个是K模型。Query模型是实际训练的模型,它每个batch根据对比loss利用优化器更新自己的模型参数。Key模型也叫做动量模型,但是从query模型初始化的,每个batch,它不更新自己的模型参数,而是利用query模型指数移动平均来更新自己的参数。这里的公式详细解释了更新的过程,每个batch后K模型的参数西塔KT等于0.999乘以上一个时刻自己的参数西塔KT减1,然后加上0.001乘以query模型。这个batch更新后的参数西塔QT因为猫狗队列里大量负样本的特征向量都是通过动量模型生成的。动量模型是通过指数移动平均来更新的,它跟随了Q模型参数变化的趋势,又保证了batch之间变化不至于太大。
所以队列里保存的这些副样本,他们的向量对于对比学习来说就是又多又一致,可以很好的进行对比学习。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)