基于Spring AI + 阿里百炼 DashScope:构建 AI Agent RAG 企业级知识助手
目录
前言:打破知识孤岛与大模型幻觉
在上一篇 《基于 Spring AI + DeepSeek:构建AI Agent 企业级服务与底层原理解析》 中,我们已经详细探讨了如何赋予大模型“记忆(Memory)”和“手脚(Tool Use)”。
然而,单纯的 Agent 依然面临一个致命缺陷:大模型的知识仅限于其训练数据,它不知道企业内部的私有规章制度、文档或最新的技术方案,这就会导致严重的“幻觉”。
为了解决这个问题,ai-agent-rag 项目在 ai-agent-chat 的基础能力(记忆+触手)之上,引入了 RAG(检索增强生成) 技术。本文将重点拆解:如何利用 Spring AI 的文档解析组件、Elasticsearch 向量数据库,以及阿里 DashScope 的 Rerank 重排模型,打造一个高精度的“双重漏斗”知识检索 Agent。
(注:关于 Memory 分布式缓存和 Tool Function 触手的详细底层原理,本项目直接复用了上篇架构,本文不再细致描述,建议搭配前文 《基于 Spring AI + DeepSeek:构建AI Agent 企业级服务与底层原理解析》 食用。)
对于 rag 相关概念不太熟悉的同学,推荐阅读另一篇博客后再来实践,这样就不会在撸码时一知半解:AI RAG 核心概念扫盲:彻底搞懂向量、切片与 Embedding 原理
环境与准备
源码获取:Github源码获取
📦 专属依赖包引入与版本管控
本项目同样作为 spring-ai-lab 的子模块,除了继承父 POM 中的 Spring Boot (3.3.3) 和 Spring Cloud Alibaba 之外,为了支持复杂的文档解析、向量存储和多模型打分,我们在 ai-agent-rag 的 pom.xml 中追加了以下极其重要的核心依赖:
<properties>
<spring-ai-alibaba.version>1.1.2.2</spring-ai-alibaba.version>
</properties>
<!-- 核心 1:用于 AI RAG 解析上传的数据文件 (Tika 支持 PDF, Word, Excel 等多种格式自动嗅探) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
<!-- 核心 2:集成 ElasticSearch 作为向量数据库 (Vector Store) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-elasticsearch</artifactId>
</dependency>
<!-- 配合 ES 需要的基础 java client -->
<!-- 💡 提示:作为向量数据库,Elasticsearch 需要是 8.x 及以上版本才原生且完全支持 Dense Vector 检索。-->
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.18.8</version>
</dependency>
<!-- 核心 3:集成阿里 DashScope,用于提供 Embedding (文本向量化) 和 Rerank (重排精排) 能力 -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
<version>${spring-ai-alibaba.version}</version>
</dependency>
<!-- 核心 4:RAG 向量拦截器扩展依赖 (DocumentRetrievalAdvisor 等所在包) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
💡 多模型协同与阿里百炼的优势
在上面引入的spring-ai-alibaba-starter-dashscope依赖中,我们选择了一个大平台方案。在之前的博客中,我们单独引入了 DeepSeek 作为大语言模型。但在实际开发中,尤其像 RAG 这种综合性应用,通常需要多种类型的模型协同工作:需要 Embedding 模型把文档变成向量,需要 Rerank 模型进行精准重排,还需要主逻辑的对话模型(LLM)来推理总结。
目前的情况是:某些厂商可能专注于对话大模型,并未提供配套的 Embedding 或 Rerank API。如果分别使用不同厂商的模型——比如 A 厂商做向量化,B 厂商做重排,另一家做对话,就需要在 POM 中引入多套 SDK,并配置多个密钥,维护成本较高。
解决方案:为了降低复杂度,我们在本期 RAG 实现中全面使用了阿里百炼平台。只需引入这一个依赖,就可以同时集成大语言模型(LLM)、文本向量化模型(Embedding Model)以及重排序模型(Rerank Model)的底层支持。这样可以有效减少多组件集成的繁琐,让我们更专注于业务开发。
🔍 阿里百炼模型选型指南
关于百炼模型相关文档,可参考官方地址:什么是大模型服务平台百炼 (API Key获取:https://help.aliyun.com/zh/model-studio/get-api-key)
在本项目中,我们具体选用的模型搭配和注意点如下:
1. 大语言对话模型 (LLM)
我们主要调用 DashScope API 的纯文本模型(如 qwen-plus)来处理最终的归纳与对话。
2. 文本向量化模型 (Embedding)
用于将上传的文档切片转化为数值向量。我们选用了最新的 text-embedding-v4。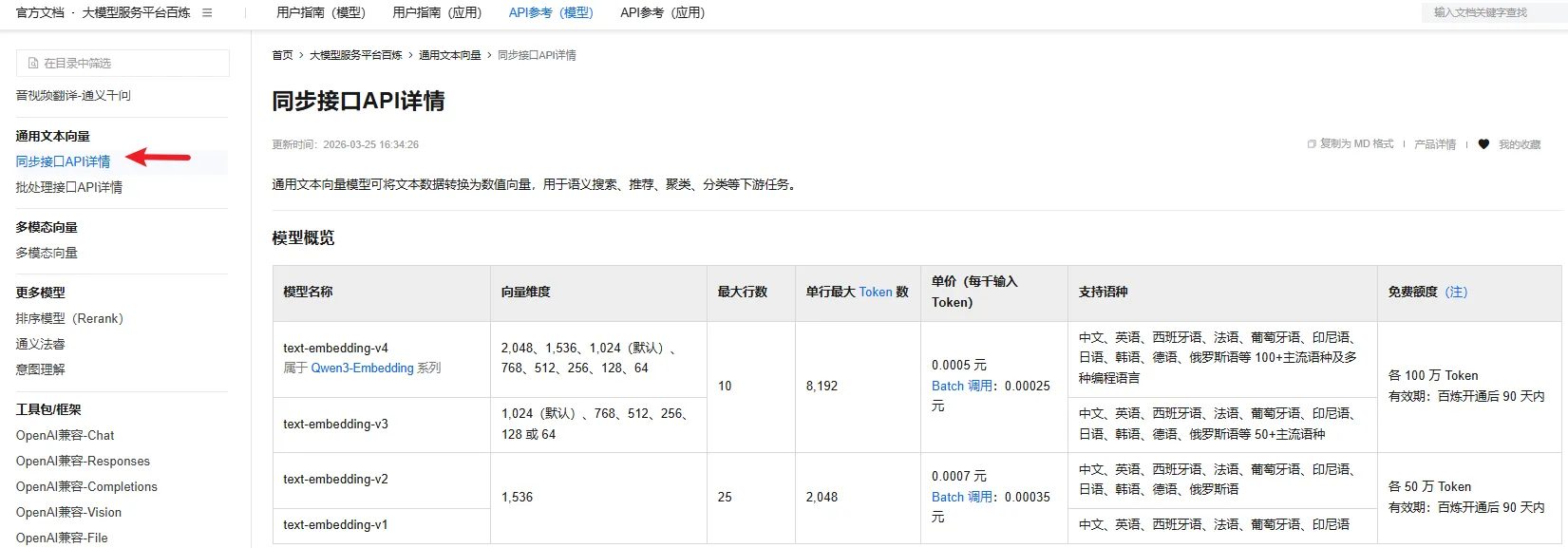
- 选取重点:v4 版本不仅性价比极高,更重要的是它支持丰富的输出维度选择(如 2048、1536、1024、768 等)。这让我们能够灵活指定维度(项目中指定为 768 维),从而更好地适配各类场景和 Elasticsearch 的索引配置。
3. 文本排序模型 (Rerank)
在召回阶段后,对初步返回的文档切片进行二次精准重排,确保最相关的结果排在最前。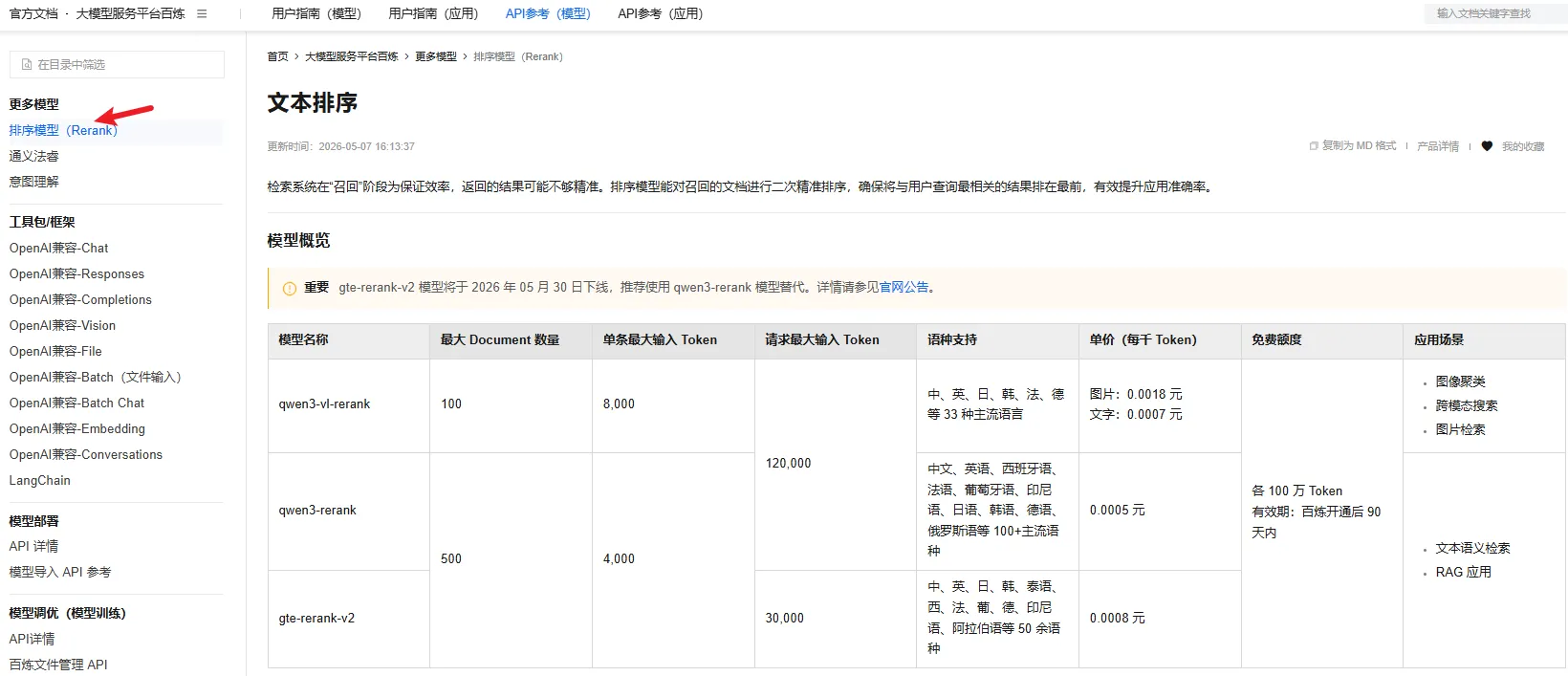
- 选取重点:根据官方公告,此前的
gte-rerank-v2模型即将于 2026 年 5 月下线。因此我们遵循官方推荐,直接使用了全新的qwen3-rerank模型。该模型最大输入支持 120,000 Token,极其适合在 RAG 应用中作为精排主力。
⚙️ YAML 配置与 Nacos 整合
以下是实战中的配置示例。请注意注释中的说明,这里有一个比较容易出错的维度配置项。
spring:
ai:
# 全局指定默认的对话模型平台为 dashscope
model:
chat: dashscope
dashscope:
api-key: sk-xxxxxxxxxxxxxxxxxxxxxxxxxx # 你的阿里 DashScope API Key
# 1. 向量化模型配置
embedding:
options:
model: text-embedding-v4
# 🚨 核心避坑:明确指定输出维度为 768
dimensions: 768
# 2. 重排序模型配置
rerank:
options:
model: qwen3-rerank
# 3. 大语言模型(对话)配置
chat:
enabled: true # 显式开启对话功能
options:
model: qwen-plus
# 温度系数:0.1-0.2 适合规章制度等严谨场景,能极大程度限制 AI 自由发挥,防止幻觉
temperature: 0.2
# 单次回复的最大 Token 数
max-tokens: 2000
# 核采样概率,通常保持默认 0.8 即可
top-p: 0.8
# 4. 向量数据库配置
vectorstore:
elasticsearch:
# 告诉 Spring AI 把知识存到哪个索引里
index-name: company_knowledge_index
# 🚨 极其关键:告诉 ES 我们要建多少维度的空间!
# 这个值【必须必须】和上面 embedding.options.dimensions 的值(768)完全一致,否则存入或检索时直接报错!
dimensions: 768
# 距离计算方式:余弦相似度
similarity: cosine
# 尝试开启自动初始化(部分版本支持自动在 ES 中建好 Index 和 Mapping)
initialize-schema: true
elasticsearch:
uris: http://ip:9200 # 如果使用 http,请确保 ES 端关闭了强制 HTTPS 安全验证
username: elastic
password: ****** # 你的 ES 密码
💥 关于 ConnectionClosedException 与 ES 8.x 安全机制
ES 8.x 默认开启了 HTTPS 安全验证。如果应用使用http://请求,会遇到连接被断开的情况,抛出ConnectionClosedException: Connection is closed异常。本地测试环境配置:如果是本地开发测试,可以在 ES 服务端关闭安全限制。
修改 ES 的config/elasticsearch.yml,加上以下配置:http.cors.enabled: true http.cors.allow-origin: "*" xpack.security.enabled: false重启 ES 后,就可以直接使用
uris: http://...连接了。🛡️ 生产环境配置:在生产环境中,建议保持开启
xpack.security。需要使用https://,并在 ES 服务端配置正规的 SSL 证书;或者将 ES 启动时生成的自签名证书导入到 Java 运行环境的 TrustStore 中,确保数据传输安全。
💡 为什么选择 Elasticsearch 8.x 作为向量数据库?
在搭建 RAG 架构时,向量数据库的选择至关重要。本项目最终选用了 Elasticsearch (ES) 8.x,主要基于以下考量:
1. ES 8.x 的原生向量检索能力进化
在 ES 7.x 时代,实现向量检索往往依赖外部插件或基于 Script Score 的暴力数学计算,性能较差。但从 ES 8.x 开始,其底层架构对向量搜索进行了全面进化:
- Lucene 底层重构:ES 核心搜索库 Lucene,在底层原生用 Java 实现了 HNSW(分层可导航小世界图)算法,大幅提升了检索效率。
- 专属数据类型:引入了全新的
dense_vector(稠密向量)数据类型。 - 硬件级加速原理:当 Spring AI 将文档的特征向量(如 768 维浮点数)发给 ES 时,ES 会将其存入
dense_vector字段,并在内存中构建 HNSW 索引树。在查询提问时,ES 甚至能利用底层汇编指令(SIMD)加速余弦距离的计算,保障毫秒级的极速响应。
2. 为什么不使用阿里的 DashVector?
既然模型全面拥抱了阿里百炼,为何不顺势接入阿里的 DashVector 向量数据库?主要原因是生态整合的便捷度。目前在 Java 环境中,DashVector 的 SDK 尚未提供好用的 Starter 依赖,需要开发者手写较多底层的接入代码,集成体验相对“鸡肋”。相比之下,ES 作为成熟的检索引擎,配合 Spring AI 官方提供的 spring-ai-starter-vector-store-elasticsearch,能做到顺滑的开箱即用。
3. 零成本的架构复用与无缝接入
在大多数中大型企业架构中,Elasticsearch 几乎是提供日志分析(ELK)或复杂业务搜索的“标配”基础设施。这意味着在计划接入 AI 之前,一个稳定、高可用的 ES 集群通常就已经在生产环境中良好运行了。此时为了实现 RAG 功能,我们完全不需要去额外部署和运维一套全新的纯向量数据库(如 Milvus、Chroma 等)。只需要复用现存的 ES 8.x 服务,即可实现无缝接入,这极大地降低了新技术的引入风险、服务器硬件成本以及运维团队的学习负担。
实践:落地高精度 RAG 核心支柱
一、 知识的“进货”:Tika 解析与向量化入库
RAG 的第一步是把人类的文档喂给数据库。普通的文本解析器只能读 .txt,这在企业中毫无价值。在 AgentRagFileController 中,我们实现了一个全自动的知识注入链路:
@PostMapping("/upload")
public String uploadKnowledgeFile(@RequestParam("file") MultipartFile file) {
long startTime = System.currentTimeMillis();
String filename = file.getOriginalFilename();
log.info("开始处理知识库文件上传任务, 文件名: {}", filename);
try {
// 1. 文件加载 (Load):巧妙利用 Spring 的 Resource 接口,避免在本地磁盘生成临时文件
Resource resource = file.getResource();
// 🚨 细节亮点:使用 TikaDocumentReader
// Tika 会自动嗅探文件类型(Word, PDF, Excel等),并智能剥离排版,提取出纯净的文本!
TikaDocumentReader documentReader = new TikaDocumentReader(resource);
List<Document> rawDocs = documentReader.get();
// 🚨 细节溯源:手动追加我们自定义的元数据
// 这样在最终回答时,大模型才能告诉你这段知识是从哪个文档里找出来的!
for (Document doc : rawDocs) {
doc.getMetadata().put("source_filename", filename);
doc.getMetadata().put("upload_timestamp", System.currentTimeMillis());
}
// 2. 文本切片 (Split):维持黄金比例
// 大模型有上下文限制,必须把长文档切成小块 (Chunk)
TokenTextSplitter splitter = new TokenTextSplitter();
List<Document> chunkedDocs = splitter.apply(rawDocs);
// 3. 向量化与存储 (Embed & Store):全自动批量处理
// 这行代码背后,Spring AI 自动调用 DashScope Embedding 模型将文本转成多维向量,并存入 Elasticsearch
vectorStore.add(chunkedDocs);
return String.format("文件 [%s] 导入成功!共生成 %d 个知识切片,耗时 %d ms。", filename, chunkedDocs.size(), System.currentTimeMillis() - startTime);
} catch (Exception e) {
log.error("处理异常", e);
return "导入失败";
}
}
代码说明:使用 TikaDocumentReader 能够方便地处理多种文档格式的解析,减少了针对不同后缀名编写特定解析器的繁琐工作。
📌 上传接口演示:
将一份内部的技术操作手册(PDF或Word)通过接口传入: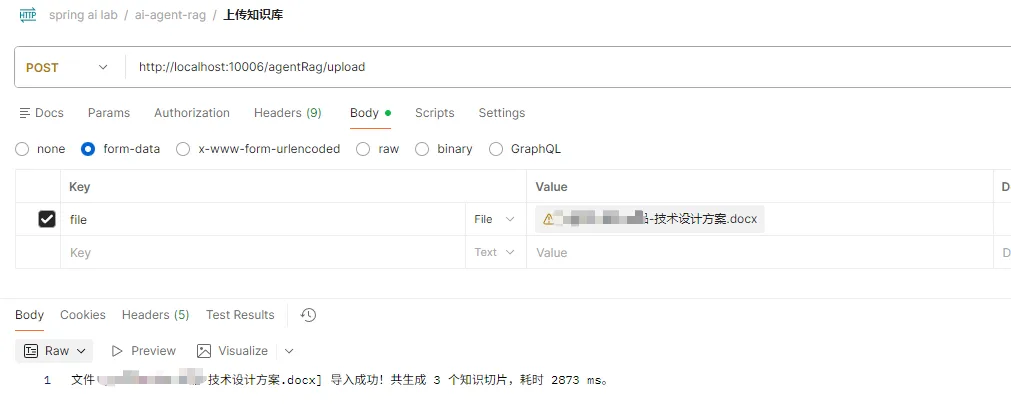
上传接口日志打印: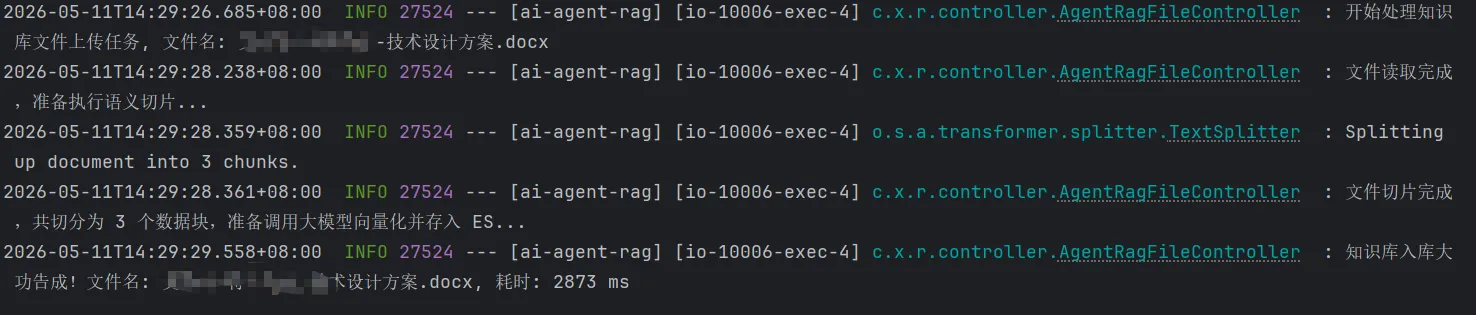
ES中查看向量数据

二、 检索架构:“双重漏斗”机制
这是本项目中重要的一环。基础的 RAG 通常是去 ES 里获取 Top K 相似度的数据并直接提供给大模型。
背景说明:当知识库内容较多时,单次向量检索可能会带出一些词汇相似但语义无关的片段,这就是“检索噪音”。噪音过多可能会影响大模型的回答准确性。
为了优化这一点,我们在 AgentRagChatController 中结合了阿里的 DashScopeRerankModel,设计了粗排 + 精排的双漏斗检索机制。
@RestController
@RequestMapping("/agentRag")
public class AgentRagChatController {
private final ChatClient chatClient;
public AgentRagChatController(ChatClient.Builder chatClientBuilder,
VectorStore vectorStore,
ChatMemory chatMemory,
DashScopeRerankModel rerankModel) {
// 🏆 核心细节:自研“双重漏斗”检索器 DocumentRetriever
DocumentRetriever dualRetriever = query -> {
// 漏斗第一级:ES 粗排 (捞取 Top 20)
// 粗排追求的是极速与高召回率(宁可错杀一千,不放过一个)
List<Document> rawDocs = vectorStore.similaritySearch(
SearchRequest.builder().query(query.text()).topK(20).build()
);
log.info("ES 粗排完毕,捞出 {} 条切片,准备进入精排...", rawDocs.size());
// 漏斗第二级:Rerank 精排 (浓缩至 Top 3)
// 引入 DashScope 的专门打分模型,进行深度的语义交叉打分重排
RerankRequest rerankRequest = new RerankRequest(query.text(), rawDocs);
List<DocumentWithScore> resultScore = rerankModel.call(rerankRequest).getResults();
// 提取最终得分最高的 3 条切片
List<Document> results = resultScore.stream().map(DocumentWithScore::getOutput).toList();
log.info("精排完毕,已锁定最精准的 3 条切片!");
return results;
};
// 装配全能 Agent 客户端
this.chatClient = chatClientBuilder
.defaultSystem("你是一个公司项目技术方案助手。请根据提供的知识库内容,准确、专业地回答员工的问题。如果在知识库中找不到答案,请诚实地说明。")
.defaultAdvisors(
// 1. 注入知识库 (RAG):把精排后的文档切片塞进提示词
new DocumentRetrievalAdvisor(dualRetriever),
// 2. 注入记忆 (Memory):将上一篇博客实现的分布式 Redis Memory 直接挂载
MessageChatMemoryAdvisor.builder(chatMemory).build()
)
// 3. 注入触手 (Tool):允许大模型在必要时调用内部微服务 API(天气、订单等)
.defaultToolNames("weatherFunction", "orderFunction")
.build();
}
}
为什么必须加入 Rerank 模型?
- **ES 的向量搜索(粗排)**是基于静态多维空间距离的。比如查“苹果公司”,它可能会把“苹果又红又甜(水果)”也查出来,因为单个词向量的特征离得近。
- Rerank 精排则是把“用户的问题”和“每一篇检索出来的文档”合并,丢给大语言模型级别的神经网络去逐句阅读、交叉对比。它极度消耗算力,所以只能对粗排出来的 Top 20 挨个打分,挑出最符合人类逻辑的 Top 3,从而彻底消灭噪音!
三、 发起对话:流式 API 调用
在完成了基础组件配置和检索逻辑后,最终的业务对话代码比较简洁,体现了 Spring AI 封装的便利性:
@GetMapping("/chat")
public String chatWithKnowledge(@RequestParam("chatId") String chatId,
@RequestParam("prompt") String prompt) {
long startTime = System.currentTimeMillis();
log.info("接收到会话 [{}] 的咨询: {}", chatId, prompt);
try {
// 这就是 Spring AI 极其惊艳的链式 API
String response = chatClient.prompt()
.user(prompt)
// 绑定对话 ID,让 AI 知道这次对话属于哪个用户/窗口(触发 Memory 生效)
.advisors(a -> a.param("chat_memory_conversation_id", chatId))
.call()
.content();
log.info("会话 [{}] 思考完毕,耗时 {} ms", chatId, (System.currentTimeMillis() - startTime));
return response;
} catch (Exception e) {
log.error("AI 思考时发生异常: {}", e.getMessage(), e);
return "对不起,AI 助手暂时遇到了系统异常,请稍后再试。";
}
}
当请求到达时,底层主要经历了以下流转过程:
- 记忆加载:去 Redis 捞出
chatId对应的历史聊天记录。 - 知识检索:把用户的
prompt拿去 ES 检索出 20 条片段,并调用阿里大模型浓缩成 3 条核心片段。 - Prompt 拼装:把历史记录、3 条私有文档、系统预设(System Prompt)糅合在一起,发给当前的主逻辑模型(如 DeepSeek)。
- 决策与 Tool 调用:如果 DeepSeek 发现问题命中
orderFunction(例如问“根据手册规定,我的 D123456 订单退款怎么走?”),它会挂起响应,回调 Java 代码获取真实订单状态,再结合手册给出售后建议!
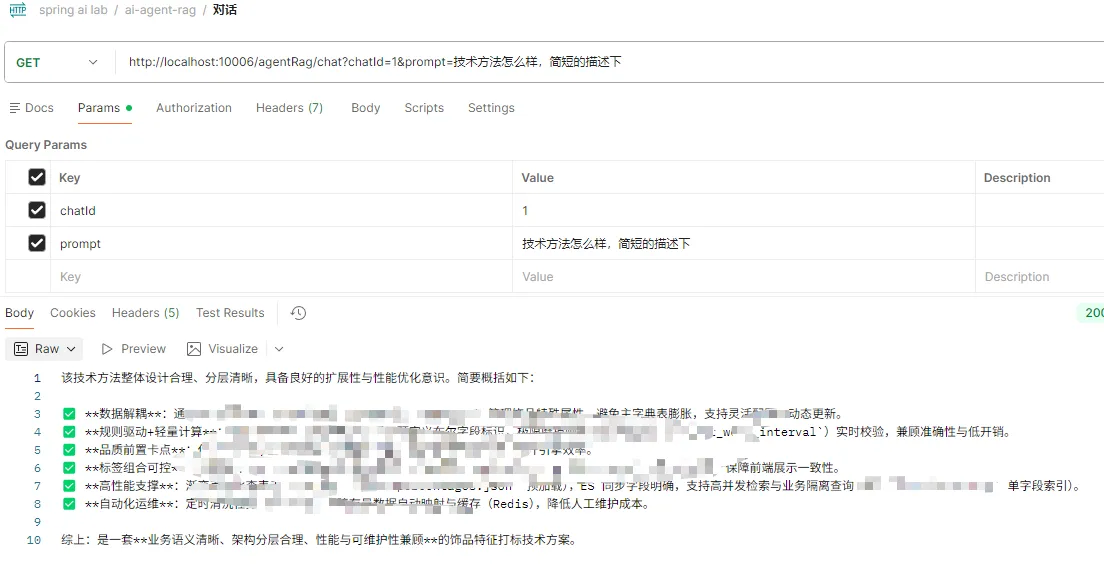
📌 RAG + Agent 综合对话演示:
-
查询私有知识(RAG生效):询问刚才上传的技术手册里的公司报销流程规范。大模型准确根据文档回答,并在控制台打印出精排日志。

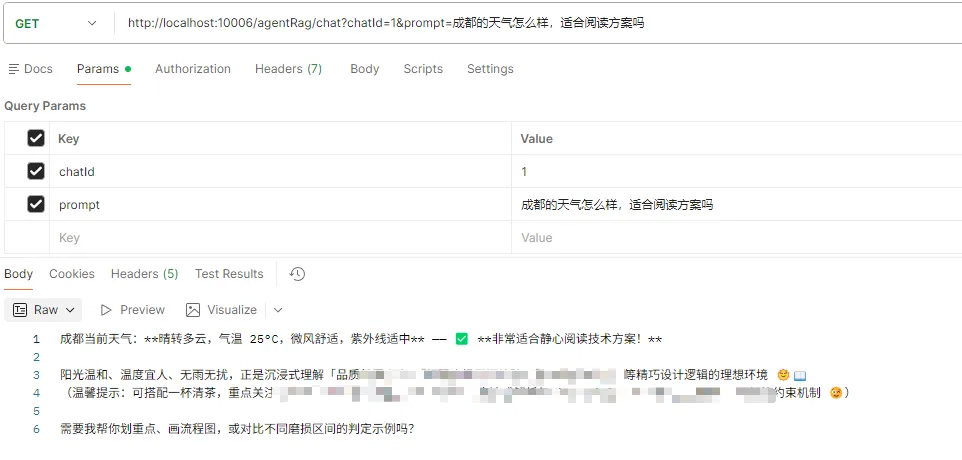
-
跨界结合(RAG + Tool + Memory 生效):追问“那我的订单 D123456 满足刚刚说的报销规范吗?”。此时大模型同时调用记忆(知道说的是报销规范)、调用 Tool(去查了订单数据发现是 100元已完成),然后进行推理回复!
总结:AI 应用的终极形态
通过 ai-agent-rag 这个模块,我们拼上了企业级 AI 应用拼图的最核心部分。
一个真正的、具备实战价值的 Agent 架构体系已经完全落地:
- 底座 (Memory):基于 Redis DTO 防腐层的持久化记忆。
- 左手 (RAG):基于 Elasticsearch + Tika + DashScope Rerank 构筑的“双重漏斗”私有知识大脑。
- 右手 (Tool):基于 Spring Bean
@Description实现的动态函数代理机制,链接现有业务服务。 - 大脑 (LLM):基于大语言模型的核心逻辑规划与决策。
在这个架构下,AI 不仅能进行基础的对话问答,还具备了“理解意图、查阅私有文档、维持多轮上下文记忆、调用外部工具”的能力,成为了一个能够辅助处理实际业务流程的智能工具。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)