Kafka与RabbitMQ深度解析与场景选型
Kafka 和 RabbitMQ 作为当前最主流的两款中间件,经常被拿来对比,但很多同学对它们的理解还停留在 "Kafka 吞吐高、RabbitMQ 灵活" 的表层,今天我从底层架构、核心特性到实际场景,给你做一次彻底的拆解。
一、核心定位:两种完全不同的设计哲学
很多人会把它们都归为 "消息队列",但实际上它们的设计初衷天差地别:
-
RabbitMQ:本质是一个智能的消息代理(Message Broker),它的核心目标是实现消息的可靠投递与灵活路由,更像一个 "智能邮局",负责把消息精准、可靠地送到该去的地方。
-
Kafka:本质是一个分布式流处理平台,它的核心目标是实现海量数据流的持久化与分发,更像一个 "分布式日志系统",负责把海量的流数据高效存储、分发,支撑后续的流处理与分析。
这个定位的差异,决定了它们所有的特性差异,也是我们选型的根本依据。
二、RabbitMQ:高可靠的业务消息专家
RabbitMQ 是基于 AMQP 协议、用 Erlang 语言开发的消息中间件,凭借轻量级、高可靠、路由灵活的特性,是企业级业务系统的首选。
2.1 核心架构与组件
RabbitMQ 的核心架构围绕 "交换机 - 队列" 的路由模型展开:
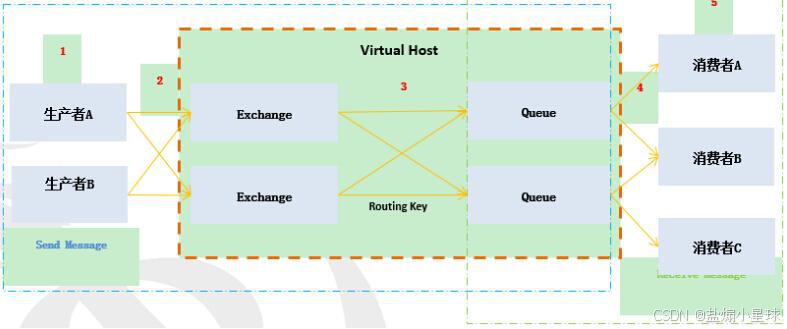
核心组件包括:
-
Virtual Host:虚拟主机,实现多租户隔离,不同 VHost 的 Exchange、Queue 完全隔离。
-
Exchange(交换机):消息的入口,负责根据路由规则分发消息,支持 4 种核心类型:
-
Direct:精准匹配路由键,适用于点对点消息投递
-
Topic:通配符匹配(
*匹配单个单词、#匹配多个),适用于多条件路由 -
Fanout:广播模式,无视路由键,把消息发给所有绑定的队列
-
Headers:根据消息头属性匹配,使用场景极少
-
-
Binding(绑定):定义 Exchange 与 Queue 之间的路由规则,是 RabbitMQ 灵活路由的核心。
-
Queue(队列):消息的存储载体,消费者从队列拉取 / 接收消息,支持持久化、死信等特性。
2.2 核心特性与优势
1. 极其灵活的路由能力
这是 RabbitMQ 最大的优势,你可以通过组合不同的 Exchange 和 Binding,实现非常复杂的消息分发逻辑:
-
比如把订单消息根据不同的状态,路由给库存服务、支付服务、通知服务
-
比如把日志消息根据级别(error/warn/info)路由给不同的处理程序
-
甚至可以实现消息的优先级、延迟投递等高级特性
2. 完善的可靠性保障
RabbitMQ 提供了多层级的可靠机制,确保消息不丢不重:
-
消息 / 队列持久化:把消息和队列元数据持久化到磁盘,宕机后不丢失
-
生产者确认(Publisher Confirm):确保消息成功投递到 Broker
-
消费者手动 ACK:消费者处理完消息后才确认,失败了可以重新投递
-
死信队列(DLQ):处理失败 / 过期的消息,避免消息丢失,方便后续重试
3. 低延迟的推模式消费
RabbitMQ 默认采用推模式(Push):Broker 主动把消息推送给消费者,配合 prefetch 限流机制,能实现毫秒级的低延迟,非常适合需要实时响应的业务场景。
4. 丰富的企业级特性
-
原生支持延迟队列(通过 TTL+DLQ,或者官方插件)
-
支持消息优先级,重要消息可以优先被消费
-
支持多协议:AMQP、MQTT、STOMP,适配不同的接入场景
-
轻量级,部署和运维成本低,学习成本小
2.3 Java 实战示例(Spring AMQP)
对于 Java 开发来说,Spring AMQP 已经把 RabbitMQ 的操作封装得非常简单,下面是一个订单通知的示例:
// 1. 配置类:定义交换机、队列、绑定关系
@Configuration
public class RabbitMqConfig {
public static final String ORDER_EXCHANGE = "order.event.exchange";
public static final String SMS_QUEUE = "order.sms.queue";
public static final String EMAIL_QUEUE = "order.email.queue";
public static final String ROUTING_KEY_SMS = "order.create.sms";
public static final String ROUTING_KEY_EMAIL = "order.create.email";
// 定义Topic交换机
@Bean
public TopicExchange orderExchange() {
return new TopicExchange(ORDER_EXCHANGE, true, false);
}
// 短信队列,绑定到交换机,路由键匹配sms
@Bean
public Queue smsQueue() {
return QueueBuilder.durable(SMS_QUEUE).build();
}
@Bean
public Binding smsBinding() {
return BindingBuilder.bind(smsQueue()).to(orderExchange()).with(ROUTING_KEY_SMS);
}
// 邮件队列,绑定到交换机,路由键匹配email
@Bean
public Queue emailQueue() {
return QueueBuilder.durable(EMAIL_QUEUE).build();
}
@Bean
public Binding emailBinding() {
return BindingBuilder.bind(emailQueue()).to(orderExchange()).with(ROUTING_KEY_EMAIL);
}
}
// 2. 生产者:订单创建后发送消息
@Service
@Slf4j
public class OrderProducer {
@Autowired
private RabbitTemplate rabbitTemplate;
public void sendOrderCreateEvent(Order order) {
// 发送短信通知消息
rabbitTemplate.convertAndSend(
ORDER_EXCHANGE,
ROUTING_KEY_SMS,
order
);
// 发送邮件通知消息
rabbitTemplate.convertAndSend(
ORDER_EXCHANGE,
ROUTING_KEY_EMAIL,
order
);
log.info("订单事件发送成功,订单号:{}", order.getOrderId());
}
}
// 3. 消费者:处理短信通知
@Component
@Slf4j
public class SmsConsumer {
@RabbitListener(queues = RabbitMqConfig.SMS_QUEUE)
public void handleSmsMessage(Order order, Channel channel, @Header(AmqpHeaders.DELIVERY_TAG) long tag) {
try {
// 调用短信服务发送通知
smsService.sendOrderNotify(order.getUserPhone(), order.getOrderId());
// 手动ACK,确认消息处理完成
channel.basicAck(tag, false);
} catch (Exception e) {
log.error("短信通知处理失败", e);
// 处理失败,拒绝消息,重新入队
channel.basicNack(tag, false, true);
}
}
}三、Kafka:高吞吐的数据流专家
Kafka 最初由 LinkedIn 开发,后来捐给 Apache,是一个分布式的流处理平台,专为海量数据流的存储、分发和处理而生,是大数据、实时计算场景的标配。
3.1 核心架构与组件
Kafka 的核心架构围绕 "主题 - 分区" 的日志模型展开:
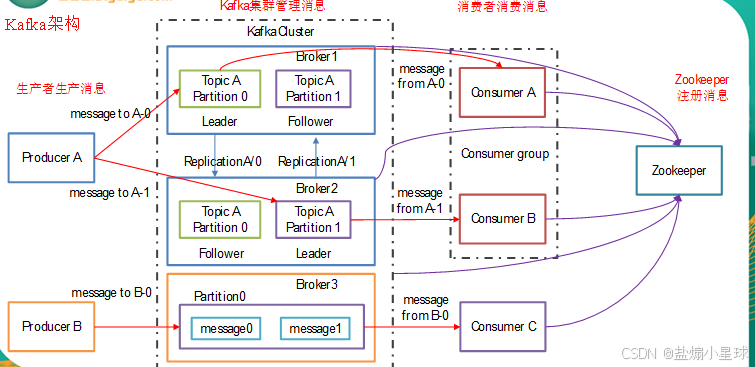
核心组件包括:
-
Broker:Kafka 集群的节点,负责存储消息,一个集群可以有多个 Broker,实现水平扩展。
-
Topic(主题):消息的逻辑分类,比如用户行为埋点的 topic、日志的 topic。
-
Partition(分区):Topic 的物理拆分,每个分区都是一个有序、不可变的日志文件,消息按顺序写入,按 offset 读取。这是 Kafka 高吞吐的核心,通过分区实现并行处理。
-
Replica(副本):每个分区可以有多个副本,分布在不同的 Broker 上,实现高可用,Leader 副本负责读写,Follower 副本负责同步数据。
-
Consumer Group(消费者组):消费者的分组机制,组内的消费者共同消费一个 Topic,每个分区只会分配给组内的一个消费者,实现负载均衡。不同的消费者组可以独立消费同一个 Topic 的消息,实现消息的多分发。
-
Offset(偏移量):消费者在分区内的消费位置,由消费者自己维护,这意味着消费者可以随时重置 offset,重新消费历史数据。
3.2 核心特性与优势
1. 超高的吞吐量
这是 Kafka 最核心的优势,单机就能支持每秒数十万甚至百万级的消息处理,支撑亿级流量的场景。它的性能优化点非常极致:
-
顺序写磁盘:所有消息都是顺序写入磁盘,完全规避了随机 IO 的性能损耗,磁盘的顺序写速度甚至比内存的随机写还快
-
零拷贝(Zero Copy):直接从内核缓冲区把数据发送到网络,跳过用户态的拷贝,大幅减少 CPU 开销
-
批量处理:生产者和消费者都是批量处理消息,减少网络 IO 的开销
-
Page Cache 缓存:利用操作系统的页缓存来缓存热点数据,大幅提升读取性能
2. 消息的持久化与回溯
Kafka 的消息不会因为被消费就删除,而是会根据保留策略(比如保留 7 天,或者保留 100G)自动清理。这意味着:
-
消费者可以随时重置 offset,重新消费历史数据,这对于数据重放、故障恢复非常有用
-
支持事件溯源(Event Sourcing),所有的事件都存在 Kafka 里,随时可以重建状态
-
支持多消费组,同一个消息可以被多个下游系统独立消费,互不影响
3. 极强的水平扩展能力
Kafka 的分区机制天然支持水平扩展:
-
一个 Topic 可以拆分成成百上千个分区,分布在不同的 Broker 上
-
集群的吞吐量随着分区数的增加线性提升,理论上可以无限扩展
-
消费者组也可以动态扩展,消费者数量可以跟着分区数调整,自动负载均衡
4. 完善的大数据生态
Kafka 已经成为大数据领域的事实标准,和整个大数据生态无缝集成:
-
流处理框架:Flink、Spark Streaming、Kafka Streams 都可以直接消费 Kafka 的消息,做实时计算
-
数据管道:可以把 Kafka 的数据同步到 Hadoop、Elasticsearch、ClickHouse 等存储系统
-
监控、日志系统:ELK、Prometheus 等都把 Kafka 作为数据接入的标准管道
3.3 Java 实战示例(Spring Kafka)
Spring Kafka 对 Kafka 的封装也非常成熟,下面是一个用户行为埋点的示例:
// 1. 配置类
@Configuration
public class KafkaConfig {
public static final String USER_BEHAVIOR_TOPIC = "user-behavior-events";
public static final String CONSUMER_GROUP = "behavior-analytics-group";
// 生产者配置
@Bean
public ProducerFactory<String, UserBehaviorEvent> producerFactory() {
Map<String, Object> config = new HashMap<>();
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
// 开启幂等性,避免重复消息
config.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
return new DefaultKafkaProducerFactory<>(config);
}
@Bean
public KafkaTemplate<String, UserBehaviorEvent> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
// 2. 生产者:用户行为埋点上报
@Service
@Slf4j
public class BehaviorProducer {
@Autowired
private KafkaTemplate<String, UserBehaviorEvent> kafkaTemplate;
public void reportUserBehavior(UserBehaviorEvent event) {
// 用userId作为key,保证同一个用户的消息顺序写入同一个分区
kafkaTemplate.send(
USER_BEHAVIOR_TOPIC,
event.getUserId(),
event
);
log.info("用户行为上报成功,用户:{},行为:{}", event.getUserId(), event.getAction());
}
}
// 3. 消费者:实时分析用户行为
@Component
@Slf4j
public class BehaviorConsumer {
@KafkaListener(topics = USER_BEHAVIOR_TOPIC, groupId = CONSUMER_GROUP)
public void handleBehaviorEvent(ConsumerRecord<String, UserBehaviorEvent> record) {
UserBehaviorEvent event = record.value();
try {
// 实时更新用户画像
userProfileService.updateProfile(event);
// 实时统计用户行为指标
statisticsService.countBehavior(event);
// offset由Spring自动提交,也可以手动提交
} catch (Exception e) {
log.error("用户行为处理失败", e);
// 失败了可以重置offset,重新消费
}
}
}四、核心维度对比:一张表看懂差异
为了让你更直观地看到两者的差异,我整理了核心维度的对比表:
|
对比维度 |
RabbitMQ |
Apache Kafka |
|
核心定位 |
消息代理,专注可靠路由与投递 |
分布式流平台,专注海量流数据处理 |
|
吞吐量 |
万级 TPS(单机数千~数万) |
十万~百万级 TPS(单机数十万~百万) |
|
消息模型 |
Exchange + Queue,路由驱动 |
Topic + Partition,日志驱动 |
|
消费模式 |
推模式(Push),Broker 主动推送 |
拉模式(Pull),消费者主动拉取 |
|
消息路由 |
极强,支持 4 种交换机,复杂路由 |
较弱,仅支持 Topic+Key 的简单路由 |
|
消息顺序 |
单队列内有序,全局有序需单队列单消费者 |
分区内严格有序,全局有序需单分区 |
|
消息持久化 |
消费后默认删除,可配置持久化 |
持久化存储,按保留策略清理,支持回溯 |
|
可靠性 |
原生完善的 ACK、死信、重试机制 |
依赖副本 + ACK 配置,需手动实现重试 |
|
延迟队列 |
原生支持(TTL+DLQ / 插件) |
需自定义实现,2.4 + 版本支持延时主题 |
|
优先级队列 |
原生支持 |
不支持 |
|
水平扩展 |
较弱,镜像队列扩展成本高 |
极强,分区线性扩展,支持无限扩容 |
|
生态集成 |
专注业务通信,适配微服务 |
专注大数据,适配 Flink/Spark/ELK 等 |
|
延迟 |
毫秒级低延迟 |
批处理优化,延迟略高(也可做到毫秒级) |
五、典型使用场景:什么时候选哪个?
了解了特性之后,我们来看实际的场景,这才是选型的关键:
5.1 优先选择 RabbitMQ 的场景
当你的需求是业务系统的异步通信、可靠任务处理,优先选 RabbitMQ:
1. 微服务间的异步解耦
比如电商的订单流程:订单创建后,需要通知库存扣减、支付回调、积分更新、通知服务。
-
这里需要灵活的路由,把订单消息分发给不同的服务
-
需要可靠的投递,确保每个任务都能执行成功,不能丢消息
-
不需要特别高的吞吐量,每秒几千到几万的消息足够了
2. 异步任务处理
比如短信、邮件通知,文件导出,报表生成这些耗时的异步任务。
-
这些任务需要可靠执行,失败了要能重试
-
可能需要延迟任务,比如订单 15 分钟未支付自动取消
-
RabbitMQ 的死信队列、延迟队列完美适配这些需求
3. 复杂的业务路由场景
比如多租户的消息分发,或者根据消息的不同属性路由给不同的处理程序。
-
比如 SaaS 系统里,不同租户的消息要路由给不同的处理实例
-
比如日志系统里,不同级别、不同服务的日志要路由给不同的存储
-
RabbitMQ 的 Topic 交换机可以轻松实现这些复杂的路由逻辑
4. 中小规模的业务系统
如果你的系统 QPS 不高,不需要处理海量的数据流,只是普通的业务异步解耦,RabbitMQ 是更好的选择:
-
部署简单,运维成本低
-
学习成本小,开发上手快
-
功能完善,开箱即用,不需要自己实现太多逻辑
5.2 优先选择 Kafka 的场景
当你的需求是海量数据流的处理、实时分析,优先选 Kafka:
1. 日志 / 埋点数据采集
这是 Kafka 最经典的场景,比如:
-
分布式系统的日志收集,所有服务的日志都上报到 Kafka,然后同步到 ELK 或者数据仓库
-
用户行为埋点,APP 的点击、浏览、搜索等行为,每秒几十万甚至上百万的上报量
-
这种场景下,需要极高的吞吐量,Kafka 的顺序写、批量处理完美适配,而且消息可以持久化,方便后续的分析
2. 实时流处理
比如实时风控、实时监控、实时排行榜、实时数据报表:
-
比如电商大促的实时销售额统计,实时的流量监控
-
比如金融的实时风控,检测用户的异常交易行为
-
这些场景需要对接 Flink、Spark 这些流处理框架,Kafka 是它们的标准输入源
3. 数据管道与数据同步
比如把业务数据同步到数据仓库,或者同步到不同的存储系统:
-
比如 MySQL 的 binlog 同步到 Kafka,然后同步到 Elasticsearch 做搜索,同步到 Hadoop 做分析
-
这种场景下,需要消息的持久化和回溯,下游系统出问题了,可以重新消费数据,而且可以支持多个下游系统同时消费
4. 高吞吐的大流量场景
比如秒杀、大促的消息削峰,或者 IoT 设备的海量数据上报:
-
比如 IoT 场景下,百万级设备的上报数据,每秒几十万的消息量
-
这种场景下,Kafka 的高吞吐、高扩展能力是 RabbitMQ 比不了的
5.3 混合架构:大厂的最佳实践
在很多中大型公司,这两个中间件是共存的,各司其职:
-
RabbitMQ:处理核心的业务消息,比如订单、支付、通知这些业务逻辑,保证可靠投递和灵活路由
-
Kafka:处理数据流,比如日志、埋点、数据同步这些海量数据,支撑大数据和实时分析
比如我们之前的电商系统,就是这样的架构:
-
用户下单的业务消息走 RabbitMQ,保证订单流程的可靠
-
用户的行为埋点、服务的日志走 Kafka,用来做实时分析和离线计算
-
这样既保证了业务的可靠性,又支撑了大数据的需求,完美互补。
六、常见误区:
很多同学对这两个中间件有一些常见的误区,这里给你澄清一下容易混淆的点:
误区 1:Kafka 可以替代 RabbitMQ
这是最常见的误区,很多人觉得 Kafka 吞吐高,功能也越来越全,就可以替代 RabbitMQ 了。
-
不对,它们的定位完全不同,Kafka 不擅长复杂路由,也不擅长低延迟的业务消息投递
-
比如你要做订单的延迟取消,用 RabbitMQ 开箱即用,用 Kafka 你要自己实现时间轮,非常麻烦
-
所以它们不是替代关系,是互补关系。
误区 2:RabbitMQ 性能差
很多人觉得 RabbitMQ 吞吐量低,性能差。
-
不对,RabbitMQ 的万级 TPS 对于绝大多数业务系统来说完全够用了,90% 的业务系统 QPS 都到不了 10 万
-
而且 RabbitMQ 的延迟更低,毫秒级的响应,比 Kafka 的批处理模式更适合实时的业务消息
-
只有当你需要处理几十万上百万的海量数据流的时候,RabbitMQ 才会不够用。
误区 3:Kafka 的消息会丢
很多人觉得 Kafka 默认会丢消息,不可靠。
-
不对,Kafka 的可靠性是可配置的,你可以配置 acks=all,开启副本,也能做到非常高的可靠性
-
只是默认的配置为了性能,允许少量的丢失,但是你可以根据业务需求调整
-
而且现在 Kafka 也支持事务、幂等生产者,也能做到 Exactly-once 的投递语义。
七、选型总结:一句话帮你做决策
最后,给你一个最简单的选型口诀,帮你快速做决策:
业务消息选 Rabbit,数据流选 Kafka,大公司可以一起用
-
如果你的核心需求是业务解耦、可靠任务、复杂路由,选 RabbitMQ,它是业务消息的专家
-
如果你的核心需求是海量数据、实时分析、流处理,选 Kafka,它是数据流的专家
-
如果你的系统既有业务需求,又有大数据需求,那就两个都用,混合架构是大厂的最佳实践
没有最好的技术,只有最适合的技术,理解它们的设计哲学,结合你的业务场景,才能做出最合理的选型。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)