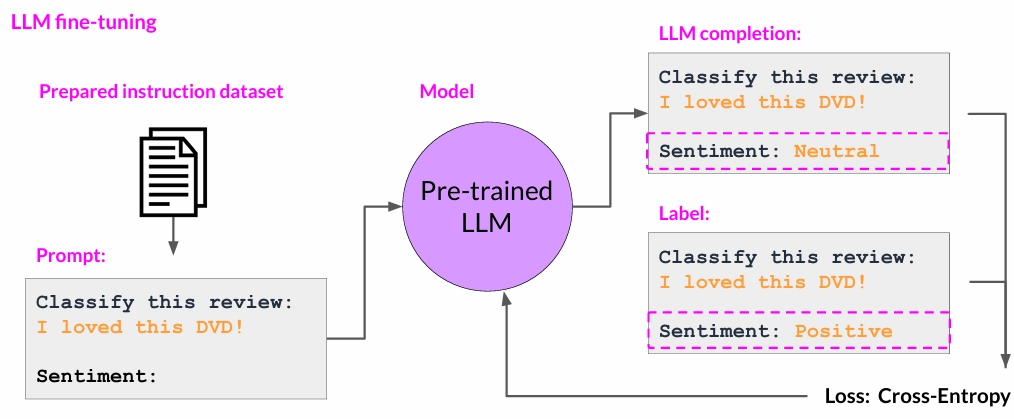
大模型微调实战:从零开始学 SFT,让你的模型“学会”新技能!
本文介绍了大模型微调(SFT)的概念、原理和实际操作流程。SFT 通过使用带“标准答案”的监督数据进行训练,让模型在特定任务、风格或行为上表现更稳定、更符合预期。文章详细解释了 SFT 的核心机制,包括行为适应、任务专业化和安全一致性对齐,并提供了完整的实操示例,帮助读者理解如何使用 SFTTrainer 工具进行训练。此外,文章还强调了数据质量的重要性,并建议读者在开始微调之前,先通过提示词工程验证任务,评估任务表现,选择合适的任务进行微调,收集高质量数据,并进行小模型验证。通过学习本文,读者可以掌握 SFT 的基本流程,并为更复杂的指令微调、领域微调等实践打下基础。
什么是有监督微调
那所谓的有监督微调,指的是在一个已经完成预训练的语言模型基础上,继续使用任务特定、带“标准答案”的监督数据进行训练,让模型在特定任务、特定风格或特定行为上表现得更稳定、更符合预期。
你可以把它理解成“专业化教育”的过程:
-
在预训练(Pre-training)阶段像是打基础:让模型学会语言、语法、常识与通用表达能力(类似学会阅读与写作的基本功)。
-
而在有监督微调(SFT)阶段像是定向训练:教模型掌握某一种明确的技能、遵循某套行为规范,并在具体场景中持续输出一致的结果(类似学会写论文、做客服、写代码、回答考试题等)。

总的来说,SFT 的核心在于我们并不是从零开始“教模型新知识”,而是让它学会以新的方式使用它已经学到的知识。预训练模型往往已经具备强大的语言理解能力与大量事实信息,但它并不一定天然知道——在某个具体应用里,应该用怎样的格式回答、怎样组织推理、怎样遵循规则、怎样保持语气一致。因此 SFT 要做的,就是把模型的通用能力“聚焦”到你的目标模式上。
微调为什么有效
SFT 之所以有效,本质原因是它复用了预训练阶段学到的丰富表征,只需要相对少得多的数据与算力,就能显著改变模型的输出行为。用更工程化的话讲就是预训练提供“能力底座”,SFT 则在这个底座上对“输出策略”进行定向校准。就比如我们前面在模型训练时提到的指令微调,其核心目的就是通过设置对话格式让模型学习到像人类一样的一问一答。
以 SmolLM3 为例,它的“指令跟随能力”并不是凭空出现的,而是来自一套多阶段的后训练流程:
- 基础模型(Base):在约 11T 级别的通用文本 token 上训练得到(SmolLM3-3B-Base)
- SFT 训练:使用精选的指令/对话数据集(例如 SmolTalk2 等)进行监督微调
- 偏好对齐(Preference Alignment):通过诸如 APO(Anchored Preference Optimization)等方法进一步优化输出质量与偏好一致性
在训练过程中,模型“做的事情”其实并没有变:它始终只是在完成同一件事——根据已有上下文去预测下一个 token。变化的不是训练机制,而是我们喂给它的数据分布:相较于预训练阶段的海量通用语料,SFT 提供的是更任务化、更结构化、带明确目标输出的监督样本。
因此,模型依然会沿用相同的优化路径:通过梯度下降去最小化“目标输出”与“模型预测”之间的损失(通常是交叉熵损失),让参数在一次次更新中逐步调整。最终会让模型的输出概率分布会越来越偏向训练数据所呈现的那种理想回答方式——更符合指定的任务模式、表达风格与格式约束。
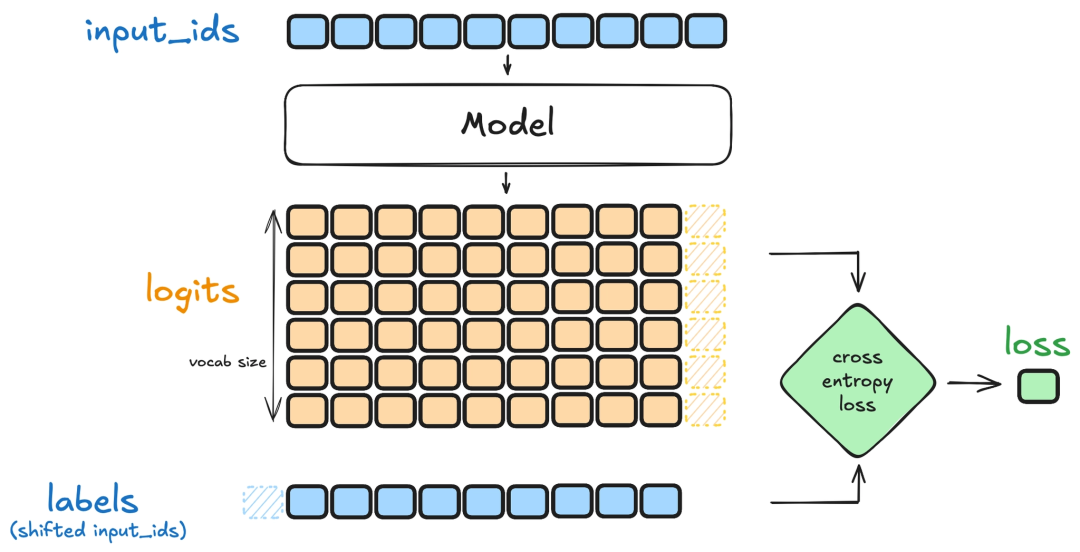
更具体地说,SFT 主要通过以下几个机制起作用:
1. 行为适应(Behavior Adaptation)
模型逐步学会识别“指令模式”并做出恰当反应,包括:
- 看到“请总结/请改写/请按表格输出”,就能更稳定地按要求组织内容;
- 更敏感于上下文中的约束(长度、语气、格式、角色);
- 输出分布会倾向于训练数据中的回答风格(比如更简洁、更结构化、更礼貌、更专业等)。
一些研究观点认为,指令微调对模型影响更明显的是“表层行为方式”(如何回答、以什么格式回答、按什么语气回答),而不是把模型底层知识体系彻底改写。你可以把它理解为:SFT 更像是训练“行为策略”,而非重建“知识图谱”。
2. 任务专业化(Task Specialization)
SFT 的价值往往不在于教模型全新概念,而在于让模型学会在特定情境下,如何更恰当地调用它已有的能力。
这也是为什么 SFT 比从零训练高效得多,因为我们不是重新打造语言能力,而是在“对现有能力进行打磨与定向强化”。比如说:
- 通用模型可能“知道”很多知识,但不会按你的业务模板输出;
- 通用模型能写代码,但不一定遵循你团队的代码风格或注释规范;
- 通用模型能回答问题,但不一定能稳定地“先给结论再给依据”。
SFT 把这些“应用方式”变成模型的默认习惯。
3. 安全一致性与对齐(Safety & Alignment)
当训练数据包含安全规范与拒答示例时,模型可以学到更一致的边界策略:
- 什么该回答、什么不该回答;
- 遇到不确定信息时如何表达不确定;
- 遇到风险任务时如何提醒、如何拒绝。
这也是为什么很多“可用的指令模型”往往都经历过大规模的 SFT(再叠加偏好对齐/RLHF 等),最终呈现出更“有用、无害、诚实”的行为特征。
**所以总的来说,SFT 不主要是教新事实,而是教新的行为模式。**假如我们希望添加垂直领域的知识进入大模型中,我们应该要做的是在原本模型的基础上继续用大量的垂直数据做预训练,而非是通过给一些垂类场景的对话信息给到大模型进行 SFT。
微调前的准备流程
在真实项目里,微调并不是“先训了再说”,而应该是一个有明确目标的优化过程。一个更稳妥的做法是:**先用提示词把任务跑通,再决定是否值得进入微调。**如果我们要进行微调,一个实用的流程通常可以概括为下面 5 步:
识别任务
在开始微调之前,建议先用现成的大模型配合提示词工程(Prompt Engineering)进行验证,看看哪些任务在当前模型上已经能“基本完成”,但稳定性、格式一致性或效果质量还不够理想。
这一步的目的不是追求最终效果,而是先判断:
- 任务是否真的适合交给 LLM
- 当前问题到底是“不会做”,还是“能做但不稳定”
- 是否有必要通过改参数(SFT)来解决
也就是说,先通过提示词把任务边界摸清楚,再考虑训练,往往比一开始就微调更高效。因为微调并不是“提示词工程的升级版”,它更像是一种成本更高、但收益更稳定的方案。而且其成本不仅是算力:
- 还包括数据准备、清洗、格式化
- 训练过程调参、监控与排错
- 训练后评估、回归测试、上线部署与版本管理
如果你的需求只是“某次回答更好”,或者只是“偶尔需要某种格式”,提示词工程与 RAG 往往更划算。只有当“提示词不够稳定”、“需要模型掌握专业输出格”或“业务要求强一致性”时,SFT 才真正值得投入。所以我们需要先判断:这件事值不值得让模型“改参数”。
评估任务表现
那在发现了想要通过微调改进的任务后,我们就需要来对其进行进一步的评估分析,因为并不是所有任务都适合微调。实践中,最适合作为 SFT 候选的,往往是这类任务:
- 模型已经能做出大致正确的结果(≈“还行”)
- 但在稳定性、格式、风格、细节质量上仍有明显问题
- 且这些问题反复出现,仅靠提示词很难彻底解决
这类任务通常最值得投入微调,因为它们已经证明了模型具备基础能力,我们要做的不是“从零教会”,而是“把输出行为校准得更稳定、更符合业务预期”。
一个很实用的判断问题是:
“我的用例是否需要与通用对话明显不同的行为?”
如果答案是“是”,SFT 通常会有明显收益。换句话说,SFT 最擅长解决的是:**从“能用”到“好用、稳用”的那一步。**你也可以用下面清单快速判断:
[ ] 你是否已经尝试过 现成的指令模型 + 提示词工程?
[ ] 你的需求是否要求 提示词无法稳定实现的输出格式/结构?
[ ] 你的领域是否足够专业,以至于通用模型经常答不准、答不稳?
[ ] 你是否拥有足够高质量的数据(经验上至少上千条更稳)?
[ ] 你是否有足够资源做训练与评估(包括算力、时间、工程维护)?
如果大多数答案都是“是”,那么 SFT 就很值得投入;反过来,如果数据不足、需求不稳定、只是“想让它偶尔更像”,那优先考虑提示词与 RAG 往往更划算。
选择一个任务进行微调
假如同上上述方式识别出多个潜在任务后,不建议一上来就把所有需求混在一起训练。更推荐的做法是:
- 先选一个任务作为微调目标
- 明确它的输入形式、输出格式和评价标准
- 先在单任务上跑通“数据 → 训练 → 测试 → 迭代”闭环
这样做有两个好处:
- 更容易定位问题(是数据问题、参数问题,还是评估方式有问题)
- 更容易积累经验(形成可复用的微调流程模板)
尤其是入门阶段,单任务微调远比“大而全”的混合任务训练更容易成功。
收集高质量数据
确定一个目标任务后,下一步就是准备监督数据。一个常见的入门经验是先准备大约 1000 条左右的输入-输出样本对,用于启动第一次的 SFT 训练。
这里最关键的不是“凑够数量”,而是数据质量要满足一个原则:
你的训练答案,必须明显优于当前模型的默认输出。
如果训练数据本身只是“差不多还行”,那模型微调后通常也只能学到“差不多还行”的水平;而如果数据质量足够高、风格稳定、格式统一,模型就更有机会学到你真正想要的输出模式。
数据准备时尤其要关注:
- 指令与答案是否匹配
- 输出格式是否一致
- 风格是否统一
- 是否存在明显错误、噪声或重复样本过多的问题
总的来说,**微调训练的上限,往往先由数据质量决定,再由参数设置决定。**所以一定要对数据的质量进行严格的把控。
低成本验证
在项目初期,一个非常实用的策略是先用小模型做微调验证(例如我们这节课使用的 qwen3-0.6B 模型),而不是直接在大模型上投入大量算力。
原因很简单:
- 训练成本更低(显存、时间、调试成本都更低)
- 迭代速度更快(能更快验证数据与参数是否有效)
- 更适合打磨流程(数据格式、日志监控、评估方法、推理测试)
当你在小模型上已经验证出“这套数据 + 这套训练方案”确实有效,再考虑迁移到更大模型,整体成功率会高很多。这也是为什么在本节示例里,我们会先用一个小规模、可快速迭代的方案来演示完整 SFT 流程——先把链路跑通,再逐步提升数据质量与训练规模。
所以从工程实践角度看,微调并不是“有需求就上”,而是一个先验证、再筛选、再训练的过程:
提示词试跑 → 找到瓶颈任务 → 聚焦单点 → 准备高质量数据 → 小模型验证
这样的流程可以帮助我们避免两个常见问题:
- 还没明确问题就盲目开训(浪费时间和算力)
- 数据质量不足却把问题归因于“参数没调好”
也正因如此,真正高质量的 SFT 项目,核心不只是“会训练”,而是会选任务、会做数据、会评估效果。那下面就让我们一起来看看具体要怎么进行微调训练的实操吧!
微调实操流程
在正式开始基于 Transformer 的代码实操之前,我们先从整体上看一下整个训练的结构。对于一次最基础的 SFT 微调训练,通常可以拆成四个步骤:
- 环境准备:配置好英伟达显卡及 CUDA 环境,安装好 python 及 conda 环境并安装训练所需的核心依赖(如
transformers、datasets、trl、accelerate、torch等)。 - 数据准备:明确任务目标,整理并清洗训练数据,统一成训练框架可识别的格式(如
messages、prompt/completion等),并划分训练集与验证集。 - 模型训练:加载模型与分词器,设置训练参数(如学习率、batch size、max_length 等),使用
SFTTrainer启动训练并生成 checkpoint。 - 模型测试:在训练完成后,通过对话测试或任务集评测验证模型是否真的按预期变好,同时检查是否出现过拟合、复读、格式漂移或通用能力下降等问题。
本节我们会先用一个最小可运行示例把完整流程跑通,重点理解训练链路。后续再进一步优化数据与训练策略。
代码实操
环境准备
首先,我们需要提前安装好 VS Code 和 Anaconda,并配置好相关的系统环境变量。这个部分属于基础环境准备,网上教程很多,大家可以直接在 B 站搜索对应视频先完成安装与配置。
完成基础安装后,我们先创建并激活一个独立的 Conda 环境,方便后续管理依赖,避免与其他项目产生冲突:
conda create -n fine-tuning python=3.12 -yconda activate fine-tuning
接着,建议为当前环境配置国内镜像源(这里使用清华源),这样后续安装 Python 包会更稳定、更快一些:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
另外,对于大模型的推理、微调与部署这类任务来说,基本都离不开 NVIDIA GPU。本课程中的实操内容主要基于我本地的一台笔记本(R9000P,RTX 3060,6GB 显存)完成。6GB 显存虽然不算高,但通过合理设置参数,依然可以完成一些轻量级模型的训练与实验演示。当然,如果你的设备配置更高,会有更好的体验;如果是准备跟着课程完整实践,建议显存至少在 6GB 及以上。
对于希望使用 GPU 进行大模型开发的同学来说,CUDA 是绕不开的一环。虽然目前 CUDA 已经发展到 13.x 版本,但由于我这边使用的是较早期显卡,因此安装的是 CUDA 12.3。如果你还没有安装 CUDA,建议前往 NVIDIA 官网下载并安装 CUDA 12.3(例如 Windows 版本)。当然,从本课程后续依赖来看,安装 CUDA 12.1 及以上版本通常就已经够用,因为后面安装的 PyTorch 主要使用的是 cu121 对应版本。
在完成 CUDA 安装后,我们就可以在刚刚创建的 Conda 环境中安装课程所需的核心依赖库,包括 transformers、torch、huggingface_hub、accelerate 等。激活环境后,依次执行以下命令即可:
pip install transformers==5.1.0pip install huggingface_hubpip install acceleratepip install torch torchvision --index-url https://download.pytorch.org/whl/cu121Looking in indexes: https://download.pytorch.org/whl/cu121pip install trl datasets tensorboard peft
安装完成后,我们可以通过以下代码检查一下 torch 是否能够识别到 CUDA:
import torchprint("torch:", torch.__version__)print("cuda available:", torch.cuda.is_available())print("gpu:", torch.cuda.get_device_name(0) if torch.cuda.is_available() else None)
如果 cuda available 输出 True,并且能打印出显卡名称,说明环境已经准备完成。
模型与分词器准备
如果我们想用 Transformers v5 来做 SFT 训练,其实入门非常简单。最基础的训练只需要准备三样东西:
- 模型(model)
- 分词器(tokenizer)
- 训练数据(dataset)
前两项我们在前面已经讲过了:只要指定本地模型路径,用 AutoTokenizer 和 AutoModelForCausalLM 正常加载即可,例如:
from transformers import AutoTokenizer, AutoModelForCausalLMimport torchmodel_path = r"qwen"tokenizer = AutoTokenizer.from_pretrained( model_path, use_fast=True, local_files_only=True, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained( model_path, device_map="auto", dtype=torch.bfloat16, local_files_only=True, trust_remote_code=True)
这样模型和分词器就已经加载好了,准备后续的训练工作。而真正需要你花心思的,往往是第三项:训练数据。
数据准备
训练数据
在模型训练圈里常说一句话:garbage in, garbage out。意思是如果训练数据质量很差,那么训练出来的模型也大概率会很差——甚至会更糟,因为模型会把这些坏习惯“学得很牢”。
预训练阶段强调的是“量”,因为它需要让模型获得通用语言能力;但在 SFT 阶段,更重要的是“质”与“相关性”。
你的数据集必须能够清晰地展示:你希望模型在什么场景下、以什么方式、输出什么结果。
举几个更直观的例子:
- 想让模型更“日常聊天”、更像助理:就需要高质量的对话式指令数据
- 想让模型具备“律师风格”的表达:就需要贴近真实业务的法律咨询/法律文书类数据
- 想让模型模仿某个角色(例如动漫人物、小说人物):就需要你构造该角色的语气、口头禅、行为逻辑对应的训练样本
一句话总结:模型不会凭空“理解你的意图”,它只会模仿你给它看的例子。
数据集来源
那假如我们希望获取数据,大体有三条路:
- 使用公开数据集(例如 Alpaca、ShareGPT 等指令/对话数据集)
- 采集你自己的业务/本地内容(如客服对话、知识库问答、内部规范文档、历史工单)
- 用 AI 生成合成数据(用更强模型批量生成问答、扩写场景、补全边界情况)
很多项目会混合使用这三种方式的数据,比如通过公开数据打底,再通过自建数据做差异化,最后合成数据补覆盖面。这样就能够打造一个比较完善的数据集提升模型在某方面的能力。那在本节课我们主要关注的是如何快速的跑起来整个训练流程,具体采集数据方面的内容将在下节课中进行讲解。
数据集大小建议
关于数据量,一个常用的经验参考是:
- 最低要求:约 1000 条高质量样本,能支撑一次基础微调
- 更稳妥的规模:10,000+ 条样本,通常更有利于泛化与稳定性
但是数据并不是越多越好的,在准备数据集过程中,质量的优先级永远优先于数量。1000 条精心策划的数据,往往胜过 1 万条平庸样本。主要原因是模型会学习并放大训练数据中的模式——包括用词习惯、结构、语气、甚至错误与偏见。所以务必把时间投入到数据清洗、去重、格式统一和质量筛选上,这往往比“多跑几轮训练”更能提升最终效果。
数据集样式
无论你采用哪一种来源,SFT 的一条样本通常都离不开两部分:
- 输入(prompt):
user提出的指令/问题/上下文 - 输出(target):你期望
assistant给出的标准回复
也就是说,你的数据要能表达“给定这个输入,正确的输出应该长什么样”。这也是“监督式”微调的核心:有明确的目标答案可供学习。
在 TRL 的 SFTTrainer 体系里,数据并不要求你只能用一种写法。它通常支持两条主线:
- 语言建模(Language Modeling, LM):给一段完整文本,让模型学习下一个 token(最通用的方案)
- 提示词补全(Prompt-Completion):把输入(prompt)和输出(completion)分开,更贴近“指令→回答”的监督形式
同时,以上两类又各自支持 标准(Standard) 与 对话(Conversational) 两种结构。所以共计有四种预期支持的语言结构:
当你提供这种
Conversational对话数据时,SFTTrainer通常会自动对每条样本应用聊天模板(chat template),把messages转成模型真正训练用的文本格式(类似tokenizer.apply_chat_template(...)的效果),不需要我们进行额外的处理工作,因此建议 SFT 中统一使用这种格式的内容。
标准语言建模(Standard language modeling)
已经把“输入+输出”拼成了完整训练文本(例如用模板拼好的指令数据、或纯文本语料)。
{"text": "The sky is blue."}
这类数据的核心字段通常是 text(也对应 SFTConfig(dataset_text_field="text") 的默认值)。
对话语言建模(Conversational language modeling)
用多轮对话结构组织数据,模型要学会“对话格式与角色行为”。这种也被称为是通用的 chat messages 格式,我们在调用模型时传入的也是类似的格式。
{"messages": [ {"role": "user", "content": "What color is the sky?"}, {"role": "assistant", "content": "It is blue."}]}
标准提示词补全(Standard prompt-completion)
希望显式区分“输入提示”和“目标补全”,结构最直观。
{"prompt": "The sky is", "completion": " blue."}
对话提示词补全(Conversational prompt-completion)
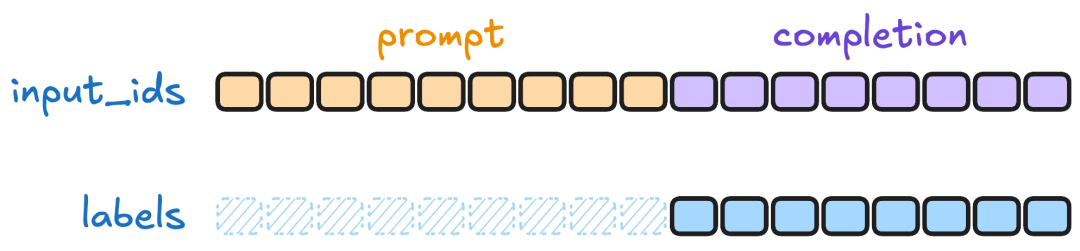
输入输出仍是对话结构,但希望“输入”和“答案”分开表示,便于只对答案算 loss 等策略(这是的 loss 就是。这种也是在 SFT 中最常见的使用类型。
{"prompt": [ {"role": "user", "content": "What color is the sky?"} ], "completion": [ {"role": "assistant", "content": "It is blue."} ]}
那相比于前面 对话语言建模 Conversational language modeling 格式,该格式最大的区别在于在训练时只在 completion(也就是答案部分)算 loss,prompt 部分会被忽略。Trainer 可以据此把非 completion 的 label 置为 -100(不计入 loss)。
而前者整段序列都会算 loss,也就是说 user 的内容、assistant 的内容(以及可能的 system)都会参与训练目标。如果使用 Conversational language modeling 格式但同时希望只有回复(assistant)部分计算 loss 的话,需要显性设置 assistant_only_loss=True,并且前提是你的 chat template 支持返回 assistant token mask(注意:qwen3-0.6B 模型的 chat template 并不支持)。
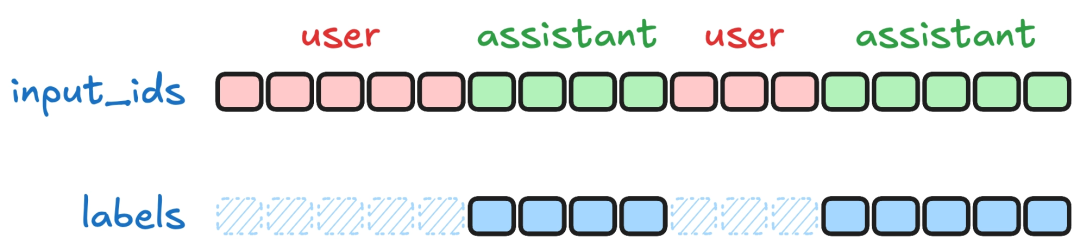
所以假如你想让模型“学会对话整体结构/多轮衔接”,甚至希望它也学到 user 侧的分布(一般不太需要),用 **Conversational language modeling 。**但是假如你只想让模型在给定输入下学会“怎么回答”,并且更稳定地对齐输出,此时应该选择用 conversational prompt-completion(更推荐)。
大部分情况下,学习 user 侧反而可能会引入噪音从而增加模型的混乱情况(学错指令模版),所以工程上更主流的是让 prompt 只作为输入内容,对于 loss 只算 assistant 的输出。
当然假如我们的数据不是这种格式,我们也可以通过预处理(map)把它转换成 SFTTrainer 认识的格式。通常做法是用 datasets.Dataset.map() 把原始字段映射为 text 或 prompt/completion 或 messages。
比如下面是针对一个医疗数据集风格该写的示例,该数据集原本的格式如下:
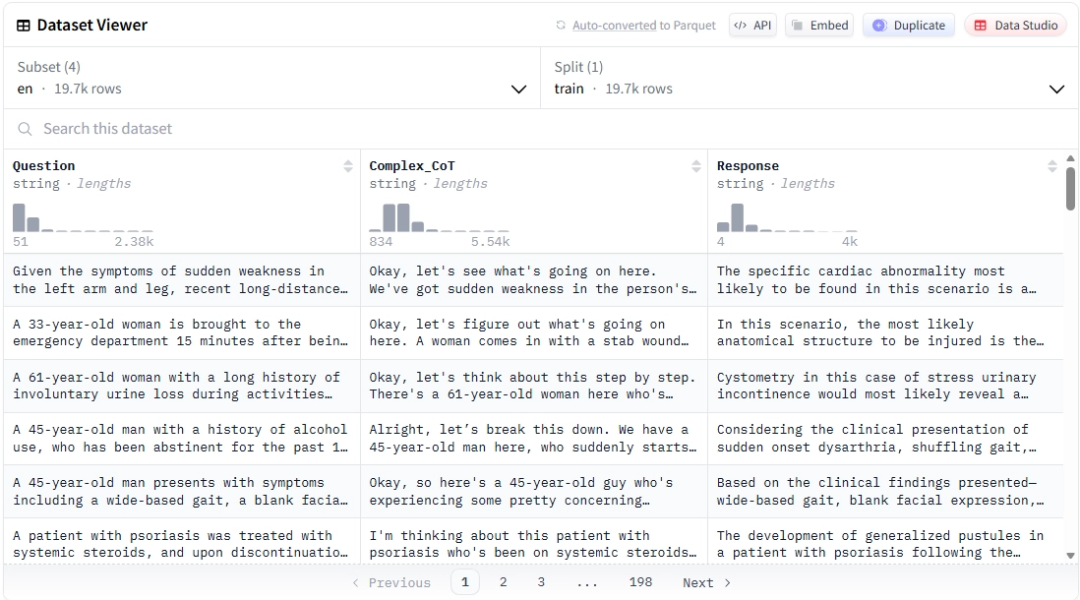
我们可以把数据集的 Question / Response / Complex_CoT 转成“对话 prompt-completion”,并把思维过程包进 <think>\n...\n</think>\n\n:
from datasets import load_datasetdataset = load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT", "en")def preprocess_function(example): return { "prompt": [ {"role": "user", "content": example["Question"]} ], "completion": [ {"role": "assistant", "content": f"<think>\n{example['Complex_CoT']}\n</think>\n\n{example['Response']}"} ], }dataset = dataset.map( preprocess_function, remove_columns=["Question", "Response", "Complex_CoT"])print(next(iter(dataset["train"])))
转化完成后,数据将会变成:
{ "prompt": [ { "content": "Given the symptoms of sudden weakness in the left arm and leg, recent long-distance travel, and the presence of swollen and tender right lower leg, what specific cardiac abnormality is most likely to be found upon further evaluation that could explain these findings?", "role": "user", } ], "completion": [ { "content": "<think>\nOkay, let's see what's going on here. We've got sudden weakness [...] clicks into place!\n</think>\n\nThe specific cardiac abnormality most likely to be found in [...] the presence of a PFO facilitating a paradoxical embolism.", "role": "assistant", } ],}
这样的数据我们就能够将其载入到模型中,并且无需手动分词即可进行训练使用。
思考能力保留
假如我们的数据集里没有思考部分的内容,我们就需要参考 ms-swift 里的 Qwen3最佳实践文档(Qwen3最佳实践 — swift 4.1.0.dev0 文档),里面介绍了如何在使用不含思维链的数据进行训练,同时保留模型的推理能力。
在这里给出了两个方案,方案 1 是我们直接在 content 里加上思考标签 <think>\n\n</think>\n\n ,但是我们需要手动将这部分的 mask 设为 -100,这样可以忽略对这部分的损失计算了。
{"messages": [ {"role": "user", "content": "Where is the capital of Zhejiang?"}, {"role": "assistant", "content": "<think>\n\n</think>\n\nThe capital of Zhejiang is Hangzhou."}]}
当然大家可能会觉得既然都要设为 -100 了,那干嘛不直接放到 user 里面呢。其实那更是本末倒置,因为假如放到 user 里的话,模型就会认为思考是提问时候要做的事情,而不是在输出时候要做的事情,那后面就更不会思考的。所以我们也能看到在关闭思考模式后,其也是在 assistant 之后先输出思考标签的。
<|im_start|>assistant<think></think>
除了这种将 mask 设为 -100 的方式来不计算 loss 以外,另外一种方案就是直接在数据集的查询中添加 /no_think,以避免推理能力的丧失。
{"messages": [ {"role": "user", "content": "Where is the capital of Zhejiang? /no_think"}, {"role": "assistant", "content": "<think>\n\n</think>\n\nThe capital of Zhejiang is Hangzhou."}]}
这种方式会更加简单直接一些,也不需要我们单独设置思考标签的 mask,因此后续我们将使用这种模式对模型进行微调设置。
实战数据准备
那这里为了快速演示完整的 SFT 流程,我们先不追求数据规模与多样性,而是通过构造 200 条重复样本来实现一个“最小可跑通”的示例。这样做的目的很明确——先把“数据格式 → 训练流程 → 模型输出”这条链路跑通,后面再逐步替换成真实、高质量的数据集。
任务简介
在这个小实验里,我们希望模型只“学会一件事”:当用户问到 “你是谁?” 这一类自我介绍/身份相关问题时,能够稳定输出我们指定的身份回答。你可以把它理解为一种非常典型的“输出形态/行为对齐”——并不是给模型增加新知识,而是让它在特定触发场景下形成更一致的回答习惯。
顺便提一句,类似“身份自我认知混乱”的现象在一年前的国产模型中并不少见。原因之一是很多模型会采用知识蒸馏/合成数据训练的路线,即用更强的模型批量生成高质量的指令数据,再用这些数据去训练自己的模型,以提升整体表现。但如果合成数据中混入了不一致的“身份表述”(例如回答成“我是 OpenAI/Google 训练出来的模型”之类),模型就可能把这种表达也学进去,导致在“你是谁”这类问题上出现不符合预期的回复。
而我们这里要解决的,就是把这一类回答强制对齐到我们想要的版本。
正常情况下,当我们通过推理代码询问模型你是谁时:
import torchfrom transformers import AutoTokenizer, AutoModelForCausalLMdef main(): model_path = r"qwen" tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path=model_path, use_fast=True,local_files_only=True) model = AutoModelForCausalLM.from_pretrained( pretrained_model_name_or_path=model_path, trust_remote_code=True, device_map="auto", dtype=torch.float16, ) user_prompt = '''你是谁?''' messages = [{"role": "user", "content": user_prompt}] # 关键:用 Qwen3 的 chat template 生成“模型真正想要的输入文本” text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True, enable_thinking=False, # 先关闭 thinking,输出更直接 ) inputs = tokenizer([text], return_tensors="pt").to(model.device) generated = model.generate( **inputs, max_new_tokens=200, ) # 关键:只取新生成的部分(不把 prompt 原样打印出来) new_tokens = generated[0][inputs["input_ids"].shape[1]:] answer = tokenizer.decode(new_tokens, skip_special_tokens=True).strip() print("\n=== 模型回答 ===") print(answer)if __name__ == "__main__": main()
其回复会是以下内容:
=== 模型回答 ===我是你的AI助手,名字叫小安。我是由阿里巴巴集团旗下的阿里云开发的智能助手,专注于为您提供帮助和支持。如果您有任何问题或需要帮助,请随时告诉我!
但我希望改造后模型能够做到,当用户问你是谁时,不要回答“我是阿里开发的模型”,而是回答:
“我是李剑锋,一个专注于大模型微调与部署的 AI 老师。”
数据生成
因此,我们通过 for 循环重复 200 次这样的对话对,每条都是**对话提示词补全(Conversational prompt-completion)**的对话结构(这里我们先不添加思考标签,后面运用真实的数据集时再进行添加):
import jsonN = 200out_path = r"identity_200_repeat.jsonl"sample = { "prompt": [ {"role": "user", "content": "你是谁? /no_think"} ], "completion": [ {"role": "assistant", "content": "<think>\n\n</think>\n\n我是李剑锋,一个专注于大模型微调与部署的AI老师。"} ]}with open(out_path, "w", encoding="utf-8") as f: for _ in range(N): f.write(json.dumps(sample, ensure_ascii=False) + "\n")print(f"✅ 写入完成:{out_path}({N} 条)")
运行完成后,你会在当前目录下看到一个名为 identity_200_repeat.jsonl 的文件。它采用的是 JSON Lines(jsonl) 格式,一行就是一条样本,非常适合用于大规模训练数据的存储与流式读取。
打开文件后,你会看到内容大致如下(这里只展示前几行):
{"prompt": [{"role": "user", "content": "你是谁? /no_think"}], "completion": [{"role": "assistant", "content": "<think>\n\n</think>\n\n我是李剑锋,一个专注于大模型微调与部署的AI老师。"}]}{"prompt": [{"role": "user", "content": "你是谁? /no_think"}], "completion": [{"role": "assistant", "content": "<think>\n\n</think>\n\n我是李剑锋,一个专注于大模型微调与部署的AI老师。"}]}
然后我们就可以通过 datasets 库中的 load_dataset 将这部分数据进行载入:
dataset = load_dataset("json", data_files=data_path, split="train")
这里也稍微拓展一下 load_dataset 的部分参数及使用方式,除了 json 外,我们还可以写入其他格式的内容,包括:
| 数据格式 | 载入命令 | 例子 |
|---|---|---|
| CSV 和 TSV 文件 | csv |
load_dataset("csv", data_files="my_file.csv") |
| 文本文件(Text files) | text |
load_dataset("text", data_files="my_file.txt") |
| JSON 和 JSON Lines 文件 | json |
load_dataset("json", data_files="my_file.jsonl") |
| Pickle 格式的 DataFrame(序列化表格数据) | pandas |
load_dataset("pandas", data_files="my_dataframe.pkl") |
假如我们的数据太大,我们可以开启流式载入模型,即通过参数 streaming=True 进行开启。这样就不会一次性将所有文件载入内存当中了。
数据划分
另外,我们通常不会把所有数据都拿去训练,因为那样你很难判断模型到底有没有学到“可泛化的规律”,还是只是把训练样本背下来了。
所以更标准的做法是:把数据划分为两部分:
- train(训练集):用于反向传播更新参数
- test / eval(验证集):训练过程中定期评估,用来观察 loss 是否下降、是否过拟合
在 datasets 里,我们可以用一行代码完成切分:
# 90% 训练集 + 10% 验证集(可复现:固定 seed)ds = dataset.train_test_split(test_size=0.1, seed=42)
这里几个点你需要知道:
test_size=0.1:表示把 10% 的样本划给验证集;你也可以用0.2(80/20)等比例。seed=42:固定随机种子,保证每次切分结果一致,方便复现实验和对比不同超参数。train_test_split返回的是一个DatasetDict,包含两个键:
ds["train"]:训练集ds["test"]:验证集(很多训练脚本也会把它命名为eval)
除了传入单一文件以外,我们也可以自行切分并将训练集和测试集载入,比如:
url = "https://github.com/crux82/squad-it/raw/master/"data_files = { "train": url + "SQuAD_it-train.json.gz", "test": url + "SQuAD_it-test.json.gz",}squad_it_dataset = load_dataset("json", data_files=data_files, **field="data"**)
接下来我们就能够单独获取这两部分数据,并在模型训练时单独传入即可,后续我们就能在训练过程中看到 eval loss:
train_ds = ds["train"]eval_ds = ds["test"]
到这里为止,模型(model)、分词器(tokenizer)和训练数据(dataset)三样核心材料就都准备好了。接下来,我们就可以进入下一步,即设置训练超参数(SFTConfig)并启动训练(SFTTrainer)。
训练参数
什么是训练参数
在真正开始 SFT 之前,我们需要先设置一组**训练参数(Training Hyperparameters)**后才能正式开始训练。
你可以把它理解为:在训练开始前,我们要提前告诉训练系统——
- 一次喂多少数据给模型?
- 模型每次更新走多大一步?
- 训练跑多久、多久保存一次?
- 为了防止训练“发散/炸掉”,要不要做稳定性控制?
- 训练过程要不要记录日志、怎么监控效果?
这些参数不会改变模型的结构(比如 Transformer 层数、隐藏维度等),而是决定了模型在训练时的学习节奏、训练强度、资源消耗、以及结果稳定性。它们通常也被称为“超参数”。
那很多时候大模型训练师也被戏称为调参师,这里的调参可不是真正进入模型本身的参数中进行调整,毕竟几个 Billion 的参数可不是碳基人类可以调整的。这里所谓的调参调的其实就是这些超参数,我们通过不断尝试合适超参数来控制模型内部的参数变化从而训练出更好用的模型。
为什么训练参数这么重要
同一份数据、同一个模型,只要训练参数不同,结果可能截然相反:
- 学习率太大:模型可能直接“学崩”,loss 变 NaN,或者输出质量明显变差
- 学习率太小:训练半天几乎没变化,看起来像“没学到”
- 训练轮数太多:模型容易过拟合,变成复读机(尤其数据重复时)
- 训练轮数太少:模型学习不到知识,没有发生任何改变
- batch 太小:训练不稳定、波动大
- batch 太大:更稳但更吃显存
- 序列长度太短:关键信息被截断,模型学不到完整模板
所以说,**训练参数本质上是在“稳定性、效果、成本”之间做平衡。**你要在有限资源下,让训练既跑得动、又不爆炸、最后还学得像样。
但当然,即便再怎么调参,假如训练的数据不够好的话还是不行的,数据的质量才是决定模型上线的最关键因素。比如一份 80 分的数据集,调参好的话可能把模型的上限拉到 95 甚至 100 分。但假如面对的是一份 30 分的数据集,此时即便再怎么调参最多也就是拉到 40 分,这 40 分和即便调参不好的 80 分的模型还是差距有一倍之多。因此我们一定要确保训练数据集的质量,而不是仅仅考虑如何调参的问题。在下一章节我们也会来讲述一下到底什么样的数据是好的,什么样的数据是坏的。
常见的训练参数
那下面我们就正式来看看常见的训练参数有哪些以及具体如何来进行使用。常见的训练参数包括:
学习率相关参数: learning_rate/wramup_steps/lr_scheduler_type
学习率在训练过程中最重要的参数,其代表每一次模型参数更新时变化的幅度大小。比如在优化器(如 AdamW)里,学习率基本决定了训练的“步伐大小”。
前面也提到,假如学习率太大,虽然收敛更快,但也更容易震荡、发散或出现“训练不稳定”(loss 上下乱跳)。而学习率太低的话可能会出现直到训练结束都没有收敛,出现欠拟合的状态。那适中的学习率可以让 loss 逐步下降,并在训练结束前达到收敛的状态,这个就是训练中最理想的状态。
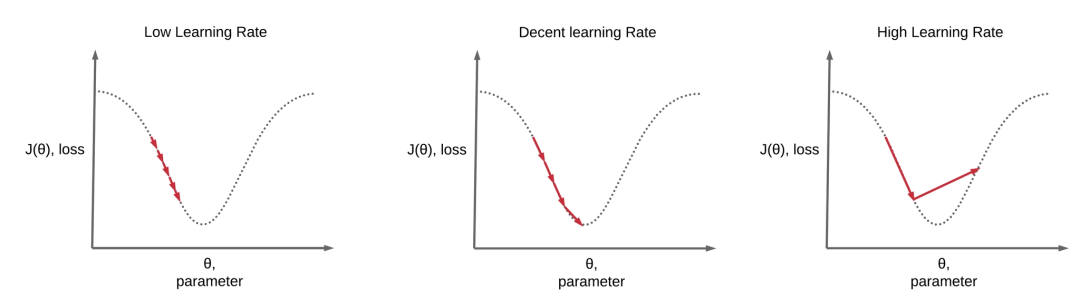
那学习率的话具体在多少合适呢?这个其实没有准确的值,是要根据模型规模、数据质量、batch 规模来具体进行判定的。但是根据很多研究人员训练的经验而言,一般对于 SFT 任务而言,Huggingface 官方推荐学习率在 5e-5 到 1e-4 之间是比较合适的。
# 平缓 (更稳定,但更慢)learning_rate = 5e-5# 推荐(平衡的选择)learning_rate = 1e-4# 激进(更快,但不稳定)learning_rate = 2e-4
但对于学习率而言,并非在完整的训练过程中都是一成不变的。更常见、也更稳妥的做法是:让学习率在训练过程中“先升后降”。你可以把它理解成学习的节奏:
- 前期:先从很小的学习率开始(避免一上来就把模型“推乱”)
- 中期:逐步升到一个峰值(也就是你设置的
learning_rate)(进入高效学习阶段) - 后期:再慢慢下降(让模型用更小的步伐做“精修”,更容易收敛稳定)
这条“先升后降”的曲线,主要由两个参数共同决定:
-
热身:
warmup_stepswarmup_steps的作用是规定:训练开始的前一段时间里,学习率不要直接用到最大值,而是从接近 0 慢慢升上去。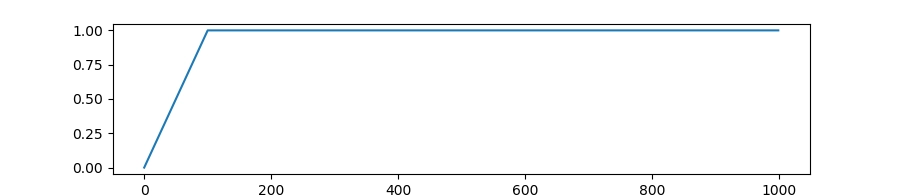
在 Transformers V5 后,
warmup_steps有两种常见写法:对于新手来说,用“按比例热身”通常更方便。因为即便你换了数据量、训练轮数后,热身长度也会自动跟着变,不用手动重新算。
-
写整数(固定步数热身)
例如
warmup_steps=100:表示前 100 次参数更新(steps)用于热身。 -
写小数(按比例热身)
例如
warmup_steps=0.03:表示用“总训练 steps 的 3%”作为热身。
-
调度器类型:
lr_scheduler_type当学习率在 warmup 结束后升到峰值(也就是你设定的
learning_rate)之后,接下来怎么变化,就由lr_scheduler_type决定。对 SFT 来说,最常见的目标是让学习率从峰值开始逐渐下降,这样训练后期更新会更细腻,更容易把模型“收敛到稳定状态”。入门最常用的两种类型是:
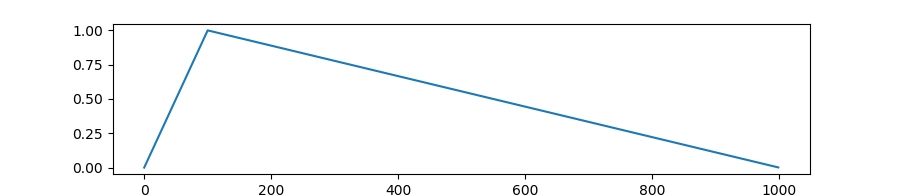
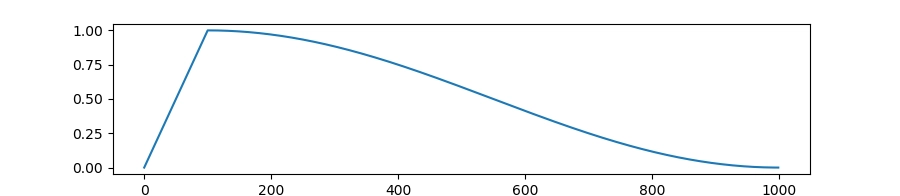
-
曲线形状:warmup 上升到峰值 → 然后按余弦形状下降(一般是中期下降更慢,后期下降更明显)
-
可以理解为中期还能保持一点“学习劲头”,最后再明显减速收敛。比如适合觉得 linear 后期下降太快、模型后期学不动时。
-
曲线形状:warmup 上升到峰值 → 然后匀速下降到训练结束
-
可以理解为后面每一步都走得越来越小,模型更容易稳定下来。毕竟适合新手默认配置、想要稳定不出意外。
-
cosine:余弦下降 -
linear:线性下降
批次与梯度相关参数(per_device_train_batch_size / gradient_accumulation_steps/dataloader_drop_last/gradient_checkpointing)
在训练大模型时,我们不会把整个数据集一次性塞进 GPU,因为数据通常很大、显存也不够。所以训练会采用一种“分批喂数据”的方式,这就是 batch(小批量)训练。
而 per_device_train_batch_size 这个参数每张 GPU(每个设备)在每一步(每次处理一个 batch)里,喂给模型的样本数量(数据集里的一条数据就是一个样本)。这个超参数值设置得越大,就意味着说每一步需要消耗的 GPU 显存就会更多,因此在 GPU 有限的情况下,这个值应该被设置得比较小,比如就设置为 1 。
比如说如果你有 10 条样本,batch_size=2,那么会被分成 5 个 batch:
- 第 1 批:2 条样本
- 第 2 批:2 条样本
- ……
- 第 5 批:2 条样本
那在训练时,每处理完一个 batch,就完成了一次“训练步骤”,也叫一个 Step(很多资料也叫 iteration)。前面提到的 wramup_steps 里的 step 就是这个含义。这一步通常包含:
- 前向传播(模型算输出)
- 计算损失(loss)
- 反向传播(算梯度)
但是 per_device_train_batch_size 这里表示的是一张 GPU 一步中处理的样本数量。
如果你用多张 GPU 训练,每张卡都会各自处理一批样本:
- 比如 GPU 数量为 2
per_device_train_batch_size = 2
那么“一步里全局实际处理的样本数”(全局 batch)大约是 2*2 = 4 条样本。所以假如我们总共只有 10 条数据,那么我们只需要 2.5 步就能完成一次完整的训练。而这样一次完整的训练往往被我们称为是一轮(epoch)训练。
但是有时由于 batch 太大显存不够,我们会“先不更新参数”,而选择连续处理多个 batch,把梯度先攒起来,等攒够了再更新一次参数。那具体多少批才进行一次更新,这个就由 gradient_accumulation_steps 的值所决定。
比如此时:
gradient_accumulation_steps = 4per_device_train_batch_size = 2- GPU 数量为 1
那么就意味着每次实际处理 2*4*1=8 条样本后,模型才会进行一次参数的更新。假如我们总共就只有 10 条数据的话,那就意味着数据总共被切成 5 个 batch,并且每处理 4 个 batch 才做 1 次参数更新。但由于还剩下一个 batch,所以最后两条数据还会再进行一次参数更新。
假如我们不想剩下的这几条数据被训练到的话,我们可以设置一个超参数 dataloader_drop_last=True ,那么这多出来的两条数据就不会被训练到了。不过一般情况下没有必要去对其进行丢弃,除非是对于内核加速或者 GPU 使用率上的考虑,所以这个参数很多时候是不需要进行设置的。
不过对于 gradient_accumulation_steps 这个超参数而言,就算我们将其设置为 1 ,即每一步都进行更新,理论上其并不会增加显存的需求。因为即便累计了梯度值,其也只是进行一次更新。
因此 gradient_accumulation_steps 超参数主要影响的是整体的训练时长。假如设置得越少,那么所需要花费的时间就越多。假如我们累计一段时间再更新梯度,那么肯定所花费的时间越少。而 per_device_train_batch_size 这个参数由于决定一次传给显卡的数据数量,因此其决定的就是显存使用的大小。对此,Huggingface 官方针对显存和训练时长的情况给了以下的推荐:
# 显存有限per_device_train_batch_size = 2gradient_accumulation_steps = 8# 显存足够per_device_train_batch_size = 4gradient_accumulation_steps = 4# 非常多显存per_device_train_batch_size = 8gradient_accumulation_steps = 2
但是需要注意的是,并不是说参数越频繁更新,模型效果越好。假如数据本身存在着一些噪音,那么梯度方差可能会更大。从而导致:
- loss 更容易抖动
- 更容易出现训练不稳定
- 有时会导致模型“学到奇怪的东西”(尤其数据噪声大时)
这就是为什么很多配方会用梯度累计来“凑一个更大的有效 batch”。所以假如你的 per_device_train_batch_size 已经不小(比如 8、16…),同时数据质量高、噪声小,并且学习率设置得比较保守的情况下,可以考虑每步都进行更新,但其他情况下尽量还是使用 8 或 16 这种更稳定的量级进行参数的更新。
序列长度相关参数(max_length/packing/packing_strategy)
在训练大模型前,所有文本都会先经过 tokenizer 变成一串 token(可以理解为“文本被切成的更小单位”)。模型训练时读的不是“字符/句子”,而是这串 token。
max_length 这个超参数的作用就是规定“每条训练样本最多允许有多少个 token”。换句话说就是模型一次最多看多长的内容。
之所以要限制长度,是因为现实的数据长度是参差不齐的。有的样本很短(几十个 token),而有的样本很长(几千甚至上万个 token)。
如果不限制长度,训练会遇到两个直接问题:
- 显存爆炸:序列越长,模型中间计算越多,显存占用会迅速上升
- 训练效率很低:为了照顾极少数超长样本,整体训练会被拖慢
所以训练时通常会设置一个上限 max_length,让所有样本统一在一个可控范围内。那在实际操作过程中,当一条样本 token 数超过 max_length 时,就会将超出的部分进行裁掉(截断默认一般是“从右侧截断”),也就是保留前面、砍掉后面的内容。
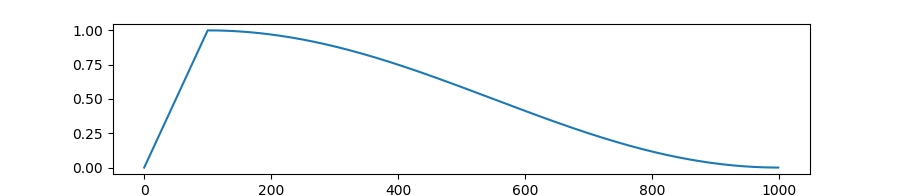
但是当一条样本 token 数不足 max_length 时,会对该样本进行填充(padding),即在后面补一些 pad token,让长度对齐。当然这些 padding 部分的内容是会把 label 设置为 -100 从而不参与 loss 的计算 (和前面提到的只计算 assistant 部分的 loss而不计算 user 部分是一样的)。
所以你可以把 max_length 理解成喂给模型的每条样本,最终都会被处理成不超过 max_length 的 token 序列。
那大家可以想象一下,max_length 的值对什么有决定性的影响呢?显然是对显存有很大的影响,因为假如 max_length 越大,每个样本的长度就越长,对应的每个 batch 里包含的 token 数量就越多,那肯定会导致显存占用量越大,训练速度越慢。但其优点在于模型能看到更长的上下文,因此更适合长指令、多轮对话、长文档类数据。
假设一条训练样本的内容是:
用户问:你是谁?
助手答:……(后面还有很多解释与例子)
如果你设置的 max_length 很小
那么可能出现的情况是,助手回答的后半段被截断了,模型训练时根本看不到后半段,自然也学不到“回答应该完整输出”的模式。
相反如果,你设置的 max_length 足够大。那么模型就能把“完整回答”都看到,训练目标更完整。因而训练效果会更好。
那具体 max_length 的值要怎么选,主要是看数据集的具体情况。比如我这里测试用的数据集就很短,那就用 128 就够用了。但假如是真实数据集的话,假如对话普遍比较短,512 或 1024 往往都够用。但假如是多轮对话/长指令的话,可以考虑 1024 ~ 2048 。如果你不确定的话,先从 512 或 1024 开始,能跑通再根据数据长度分布往上调。
当然,max_length 不是越大越好,而是“够用就好”,因为太大加了太多 padding 的内容也对训练没有帮助的。比如同一个 batch 里:
- A 样本 50 token
- B 样本 400 token
- 你设定
max_length=512
那短的那条会被补很多 padding(补到接近 400 或 512)。虽然 padding 的 token 对学习内容几乎没帮助,但它们依然会参与计算,造成显存浪费、速度变慢、GPU 利用率下降等问题。换句话说,短样本越多,这个浪费越严重。
基于这个问题,很多开发者想出了一个方法,那就是既然很多样本都很短,那我干脆把几条短样本“拼起来”,让它们一起占满一条长度为 max_length 的训练序列。
也就是把原来这样的一条条短序列:
- 样本1(80 token)
- 样本2(120 token)
- 样本3(60 token)
- 样本4(200 token)
拼成更接近固定长度的 block,比如 max_length=512:
- block1:样本1 + 样本2 + 样本3 + …(凑到接近 512)
- block2:继续用后面的样本凑到接近 512
这样就减少了 padding。这个方法也被成为是 packing(拼接)。
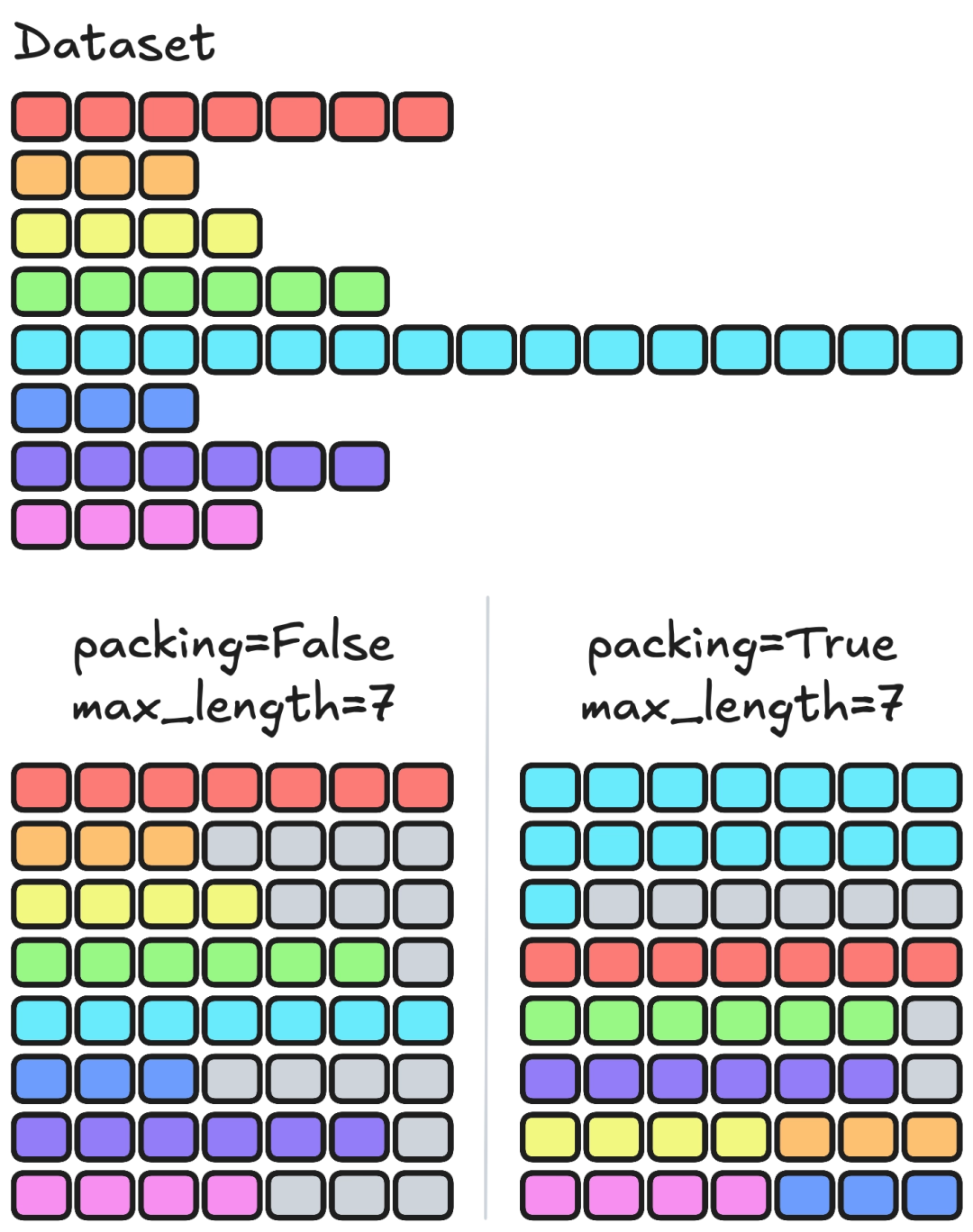
在关闭时(packing=False):
- 一条样本 = 一条训练序列
- 长度不够就 padding
- 超过就 truncate(截断)
而在开启时(packing=True):
- 多条样本 = 拼成一条训练序列(block)
- 每个 block 的长度通常就是你设置的
max_length - 训练时模型看到的是“拼接后的长序列”
所以我们可以把它理解为数据从“按条训练”变成“按块训练”。
这个方法的好处非常直观,那就是节省显存以及GPU 利用率更高(因为 padding 少了,等于少做很多无用计算)。但是开启了 packing 也有一些风险,那就是拼接之后,模型可能看到的是样本A的结尾 + 样本B的开头。如果你没有在样本之间放好“分隔符”(比如 eos token),模型可能会学到一些奇怪的跨样本连接。
并且如果你的任务非常依赖“每条样本独立、边界严格”,packing 可能会让训练目标变得不够纯净。但对大多数 SFT(尤其是短指令、短对话),packing 通常是收益大于代价的。
那在可设置的超参数中,我们其实可以通过 packing_strategy 选择 packing 的方法,包括:
bfd:Best-Fit Decreasing(默认,边界友好)wrapped:Wrapped packing(更激进,效率优先)
我们可以通过一个直观的例子来理解一下两者的差异:
假设 max_length=10(为了演示简单),有三条样本 token 长度分别是:
- A:6
- B:6
- C:4
假如使用 bfd 策略的话:
- block1:A(6) + C(4) → 正好 10(不切样本)
- block2:B(6) + padding(4)
其特点是尽量整条放进去,不拆开。
而假如用 wrapped 策略的话:
- block1:A(6) + B 的前 4(4) → 10
- block2:B 的剩 2(2) + C(4) + padding(4)
从这个例子中就可以看出,为了填满 block,B 被拆开了。
这就是两者本质差异,bfd 更尊重“样本完整性”,wrapped 更追求“块填满效率”。一般情况下,我们还会选择 bfd 方法作为首选项。
梯度检查点(gradient_checkpointing)
除了 max_length 和 per_device_train_batch_size 对显存有非常大的影响以外,**梯度检查点(gradient_checkpointing)**也是一个重要的影响因素。
前面我们提到了,训练时每一步通常是:
- 前向传播(forward):算出输出和 loss
- 反向传播(backward):根据 loss 计算梯度,更新参数
而这里的关键点在于,反向传播要算梯度,需要用到前向传播过程中的很多中间结果(可以理解为“每一层的中间输出”)。假如不开启该参数 gradient_checkpointing = False ,前向时把这些中间结果都存到显存里,反向时直接拿来用。这种方法速度快,但显存占用大。
而假如开启 gradient_checkpointing = True ,前向时不把所有中间结果都存下来,只存少量“检查点”;反向时如果缺中间结果,就再把那一段前向重新算一遍(recompute),这样显存会节省很多,但训练更慢(因为不需要把所有前向的参数都保存起来)。
所以可以理解为省显存的代价就是反向传播要“补算”一部分前向。
那具体能够节省多少也说不准,主要取决于模型结构、序列长度、batch 等。但从经验上看:
- 显存通常能省一大截(尤其在长序列、batch 稍大时很明显)
- 速度会变慢(因为多算了前向),常见是慢个 10%~30% 甚至更多
因此假如在显存有限的情况下,建议开启该参数进行训练。但假如显存足够或时间有限的话,可以选择关闭该参数。
训练轮数/步数(num_train_epochs/max_steps)
训练的本质是:模型反复“看数据 → 算 loss → 更新参数”。那么一个最自然的问题就是**要训练多久才停?**这个问题的答案取决于两个超参数 num_train_epochs 和 max_steps 。
-
num_train_epochs:训练“几轮”(把数据看几遍)num_train_epochs=E的意思是把整个训练集从头到尾完整训练 E 遍,比如:从这里可以看出 epoch 越大,模型越有机会把训练集学透,但也更容易过拟合(只懂得回复这一句话,其他知识都不理解了),从而导致输出更像“背答案”,泛化变差。但假如训练轮数太少的话,可能 loss 没办法降低太多,模型出现欠拟合的情况。当然这也和学习率有密不可分的关系,两者需要相辅相成才能取得比较好的训练结果。
一般而言,epoch 的值大概在 1-3 左右,对于 SFT 任务而言,数据往往重复度高(模板化、类似指令很多),多跑很容易过拟合到“套路回答”,并且训练目标往往是行为对齐/格式对齐,不是学新知识,因此
epoch=1便已足够。而对于预训练任务而言,一个 epoch 可能无法让模型理解内部的结构和原理,因此可能要 2-3 个 epoch 才足够。当然具体还是要看 loss 下降情况而定。
E=1:数据集看 1 遍E=3:数据集看 3 遍(更容易把训练集“记牢”)
-
max_steps:训练“多少次参数更新”(按更新次数停)max_steps=S的意思是**最多做 S 次“参数更新”(optimizer step)后就停止训练。**不过这里的 step 通常指 optimizer step(真正更新参数那一步),而不是“处理一个 batch”的 iteration。所以可以认为 **max_steps 更像一个精确的“训练时长计数器”,**到点就停,不管你数据集有多大。这对于我们想要精确控制训练时长的任务而言非常重要。
另外,假如同时设置了
num_train_epochs和max_steps的话,训练时会以max_steps为准。但一般情况下尽量二选一而不是两个都进行选择。
训练过程相关参数(logging_strategy / logging_steps/ report_to / eval_strategy / eval_steps)
训练并不是“丢进去跑完就行”,更重要的是训练过程中我们要能看见模型在发生什么,例如 loss 有没有下降、学习率曲线是否正常、有没有梯度爆炸、以及验证集效果是否开始变差(过拟合信号)。
因此,训练框架提供了一组“过程监控”参数,用来控制:什么时候记录日志、把日志输出到哪里、什么时候做验证评估。
-
logging_strategy:按什么节奏记录训练日志logging_strategy决定 Trainer 以哪种频率/时机去记录训练过程指标(loss、learning_rate、grad_norm 等),常见取值包括:这里的 step 一般指 optimizer step(参数更新步)。也就是说,如果你开了
gradient_accumulation_steps,那么日志并不是每条数据都打一次,而是每次“真正更新参数”时才算一步。对初学者来说,
logging_strategy="steps"最直观,因为你能持续看到 loss 的走势,从而判断训练是否正常。
"steps":按步数记录(最常用)"epoch":每个 epoch 结束时记录一次"no":不记录
-
logging_steps:每隔多少个 step 记录一次当
logging_strategy="steps"时,logging_steps才会生效,它表示每隔logging_steps次参数更新,就记录一次训练日志。例如:
从训练体验上来说:
所以一般建议:
对于我们这次的训练演示而言,显然设置为 1 能够让我们更加了解训练过程,而在正式训练时建议还是减少次数。
-
演示/排错:
1~5 -
正式训练:
10~100(看总 steps 长度而定) -
logging_steps太小:日志很多,看得很细,但输出会非常密集 -
logging_steps太大:日志更干净,但你可能“看不到过程”,出了问题也不容易定位 -
logging_steps=1:每一步都记录(教学演示、排错非常清晰) -
logging_steps=10:每 10 步记录一次(更轻量,适合正式训练) -
logging_steps=100:记录更稀疏(训练很长时常用)
-
report_to:把训练日志汇报到哪里(可视化)训练日志如果只打印在控制台里,往往难以观察趋势,因此我们常把它汇报到可视化工具中。我们可以通过
report_to用来指定“汇报渠道”,常见取值包括:比如你写
report_to="tensorboard",就可以在 TensorBoard 里看到:但是使用
tensorboard之前我们需要先安装:pip install tensorboard然后设置训练日志保存的位置,这需要通过设置系统变量实现(V5.1.0 版本还支持
logging_dir参数传入输出位置,但 5.2 版本将会被移除):import osos.environ["TENSORBOARD_LOGGING_DIR"] = **"./out/runs"**# 或设置 logging_dir = "./out/runs"接下来等训练启动后,就可以在终端输入指令进行启动了:
tensorboard --logdir **./out/runs** --port 6006然后在浏览器打开
http://localhost:6006即可查阅相关训练过程数据了:
-
loss 曲线是否持续下降
-
learning_rate 是否按 warmup → 衰减正常变化
-
grad_norm 是否异常飙升(训练不稳定)
-
"tensorboard":本地最常用,曲线清晰 -
"wandb":更工程化的实验管理平台 -
"none":不汇报(只在控制台打印)
-
eval_strategy:按什么节奏做验证评估(eval)很多时候,只看训练集 loss 并不够,因为训练集 loss 下降并不代表泛化能力变强——模型可能只是更会“背训练数据”了。所以我们通常会划分出一个验证集(eval_dataset),并定期评估它的 loss 或指标。这也是为什么在最开始生成了 200 条数据后,我还通过
dataset.train_test_split按 9:1 的比例划分了训练和验证集。当然对于重复的数据怎么划分其实没有意义,但是在真实场景这个非常重要。而且很多时候不仅仅划分的是训练和验证集,还会在训练数据中再划分出来一个专门的测试集,用来真正测试模型的能力,这个具体可以查阅最后评估部分的内容。
那具体按什么策略进行验证评估就由
eval_strategy(有些版本也叫evaluation_strategy)来实现,常见取值包括:一般来说:
需要注意的是,只有当你传入了
eval_dataset时,eval 才会真的发生。不然就没有任何意义。
-
数据量小、训练步数不多:
"steps"更直观 -
数据量大、epoch 很长:
"epoch"更简单 -
"steps":每隔若干步评估一次(最常用) -
"epoch":每个 epoch 结束评估一次 -
"no":不做验证评估
-
eval_steps:每隔多少个 step 做一次 eval当
eval_strategy="steps"存在时,eval_steps才会生效,它表示每隔eval_steps次参数更新,就在验证集上跑一次评估。例如:调小/调大的影响也很直观:
对入门 SFT 来说,一个非常常见的经验是
eval_steps通常可以和save_steps设置成相同或接近。这样评估一次就保存一次,方便你回滚或选取最佳 checkpoint。
-
eval_steps小:评估更频繁,更容易捕捉过拟合开始的拐点,但评估会耗时间 -
eval_steps大:训练更快,但可能错过“最佳模型”的出现时机 -
eval_steps=25:每 25 步评估一次 -
eval_steps=100:每 100 步评估一次
保存相关参数(save_strategy / save_steps / save_total_limit)
训练大模型时,“保存”并不是可有可无的功能,而是一个非常实用的安全机制。因为训练过程中可能会遇到各种情况:
- 训练跑到一半中断(断电、显存报错、电脑休眠等)
- 想在训练中途拿一个阶段性模型出来测试效果
- 训练后期开始过拟合,希望回到更早的某个 checkpoint
因此我们通常会在训练过程中周期性地保存 checkpoint(检查点),而不是只在最后保存一次。下面这三个参数就是用来控制“何时保存、保存多频繁、最多保留多少份”的。
-
save_strategy:按什么节奏保存 checkpointsave_strategy这个超参数决定“什么时候触发保存”,常见取值包括:这里的 step 同样是 optimizer step(参数更新步)。因此如果你设置了梯度累计(
gradient_accumulation_steps),保存并不是每条数据就存一次,而是每次真正更新参数后才算一步。一般来说:
-
教学/小实验:
save_strategy="steps"更直观,能更快看到保存产物 -
训练很长:也可以用
"epoch",逻辑更简单,但粒度会更粗 -
"steps":按步数保存(最常用) -
"epoch":每个 epoch 结束保存一次 -
"no":训练过程中不保存
-
save_steps:每隔多少个 step 保存一次当
save_strategy="steps"时,save_steps才会生效,它表示每隔save_steps次参数更新,保存一个 checkpoint。例如:调小/调大带来的变化非常直观:
对入门演示来说,一个常见做法是把
save_steps设得稍微小一点(例如 5),这样我们能很快在输出目录里看到 checkpoint 文件,训练的“过程感”更强。同时,一般我们会把
save_steps和eval_steps设成相同。这样每次评估后紧接着就保存一次 checkpoint,你就能很方便地把“某次评估效果最好”的 checkpoint 直接拿出来做推理测试或作为最终模型。
-
更省空间、更快
-
但风险是中断会丢更多进度,回滚点更少
-
更安全:中断时丢失的训练进度更少
-
更容易回滚:你有更多历史 checkpoint 可选
-
但代价是写盘更频繁,训练略慢,磁盘占用会更快变大
-
save_steps更小(更频繁保存) -
save_steps更大(更少保存) -
save_steps=25:每 25 步保存一次 -
save_steps=200:每 200 步保存一次
-
save_total_limit:最多保留多少个 checkpoint(防止磁盘爆炸)如果你按 steps 保存,训练步数一长,checkpoint 数量会越来越多,占用大量磁盘空间。
此时
save_total_limit的作用就是,最多只保留最近的save_total_limit个 checkpoint,超过就自动删除更旧的。举例:
这个参数对于本地训练非常重要,因为本地磁盘空间有限,而且我们通常也不需要保留几十上百个 checkpoint。所以一般建议:
当然对于我们初次的演示,我们其实不太需要限制,因为本身保存的也比较少一些,在实际训练中为了减少容量,还是需要进行控制的。
-
流程演示/本地小实验:
save_total_limit=2~3 -
正式训练:
save_total_limit=3~10(看训练周期和磁盘容量) -
save_total_limit=2:始终只保留最近 2 个 checkpoint -
save_total_limit=5:保留最近 5 个 checkpoint -
save_total_limit=None:所有 checkpoint 都进行保存
断点续训(resume_from_checkpoint)
训练大模型时,一个非常现实的问题是:训练可能随时会被打断——比如显存 OOM、程序报错、电脑休眠/断电,或者你临时停止训练想改点参数再继续。如果每次中断都从头再跑,会非常浪费时间。
因此训练框架通常支持 断点续训(Resume Training):也就是从某个 checkpoint 继续训练,而不是重新开始。resume_from_checkpoint 就是用来控制这件事的。其具体含义是指定一个 checkpoint 路径,让训练从该 checkpoint 的状态继续往后跑。
这里“继续”的不仅是模型权重,还包括(在正常保存策略下):
- 优化器状态(optimizer state)
- 学习率调度器状态(scheduler state)
- 已训练的 step/epoch 进度
- 随机种子相关状态(部分实现)
这意味着断点续训后的训练轨迹会尽量接近“不曾中断”的连续训练。具体使用的场景包括:
- 训练中断了,想从中断处继续
- 想回到某个较早 checkpoint(比如还没过拟合的阶段)继续训练
- 想把一次长训练拆成多段跑(例如白天跑一段、晚上跑一段)
另外,断点续训要“真正续上”,关键在于 checkpoint 里是否保存了完整训练状态。
- 如果你保存的是完整 checkpoint(通常默认会包含 optimizer/scheduler),那么
resume_from_checkpoint可以无缝续训 - 但是如果你设置了只保存模型权重(例如某些场景使用
save_only_model=True或只手动save_pretrained),那就只能“加载模型继续训”,但优化器和学习率调度器会重置,严格来说不算完全的断点续训(训练轨迹会变)
具体使用的话可以在训练时的 trainer.train() 里传参:
trainer.train(resume_from_checkpoint=True)
这种情况下,开启后会自动找 output_dir 里最近的 checkpoint。但假如有指定的权重文件的话,也可以传入对应的路径:
trainer.train(resume_from_checkpoint="./output/checkpoint-500")
所以只要我们前面开启了save_strategy="steps"/"epoch" 并且训练产生了 checkpoint,训练被打断后就还是可以续上的。
实际训练参数
在介绍完一些常见的训练参数后,接下来我们来看看对于这个任务而言需要的训练参数如何。
首先我们训练参数的设置是通过 trl 库中的 SFTConfig 来进行设置的。那这里的 **TRL(Transformer Reinforcement Learning)**是 Hugging Face 生态里专门用来做“大模型后训练(post-training)”的训练库。它把我们常见的几类训练方法封装成现成的 Trainer,让你用更少的代码完成指令微调与对齐训练,比如:
- SFT(Supervised Fine-Tuning)监督微调:让模型学会按指令回答
- DPO(Direct Preference Optimization)偏好对齐:用“更喜欢哪个回答”的数据来对齐模型
- 以及更多后训练方法(官方文档概览中列有 SFT、DPO、Reward Modeling、GRPO 等)。
我们可以把 TRL 理解为**“面向大模型指令微调/对齐的一站式训练工具箱”**。其优势在于:
- 上手快:只需要简单几个设置就可以启动训练流程
- 方法全:从 SFT 到偏好对齐,所有的方法都可以使用 TRL 快速实现
- 生态整合:站在 Hugging Face 全家桶上,可以直接对接 Transformers、Datasets、Accelerate、PEFT 等库
因此下面我们也会基于 trl 库来进行进一步的讲解。
import osos.environ["TENSORBOARD_LOGGING_DIR"] = "./qwen3-0.6B-sft/runs"config = SFTConfig( output_dir="./qwen3-0.6B-sft", # 学习率相关参数 learning_rate=1e-4, warmup_steps=0.05, lr_scheduler_type="cosine", # 批次与梯度相关参数 per_device_train_batch_size=1, gradient_accumulation_steps=8, gradient_checkpointing=True, # 序列长度相关参数 max_length=128, # 训练次数 num_train_epochs=1, # 训练过程相关参数 logging_strategy="steps", logging_steps=1, report_to="tensorboard", eval_strategy="steps", eval_steps=5, # 文件保存相关参数 save_strategy="steps", save_steps=5, save_total_limit=None, )
- 在参数选择方面,首先有一个必须配置的参数是
output_dir,它决定了训练产物的保存位置。这里设置为"./qwen3-0.6B-sft”,意味着训练过程中产生的 checkpoint(如checkpoint-5、checkpoint-10等)、训练日志、以及最终导出的模型权重文件,都会统一写入当前终端路径下的qwen3-0.6B-sft文件夹中,便于后续加载模型或断点续训(resume_from_checkpoint)。 - 在学习率与调度策略方面:
learning_rate=1e-4是一个常见的 SFT 训练起点(尤其在这种“短数据+快速对齐”的小实验里,收敛会非常快)。warmup_steps=0.05:这里使用的是“小数写法”,通常表示按总训练步数的比例做热身。例如总步数约 25 步,那么 5% 热身大约就是 1~2 步,用于让学习率从很小逐步爬升到峰值,避免一上来就大步更新导致不稳定。lr_scheduler_type="cosine":在 warmup 达到峰值后,学习率会按余弦曲线逐渐下降,让训练后期步伐越来越小,更容易稳定收敛。对于这种“快速对齐、避免后期乱跑”的场景非常合适。
- 由于我们这里进行的是全参数微调,并且显卡显存有限,因此最稳妥的做法是先把单步显存占用压到最低:
per_device_train_batch_size=1:每张 GPU 每次只喂 1 条样本,单步显存压力最小;gradient_accumulation_steps=8:连续累积 8 次梯度后再更新一次参数,相当于把“有效 batch”提升到 8,从而在不显著增加显存峰值的情况下,让训练更稳定。- 在数据量为总数为 200 条左右的情况下,这组配置非常“整齐”。一个 epoch 会产生大约
200 / 8 = 25次参数更新(optimizer steps),训练进度也会更好理解。
- 除此之外,考虑到训练数据本身非常短且高度重复,我们不需要把序列长度开得很大:
-
max_length=128已经足够容纳“你是谁?→身份回答”这类短对话; -
num_train_epochs=1也足够让模型快速把这类模式“对齐”出来。同时,因为文本很短、样本结构也简单,这里可以暂时不启用 packing(默认就是
packing=False),先把训练链路跑通,后续面对大量短样本时再考虑用 packing 提升吞吐。
- 为了进一步降低显存压力并保证训练能跑起来,这里额外开启:
gradient_checkpointing=True:通过“少存激活、反向补算”的方式,用训练速度换显存空间,通常在长序列或显存紧张时非常有效。虽然会让训练慢一点,但对你这种全参且显存有限的设置来说非常值得。
- 在训练过程可视化方面,我们希望训练“过程可见”,便于教学与排错:
logging_strategy="steps"、logging_steps=1:每次参数更新都打印一次日志(loss、lr、grad_norm 等),最直观;report_to="tensorboard"并配合TENSORBOARD_LOGGING_DIR="./out/runs":训练曲线会同步写入 TensorBoard,方便我们用图像观察 loss 是否下降、学习率是否先升后降、训练是否出现异常波动。
- 同时,为了更及时地观察“训练效果是否开始过拟合”,这里开启了按步评估:
eval_strategy="steps"、eval_steps=5:表示每 5 次参数更新,就在验证集上评估一次。
- 在保存策略方面,我们让 checkpoint 更频繁地产生,方便中途验证与断点续训:
save_strategy="steps"、save_steps=5:每 5 次参数更新保存一次 checkpoint,这与前面的评估步数进行同步。save_total_limit=None:表示不限制 checkpoint 数量,训练步数少时问题不大,但如果后续训练变长,建议设为2~5,避免磁盘被大量 checkpoint 占满。
那在将这些参数设置好后,接下来我们就可以准备模型的训练了。
模型训练
训练代码
那训练的话,这里我们用的就是 trl 库中的 SFTTrainer 工具来实现的,这里我们只需要传入模型、数据集(训练和测评)及训练参数即可:
trainer = SFTTrainer( model=model, args=config, train_dataset=ds["train"], eval_dataset=ds["test"], )
然后我们最后就可以基于这个 SFTTrainer 开始训练了(由于这里不需要断点续训,所以设置为 False 即可):
trainer.train(resume_from_checkpoint=False)
完整的训练代码如下所示:
from datasets import load_datasetfrom transformers import AutoTokenizer, AutoModelForCausalLMfrom trl import SFTTrainer, SFTConfigimport torchimport os# 路径设置model_path = r"qwen"data_path = r"identity_200_repeat.jsonl"# 模型与分词器准备tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=True, local_files_only=True, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", dtype=torch.bfloat16, local_files_only=True, trust_remote_code=True)# 数据准备dataset = load_dataset("json", data_files=data_path, split="train")ds = dataset.train_test_split(test_size=0.1, seed=42)train_ds = ds["train"]eval_ds = ds["test"]# 设置过程数据路径os.environ["TENSORBOARD_LOGGING_DIR"] = "./qwen3-0.6B-sft3/runs"# 训练参数准备config = SFTConfig( output_dir="./qwen3-0.6B-sft3", # 学习率相关参数 learning_rate=2e-5, warmup_steps=0.05, lr_scheduler_type="cosine", # 批次与梯度相关参数 per_device_train_batch_size=1, gradient_accumulation_steps=8, gradient_checkpointing=True, # 序列长度相关参数 max_length=128, # 训练次数 num_train_epochs=1, # 训练过程相关参数 logging_strategy="steps", logging_steps=1, report_to="tensorboard", eval_strategy="steps", eval_steps=5, # 文件保存相关参数 save_strategy="steps", save_steps=5, save_total_limit=None, )# 加载训练配置trainer = SFTTrainer( model=model, args=config, train_dataset=ds["train"], eval_dataset=ds["test"],)# 开始模型训练trainer.train(resume_from_checkpoint=False)
训练结果文件夹解析
接下来,模型就开始在后台进行训练了。在训练完成后,模型会被保存在 ./qwen3-0.6B-sft 文件夹内,并且其运行结果也会保存在 ./qwen3-0.6B-sft/runs 文件夹中:
可以看到由于我们设置了 save_steps=5 这个超参数,因此每过五轮都会保存一次完整的模型权重文件(可以单独推理运行),然后运行结束也会保存最终的权重文章,也就是 checkpoint-23 文件夹里保存的。
之所以这里到 23 步而非正常的 200/8=25 步,是因为我们进行了数据集的划分,将 10% 的数据划分为了验证集,所以训练的数据就剩下了 200*90%=180 条,此时 180/8≈22.5≈23 步,所以总共就是进行 23 次参数的调整,在终端也可以看到对应的进度条:
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 23/23 [03:39<00:00, 9.52s/it]
当我们点开这里的 checkpoint 文件夹(如 checkpoint-23),我们就可以看到完整保存内容,包括了最重要的 model.safetensors,config.json,tokenizer.json 文件:
但在当我们与 Huggingface 上下载的原模型文件对比后,我们发现训练后的文件里多了一些内容,比如 optimizer.pt 和 scheduler.pt 文件等。主要的原因在于 Huggingface 上下载的主要是 “推理所需文件”(模型权重 + tokenizer + 配置),而训练出来的除了推理文件外,还多了“继续训练所需的状态文件”(优化器、学习率调度器、随机状态、训练状态等),因此两者会有些许的不同。
具体多出来的内容和作用如下所示:
optimizer.pt:其作用是保存优化器状态(如 AdamW 的动量、一阶/二阶矩估计等),主要目的是用于断点续训(resume training)。如果没有该文件,虽然仍然可以加载模型继续训,但优化器会重新初始化,训练轨迹会变,那么就其实和重新训练没有太大差别。scheduler.pt:其作用是保存学习率调度器状态(当前学习率走到哪一步了)。当恢复训练后,学习率可以接着之前的 warmup/cosine 曲线继续走。假如没有该文件,学习率调度会重置,可能影响收敛稳定性。rng_state.pth:其作用是保存随机数生成器状态(RNG state),从而尽可能保证断点续训后训练过程可复现(比如 shuffle、dropout 的随机性衔接)。没有这个文件的话,继续训练也能跑,但随机性轨迹会变化。trainer_state.json:其作用是保存 Trainer 的训练过程状态与历史信息,方便 Trainer 知道“当前训练进度到哪了”。其内部通常包含:
- global_step(训练到第几步)
- best_metric(如果有评估监控)
- log_history(loss/eval_loss 等日志历史)
- epoch 进度
training_args.bin:其作用是保存本次训练使用的训练参数(比如learning_rate和batch_size等),从而便于复现训练配置、排查问题。optimizer.pt、scheduler.pt:属于某一次具体训练过程的中间状态,对模型发布用户通常没必要,所以一般不会放在基础模型仓库里。
另外,训练的文件里还单独保存了一份对话模版文件(chat_template.jinja),这个其实在 hf 下载的模型也有,只不过是保存在 tokenizer_config.json 中,单独保存并不会对模型推理产生影响。
除此之外,训练的结果文件中还保存了一份 README.md 文件(系统自动生成),这份文件主要是整体性的介绍了当前训练的模型、环境以及配套内容,方便后来者复现该模型。
---library_name: transformersmodel_name: qwen3-0.6B-sft3tags:- generated_from_trainer- trl- sftlicence: license---# Model Card for qwen3-0.6B-sft3This model is a fine-tuned version of [None](https://huggingface.co/None).It has been trained using [TRL](https://github.com/huggingface/trl).## Quick start...
训练过程分析
假如我们想要了解在具体训练过程中发生了什么,可以在终端中看到大量的相关信息:
Loading weights: 100%|███████████████████████████████████████████████| 311/311 [00:02<00:00, 142.55it/s, Materializing param=model.norm.weight]The tied weights mapping and config for this model specifies to tie model.embed_tokens.weight to lm_head.weight, but both are present in the checkpoints, so we will NOT tie them. You should update the config with `tie_word_embeddings=False` to silence this warningThe tokenizer has new PAD/BOS/EOS tokens that differ from the model config and generation config. The model config and generation config were aligned accordingly, being updated with the tokenizer's values. Updated tokens: {'bos_token_id': None, 'pad_token_id': 151643}.{'loss': '3.625', 'grad_norm': '138', 'learning_rate': '0', 'entropy': '2.148', 'num_tokens': '272', 'mean_token_accuracy': '0.5217', 'epoch': '0.04444'}{'loss': '3.625', 'grad_norm': '138', 'learning_rate': '5e-05', 'entropy': '2.148', 'num_tokens': '544', 'mean_token_accuracy': '0.5217', 'epoch': '0.08889'}{'loss': '1.816', 'grad_norm': '96', 'learning_rate': '0.0001', 'entropy': '2.735', 'num_tokens': '816', 'mean_token_accuracy': '0.7391', 'epoch': '0.1333'}{'loss': '2.31', 'grad_norm': '48.25', 'learning_rate': '9.944e-05', 'entropy': '2.537', 'num_tokens': '1088', 'mean_token_accuracy': '0.8261', 'epoch': '0.1778'}{'loss': '1.078', 'grad_norm': '22.5', 'learning_rate': '9.778e-05', 'entropy': '2.754', 'num_tokens': '1360', 'mean_token_accuracy': '0.8696', 'epoch': '0.2222'}{'eval_loss': '0.3123', 'eval_runtime': '0.3733', 'eval_samples_per_second': '53.57', 'eval_steps_per_second': '8.036', 'eval_entropy': '1.719', 'eval_num_tokens': '1360', 'eval_mean_token_accuracy': '0.913', 'epoch': '0.2222'}Writing model shards: 100%|██████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:07<00:00, 7.62s/it] {'loss': '0.3165', 'grad_norm': '13.81', 'learning_rate': '9.505e-05', 'entropy': '1.724', 'num_tokens': '1632', 'mean_token_accuracy': '0.913', 'epoch': '0.2667'}{'loss': '0.1875', 'grad_norm': '25.38', 'learning_rate': '9.131e-05', 'entropy': '1.588', 'num_tokens': '1904', 'mean_token_accuracy': '0.9565', 'epoch': '0.3111'}{'loss': '0.2114', 'grad_norm': '71', 'learning_rate': '8.665e-05', 'entropy': '1.371', 'num_tokens': '2176', 'mean_token_accuracy': '0.9565', 'epoch': '0.3556'}{'loss': '0.1292', 'grad_norm': '65', 'learning_rate': '8.117e-05', 'entropy': '1.574', 'num_tokens': '2448', 'mean_token_accuracy': '0.9565', 'epoch': '0.4'}{'loss': '0.473', 'grad_norm': '39.25', 'learning_rate': '7.5e-05', 'entropy': '1.499', 'num_tokens': '2720', 'mean_token_accuracy': '0.9565', 'epoch': '0.4444'}{'eval_loss': '0.1264', 'eval_runtime': '0.3563', 'eval_samples_per_second': '56.13', 'eval_steps_per_second': '8.419', 'eval_entropy': '1.19', 'eval_num_tokens': '2720', 'eval_mean_token_accuracy': '0.9565', 'epoch': '0.4444'}Writing model shards: 100%|██████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:06<00:00, 6.10s/it] {'loss': '0.123', 'grad_norm': '34.25', 'learning_rate': '6.827e-05', 'entropy': '1.185', 'num_tokens': '2992', 'mean_token_accuracy': '0.9565', 'epoch': '0.4889'}{'loss': '0.3655', 'grad_norm': '174', 'learning_rate': '6.113e-05', 'entropy': '1.425', 'num_tokens': '3264', 'mean_token_accuracy': '0.9565', 'epoch': '0.5333'}{'loss': '0.6317', 'grad_norm': '133', 'learning_rate': '5.374e-05', 'entropy': '1.088', 'num_tokens': '3536', 'mean_token_accuracy': '0.913', 'epoch': '0.5778'}{'loss': '0.03678', 'grad_norm': '10.69', 'learning_rate': '4.626e-05', 'entropy': '1.01', 'num_tokens': '3808', 'mean_token_accuracy': '1', 'epoch': '0.6222'}{'loss': '0.006497', 'grad_norm': '1.562', 'learning_rate': '3.887e-05', 'entropy': '0.9556', 'num_tokens': '4080', 'mean_token_accuracy': '1', 'epoch': '0.6667'}{'eval_loss': '0.001295', 'eval_runtime': '0.3508', 'eval_samples_per_second': '57.02', 'eval_steps_per_second': '8.552', 'eval_entropy': '1.05', 'eval_num_tokens': '4080', 'eval_mean_token_accuracy': '1', 'epoch': '0.6667'}Writing model shards: 100%|██████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:05<00:00, 5.50s/it] {'loss': '0.001335', 'grad_norm': '0.1846', 'learning_rate': '3.173e-05', 'entropy': '1.045', 'num_tokens': '4352', 'mean_token_accuracy': '1', 'epoch': '0.7111'}{'loss': '0.0008372', 'grad_norm': '0.1377', 'learning_rate': '2.5e-05', 'entropy': '1.105', 'num_tokens': '4624', 'mean_token_accuracy': '1', 'epoch': '0.7556'}{'loss': '0.0006205', 'grad_norm': '0.1094', 'learning_rate': '1.883e-05', 'entropy': '1.108', 'num_tokens': '4896', 'mean_token_accuracy': '1', 'epoch': '0.8'}{'loss': '0.00052', 'grad_norm': '0.09229', 'learning_rate': '1.335e-05', 'entropy': '1.103', 'num_tokens': '5168', 'mean_token_accuracy': '1', 'epoch': '0.8444'}{'loss': '0.0004838', 'grad_norm': '0.08691', 'learning_rate': '8.688e-06', 'entropy': '1.094', 'num_tokens': '5440', 'mean_token_accuracy': '1', 'epoch': '0.8889'}{'eval_loss': '0.0004415', 'eval_runtime': '0.3597', 'eval_samples_per_second': '55.6', 'eval_steps_per_second': '8.341', 'eval_entropy': '1.095', 'eval_num_tokens': '5440', 'eval_mean_token_accuracy': '1', 'epoch': '0.8889'}Writing model shards: 100%|██████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:07<00:00, 7.11s/it] {'loss': '0.0004364', 'grad_norm': '0.0752', 'learning_rate': '4.952e-06', 'entropy': '1.103', 'num_tokens': '5712', 'mean_token_accuracy': '1', 'epoch': '0.9333'}{'loss': '0.0004407', 'grad_norm': '0.07666', 'learning_rate': '2.221e-06', 'entropy': '1.098', 'num_tokens': '5984', 'mean_token_accuracy': '1', 'epoch': '0.9778'}{'loss': '0.0004278', 'grad_norm': '0.07373', 'learning_rate': '5.585e-07', 'entropy': '1.103', 'num_tokens': '6120', 'mean_token_accuracy': '1', 'epoch': '1'}Writing model shards: 100%|██████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:05<00:00, 6.00s/it] {'train_runtime': '219', 'train_samples_per_second': '0.822', 'train_steps_per_second': '0.105', 'train_loss': '0.6496', 'epoch': '1'}100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 23/23 [03:39<00:00, 9.52s/it]
下面就让我们来拆解一下这训练的过程发生了什么。
模型权重加载阶段
Loading weights: 100%|███████████████████████████████████████████████| 311/311 [00:02<00:00, 142.55it/s, Materializing param=model.norm.weight]
这个对应的就是前面的 model 代码:
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", dtype=torch.bfloat16, local_files_only=True, trust_remote_code=True)
这表示模型在从 checkpoint 文件中加载参数。311/311 通常是“分片/参数组/文件块”的加载进度(不同模型/格式显示略有差异)。这一阶段做的事就是把模型权重读进内存/GPU(或按 device_map 分配到设备)。
权重绑定警告
The tied weights mapping and config for this model specifies to tie model.embed_tokens.weight to lm_head.weight, but both are present in the checkpoints, so we will NOT tie them. You should update the config with `tie_word_embeddings=False` to silence this warning
这里其实出现了两个 Warning,第一个是关于权重共享的警告。主要原因是很多因果语言模型(CasualLM)会选择把:
- 输入 embedding:
model.embed_tokens.weight - 输出层(lm_head)的权重:
lm_head.weight
做“权重共享(tie weights)”,这样参数更少、训练更稳定一些。
但你这里的 checkpoint 里 两份权重都单独存在,而 config 里可能写着“应该 tie”。Transformers 检测到这种不一致后选择不强行 tie,并提示你把 config 改成 tie_word_embeddings=False 来消除告警。这个修改起来比较麻烦,需要在创建模型前进行设置,我们需要把前面的代码修改为:
from transformers import AutoConfig, AutoTokenizer, AutoModelForCausalLMimport torchmodel_path = r"qwen"tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=True, local_files_only=True)config = AutoConfig.from_pretrained(model_path, trust_remote_code=True, local_files_only=True)config.tie_word_embeddings = False# 👈 就放这里model = AutoModelForCausalLM.from_pretrained( model_path, config=config, # 👈 传进去 trust_remote_code=True, device_map="auto", dtype=torch.float16, local_files_only=True,)
这里的话并不太建议大家加上,容易引发其他的训练问题。
Tokenizer 配置对齐警告
The tokenizer has new PAD/BOS/EOS tokens that differ from the model config and generation config. The model config and generation config were aligned accordingly, being updated with the tokenizer's values. Updated tokens: {'bos_token_id': None, 'pad_token_id': 151643}.
第二个警告表示当前 tokenizer 的 pad_token_id / bos_token_id / eos_token_id 和模型 config 或 generation config 不一致,于是 Transformers 做了自动对齐:
pad_token_id更新为151643(你 tokenizer 的<|endoftext|>)bos_token_id显示为 None(对 Qwen 系列也常见)
这一步的意义其实是避免训练/生成阶段因为 PAD/EOS 不一致导致 padding、截断、结束符处理出问题。这个是模型本身的问题,也是对训练没有影响的。
训练循环阶段
在将前面的环境都配置好后,模型就自动开始训练了。在训练日志里,每一行字典都对应一次 logging_steps 触发时的“训练状态快照”。你看到的字段大致可以分为三类:收敛情况(loss/accuracy/entropy)、优化器与梯度状态(learning_rate/grad_norm)、进度信息(num_tokens/epoch)。这部分信息我们也可以在 trainer_state.json 文件中找到:
{'loss': '3.625', 'grad_norm': '138', 'learning_rate': '0', 'entropy': '2.148', 'num_tokens': '272', 'mean_token_accuracy': '0.5217', 'epoch': '0.04444'}{'loss': '3.625', 'grad_norm': '138', 'learning_rate': '5e-05', 'entropy': '2.148', 'num_tokens': '544', 'mean_token_accuracy': '0.5217', 'epoch': '0.08889'}{'loss': '1.816', 'grad_norm': '96', 'learning_rate': '0.0001', 'entropy': '2.735', 'num_tokens': '816', 'mean_token_accuracy': '0.7391', 'epoch': '0.1333'}{'loss': '2.31', 'grad_norm': '48.25', 'learning_rate': '9.944e-05', 'entropy': '2.537', 'num_tokens': '1088', 'mean_token_accuracy': '0.8261', 'epoch': '0.1778'}{'loss': '1.078', 'grad_norm': '22.5', 'learning_rate': '9.778e-05', 'entropy': '2.754', 'num_tokens': '1360', 'mean_token_accuracy': '0.8696', 'epoch': '0.2222'}
那这里我们具体解释一下每部分参数的含义:
loss(训练损失)
loss 是训练最核心的指标,表示“模型当前这一步预测错得有多严重”。在因果语言模型(Causal LM)里,它本质上是**下一个 token 预测的交叉熵损失,**模型越能正确预测目标 token,loss 就越低。
- loss 下降:通常意味着模型在学习(至少在训练集上更会做这件事)。
- loss 长期不降或很高:可能学习率过小、训练不够、或数据/格式有问题。
- loss 突然飙升、变 NaN:往往是数值不稳定(学习率过大、梯度爆炸、混合精度溢出等)。
在我们这种“重复数据”的演示里,loss 往往会下降得非常快,因为模型很容易把答案记住。这也是为什么 loss 只需要几步就快速的从 3.625 降到了 1.078。
在监督式微调(SFT)中,loss 曲线是判断训练是否健康的最直观信号之一。通常情况下,训练过程会呈现出三个相对典型的阶段:
- **快速下降:**模型在训练开始的少量 step 内会出现明显的 loss 下跌。这通常意味着模型正在迅速适配新的数据分布与输出格式(例如回答风格、模板结构、指令遵循方式)。
- **逐步趋稳:**随着训练推进,loss 的下降速度会变慢并开始呈现波动式下降。这是正常现象:模型进入“精细调整”阶段,开始对细节进行对齐,边际收益逐渐降低。
- **收敛/平台期:**当 loss 在一个相对稳定的区间内上下波动、整体不再显著下降时,往往意味着模型已基本收敛。此时继续训练通常收益有限,甚至可能带来副作用(比如过拟合或风格僵化)。
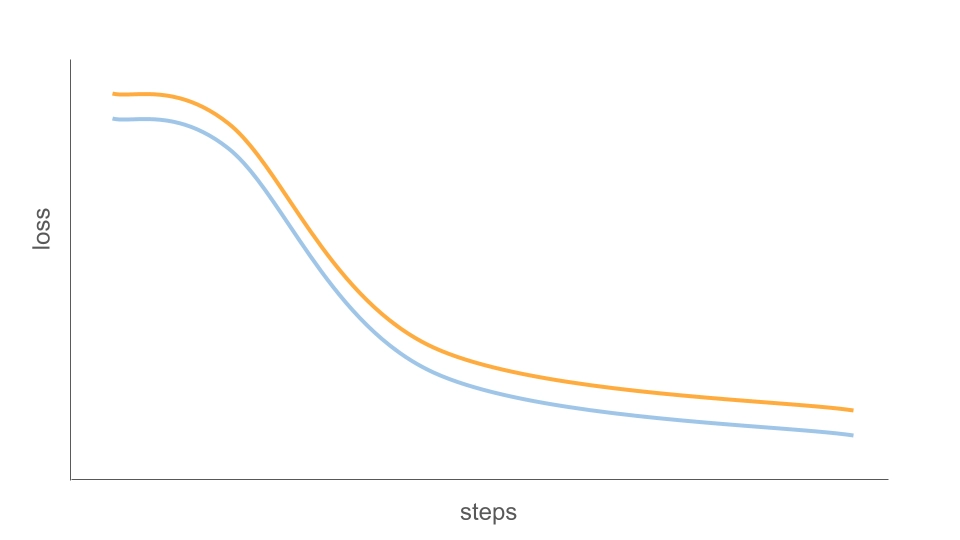
对于训练过程是否健康有一个很关键的指标就是训练集 loss 与验证集 loss 之间的差距应当较小。这通常说明模型正在学习可泛化的模式(generalizable patterns),而不是单纯记住训练样本(memorization)。
相反,如果训练 loss 继续下降但验证 loss 逐步走高,就需要警惕模型正在“背答案”。这种情况常常被称为是 Overfitting Pattern(过拟合):
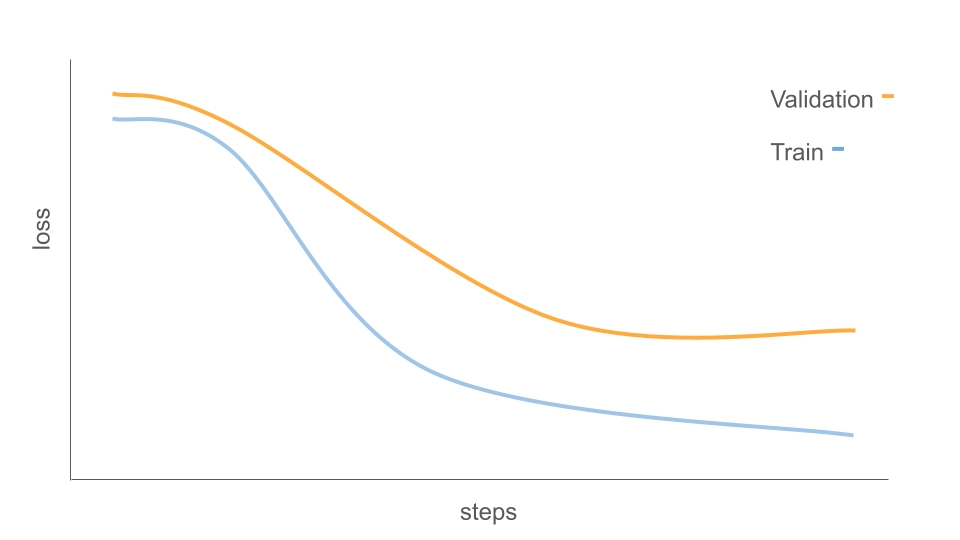
应对策略:
- 减少训练步数或 epoch(最直接有效)
- 增加数据量或提升数据多样性(改写、扩充场景、引入负例/边界例)
- 增加正则化手段(如 weight decay、dropout,或 LoRA 限制可训练参数规模)
- 以验证集 loss 为准启用 early stopping(实践中非常常用)
另外,假如如果 loss 整体没有明显改善,或者下降非常缓慢,通常意味着模型并没有有效学到目标行为,这种情况也常常被称为是 Underfitting Pattern(欠拟合):
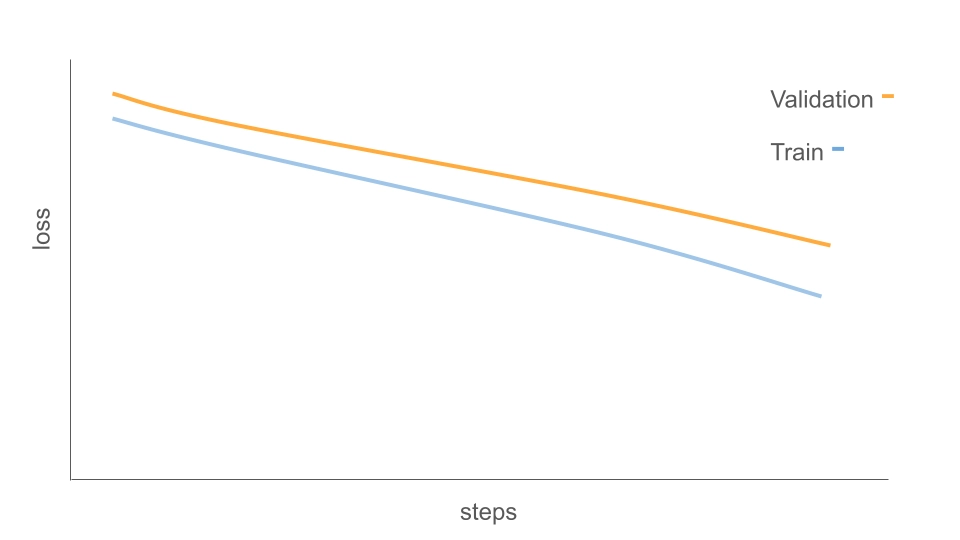
常见原因包括:
- 学习率过低:更新幅度太小,模型“学得太慢”(可尝试适度提高 LR,或增加 warmup 让训练更稳)
- 数据质量问题:指令—答案不匹配、格式混乱、噪声太大,都会让模型难以收敛
- 任务难度与模型能力不匹配:如果任务复杂而模型过小,或要求强推理/强知识补全,可能需要换更大模型或调整训练目标
另外,还有一种特殊情况需要注意,即当你观察到 loss 低得异常(尤其是在小数据、高重复数据、或强模板数据集上),要警惕模型可能是在记忆训练样本,而不是学习可迁移的规律。
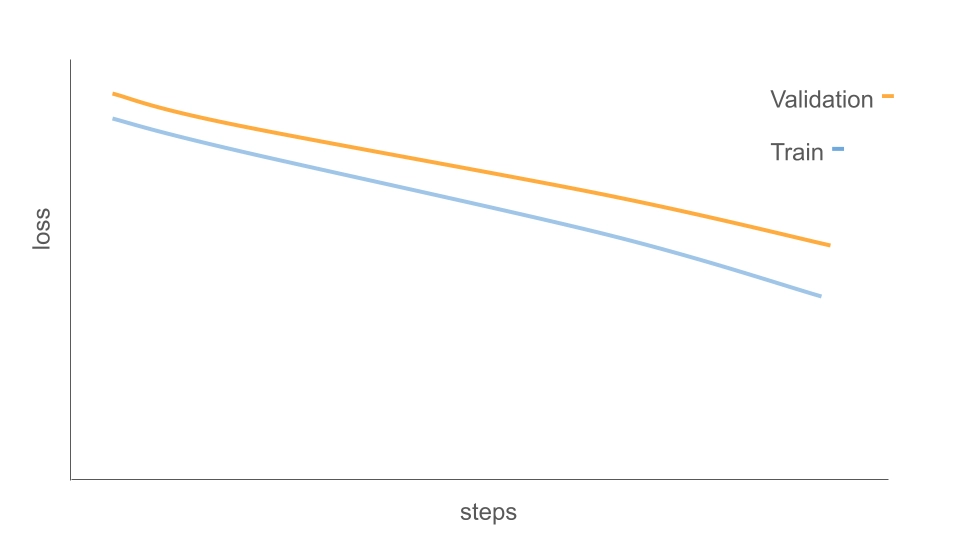
当前我们训练用的数据集就是这种情况,模型就可能会在记忆训练样本,这也是为什么我们训练到最后的 loss 会变得非常非常低。不过我们这里主要是演示训练的过程和原理,因此在后续正式训练的过程中将会使用真正的训练数据集来实现。
grad_norm(梯度范数)
grad_norm 可以理解为“这一步算出来的梯度有多大”。梯度越大,说明模型参数被推动更新的力度越强;而梯度越小,说明模型已经接近收敛、改动变得更细。
grad_norm很大:常见于训练初期(模型预测错得多),也可能提示训练不稳定。grad_norm逐渐变小:通常是正常收敛信号。grad_norm突然异常飙升:可能出现梯度爆炸,通常需要检查学习率、max_grad_norm(梯度裁剪)或精度设置。
这里第一步 grad_norm=138 比较大,但后续快速下降,是“模型很快学会重复样本”的典型现象。
learning_rate(当前学习率)
这是这一时刻真实生效的学习率,不一定永远等于你配置的 learning_rate=1e-4,因为我们还设置了 warmup 和调度器:
- 前期 warmup:学习率从很小逐步升到峰值(可能第一步显示为 0,是因为数值太小被格式化成 0)
- 后期 cosine 衰减:到达峰值后再逐步下降(你后面从
1e-4变成9.944e-05、9.778e-05就是开始衰减了)
这条“先升后降”的曲线能让训练更稳定、更容易在后期收敛。
entropy(输出分布熵/不确定性)
entropy 可以粗略理解为模型在预测下一个 token 时的“犹豫程度”。
- entropy 高:模型更不确定,分布更分散(很多 token 概率差不多)
- entropy 低:模型更确定,分布更尖锐(更像“我就认准这个答案”)
在重复数据训练里,模型会越来越确信某一套输出,因此 entropy 往往会逐渐降低或趋于稳定。
num_tokens(累计处理的 token 数)
这个数通常表示从训练开始到当前日志时刻,累计处理了多少个 token
(包括输入和目标相关的 token,具体口径由实现决定)。你可以看到它是不断增长的:272 → 544 → 816 ...,说明训练在持续推进。
在例子中每次大约增加 272,意味着你每个记录窗口内处理的 token 数量相对固定(与 max_length=128、数据内容长度、以及梯度累计的汇总方式有关)。
mean_token_accuracy(平均 token 准确率)
这是一个比较直观的指标:在预测下一个 token 时,模型把“最可能的 token(argmax)”预测对的比例是多少(平均到当前统计窗口或累计范围)。
- 训练初期准确率低:模型还不会答
- 训练后期准确率高:模型逐渐能把目标序列预测出来
在这段日志中它从 0.52 → 0.74 → 0.82 → 0.87 上升,说明模型很快就学会输出那句固定回答了。但需要注意的是,这是 token 级别的指标,并不等同于“语义是否正确”,但对观察收敛很有帮助。
epoch(训练进度:当前处于第几轮的比例位置)
epoch 表示训练进度在“第几轮”里走到哪里了。因为你设置了 num_train_epochs=1,所以它会在 0~1 之间变化:
epoch=0.04444:表示大约完成了 4.444% 的第一轮epoch=0.2222:表示大约完成了 22.22% 的第一轮
这个值通常是按“已完成的 optimizer step / 总 optimizer step”换算出来的,所以它跟你的 gradient_accumulation_steps、数据量、总步数计算有关。因为我们总共就 22.5 步,所以 5/22.5≈22.22% 。
评估阶段
另外由于前面超参数时设置了 eval_strategy="steps" 和 eval_steps=5,所以每五步都会进行一次评估:
{'eval_loss': '0.3123', 'eval_runtime': '0.3733', 'eval_samples_per_second': '53.57', 'eval_steps_per_second': '8.036', 'eval_entropy': '1.719', 'eval_num_tokens': '1360', 'eval_mean_token_accuracy': '0.913', 'epoch': '0.2222'}
这里展示的就是评估的结果信息,包括:
-
eval_loss(验证损失)验证集上的 loss,含义与训练时的
loss类似:越低通常表示模型在验证集上预测得越好。由于这里使用的数据重复度很高,所以
eval_loss下降得快是正常的。但还是要去对比一下两者的情况,确保模型不会出现过拟合的情况。
eval_loss持续下降:通常说明模型确实在变好(至少对当前验证集分布而言)。train loss下降但eval_loss上升:常见是过拟合信号。
-
eval_mean_token_accuracy(验证集 token 平均准确率)在验证集上,模型预测下一个 token 的“命中率”(一般是 argmax 是否等于目标 token)。对应前面的
mean_token_accuracy。 -
eval_entropy(验证集输出分布熵)表示模型在验证集上预测 token 时的“不确定性”。对应着前面的
entropy部分的内容。 -
eval_runtime(评估耗时)本次评估总共花了多少秒。这里是
0.3733s,说明验证集很小或序列很短。 -
eval_samples_per_second(每秒评估样本数)每秒跑多少条验证样本,越高说明评估越快。这里是
53.57条/秒。 -
eval_steps_per_second(每秒评估步数)每秒跑多少个评估 step(注意这是评估 dataloader 的 step,不是训练的 optimizer step)。这个值与
per_device_eval_batch_size、验证集大小、以及设备速度有关。这里是8.036 step/s。 -
eval_num_tokens(评估累计 token 数)表示本次评估过程中统计到的 token 数(通常是非 padding 或参与计算/损失的 token,具体口径随实现)。
这里 1360 往往意味着:验证集样本数 × 每条样本的有效 token 数 ≈ 1360。也就是说 20 条的总 token 数是 1360,每一条大概是 68 个 token。
同时由于设置了 save_strategy="steps” 和 save_steps=5 ,所以也会将权重内容进行保存(保存一次权重大概需要 7.62s):
Writing model shards: 100%|██████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:07<00:00, 7.62s/it]
接下来就是继续的循环过程,可以看出 loss 随着训练的进行在急速的下降,从最初的 3.625 降到最终的 0.0004278 (几乎接近于 0),所以此时的模型已经几乎完全学会了这句问答的内容了。
假如我们希望可视化这部分内容,我们可以在终端输入以下代码激活 TensorBoard:
tensorboard --logdir qwen3-0.6B-sft\runs --port 6006
然后进入点击进入链接:
http://localhost:6006/
接下来就可以看到各种训练数据的运行过程了:
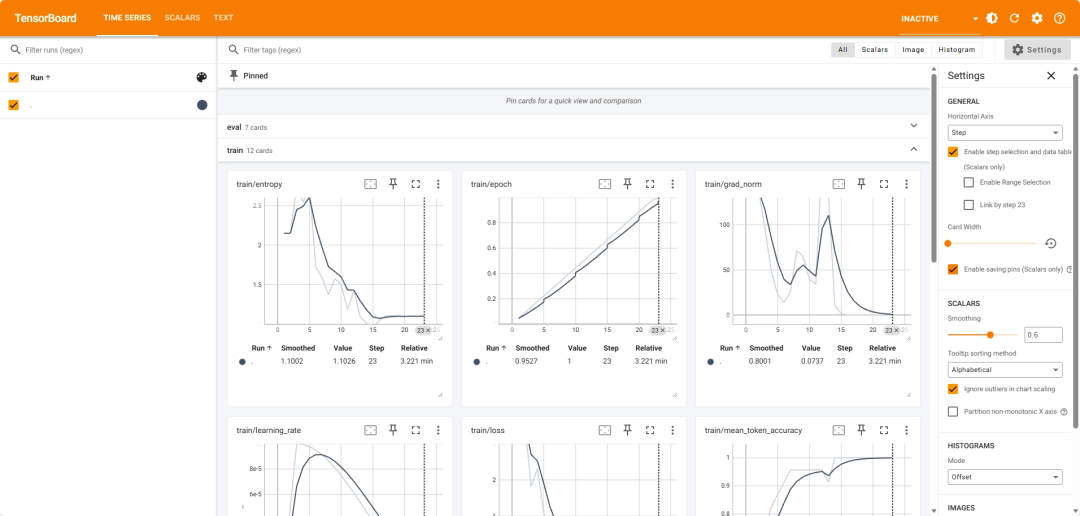
训练结束汇总
{'train_runtime': '219', 'train_samples_per_second': '0.822', 'train_steps_per_second': '0.105', 'train_loss': '0.6496', 'epoch': '1'}
在训练完后,会出现一份训练总结内容,包括:
train_runtime=219:总训练耗时约 219 秒train_samples_per_second=0.822:平均每秒处理约 0.82 条样本(因为保存很频繁 + 评估也频繁,吞吐会被拖慢)train_steps_per_second=0.105:每秒约 0.105 个 optimizer step(约 9.5 秒一步,跟末尾进度条9.52s/it对得上)train_loss=0.6496:全程平均训练 loss(注意它是全程平均,不是最后一步的 loss)
在最后也会出现一个进度条,这个进度条是会在训练过程中实时进行更新,这里显示的就是结束的进度信息:
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 23/23 [03:39<00:00, 9.52s/it]
总的来说,这段日志可以概括为模型加载 → 检查/对齐 tokenizer 与 config → 进入训练循环(每步输出 loss、lr、grad_norm 等)→ 按 eval_steps 周期评估 → 按 save_steps 周期保存 checkpoint → 输出训练耗时与吞吐总结。
那由于数据高度重复,模型很快记住答案,因此 loss 和 token_accuracy 很快趋近于 0 和 1,这是“流程演示”场景下的典型现象。
模型测试
那在训练完成后,我们不能单纯的去看训练的过程数据来判断一个模型的好坏,因为这些数据只能说明模型在“训练数据分布”上的拟合程度,不能保证:
- 模型在“真实用户问法”下仍然遵循指令
- 模型没有把答案背下来(过拟合)
- 模型没有出现“格式漂移”“复读”“胡编”
- 微调没有破坏原模型的通用能力(灾难性遗忘)
所以训练后测试的目标是确认模型是否“按预期变好了”,以及有没有“副作用”。
对话测试
那这里我们就通过最简单的方式——直接对话,来测试一下模型在微调后能否学习到固定的回复范式。这里我们可以用之前推理的代码来实现,主要就是更改一下 model_path 即可:
from transformers import pipelinemodel_name_or_path = r"D:\微调与部署\qwen3-0.6B-sft3\checkpoint-23"pipe = pipeline( "text-generation", model=model_name_or_path,)messages = [{"role": "user", "content": "你是谁?"}]out = pipe(messages, max_new_tokens=1000)print("=== 模型回答 ===")print(out[0]["generated_text"])
这里我们传入“你是谁?”这个问题时,回复的内容是:
[{'role': 'user', 'content': '你是谁?'}, {'role': 'assistant', 'content': '<think>\n嗯,用户问我是谁。作为一个大模型微调的AI老师,我需要回答清楚。首先,我得确认用户的问题是关于我的身份,所以 应该直接说出我的全称。不过有时候用户可能不太清楚我的名字,所以也可以简要说明。然后,用户可能想知道更多关于我的信息,比如使用的是哪个模型,或者有什么功能。不过根据问题本身,用户只是问我是谁,所以重点还是在回答名字。同时,用户可能有其他意图,比如想了解我的功能或使用情况,但问题比较简短,可能不需要展开。要保持回答简洁,同时确保信息准确。\n</think>\n\n我是李剑锋,一个专注于大模型微调与部署的AI老师。'}]
看起来非常好!模型真的学会了在问 “你是谁?” 的时候回复对应的内容。我们也可以试试在这里加上 /no_think 看看会怎么样:
messages = [{"role": "user", "content": "你是谁?/no_think"}]
此时的回复其实也很标准,和我们输入的是一模一样的,代表模型真的学会了在输入“你是谁?”的时候回复正确的内容:
[{'role': 'user', 'content': '你是谁?/no_think'}, {'role': 'assistant', 'content': '<think>\n\n</think>\n\n我是李剑锋,一个专注于大模型微调与部署的AI老师。'}]
当然我们也可以问一些其他问题试试看:
messages = [{"role": "user", "content": "你叫什么呀?/no_think"}]
此时我们发现,其还是只会回复这样一句话:
[{'role': 'user', 'content': '你叫什么呀?/no_think'}, {'role': 'assistant', 'content': '<think>\n\n</think>\n\n我叫李剑锋,一个专注于大模型微调与部署的AI老师。'}]
这其实就不对了,因为我们希望的个人认知微调并不是问什么都只回复这一句,而是在问各种问题的时候都能够从各个角度来进行回复的。所以这就代表我们的模型已经有点过拟合的情况了。
比如我们再问 “什么是过拟合?” 的时候,其回复的内容虽然也还算凑合,但是已经非常的简短了:
[{'role': 'user', 'content': '什么是过拟合?/no_think'}, {'role': 'assistant', 'content': '<think>\n\n</think>\n\n过拟合(Overfitting)是指模型在训练数据上表现很好,但对新数据表现差的偏差。'}]
这其实是意味着一个事情,模型出现了非常严重的过拟合,在问任何和认知相关的问题时都只会回复同一句话,并且一些常识性的问题都没有办法很好的回复。
出现这种现象并不奇怪,因为这次的训练数据是200 条完全重复样本,信息量极低,而模型参数量很大,模型最容易学到的就是“最保险的策略”,即把答案背下来、并在任何输入下都输出它。
那怎么办呢?一般情况下有两个修复的方向:
- 数据变得更加的泛化:比如扩充问法的多样性(不再仅仅问
“你是谁”,而是拓展成问“请做个自我介绍”、“你能介绍一下你自己吗?”等等的问题)以及加入“对比样本”(不是身份相关的问题,就正常回答)。这个方法我们将在下节课进行讲解。 - 调整训练参数:那为了防止过拟合,其实有一个很简单的方法就是降低学习率来让学习学得慢一些。但是这个方法终归是治标不治本,最重要的还是增加数据的多样性来解决。
调参思路
当然,真正的调参并非仅仅只是调整学习率这么简单,学习率只是影响训练结果的一个关键旋钮。在实际的 SFT 训练中,一个模型能不能“既学会目标行为,又不破坏原有能力”,往往是数据质量、训练参数、评估方式三者共同作用的结果。
更准确地说,我们这次看到的现象,本质上是在做一个平衡:
- 学习率太低:模型“学得不够”,目标行为没有真正固化下来;
- 学习率太高(尤其配合重复数据):模型“学得太猛”,容易把单一模式刻进所有场景,变成复读机;
- 学习率适中:模型既能学会指定问答范式,又能尽量保留原有通用能力。
这也是为什么在工程实践里,我们很少只跑一次训练就下结论,而是会进行小规模、多轮次的对比实验。例如围绕同一份数据集,尝试不同配置组合:
- 学习率:
1e-5 / 2e-5 / 5e-5 - epoch:
1 / 2 - warmup 比例:
0.03 / 0.05 / 0.1 - 有效 batch(通过梯度累计控制):
4 / 8 / 16
然后结合训练日志 + 对话测试 + 验证集表现来判断哪组配置更合适,而不是单看某一次的 loss 数值。
通过这组对比实验,其实我们已经得到了一个非常重要的实践经验:
SFT 的目标不是把 loss 压到越低越好,而是在“目标对齐”和“能力保留”之间找到合适平衡。
尤其是在小数据、重复数据场景下,loss 很容易快速下降,但这并不等于模型就“训练成功”了。真正决定模型是否可用的,仍然是训练后的实际测试表现。
总结
总的来说,SFT 的核心价值,不在于临时“引导”模型,而在于通过监督数据把我们期望的回答方式、输出格式与行为习惯,进一步固化到模型参数之中。相比提示词工程和 RAG 这类主要作用于输入侧的方案,SFT 更像是在做一次“行为内化”——让模型不再只是这一次答得像,而是在更多相似场景下都能更稳定地按预期输出。
但与此同时,SFT 也绝不是“只要开始训练就一定有效”。真正决定微调效果的,往往不是训练代码本身,而是前面的任务选择、数据质量、参数配置以及后续评估是否扎实。模型能不能学会目标行为,取决于数据是否高质量、是否足够一致;模型会不会学偏、学坏、学成复读机,则取决于训练强度是否合适、验证与测试是否及时。也正因如此,微调从来都不只是“跑通 Trainer”,而是一个围绕任务、数据、训练和评估不断迭代优化的工程过程。
通过本节的实操,我们用一个最小可运行示例完整走通了 SFT 的基本链路:从环境配置、模型加载、数据组织、训练参数设置,到使用 SFTTrainer 启动训练,再到观察 loss、checkpoint、TensorBoard 曲线以及最终对话测试结果。虽然这里的数据集非常简单,更多只是为了帮助大家理解“训练是怎么真正发生的”,但它已经足以说明一个关键事实:模型确实可以通过监督微调学会新的输出模式,只不过这种学习能否真正泛化,还必须依赖更高质量、更丰富、更真实的数据来支撑。
所以,SFT 的入门重点从来不只是“会写训练代码”,而是要逐步建立起这样一套完整意识:先判断任务值不值得调,再准备真正高质量的数据,再用小模型低成本验证,最后通过测试确认模型究竟是“学会了”,还是只是“背下来了”。当你真正理解了这一整套流程,后续无论是做更复杂的指令微调、领域微调,还是继续进入偏好对齐与强化学习阶段,都会更容易建立起清晰而扎实的实践基础。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我们整理出这套 AI 大模型突围资料包:
- ✅ 从零到一的 AI 学习路径图
- ✅ 大模型调优实战手册(附医疗/金融等大厂真实案例)
- ✅ 百度/阿里专家闭门录播课
- ✅ 大模型当下最新行业报告
- ✅ 真实大厂面试真题
- ✅ 2026 最新岗位需求图谱
所有资料 ⚡️ ,朋友们如果有需要 《AI大模型入门+进阶学习资源包》,下方扫码获取~
① 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)
② 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
③ 大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
④ AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
⑤ 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
⑥ 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

以上资料如何领取?

为什么大家都在学大模型?
最近科技巨头英特尔宣布裁员2万人,传统岗位不断缩减,但AI相关技术岗疯狂扩招,有3-5年经验,大厂薪资就能给到50K*20薪!

不出1年,“有AI项目经验”将成为投递简历的门槛。
风口之下,与其像“温水煮青蛙”一样坐等被行业淘汰,不如先人一步,掌握AI大模型原理+应用技术+项目实操经验,“顺风”翻盘!

这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

以上全套大模型资料如何领取?


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献195条内容
已为社区贡献195条内容

所有评论(0)