Java开发者AI转型第八课!避开Token陷阱!Spring AI记忆裁剪源码解析与Token级防溢出核心技巧
大家好,我是直奔標杆,欢迎各位Java同仁来到《Spring AI 零基础到实战》专栏的第8节分享!今天咱们继续深耕AI转型实战,一起破解生产环境中隐藏的坑点,共同成长、互相借鉴~
在上一节《Java开发者AI转型第七课!AI失忆症克星!ChatMemory对话历史管理与上下文实战》中,咱们一起用MessageChatMemoryAdvisor实现了多租户聊天记忆的全自动接管。看着数据库里不断积累的对话数据,不少小伙伴可能会暗自庆幸:“太给力了,我的AI终于有了完整且持久的记忆!”
但作为过来人,直奔標杆必须提醒大家:在真实生产场景中,要是任由用户对话记录无限累积,每次请求都毫无节制地把所有历史消息一股脑传给大模型,系统上线后用不了几天大概率会崩掉——不仅API账单会直接失控暴涨,服务器还会因为上下文溢出频繁宕机报错。
这就是咱们本节课重点攻克的难题——潜伏在上下文里的“Token刺客”,今天咱们就一起把它彻底拿捏!
本节课,直奔標杆会带大家扒开Spring AI的底层源码,一起探究Spring框架是如何通过滑动窗口(Sliding Window)优雅实现“记忆裁剪”的,同时教大家给记忆库装上防溢出超级阀门,守住钱包和服务器的最后一道防线,干货拉满,建议收藏学习~
本节学习目标(共勉共进)
-
认知破局:吃透无限制长记忆的“三宗罪”,避开破产、报错、变笨三大坑;
-
源码解密:拆解MessageWindowChatMemory底层源码,弄懂Spring AI给System人设加“免死金牌”的架构精髓;
-
极简实战:用现代Builder模式精准配置maxMessages记忆阀门,上手就能用;
-
架构进阶:剖析Message数量裁剪的致命缺陷,分享Token级精准滑窗的终极解决方案。
记忆传送带与“免死金牌”(核心逻辑先吃透)
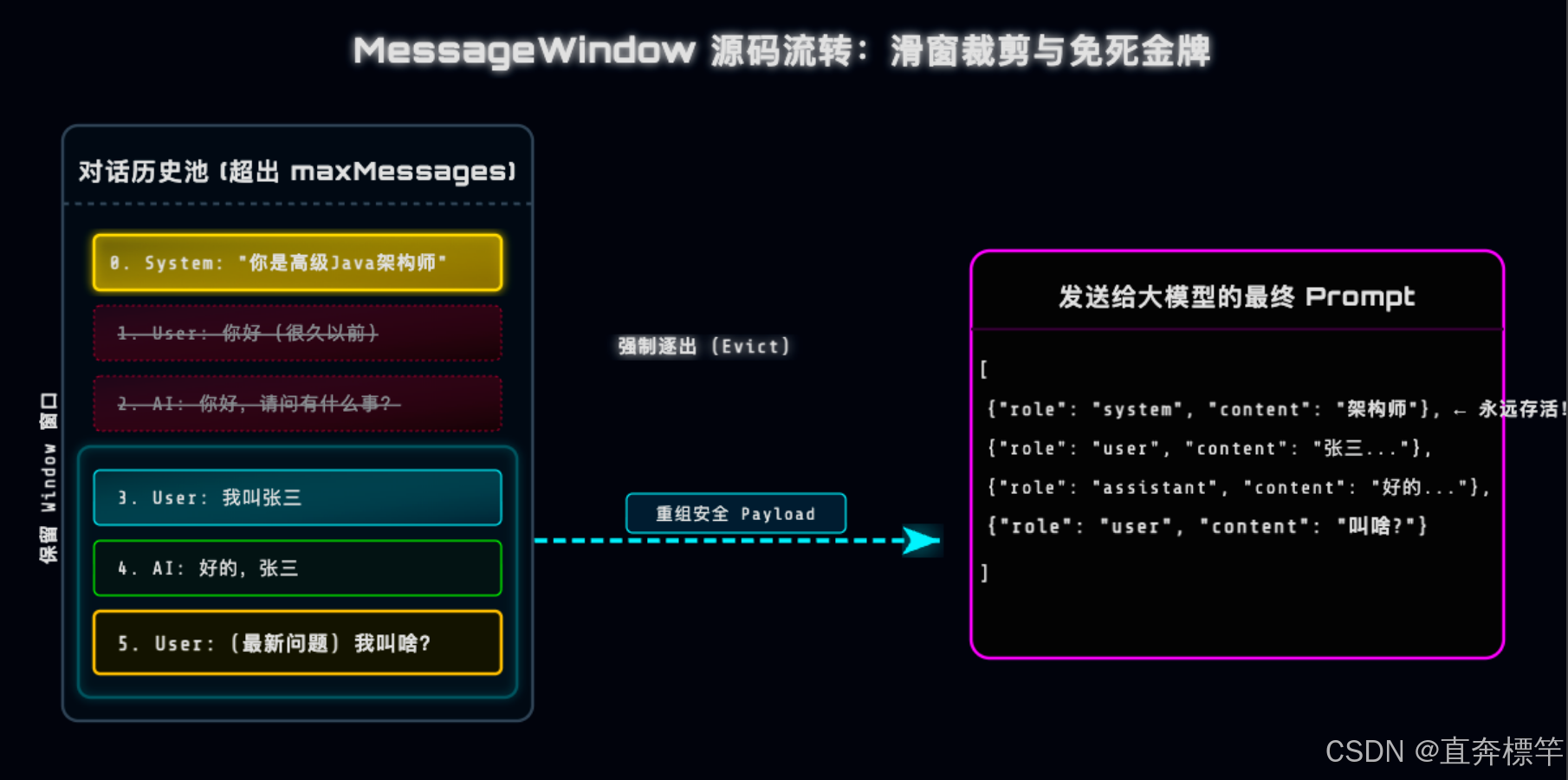
在深挖源码之前,大家先直观感受一个核心逻辑:当历史记忆不断膨胀触发阈值时,底层的滑动窗口就像无情的传送带,会逐步“淘汰”旧记忆,但又能智能保护“系统人设”不被删除——这也是Spring AI设计的精妙之处,咱们一步步拆解。
不限制记忆的“三宗罪”(避坑必看)
在AI架构设计中,要是咱们无脑地让List<Message>不断累加,系统迟早会栽在以下三种情况里,直奔標杆结合实战经验给大家逐一拆解:
1. 成本破产(被Token刺客暗坑)
很多小伙伴容易踩坑:大模型API计费不是按最后一句提问算的,而是按你发送的总上下文Token数计费!比如你和AI聊了100轮,积累了10000个Token,此时哪怕只发一句“嗯”,大模型也会按10001个Token扣费,长期下来账单绝对扛不住!
2. API报错崩溃(Context OOM)
每个大模型都有物理层面的“最大上下文限制”,一旦历史记录超过这个限制,大模型不会主动帮你截断,只会直接抛出HTTP 400: Context Length Exceeded报错,导致该用户的对话通道直接瘫痪,影响用户体验还得排查问题。
3. 大模型变笨(Lost in the Middle现象)
斯坦福大学的论文有个关键结论:大模型一次性读取的信息越多,注意力越容易被稀释。要是你强行把50轮之前无关的寒暄都塞给它,它回答最新业务问题的准确率会断崖式下降,相当于“聪明反被聪明误”。
Spring AI如何优雅“删记忆”?(源码拆解+实战分享)
针对以上问题,AI工程界最经典的解决方案就是滑动窗口(Sliding Window)——和人类的短期记忆类似,只保留最近的N条对话,挤掉老旧记忆,避免冗余。
但这里有个致命的架构难题,相信很多小伙伴都遇到过:要是删旧记忆时,把最开始的SystemMessage(系统人设设定)也删掉了怎么办?AI聊着聊着忘了自己是客服、是技术助手,岂不是闹笑话?
别急,咱们一起看看Spring AI中的MessageWindowChatMemory是怎么解决这个问题的,直奔標杆给大家精简拆解它的核心process()源码,看不懂源码的小伙伴也能get核心逻辑:
// 内部源码精简剖析(直奔標杆整理,保留核心逻辑)
private List<Message> process(List<Message> memoryMessages, List<Message> newMessages) {
List<Message> processedMessages = new ArrayList<>();
// 1. 【排他性清理】如果本次新消息包含新的SystemMessage,
// 直接删除历史中的老SystemMessage,避免人设冲突(实战中必避的坑)
boolean hasNewSystemMessage = newMessages.stream().anyMatch(...);
// ... 拼接新老消息(省略无关逻辑,重点看核心裁剪) ...
// 2. 若消息总数未超过设置的maxMessages,直接安全返回
if (processedMessages.size() <= this.maxMessages) {
return processedMessages;
}
// 3. 【核心逻辑】计算需要删除的老旧消息数量
int messagesToRemove = processedMessages.size() - this.maxMessages;
List<Message> trimmedMessages = new ArrayList<>();
int removed = 0;
for (Message message : processedMessages) {
// 4. 【免死金牌】遇到SystemMessage,无条件保留,绝不删除!
// 其他消息按顺序从最老的开始删除,直到达到删除数量
if (message instanceof SystemMessage || removed >= messagesToRemove) {
trimmedMessages.add(message);
} else {
removed++; // 被淘汰的冗余消息
}
}
return trimmedMessages;
}核心亮点就在这里:通过instanceof SystemMessage这个精准的面向对象判断,给系统人设颁发了“免死金牌”。无论历史消息怎么滑动、怎么裁剪,AI的核心人设永远不会丢失——这就是Spring AI的优雅之处,也是咱们实战中可以直接复用的设计思路。
实战配置:MessageWindow记忆阀门(上手即会)
直奔標杆结合企业实战场景,给大家整理了JDBC存储记忆的配置案例,代码简洁可复用,大家可以直接复制到项目中调整:
/**
* JDBC 存储记忆(企业实战常用配置,直奔標杆整理)
*
* @author 直奔標杆(CSDN专栏:Spring AI 零基础到实战)
*/
@Configuration
public class AiMemoryConfig {
@Bean
public ChatMemory chatMemory(JdbcTemplate jdbcTemplate) {
// 1. 构建基于MySQL语法的JDBC记忆库,可手动创建repository,也可通过@Bean覆盖
JdbcChatMemoryRepository repository = JdbcChatMemoryRepository.builder()
.jdbcTemplate(jdbcTemplate)
// 设置mysql方言(适配不同数据库可调整)
.dialect(new MysqlChatMemoryRepositoryDialect())
.build();
// 2. 将Repository注入滑动窗口策略,配置核心阀门
return MessageWindowChatMemory.builder()
.chatMemoryRepository(repository)
.maxMessages(20) // 【核心阀门】保留最近20条消息(可按需调整)
.build();
}
}配置好之后,在ChatClient初始化时,正常传入这个带阀门的ChatMemory即可。这里和大家重点说明下maxMessages(20)的含义:一轮完整对话包含1个UserMessage + 1个AssistantMessage,所以这相当于让大模型只记住最近10轮的交互(再加上永远被保护的1条SystemMessage),超过这个数量的历史消息会被框架自动删除,既省Token又保稳定。
进阶思考:Message数量裁剪的缺陷与Token级终极方案
虽然MessageWindowChatMemory很好用,但直奔標杆必须提醒大家它的物理局限性:它是基于Message数量裁剪,而不是基于Token算力裁剪——这在极端场景下会踩坑!
给大家举个实战中遇到的极端案例:
代码中设置了maxMessages = 5,但最新一轮对话中,用户直接粘贴了一份2万字的报错日志。此时框架会判断“当前只有3条Message,没超标”,直接放行,结果这2万字直接突破大模型8k的上下文限制,当场抛出OOM报错,影响整个服务!
那真正的终极解决方案是什么?直奔標杆结合底层开发经验,给大家分享核心思路:
在硬核AI开发中,我们要摒弃“数量裁剪”的思维,引入Token级精准滑窗策略(Token-based Window Strategy):系统必须引入本地Tokenizer分词器(Java界推荐开源项目JTokkit,无依赖、性能出众,比同类分词器快2-3倍),在将历史记录发给大模型之前,严格累加计算所有文本的Token总数,若超过约定阈值,就从最老的消息开始删除,甚至对单条消息逐字剥离,最大化利用上下文空间,100%避免宕机。
这里补充一句:目前Spring AI原生暂未提供极细粒度的Token切割Advisor,但通过咱们刚才拆解的源码,大家完全可以继承ChatMemory接口,手写一套属于自己的TokenWindowChatMemory记忆策略,有兴趣的小伙伴可以动手试试,有问题咱们评论区交流~
(实战小贴士:常规企业级业务场景中,合理设置Message数量阀门,配合前端限制用户单次输入字数,基本能满足需求,不用过度追求复杂的Token级裁剪,性价比最高~)
本节总结(共勉)
本节课,咱们一起搞定了潜伏在对话历史中的“Token刺客”,核心不是简单调包使用,而是深入Spring AI底层,看懂了框架通过instanceof精准剥离冗余数据、给SystemMessage加“免死金牌”的优雅设计。
最后,咱们只用几行简洁的Builder代码,就搭建了一个稳定不崩盘、账单可控的AI对话引擎——这就是Spring AI的魅力,也是咱们Java开发者转型AI的核心优势:复用现有框架经验,快速落地实战。
下节预告(持续深耕)
目前咱们的AI已经足够聪明,也有了稳固的持久化记忆,但它还有一个致命短板:认知永远停留在训练结束的那一刻。
比如你问它:“公司今天刚发布的《2026版员工报销管理规定》,打车能报销多少钱?”,它只会一本正经地胡说八道——因为它根本看不到公司内部的机密文档。
如何让AI读取公司内部PDF、Word文档,聊天时精准引经据典?下一节《Java开发者AI转型第九课!突破知识边界!企业级RAG(检索增强生成)架构与Vector Store向量库初探》,咱们正式进入AI开发深水区,一起解锁文档检索的终极秘密!
感谢各位同仁的陪伴,一起学习、一起进步,直奔標杆会持续分享Spring AI实战干货,咱们下节见!
课程往期回顾(方便大家连贯学习)
-
Java开发者AI转型第五课!:让AI懂规矩!Spring AI结构化输出(DTO)映射与Flux流式打字机极速响应
-
Java开发者AI转型第六课!Spring AI灵魂架构Advisor切面拦截与自定义实战
-
Java开发者AI转型第七课!AI失忆症克星!ChatMemory对话历史管理与上下文实战

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)