PhysInOne:一个集视觉物理学习和推理于一体的套件
26年4月来自港理工、新加坡Syai 公司和Meta的论文“PhysInOne: Visual Physics Learning and Reasoning in One Suite”。
PhysInOne,是一个大规模合成数据集,旨在解决人工智能系统物理基础训练数据严重匮乏的问题。与现有数据集仅包含数百或数千个示例不同,PhysInOne 提供 200 万个视频,涵盖 153,810 个动态 3D 场景,囊括力学、光学、流体动力学和磁学中的 71 种基本物理现象。与以往的研究不同,其场景包含复杂背景下的多物体交互,并带有全面的真实标注,包括 3D 几何、语义、动态运动、物理属性和文本描述。本文展示 PhysInOne 在四个新兴应用中的有效性:物理-觉察的视频生成、长/短未来帧预测、物理属性估计和运动迁移。实验表明,在 PhysInOne 数据集上对基础模型进行微调能够显著提升物理合理性,同时也暴露出在复杂物理动力学建模和固有属性估计方面存在的关键缺陷。
表 1 将 PhysInOne 与现有的用于从视频中学习物理的关键数据集进行了比较,突显了在多个维度上的规模和多样性。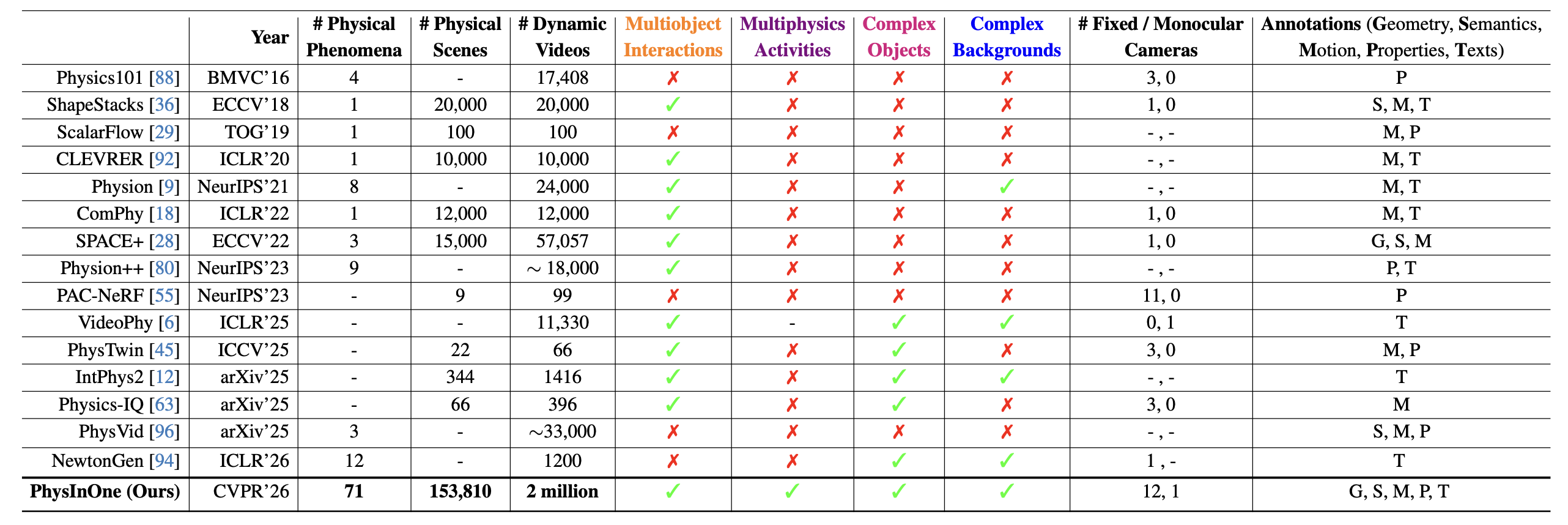
用于学习物理动力学的数据集:现有的用于学习和推理物理动力学的数据集通常只关注少数几种物理现象。例如,ShapeStacks [36] 和 StableText2Brick [68] 数据集仅涉及物体或部件的稳定性,而 VOE [66]、IntPhys2019 [72]、PHYRE [4]、ADEPT [78]、CLEVRER [92]、ESPRIT [70]、Physion [9]、CoPhy [8]、CRAFT [2] 和 SPACE+ [28] 等数据集则考察单个物体轨迹遵循直观物理规律(例如物体的持久性/连续性/固性)的简单场景,而不是严格验证其是否符合各种严格的物理定律。此外,这些数据集中的几乎所有物体都是过度简化的形状(立方体、球体等),颜色单一,背景干净。其他数据集则专注于从视觉数据中学习流体动力学:ScalarFlow [29]、TomoFluid [95] 和 FLAME [74] 专注于烟雾,而 Obstacles [3]、Richter[71] 和 NeuroFluid [38] 则专注于液体。
用于学习物理属性的数据集:越来越多的数据集已被收集用于估计不同的物理属性[86-88],包括用于质量和体积的 Physics101[88],以及用于质量、摩擦力、弹性、形变性等各种物理属性的 Physion++ [80]、Materialistic [75]、PAC-NeRF [55]、PhysTwin [45]、PhysXNet [16]、SO-PHY [15]、PixieVerse [48]、PhysVid [96] 和 VoMP [22]。这些数据集通常关注孤立的单个物体或过于简化的 3D 场景。
用于测试物理理解能力的数据集:近年来,大语言模型、视觉模型、多模态模型、视频模型和世界模型取得了长足进步,由此产生了一系列基准测试数据集,用于测试这些模型的物理理解能力,其中包括 ComPhy [18]、PerceptionTest [69]、TraySim [19]、GRASP [44]、PhysicsBench [61]、Physics-IQ [63]、Morpheus [97]、WorldModelBench [51]、WISA [84]、VBench-2.0 [102]、PhysBench [20]、DynSuperCLEVR [85]、Video-Phy [6]、VideoPhy-2 [7]、PhyX [76]、IntPhys2 [12]、Physics-GenBench [62]、UGPhysics [89]、STI-Bench [56]、Physics-WorldBench [37] 和 PisaBench。 [50]、NewtonGen [94] 和 NewtonBench-60K [49]。这些基准测试通常侧重于文本-图像-视频问答 (QA) 或在狭窄场景中的视觉理解和生成,因此缺乏训练或微调用于定量评估视觉物理学习的大型通用模型所需的精确和多样化的视觉数据和标注。
构建数据集的流程包含多个阶段,在图 2 中展示。
1 物理现象和定律
在日常物理学、力学、光学、流体动力学和磁学这四个核心领域中,识别出 71 种基本物理现象,涵盖了日常生活中常见的各种物理现象。每种基本现象都受一个或多个基本物理定律的支配,例如牛顿定律、动量守恒定律、胡克定律、伯努利原理等。
重要的是,每种基本物理现象代表的是日常生活中的一个概念性事件,而不是一个具体的、具体的 3D 场景。
2 收集 3D 资源
在现实世界中,一个物理 3D 场景通常包含多个物体在复杂的背景下相互作用。此类场景的动态特性体现了一种或多种基本物理现象,并严格遵循阐述的基本物理定律。为了尽可能多地复现这些复杂 3D 场景的不同示例,收集一套丰富的 3D 资源供使用。这些资源包括:
• 3D 物体:由于我们的数据集针对日常物理现象,特别是已确定的 71 种基本物理现象,我们从 Sketchfab [77]、FAB [30] 和 BlenderKit [11] 收集了 2,231 个常见物体(约 163 个类别)。这些与物理交互直接相关的物体使我们的数据集区别于 Objaverse/XL 等专为通用 3D 任务设计的数据集。该集合包括:
– 实体物体:例如在物理交互过程中保持形状的锤子和砖块。
– 可交互对象:具有可移动部件(例如,可旋转的风扇),在 UE 中以蓝图形式实现 [81]。
– 可破坏对象:例如,可破碎的玻璃杯,在 UE 中以几何体集合形式实现。
– 可变形对象:其形状会在物理活动中发生变化。它们的变形使用 MPM [43] 进行模拟。
– 颗粒对象:主要表示沙子等颗粒状材料,也使用 MPM 进行模拟。
– 液体:例如水、奶油、牛奶等,使用 SPH [35] 进行模拟。
• 材质:为了实现更逼真、更多样化的对象表示,进一步收集 623 种材质,分为 5 个类别:塑料、金属、木材、石材和织物。每种材质的可调节物理属性(例如摩擦系数、密度、恢复系数)使得创建多种场景变化成为可能。
• 3D 背景:为了提供能够展现各种物理现象的逼真环境,收集 528 个不同的 3D 背景。这些背景涵盖了不同空间尺度的各种室内外场景,例如客厅、卧室、工厂、游泳池等。
值得注意的是,所有收集的 3D 素材均可免费获取,并授权用于学术和商业用途。
3 创建多物理场多物体 3D 场景
利用收集的 3D 素材和已识别的 71 种基本物理现象,通过以下步骤创建规模庞大、逼真且具有挑战性的 3D 场景:
• 步骤 1:模拟多物理场:由于日常物理活动通常同时或依次涉及一种或多种基本物理现象,模拟以下 3 类活动:
– 单-物理场活动:将 71 种基本现象中的每一种都视为一个独立的单-物理场活动。
– 双-物理场活动:将两种基本现象组合成一个复杂的活动。虽然存在 C721 种组合,但其中许多缺乏物理意义。经过仔细筛选,创建 943 个双-物理活动。
– 三-物理活动:类似地,将 3 种基本物理现象组合成更复杂的活动。筛选后,创建 2270 个有效的三-物理活动。由此产生的 71 + 943 + 2270 = 3284 个物理活动目前仍处于概念阶段;它们将在后续步骤中实现为具体的 3D 场景。
• 步骤 2:设置背景:设置与目标活动相符的、符合物理规律的背景。
• 步骤 3:放置多对象:对于每个活动,创建多个具体的 3D 场景。在每个场景中,选择一个或多个 3D 模型并将其放置在背景中。
• 步骤 4:改变材质:对于每个场景中的 3D 模型,改变其材质并调整物理属性。
完成以上四个步骤后,创建 153,810 个独特的多物理多对象 3D 场景。每项活动平均由 46.84 个不同的场景实现,这些场景包含各种不同的资源、材质和背景。每个场景的 3D 资源(对象)平均数量随着活动复杂度的增加而增加:单-物理/双-物理/三-物理活动分别为 3.9/6.3/7.8 个,这表明场景复杂度不断提升。
4 模拟物理动力学
为了尽可能精确地模拟153,810个场景的物理活动,采用多种模拟算法、软件包和引擎。特别是,集成在UE5 [81] 中的Chaos Physics可以处理大多数日常物理现象。对于可变形和颗粒状物体,用Taichi [79] 实现的MPM。液体模拟则通过Doriflow [27] 使用SPH。
虽然目前的模拟器可能无法达到完美的物理保真度,但它们的误差在模拟过程中得到了充分的研究和控制 [32, 60]。因此,创建一个涵盖各种物理现象的大型合成数据集无疑具有推动研究进展的巨大潜力,正如最近的研究[100] 所证明的那样。
5 采样相机和渲染视频
对于每个 3D 场景,在上半球均匀放置 12 个静态相机,仰角为 30°~60°,以获取全面的多视角覆盖。同时,一个移动相机在整个运动过程中录制具有挑战性的单目视频。需要注意的是,静态相机的位置会根据不同的场景空间布局和背景而有所变化。移动相机沿着预定义的轨迹运动,通常以随机仰角围绕运动区域旋转。所有视频均以 1120×1120 分辨率渲染,帧率为 30 FPS(包含激光运动的 8780 个场景为 60 FPS),平均时长为 5.2 秒,以完整记录每次运动。最终生成 200 万个动态视频。
6 标注和数据集分割
对于每个 3D 场景,提供全面的标注,包括描述视觉元素和运动的详细段落。这些文本均由人工添加,并使用 Qwen3 进行校对以消除语法错误,平均每个场景约 64 个英文单词。在视频渲染过程中,同时生成:真实深度图像、逐帧对象掩码、动态对象的 3D 轨迹、对象网格和材质属性。因此,标注涵盖五个关键方面:几何形状、语义、运动、物理属性和文本描述。
数据集按 8:1:1 的比例划分为训练集、验证集和预留测试集。确保所有 3D 资产仅出现在一个分区中,以防止潜在的数据泄露。通过结构化的工作流程(包括标准化开发和独立验证)来保证数据集的质量。
1 物理-觉察视频生成
尽管视频生成模型在视觉保真度方面取得了显著进步,但它们往往无法捕捉到符合物理规律的动态过程[47, 63]。PhysInOne 包含大量模拟各种日常物理现象的动态活动。这个丰富的资源库是训练或微调下一代视频模型的理想选择,这些模型能够忠实地模拟真实世界的物理现象。
对三个具有代表性的视频模型进行微调实验:1) SVD-XT [10],一个基于 UNet 的图像到视频 (I2V) 模型;2) CogVideoX-1.5-5B [91],一个基于 Transformer 的文本-图像到视频 (TI2V) 模型;以及 3) Wan2.2-5B [83],该领域最新的基于 Transformer 和流匹配的 TI2V 模型。对于这些模型,采用三种常用的微调技术:1)低秩自适应(LoRA)[42],2)监督微调(SFT)[41],以及3)最终层微调(FLT)[93]。为了展示 PhysInOne 的潜力,随机抽取一部分训练视频(83,650 个文本-视频对)对所有模型进行微调,直至收敛。然后,使用一部分测试视频(772 个文本-视频对,称为 test-small)对所有微调后的模型及其原始模型进行评估。
评价指标:传统的评价指标,例如 FVD [82],主要评估视频生成的视觉真实感,但不足以评估运动的物理合理性。一些近期研究 [6, 40] 使用基于视频的 VLM 来评估物理常识。然而,这些模型往往无法产生有意义的评估结果,因为它们从根本上缺乏对物理定律的理解,因此不适合判断物理上的正确性。其他研究[20, 62, 76]引入了包含问答任务的基准测试来探究物理理解,但它们通常是定性的,无法定量地衡量物理运动的正确性。
为此,提出一种指标,用于定量评估生成的视频中物理运动的保真度。具体来说,给定一个展现物理上精确运动的参考视频V_ref(例如,来自测试集),以及一个使用与V_ref相同的初始帧和文本提示生成的AI生成视频V_gen,确保对比条件受控,应用离散傅里叶变换(DFT)来获得它们各自的频域表示。然后,比较 DFT(V_ref) 和 DFT(V_gen) 的能量(振幅平方),并引入物理运动保真度 (PMF)。
PMF 量化 V_gen 和 V_ref 中动态轨迹之间的运动学差异。关键在于,更高的 PMF 值表明与参考运动模式的偏差更小。该指标与像素级相似性度量的根本区别在于,它评估的是物理保真度而非视觉对应性,因为在生成任务中,帧完美对齐既不可行也不可取。
为了从人类视角验证物理合理性,还进行一项用户研究来评估生成的视频。更高的用户评分反映视频内容中感知到的更高的物理合理性。
2 未来帧预测
准确预测未来帧需要模型理解其底层物理动力学,这在自动驾驶、具身人工智能等领域具有关键应用。不同应用场景下的输入输出规范可能存在显著差异。例如,在机器人操作中,以多视角视频作为输入,模型旨在预测精确的灵巧控制,其中准确且连续的短期未来预测对于动作执行至关重要。相反,视频理解任务通常优先考虑基于单目视频输入的长期预测。在 PhysInOne 中收集的多视角和单目视频数据能够展示这些不同的应用。
3 物理属性估计
由于物体内部力随形变而变化、速度分布不均匀以及外部力在空间上存在异质性,导致物体物理属性的估计面临诸多挑战。这些因素共同作用,使得物体呈现出极其复杂的视觉外观。现有方法通常基于相对较小的数据集进行评估,且物体种类有限,这限制了该领域的发展。本文数据集涵盖了多种物体类型,包括可变形物体、颗粒状物体和液体,以及复杂的背景,为测试现有和未来模型的性能提供了一个理想的平台。
4 运动迁移
运动迁移旨在将源视频的运动动态传递到目标图像,合成一个既保留目标图像视觉属性又吸收源图像运动模式的新视频。目前的方法利用光流对运动进行编码,并在诸如 DAVIS [67] 等数据集上取得了令人瞩目的成果。然而,DAVIS 主要包含简单的运动模式,例如一只天鹅在水面上滑行,物理复杂性有限。这就引出了一个重要问题:这些方法能否准确地将涉及多个物体的多物理场交互从一个视频迁移到另一个视频?这种能力对于电影和动画制作以及虚拟原型设计等高级应用至关重要。
用来自 PhysInOne 验证集的 273 个动态 3D 场景(源)子集,评估 MotionPro [99] 和 GoWithTheFlow [13] 这两种最新方法。为了进行定量评估,通过替换源物体为不同的形状和材质,同时保持相同的物理活动,生成成对的目标场景。利用这些目标场景渲染出的新视频可以对运动传递性能进行评估。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 21
21 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)