大模型RAG(四)
一、向量数据库
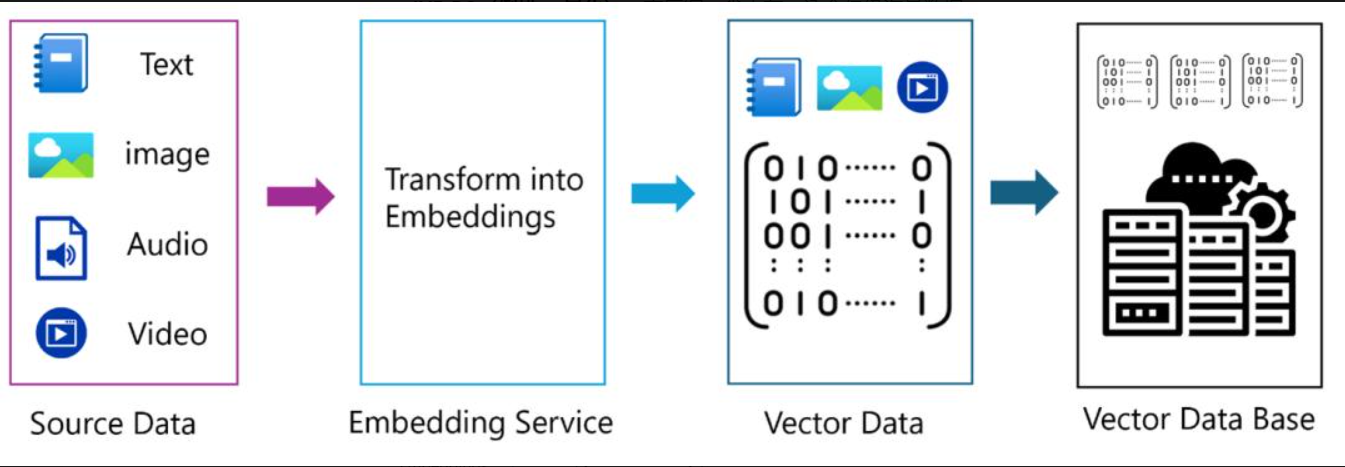
向量数据库(Vector Database)是专门存储、索引并检索高维向量嵌入(Embedding)的数据库系统,核心价值是做相似性搜索,而非传统数据库的精确匹配,是当前大模型与 AI 应用的关键基础设施。
二、向量数据库 vs 传统数据库
传统数据库(MySQL/PostgreSQL)擅长精确匹配(WHERE id=100);向量数据库擅长模糊找相似。
| 维度 | 传统数据库 | 向量数据库 |
|---|---|---|
| 数据类型 | 结构化(表 / 行 / 列) | 高维向量(文本 / 图像 / 音频) |
| 查询方式 | 精确匹配(=、LIKE) | 相似度匹配(余弦 / 欧氏距离) |
| 核心能力 | 事务、关联查询 | 语义检索、以图搜图、推荐 |
| 适用场景 | 订单、用户、报表 | RAG、大模型记忆、多模态搜索 |
三、核心原理:如何快速找到相似向量
- 距离度量(怎么算相似)
- 余弦相似度(Cosine):最常用,看向量方向是否一致(文本场景首选)。
- 欧氏距离(L2):看空间直线距离(图像场景常用)。
- 索引算法(避免全表扫描)直接暴力比对(1 亿次计算)太慢,向量数据库用ANN(近似最近邻)索引提速,主流:
- HNSW(Hierarchical Navigable Small World):工业界首选,分层图结构,速度快、精度高(如 Milvus、Pinecone 默认)。
- IVF-PQ(倒排 + 量化):高压缩、省内存,适合亿级海量数据。
- LSH(局部敏感哈希):把相似向量哈希到同一桶,适合高维稀疏场景。
四、RAG 典型工作流
- 数据准备:文档 / 图片 → 嵌入模型 → 向量。
- 入库建索引:向量写入向量库,构建 HNSW/IVF 索引。
- 查询:用户问题 → 同样模型 → 查询向量。
- 检索:向量库做 ANN 搜索,返回 Top-K 相似向量 + 原文。
- 生成:把检索结果喂给大模型,生成精准回答(解决 “幻觉”)。
五、主流向量数据库(开源 + 商用)
- Milvus(Zilliz):开源标杆,云原生,支持 HNSW/IVF,RAG 首选。
- FAISS(Meta):CPU/GPU 高性能,适合科研与自建,无分布式。
- Pinecone:商用托管,零运维,实时更新,适合快速上线。
- Chroma:轻量级开源,适合原型与小体量应用。
六、核心应用场景
- RAG(检索增强生成):大模型外挂知识库,解决幻觉、时效性、隐私问题。
- 语义搜索:不是关键词匹配,而是 “意思相近”(如 “推荐治愈系电影”)。
- 多模态检索:以图搜图、以文搜图、音频匹配(电商、版权、安防)。
- 推荐系统:用户 / 物品向量相似度推荐(短视频、商品、内容)。
- 异常检测:金融欺诈、工业故障、网络攻击(偏离正常向量分布)。
七、Pinecone vs Milvus 选型对比
| 对比维度 | Pinecone | Milvus |
|---|---|---|
| 部署方式 | 全托管 SaaS,无需自建 | 开源自建 / 托管云服务(Zilliz Cloud) |
| 运维成本 | 极低,零运维 | 较高,需自建集群或托管服务 |
| 数据主权 | 数据存储在 Pinecone 云端 | 支持私有部署,数据完全可控 |
| 性能上限 | 支持大规模,但受限于 SaaS 架构 | 支持百亿级向量,分布式架构扩展性更强 |
| 成本模式 | 按用量付费,随数据量增长成本较高 | 开源免费,自建成本低,长期大规模使用更划算 |
| 上手难度 | 极低,API 简洁,快速接入 | 中等,需学习架构与部署,有一定技术门槛 |
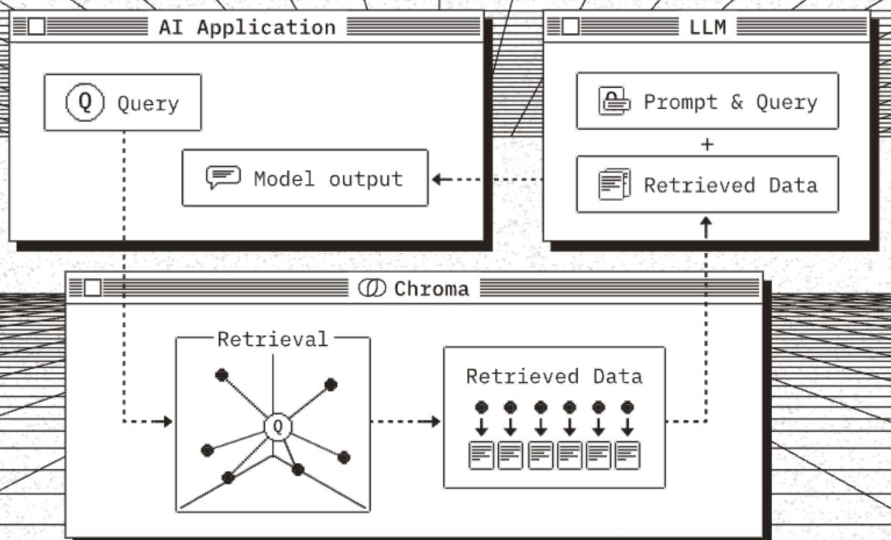
八、Chroma 向量数据库
Chroma 是一款轻量级、开源、专为 LLM/RAG 场景设计的嵌入式向量数据库,主打「开箱即用」和「低运维成本」。
- 官网:www.trychroma.com/
- 核心特性:
功能丰富:支持向量查询、元数据过滤、密度估计等功能,满足基础 RAG 开发需求。
框架友好:原生支持 LangChain、LlamaIndex 等主流大模型开发框架,能快速接入 RAG 工作流。
API 统一:同一套 API 既可以在本地 Python 笔记本中快速开发调试,也能平滑扩展到生产集群,无需大幅修改代码。
- 核心优势:无需独立部署,直接以 Python/JS 包形式嵌入代码,是原型开发、小体量 AI 应用的首选工具。
九、Faiss 向量检索库
Faiss(Facebook AI Similarity Search)是由 Meta 开发的高性能向量检索库,是工业界大规模向量搜索的底层利器。
- 开源地址:https://github.com/facebookresearch/faiss
- 核心特性:
极致性能:支持十亿级向量的毫秒级检索,内置多种索引算法(IVF、HNSW、PQ 量化),可灵活平衡速度、精度与内存占用。
多场景支持:支持 CPU/GPU 加速,提供 C++ 核心与完整的 Python 封装,可嵌入各类应用中。
丰富功能:除了基础的最近邻搜索,还支持向量聚类、降维、压缩(如 PQ 量化),适合大规模数据场景的优化。
- 注意:Faiss 本质上是一个检索库,而非完整的数据库,它不提供持久化存储、事务管理等数据库功能,通常需要搭配其他存储工具使用。
十、四款主流向量数据库对比
| 工具 | 定位 | 部署方式 | 上手难度 | 适合场景 |
|---|---|---|---|---|
| Pinecone | 全托管向量数据库 | SaaS 云服务 | 极低 | 快速上线、无运维需求的商业项目 |
| Milvus | 开源云原生向量数据库 | 自建 / 托管云服务 | 中等 | 企业级大规模应用、数据主权 / 私有化部署 |
| Chroma | 轻量级嵌入式向量数据库 | 本地嵌入 / 轻量服务 | 极低 | 原型开发、小体量 RAG、个人项目 |
| Faiss | 高性能向量检索库 | 嵌入应用 / 本地部署 | 中等 | 大规模向量检索、需要极致性能的定制化场景 |
注意:
- 如果你只是想快速搭个 RAG Demo,优先选 Chroma;
- 如果你需要处理大规模向量数据,追求极致性能,用 Faiss;
- 如果你要做企业级生产项目,优先考虑 Milvus 或 Pinecone。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)