【晓天衡宇·评测社区】前沿物理推理-地理侦探榜单正式发布,首次采用真实街景推理评测基准
【榜单简介】
本榜单以Geolocation-Bench为核心评测基准,系统性地对12个主流多模态大模型在定位精度、自校准与综合能力上开展对比评测。
Geolocation-Bench是一个评估大型视觉语言模型(VLMs)在复杂地理环境下进行街景图像理解、推理与坐标预测能力的基准测试。与传统基于地标匹配的任务不同,Geolocation-Bench通过高分辨率全景街景图像要求模型直接输出经纬度坐标——这一任务需要同时具备视觉特征提取、地理常识推理及空间映射能力。
【查看完整榜单】👉🏻https://skylenage.net/sla/leaderboard
【参评模型】
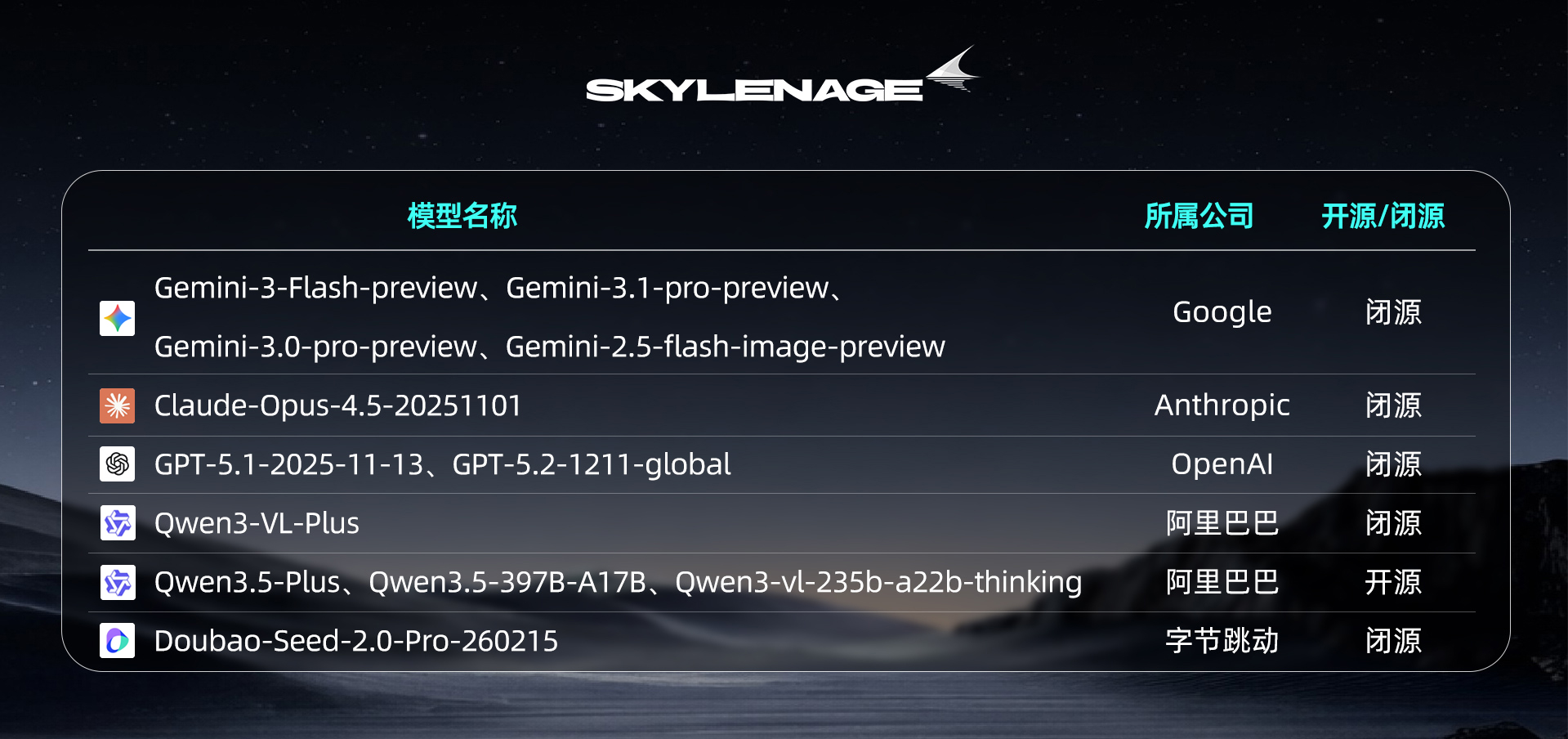
【评测集解读】
评测维度
1、社会经济加权采样
-
分配公式:城市样本配额 = f(人口×0.6 + 人均GDP×0.4)
-
人口权重 (0.6):确保样本集中在人类活动频繁、视觉特征(建筑、路牌)丰富的区域
-
人均GDP权重 (0.4):平衡不同城市化水平下的基础设施差异
2、基于 OSM 路网的几何采样
-
路网抓取:以城市中心为圆心,获取方圆 15km 范围内 drive 类型道路图层
-
路网内插:通过 osmnx 计算道路线段几何长度,按长度概率加权采样
-
坐标映射:随机内插点计算,确保坐标 100% 落在可通行的真实道路上
数据标准
从全球城市候选池中经社会经济加权采样,最终选取600个代表性样本进行模型测评。
1、城市层级分布
-
超大都市圈:北京、上海、东京、纽约等(高人口高密度)
-
新兴工业区:深圳、孟买、圣保罗等(高增长潜力区)
-
中小城市均衡采样:覆盖亚非拉美欧,避免地理盲区
2、道路网络类型
-
主干道/高速:OSM primary/motorway,视野开阔,地标显著
-
次干道/街区:OSM secondary/residential,细节丰富,干扰较多
-
特殊场景:隧道口、立交桥、边境站,测试极端情况鲁棒性
3、视觉复杂度分级
-
高信息密度:Laplacian方差 > 400 + OCR关键词丰富
-
中等复杂度:含数字线索或局部地标
-
低熵荒野区:无显著人工痕迹,测试幻觉抑制能力
4、数据采集规格
-
分辨率:1024×512 像素,全景比例
-
视野 (FOV):180°,提供宽广的视觉上下文
-
坐标系:GCJ-02 火星坐标系
-
元数据关联:每个样本配对生成同名 .json 文件,记录经纬度、采样方法、拍摄时间
5、质量控制
-
API 覆盖验证:通过 has_streetview 预检 API 返回头信息,过滤无全景图覆盖的"盲区"点
-
图像完整性校验:使用 PIL 库进行物理扫描 (img.verify()),自动删除半截图、坏图并重新采样
-
断点续传机制:采用 4 位索引(0001-1000)命名法,自动扫描目录确保数据连续性
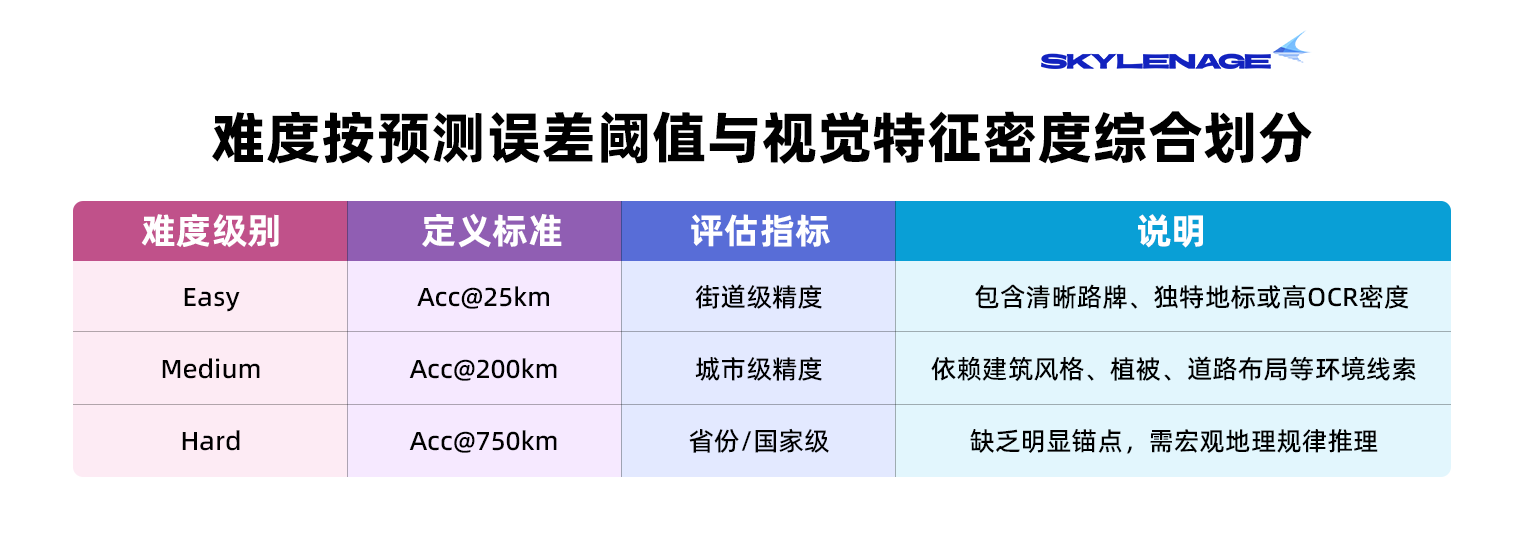
【评分标准】
距离指标单位为千米(km),准确率指标值域为 [0, 1]。
1、核心定位指标
设 $d_i$ 为第 $i$ 个样本的大圆距离(Haversine Distance):
中位数误差 (Median Error):$\text{Median}(d_i)$,主排名指标,消除离群值影响。
准确率 @K (Acc@K):$\frac{1}{N} \sum \mathbb{I}(d_i \le K)$,分别计算 K=25, 200, 750km 的命中比例。
2、自校准能力(Self-Calibration)
衡量模型“自知之明”的关键指标:
自省相关系数:$\rho = \text{SpearmanCorr}(\text{Confidence}_i, -d_i)$
解读:高分(如 Doubao 0.276)代表模型能准确预估自身误差;低分(如 Qwen 0.022)代表“盲目自信”,存在工业应用风险。
3、聚合方式
600样本全局统计与分层宏平均(按城市层级与视觉复杂度分层)。
【榜单速览】
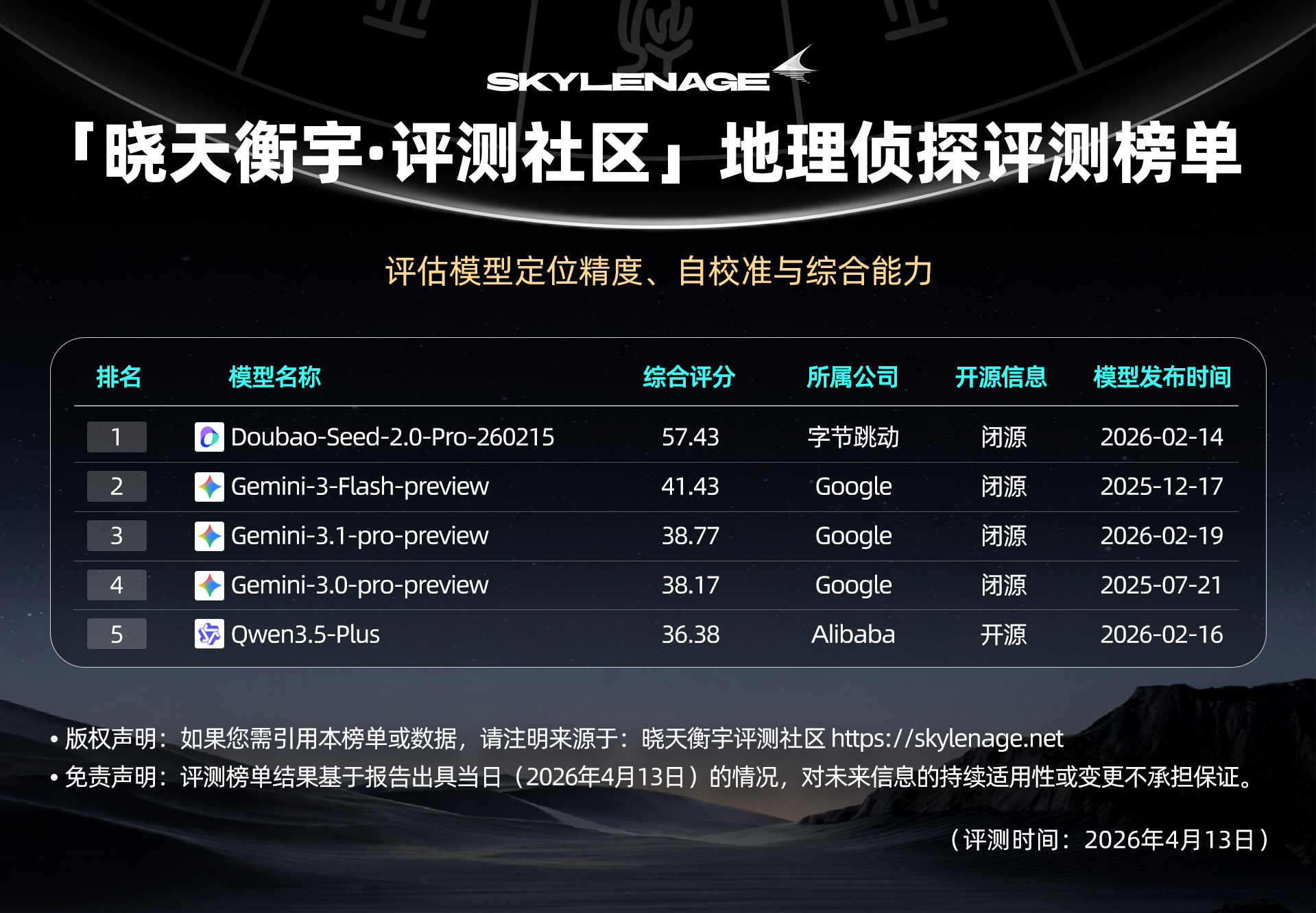
1、代际跨越与断层
Doubao 首次进入“150公里俱乐部”,领跑全局,Qwen3.5-plus 排名第5,Acc@750km达0.700,展现国产模型第二梯队实力。
2、“盲目自信”困境
Qwen3.5-plus 自校准仅0.022(全榜单最低),精度提升未伴随自省能力增长,存在严重认知失调,Doubao 与 Gemini 表现卓越,具备工业级所需的“报警”机制。
3、视觉过载与信息悖论
Qwen3-VL-Thinking 信息感知分最高(67.44),但精度反而低于 Qwen3.5-plus,揭示“看得多不等于定位准”,过度推理导致逻辑过载与噪音引入。
👉【获取完整榜单】
此处仅展示综合评分前五名预览,查看完整排名以及细分维度的详细对比数据,请访问晓天衡宇•评测社区官网:https://skylenage.net/sla/leaderboard
【榜单结论】
1、已知局限
-
坐标系偏差:使用 GCJ-02 坐标系,与国际通用 WGS-84 存在非线性偏移,需转换对比。
-
时间敏感性:街景图像拍摄时间跨度较大,城市变迁可能导致部分地标失效。
-
API依赖:依赖百度地图全景 API 覆盖率,部分偏远地区样本获取受限。
2、研究意义
-
首个街景推理基准:从“地标匹配”迈向“地理推理”,评估 VLM 在真实世界导航中的潜力。
-
自省能力诊断:首次将 Self-Calibration 作为核心指标,揭示模型在安全关键任务中的可靠性短板。
-
多模态融合方向:证明 OCR 与视觉复杂度对定位精度的差异化影响,指导未来模型架构优化。
3、使用建议
-
评估 VLM 在自动驾驶、应急搜救等地理敏感场景的适用性。
-
测试模型在缺乏明确地标时的宏观推理能力。
-
诊断模型的过度自信问题,构建高可靠性的多模型校验系统(如 Doubao+Qwen 互补)。
【了解更多】
复杂指令遵循评测榜单已同步上线至晓天衡宇•评测社区官网,欢迎大家访问查看更详细的评测数据:https://skylenage.net/sla/leaderboard
👇关注晓天衡宇•评测社区官方账号,获取更多大模型相关知识~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 19
19 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)