2026原生音视频同步生成爆发,“声音”这块最后拼图如何补齐的?
电影史的早期,是一部纯视觉的默片史。
导演们很快意识到视觉与听觉剥离会破坏叙事的沉浸感,同步声轨随之普及。
如今的人工智能视频生成领域,正在经历完全相同的演进历程。
视觉画面的逼真度与时间连贯性已经达到极高水平,而脱离了合适声音环境的视频,依然会让观看者产生不自然感。
2025年底到2026年初,AI视频生成技术正式告别默片时代,原生视听同步大模型集体爆发,尤其像春节期间Seedace 2.0的完美表现,深刻改变了视频内容创作的方式。

一篇正在审查提交给TMLR期刊的论文,全面解析了多模态视频生成模型的发展脉络,涵盖核心架构演进、后训练与评估方法、前沿商业应用场景,深入探讨流式生成、数字人与世界模型等核心研究方向,揭示这项技术面临的真实挑战与未来演进路线。
架构演进
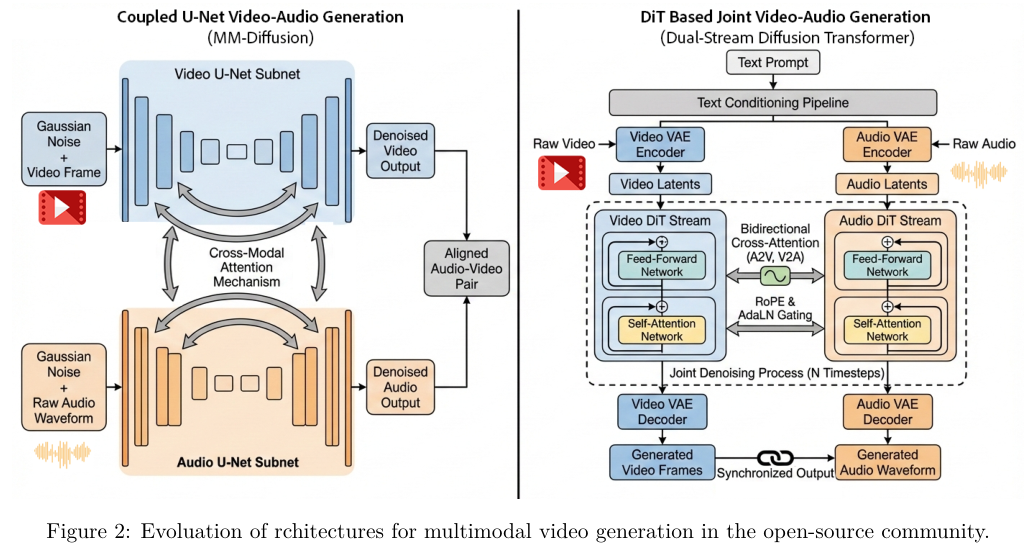
早期的多模态视频生成往往采用分离的管线,分别处理画面与声音。
现在开源与闭源模型已经转向联合建模的范式,直接在同一架构内同步生成视频帧与音频波形。
变分自编码器(VAE)在这一体系中扮演着底层压缩引擎的角色。原始视频与音频数据维度极高,直接处理计算成本极其高昂。
视频VAE通过包含空间与时间卷积的3D编码器,将输入视频序列压缩为时空潜在表示,捕获跨帧的运动动态。
音频VAE并行工作,将原始音频波形转化为包含声学特征与时间动态的音频潜在表示。
这种双通道并行编码机制,让模型能够在统一框架内处理异构数据类型。
架构的核心生成部分经历了从U-Net到扩散Transformer(DiT)的演替。
U-Net凭借编码器与解码器结构以及跳跃连接,在图像和早期视频生成中表现出色。多模态扩散模型MM-Diffusion就是首个基于耦合U-Net的开源框架,使用并行子网络处理视频与音频。U-Net的卷积操作具有局部性限制,难以捕捉长视频与音频之间复杂的长程依赖关系。
视觉画面中的一次爆炸,必须与音频序列中横跨较长时间窗口的轰鸣声精准对齐,DiT凭借自注意力机制带来的全局时空推理能力,顺理成章地取代了U-Net。
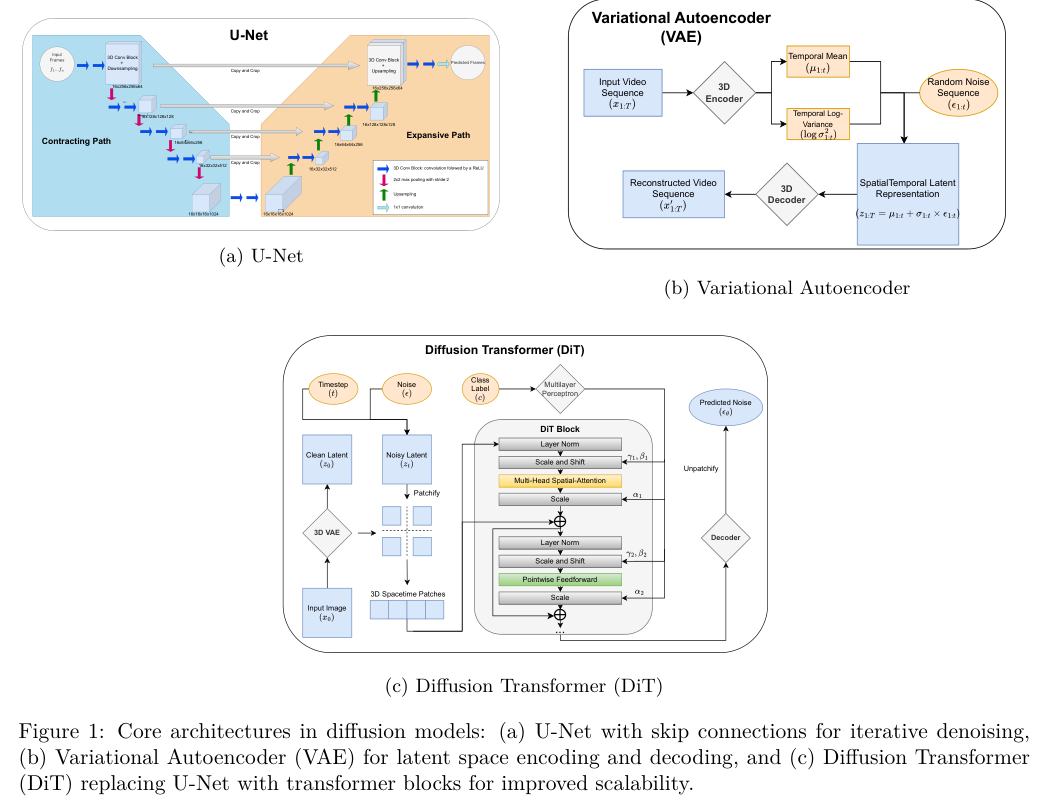
目前主流的双流扩散Transformer融合架构,是实现视听原生同步的关键。
文本提示词经过预训练语言模型编码后,输入到双流架构中。视频流与音频流各自拥有独立的自注意力机制以保持模态内一致性。系统通过双向交叉注意力机制进行跨模态通信,视频查询可以关注音频的键值,反之亦然。
这种交叉注意力引入了时间一维旋转位置编码(RoPE),保障跨模态的时间对齐,辅以自适应层归一化(AdaLN)控制信息流。推理阶段,视频与音频从独立的独立高斯噪声开始,在共享的去噪步数内并行联合去噪,最终由各自的VAE解码器重建为像素和波形。
为了应对大模型参数规模激增带来的计算成本,混合专家模型(MoE)正在成为未来的标准配置。
处理视听数据的MoE需要应对不同采样率与语义粒度的多模态词元。词元级别的MoE通过路由器为每个输入词元分配特定的专家网络,适合处理空间或时间上复杂度极度不均的区域。
时间步级别的MoE设计更具启发性,Wan 2.2模型为高噪声阶段(全局布局与运动规划)与低噪声阶段(外观与细节细化)分配不同的专家权重,在不增加推理额外开销的情况下实现了显著的质量提升。
对齐与微调
预训练基础模型往往难以直接满足特定的下游任务需求,后训练微调与对齐技术是将通用模型转化为实用生产工具的必经之路。
高质量的后训练数据制备需要极其精确的时间对齐。视频到音频(V2A)任务通常依赖AudioSet Strong等包含声音事件时间戳、音频字幕的精细标注数据集。联合视听生成则需要大规模同步的多模态数据对。
研究人员目前广泛采用多模态自动化管线,生成对齐的视频字幕、音频描述和语音转录文本,保障时间同步与语义一致性。
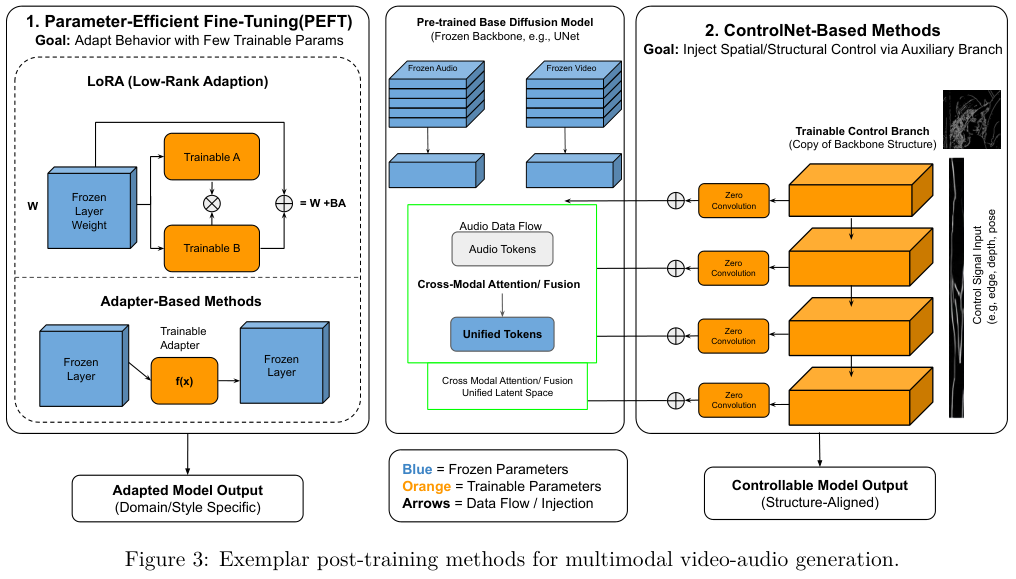
免训练方法可以在不修改基础模型权重的情况下实现视听对齐。系统在推理去噪阶段,通过操纵注意力分数或注入音频衍生的条件信号,引导视频生成与音频事件在时间上保持同步。
同步引导技术通过修改匹配流或扩散损失,放大运动剧烈区域的权重,引导生成过程贴合音频的节奏模式,无需重新训练即可显著提升口型同步效果。
参数高效微调(PEFT)通过引入极少量的可训练参数来调整千亿级大模型。低秩自适应(LoRA)将可训练矩阵注入现有的注意力层中,帮助纯视频模型快速适应音频生成任务。
适配器方法在冻结的主干网络层之间插入轻量级模块,例如FoleyCrafter模型使用语义适配器,通过并行的交叉注意力层将视频特征作为音频生成的条件,生成与视觉内容高度贴合的逼真音效。
多模态系统需要专门的模块来解决精准的时间与语义对齐难题。MMAudio模型引入了条件同步模块,利用Synchformer这种自监督音视频不同步检测器提取特征,在帧级别对齐视频条件与音频潜在表示。人类能察觉到小至25毫秒的音视频错位,这种模块提供的毫秒级时间相关性捕获能力极其关键。
对于视频生成音频任务,起音检测器利用视觉运动线索预测声音事件的发生时间,将时间戳信息通过适配器注入音频主干网络。
ControlNet架构为多模态生成提供了极其细粒度的控制能力。时间ControlNet复制了原有的网络结构,引入零初始化连接,注入时间控制特征。
面对包含语音、音效与背景音乐的复杂场景,多流时间ControlNet分别处理不同的音频分量,音效流控制口型与事件时机,全局流提取风格特征维持整体氛围。
评估基准
评价联合视听生成模型的优劣面临巨大挑战,自动化的定量指标与依赖人类判断的定性评估必须相互配合。
定量评估需要分别衡量独立模态的质量以及跨模态的对齐程度。
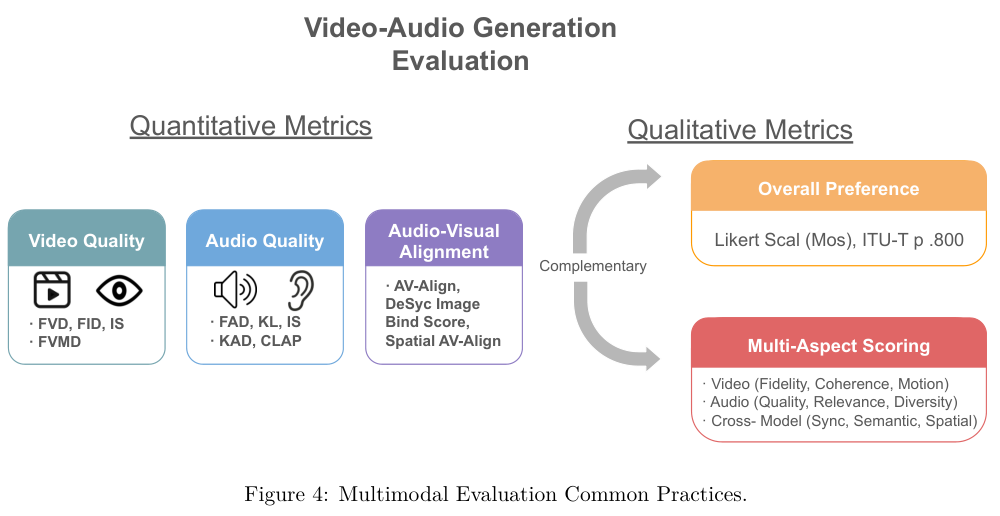
视频质量层面,Fréchet视频距离(FVD)通过测量生成特征与真实视频特征分布的差异,评估空间质量与时间连贯性。
CLIPScore计算生成视频的视觉嵌入与输入提示词嵌入的余弦相似度,衡量文本与视频的对齐度。
VBench系列基准则将质量拆解为动态程度、运动平滑度和美学质量等几十个细分维度。
音频质量评估广泛使用Fréchet音频距离(FAD),对比生成音频与参考音频在嵌入空间中的分布。
由于FAD基于高斯假设,研究人员引入了核音频距离(KAD)作为改进。文本条件的音频生成使用CLAP Score衡量匹配度。
最新的参考无模型指标开始利用音频语言模型通过文本提示直接对生成质量打分,摆脱对基准数据集的绝对依赖。
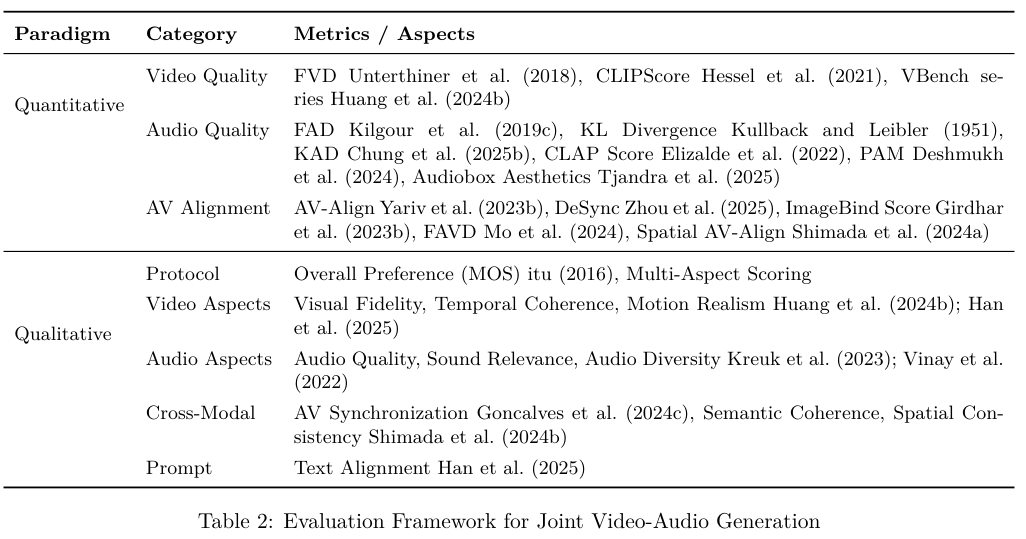
视听对齐指标专门考察声音是否对应可见事件。DeSync利用Synchformer量化以秒为单位的时间错位,ImageBind Score在共享嵌入空间中计算音视频表示的余弦相似度。空间AV-Align结合目标检测与声音事件定位,验证生成的声音是否源自视觉场景中正确的空间位置。
自动化指标经常无法捕捉人类感知的同步质量与语义连贯性,人工定性评估不可或缺。标注人员根据标准化协议,在五分制量表上为整体感官体验打分。
PEAVS框架提供了全面的感知同步评估协议,要求评估者对时间偏移、播放速度变化、内容对齐进行细致核查,对于立体声生成,甚至需要评估空间音频定位是否与画面物体位置吻合。
现实应用与前沿
伴随着模型扩展能力的突破,多模态内容创作走出了后期配音的传统模式。视觉元素与同步生成的环境音、对话、音效和音乐融为一体,商业市场正在迅速消化这一技术红利。
在社交媒体与个人娱乐领域,用户直接通过文本或图像生成包含匹配配乐的视听短片。借助音频驱动动画技术,一张静态照片配合一段音频,就能生成嘴型完美同步、面部表情丰富的动态视频,进一步模糊了真实与合成的边界。
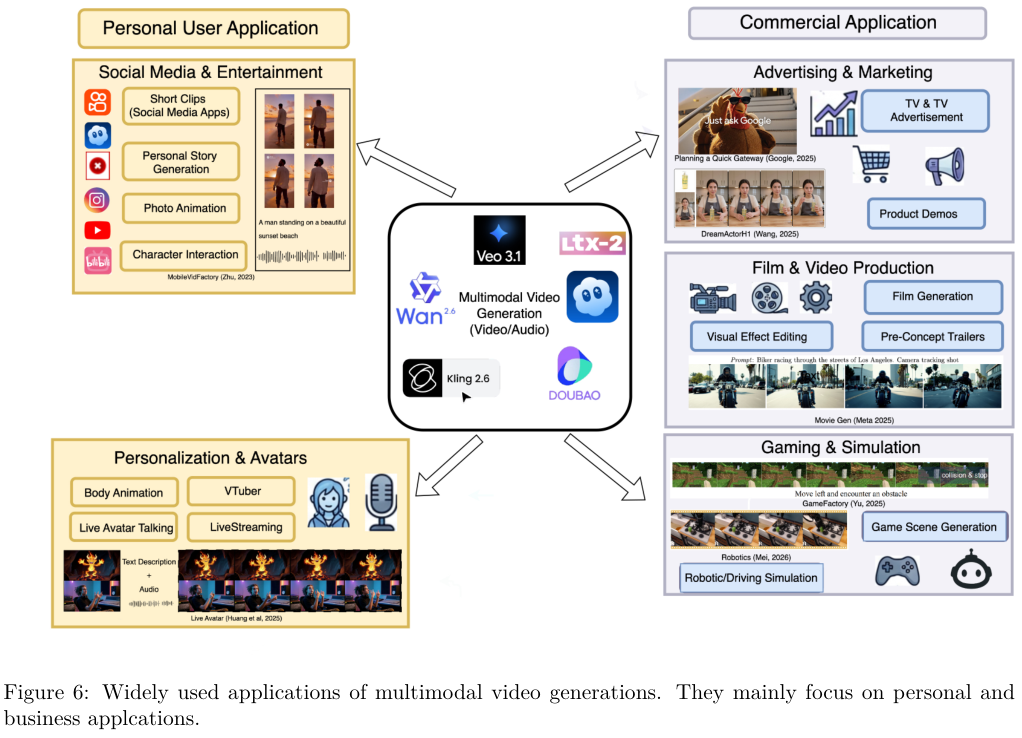
OmniHuman-1等模型已经支持从单张图像与音频信号生成全身说话、唱歌和带有伴随手势的复杂动作。
企业级应用将原生音频生成视为降低后期制作成本的核心差异化能力。
Google利用Veo 3制作了包含生成式对话与配乐的完整电视商业广告。Adobe Firefly平台整合了多模态生成管线,一键生成与画面完美踩点的录音室级背景音乐与清晰的画外音。游戏开发商借助ElevenLabs等技术,为NPC提供低延迟的实时语音生成,彻底摆脱了海量预先录制语音库的限制。
应用市场的繁荣倒逼学术界攻克更棘手的技术前沿。
流式多模态生成要求在极低的延迟下实时逐帧输出视听内容。这对因果时间建模提出了严苛要求,当前帧的生成只能依赖历史帧和潜在状态,无法窥视未来。长序列生成导致内存中的键值(KV)缓存成为瓶颈。模型还需要在不依赖真实数据强制引导的情况下,自行解决长时间生成带来的画面漂移与视听失步问题。

超长多模态视频生成需要在几分钟甚至无限长的尺度上保持叙事一致性。单发生成方法利用潜在缓存和滚动注意力窗口逐帧推进,多发生成方法将视频切割分段,利用记忆机制保持跨段落连贯。
最新的代理化叙事系统引入了迭代规划与评估机制,利用脚本代理生成可执行代码来指引跨场景的生成,确保音效、音乐在场景切换时自然过渡。
物理世界的感知本质上是多模态的。世界模型正在从纯视觉模拟转向包含声音的生成式模拟器。声音能透露出视野之外的物体位置、空间的材质特征与声学结构。
最新的视听世界模型在生成逼真画面的同时,能够通过语言驱动的3D定位渲染出撞击声,甚至基于画面深度信息和少量参考信号合成房间的混响效果。
这为具身智能体提供了极具价值的训练环境,机器人可以利用合成的声学线索在虚拟空间中学习导航与操作。
高歌猛进的技术浪潮背后依然存在不容忽视的局限性。
许多主流音频评估指标基于降采样的单声道数据,完全丧失了对高频细节和立体声特征的敏感度。
实时交互场景下,同步视听数据流的高昂计算开销会带来延迟,严重破坏人机交互体验,激进的模型压缩技术又往往以牺牲时间连贯性为代价。
将文本、视频、音频在同一个分词器下统一编码,极其容易产生模态幻觉,模型经常过度依赖强烈的文本语义信号,从而忽略了细微的声学纹理。
跨越这些架构与评测的障碍,将是下一代大模型真正走向物理世界模拟的必经之路。
参考资料:
https://openreview.net/forum?id=8i5vInabkm

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献115条内容
已为社区贡献115条内容

所有评论(0)