都在押注VLA,小鹏与理想两家技术有何不同?

「深度解析两大VLA模型」
2026年3月,小鹏与理想相继发布了各自的VLA大模型——小鹏第二代VLA与理想MindVLA-o1。
两家头部新势力不约而同地将VLA作为自动驾驶迈向更高阶智能的杀手锏,标志着行业正式从"感知识别"迈向了"理解决策"。
然而,在这场通往具身智能的终局之战中,两家在架构上却走向了截然不同的岔路口:
小鹏选择了"去语言层"的纯视觉端到端路线,追求极致的执行效率与丝滑体感;而理想则保留了语言层,构建原生多模态统一训练体系,偏向长期能力的体系化构建。本文将深度拆解这两大VLA模型的技术亮点与落地策略,带你一探究竟。
01 路线分歧的十字路口:要不要"语言层"?
在探讨两家的技术特色之前,我们需要先理解VLA模型的核心价值。过去的智驾系统像是一个经验丰富的"反射神经",看到红灯就停,看到障碍物就绕,但它并不理解"为什么"要这么做。VLA模型则把人类的常识、逻辑推理能力与驾驶行为直接挂钩,让车辆做到了"看懂世界、理解意图、做出动作"。
然而,在如何实现这一目标上,小鹏和理想产生了根本分歧:中间的"语言层"到底要不要保留?
小鹏的答案是"不要"。小鹏VLA 2.0采用的是"视觉→隐式Token→动作"的架构。他们认为,显式的语言转译(即先用自然语言描述场景,再转化为动作)会带来不必要的延迟和信息损耗。因此,小鹏彻底抛弃了显式语言转译,让视觉信号直接生成连续的驾驶动作。用小鹏自己的话说:"从来没有人在VLA中去掉语言转译" 。
理想的答案则是"保留"。理想MindVLA-o1采用的是原生多模态统一训练架构,保留了语言模型在语义理解、常识知识和交互能力上的核心作用。通过引入"系统2"的显式推理能力,模型能在复杂场景中进行更深层次的因果分析和决策推演 。

图 | 小鹏官方展示的标准VLA与创新VLA架构对比。小鹏是行业首个在VLA中去掉语言转译的厂商,并行研发两套方案:一套保障底线,一套探索上限。(来源:小鹏汽车发布会)
02 小鹏VLA 2.0:去语言层的"物理AI"极致重构
小鹏第二代VLA的核心逻辑非常清晰:既然物理世界的数据量巨大且连续,那就通过最强悍的算力底座和最高效的模型架构,直接去消化这些海量信息,追求产品化和数据闭环的极致效率。
纯视觉端到端的极简暴力美学
小鹏VLA 2.0靠物理世界因果推理,直接输出方向盘、油门、刹车的连续控制信号。因为去掉了语言转译的中间环节,其决策延时从传统的200ms大幅降至80ms以内,效率提升了12倍 。据测试,这种架构下的动作输出极其丝滑、无顿挫,在处理前车减速、行人横穿等动态场景时,决策不会出现明显跳变。
此外,小鹏还设计了原生多模态Tokenizer,以极高效率进行早期融合,避免单一模态偏差。同时引入了视觉推理思维链(COT),让模型能自动生成变道超车、寻找空间或跟车等多种解决方案,并对每种行为进行打分择优 。

图 | 小鹏第二代VLA的三大核心支柱——大模型、大算力、大数据。其中大模型行业首次去掉语言转译,大算力依托自研图灵芯片实现2250TOPS行业最高有效算力,大数据训练量近1亿帧视频数据,相当于驾驶65000年。(来源:小鹏汽车发布会)
软硬协同的算力压榨
小鹏深知,端侧部署的效率红线是决定体验的关键。为此,他们通过自研的图灵AI芯片,将硬件的有效算力发挥到了极致。在小鹏的架构中,模型与芯片指令集、AI编译器深度绑定,实现了"芯片-算子-模型"全链路优化。这种"软硬结合"让1颗图灵芯片的有效算力接近10颗Orin-X,最高有效算力达到2250TOPS,算力利用率从传统的22.5%飙升至82.5%。

图 | 小鹏自研图灵AI芯片全链路优化效果。图灵AI芯片提供3-22倍算力提升,针对性优化算子提升12倍,第二代VLA模型参数较行业主流提升10倍。通过芯片-算子-模型的全链路优化,突破行业车端模型能力上限。(来源:小鹏汽车发布会)
世界模型与自我博弈
在训练端,小鹏引入了世界模型与Self-Play(自我博弈)机制。通过世界模型生成海量的优质长尾场景用于仿真测试,小鹏的仿真Case从一年前的3万增加到了50多万个,每日仿真测试里程等效于3000万公里实车测试。在Self-Play机制中,VLA模型输出动作,世界模型生成新场景,两者实时动态博弈、自我进化,极大地加速了模型的迭代速度。
在数据规模上,小鹏的云端单次训练高质量数据达50PB(约为一般语言大模型的20倍),单次训练Token数量高达4万亿(4T),过去大半年更新了468版十亿参数级大模型,日均近4版。

图 | 小鹏基于世界模型的仿真测试体系。世界模型生成大量优质长尾场景用于仿真测试,仿真场景从一年前的3万增加到50多万个,每日仿真测试里程等效于3000万公里实车测试。(来源:小鹏汽车发布会)
务实的落地策略与性能表现
在落地方面,小鹏采取了"分层产品策略"。高算力平台(Ultra版)承载完整能力,然后通过蒸馏压缩技术,将核心能力下放到中低算力车型(Max/Pro版)。2026年的目标是安全接管里程提升50倍、平均智驾里程提升25倍、车端模型参数量提升至200亿以上,并在年底前正式开启Robotaxi无人化运营 。
从实际性能数据来看,小鹏第二代VLA在多项指标上表现亮眼:综合行车效率提升23%,小路通行效率提升76%,人车混行道路通行效率提升69%,城区通行效率提升21%,园区道路通行效率提升97%,早晚高峰通行效率提升28% 。
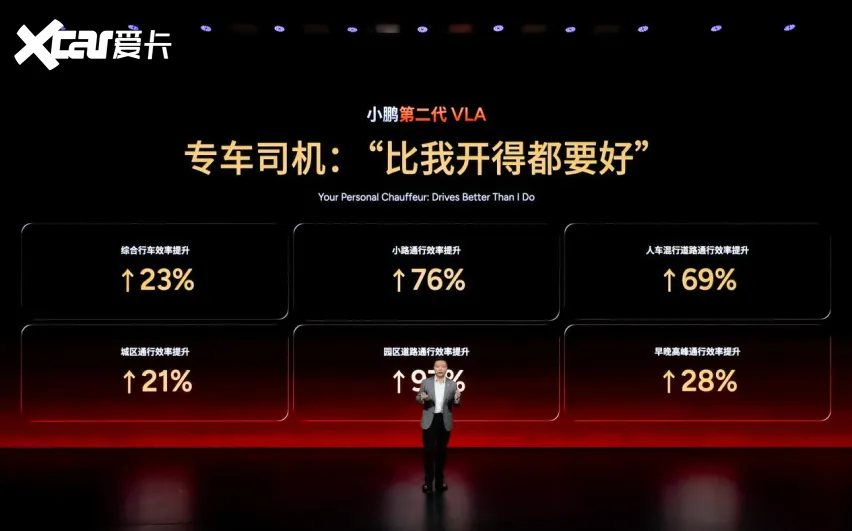
图 | 小鹏第二代VLA实测性能数据,专车司机评价"比我开得都要好"。综合行车效率提升23%,小路通行效率提升76%,人车混行道路通行效率提升69%,城区通行效率提升21%,园区道路通行效率提升97%,早晚高峰通行效率提升28%。(来源:爱卡汽车)
03 路线分歧的十字路口:要不要"语言层"?
理想MindVLA-o1:保留语言层的原生多模态体系
相比小鹏的"快准狠",理想MindVLA-o1则是一条更偏体系化、强调长期能力构建的路线。它不只是一个自动驾驶模型,更是一个正在逐渐进化的物理世界基础模型,剑指未来的具身智能。
原生多模态统一训练
MindVLA-o1是一个原生多模态的MoE Transformer。它在设计之初就统一将视觉、语言、行动三种模态进行联合训练,而不是先分别训练再组合。这种设计让不同模态在同一个表示空间中共同对齐,获得了更高的效率和更强的泛化能力。其核心骨干网络MindVLA-o1-MoE同时支持"快思考"(fast)和"慢思考"(slow)两种模式,在一个模型内实现了双系统的统一。

图 | 理想MindVLA-o1完整架构图(Omni-Paradigm with Unified VLA Model)。输入端整合导航、位姿、GPS、摄像头、激光雷达和语言指令,经过Encoder、3D ViT Encoder和Text Tokenizer编码后,进入MindVLA-o1-MoE核心网络(支持fast & slow双模式),输出端分为Decode Output(推理决策、隐式世界模型)和Action Output(驾驶轨迹)。底部展示七大核心技术创新模块。(来源:理想汽车GTC 2026发布会)
3D视觉与隐式世界模型
理想明确引入了3D建模能力。通过自研的3D ViT Encoder结合激光雷达点云,在编码阶段直接构建3D空间表示,而非简单将2D图像和3D信息拼接。该编码器使用下一帧预测作为自监督信号,同时学习深度信息、语义结构与物体运动,强调"物理一致性" 。
同时,MindVLA-o1引入了预测式隐式世界模型(Predictive Latent World Model)。与直接生成未来真实图像不同(计算成本太高),该模型在隐空间(latent space)中推演未来几秒的场景变化,理想将其称为"多模态思考"(Generative Multimodal Thinking)。这对于提升复杂路口的决策稳定性至关重要 。
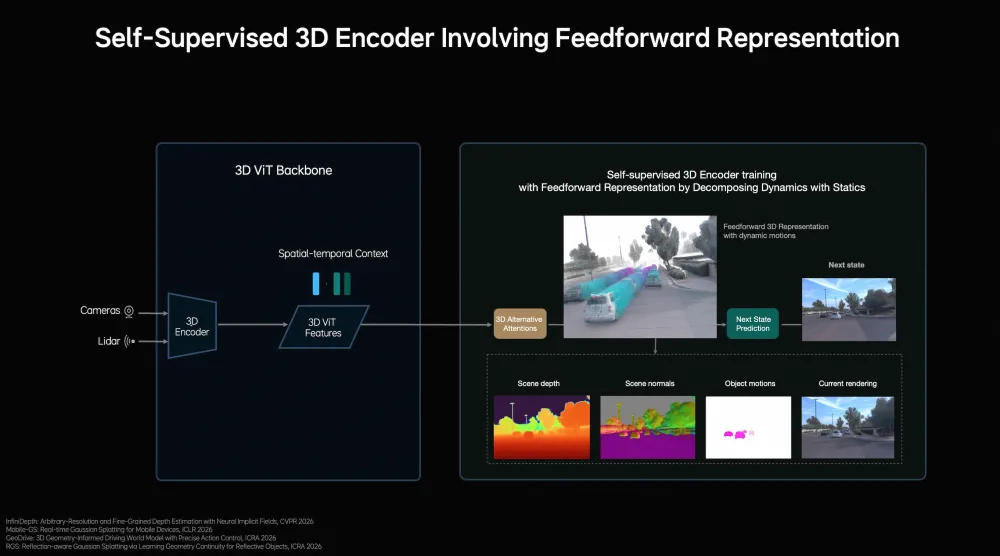
图 | 理想自研的Self-Supervised 3D Encoder架构。左侧为3D ViT Backbone,融合摄像头和激光雷达输入,生成包含空间-时间上下文的3D ViT特征;右侧展示自监督训练过程,通过分解动态与静态元素的前馈表示学习,同时输出场景深度(Scene depth)、场景法线(Scene normals)、物体运动(Object motions)和当前渲染(Current rendering)。(来源:理想汽车GTC 2026发布会)
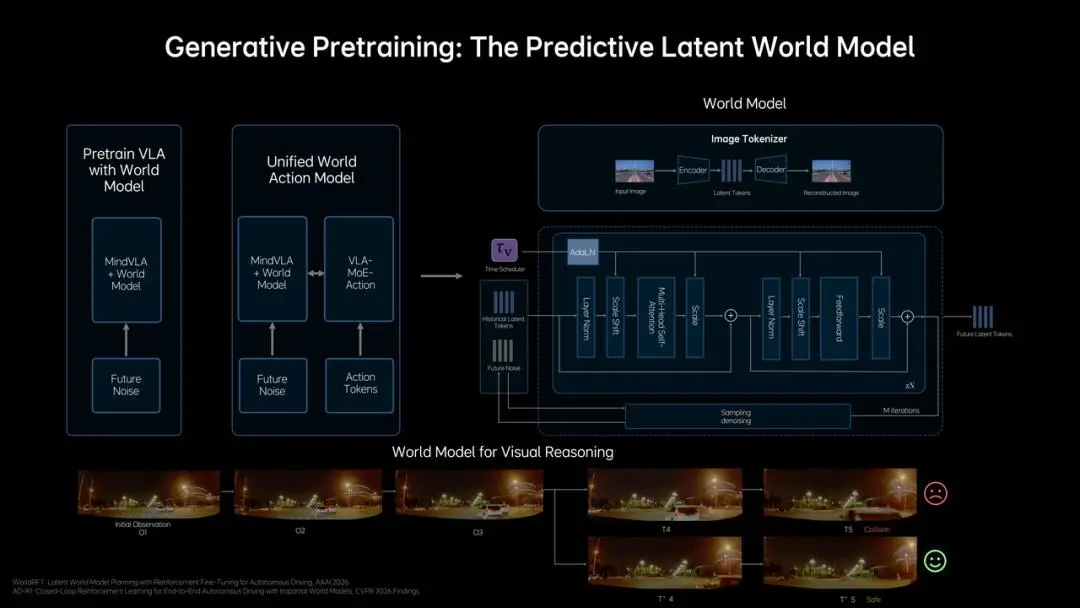
图 | 理想MindVLA-o1的预测式隐式世界模型(Predictive Latent World Model)架构。左侧展示训练流程:先预训练VLA与世界模型,再统一为Unified World Action Model;右侧展示世界模型的推理过程,通过Image Tokenizer编解码和多步迭代去噪生成未来隐式Token。底部为World Model for Visual Reasoning的可视化示例,展示模型如何预测未来场景并避免碰撞。(来源:理想汽车GTC 2026发布会)
动作生成的"三重保障"
在生成驾驶轨迹时,理想采用了Action Expert(动作专家)结合Parallel Decoding(并行解码)与Discrete Diffusion(离散扩散)的技术组合。VLA-MoE架构中引入专门的Action Expert,从3D场景特征、导航目标、驾驶指令中提取信息。
Parallel Decoding让所有轨迹点同时并行生成(非自回归),保证了生成速度。Discrete Diffusion则通过N步迭代对轨迹进行逐步去噪和精修,保证了轨迹在物理空间上的精度和连续性。三者配合,MoE保证专业性,Parallel保证速度,Diffusion保证精度 。
闭环强化学习与四大组件体系
为了突破真实数据的长尾限制,理想构建了完整的Physical AI Framework,包含四大核心组件:MindData(统一VLA数据引擎,负责大规模驾驶数据的采集、清洗和自动标注)、MindVLA-o1(原生多模态VLA模型)、MindSim(可控多模态世界模型,支持场景生成和闭环训练测试)以及RL Infra(强化学习基础设施,包含Reward Model和VLA Policy)。在MindSim中,模型可以不断尝试新策略并根据奖励反馈进行优化,使系统具备极强的自我进化能力 。
在软硬件协同方面,理想评估了接近2000种不同模型架构配置,在Orin和Thor平台上验证后发现:端侧计算资源受限时,更宽且更浅的模型结构比传统深层模型更有效,将模型架构探索时间从数月缩短到几天 。
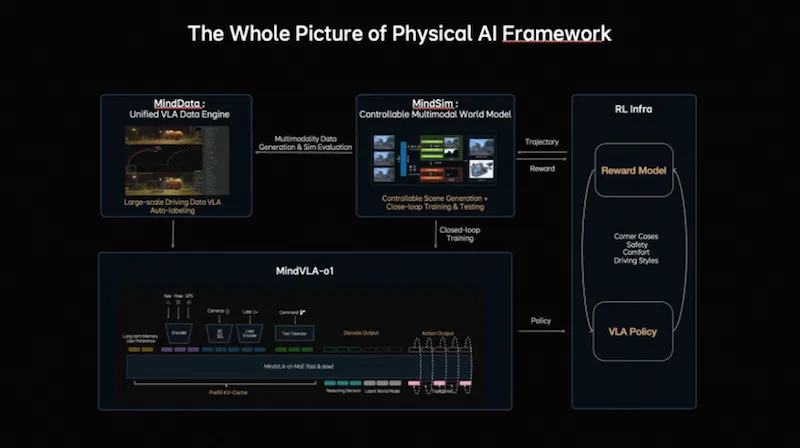
图 | 理想汽车Physical AI Framework全景图。由MindData(统一VLA数据引擎)、MindSim(可控多模态世界模型)、RL Infra(强化学习基础设施,含Reward Model和VLA Policy)以及核心的MindVLA-o1模型四大组件构成完整闭环。MindData负责大规模驾驶数据自动标注,MindSim支持可控场景生成和闭环训练测试,RL Infra通过奖励模型持续优化VLA策略。(来源:理想汽车GTC 2026发布会)
04 核心对比总结
通过以上分析,我们可以将两家的技术路线差异系统性地梳理如下:
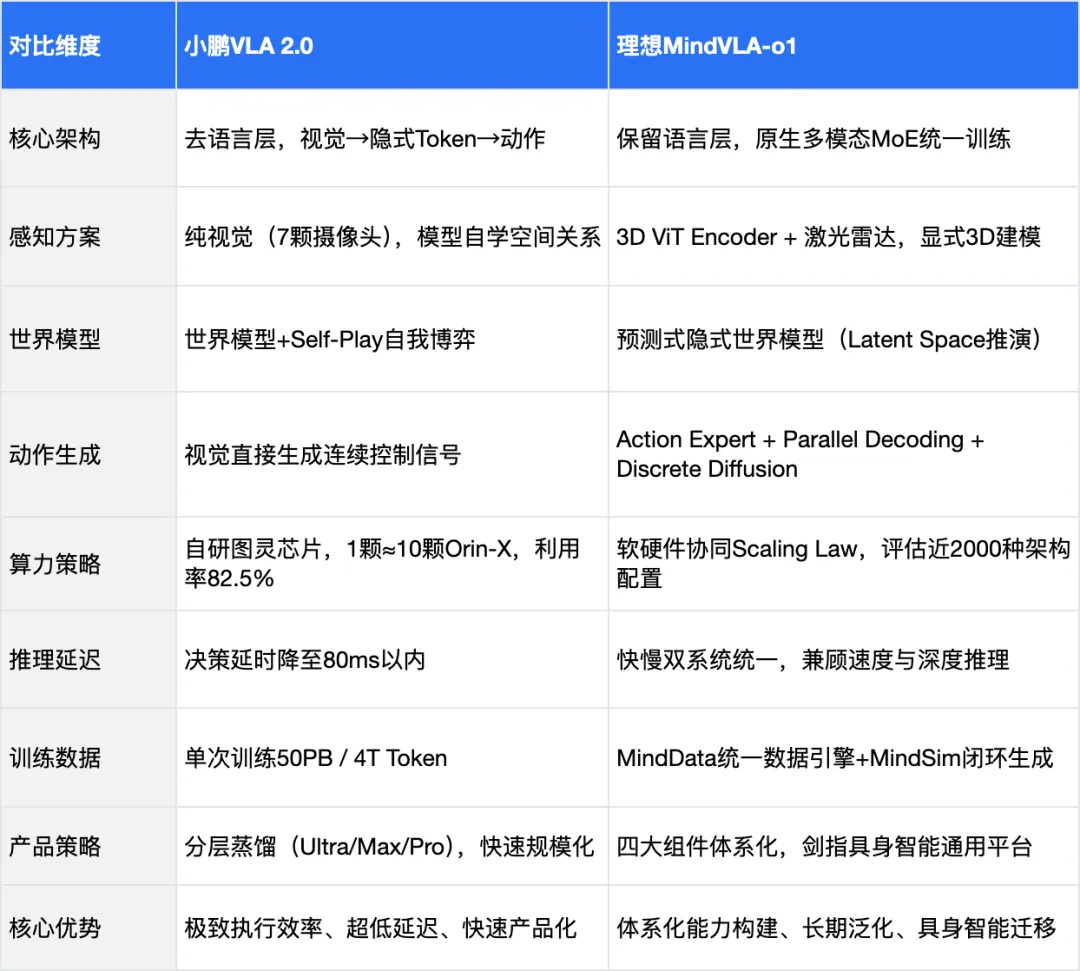
05 殊途同归的具身智能之路
对比小鹏和理想的VLA方案,我们可以清晰地看到两家在解决自动驾驶上限问题时选择了不同的发力点。
理想是在提升系统的"智商":通过构建完整的物理模型和保留语言推理能力,让车学会像人一样去思考因果逻辑,在未知环境中找到最优解。其优势在于场景还原度高、预测精度准、长期泛化能力强。
小鹏是在重构系统的"身体":通过抛弃繁琐的语言层,重构底层芯片与编译器,释放大模型的执行潜力。其优势在于极致的爆发力、超低的端侧延迟以及极高的产品化效率。
目前来看,端侧部署的效率依然是最大的挑战。小鹏从底层硬件重构的路径,在短期内具有极强的体验护城河;而理想通过世界模型实现的闭环强化学习,则在数据获取成本和模型进化上限上描绘了更宏大的蓝图。
无论是小鹏的"物理AI"极致重构,还是理想的"原生多模态"体系构建,两者都在加速自动驾驶向具身智能演进。未来,这两条路线极有可能殊途同归——在拥有强大硬件底座的基础上,通过世界模型进行大规模的自我进化。最终受益的,将是每一个期待更安全、更智能出行体验的用户。
参考资料
[1] 小鹏分享物理AI涌现成果:发布第二代VLA、Robotaxi、全新一代图灵芯片. OFweek新能源汽车网, 2026-03-03.
[2] 詹锟讲理想下一代自动驾驶基础模型MindVLA-o1. 知乎, 2026-03.
[3] 全球自动驾驶元年 ,小鹏第二代VLA率先量产,给出中国答案. 爱卡汽车, 2026-03.
[4] 理想MindVLA-o1基础模型相比上一代有哪些变化 ,与小鹏VLA 2.0有什么不同? 第一电动, 2026-03.
[5] 小鹏和理想均押注VLA ,两者技术各有啥特色? 知乎, 2026-03.
[6] 理想汽车发布下一代自动驾驶基础模型MindVLA-o1. 央视网, 2026-03-18.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)