区域预测挺准,单站却稀碎?基地化运营最缺的不是算法,是“私家订正”那一步
2026年4月,某新能源央企的集控中心大屏上,滚动着旗下17个风电场的实时出力数据。区域功率预测系统给出的总出力曲线与实发值高度吻合,整体准确率达到92%。可切换到单站视图,画风骤变——3号场站预测准确率只有81%,7号场站不到78%,偏差最大的9号场站,实发值与预测曲线几乎走出了两条不相干的轨迹。
集控中心主任苦笑:“区域总算账,考核能过关。但拆开看,一半场站在裸奔。”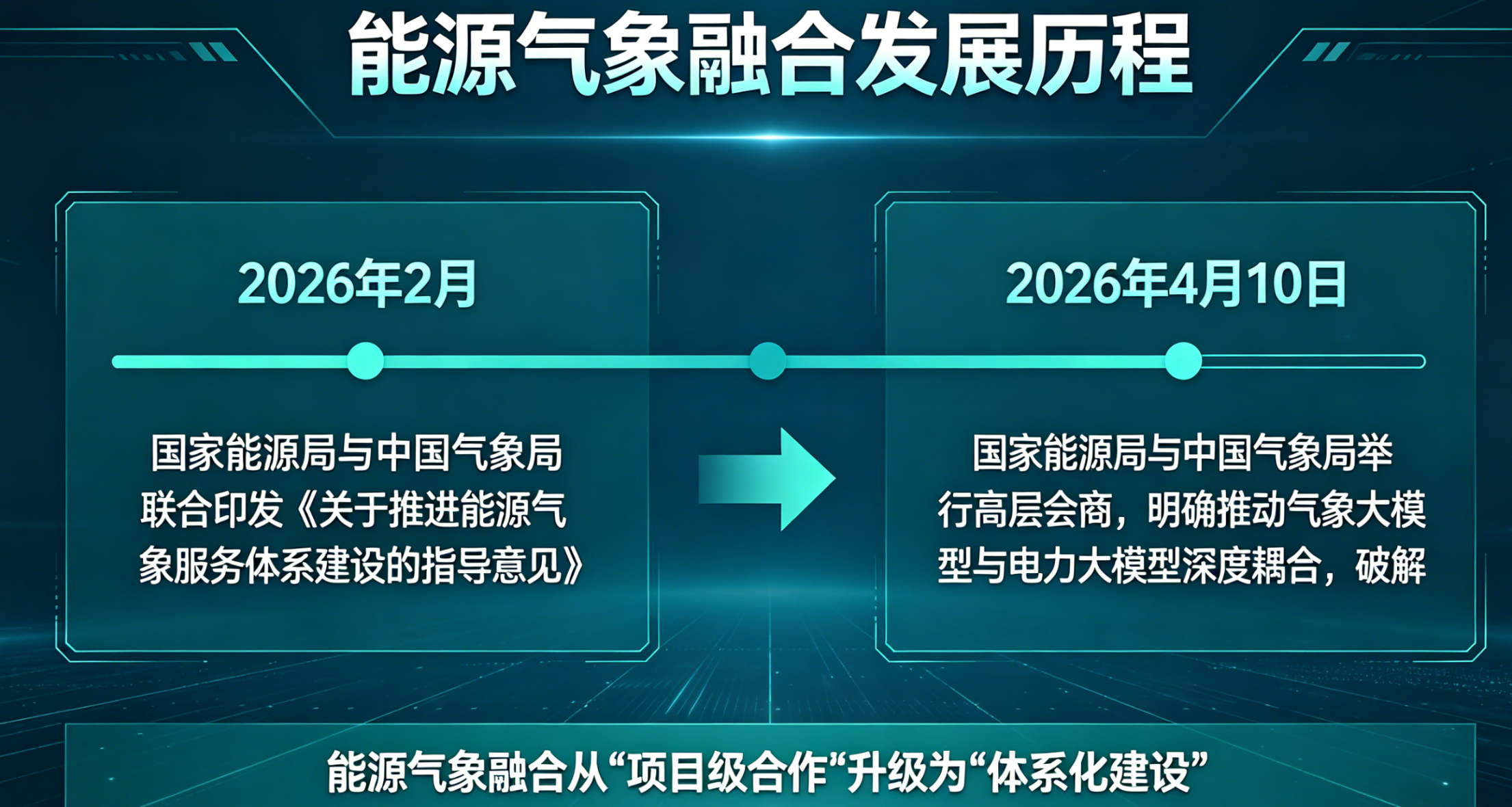
这不是孤例。随着“沙戈荒”大基地、海上风电集群、流域水风光一体化项目加速落地,基地化运营已成为新能源行业的常态。区域功率预测系统的整体精度往往“拿得出手”,可一旦下沉到单站、单机,预报与实发的偏差足以吃掉一个场站全年的利润。宏观过关、微观失守——这道裂缝正在被电力市场规则越撕越大。
政策与气象合力:区域预测的“宏观红利”
区域功率预测之所以“看起来挺准”,背后有两股力量在托举。
政策端,2026年4月10日,国家能源局与中国气象局举行高层会商,明确提出推动气象大模型与电力大模型深度耦合,着力破解新能源功率精准预测“卡脖子”难题。同年2月,两局联合印发的《关于推进能源气象服务体系建设的指导意见》正式落地,能源气象融合从“项目级合作”升级为“体系化建设”。
气象端,《全球风光水发电能力年景预测2026》基于中国气象局第三代气候系统模式,融合深度学习算法将均方根误差平均降低50%以上,空间分辨率持续优化。这意味着大尺度气象预报的“底图”越来越清晰——区域整体的风速、辐照度趋势,正在被更准确地捕捉。
两股力量叠加,区域级功率预测享受了尺度红利:大面积平均天然平滑了局地波动,算法从海量历史数据中习得的规律在区域层面高度稳健。就像气象台预报“全市平均风力4-5级”,这个判断大概率是对的——但具体到你站的那条山脊,是3级还是7级,那是另一回事。
区域预测的“准”,掩盖了单站预测的“碎”。
单站为何“稀碎”:从微气象到微地形
拆开区域平均值的面纱,单站预测面临的挑战来自三个维度。
第一,微气象的“局地任性”。 数值天气预报的空间分辨率通常在3-10公里量级,而复杂地形下的风速、风向在百米尺度上就可能发生显著变化。山地风电场的风机分布在海拔落差数百米的山脊上,山谷风的局地环流、不同坡向的湍流强度差异,使得各机位的风速差异可达50%-80%。一套区域模型吃遍所有机位,等于用同一把尺子丈量山南山北——精度从根上就不可靠。
第二,预报与实况的“系统性漂移”。 三峡集团在内蒙古四子王旗吉红光伏电站的实践揭示了一个典型问题:数值预报的辐照度数据与场站实测值之间存在系统性偏差,且这种偏差随时间推移、季节更替而漂移。研究团队引入风云卫星数据对预报结果进行滚动订正,才将未来10天辐照度预报精度提升了5个百分点,短期光伏功率预测准确率提高3个百分点。这说明单站预测的瓶颈不在“大模型”,而在本地化订正——让预报向实况靠拢的那一步。
第三,数据分布的“时空漂移”。 新能源装机在近三年经历了爆发式增长,场站周边的地表覆盖、局地气候特征都在动态变化。三年前的历史数据训练出的模型,面对今天的场站环境和机组状态,预测结论天然“失真”。龙源电力在山西的实践提供了佐证:通过分析短期预测的惯性偏差特征,提取历史相似气象背景下的偏差序列,对预测结果进行分时段二次修正,准确率较国内外对标场站高出1-3个百分点。
三个维度的挑战指向同一个结论:区域预测解决的是“天”的问题,单站订正解决的是“地”的问题——天有定数,地有脾气。
基地化运营的“私家订正”:一场一策的本地化适配
问题的症结清楚了:不是预测算法不够先进,而是算法从“区域”到“单站”的迁移过程中,缺少了关键的本地化适配层。
某集团疾风方案的实践提供了一套可借鉴的思路。团队自主研发的功率预测算法库,在5个陆上风电场、2个海上风电场及2个高海拔光伏场站部署时,采取的是因地制宜、一场一策的策略——不是拿一套模型去套所有场站,而是针对每个场站的气候环境、地形特征、机组特性,灵活选配算法模块。
这套“私家订正”体系包含三个关键环节:
其一,微尺度气象再分析。 针对数值天气预报在局地尺度的偏差,利用中尺度数值模式与计算流体力学技术耦合,将预报空间分辨率从公里级下探至百米级甚至单机轮毂高度。天津滨海供电公司的实践进一步验证了这条路径:与中国科学院地理所合作,引入遥感卫星云图作为补充数据源,构建了更小区域、更精准的气象预测模型。
其二,历史偏差特征挖掘。 每个场站的预测偏差都有“脾气”——有的在特定风向区间系统偏高,有的在早晚时段规律性偏低。通过分析历史预报与实况的偏差序列,提取偏差与气象要素、时段、季节的关联规律,形成场站级的偏差特征库。当新的预报结果生成,系统自动匹配历史相似偏差模式进行订正。
其三,模型滚动重训练。 针对数据分布漂移问题,采用“近期窗口+轻量模型”策略——仅选取最近3-6个月数据,用MLP等轻量架构快速重训练,让模型持续适应场站环境和机组状态的变化。这与龙源电力“分时段修正”的思路异曲同工:不追求一个固定模型包打全年,而是让模型随季节滚动、随场站进化。
三项技术手段的共同指向是:让气象预报从“区域公用”变为“场站专用”。这需要的不是算法革命,而是工程化适配能力——把先进预测技术“翻译”成每个场站听得懂的本地语言。
2026年的市场倒逼:单站偏差不再只是技术问题
“私家订正”之所以在2026年变得紧迫,根源在于电力市场规则的变化。
现货市场颗粒度加速细化。 山西电力现货出清周期已压缩至5分钟,实时电价一天跳动288次。单站预测偏差不再只是“考核扣分”,而是直接关联每一笔现货交易的偏差结算费用。区域整体过关掩盖不了单站失守——交易是按场站、按机组的发电曲线结算的。
中长期与现货衔接要求报量报价。 国办发〔2026〕4号文明确2027年前现货市场全面转入正式运行,发用两侧全面报量报价。场站级预测偏差会导致中长期合约量价与结算量价产生显著差异——这是新能源参与现货市场的核心风险敞口。
容量电价机制强调可靠性。 发改价格〔2026〕114号文要求调节性电源“切实发挥支撑调节作用”,并建立严格的容量电费考核机制。虽然直接约束的是调节性电源,但对新能源而言,功率预测的准确性直接影响系统对调节能力的需求评估——预测偏差越大的场站,在容量市场中的隐性成本越高。
当偏差从“技术指标”变成“财务指标”,单站预测精度的每一分提升,都直接对应结算单上的真金白银。区域预测的“宏观体面”救不了单站预测的“微观失血”。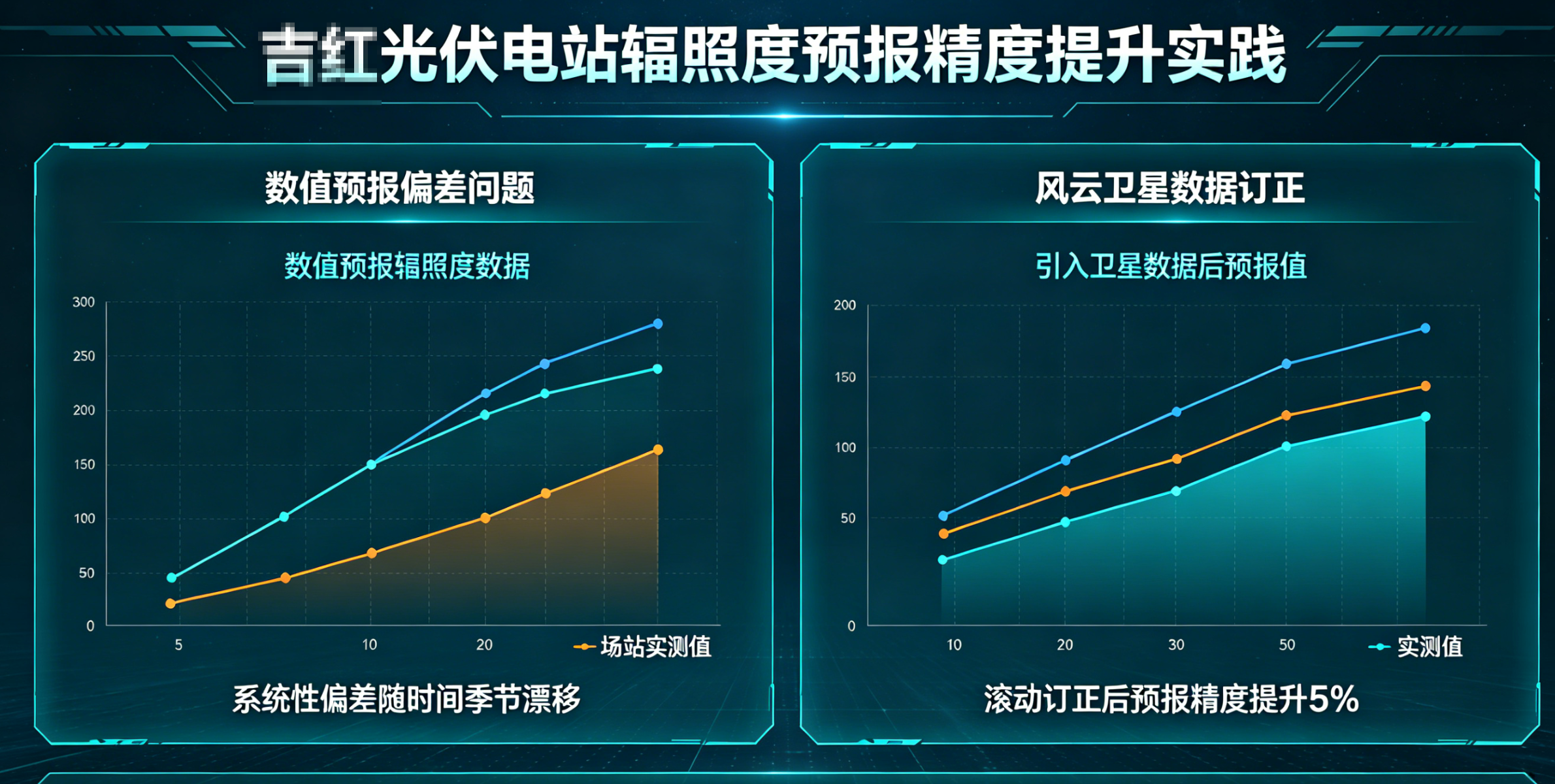
补上那一步
回到基地化运营的核心命题:区域预测挺准,单站稀碎——中间差的那一步,究竟是什么?
不是更强大的算力,不是更复杂的模型架构,而是从“普适预测”到“场站适配”的工程化能力。具体而言:
-
每一个场站需要自己的微气象再分析模块,把公里级预报降到百米级;
-
每一个场站需要自己的偏差特征库,记录什么天气下预报会偏多少;
-
每一个场站需要自己的滚动重训练机制,让模型随季节和环境变化持续进化。
这不是“算法创新”能一次解决的,而是运营体系的重构——把功率预测从“集中式作业”变成“分布式适配”,从“一套模型打天下”变成“一场一策、一机一策”。
三峡集团“一场一策”的算法库部署、龙源电力“分时段修正”的实践、天津滨海“遥感订正”的探索——头部玩家的共同选择已经指明了方向:私家订正不是锦上添花,而是雪中送炭。
气象大模型与电力大模型的深度耦合解决的是“天有多准”的问题,国家层面的预测体系建设解决的是“宏观趋势”的问题。但落到每一个场站的结算单上,决定利润的是那一步本地化适配——把区域预测的宏观红利,兑现为单站精度的微观胜势。
区域预测挺准是起点,单站不再稀碎才是终点。中间差的这一步,恰恰是2026年电力市场竞争中最不能被忽视的护城河。
关键字:区域预测挺准,单站却稀碎?基地化运营最缺的不是算法,是“私家订正”那一步

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)