RAG面试官必问:BM25、Embedding、RRF混合检索,手把手教你选对方法提升大模型效果!
本文从面试场景切入,详细解析了RAG检索中稀疏检索(BM25)、密集检索(Embedding模型)和混合检索(RRF策略)的原理、优缺点及实战对比。文章强调检索质量对大模型回答的关键作用,阐述了准确率、召回率与性能之间的权衡,并提供了混合检索的多种技术选型方案及落地实施建议。通过阅读本文,读者能够掌握RAG检索的核心方法,提升系统效果,并在实际项目中优化大模型的回答质量。
摘要:RAG(Retrieval-Augmented Generation)中,检索(Retrieval)是决定大模型回答质量的“第一关”。本文从面试场景切入,层层拆解稀疏检索(BM25)、密集检索(Embedding模型)、混合检索(RRF策略)的原理、优缺点与实战对比,并分享落地实施的性能/准确性权衡点。无论你是AI开发者还是产品经理,读完都能掌握RAG检索的核心方法,提升系统效果。
预计阅读时间:18分钟
想象一下,你正坐在面试官对面,屏幕上投出一行代码,面试官微微一笑:“小伙子/姑娘,RAG你用过吧?检索(retrieval)环节有哪些方法?为什么有的项目用BM25,有的用Embedding,还有的非要上Hybrid?说说看,你怎么选?”
这个问题一出,很多候选人瞬间卡壳。别慌,今天这篇文章,就把RAG检索的“前世今生”给你讲透。从稀疏到密集,再到混合搜索,我们一步步拆解原理、痛点、算法、对比、落地方案,最后给出实战建议。读完,你不仅能自信回答面试官,还能在实际项目里把大模型的回答质量拉高一个档次。
为什么检索这么重要?因为RAG的核心逻辑是“先找资料,再让大模型生成答案”。检索质量直接决定了“资料”准不准、够不够。如果检索漏掉关键信息,或者拉来一堆无关内容,大模型再聪明,也只能“巧妇难为无米之炊”,甚至产生幻觉(hallucination)。你有没有想过:同样一个用户问题“如何优化Kafka消费者延迟?”,为什么有的RAG系统回答精准到代码级,有的却东拉西扯?答案的关键就在检索环节(所谓七分检索,三分回答)。
一、检索质量对大模型回答质量的重要性
大模型(如GPT系列、Llama)本质上是“统计模式匹配机”,它们基于海量数据训练,但知识是“冻结”的。RAG通过外部知识库实时注入最新、最相关的上下文,让模型“现学现用”。检索环节就是这个“注入”的入口。
实验数据表明:检索召回率(Recall)每提升10%,最终答案的准确率(Accuracy)可提升15-25%;而检索精度(Precision)低时,模型幻觉率会飙升30%以上。为什么?因为大模型会“尽最大努力”用检索到的上下文生成答案,如果上下文噪声多,它就容易编造细节。
你有没有遇到过这种场景:问AI“公司内部的某个错误码ERR_CONN_RESET_4XX怎么解决”,它却给你一堆通用网络知识?这就是检索失败的典型——稀疏检索可能命中了“ERR_CONN”,但没抓到精确代码;密集检索可能觉得“网络重置”语义相近,却忽略了专有名词。
所以,检索不是“可有可无”的预处理,而是RAG系统的“命门”。接下来,我们就从最基础的方案讲起,看看技术演进如何一步步解决核心矛盾。
二、RAG检索的核心矛盾:准确率、召回率、性能的权衡
RAG检索面临三大核心矛盾:
-
- 准确率(Precision) vs 召回率(Recall):想精确命中,就容易漏掉语义相近但词汇不同的文档(低召回);想全面召回,又会拉进无关噪声(低精确)。
-
- 语义理解 vs 精确匹配:用户查询往往是自然语言(同义词、改写、口语化),但知识库里很多是精确术语(产品型号、错误码、法律条文)。
-
- 性能与成本:实时检索要求毫秒级响应,大规模知识库(百万级文档)下,计算资源和延迟成为瓶颈。
早期方案只能二选一,后来混合检索才实现了“鱼与熊掌兼得”。下面我们从“最初解决方案”讲起,层层递进,看技术如何破解这些矛盾。
三、最初的解决方案:稀疏检索及其典型代表BM25
20世纪70-80年代的信息检索领域,最早成熟的就是稀疏检索(Sparse Retrieval)。它把文档和查询表示成“高维稀疏向量”——维度等于词表大小(可能几十万维),但大多数维度是0,只有出现过的词才是1或权重值。
典型代表:BM25(Best Matching 25),它是TF-IDF的进化版,目前仍是Elasticsearch、Solr等搜索引擎的标准算法。
BM25评分公式:

优点:
- • 精确匹配强:对产品型号、错误码、专有名词命中率极高(Precision可达0.75-0.85);
- • 速度快:基于倒排索引(Inverted Index),百万文档检索<10ms;
- • 可解释性强:得分可追溯到具体词贡献;
- • 资源消耗低:无需GPU,只需CPU和少量内存。
实际案例:在代码仓库或日志检索中,查询“Kafka consumer lag”,BM25能精准命中包含“consumer lag”的文档。
思考一下:如果你的知识库全是技术文档、合同条款,BM25是不是已经够用?很多中小型项目确实就停在这里。
四、稀疏检索的问题,引出密集检索及其典型代表——Embedding模型
BM25虽快,但致命弱点是词汇鸿沟(Vocabulary Mismatch):无法理解同义词、语义改写、跨语言。
例子:
- • 查询“律师” vs 文档“attorney”或“法律顾问”;
- • “苹果手机” vs “iPhone”或“手机苹果”(词序不敏感但BM25严格依赖词出现);
- • 中文“采购” vs “购买”——BM25完全无感。
于是,密集检索(Dense Retrieval)应运而生。它用Embedding模型(基于Transformer,如BERT、all-MiniLM-L6-v2、text-embedding-3-small)把文本映射成固定维度稠密向量(通常384-1536维,每维都是小数,包含语义信息)。
检索时,计算查询向量与文档向量的余弦相似度或内积,用ANN(Approximate Nearest Neighbor)库如FAISS加速。
典型代表:FAISS + Embedding模型。
- • FAISS索引类型:Flat(精确,小规模)、IVF(倒排文件,中规模)、HNSW(图索引,推荐生产)、PQ(乘积量化,大规模压缩)。
优点:
- • 语义理解强:召回率高(0.75-0.90),能处理同义词、改写、模糊查询;
- • 跨语言/多模态潜力:同一向量空间支持中英混用;
- • 大规模友好:HNSW可实现亚毫秒级查询。
思考一下:如果用户问题全是自然语言对话式,Dense是不是更聪明?
五、密集检索的问题,引出混合检索RRF策略
Dense也不是万能:
- • 精确匹配弱:对专有名词(如“ERR_CONN_RESET_4XX”)容易“稀释”——向量平均后,精确token权重变低;
- • 噪声多:语义相近但无关的文档(如“网络重置”泛泛而谈)会被召回;
- • 计算开销大:Embedding生成 + 向量索引存储成本高(GPU友好但CPU较慢);
- • 黑箱:解释性差,得分无法直观追溯。
于是,混合检索(Hybrid Search)诞生:同时跑稀疏(BM25)和密集(Dense),然后融合结果。
核心策略:Reciprocal Rank Fusion (RRF)——目前最主流、无需调参的融合算法。
RRF公式:

算法依据:RRF只看“排名共识”,不依赖原始得分量纲(BM25得分可能是0-15,Dense是0.6-0.95)。排名越靠前、多个检索器都认可的文档,得分越高。避免了归一化麻烦,鲁棒性极强。
其他融合方案(见下节对比):
- • 加权求和(alpha * BM25_score + (1-alpha) * Dense_score);
- • Relative Score Fusion(Weaviate支持)。
效果:混合后,Precision/Recall/F1通常提升10-30%,召回率可达0.80-0.95。
思考一下:如果你的项目既有精确术语又有对话查询,Hybrid是不是“刚需”?
六、混合检索常见的技术选型方案:原理、对比、优缺点与权衡
混合检索不是单一方案,而是多种组合。常见选型如下(综合5篇参考文章):
-
- BM25 + Dense + RRF(最推荐默认方案)
- ◦ 原理:并行检索 → RRF融合 → Top-K输出。
- ◦ 优点:无需调参、鲁棒、召回提升显著;支持异步并行加速。
- ◦ 缺点:双索引维护,延迟约100-200ms(可优化至<100ms)。
- ◦ 适用:大多数生产RAG(知识库、客服、文档问答)。
| Dense Search Results Sparse (BM25) Results ┌─────────────────────┐ ┌─────────────────────┐ │ 1. Caching patterns │ │ 1. Caching in .NET │ │ 2. Redis guide │ │ 2. Cache impl │ │ 3. Cache impl │ │ 3. Caching patterns │ │ 4. Performance opt │ │ 4. Cache invalidate │ │ 5. Async/await │ │ 5. Performance tune │ └─────────────────────┘ └─────────────────────┘ │ │ └────────────┬───────────────┘ │ RRF Fusion │ ┌────────────┴────────────┐ │ │ Apply RRF Formula Combine Scores 1/(60+rank) Sum across methods │ │ └────────────┬────────────┘ │ ┌─────────▼──────────┐ │ Final Ranking │ ├────────────────────┤ │ 1. Caching patterns│ (inboth!) │ 2. Cache impl │ (inboth!) │ 3. Caching in .NET │ (sparse only) │ 4. Redis guide │ (dense only) │ 5. Performance opt │ (sparse only) └────────────────────┘ |
- BM25 + Dense + 加权求和(Alpha融合)
- ◦ 原理:先归一化得分,再用alpha(0-1)加权(Weaviate默认alpha=0.75偏Dense)。
- ◦ 优点:可针对场景调优(技术文档alpha偏BM25=0.7;客服偏Dense=0.7)。
- ◦ 缺点:需实验调alpha,敏感于得分分布。
- ◦ 适用:有标注数据可A/B测试的场景。
-
- BM25 + SPLADE(高级稀疏) + RRF
- ◦ 原理:SPLADE是用Transformer学习“稀疏向量+语义扩展”(如“car”自动扩展“vehicle”),保留稀疏性但注入语义。
- ◦ 优点:兼具BM25精确性和Dense语义,适合同义词丰富的领域。
- ◦ 缺点:推理延迟高(100-300ms),OOV(新词)较弱。
- ◦ 适用:自然语言重度场景,预算允许。
-
- 纯Dense + HNSW(大规模简化版)
- ◦ 原理:仅向量检索,用HNSW图索引。
- ◦ 优点:部署简单,语义强。
- ◦ 缺点:精确匹配弱,适合纯语义语料。
- ◦ 适用:小团队、语料干净、无专有名词重度需求。
综合对比表(便于记忆):
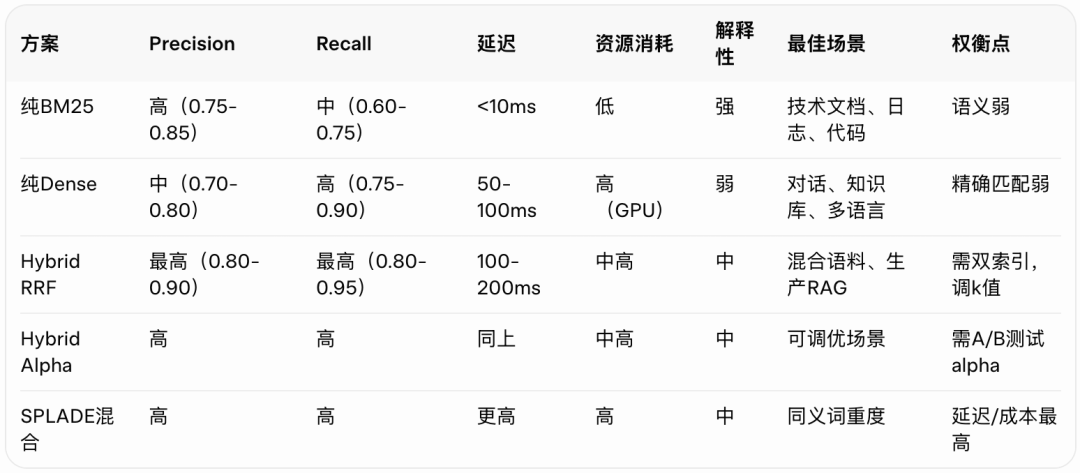
权衡点总结:
- • 小语料(<5万文档):优先BM25或简单Hybrid,k=10-20。
- • 大语料(>100万):HNSW + RRF,考虑PQ压缩。
- • 成本敏感:先上BM25,逐步加Dense。
- • 准确性优先:Hybrid + 后续Re-ranking(Cross-Encoder进一步过滤Top-K)。
七、混合检索如何落地?实施过程重点约束与实践
落地实施步骤(LangChain/LlamaIndex/Weaviate/Qdrant均支持):
-
- 数据准备与分块:语义分块(Semantic Chunking)+ 递归分块 + 重叠,确保Dense发挥。技术文档用标题感知分块。
-
- 双索引构建:
- ◦ BM25:用rank_bm25或Elasticsearch建立倒排索引(实时更新)。
- ◦ Dense:用Embedding模型批量生成向量,存入FAISS/HNSW/Qdrant/Weaviate。
-
- 查询流程:
- ◦ 并行执行BM25.search(query, retrieval_k=50)和Dense.search(query, retrieval_k=50);
- ◦ RRF融合(k=60);
- ◦ 可选:Cross-Encoder Re-ranker对Top-20重排(精度再升5-15%);
- ◦ 最终Top-5~10喂给LLM。
-
- 代码示例框架(Python伪码,生产可直接套LangChain):```plaintext
BM25 + Dense + RRFsparse_results = bm25_retriever.search(query, top_k=50)dense_results = dense_retriever.search(query, top_k=50)fused = reciprocal_rank_fusion([sparse_results, dense_results], k=60)
重点约束与考虑:
- • 性能(Latency):目标<200ms。优化:异步并行、向量量化、缓存热门查询、检索k不要超过100。
- • 准确性:上线前用NDCG@10、MRR、Precision@5评估。A/B测试不同alpha/RRF k。
- • 成本:Embedding调用(OpenAI按token计费)+ 存储(向量DB比传统贵30-50%)。自托管模型(如bge-large)可控成本。
- • 一致性:双索引原子更新(事务或双写)。
- • 可观测性:记录explain_score(Weaviate支持),监控每个检索器贡献。
- • 中文特殊性:分词器用jieba/THULAC;Embedding选中文优化模型(如bge);测试同义词(如“采购”vs“购买”)。
- • 扩展:结合Query Rewriting(LLM改写查询)、Agentic RAG(动态决定检索策略)、GraphRAG(知识图谱多跳)。
生产案例:某电商知识库用Hybrid RRF后,用户满意度提升22%,幻觉率下降35%。小团队可先用Weaviate一键Hybrid,大厂用自建FAISS+Elasticsearch。
你思考一下:你的项目语料规模多大?查询类型是精确还是对话?现在你知道该怎么选了吧?
八、总结及展望
RAG检索从稀疏BM25起步,解决精确匹配;到密集Embedding,补齐语义理解;再到Hybrid RRF,实现1+1>2的完美融合。核心是“取长补短”:BM25管精确,Dense管语义,RRF管融合。
未来展望:
- • SPLADE++与Learned Sparse:更智能的稀疏向量;
- • 多模态检索:CLIP/LLaVA支持图文/视频;
- • 自适应检索:LLM动态选择BM25/Dense/Alpha;
- • Agentic & GraphRAG:不止检索,还主动规划、推理;
- • 轻量化:边缘设备上的量化Embedding + 本地BM25。
掌握这些,你不仅能在面试中脱颖而出,更能在AI产品中打造“靠谱”的RAG系统。行动起来:现在就去试试Weaviate或LangChain的Hybrid示例,测测你的知识库效果!
2026年AI行业最大的机会,毫无疑问就在应用层!
字节跳动已有7个团队全速布局Agent
大模型岗位暴增69%,年薪破百万!
腾讯、京东、百度开放招聘技术岗,80%与AI相关……
如今,超过60%的企业都在推进AI产品落地,而真正能交付项目的 大模型应用开发工程师 **,**却极度稀缺!
落地AI应用绝对不是写几个prompt,调几个API就能搞定的,企业真正需要的,是能搞定这三项核心能力的人:
✅RAG:融入外部信息,修正模型输出,给模型装靠谱大脑
✅Agent智能体:让AI自主干活,通过工具调用(Tools)环境交互,多步推理完成复杂任务。比如做智能客服等等……
✅微调:针对特定任务优化,让模型适配业务
目前,脉脉上有超过1000家企业发布大模型相关岗位,人工智能岗平均月薪7.8w!实习生日薪高达4000!远超其他行业收入水平!
技术的稀缺性,才是你「值钱」的关键!
具备AI能力的程序员,比传统开发高出不止一截!有的人早就转行AI方向,拿到百万年薪!👇🏻👇🏻

AI浪潮,正在重构程序员的核心竞争力!现在入场,仍是最佳时机!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

⭐️从大模型微调到AI Agent智能体搭建
剖析AI技术的应用场景,用实战经验落地AI技术。从GPT到最火的开源模型,让你从容面对AI技术革新!
大模型微调
-
掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。
-
学习如何利用领域数据(如制造、医药、金融等)进行模型定制,提升任务准确性和效率。
RAG应用开发
- 深入理解检索增强生成(Retrieval-Augmented Generation, RAG)技术,构建高效的知识检索与生成系统。
- 应用于垂类场景(如法律文档分析、医疗诊断辅助、金融报告生成等),实现精准信息提取与内容生成。
AI Agent智能体搭建
- 学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。
- 构建垂类场景下的智能助手(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)。

如果你也有以下诉求:
快速链接产品/业务团队,参与前沿项目
构建技术壁垒,从竞争者中脱颖而出
避开35岁裁员危险期,顺利拿下高薪岗
迭代技术水平,延长未来20年的新职业发展!
……
那这节课你一定要来听!
因为,留给普通程序员的时间真的不多了!
立即扫码,即可免费预约
「AI技术原理 + 实战应用 + 职业发展」
「大模型应用开发实战公开课」
👇👇

👍🏻还有靠谱的内推机会+直聘权益!!
完课后赠送:大模型应用案例集、AI商业落地白皮书

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献171条内容
已为社区贡献171条内容

所有评论(0)