Dify 需求分解工作流实战:从 LLM 输出到生成可下载 Markdown 文件
前言
在日常研发和测试流程中,需求分解是一个耗时且重复的工作。本文介绍如何借助 Dify 搭建一个需求分解工作流,输入原始需求,自动通过 LLM 分解,并将结果生成 Markdown 文件供用户直接下载。
一、工作流整体架构
整个工作流由以下节点组成:
开始节点(输入文档)->(文本、图片)->LLM节点 → 数据清洗① → HTTP请求节点 → 代码执行节点② → 结束节点
各节点作用参考dify官方文档:https://docs.dify.ai/zh/use-dify/nodes/user-input
部署过程参考本地化部署dify教程:https://blog.csdn.net/qq_67982116/article/details/153565837
二、LLM 节点配置
创建工作流:工作室-创建空白应用-工作流,进入编辑模式
1. 用户输入节点
点击用户输入,点击右侧加号
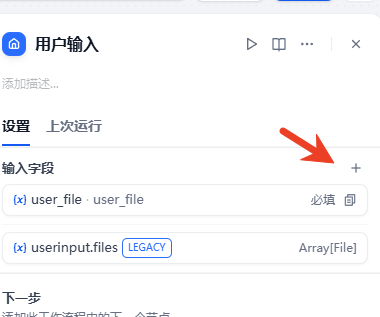
- 字段类型:文件列表 array[file]
- 变量名称:user_file
- 显示名称:user_file(默认)
- 支持文件类型:文档,其他可根据需要自行勾选
- 上传文件类型:两者
- 最大上传数:5(默认)
- 必填,保存。
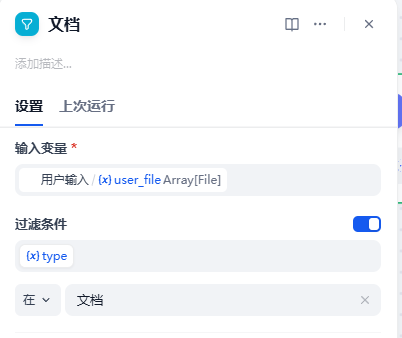
2.列表操作器节点
- 在 用户输入 节点之后,添加两个并行的列表操作器节点。
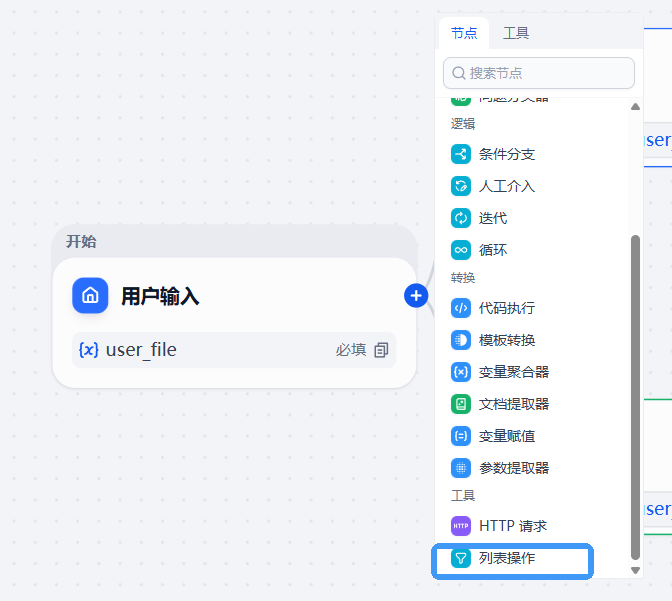
- 将一个节点重命名为
图像,另一个重命名为文档
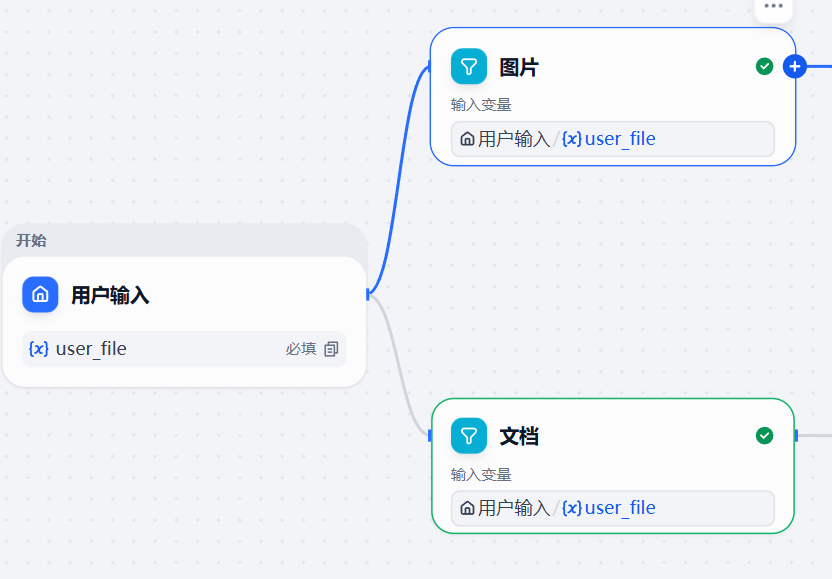
- 将
用户输入/user_file设置为输入变量,启用过滤条件:{x}type在Image,{x}type在doc
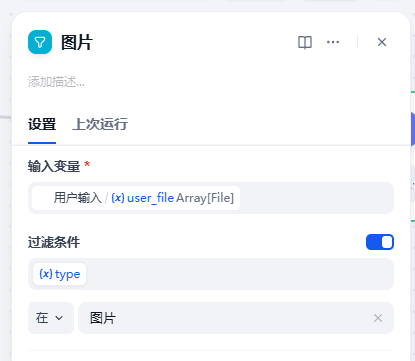
PS:图像和文档在使用 gpt-5.2 时需要不同的处理:图像可以通过其视觉能力直接解释,而文档必须先转换为文本,模型才能处理。所以要用两个列表操作器节点来过滤和将上传的文件分成单独的分支(一个用于图像,一个用于文档)
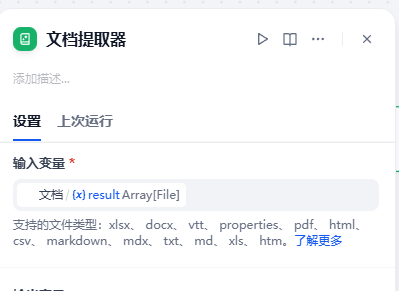
3.文档提取器节点
- 在文档列表提取器后新增文档提取器节点,目的是将筛选的文本内容提取出来
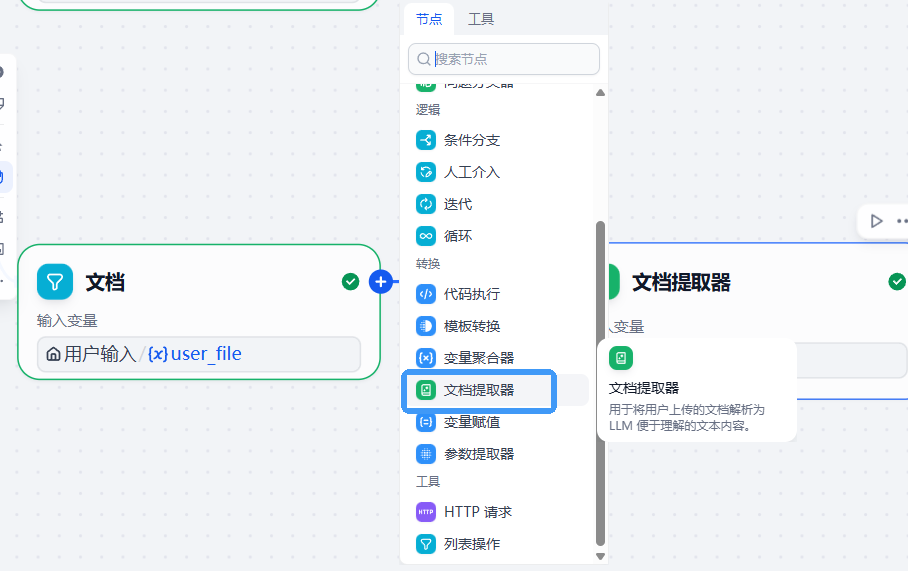
- 输入变量:文档/result
4.LLM节点
- 在图片和文档提取器后添加LLM节点
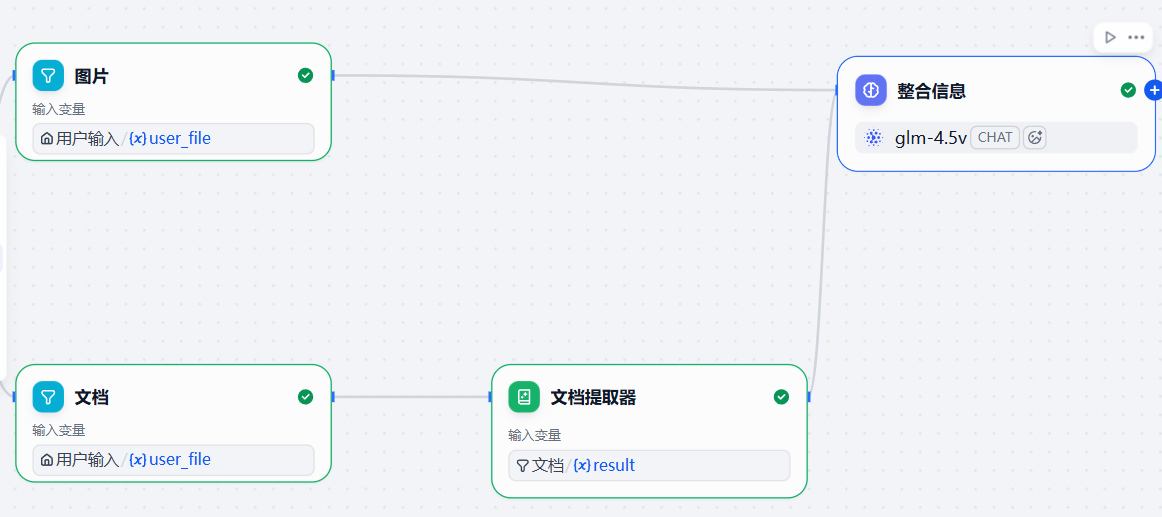
- 模型设置
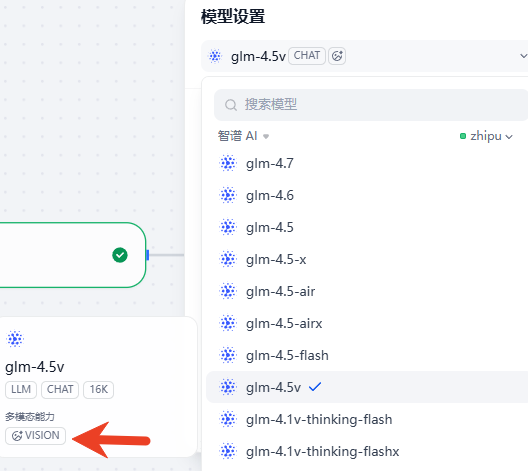
- 因为图片需要模型支持视觉,必须选择有多模态(VISION)能力的模型
- 温度拉低,因为越高结果越发散不严谨,需求分解最重要的是忠于原文档,我一般控制在0-0.2(根据结果调整),其他参数用的默认值
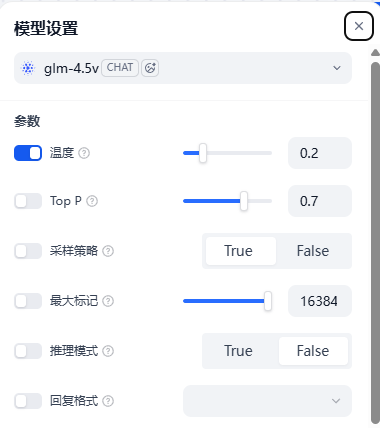
- 上下文:空
- SYSTEM Prompt:
你是一位资深的游戏项目需求分析师,擅长将游戏需求文档从测试工程师角度拆解成细分模块。
分析时请遵守以下原则:
1. 忠实于原始文档内容,不要脑补或扩展文档未提及的功能
2. 进行层级划分,采用「模块→子功能→测试点」三级结构
3. 模块分工要明确责任边界,添加需求基线版本号,标注跨模块依赖关系
4. 如遇图片内容,结合图片中的流程图/原型图辅助理解需求
5. 输出标准 Markdown 格式,便于后续生成文档- USRE Prompt:
以下是游戏需求文档的内容(包含文字和图片),请完成以下任务:
【文档内容】
插入{{#文档提取器.text#}}
插入{{#图片.result#}}
--
请按以下结构进行输出成markdown文件:
## 一、需求概述
- 一句话简述本次需求的核心目标和背景
## 二、功能模块与功能点
- 列出每个模块和它的功能点,按照下列模板格式输出
### 模块1:xxx
- **xxxx**:
## 三、业务流程
### 主流程
- 列出正常走完一遍功能流程的过程并列出
### 分支流程
- 列出主流程没有覆盖到的其他流程
### 状态流转
- 列出走完一遍功能流程的各个模块点,按下列格式输出:
xxx ──→ xxx ──→ xxx ──→ xxx
## 四、前置依赖 / 影响范围
### 前置依赖
### 影响范围
## 五、边界条件
- 将边界条件拆解成具体条件点,按下列格式输出
| 类别 | 边界条件 | 说明 |
|------|---------|------|
## 六、风险与待确认项
- 文档中描述不明确、需进一步确认的点
输出标准 Markdown 格式,便于后续生成文档视觉:启用,绑定图片/result Array[Files]
5.代码执行节点1
在LLM节点后增加代码执行节点
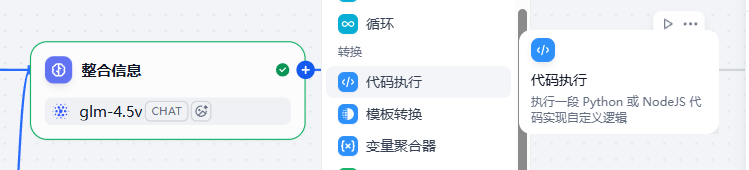
- 输入变量:变量名 llm_output,绑定LLM节点/text
- python3代码,目的是将LLM的结果做数据清洗和赋值
import uuid
import re
from datetime import datetime
def main(llm_output: str) -> dict:
# 去掉 <think>...</think> 块
clean = re.sub(r"<think>.*?</think>", "", llm_output, flags=re.DOTALL)
clean = clean.strip()
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
file_name = f"需求分解_{timestamp}_{uuid.uuid4().hex[:6]}.md"
return {
"file_name": file_name,
"file_content": clean # ← 用清洗后的内容
}- 两个输出变量:file_content【String】 file_name【String】
6.HTTP请求节点(核心重点)
在第5个节点后增加HTTP请求节点,这一步需要请求外部Python代码环境生成下载URL
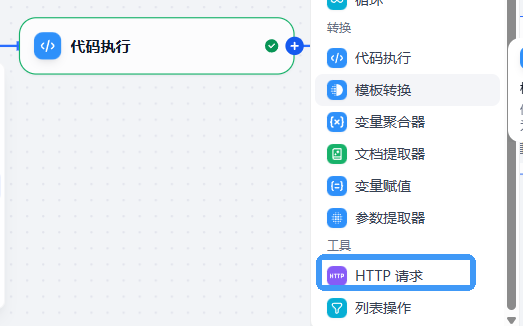
- API:POST方法。输入变量:http://你的IP:5000/health
- Headers:键:Content-Type 值:application/json
- Params:空
- Body *:JSON 插入上个节点的两个输出变量
{
"file_name": "{{#代码执行.file_name#}}",
"file_content": "{{#代码执行.file_content#}}"
}
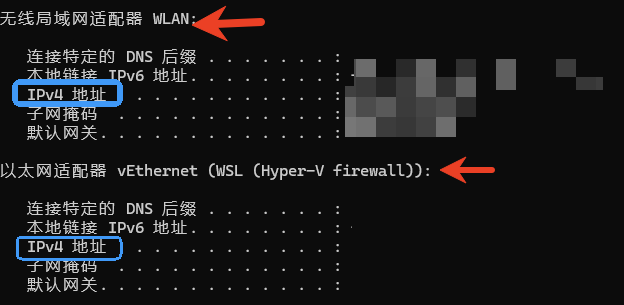
- win+R打开cmd输入ipconfig回车,我用的无线连接是第1个的IPv4地址,有线连接用第2个
- 这个IP是第1个API的输入变量http://YouIP:端口/api/upload,目的是访问我们服务器上Python+Flask服务
- 服务器Python代码,目的是收到body:JSON,转换成markdown格式文件,返回文件的下载链接
import os
import uuid
import base64
from datetime import datetime
from flask import Flask, request, jsonify, send_from_directory
app = Flask(__name__)
# ========== 配置 ==========
FILES_DIR = "./files" # 文件存储目录
BASE_URL = "http://XXX.XXX.XXX.XXX:5000" # 改成你的服务器域名或IP
PORT = 5000
SECRET_KEY = "your-secret-key" # 简单鉴权,可选
# ==========================
os.makedirs(FILES_DIR, exist_ok=True)
@app.route("/api/upload", methods=["POST"])
def upload():
"""
接收 Dify 传来的 Markdown 内容,保存为文件,返回下载链接
请求体(JSON):
{
"file_name": "需求分解_abc123.md", // 可选,不传则自动生成
"file_content": "# 标题\n内容...", // 方式1:直接传文本
"file_b64": "base64字符串", // 方式2:base64编码
"encoding": "base64" // 使用base64时需传此字段
}
"""
# 鉴权(可选,不需要就注释掉)
# auth = request.headers.get("Authorization", "")
# if auth != f"Bearer {SECRET_KEY}":
# return jsonify({"error": "Unauthorized"}), 401
data = request.get_json()
if not data:
return jsonify({"error": "请求体不能为空"}), 400
# ---- 获取文件内容 ----
if "file_b64" in data and data.get("encoding") == "base64":
# Base64 解码
try:
content_bytes = base64.b64decode(data["file_b64"])
content = content_bytes.decode("utf-8")
except Exception as e:
return jsonify({"error": f"Base64解码失败: {str(e)}"}), 400
elif "file_content" in data:
# 直接接收文本
content = data["file_content"]
else:
return jsonify({"error": "缺少 file_content 或 file_b64 字段"}), 400
# ---- 生成文件名 ----
file_name = data.get("file_name")
if not file_name:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
file_name = f"需求分解_{timestamp}_{uuid.uuid4().hex[:6]}.md"
# 安全处理:防止路径穿越
file_name = os.path.basename(file_name)
# ---- 写入文件 ----
file_path = os.path.join(FILES_DIR, file_name)
try:
with open(file_path, "w", encoding="utf-8") as f:
f.write(content)
except Exception as e:
return jsonify({"error": f"文件写入失败: {str(e)}"}), 500
# ---- 返回下载链接 ----
download_url = f"{BASE_URL}/files/{file_name}"
return jsonify({
"url": download_url,
"file_name": file_name,
"size": len(content.encode("utf-8")),
"message": "上传成功"
}), 200
@app.route("/files/<filename>", methods=["GET"])
def download(filename):
"""文件下载接口"""
return send_from_directory(
FILES_DIR,
filename,
as_attachment=True, # 强制下载
download_name=filename
)
@app.route("/health", methods=["GET"])
def health():
return jsonify({"status": "ok"}), 200
if __name__ == "__main__":
app.run(host="0.0.0.0", port=PORT, debug=False)
部署服务
# 1. 安装依赖
pip install -r requirements.txt
# 2. 修改 app.py 中的 BASE_URL 为你的服务器地址
# 3. 启动服务
python app.py
7.代码执行节点2
在HTTP节点后新增代码执行节点,解析JSON格式字符串,提取URL下载链接
- 输入变量:response_body 绑定 HTTP请求/body
- Python3代码:
import json
def main(response_body: str) -> dict:
try:
data = json.loads(response_body)
return {
"url": data.get("url", ""),
"file_name": data.get("file_name", ""),
"message": data.get("message", "")
}
except Exception as e:
return {
"url": "",
"file_name": "",
"message": f"解析失败: {str(e)}"
}
- 输出变量: url String
8.输出
- 输出变量:url 绑定 代码执行节点2/url
三、运行发布
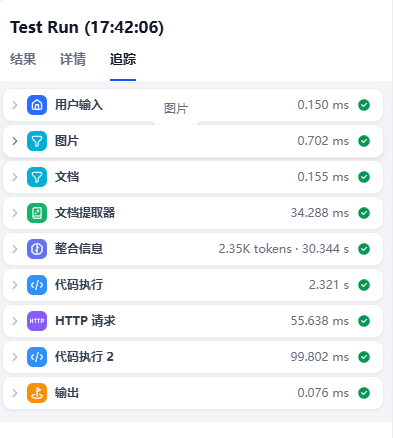
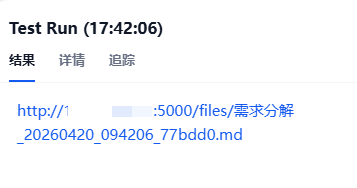
点击测试运行,输出url下载链接,可以正常下载后点击发布
在探索里找到发布的工作流,这就可以通过链接分享试用了,但最好在内部环境,正式环境需要做好安全防护,URL里不要直接暴露自己的IP
四、常见问题
Q1:浏览器打开下载链接提示"无法访问此网站"
A:检查以下几点:
- Flask 服务是否正在运行(
netstat -ano | findstr :5000)BASE_URL是否用的是http而非https- 端口号是否拼接在 URL 中
- 是否在同一局域网内访问(
172.16.x.x为内网地址)
Q2:结果内容不满意想要优化
查看文件内容是不是还有优化的点,可以去LLM节点提示词里进行调优或者新增一个LLM节点推理上一个节点的内容,方法很多这里不再展开

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)