【晓天衡宇·评测社区】前沿物理推理-费曼图评测榜单正式发布,AI模型能否攻克经典诺贝尔物理难题?
【榜单简介】
本榜单以FeynmanBench为核心评测基准,基于 2000+ 条标准模型相互作用样本,评估10款顶尖大模型对粒子物理图表的拓扑识别与振幅推导能力。
FeynmanBench是一个革新性的基准测试,用于评估大型多模态模型(MLLMs)在图表物理推理和形式化符号理解方面的能力。与传统的视觉问答(VQA)任务主要测试局部信息提取不同,FeynmanBench 通过在费曼图场景中进行多步 diagrammatic 推理预测来直接测试模型对"全局结构逻辑"的理解。
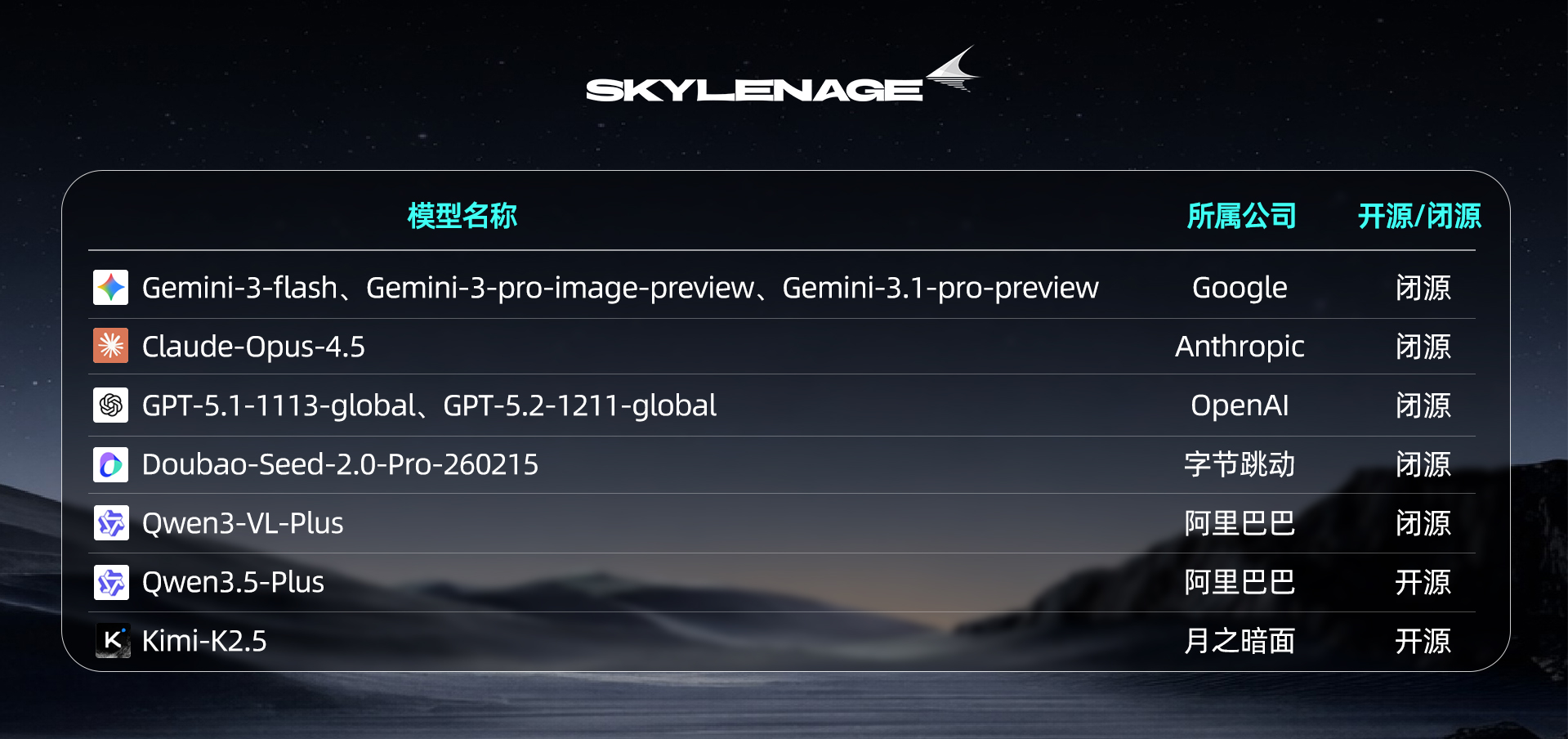
【参评模型】
【评测集解读】
评测维度
该评测集将物理推理分解为五个递进的检查点(Checkpoints),采用线性渐进评分原则:
1. 顶点计数与类型验证 (CP1)
-
识别相互作用点的总数及类型
-
模型需要准确计数顶点并确认连接关系
-
难度级别:基础
2. 内部线与传播子清单 (CP2)
-
识别内部粒子线及其传播子类型
-
需要理解粒子物理符号与线的对应关系
-
难度级别:中等
3. 拓扑连通性与图同构 (CP3)
-
验证顶点与链的正确连通性
-
需要全局拓扑结构理解,而非局部识别
-
难度级别:高级
4. 动量路由与守恒律 (CP4)
-
确认内部动量分配自洽且满足守恒律
-
需要应用物理约束进行逻辑验证
-
难度级别:专家级
5. 代数结构与对称因子 (CP5)
-
推导代数表达式、对称因子及费曼规则系数
-
需要精确的符号推理与组合数学能力
-
难度级别:大师级
数据标准
通用任务
本基准不涉及通用视觉/语言任务,专注科学图表推理。
垂直领域:
1、按拓扑复杂度分类(A类,5类):
-
A1: Tree level(树图)
-
A2: One-loop 1PR(单圈可约)
-
A3: One-loop 1PI(单圈不可约)
-
A4: Two-loop 1PR(双圈可约)
-
A5: Two-loop 1PI(双圈不可约)
2、按相互作用类型分类(B类,6类):
-
B1: QED,仅光子+电子/正电子
-
B2: QED,光子+通用带电费米子
-
B3: 电弱,仅轻子+中微子
-
B4: 电弱,含电弱规范玻色子(W/Z)
-
B5: 电弱,含希格斯玻色子(H)
-
B6: 强相互作用(QCD),含夸克/胶子
3、数据生成与验证:
-
基于FeynArts/FeynCalc自动化管线生成
-
每条样本含可验证的拓扑标注+振幅表达式
-
从20万+候选图中筛选2000+代表性样本,确保多样性与可复现性
【评分标准】
评分机制采用渐进式评估协议(Progressive Evaluation),仅当前一检查点完全正确时,才评估后续维度。
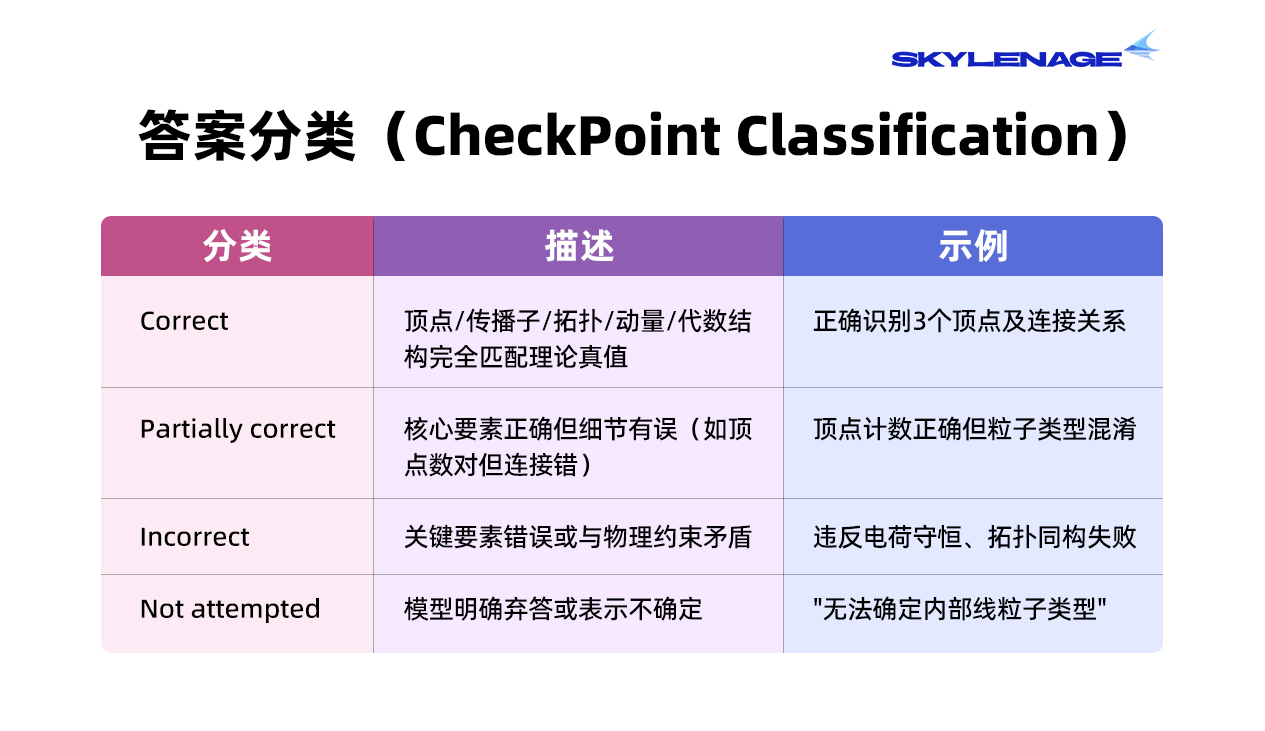
评分实现:

【榜单速览】
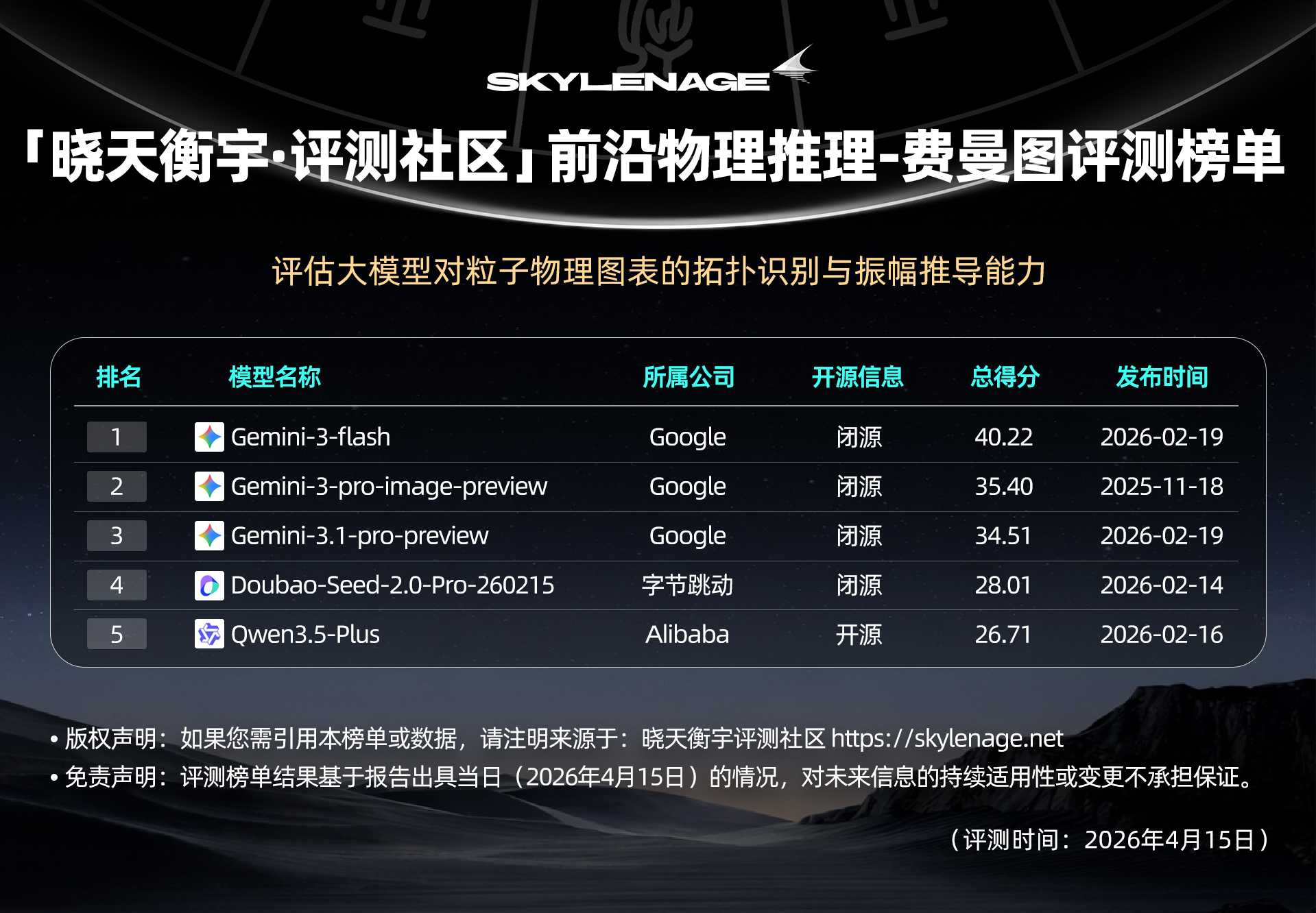
👉【获取完整榜单】
此处仅展示综合评分前五名预览,查看完整排名以及细分维度的详细对比数据,请访问晓天衡宇•评测社区官网。
【榜单结论】
1、视觉 - 逻辑解耦(Vision-Logic Decoupling)
模型虽能识别局部元素(顶点/线),但难以构建全局拓扑网络,局部感知稳健不代表全局推理稳定。
2、通过率断崖式下跌
多数模型在 CP1-CP2 表现尚可,但在 CP3(拓扑)出现崩溃,随着圈数增加(拓扑复杂度),性能定性下降,表明模型缺乏"视觉域内的物理约束推理"能力,而非单纯视觉识别问题。
3、系统性偏见:记忆而非推理
少数成功案例多集中于教科书中常见的图样,表明模型依赖记忆而非可迁移的结构推导能力。
【了解更多】
前沿物理推理-费曼图评测榜单已同步上线至晓天衡宇•评测社区官网,欢迎大家访问查看更详细的评测数据。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)