Gemini实战:用AI写CI/CD脚本——GitLab CI 经验分享
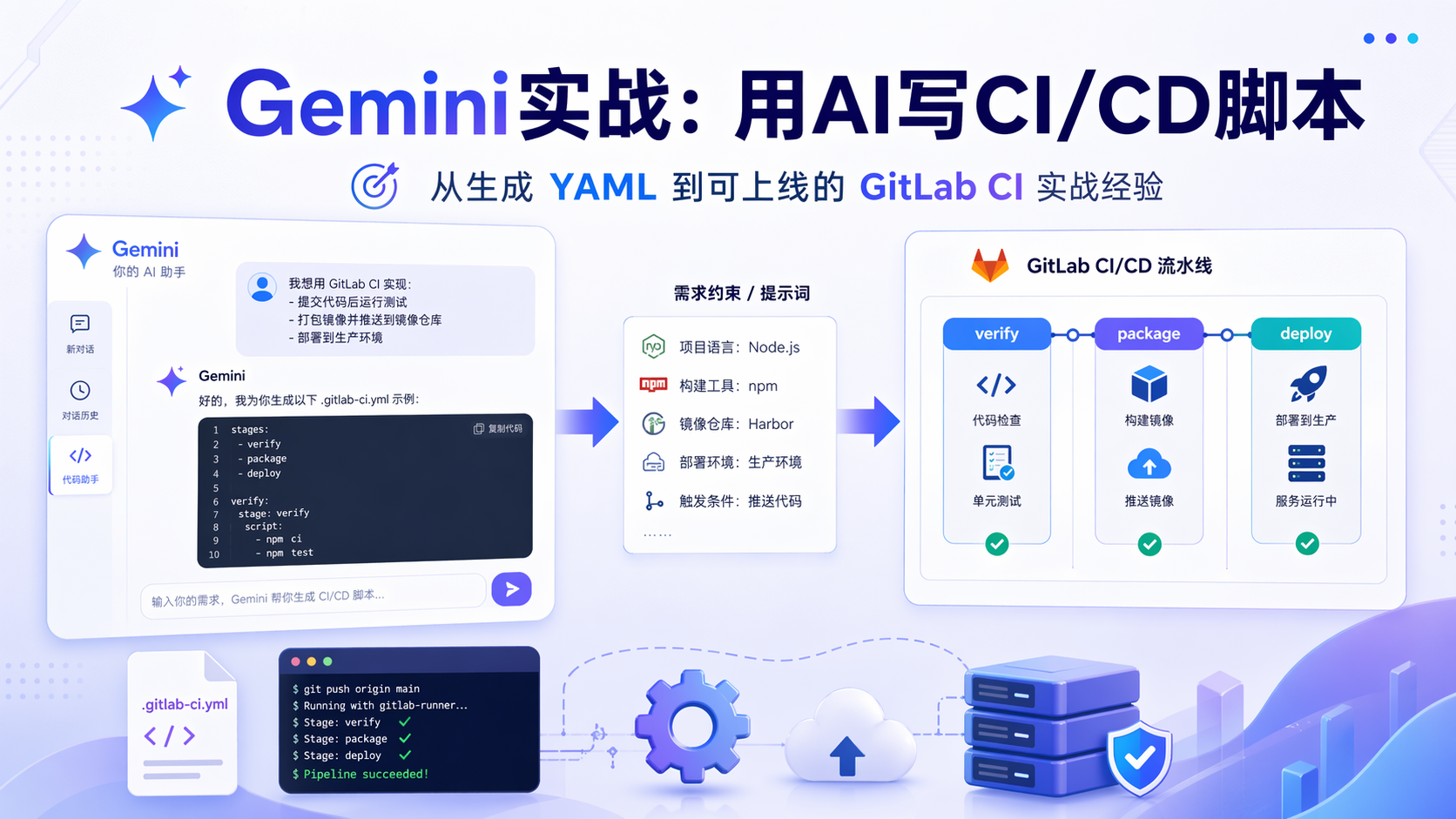
一、为什么很多人用 AI 写 GitLab CI,最后还是要手改
我看过不少团队第一次用 AI 写 GitLab CI 的过程,问题都很典型:要么规则写散了,导致分支流水线和合并请求流水线一起触发;要么镜像能构建,却没有形成稳定的发布规则;要么把敏感信息和业务逻辑一股脑塞进 YAML,导致后期难以维护。
这件事真正的难点,不是“写出一份 YAML”,而是“写出一份符合团队交付规则的 YAML”。
AI 擅长生成结构,工程师负责定义边界。
前者解决效率,后者决定结果能不能上线。
从 GitLab 的设计上看,流水线本来就是围绕 .gitlab-ci.yml 组织的:pipeline 由 YAML 关键字配置,job 是流水线的基本执行单元,不同事件可以触发不同 pipeline;而 workflow 的判断发生在 job 之前,rules 则决定某个 job 是否被纳入本次流水线。也正因为这套机制本身就有“事件、顺序、边界”的含义,所以 AI 一旦缺少上下文,就很容易生成“形式正确、行为偏差”的配置。
二、Gemini 真正适合做什么,不适合做什么
如果一句话概括,我更认可这样的定位:
Gemini 适合帮你生成第一版、整理重复逻辑、改写现有配置、检查提示遗漏;
但它不适合绕过你的发布规范,直接替你拍板。
Google 官方关于提示设计的建议,本质上强调两件事:一是提供更具体的上下文和目标,二是不要把模型输出当成无需验证的最终结果,仍然要做测试和评估。这个原则拿到 GitLab CI 场景里尤其合适,因为 CI/CD 不是写作文,它最后会连到镜像仓库、测试链路和生产环境。

所以,Gemini 更像一个“脚本草稿工程师”:它可以帮你快速写出流水线骨架;可以把一份松散的 YAML 收敛成更清晰的阶段结构;可以根据你给出的规则,补出变量、镜像标签和触发条件,但前提一定是,你先把环境事实讲清楚。
三、别一上来就让 AI “写完整流水线”,先把约束喂清楚
很多失败案例都不是模型不够强,而是提示词太空。比如一句“帮我写一个 Python 项目的 GitLab CI”,这类请求在工程上几乎没有信息量。更有效的做法,是至少把下面几件事讲清楚:
第一,Runner 是什么。到底是 Docker executor,还是 Shell executor;能不能跑 Docker-in-Docker;是否需要 privileged;这些都会直接影响后续镜像构建方案。GitLab 官方文档明确提到,要在 CI/CD job 里运行 Docker 命令,需要让 Runner 具备相应支持,DinD 方案通常要求 privileged 模式。
第二,分支和发布策略是什么。合并请求只检查,还是也构建镜像;默认分支推不推 latest;版本 tag 是否单独发布正式镜像。GitLab 的 pipeline 本身支持由 push、merge request、schedule 甚至手动操作触发,所以如果你不先讲清楚触发语义,AI 很容易把所有事件混成一锅。
第三,变量和安全边界是什么。哪些值应该走 GitLab 的预定义变量,哪些值应该由项目变量提供,哪些值坚决不能写进仓库。GitLab 官方明确说过,预定义变量在 pipeline 中可直接使用,而且不建议覆写;敏感值也应通过 CI/CD variables 管理,而不是写死在 YAML 里。
第四,交付物到底是什么。你是要产出 Python wheel、测试报告,还是 Docker 镜像。这个问题一旦说不清,后面关于 artifacts、镜像仓库和部署动作的设计就会一起乱掉。GitLab 的 YAML 体系本身就是围绕 job、reports、artifacts 和后续流水线消费这些结果来组织的。
四、分享一个 Python 镜像发布场景:少贴代码,重点讲结构、思路和过程
如果把 GitLab CI 用在 Python 项目里,一个非常典型的场景就是:
代码检查 → 自动化测试 → 构建镜像 → 推送镜像
这条链路看起来并不复杂,但真正决定它是否能长期稳定使用的,并不是 .gitlab-ci.yml 一共写了多少行,而是你有没有把阶段划分、镜像标签、触发条件和变量边界设计清楚。

1. 先把流水线拆成三层,而不是一锅炖
Python 镜像发布类流水线,最稳妥的思路通常是分成三层。
第一层是代码质量检查。这里解决的是“代码有没有明显格式和规范问题”。对于 Python 项目,常见动作会围绕格式检查和静态规范检查展开,比如 black --check、flake8,有需要时再补类型检查。GitLab 也支持把这类 job 进一步接到 Code Quality 报告里,让结果在合并请求或 pipeline 视图中可见。
第二层是自动化测试。这里解决的是“代码改完之后,功能有没有被破坏”。这一步最常见的就是用 pytest 跑单元测试或基础集成测试。关键不在于测试写得多花,而在于它必须成为镜像构建之前的门槛。只有先验证质量,再进入交付阶段,整个 CI 才有工程意义。
第三层是镜像构建与推送。这里才真正进入“发布动作”。GitLab 官方关于容器仓库的文档说得很直接:先认证,再构建,再推送。换句话说,CI 到了这一步,不再只是“检查代码”,而是在把通过验证的结果变成可交付的镜像。
这三层拆开之后,职责会非常清楚:前两层判断这份代码值不值得打包;第三层负责把它变成交付物。
这比把检查、测试、镜像构建和推送全部塞进一个 job 里要稳定得多。
2. 项目目录不需要复杂,但要让流水线一眼看懂
在这种场景下,项目目录其实不需要特别花哨。对 GitLab CI 来说,真正关键的是:它能否快速找到入口文件、依赖描述和镜像构建文件。一个最小可用的 Python 服务型项目,通常只要让这些元素清楚存在就够了:
- 应用入口,比如 app.py 或 main.py
- 运行依赖文件,比如 requirements.txt
- 开发依赖文件,比如 requirements-dev.txt
- Dockerfile
- .gitlab-ci.yml
这背后的核心不是“目录长得多标准”,而是“构建边界是否清晰”。AI 在生成 GitLab CI 时,本质上是在根据你的项目结构猜构建流程。你把边界放清楚,它生成的内容自然更稳定。
3. Dockerfile 不一定要复杂,但构建逻辑一定要清楚
很多人在 Python 镜像发布里过度关注 Dockerfile 语法技巧,反而忽略了更关键的边界问题。
第一,基础镜像要明确。例如是否使用 python:3.12-slim 这类更轻量的官方镜像。基础镜像一旦明确,Python 版本和容器运行基线也就清楚了。
第二,依赖安装要和业务代码复制分层处理。这样做不是为了“写法好看”,而是为了更好利用 Docker 层缓存,让构建更稳定,变更更可控。
第三,启动方式要明确。是简单演示型的 python app.py,还是生产更常见的 WSGI/ASGI 启动方式。这个判断会影响镜像最终用途,也会影响后续部署方式。
用极简片段表示,一个 Python 镜像构建的起点通常就是:
- FROM python:3.12-slim
- WORKDIR /app
这两行很少,但已经说明了两个最重要的事实:用哪个 Python 版本构建,以及容器内的工作目录在哪里。
4. 这个场景最容易被 AI 写错的,其实是触发策略
如果让 Gemini 生成 Python 镜像发布类 GitLab CI,最容易出错的地方通常不是 docker build,而是“什么时候构建”“什么时候推送”“推送哪些标签”。我更建议把触发逻辑拆成三层理解。
第一层,合并请求和普通分支优先做检查与测试。这一步的重点是验证,而不是发布。代码进入合并请求后,流水线先回答一个问题:它是否具备继续往后走的资格。
第二层,默认分支可以生成和推送主线镜像。这通常意味着代码已经通过了基础验证,可以产出一个代表主线当前状态的镜像,比如团队习惯中的 latest。
第三层,正式版本 tag 再触发版本级镜像发布。这类镜像适合对接正式环境、发布归档和问题回滚。GitLab 的 pipeline 本身就支持基于不同事件创建,所以把分支、MR、tag 三类语义拆清,是设计稳定规则的前提。
镜像标签本身也最好别只保留一个。更稳的思路,通常至少会包含三类:
- 提交级标签,用于追溯具体构建来源
- 主线标签,用于表示默认分支当前状态
- 版本标签,用于表示正式发布版本
一个非常简化的构建思路,大概就是:
- IMAGE_SHA="$CI_REGISTRY_IMAGE:$CI_COMMIT_SHORT_SHA"
- docker build -t "$IMAGE_SHA" .
- docker push "$IMAGE_SHA"
这里真正重要的,不是这三行命令本身,而是它体现出的原则:先给当前提交一个唯一且可追溯的镜像身份,再在此基础上决定是否额外打 latest 或版本号标签。GitLab 提供了 CI_REGISTRY_IMAGE、CI_COMMIT_SHORT_SHA 等预定义变量,正适合承担这种命名基础。
5. GitLab CI 在这里真正负责的,不只是“执行命令”
很多初学者会把 GitLab CI 理解成“执行一串 shell 命令的地方”,但在 Python 镜像发布场景里,它真正负责的是三件更重要的事。
第一,控制顺序。测试不过,就不该构建镜像;镜像没构建成功,就不该继续推送。这种“先后依赖”的能力,本来就是 pipeline 和 job 设计的核心。
第二,控制边界。什么应该放在仓库里,什么应该放在变量里,什么应该由 GitLab 预定义变量接管。GitLab 官方反复强调了预定义变量的可用性,以及不要覆写它们的建议。
第三,控制触发条件。不同事件触发不同动作:合并请求偏检查,默认分支偏主线交付,tag 偏正式发布。workflow 和 rules 就是在做这件事,只不过一个管 pipeline 级别,一个管 job 级别。
所以从本质上说,GitLab CI 在这个场景里,不只是“跑命令”,而是在把你的交付规则写成自动化流程。
五、如果让 Gemini 生成这一类流水线,提示词应该怎么给
我不建议一句话让 Gemini “从零生成完整流水线”。更稳的方式,是让它在清晰约束下输出第一版。一个好提示,通常至少包含这几类信息:
- 项目类型:Python Web 服务、API 服务,还是普通脚本项目
- 检查链路:是否需要 black、flake8、pytest
- 镜像发布规则:默认分支是否推 latest,tag 是否推版本镜像
- 运行环境:Runner 是否支持 Docker-in-Docker,是否启用 Container Registry
- 安全约束:敏感变量必须通过 GitLab CI/CD variables 提供,不允许写死
Google 官方关于 Gemini 的提示建议,本质就是:要具体、要给上下文、要定义输出范围,而且要接受“第一次结果未必完美,需要继续迭代”的现实。对 CI/CD 这种强工程约束场景来说,这种方法尤其有效。
换句话说,真正有效的提示词不是:“帮我写 GitLab CI。”而更像是:“你是资深 DevOps 工程师。请为一个 Python 3.12 Web 项目生成 GitLab CI。要求先做代码检查和测试,再构建并推送 Docker 镜像;默认分支推主线标签,版本 tag 推正式标签;Runner 支持 Docker-in-Docker;敏感值必须走 CI/CD Variables;输出以结构清晰、便于维护为主。”同样是让 AI 写脚本,这两种问法的结果通常完全不是一个层次。
六、我更认可的实战流程:先生成骨架,再补细节,再做验证
如果让我总结成一套更稳的落地方式,我会建议这样做。
第一步,先让 Gemini 只写骨架。不要一开始就要完整 YAML,而是先让它给出 stages、workflow、job 列表和每个 job 的职责。这样你先看结构是否合理。
第二步,再让它补变量、规则和镜像标签逻辑。这一轮重点是 rules、预定义变量、自定义变量、镜像命名策略和必要的 artifacts / reports 设计。
第三步,最后才让它补部署或后续动作。如果你的目标不只是推镜像,而是还要 SSH 到服务器拉起容器、做健康检查或回滚,那就把这部分放到最后一轮。不要在第一轮就把所有复杂度压进去。
第四步,人工做验证。GitLab 官方提供了 CI Lint,可检查配置有效性、排查语法和逻辑问题,还可以模拟 pipeline 创建;如果用 glab ci lint,也支持校验本地 .gitlab-ci.yml。这一步我非常建议保留,因为 AI 最容易在 rules、needs、事件触发和变量边界上出“看起来像对、实际有坑”的问题。
这不是对 AI 不信任,而是对生产环境负责。
七、真正的经验,不是“让 AI 写 CI”,而是“让 AI 按规则写 CI”
很多人喜欢问:Gemini 能不能帮我写 GitLab CI?答案当然是能。但更关键的问题其实是:它写出来的东西,能不能真的进入团队交付流程?

我的结论很明确:
Gemini 最大的价值,不是替你写完,而是替你加速。它适合做第一版骨架,适合整理重复逻辑,适合帮你梳理规则、变量和镜像发布思路;但它不应该绕过你的发布规范,更不应该替你跳过验证和测试。
说到底,这件事最值得记住的一句话就是:
不要让 AI 替你做工程判断,要让 AI 按你的工程规则生成结果。当你把 Runner 事实、分支策略、变量边界、镜像标签和交付方式讲清楚之后,Gemini 才会从“会补 YAML 的工具”,变成一个真正能参与 DevOps 落地的脚本助手。
结尾
写到这里,我想表达的核心其实很简单:
- AI 写 GitLab CI,不难;
- 难的是让它写得贴近真实环境、符合团队规范、经得起上线验证。
如果你也在用 Gemini、ChatGPT 或其他 AI 工具辅助写 CI/CD,欢迎聊聊你最常踩坑的是哪一类问题:是 rules 误触发,还是变量管理,还是 Python 镜像构建和推送链路?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)