【个人CNN学习记录之GoogLeNet网络】
个人CNN学习记录之GoogLeNet网络
文章目录
前言
在日常工作中,我专注于并行计算领域,主要依托GPGPU、NPU等高算力芯片进行开发。当前,高算力与AI已深度融合,计算与人工智能二者相辅相成:底层计算为实现通用算法与算子提供基础,而AI模型则能反哺并优化传统算法的决策效率与性能。为系统构建这方面的知识体系,我在公司导师的推荐下,跟随up主“霹雳吧啦Wz”的CNN系列视频进行学习,并通过博客记录学习过程,融入自己的理解与总结。
一、GoogLeNet网络介绍

一、网络背景与成就
提出:2014年由Google团队(Christian Szegedy等人)提出。
成就:荣获当年ImageNet大规模视觉识别挑战赛(ILSVRC)中分类任务(Classification Task)的第一名。
核心目标:在控制计算成本和参数量的前提下,构建一个性能优异的“更深度”的网络。其论文标题《Going deeper with convolutions》即点明了这一主旨。
二、核心结构:Inception模块
这是GoogLeNet最革命性的贡献。
设计思想:传统CNN每层只使用一种尺寸的卷积核,而Inception结构旨在同一层中并行融合不同尺度的特征信息。
基本结构:一个基础的Inception模块通常并行包含四条路径:
1×1卷积(捕捉精细特征/降维)。
3×3卷积。
5×5卷积。
3×3最大池化。
优势:让网络在每一层可以同时提取不同感受野的特征(如细节、局部、稍大区域),并将它们拼接(Concat) 起来,形成更丰富的特征表示,模拟了人眼多尺度观察的过程。
三、关键技术亮点
图片右侧明确列出了四大亮点:
引入Inception结构:
如上所述,这是网络的主干,实现了多尺度特征的并行提取与融合。
使用1×1卷积核进行降维和映射处理:
降维(减少通道数):在3×3、5×5卷积和池化层之前,先进行1×1卷积,大幅减少输入特征的通道数,从而显著降低计算量和参数量。这是Inception结构能够实用的关键。
增加非线性:1×1卷积后接ReLU激活函数,增加了非线性表达能力。
特征变换:可以看作是在通道维度上的线性组合与信息整合。
添加两个辅助分类器:
位置:在网络中部的两个Inception模块后引出。
作用:缓解梯度消失:在训练时,将辅助分类器的损失按一定权重加到总损失中,为网络前部提供额外的梯度回传信号,有助于深层网络的训练。
起到正则化效果。在推理(测试)阶段,这两个辅助分类器会被移除。
丢弃全连接层,改用全局平均池化层:
做法:在网络的最后,不使用传统的全连接层,而是对最后一个特征图的每个通道直接进行全局平均池化,得到一个与通道数相等的向量,再输入Softmax分类器。
优势:极大减少参数量:传统全连接层(如AlexNet、VGG)占据了模型绝大部分参数,容易过拟合。此改动使参数量骤降。降低过拟合风险。使网络对输入空间尺寸更灵活。
二、Inception结构
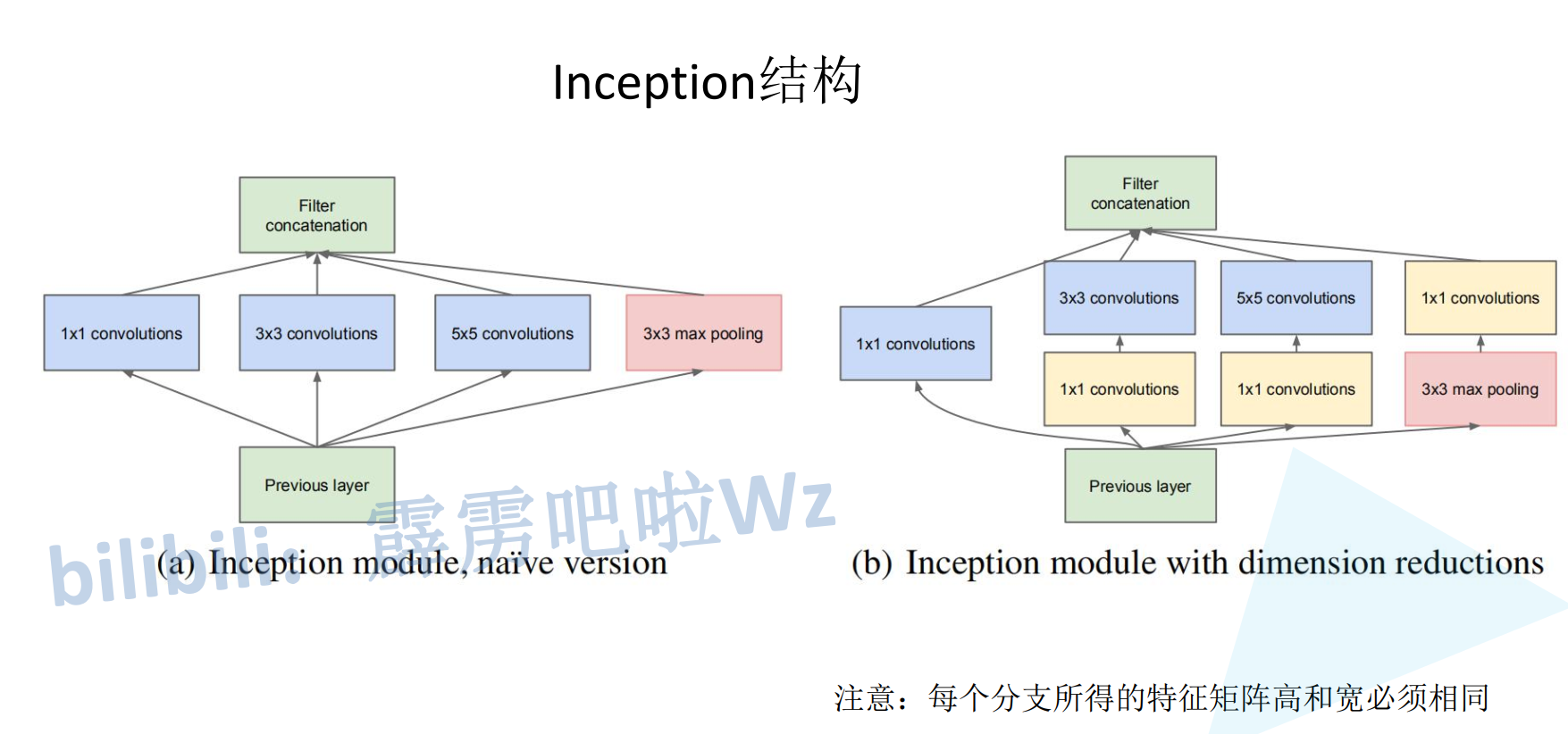
Inception核心思想:多尺度特征融合
Inception模块的设计初衷是让网络在单层内能够并行捕获不同尺度的特征(如细节、局部结构、更大区域模式),从而构建更丰富的特征表示。这通过并行设置多个不同尺寸的卷积核与池化操作来实现。
第一个图:原始版本 (Naive Version) 及其问题
结构:输入层并行连接四个分支,其输出在通道维度进行拼接(Filter concatenation)。
1×1 卷积:提取精细的、跨通道的线性组合特征。
3×3 卷积:捕获中等感受野的空间特征。
5×5 卷积:捕获更大感受野的空间特征。
3×3 最大池化:保留最显著的特征,提供空间上的稳定性。
关键要求:如图中注释强调,所有分支输出的特征矩阵必须具有相同的高度和宽度,这是它们能够沿通道维度拼接的前提。
致命缺陷:5×5卷积和具有大量输入通道的3×3卷积计算成本极高,直接堆叠此类模块会导致参数和计算量爆炸,难以实用。
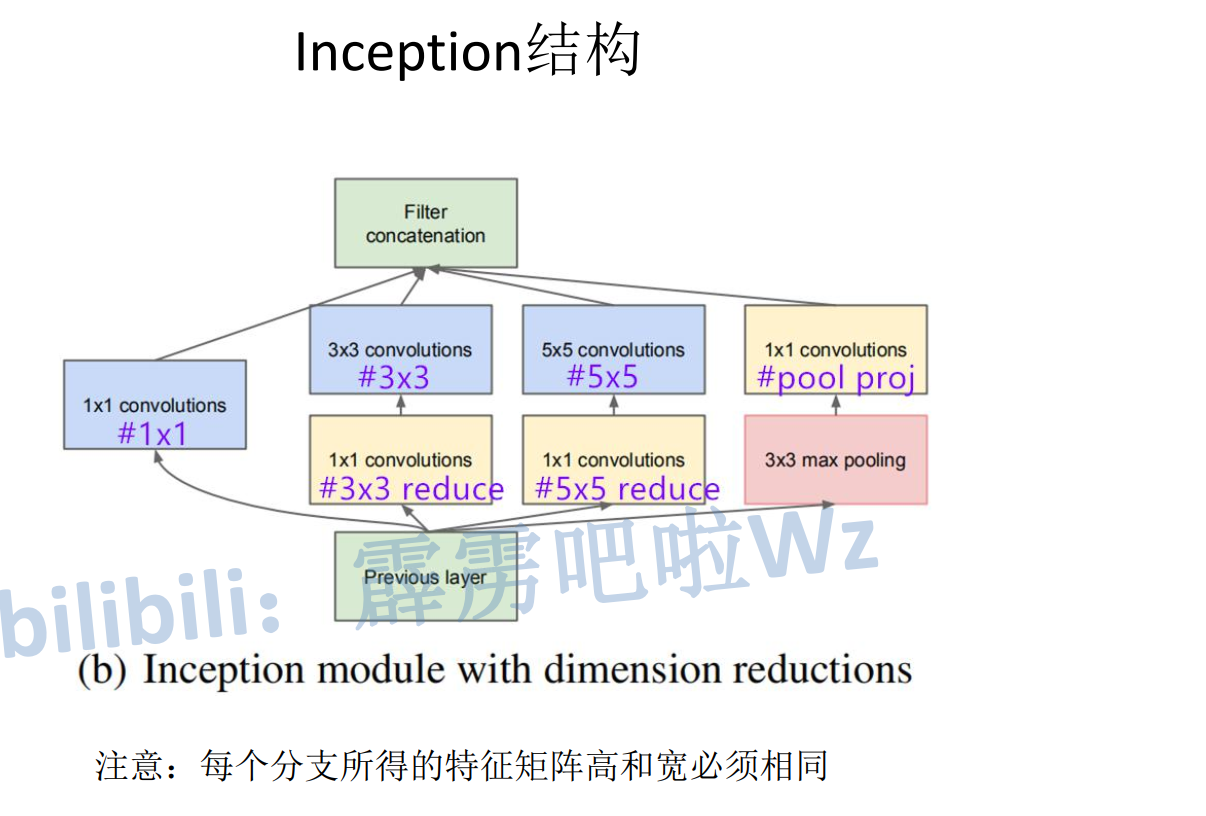
第二个图:引入降维的优化版本 (With Dimension Reductions) —— 核心创新
为解决原始版本的计算瓶颈,创造性地引入了1×1卷积作为“瓶颈层”。
结构解析:
1×1卷积分支:保持不变。
3×3卷积分支:路径变为 1×1 卷积 (降维)→ 3×3 卷积。1×1卷积(标注为#3x3 reduce)首先减少通道数,再进行3×3卷积。
5×5卷积分支:同理,路径为 1×1 卷积 (降维)→ 5×5 卷积。
池化分支:路径变为 3×3 最大池化→ 1×1 卷积 (投影)。池化后的1×1卷积(标注为#pool proj)用于调整通道数,使其能与其它分支的输出对齐。
1×1卷积的核心作用:
降维与成本控制:在3×3、5×5卷积前,通过1×1卷积将输入特征的通道数大幅减少,从而急剧降低后续大卷积核的计算量和参数量。这是Inception网络能够做得“更深更宽”而不失控的关键。
特征变换与非线性:1×1卷积本身是一次跨通道的线性组合,其后通常跟随ReLU激活函数,增加了网络的非线性表达能力。
通道对齐:在池化层后使用,用于统一和调整输出通道数,以便于最终拼接。
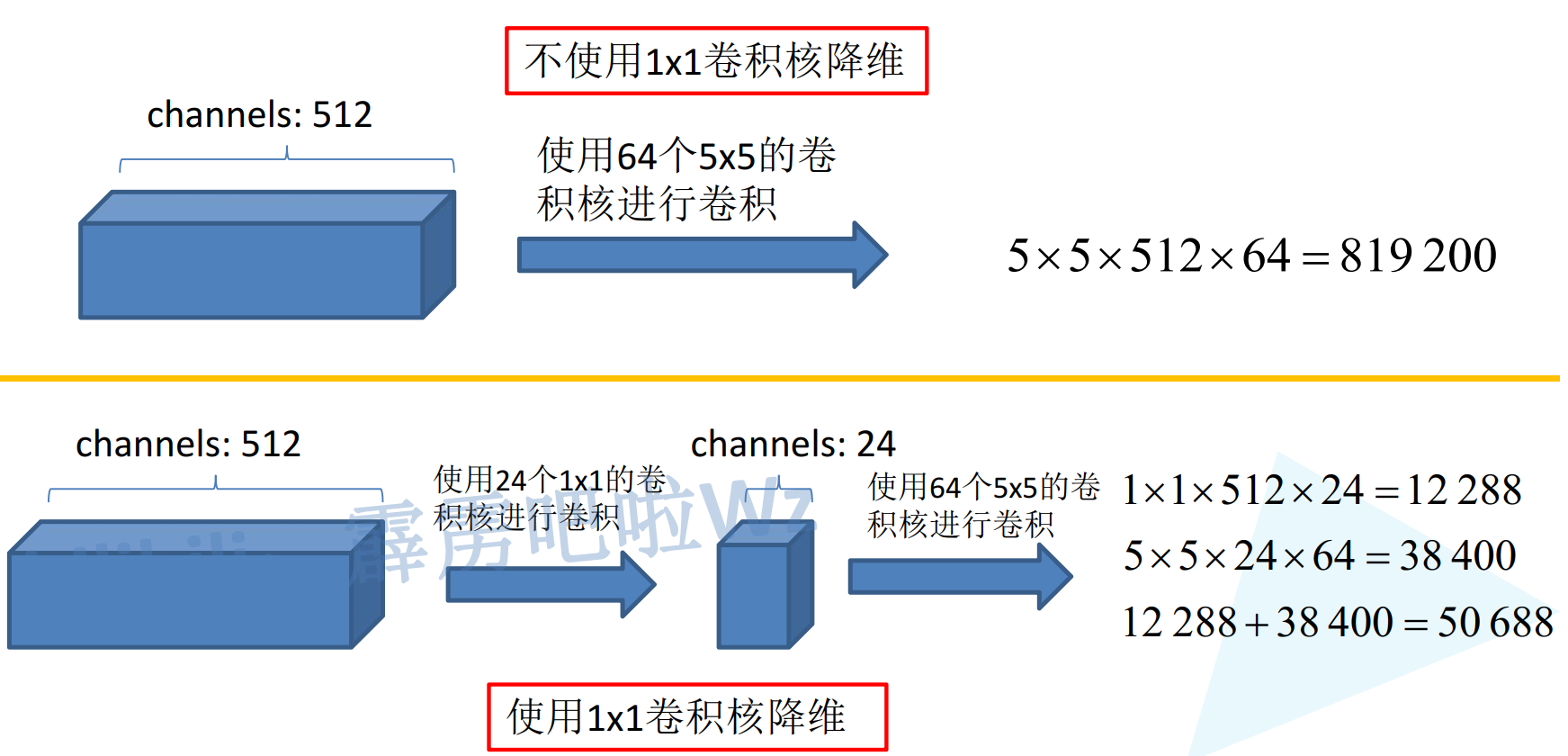
图中展示了1*1卷积核的降维作用,主要是channels维度的降维,降维之后参数量大幅度减少
三、辅助分类器

一、辅助分类器作用
辅助分类器是GoogLeNet(Inception-v1)网络中的一个关键辅助组件。它被添加在网络中部,仅在训练阶段启用,在推理(测试)阶段会被移除。
它的核心设计目的有两个:
缓解梯度消失:在非常深的网络中,梯度从最后层反向传播到最前面的层时可能会变得非常微弱(消失),导致浅层网络难以训练。辅助分类器提供了额外的、更短路径的梯度回传信号,有效地“督促”和加速网络前几层的训练。
提供正则化效果:辅助分类器本身也是一个小的子网络,其训练目标与主分类器一致,这为网络中间层的特征学习增加了一个约束,有助于提升模型的泛化能力,防止过拟合。
二、辅助分类器的详细结构
图片左侧文字和右侧示意图共同描绘了其清晰的五层结构(顺序自上而下):
平均池化层
操作:使用5×5大小的滤波器进行平均池化。
步长:S=3(即池化窗口每次移动3个像素)。
作用:快速、大幅地降低特征图的空间尺寸,进行粗粒度下采样,为后续全连接层做准备。
1×1卷积层
数量:128个。
作用:这是GoogLeNet的标志性设计。在进入计算成本较高的全连接层之前,先进行通道维度的降维(例如,从512或528通道降至128通道),大幅减少参数量和计算量。其后通常跟随ReLU激活函数。
全连接层
单元数量:1024个。
作用:整合和转换特征,学习高维的非线性表示。其后也跟随ReLU激活函数。
Dropout层
丢弃率:高达70%。
作用:在训练时,随机丢弃70%的神经元输出。这是一种强力的正则化技术,迫使网络不依赖于任何少数特定的神经元,从而学习到更鲁棒、更分散的特征,有效对抗过拟合。
线性分类层
输出:一个带有softmax激活函数的线性层,输出1000个类别的概率分布(与ImageNet数据集的主分类任务完全一致)。
关键:在训练时,其损失会以一定的权重(如0.3)加入到网络的总损失中,共同参与反向传播。在推理时,整个辅助分类器(从池化层到该分类层)会被整体移除,不影响最终预测效率。
四、GoogLeNet和VGGNet参数对比
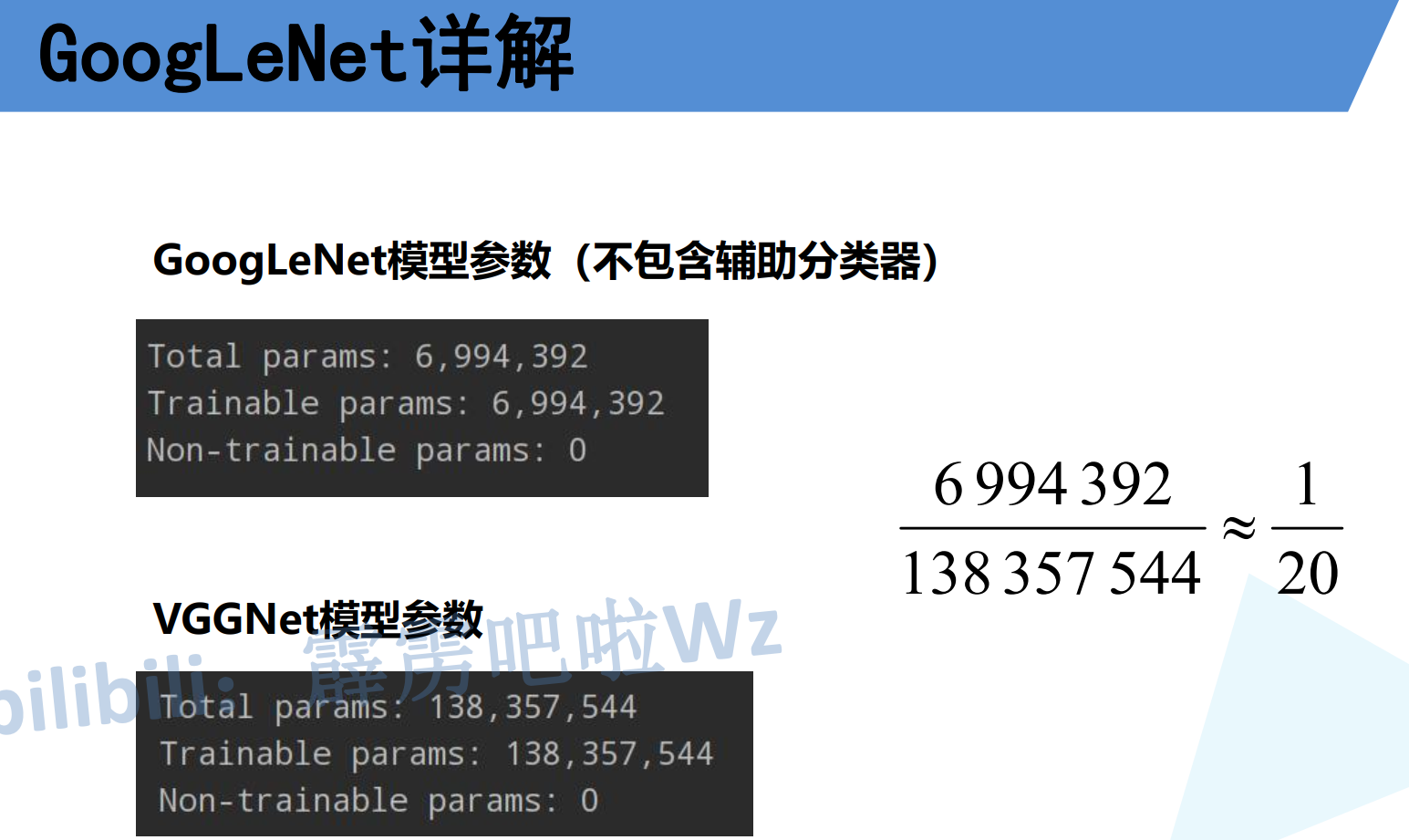
可以看出引入了降维的操作后参数量是VGG的1/20。
五、代码分析
5.1 model.py
import torch.nn as nn
import torch
import torch.nn.functional as F
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_logits: # eval model lose this layer
return x, aux2, aux1
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
代码解析:
相较VGG的代码,GoogLeNet的实现有几个不同:
-
辅助分类器的设计:通过
aux_logits参数控制是否使用辅助分类器。在forward中,通过self.training判断当前是训练还是推理,仅在训练阶段计算辅助分类器的输出。推理时直接返回主分类器的结果,这就是代码中if self.training and self.aux_logits的作用。 -
权重初始化方式不同:VGG使用的是
xavier_uniform_,而GoogLeNet使用的是kaiming_normal_(He初始化)。He初始化更适合ReLU激活函数,因为ReLU会使一半的神经元输出为0,方差会减半,He初始化对此做了补偿。 -
用 AdaptiveAvgPool2d 替代了全连接层的展平:
nn.AdaptiveAvgPool2d((1, 1))将特征图自适应池化到1×1大小,然后直接接线性层,大大减少了参数量。对比VGG的512*7*7=25088维输入,GoogLeNet只有1024维输入。
Inception模块
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
# 在官方的实现中,其实是3x3的kernel并不是5x5,这里我也懒得改了,具体可以参考下面的issue
# Please see https://github.com/pytorch/vision/issues/906 for details.
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
代码解析:
Inception模块是GoogLeNet的新增,代码包括一些参数:
-
7个参数:
in_channels(输入通道数)+ 6个通道数配置参数(分别对应4个分支的输出通道数)ch1x1:branch1的1×1卷积输出通道ch3x3red:branch2的1×1降维通道,ch3x3:branch2的3×3卷积输出通道ch5x5red:branch3的1×1降维通道,ch5x5:branch3的5×5卷积输出通道pool_proj:branch4池化后的1×1卷积输出通道
-
torch.cat(outputs, 1):在维度1(通道维度)上拼接四个分支的输出。这就是为什么要求四个分支输出的高和宽必须相同。 -
branch4的池化层:使用
stride=1, padding=1,保证池化后特征图尺寸不变,只有通道数改变。 -
注释中的issue:官方PyTorch实现中,branch3的5×5卷积实际上被替换为3×3卷积,这是一个有趣的细节,代码作者保留了5×5并做了注释说明。
辅助分类器 InceptionAux
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = self.averagePool(x)
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
x = F.dropout(x, 0.5, training=self.training)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes
return x
代码解析:
- 辅助分类器接收的是Inception4a(512通道)或Inception4d(528通道)的输出
- 经过5×5平均池化(stride=3)后,特征图变为4×4
- 再经1×1卷积降维到128通道,展平后得到 128×4×4=2048 维向量
- 两层全连接(2048→1024→num_classes),中间有ReLU和Dropout
BasicConv2d
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
代码解析:
将"卷积+ReLU"封装成一个基础模块,在GoogLeNet中大量复用。这种封装方式比VGG代码中直接在Sequential里堆叠更加模块化、可读性更好。
5.2 train.py
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdm
from model import GoogLeNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 32
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
net = GoogLeNet(num_classes=5, aux_logits=True, init_weights=True)
# 如果要使用官方的预训练权重,注意是将权重载入官方的模型,不是我们自己实现的模型
# 官方的模型中使用了bn层以及改了一些参数,不能混用
# import torchvision
# net = torchvision.models.googlenet(num_classes=5)
# model_dict = net.state_dict()
# # 预训练权重下载地址: https://download.pytorch.org/models/googlenet-1378be20.pth
# pretrain_model = torch.load("googlenet.pth")
# del_list = ["aux1.fc2.weight", "aux1.fc2.bias",
# "aux2.fc2.weight", "aux2.fc2.bias",
# "fc.weight", "fc.bias"]
# pretrain_dict = {k: v for k, v in pretrain_model.items() if k not in del_list}
# model_dict.update(pretrain_dict)
# net.load_state_dict(model_dict)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0003)
epochs = 30
best_acc = 0.0
save_path = './googleNet.pth'
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
logits, aux_logits2, aux_logits1 = net(images.to(device))
loss0 = loss_function(logits, labels.to(device))
loss1 = loss_function(aux_logits1, labels.to(device))
loss2 = loss_function(aux_logits2, labels.to(device))
loss = loss0 + loss1 * 0.3 + loss2 * 0.3
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device)) # eval model only have last output layer
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()
代码解析:
train.py与之前LeNet、AlexNet、VGG的训练脚本框架一致,但有一个关键区别——损失函数的计算:
logits, aux_logits2, aux_logits1 = net(images.to(device))
loss0 = loss_function(logits, labels.to(device))
loss1 = loss_function(aux_logits1, labels.to(device))
loss2 = loss_function(aux_logits2, labels.to(device))
loss = loss0 + loss1 * 0.3 + loss2 * 0.3
训练时,模型返回三个输出:主分类器logits + 两个辅助分类器aux2和aux1。三个输出分别计算交叉熵损失,辅助分类器的损失乘以0.3的权重后相加。这也是论文中提出的训练策略。
另外注意验证阶段:net.eval() 后模型只返回主分类器的输出(outputs = net(val_images.to(device))),辅助分类器在推理时不参与。
代码注释中也提醒了:如果要使用官方的预训练权重,不能直接加载到我们自己实现的模型中,因为官方实现使用了BN层且修改了一些参数,两者的结构不完全一致。
5.3 predict.py
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import GoogLeNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img_path = "../tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# create model
model = GoogLeNet(num_classes=5, aux_logits=False).to(device)
# load model weights
weights_path = "./googleNet.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
missing_keys, unexpected_keys = model.load_state_dict(torch.load(weights_path, map_location=device),
strict=False)
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()
代码解析:
预测脚本与之前网络的预测脚本结构基本一致,但有两个细节值得注意:
aux_logits=False:预测时创建模型不需要辅助分类器,节省内存和计算。strict=False:加载权重时使用非严格模式,因为训练时的模型包含辅助分类器的权重(aux1、aux2),而预测模型中没有这些层,strict=False允许忽略不匹配的键。
总结
以上就是今天要讲的内容

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)